문서 요약 자동화를 위한 LangChain 활용
LangChain은 대규모 언어 모델(LLM)을 다양한 도구 및 데이터 소스와 연결하여 문서 처리 작업을 자동화할 수 있습니다.
개발자는 긴 문서를 빠르고 정확하게 요약하는 애플리케이션을 만들 수 있어 시간과 노력을 크게 절약할 수 있습니다.
문서 요약 자동화를 위한 LangChain 활용
기본 문서 처리 파이프라인 구축
-
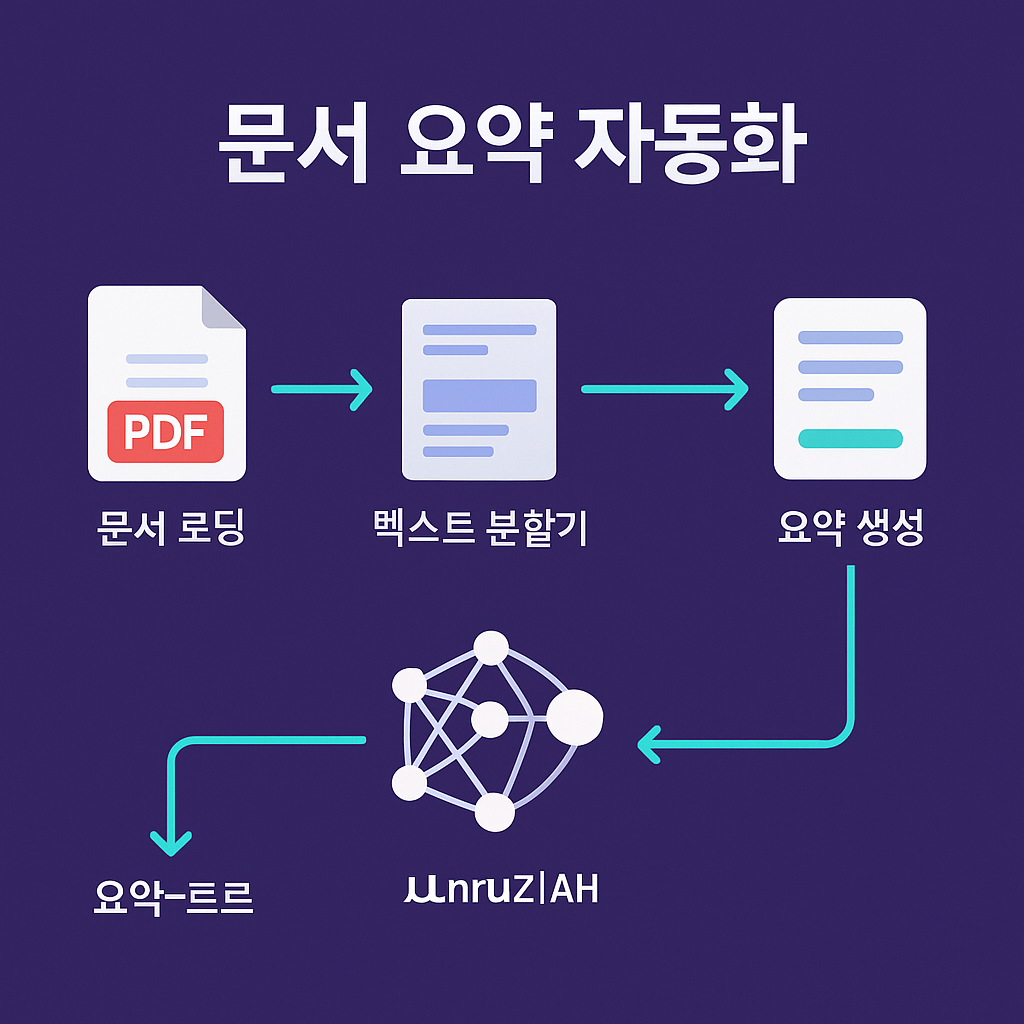
LangChain을 사용한 문서 처리의 핵심은 문서 로딩, 텍스트 분할기, 언어 모델을 연결하는 파이프라인을 구축
1. 문서 로딩: DocumentLoader를 사용하여 PDF, 웹사이트, 데이터베이스 등 다양한 소스에서 콘텐츠를 가져옵니다.
2. 텍스트 분할: 큰 문서를 관리 가능한 청크로 나누기 위해 RecursiveCharacterTextSplitter와 같은 도구를 사용합니다.
3. 요약 생성: 처리된 텍스트를 OpenAI의 GPT-3.5나 다른 오픈소스 엔진과 같은 LLM에 전달합니다.
긴 문서 처리하기
LangChain의 주요 장점 중 하나는 LLM 토큰 제한을 초과하는 긴 문서를 처리할 수 있는 능력입니다.
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)
# 문서 로딩 및 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(long_document_text)
# 요약 체인 생성 및 실행
chain = load_summarize_chain(llm, chain_type="map_reduce")
summary = chain.run(texts)-
이 접근 방식은 "map-reduce" 전략을 사용합니다.
- Map: 각 섹션을 개별적으로 요약
- Reduce: 섹션 요약들을 결합하여 최종 요약 생성
자동 문서 처리를 위한 고급 기법
사용자 정의 처리 파이프라인
-
LangChain은 특정 사용 사례에 맞게 처리 파이프라인을 사용자 정의할 수 있는 유연성을 제공
- 질저리 단계: 질문을 사용하여 관련 없는 섹션 필터링
- 후처리: 스타일 가이드라인 적용
- 특수 사용 사례: 법률 계약서 요약 시 핵심 조항 먼저 추출 후 이후 단계에서 검토하도록 LLM에 지시
다양한 문서 형식 처리
-
LangChain은 여러 문서 형식을 처리하기 위한 다양한 로더를 제공
- PDF: PyPDFLoader
- Word 문서: DocxTextLoader
- HTML/DOCX: UnstructuredFileLoader
- 범용 처리: 지원되지 않는 형식을 위한 UnstructuredFileLoader
구조화된 출력 생성
-
문서에서 구조화된 데이터를 추출
- PydanticOutputParser를 사용하여 LLM 응답을 JSON 스키마로 검증
- OutputParsers로 LLM 텍스트 응답을 CSV, JSON과 같은 구조화된 형식으로 변환
- 추출된 데이터를 데이터베이스나 API와 통합
실무 응용 사례
LangChain을 활용한 문서 처리는 다양한 실무 환경에서 유용합니다.
- 법률 문서: 계약서에서 핵심 조항 추출 및 의무 사항 요약
- 연구 논문: 대량의 학술 자료에서 핵심 요점 추출
- 의료 기록: 환자 기록에서 중요 정보 요약
- 재무 보고서: 재무 데이터 분석 및 주요 지표 추출
- 고객 피드백: 대량의 고객 리뷰 분석 및 주요 테마 식별
마무리
LangChain의 유연한 프레임워크는 개발자가 문서 처리 작업을 자동화하는 데 필요한 도구를 제공하여 대량의 정보를 효율적으로 관리할 수 있게 합니다.
이를 통해 수동 검토가 필요했던 작업을 자동화하면서도 대규모 문서 세트 전반에 걸쳐 일관성을 보장할 수 있습니다.
