
LangChain 기반 시계열 데이터 분석 및 이상 탐지 시스템
LangChain을 활용해 시계열 데이터 분석 및 이상 탐지 시스템을 구축하는 방법을 단계별로 설명합니다.
본 시스템은 LLM의 자연어 처리 능력과 머신러닝 모델의 분석 기능을 결합해 종합적인 인사이트를 제공합니다.
시스템 아키텍처
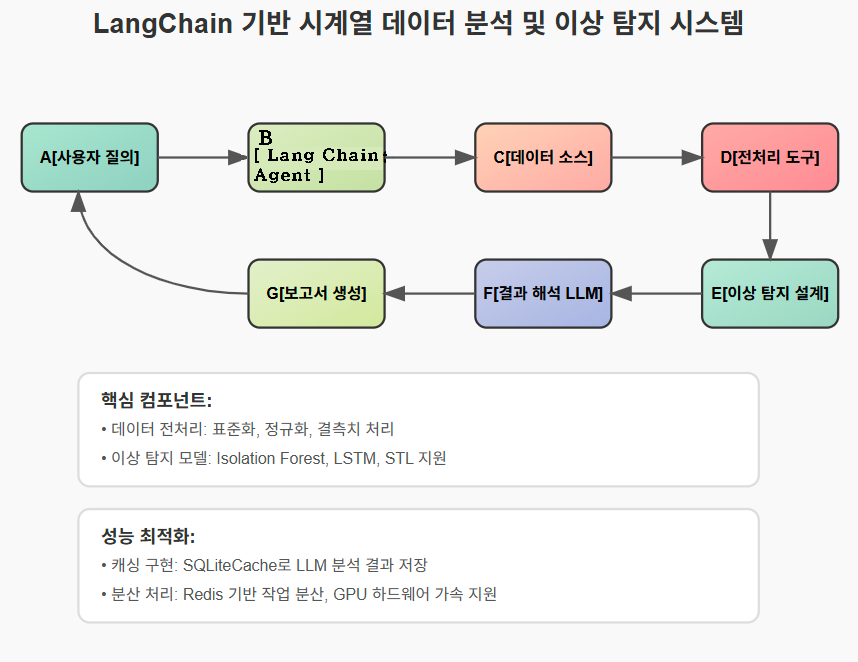
A[사용자 질의] → B[LangChain Agent]
- 사용자의 질문을 LangChain Agent가 처리
- 자연어 요청을 시스템 컴포넌트로 라우팅
B → C[데이터 소스]
- 다양한 데이터 소스(CSV, DB, API)로부터 데이터 수집
- 시계열 데이터 포맷으로 변환
C → D[전처리 도구]
- 시계열 데이터 표준화
- 결측치 처리, 이상값 필터링, 정규화 수행
D → E[이상 탐지 설계]
- 다양한 모델 지원: Isolation Forest, LSTM, STL 등
- 데이터 특성에 따른 최적 모델 자동 선택
E → F[결과 해석 LLM]
- ChatOpenAI(model="gpt-4o") 활용
- 이상 탐지 결과를 자연어로 해석 및 설명
F → G[보고서 생성]
- 자연어 형태의 분석 보고서 생성
- 시각화 자료 포함 가능
핵심 컴포넌트 구현
1. 데이터 전처리 도구
@tool
def preprocess_data(raw_data: dict) -> pd.DataFrame:
"""시계열 데이터 표준화
Args:
raw_data: {'timestamp': [...], 'values': [...]}
"""
df = pd.DataFrame(raw_data)
df['value'] = (df['value'] - df['value'].mean()) / df['value'].std()
return df2. 이상 탐지 모델
@tool
def detect_anomalies(data: pd.DataFrame, model_type: str = "isolation_forest") -> dict:
"""시계열 데이터 이상 탐지 도구
Args:
data: 시계열 DataFrame (timestamp, value)
model_type: isolation_forest, lstm, stl
Returns:
{'scores': [...], 'threshold': float}
"""
if model_type == "isolation_forest":
model = IsolationForest(contamination=0.05)
scores = model.fit_predict(data[['value']])
return {'scores': scores.tolist(), 'threshold': -0.5}3. 모델 선택 로직
MODEL_SWITCH_LOGIC = {
"계절성 감지": "stl",
"비선형 패턴": "lstm",
"기본": "isolation_forest"
}
def select_model(data: pd.DataFrame) -> str:
from statsmodels.tsa.seasonal import STL
stl = STL(data['value']).fit()
if stl.seasonal.std() > data['value'].std()*0.3:
return "stl"
# 추가 로직...4. LangChain 에이전트 구성
from langchain.agents import initialize_agent
from langchain.chat_models import ChatOpenAI
tools = [detect_anomalies, preprocess_data]
llm = ChatOpenAI(model="gpt-4o")
agent = initialize_agent(
tools,
llm,
agent="structured-chat-zero-shot-react-description",
verbose=True
)5. 결과 해석 모듈
from langchain.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "나는 데이터 분석 전문가입니다. 다음 결과를 설명해주세요:"),
("human", "이상 점수: {scores}\n임계값: {threshold}")
])
interpret_chain = prompt | llm
interpret_chain.invoke({
"scores": [-0.1, 0.5, -1.2, ...],
"threshold": -0.5
})성능 최적화 전략
1. 캐싱 구현
from langchain.cache import SQLiteCache
import langchain
langchain.llm_cache = SQLiteCache("analysis_cache.db")2. 분산 처리 아키텍처
from langchain.distributed import DistributedAgent
dist_agent = DistributedAgent(
agent,
redis_url="redis://localhost:6379",
task_timeout=300
)3. 하드웨어 가속
@tool(accelerator="cuda")
def lstm_prediction(data: pd.DataFrame):
import torch
# CUDA 가속 LSTM 모델 실행배포 및 모니터링
Docker 구성
# docker-compose.yml
services:
langchain-api:
image: langchain-analytics:v1.0
ports:
- "8000:8000"
depends_on:
- mlflow
- redis
mlflow:
image: mlflow-server:latest
redis:
image: redis:alpine실행 방법
python -m uvicorn main:app --reload --port 8000시스템 특징 및 장점
- 다양한 데이터 소스: CSV, DB, API, 실시간 스트림 등 지원
- 자동 모델 선택: 데이터 특성 기반 자동형 알고리즘 선택
- 실용적 해석: LLM 기반 자연어 설명 자동 생성
- 확장성: 새로운 모델 및 전처리 기법 모듈식 추가 가능
이 시스템은 제조 설비 모니터링, 금융 시간 탐지, IoT 센서 분석 등 다양한 분야에 적용 가능하며, LangChain의 유연한 확장성을 통해 자속적인 기능 향상이 가능합니다.

레거시를 이해하면서도 새로운 기술을 현실적으로 적용할 수 있는 백엔드 개발자가 되는 것이 목표입니다.