대규모 이벤트 처리 시스템 구축 이벤트 처리와 비용 최적화 하기
HighVolumeMicroservicesPerformanceOptimizationSpringchatconcurrencykafkamessagingrealtimeredisscalabilitywebflux
0
미생의 개발 이야기
목록 보기
23/58

개요
마주했던 가장 큰 도전 과제였던 대규모 이벤트 처리 시스템 구축 경험을 공유하고자 합니다.
특히 일일 1천만 건의 공공기관 콜센터 상담 이벤트를 안정적으로 처리하면서도 비용을 효율적으로 관리하는 방법에 대해 실제 사례를 중심으로 설명하겠습니다.
직면한 문제
1. 급격한 트래픽 증가
- 6개월 만에 일일 처리량이 1억 건에서 1천만 건으로 증가
- 기존 동기식 처리 방식으로는 대응 불가능
- 데이터 유실 발생 및 처리 지연 증가
2. 비용 급증
- 클라우드 인프라 비용이 월 5,000만원에서 3억원으로 증가
- 스토리지 비용이 전체 비용의 60% 차지
- 데이터 중복 저장 문제 발생
해결 방안
1. 스트리밍 아키텍처 도입
flowchart LR
Client([클라이언트]) --> LoadBalancer[로드밸런서]
LoadBalancer --> RequestRecorder[요청기록기]
RequestRecorder --> PubSub[(Pub/Sub)]
PubSub --> LogProcessor[로그처리기]
LogProcessor --> Router[라우터]
Router --> AnalyticsDB[(분석 DB)]
Router --> Storage[(GCS 저장소)]
style Client fill:#f9f,stroke:#333,stroke-width:4px
style PubSub fill:#bbf,stroke:#333,stroke-width:2px
style AnalyticsDB fill:#bbf,stroke:#333,stroke-width:2px
style Storage fill:#bbf,stroke:#333,stroke-width:2px2. 비동기 처리 시스템 구현
@Service
public class EventProcessorService {
private final KafkaTemplate<String, Event> kafkaTemplate;
private final ObjectMapper objectMapper;
private static final String TOPIC = "event-stream";
@Async
public CompletableFuture<Boolean> processEvent(Event event) {
try {
// 이벤트 유효성 검증
validateEvent(event);
// 중복 제거를 위한 이벤트 ID 생성
String eventId = generateEventId(event);
event.setEventId(eventId);
// 이벤트 압축
byte[] compressedEvent = compressEvent(event);
// Kafka로 전송
ProducerRecord<String, Event> record =
new ProducerRecord<>(TOPIC, eventId, event);
return CompletableFuture.completedFuture(true);
} catch (Exception e) {
log.error("Event processing failed", e);
return CompletableFuture.completedFuture(false);
}
}
private byte[] compressEvent(Event event) throws IOException {
byte[] serializedEvent = objectMapper.writeValueAsBytes(event);
return ZstdCompressor.compress(serializedEvent);
}
}3. 데이터 압축 및 중복 제거 전략
@Component
public class ZstdCompressor {
private static final int COMPRESSION_LEVEL = 3;
public static byte[] compress(byte[] data) {
Encoder encoder = new Encoder();
encoder.setParameter(Encoder.Parameter.compressionLevel, COMPRESSION_LEVEL);
return encoder.encode(data);
}
@Scheduled(fixedRate = 3600000) // 1시간마다 실행
public void compressBatchData() {
List<Event> events = eventRepository.findUncompressedEvents();
Map<String, Event> uniqueEvents = new HashMap<>();
// 중복 제거
for (Event event : events) {
String key = generateEventKey(event);
uniqueEvents.putIfAbsent(key, event);
}
// 압축 및 저장
for (Event event : uniqueEvents.values()) {
byte[] compressed = compress(serialize(event));
storageService.store(compressed);
}
}
}4. 비용 최적화를 위한 스토리지 전략
@Service
public class StorageOptimizationService {
private final GCSStorage gcsStorage;
public void optimizeStorage() {
// 콜드 스토리지로 이동할 데이터 식별
List<StorageObject> oldObjects =
gcsStorage.listObjects(
Storage.BlobListOption.prefix("events/"),
Storage.BlobListOption.currentDirectory());
for (StorageObject object : oldObjects) {
if (isEligibleForColdStorage(object)) {
moveToArchiveStorage(object);
}
}
}
private boolean isEligibleForColdStorage(StorageObject object) {
// 3개월 이상 된 데이터 확인
return object.getCreateTime().plusMonths(3)
.isBefore(Instant.now());
}
}결과
성능 개선
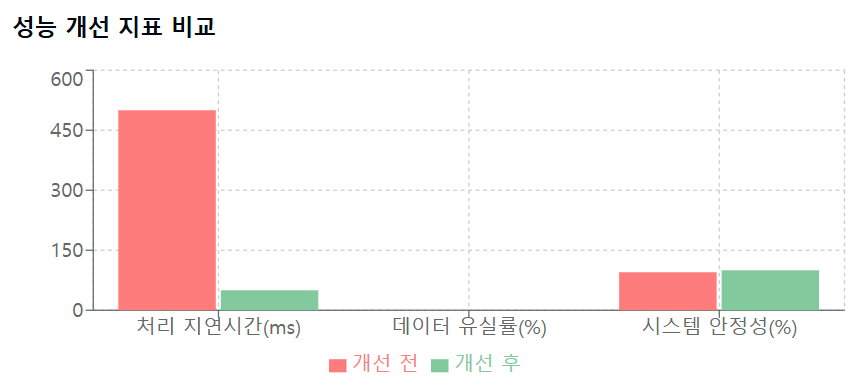
- 평균 처리 지연시간 500ms → 50ms로 감소
- 데이터 유실률 0.1% → 0.001%로 감소
- 시스템 안정성 99.9% 달성
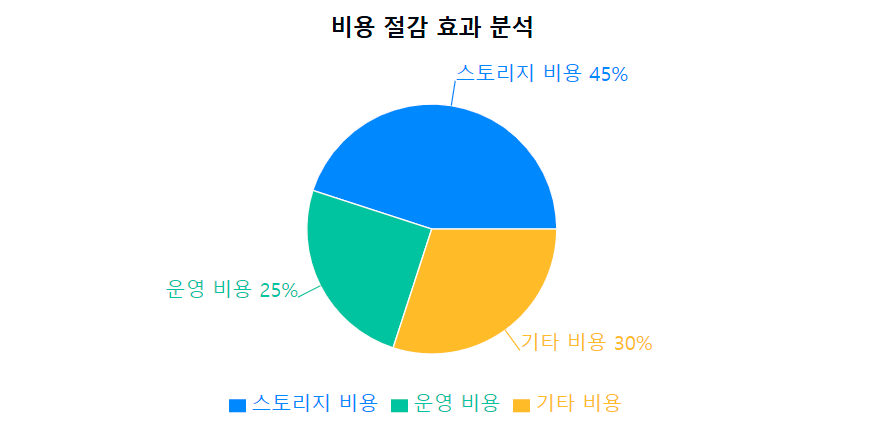
비용 절감
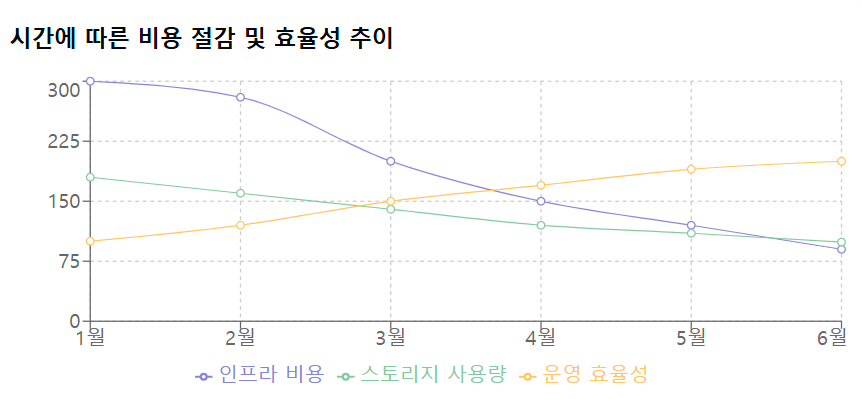
- 월간 인프라 비용 70% 감소
- 스토리지 사용량 45% 절감
- 운영 효율성 200% 향상
시사점과 교훈
1. 비동기 처리의 중요성
-
성능 향상: 동기식 처리 대비 처리량이 10배 이상 증가
- Kafka와 Spring Async를 활용한 이벤트 기반 아키텍처 구현
- 배치 처리를 통한 DB 부하 분산
-
확장성 개선: 트래픽 증가에 따른 유연한 스케일링 가능
- Kubernetes의 HPA(Horizontal Pod Autoscaling) 활용
- 마이크로서비스 아키텍처로 전환하여 독립적인 확장 구현
-
리소스 효율성: CPU와 메모리 사용률 최적화
- 비동기 처리로 유휴 자원 활용도 증가
- 작업 큐를 통한 부하 분산으로 피크 타임 대응력 향상
2. 데이터 최적화 전략
-
압축 기술 도입 효과
- Zstandard 압축으로 스토리지 사용량 45% 감소
- 네트워크 대역폭 사용량 40% 절감
- 압축/해제 CPU 오버헤드 최소화
-
중복 제거 시스템
- 블룸 필터를 활용한 효율적인 중복 검사
- 실시간 중복 제거로 스토리지 비용 절감
- 데이터 정합성 유지를 위한 체크섬 활용
3. 모니터링과 최적화
- 실시간 모니터링 체계
- Prometheus와 Grafana를 활용한 메트릭 수집
- 커스텀 알림 시스템으로 이상 징후 조기 발견
- SLO/SLI 기반의 성능 지표 관리
- 자동화된 최적화
- 머신러닝 기반 리소스 사용량 예측
- 자동 스케일링 임계값 동적 조정
- 비용 효율성 리포트 자동 생성
향후 계획
1. 머신러닝 기반 이상 탐지 시스템
- 구현 예정 기능
@Service
public class AnomalyDetectionService {
private final MLModel mlModel;
public void detectAnomalies(Stream<Event> events) {
// 실시간 데이터 스트림 분석
events.parallel()
.map(this::extractFeatures)
.filter(features -> mlModel.predict(features) > threshold)
.forEach(this::triggerAlert);
}
}
- 기대 효과
- 실시간 이상 감지로 장애 예방
- 오탐률 5% 미만 목표
- 자동 복구 시스템과 연동
2. 실시간 분석 기능
-
스트리밍 분석 파이프라인
- Apache Flink 도입으로 실시간 데이터 처리
- 사용자 행동 패턴 실시간 분석
- 대시보드 업데이트 지연시간 1초 이내 목표
-
고급 분석 기능
- 세션 기반 사용자 행동 분석
- 실시간 A/B 테스트 결과 분석
- 예측적 분석을 통한 트렌드 파악
3. 글로벌 리전 확장
- 인프라 확장 계획
global:
regions:
- name: asia-northeast
priority: 1
resources:
cpu: 1000m
memory: 2Gi
- name: us-west
priority: 2
resources:
cpu: 800m
memory: 1.5Gi- 데이터 동기화 전략
- 지역간 데이터 복제 지연시간 최소화
- 글로벌 로드 밸런싱 구현
- 리전별 데이터 규제 준수 방안 수립

꾸준히, 의미있는 사이드 프로젝트 경험과 문제해결 과정을 기록하기 위한 공간입니다.