소개
이 글은 SOOP 기술팀이 공유한 "댓글 시스템의 다단계 저장 구조" 를 기반으로 합니다.
이 글은 수억 건의 트래픽이 몰려오는 상황 속에서도, 하나의 초대형 커뮤니티가 어떻게 핵심 인터랙션 기능을 안정적으로 유지할 수 있었는지를 잘 보여줍니다.
다만, 해당 아키텍처의 핵심 구성요소인 "GIGABYTE G-Series 서버"는 자체 개발한 시스템이기 때문에 외부에서 직접 접근할 수는 없습니다.
그래서 이번 글의 핵심 목표는, 이 고급 사설 아키텍처를 우리가 잘 아는 오픈소스 기술로 "번역" 해보는 데 있습니다.
**MySQL** , **Redis** 그리고 Java 기술 스택을 기반으로, 다단계 저장 구조, 데이터 동기화, 페일오버 및 디그레이드 전략 같은 핵심 설계를 어떻게 재현할 수 있는지 함께 살펴보겠습니다.
이 글이 대형 IT 기업의 시스템 아키텍처를 탐구해보는 첫걸음이 되었으면 합니다.
글을 읽으며 떠오르는 의견이나 궁금한 점이 있다면 댓글로 함께 이야기 나눠요. 같이 성장해나가길 바랍니다.
댓글시스템 아키텍처 분석하기
(참고: 시스템에서는 TiDB를 주 저장소로 사용하고 있습니다.
본 글에서도 원문의 느낌을 살리기 위해 TiDB를 사용했지만, 독자 여러분은 익숙한 데이터베이스(MySQL등)로 충분히 구현이 가능합니다.
아키텍처의 핵심 개념은 그대로 적용되기 때문입니다.)
거대한 댓글 시스템을 하나의 초대형 도서관이라고 상상해보세요.
그 안에 있는 수많은 댓글들은 일종의 책이라고 볼 수 있습니다.
이제 이 도서관이 마주한 두 가지 핵심 문제를 먼저 살펴봅시다.
💥 주요 문제점
1. 책 찾기가 너무 느리다 (조회 성능의 병목 현상)
수천, 수만 명의 사람들이 "가장 인기 있는 댓글 10개"를 보려고 할 때, 도서관 관장(TiDB)은 전 서가를 몽땅 뒤져야 합니다.
일일이 다 꺼내서 정렬하고, 그중 TOP 10을 골라야 하죠.
이 작업은 느릴 뿐 아니라, 관장을 지치게 만들어 다른 대출/반납 업무(일반 읽기·쓰기)도 함께 느려집니다.
2. 관장이 아프면 도서관 마비 (단일 장애점 위험)
이 도서관엔 관장이 딱 한 명(TiDB 클러스터)뿐입니다.
만약 이 사람이 아프거나(노드 다운, 네트워크 지연 등) 잠시 자리를 비우면, 도서관 전체 운영이 중단될 수 있습니다.
🧠 "다단계 저장소" 시스템
이 문제들을 해결하기 위해, SOOP의 개발자들은 다단계 저장소 구조를 설계했습니다.
핵심 아이디어는 이렇습니다.
모든 요청을 메인 데이터베이스(TiDB) 하나에 몰아주지 않고, 역할을 나눠서 빠르고 효율적인 부서(예: Redis)를 함께 활용한다는 것.
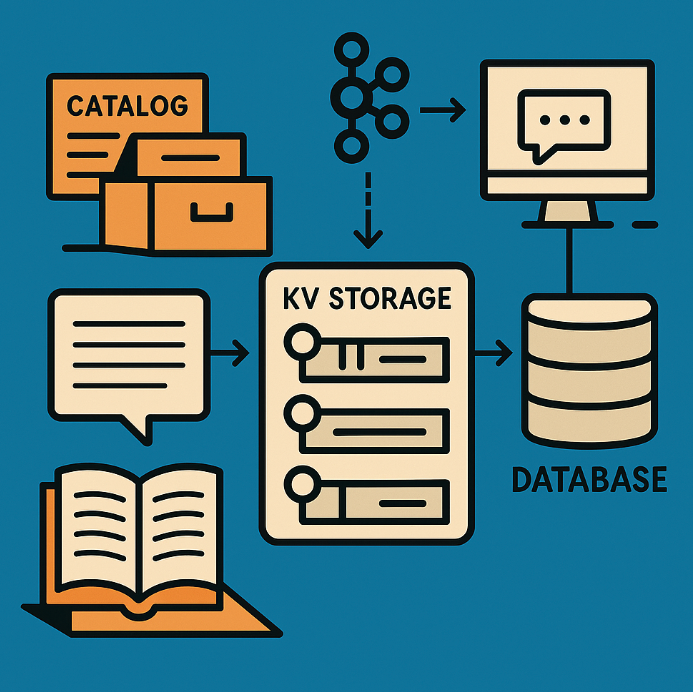
✅ 핵심 설계 1: "책"과 "목차"를 분리해 초고속 조회
이게 전체 시스템의 핵심입니다.
도서관에서 책을 찾는 대신, 전용 목차 검색 데스크를 두는 겁니다.
구조는 다음과 같습니다.
-
KV 저장소: 댓글 본문은 KV(Key-Value) 형태로 저장됩니다.
책 한 권(댓글 하나)은 고유 ID(reply_id)로 저장되어, 해당 ID만 알면 즉시 내용을 꺼낼 수 있어요. -
인덱스(Index): 인기순, 최신순 등의 목록은 Redis가 담당합니다.
Redis는 책을 저장하진 않지만, 정렬된 책 ID 리스트를 보관합니다.
(예: 좋아요 수 순으로 정렬된 ID들)
🔁 예를 들어, 사용자가 “좋아요 TOP 10 댓글”을 보려고 하면,
1. “Redis에 요청 → 좋아요 순 Top 10 댓글 ID를 가져옴“
2. “이 ID들을 가지고 KV 저장소에서 실제 댓글 내용을 조회“
이 방식은 기존처럼 전체 서가를 뒤지는 게 아니라, 정렬된 인덱스를 통해 위치만 알아낸 후 정확한 ID로 빠르게 꺼내는 방식입니다.
조회 성능이 비약적으로 좋아집니다.
✅ 핵심 설계 2: "작업일지"와 "전자 게시판"으로 인덱스를 항상 최신 상태로
그런데, Redis는 책 내용을 직접 보지 않기 때문에, 어떤 댓글이 새로 등록되었는지, 좋아요가 얼마나 올랐는지 실시간으로 어떻게 알 수 있을까요?
이를 위해 도서관은 두 가지 시스템을 운영합니다.
- 작업일지 (Binlog): 관장(TiDB)은 어떤 작업을 하든 간에 반드시 일지(Binlog)에 기록합니다.
- 전자 게시판 (Kafka): 도서관 안의 공지사항 시스템입니다. Redis 등 다른 부서가 참고합니다.
🔁 작동 방식
- TiDB가 Binlog에 기록 → 예: 댓글 등록, 좋아요 +1
- TiCDC가 감지 → 일지를 복사해 메시지를 생성
- Kafka에 메시지 전송 → 전자 공지로 등록
- Redis가 Kafka 메시지를 소비 → 인덱스를 업데이트
이 방식은 비동기 처리입니다.
약간의 지연(ms 단위)은 생기지만, 그 대신 TiDB는 더 빠르게 운영될 수 있고 전체 시스템의 효율이 올라갑니다.
✅ 핵심 설계 3: 세 가지 안전장치로 데이터 불일치 방지
자동화 시스템이 아무리 잘 되어도, 예외 상황은 늘 생깁니다. Redis가 메시지를 못 받거나, Kafka가 일시적으로 지연되는 경우도 있겠죠?
이를 대비해 세 가지 안전장치가 마련되어 있습니다:
1. 실패 시 재시도 (ACK 기반)
Kafka는 메시지를 Redis가 '확실히 받았다'고 확인(ACK)할 때까지 계속 재시도합니다.
2. 버전 관리 (Version Stamp + CAS)
TiDB는 각 작업마다 버전 넘버를 붙입니다.
Redis는 버전이 최신일 때만 인덱스를 갱신해서, 과거 데이터로 덮어쓰는 실수를 방지합니다.
3. 정기 대조 (데이터 정합성 검증)
매일 특정 시간마다, TiDB와 Redis가 핵심 데이터를 대조해 불일치가 발견되면 즉시 Redis 데이터를 수정합니다.
✅ 핵심 설계 4: 서비스 중단 방지를 위한 이중 대응 전략
마지막으로, TiDB가 일시적으로 느려지거나 응답이 없을 때 어떻게 할까요? 사용자에게 "서버 응답 대기 중" 메시지를 보여줄 수는 없습니다.
그래서 프론트엔드 서비스 계층에서 '이중 경로 요청' 전략을 씁니다.
요청을 받으면,
1. 먼저 TiDB에 요청
2. 동시에 20ms 타이머 작동
3. 타이머가 끝날 때까지 응답이 없으면, Redis에게도 같은 요청
4. 먼저 도착한 결과를 사용
이 전략을 통해, TiDB가 지연되거나 장애가 있어도 사용자 측에서는 거의 끊김 없는 경험을 유지할 수 있습니다.
이를 우아한 장애 대응(failover) 이라고 부릅니다.
요약하자면
| 문제 | 해결 방법 |
|---|---|
| 조회 속도 느림 | Index + KV 구조 / Redis로 빠른 인덱스 제공 |
| 단일 장애점 위험 | Redis, Kafka, TiCDC로 부하 분산 |
| 인덱스 최신화 어려움 | Binlog → TiCDC → Kafka → Redis 연동 |
| 동기화 실패 가능성 | 재시도, 버전 관리, 정기 대조로 보완 |
| 장애 시 사용자 경험 저하 | 이중 요청 전략으로 무중단 처리 |
오픈소스 기반 기술 선택 및 아키텍처 구성
앞서 살펴본 핵심 설계 요소들을 바탕으로, 우리는 주류 오픈소스 컴포넌트를 활용한 기술 구현 방안을 제안합니다.
이 방안은 댓글 시스템의 아키텍처 철학을 재현하는 것을 목표로 하며,
고성능 읽기/쓰기 처리, 낮은 지연 시간의 조회, 높은 가용성을 갖춘 시스템을 구현할 수 있도록 설계되었습니다.
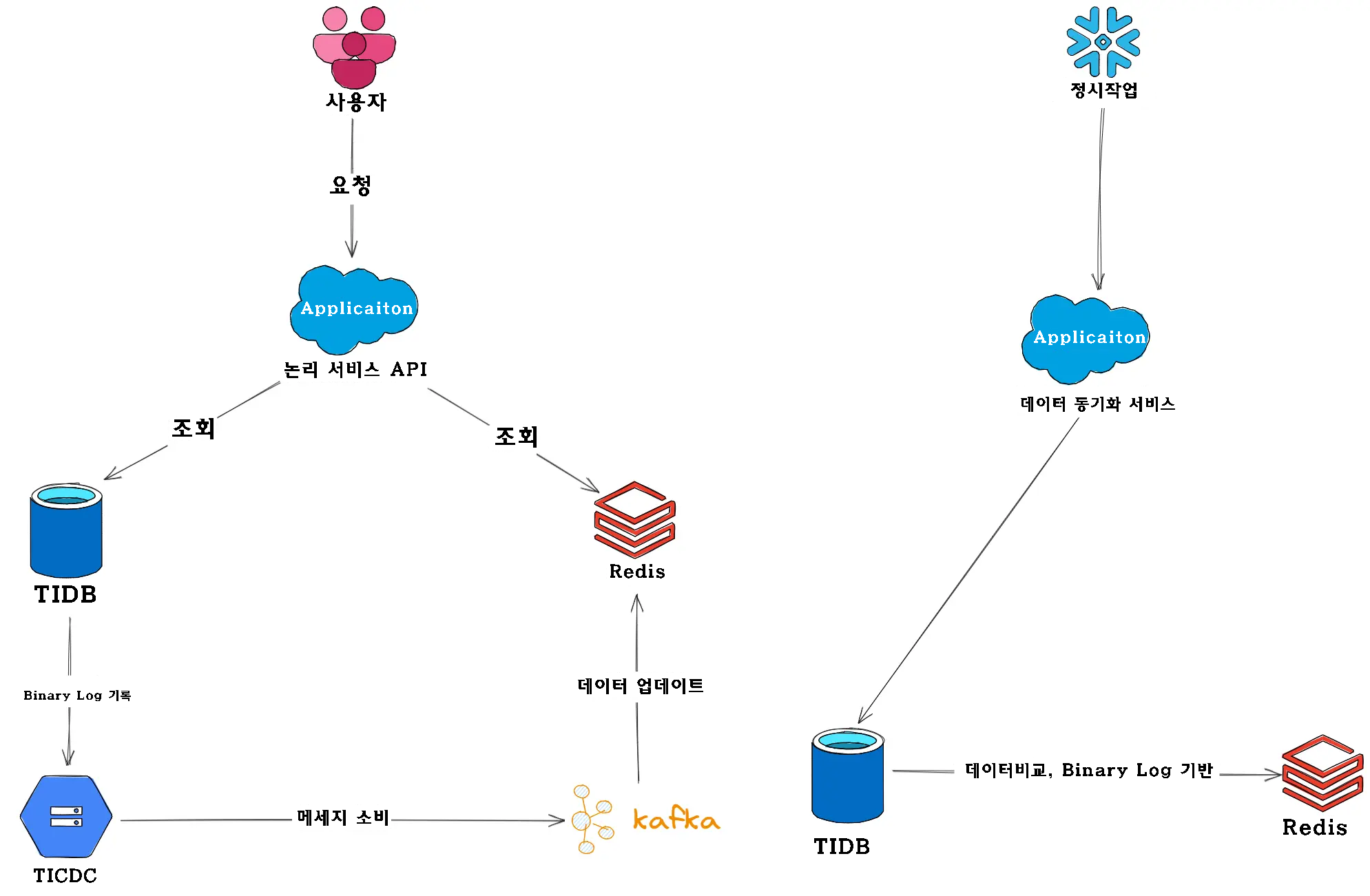
📦 주요 구성 요소 및 오픈소스 기반 아키텍처 설계
✅ 주 저장소: TiDB 클러스터
원본 아키텍처를 최대한 충실히 재현하기 위해, TiDB의 네이티브 분산 데이터베이스를 메인 저장소로 선택했습니다.
TiDB는 수평 확장이 뛰어나며, 고동시성 트래픽 처리에 유리한 구조를 갖추고 있습니다.
※ 참고: 만약 MySQL 환경에 더 익숙하다면, TiDB 대신 MySQL 클러스터로 대체해도 무방합니다. 이 경우, TiCDC 대신 Debezium을 데이터 동기화 도구로 사용할 수 있습니다.
✅ 다단계 저장소: Redis Cluster
스트링개발팀 자체 개발한 오픈소스 대체제로, Redis Cluster를 도입했습니다.
Redis는 빠른 Key-Value 처리 능력과 Sorted Set 구조를 바탕으로, 핫데이터 캐싱 및 인기순 정렬 기능을 구현하는 데 매우 적합합니다.
✅ 데이터 동기화 파이프라인 (DTS 대체 구성)
-
변경 감지(CDC)
TiDB의 공식 증분 동기화 도구인 TiCDC를 활용합니다.
이는 binlog의 변동 내용을 실시간으로 감지하고 하위 시스템으로 전달합니다. -
메시지 큐
산업 표준인 Apache Kafka를 메시지 브로커로 사용합니다.
TiCDC와 소비 애플리케이션 사이의 결합도를 낮추고, 데이터 버퍼링 및 고가용성을 제공합니다.
✅ 동기화 소비 애플리케이션
메시지 소비는 Spring Boot 애플리케이션으로 구현하며,
sprint-kafka 라이브러리를 통해 Kafka 메시지를 수신하고,
Lettuce 또는 Jedis 클라이언트를 통해 해당 데이터를 Redis Cluster에 반영합니다.
✅ 데이터 정합성 점검 서비스
분산형 스케줄링 프레임워크인 XXL-Job 등을 활용하여,
주기적으로 메인 저장소(TiDB)와 Redis 간의 데이터 일치 여부를 확인하고,
필요 시 자동으로 수정하는 데이터 대조 및 정합성 복구 프로세스를 수행합니다.
🛠 기술 구현
이론은 결국 실제로 구현해봐야 그 가치를 입증할 수 있습니다.
이제 직접 손으로 댓글 시스템의 핵심 아키텍처를 구축해보겠습니다.
🧱 개발 환경 구성
우리는 Docker를 활용해, TiDB, TiCDC, Kafka, Redis 등으로 구성된 통합 개발 환경을 손쉽게 구축할 수 있습니다.
docker-compose를 사용하면 이들 서비스를 한 번에 띄울 수 있는 자동화 구성이 가능해집니다.
- 먼저, 프로젝트를 위한 디렉토리를 하나 만들고
- 그 안에 docker-compose.yml 파일을 생성해
- 필요한 모든 컴포넌트를 정의합니다.
이렇게 하면 복잡한 설치 과정 없이도, 단 한 번의 명령으로 전체 환경을 빠르게 띄울 수 있습니다.
version: '3.8'
services:
# 1. TiDB 클러스터 (PD, TiKV, TiDB 포함)
pd:
image: pingcap/pd:v6.5.0
ports:
- "2379:2379"
volumes:
- ./pd_data:/data/pd
command:
- --name=pd
- --client-urls=http://0.0.0.0:2379
- --peer-urls=http://0.0.0.0:2380
- --advertise-client-urls=http://pd:2379
- --advertise-peer-urls=http://pd:2380
- --initial-cluster=pd=http://pd:2380
networks:
- tidb_net
tikv:
image: pingcap/tikv:v6.5.0
ports:
- "20160:20160"
volumes:
- ./tikv_data:/data/tikv
command:
- --addr=0.0.0.0:20160
- --advertise-addr=tikv:20160
- --pd=pd:2379
depends_on:
- pd
networks:
- tidb_net
tidb:
image: pingcap/tidb:v6.5.0
ports:
- "4000:4000" # MySQL 클라이언트 연결 포트
- "10080:10080"
command:
- --store=tikv
- --path=pd:2379
depends_on:
- tikv
networks:
- tidb_net
# 2. TiCDC (데이터 동기화 도구)
ticdc:
image: pingcap/ticdc:v6.5.0
ports:
- "8300:8300"
command: ["/cdc", "server", "--pd=http://pd:2379", "--addr=0.0.0.0:8300", "--advertise-addr=ticdc:8300"]
volumes:
- ./changefeed.toml:/tmp/changefeed.toml
depends_on:
- tidb
restart: unless-stopped
networks:
- tidb_net
# 3. Kafka 클러스터 (Zookeeper 및 Kafka 포함)
zookeeper:
image: confluentinc/cp-zookeeper:7.3.0
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
networks:
- tidb_net
kafka:
image: confluentinc/cp-kafka:7.3.0
ports:
- "29092:29092" # 호스트(Spring Boot 애플리케이션)에 노출된 포트
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTI persecut://kafka:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
networks:
- tidb_net
# 4. Redis (2차 저장소)
redis:
image: redis:6.2-alpine
ports:
- "6379:6379"
networks:
- tidb_net
networks:
tidb_net:
driver: bridge프로젝트 루트 디렉토리에는 changefeed.toml 파일을 생성합니다.
이 파일은 TiCDC가 comment_db 데이터베이스의 t_comment 테이블만 추적하도록 설정하는 역할을 합니다.
[filter]
# 필터링 규칙
rules = ['comment_db.t_comment']이어서 docker-compose.yml 파일이 위치한 디렉터리에서 아래 명령어를 실행합니다.
docker-compose up -d잠시만 기다려 주세요.
모든 서비스가 완전히 시작될 때까지 기다려야 합니다.
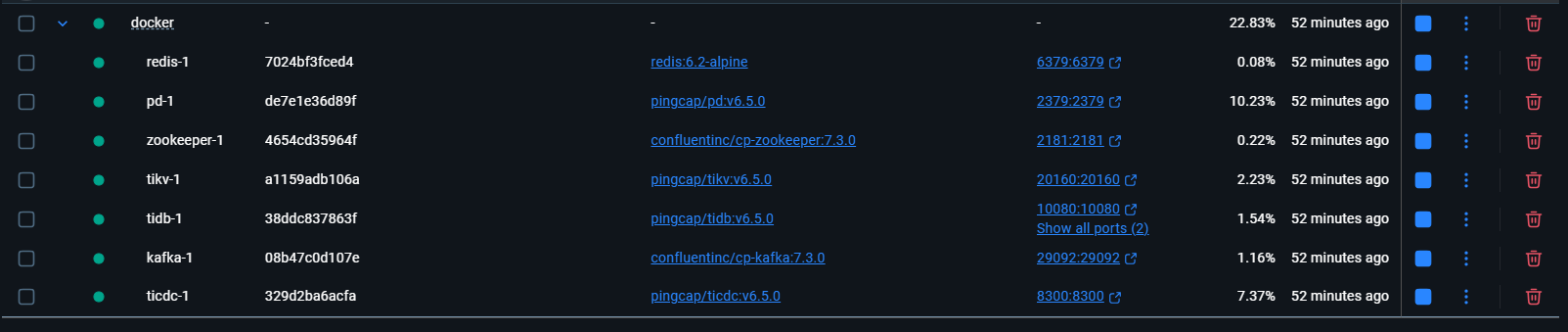
우리는 TiCDC를 위해 데이터 동기화 작업을 하나 더 만들어야 합니다.
이 작업은 TiDB와 Kafka 사이에서 데이터를 연결해 주는 역할을 합니다.
# 1. TiCDC 컨테이너에 진입
docker-compose exec ticdc sh
# 2. 컨테이너 내에서 생성 명령 실행
/cdc cli changefeed create \
--pd="http://pd:2379" \
--changefeed-id="comment-sync-to-kafka" \
--sink-uri="kafka://kafka:9092/comment-topic?protocol=open-protocol&kafka-version=2.8.1&max-message-bytes=10485760&partition-num=1" \
--config="/tmp/changefeed.toml"
# 3. 컨테이너 종료
exit이제 우리의 개발 환경이 모두 준비되었습니다!
데이터베이스 및 테이블 설계
표준 MySQL 클라이언트(예: Navicat, DBeaver, 또는 커맨드라인)를 사용해 TiDB에 접속할 수 있습니다.
접속 정보는 다음과 같습니다.
- 호스트: 127.0.0.1
- 포트: 4000
- 사용자명: root
- 비밀번호: (기본값은 없음)
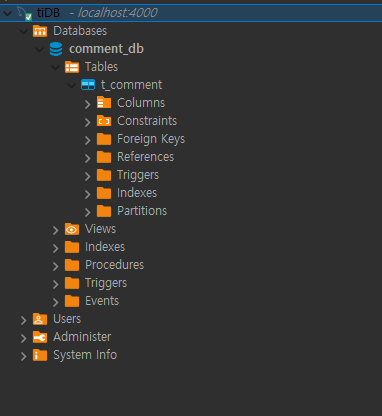
TiDB에 댓글 데이터를 저장할 테이블을 하나 만들어야 합니다.
아래의 SQL 문을 실행해 주세요.
-- 데이터베이스 생성
CREATE DATABASE `comment_db` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
-- 해당 데이터베이스로 전환
USE `comment_db`;
-- 댓글 테이블 생성
CREATE TABLE `t_comment` (
`id` BIGINT(20) NOT NULL AUTO_RANDOM, -- TiDB는 AUTO_RANDOM을 권장하여 쓰기 핫스팟 방지
`content` TEXT NOT NULL COMMENT '댓글 내용',
`user_id` VARCHAR(64) NOT NULL COMMENT '사용자 ID',
`likes` INT(11) UNSIGNED NOT NULL DEFAULT '0' COMMENT '좋아요 수',
`created_at` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '생성 시간',
`updated_at` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '업데이트 시간',
`version` INT(11) UNSIGNED NOT NULL DEFAULT '0' COMMENT '낙관적 잠금 버전 번호',
PRIMARY KEY (`id`),
KEY `idx_likes` (`likes`),
KEY `idx_created_at` (`created_at`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;추가 설명입니다.
-
AUTO_RANDOM: TiDB의 고유 기능으로, 샤딩 시 기본 키 값을 분산시켜 쓰기 요청이 특정 TiKV 노드에 집중되는 문제(쓰기 핫스팟)를 방지해줍니다.
-
version: 이 필드는 낙관적 락(Optimistic Lock)을 구현하기 위한 용도로 사용되며, 앞서 소개한 "핵심 설계 3"의 버전 관리 메커니즘과 연결됩니다.
동시 업데이트 시 데이터가 덮어써지는 문제를 막아줍니다.
📱 애플리케이션 개발
먼저, Spring Boot 프로젝트를 생성하고 필요한 **build.gradle.kts** 의존성을 추가합니다.
plugins {
kotlin("jvm") version "1.9.25"
kotlin("plugin.spring") version "1.9.25"
id("org.springframework.boot") version "3.5.0"
id("io.spring.dependency-management") version "1.1.7"
}
group = "com.sleekydz86"
version = "0.0.1-SNAPSHOT"
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.springframework.boot:spring-boot-starter")
implementation("org.jetbrains.kotlin:kotlin-reflect")
testImplementation("org.springframework.boot:spring-boot-starter-test")
testImplementation("org.jetbrains.kotlin:kotlin-test-junit5")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
implementation("org.springframework.boot:spring-boot-starter-data-redis")
implementation("org.springframework.kafka:spring-kafka")
//implementation("org.quartz-scheduler:quartz:2.3.2")
implementation("com.xuxueli:xxl-job-core:3.1.0")
}
kotlin {
compilerOptions {
freeCompilerArgs.addAll("-Xjsr305=strict")
}
}
tasks.withType<Test> {
useJUnitPlatform()
}
다음으로, application.yml에서 모든 서비스의 연결 정보를 설정합니다.
server:
port: 8082
spring:
# --- TiDB ---
datasource:
url: jdbc:mysql://127.0.0.1:4000/comment_db?useUnicode=true&characterEncoding=utf8mb4&serverTimezone=Asia/Seoul
username: root
password:
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
hibernate:
ddl-auto: update
show-sql: true
properties:
hibernate:
dialect: org.hibernate.dialect.MySQL8Dialect
# --- Redis ---
data:
redis:
host: 127.0.0.1
port: 6379
database: 0
# --- Kafka ---
kafka:
bootstrap-servers: localhost:29092
consumer:
group-id: comment-sync-group
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.ByteArrayDeserializer
# 스케줄링 센터 배포 루트 주소 [선택]: 스케줄링 센터 클러스터 배포 시 여러 주소가 있는 경우 쉼표로 구분. 실행기는 이 주소를 사용하여 "실행기 하트비트 등록" 및 "작업 결과 콜백"을 수행. 비어 있으면 자동 등록 비활성화;
xxl:
job:
admin:
addresses: http://127.0.0.1:8080/xxl-job-admin
# 실행기 통신 토큰 [선택]: 비어 있지 않으면 활성화;
accessToken: default_token
# 실행기 AppName [선택]: 실행기 하트비트 등록 그룹화 기준; 비어 있으면 자동 등록 비활성화
executor:
appname: xxl-job-executor-sample
# 실행기 등록 [선택]: 이 설정을 등록 주소로 우선 사용, 비어 있으면 내장 서비스 "IP:PORT"를 등록 주소로 사용. 이를 통해 컨테이너 타입 실행기의 동적 IP 및 동적 포트 매핑 문제를 유연하게 지원;
address:
# 실행기 IP [선택]: 기본값은 비어 있으며 자동으로 IP 획득. 다중 네트워크 카드일 경우 지정 IP를 수동으로 설정 가능. 이 IP는 호스트에 바인딩되지 않고 통신 용도로만 사용; 주소 정보는 "실행기 등록" 및 "스케줄링 센터 요청 및 작업 트리거"에 사용;
ip: 127.0.0.1
# 실행기 포트 번호 [선택]: 0 이하일 경우 자동 획득; 기본 포트는 9999이며, 단일 머신에 여러 실행기를 배포할 경우 서로 다른 실행기 포트를 설정해야 함;
port: 9999
# 실행기 실행 로그 파일 저장 디스크 경로 [선택]: 이 경로에 읽기/쓰기 권한이 필요; 비어 있으면 기본 경로 사용;
logpath: /data/applogs/xxl-job/jobhandler
# 실행기 로그 파일 보존 일수 [선택]: 만료된 로그 자동 정리, 제한값이 3 이상일 때 활성화; 그렇지 않으면, 예: -1, 자동 정리 기능 비활성화;
logretentiondays: 30Comment 엔티티는 댓글의 데이터 구조를 정의하는 클래스입니다.
여기서 우리는 @Version 어노테이션을 사용해 낙관적 락(Optimistic Lock)을 적용했습니다.
이 기능은 좋아요 수가 급격히 증가하는 고동시성 환경에서도 데이터 불일치 문제를 방지하는 데 핵심적인 역할을 합니다.
package com.sleekydz86.domain.comment.entity
import jakarta.persistence.*
import java.io.Serializable
import java.time.LocalDateTime
@Entity
@Table(name = "t_comment")
data class Comment(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
var id: Long? = null, // 댓글 ID
var content: String? = null, // 댓글 내용
var userId: String? = null, // 사용자 ID
var likes: Int = 0, // 좋아요 수, 기본값 0
@Column(name = "created_at", updatable = false)
var createdAt: LocalDateTime? = null, // 생성 시간
@Column(name = "updated_at")
var updatedAt: LocalDateTime? = null, // 수정 시간
@Version // 중요! 낙관적 락 버전 번호 필드
var version: Int = 0 // 버전, 기본값 0
) : Serializable {
companion object {
private const val serialVersionUID: Long = 1L // 직렬화 버전 UID
}
@PrePersist
protected fun onCreate() {
this.createdAt = LocalDateTime.now() // 생성 시 현재 시간 설정
this.updatedAt = LocalDateTime.now() // 생성 시 수정 시간도 현재 시간으로 설정
}
@PreUpdate
protected fun onUpdate() {
this.updatedAt = LocalDateTime.now() // 수정 시 현재 시간으로 갱신
}
}다음으로, 컨트롤러를 만들어서 API 입구로 설정해 줍니다.
package com.sleekydz86.global.jobhandler
import com.sleekydz86.domain.comment.service.CommentSyncService
import com.xxl.job.core.context.XxlJobHelper
import com.xxl.job.core.handler.annotation.XxlJob
import org.slf4j.LoggerFactory
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.stereotype.Component
@Component
class CommentSyncXxlJobHandler {
companion object {
private val log = LoggerFactory.getLogger(CommentSyncXxlJobHandler::class.java) // 로거
}
@Autowired
private lateinit var commentSyncService: CommentSyncService // 댓글 동기화 서비스
@XxlJob("syncHotCommentsJobHandler")
fun executeSyncHotComments() {
XxlJobHelper.log("【인기 댓글 동기화 작업】 시작...")
log.info("【인기 댓글 동기화 작업】 XXL-Job 트리거, 실행 시작...")
try {
// 핵심 비즈니스 로직 호출
commentSyncService.syncHotCommentsToRedis()
XxlJobHelper.log("【인기 댓글 동기화 작업】 실행 성공!")
log.info("【인기 댓글 동기화 작업】 실행 성공!")
// 실행 성공 보고
XxlJobHelper.handleSuccess()
} catch (e: Exception) {
XxlJobHelper.log("【인기 댓글 동기화 작업】 실행 실패! 오류 메시지: {}", e.message)
log.error("【인기 댓글 동기화 작업】 실행 실패!", e)
// 실행 실패 보고
XxlJobHelper.handleFail(e.message)
}
}
}
package com.sleekydz86.domain.comment.service
import com.fasterxml.jackson.databind.ObjectMapper
import com.sleekydz86.domain.comment.entity.Comment
import com.sleekydz86.domain.comment.repository.CommentRepository
import jakarta.persistence.EntityNotFoundException
import org.slf4j.LoggerFactory
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.data.redis.core.RedisTemplate
import org.springframework.stereotype.Service
import org.springframework.transaction.annotation.Transactional
import java.util.concurrent.TimeUnit
@Service
class CommentService {
companion object {
private val log = LoggerFactory.getLogger(CommentService::class.java)
private const val KEY_HOT_COMMENTS = "hot_comments"
private const val KEY_COMMENT_CACHE_PREFIX = "comment:"
}
@Autowired
private lateinit var commentRepository: CommentRepository
@Autowired
private lateinit var redisTemplate: RedisTemplate<String, Any>
@Autowired
private lateinit var objectMapper: ObjectMapper
@Transactional
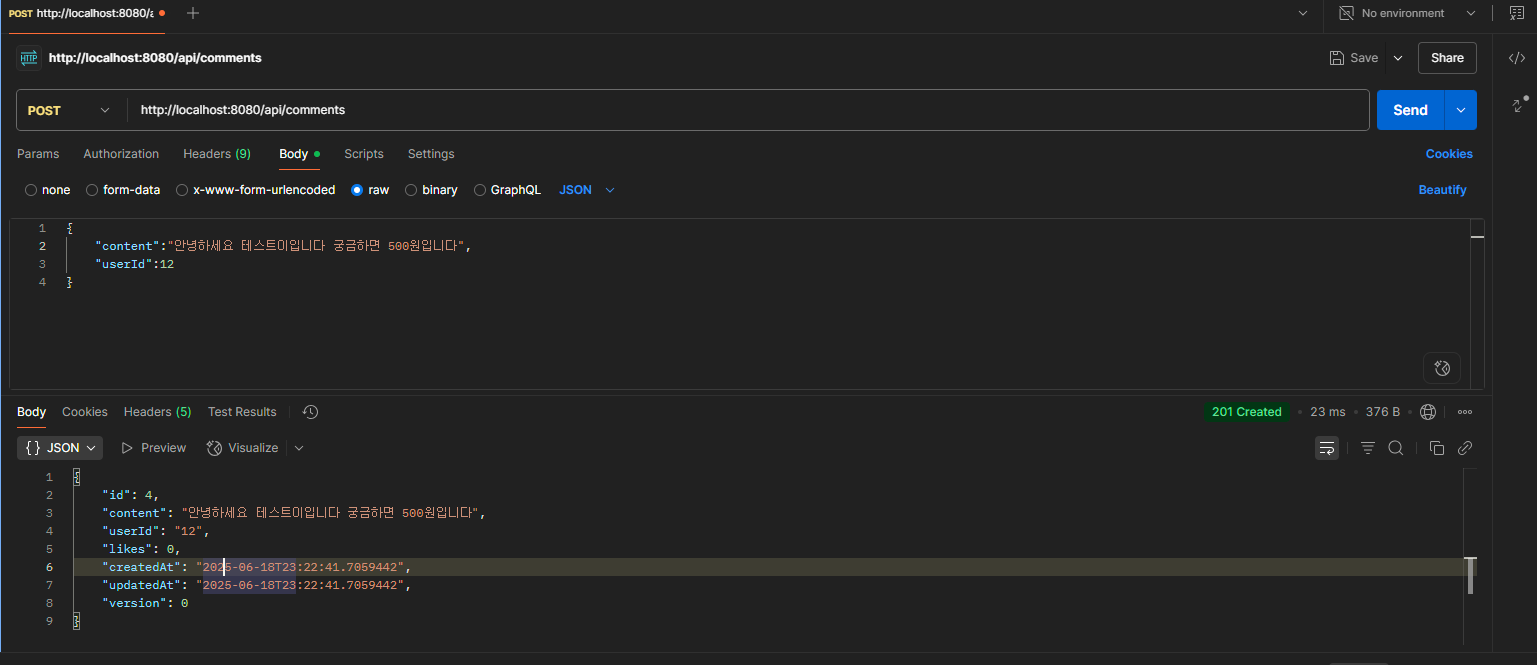
fun createComment(content: String, userId: String): Comment {
val comment = Comment().apply {
this.content = content
this.userId = userId
}
val savedComment = commentRepository.save(comment)
// Redis에도 저장 (새 댓글이므로 좋아요 수는 0)
try {
redisTemplate.opsForZSet().add(KEY_HOT_COMMENTS, savedComment.id.toString(), 0.0)
val cacheKey = "$KEY_COMMENT_CACHE_PREFIX${savedComment.id}"
val commentJson = objectMapper.writeValueAsString(savedComment)
redisTemplate.opsForValue().set(cacheKey, commentJson, 1, TimeUnit.HOURS)
log.info("새 댓글 Redis 저장 완료: ID = {}", savedComment.id)
} catch (e: Exception) {
log.error("새 댓글 Redis 저장 실패: {}", e.message, e)
}
return savedComment
}
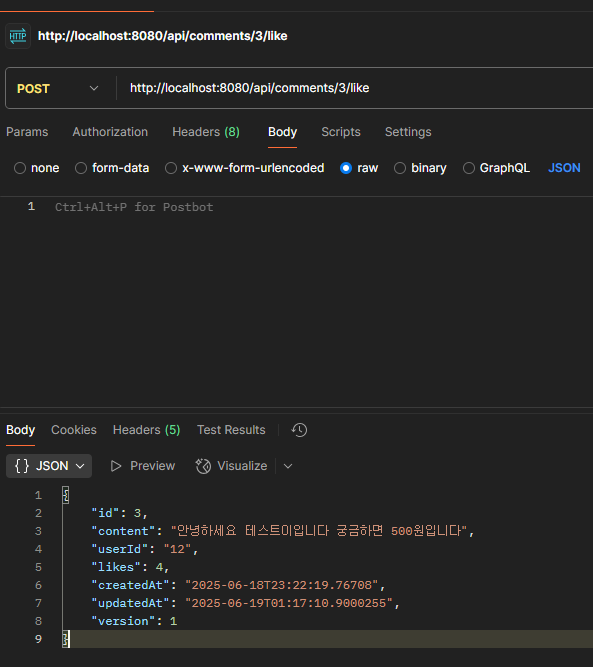
@Transactional
fun likeComment(commentId: Long): Comment {
val comment = commentRepository.findById(commentId)
.orElseThrow { EntityNotFoundException("댓글이 존재하지 않음: $commentId") }
comment.likes = comment.likes + 1
val updatedComment = commentRepository.save(comment)
try {
// Sorted Set 업데이트 (좋아요 수로 점수 설정)
redisTemplate.opsForZSet().add(KEY_HOT_COMMENTS, updatedComment.id.toString(), updatedComment.likes.toDouble())
// 캐시 업데이트 (TTL 1시간)
val cacheKey = "$KEY_COMMENT_CACHE_PREFIX${updatedComment.id}"
val commentJson = objectMapper.writeValueAsString(updatedComment)
redisTemplate.opsForValue().set(cacheKey, commentJson, 1, TimeUnit.HOURS)
log.info("Redis 업데이트 성공 - 댓글 ID: {}, 좋아요 수: {}", updatedComment.id, updatedComment.likes)
} catch (e: Exception) {
log.error("Redis 업데이트 실패: {}", e.message, e)
}
return updatedComment
}
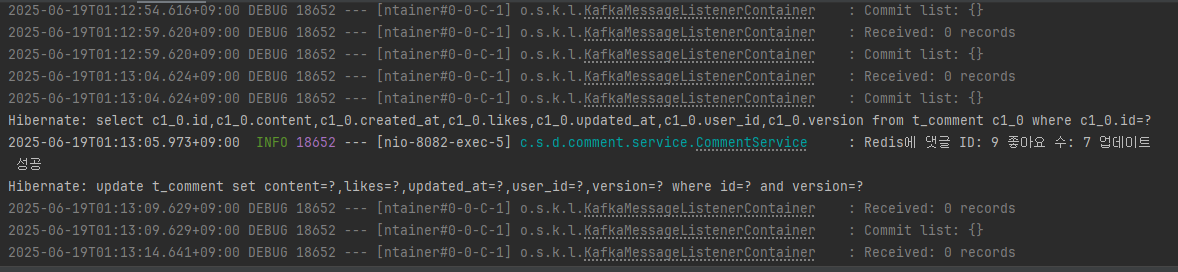
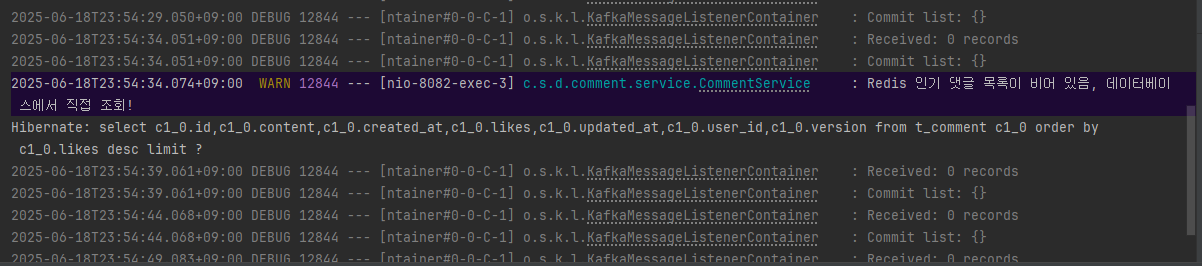
fun getTop10HotComments(): List<Comment> {
try {
// Redis Sorted Set에서 상위 10개 댓글 ID 조회 (점수 높은 순)
val commentIds = redisTemplate.opsForZSet().reverseRange(KEY_HOT_COMMENTS, 0, 9)
if (commentIds.isNullOrEmpty()) {
log.warn("Redis 인기 댓글 목록이 비어 있음, 데이터베이스에서 조회")
return fetchFromDB()
}
// Redis 캐시에서 댓글 상세 정보 조회
val comments = mutableListOf<Comment>()
val missingIds = mutableListOf<String>()
commentIds.forEach { id ->
val cacheKey = "$KEY_COMMENT_CACHE_PREFIX$id"
try {
val cachedJson = redisTemplate.opsForValue().get(cacheKey) as? String
if (cachedJson != null) {
val comment = objectMapper.readValue(cachedJson, Comment::class.java)
comments.add(comment)
} else {
missingIds.add(id.toString())
}
} catch (e: Exception) {
log.error("댓글 ID {} 역직렬화 실패", id, e)
missingIds.add(id.toString())
}
}
// 캐시 미스된 댓글들을 DB에서 조회하여 캐시 보충
if (missingIds.isNotEmpty()) {
val missingComments = commentRepository.findAllById(missingIds.map { it.toLong() })
missingComments.forEach { comment ->
try {
val cacheKey = "$KEY_COMMENT_CACHE_PREFIX${comment.id}"
val commentJson = objectMapper.writeValueAsString(comment)
redisTemplate.opsForValue().set(cacheKey, commentJson, 1, TimeUnit.HOURS)
comments.add(comment)
} catch (e: Exception) {
log.error("캐시 보충 실패: 댓글 ID {}", comment.id, e)
}
}
}
// 좋아요 수 기준으로 정렬하여 반환
return comments.sortedByDescending { it.likes }
} catch (e: Exception) {
log.error("Redis에서 인기 댓글 조회 실패, DB 폴백", e)
return fetchFromDB()
}
}
// 데이터베이스 폴백 메서드
private fun fetchFromDB(): List<Comment> {
return try {
commentRepository.findTop10ByOrderByLikesDesc()
} catch (e: Exception) {
log.error("데이터베이스에서도 댓글 조회 실패", e)
emptyList()
}
}
}
또한 리포지토리에 몇 가지 필수 메서드를 만들어야 합니다.
package com.sleekydz86.domain.comment.repository
import com.sleekydz86.domain.comment.entity.Comment
import org.springframework.data.domain.Pageable
import org.springframework.data.jpa.repository.JpaRepository
import org.springframework.data.jpa.repository.Query
import org.springframework.stereotype.Repository
import java.time.LocalDateTime
@Repository
interface CommentRepository : JpaRepository<Comment, Long> {
// 좋아요 수 기준 상위 10개 댓글 조회
fun findTop10ByOrderByLikesDesc(): List<Comment>
/**
* 지정된 시간 이후 좋아요 수 기준 상위 N개 댓글 조회
* @param since 기준 시간 (예: 7일 전)
* @param pageable 페이징 파라미터, 반환 레코드 수 N 제한
* @return 댓글 목록
*/
@Query("SELECT c FROM Comment c WHERE c.updatedAt >= :since ORDER BY c.likes DESC")
fun findTopLikedCommentsSince(since: LocalDateTime, pageable: Pageable): List<Comment>
}CommentSyncConsumer는 TiCDC와 Redis를 연결하는 핵심 허브입니다.
Kafka 토픽을 모니터링하고, TiCDC가 보내는 바이너리 메시지를 파싱해서 최신 데이터 변경 사항을 실시간으로 Redis의 인기 순위와 상세 캐시에 동기화 합니다.
package com.sleekydz86.global.consumer
import com.fasterxml.jackson.databind.JsonNode
import com.fasterxml.jackson.databind.ObjectMapper
import com.sleekydz86.domain.comment.entity.Comment
import org.slf4j.LoggerFactory
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.data.redis.core.RedisTemplate
import org.springframework.kafka.annotation.KafkaListener
import org.springframework.stereotype.Service
import java.nio.charset.StandardCharsets
import java.time.LocalDateTime
import java.time.format.DateTimeFormatter
import java.util.concurrent.TimeUnit
@Service
class CommentSyncConsumer {
companion object {
private val log = LoggerFactory.getLogger(CommentSyncConsumer::class.java)
private const val KEY_HOT_COMMENTS = "hot_comments"
private const val KEY_COMMENT_CACHE_PREFIX = "comment:"
private val TIDB_DATETIME_FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")
}
@Autowired
private lateinit var objectMapper: ObjectMapper
@Autowired
private lateinit var redisTemplate: RedisTemplate<String, Any>
@KafkaListener(topics = ["comment-topic"], groupId = "comment-sync-group-final")
fun listen(messageBytes: ByteArray?) {
if (messageBytes == null || messageBytes.isEmpty()) {
return
}
val originalMessage = String(messageBytes, StandardCharsets.UTF_8)
var jsonPayload = ""
try {
val jsonStart = originalMessage.indexOf('{')
if (jsonStart == -1) {
log.warn("유효하지 않은 JSON 메시지: {}", originalMessage)
return
}
jsonPayload = originalMessage.substring(jsonStart)
log.info("처리할 JSON 메시지: {}", jsonPayload)
val rootNode: JsonNode = objectMapper.readTree(jsonPayload)
val (eventType, dataNode) = when {
rootNode.has("u") -> "UPSERT" to rootNode.get("u")
rootNode.has("d") -> "DELETE" to rootNode.get("d")
else -> {
log.warn("알 수 없는 이벤트 타입: {}", jsonPayload)
return
}
}
val comment = parseComment(dataNode)
log.info("파싱된 Comment: ID={}, Content={}, Likes={}", comment.id, comment.content, comment.likes)
// Redis 업데이트
when (eventType) {
"UPSERT" -> handleUpsertEvent(comment)
"DELETE" -> handleDeleteEvent(comment)
}
} catch (e: Exception) {
log.error("Kafka 메시지 처리 실패 - 원본: [{}], JSON: [{}]", originalMessage, jsonPayload, e)
}
}
private fun parseComment(dataNode: JsonNode): Comment {
return Comment().apply {
id = dataNode.get("id").get("v").asLong()
content = dataNode.get("content").get("v").asText()
userId = dataNode.get("user_id").get("v").asText()
likes = dataNode.get("likes").get("v").asInt()
version = dataNode.get("version").get("v").asInt()
val createdAtStr = dataNode.get("created_at").get("v").asText()
val updatedAtStr = dataNode.get("updated_at").get("v").asText()
createdAt = LocalDateTime.parse(createdAtStr, TIDB_DATETIME_FORMATTER)
updatedAt = LocalDateTime.parse(updatedAtStr, TIDB_DATETIME_FORMATTER)
}
}
private fun handleUpsertEvent(comment: Comment) {
try {
comment.id?.let { commentId ->
// Sorted Set 업데이트 (좋아요 수를 점수로 사용)
redisTemplate.opsForZSet().add(
KEY_HOT_COMMENTS,
commentId.toString(),
comment.likes.toDouble()
)
// 개별 댓글 캐시 업데이트
val cacheKey = "$KEY_COMMENT_CACHE_PREFIX$commentId"
val commentJson = objectMapper.writeValueAsString(comment)
redisTemplate.opsForValue().set(cacheKey, commentJson, 1, TimeUnit.HOURS)
log.info("Redis UPSERT 완료 - ID: {}, Likes: {}", commentId, comment.likes)
}
} catch (e: Exception) {
log.error("Redis UPSERT 실패 - Comment ID: {}", comment.id, e)
}
}
private fun handleDeleteEvent(comment: Comment) {
try {
comment.id?.let { commentId ->
// Sorted Set에서 제거
redisTemplate.opsForZSet().remove(KEY_HOT_COMMENTS, commentId.toString())
// 개별 캐시 삭제
val cacheKey = "$KEY_COMMENT_CACHE_PREFIX$commentId"
redisTemplate.delete(cacheKey)
log.info("Redis DELETE 완료 - ID: {}", commentId)
}
} catch (e: Exception) {
log.error("Redis DELETE 실패 - Comment ID: {}", comment.id, e)
}
}
}데이터의 최종 일관성을 보장하기 위해, 우리는 XXL-Job을 도입해서 매일 한 번씩 데이터 교정 작업을 실행합니다.
이렇게 해서 Redis에 저장된 데이터가 TiDB의 "황금 데이터"와 최종적으로 일관되도록 유지합니다.
package com.sleekydz86.global.jobhandler
import com.sleekydz86.domain.comment.service.CommentSyncService
import com.xxl.job.core.context.XxlJobHelper
import com.xxl.job.core.handler.annotation.XxlJob
import org.slf4j.LoggerFactory
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.stereotype.Component
@Component
class CommentSyncXxlJobHandler {
companion object {
private val log = LoggerFactory.getLogger(CommentSyncXxlJobHandler::class.java) // 로거
}
@Autowired
private lateinit var commentSyncService: CommentSyncService // 댓글 동기화 서비스
@XxlJob("syncHotCommentsJobHandler")
fun executeSyncHotComments() {
XxlJobHelper.log("【인기 댓글 동기화 작업】 시작...")
log.info("【인기 댓글 동기화 작업】 XXL-Job 트리거, 실행 시작...")
try {
// 핵심 비즈니스 로직 호출
commentSyncService.syncHotCommentsToRedis()
XxlJobHelper.log("【인기 댓글 동기화 작업】 실행 성공!")
log.info("【인기 댓글 동기화 작업】 실행 성공!")
// 실행 성공 보고
XxlJobHelper.handleSuccess()
} catch (e: Exception) {
XxlJobHelper.log("【인기 댓글 동기화 작업】 실행 실패! 오류 메시지: {}", e.message)
log.error("【인기 댓글 동기화 작업】 실행 실패!", e)
// 실행 실패 보고
XxlJobHelper.handleFail(e.message)
}
}
}우리는 로직과 스케줄링 분리의 모범 사례를 따라했습니다.
Handler는 XXL-Job에 의해 트리거되는 역할을 맡고, Service는 구체적인 동기화 로직을 실행합니다.
package com.sleekydz86.domain.comment.service
import com.fasterxml.jackson.databind.ObjectMapper
import com.sleekydz86.domain.comment.repository.CommentRepository
import org.slf4j.LoggerFactory
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.data.domain.PageRequest
import org.springframework.data.redis.core.RedisTemplate
import org.springframework.stereotype.Service
import org.springframework.transaction.annotation.Transactional
import java.time.LocalDateTime
import java.util.concurrent.TimeUnit
@Service
class CommentSyncService {
companion object {
private val log = LoggerFactory.getLogger(CommentSyncService::class.java)
private const val KEY_HOT_COMMENTS = "hot_comments"
private const val KEY_HOT_COMMENTS_TEMP = "hot_comments_temp"
private const val KEY_COMMENT_CACHE_PREFIX = "comment:"
}
@Autowired
private lateinit var commentRepository: CommentRepository
@Autowired
private lateinit var redisTemplate: RedisTemplate<String, Any>
@Autowired
private lateinit var objectMapper: ObjectMapper
@Transactional(readOnly = true)
fun syncHotCommentsToRedis() {
log.info("인기 댓글 Redis 동기화 시작...")
try {
// 1. 동기화 범위 정의 (최근 7일)
val sevenDaysAgo = LocalDateTime.now().minusDays(7)
val pageRequest = PageRequest.of(0, 1000)
// 2. TiDB에서 인기 댓글 조회
val hotComments = commentRepository.findTopLikedCommentsSince(sevenDaysAgo, pageRequest)
if (hotComments.isEmpty()) {
log.info("동기화할 인기 댓글이 없음")
return
}
log.info("데이터베이스에서 {}개의 인기 댓글 조회", hotComments.size)
// 3. 임시 키 초기화
redisTemplate.delete(KEY_HOT_COMMENTS_TEMP)
// 4. 배치로 Redis에 저장
hotComments.forEach { comment ->
try {
// Sorted Set에 추가 (좋아요 수를 점수로 사용)
redisTemplate.opsForZSet().add(
KEY_HOT_COMMENTS_TEMP,
comment.id.toString(),
comment.likes.toDouble()
)
// 개별 댓글 캐시 저장
val cacheKey = "$KEY_COMMENT_CACHE_PREFIX${comment.id}"
val commentJson = objectMapper.writeValueAsString(comment)
redisTemplate.opsForValue().set(cacheKey, commentJson, 1, TimeUnit.HOURS)
} catch (e: Exception) {
log.error("댓글 ID {} Redis 저장 실패", comment.id, e)
}
}
// 5. 원자적 키 교체 (데이터 일관성 보장)
if (redisTemplate.hasKey(KEY_HOT_COMMENTS_TEMP)) {
redisTemplate.rename(KEY_HOT_COMMENTS_TEMP, KEY_HOT_COMMENTS)
log.info("{}개의 인기 댓글 Redis 동기화 완료", hotComments.size)
} else {
log.warn("임시 키가 존재하지 않음, 동기화 실패")
}
} catch (e: Exception) {
log.error("인기 댓글 Redis 동기화 실패", e)
// 임시 키 정리
try {
redisTemplate.delete(KEY_HOT_COMMENTS_TEMP)
} catch (cleanupEx: Exception) {
log.error("임시 키 정리 실패", cleanupEx)
}
throw e // 상위로 예외 전파
}
}
}여기까지, 우리의 스타일 댓글 시스템 개발이 완료 입니다!
🔍 정리
이 아키텍처의 핵심은 TiDB를 데이터 저장의 기반으로 삼고, Redis를 고속 캐시로 활용하여 서로 보완적으로 동작하게 만드는 데 있습니다.
단순한 캐시 읽기/쓰기에 그치지 않고, 우리는 “실시간 동기화 + 주기적 검증”이라는 이중 구조의 데이터 동기화 메커니즘을 설계하고 구현했습니다.
실시간 동기화
TiDB → TiCDC → Kafka → 서비스로 이어지는 데이터 파이프라인을 통해
데이터 변경 사항을 밀리초 단위로 감지하고 전파합니다.
이를 통해 사용자 인터랙션에 대한 즉각적인 반영이 가능해집니다.
주기적 검증
분산 스케줄링 도구인 XXL-Job을 활용해, 주기적으로 데이터 정합성을 검사합니다.
이 방식은 메시지 유실이나 서비스 중단 등 예외 상황에서도 데이터의 최종 일관성을 확보하는 데 중요한 역할을 합니다.
🛠 기술 구현 측면
우리는 Spring Boot 기술 스택을 기반으로 시스템을 구현했으며,
여기에는 낙관적 락, 캐시 강제 강등(Fallback), 원자적 업데이트(Atomic Update) 등의
다양한 설계 패턴을 적용해, 전반적인 비즈니스 로직의 안정성과 견고함을 확보했습니다.
