
들어가기 전에
- 이 글의 제목은 멘토링을 진행하면서 들은 질문인데 나는 그냥 "스레드풀이 고갈될 것 같습니다." 라고 대답했다.
- 하지만 멘토님이 원하시는 답변은 그것보다 깊은 대답을 원하셨다. 그러고 나서 신입에게는 카프카, 쿠버네티스 같은 지식보다는 스프링을 조금 더 깊이 알 것을 권유하셨다.
(물론 대기업 기준일지도) - 그래서 그때 질문받은 것을 정리하기 위해 이 글을 작성한다.
Spring Boot's Embedded Tomcat
- 기존 Spring 에는 WAS (Tomcat) 을 별도로 설치하고 개발 완료된 자바 코드를 WAR 파일로 빌드하여 WAS에 옮겨 서버를 실행했다.
- 하지만 Spring Boot로 오면서 Embedded Tomcat을 지원하기 시작했고, 별도의 WAS 설치는 필요 없어졌다.
- 그렇다면 스프링 부트에서 사용자의 요청을 어떻게 처리하는지 알아보자.
Spring Boot의 사용자 요청 처리
- 전체 흐름은 아래와 같다.
1. 클라이언트 요청 2. DispatcherServlet 가 요청을 수신 3. HandlerMapping으로 컨트롤러 매핑 4. HandlerAdapter로 실제 실행 5. 컨트롤러(@Controller, @RestController) 실행 6. 뷰 리졸버 또는 JSON 응답 처리 7. 응답 반환
DispatcherServlet은 Spring 의 Front Controller 패턴의 구현체이자 HTTP 요청의 진입 지점이다.- 나의 지식은 여기까지 였고, 이는 Spring MVC 에서 발생하는 일이다. 하지만 지금부터 정리할 내용은 그 이전인 Servlet Container 에서 발생하는 일이다.
Connector
- Connector은 소켓 연결을 해주고 데이터 패킷을 획득하여 이를
HttpServletRequest객체로 변환하고,Servlet객체에 전달하는 역할을 한다. - 변환 과정이 BIO, NIO가 차이가 난다.
Tomcat BIO
- Tomcat 8.0 이전에는 BIO(Blocking I/O) 방식을 기본적으로 사용했다.
- 이때 사용된 BIO Connector 는 Socket Connection을 처리할 때 Java의 기본적인 I/O 기술을 사용했기에 사용자의 요청 1개당 thread 1개를 할당해주었다. 이는 굉장히 비효율적이다.
- 따라서 thread들이 충분히 사용되지 않고 idle(아무것도 하지않는) 상태로 낭비되는 시간이 많이 발생했다.
- 그래서 이 방법은 Tomcat 9.0 부터는 더 이상 지원하지 않는다.
스레드 생성량이 많아지면 그 만큼 메모리를 차지하고, Context Switch 가 많이 발생한다.
Tomcat NIO
- Tomcat 6.0부터 등장했고, Tomcat 8.0 부터는 NIO(NonBlocking I/O) 방식을 기본적으로 사용한다. 소수의 thread로 다수의 사용자 요청을 처리할 수 있다. 이게 어떻게 가능할까?
Tomcat NIO 작동 방식
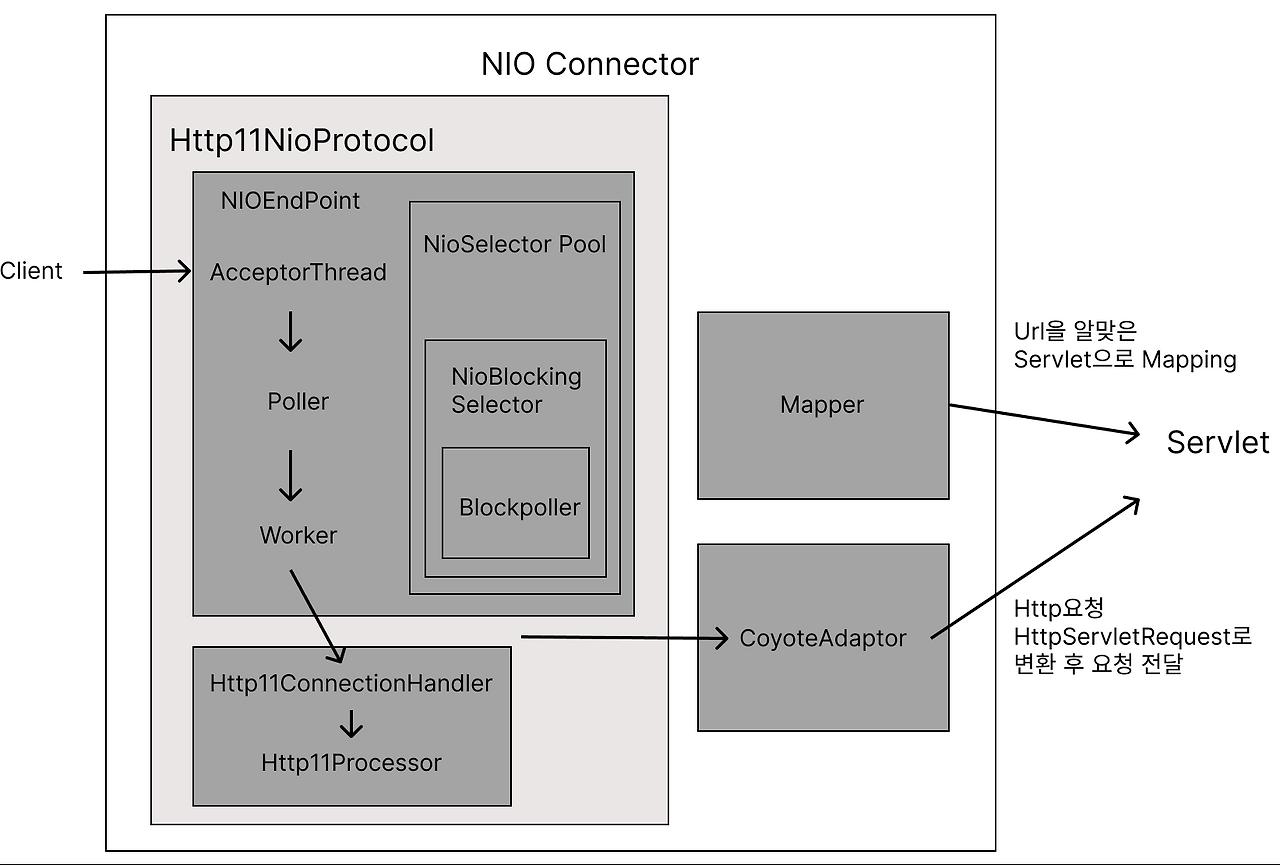
- 여기서 NIOEndPoint 부분을 자세히 보자. (AcceptorThread -> Poller -> Worker)
NIOEndPoint
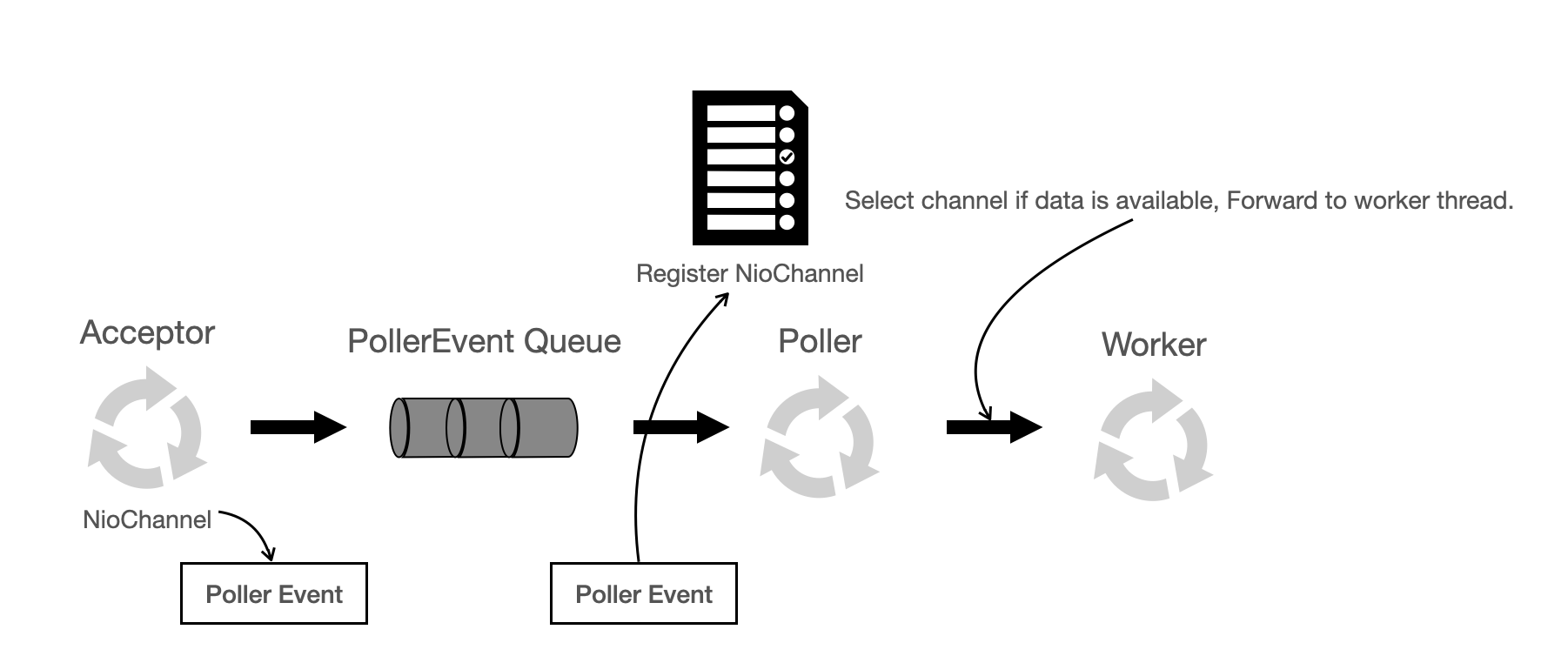
- Acceptor은 Socket Connection을 받아들인다. (
ServerSocket.accept()) - Socket 에서 Socket Channel 객체를 얻고 NioChannel 객체로 변환하고, PollerEvent 객체로 한번 더 캡슐화하여 PollerEvent Queue에 넣게 된다.
PollerEvent Queue 를 파헤치는 글은 여기
- Poller 는 NIO의 Selector을 가지고 있다. Selector 에는 다수의 채널이 등록되어 있고, Select 을 수행하여 데이터를 읽을 수 있는 소켓을 얻는다.
- 그리고 Worker Thread Pool 에서 이용할 수 있는 Worker Thread 을 얻어서 해당 소켓을 Worker Thread에 넘기게 된다.
- Java NIO Selector 을 사용해서 Data 를 처리할 수 있는 경우에만 Thread 를 사용하기 때문에 Idle 상태로 낭비되는 Thread가 적다.
- Poller에선
maxConnection까지 연결을 수락하고, Selector 를 통해 채널을 관리하므로 작업 큐 사이즈(acceptCount)와 관계없이 추가로 커넥션을 refuse하지 않고 받아놓을 수 있다.
Http11ConnectionHandler
- 여기서부터는 BIO 방식과 NIO 방식이 거의 동일하다.
- Http11ConnectionHandler 는 Connection 을 받아서 적절한 Processor 을 할당해주는 역할을 한다.
Http11Processor
- Http11Processor 는 HTTP 요청을 파싱하고
org.apache.coyote.Request객체와org.apache.coyote.Response객체를 만든다. (Tomcat의 저수준 HTTP 파싱 결과를 담는 클래스)
CoyoteAdapter
CoyoteAdapter.service()을 호출하여 Http11Processor 에서 받은 객체를 Servlet API 객체로 감싸는 작업을 한다. 여기서 우리가 흔히 사용하는HttpServletRequest,HttpSerlvetResponse객체가 만들어진다.- 다음은 코드 중 일부이다.
@Override
public void service(org.apache.coyote.Request req, org.apache.coyote.Response res) throws Exception {
Request request = (Request) req.getNote(ADAPTER_NOTES);
Response response = (Response) res.getNote(ADAPTER_NOTES);
if (request == null) {
// Create objects
request = connector.createRequest();
request.setCoyoteRequest(req);
response = connector.createResponse();
response.setCoyoteResponse(res);
// Link objects
request.setResponse(response);
response.setRequest(request);import org.apache.catalina.connector
public class Request implements HttpServletRequest {
/**
* Coyote request.
*/
protected org.apache.coyote.Request coyoteRequest;
- 여기서 만들어지는
org.apache.catalina.connector.Request객체가 우리가 흔히 사용하는jakarta.servlet.http.HttpServletRequest을 구현하고 있다는 것을 볼 수 있다. 우리는 이Request객체를 사용하고 있는 것이다. - 이렇게 만들어진 객체들은 이제 Spring 의 DispatcherServlet 으로 전송된다.

공유하며 성장하는 Spring 백엔드 취준생입니다