node-express app과 database 함께 사용하기
SQL과 NoSQL의 차이점
데이버 베이스 사용의 목표: 항상 데이터를 저장하고 쉽게 가용 혹은 접근 할 수 있게 하여 코드에서의 접근만이 아니라 데이터 접근도 용이하게 해야 한다. 또한 효율적이고 빨라야 한다.
내부 데이터의 크기가 커짐에 따라서 파일에 접근할때 보다 더 빠르다. 하나의 정보를 찾기 위해서 전체 파일을 다 읽을 필요가 없기 때문이다.
그렇다면, SQL기반의 DB로는 대표적으로 MySQL이 있다. NoSQL로는 MongoDBrk 대표적이다.
대체 SQL은 무엇인가.? NoSQL은 또 뭔가..?
SQL DB는 table을 형태로 데이터를 구조화하고 각 테이블의. column, row에 각 개별 데이터를 저장한다. 또한 서로 다른 table이 서로 연결될 수 있다.
Schema를 지니고 있어서 각각의 표마다 내부 데이터의 형태와 저장되는 데이터의 종류(숫자, 문자열, 텍스트, 불리언 등)를 정의할 수 있다. 테이블의 모든 데이터는 해당 테이블에 대한 스키마와 일치해야 한다.
테이블의 형태에 대한 정의가 SQL DB의 중요한 특성이다.
SQL DB의 다른 특성으로는 데이터간의 상관관계가 존재한다. (일대일, 일대다 또는 다대다) 상관관계는 다양한 테이블의들의 관계를 결정하게 된다. 테이블내에 있는 기록들이 각각 일대일 대응이 되거나 다른 관계를 지닐 수 있다.
SQL의 약자는 구조화된 쿼리 언어를 의미한다.
쿼리는 우리가 데이터베이스와 상호작용시에 사용되는 명령어이다.
NoSQL은 위의 SQL의 특징을 따르지 않는다는 것이다. 이들도 다양한 쿼리언어를 사용하긴 하나, 스키마와 상관관계 대신 NoSQL은 다른 특징들이 존재한다.
NoSQL에도 table이 존재하며 table이라는 명칭대신 집합이라고 표현된다.(table과 같은 개념이지만, 집합이라고 부름) 집합에는 문서들이 존재하는데, {...} JS의 객체와 형태가 유사하다. NoSQL에는 Schema가 없어서 같은 집합에 문서가 2개 존재하는데 {name: 'Max', age: 29} {name: 'Jane'} 두번째 문서에 연령이 없어도 NoSQL에서는 같은 집단에 각각 다른 구조를 지닌 다수의 문서들을 저장할 수 있다. 전반적으로 동일하지만 몇몇 영역이 다른 문서들도 문제없이 저장할 수 있다. 또 다른 점에서는 NoSQL에서는 상관관계가 존재하지 않는다. 대신 data를 복제한다. 물론 data가 변경이 된다면 여러 곳에서 이를 업데이트 해야하는 것을 뜻하기도 한다. id또는 상관관계를 통해 집합들을 연결하지 않기 때문에 성능에 까지 영향을 크게 미칠 일이 없어지고 매우 빠르다는 장점이 존재한다.
데이터를 복사하여 각각 작동하는 문서들의 집합을 보유하게 된다.
Horizontal / Vertical Scaling
Horizontal은 수평적 확장을 의미 한다. 수평적 확장이란, 서버를 추가하여 데이터베이스를 연결한 뒤 서버들에 데이터를 분산시키는 방법이다. 동시에 쿼리를 실행하고 통합하는 절차가 필요하다.
Vertical은 수직적 확장이며, 수직 확장은 이미 존재하는 서버에 CPU나 메모리등을 추가해 서버의 성능을 더 강력하게 만든다. 하지만 성능을 무한정으로 끌어올릴 수는 없고 한계가 존재한다. 단일 머신에 무한정으로 CPU와 메모리를 집어 넣을 수는 없을 거다.
그렇다면, SQL과 NoSQL은 어떻게 확장할 수 있을까?
일반적으로 SQL은 스키마(Schema)를 사용하고 데이터간의 상관관계가 존재한다. 스케일링에 있어서 SQL은 수평 스케일링이 매우 어렵거나 만약 수평확장을 진행하였다고 하더라도 힘들수도 있다. 물론 서버를 추가하는건 가능하지만, 전부 하나의 공유된 데이터 클라우드에서 구동하는건 어렵다. 반면 수직 스케일링은 쉽게 할 수 있어, 서버를 더욱 강력하게 만들면 되지만, 서버를 추가 하는 것은 매우 어렵기도 하고 비용적인 부담이 들 수 있다.
매초마다 대량의 쿼리를 읽고 쓰기를 진행하는 경우 아무리 좋은 서버여도 부담이 되는 것은 사실이다.
NoSQL은 스키마(Schema)가 없고 상관관계도 거의 없거나 아예 없다. 데이터는 집합들안에 있는 문서에 있으며 이 경우 수평 스케일링이 더 쉽다. 왜냐면 집합들은 서로 각기 다른 형식이여도 허용하기 때문이며, 집합들 내부의 데이터들을 복제하기 때문이다. 일반적으로 연결 수가 적은 작동방식이기에 가능한 일이다. 방대한 읽기 쓰기 요청에 대해서 탁월한 성능을 얻게 되고 NoSQL은 처리량이 많은 애플리케이션에서 유용하다.
따라서 저장하는 데이터의 종류에 따라 어떤 것이 더 나은지는 항상 달라진다. 자주 변경되지 않는 데이터 예를 들어 사용자 정보등의 데이터라면 SQL이 더 나은 선택일 수 있다. 반면, 주문정보나 사용자의 장바구니와 같이 자주 변경되는 부분에 있어서는 NoSQL을 통해 저장될 수 있다. 사용자가 본인의 회원정보를 변경했다고 하여 장바구니 정보까지 건드릴 필요가 없기 때문이다.
Node.js에 SQL사용하는 방법과 NoSQL(=MongoDB)을 적용하는 방법
- SQL 적용하기
- MySQL-Workbench에서 schema를 만들어 준다.
- node App + SQL DB 연결하기
npm install --save mysql2
module import를 하기 위해 util folder에 새로운 js파일을 생성하여
const mysql = require('mysql2')를 생성해 준다.
SQL DB와 연결하는 방법에는 크게 2가지가 존재한다.
하나는 연결을 설정한 다음 쿼리를 실행하기 위해 사용 되어진다. 단, 쿼리를 실행 완료한 다음에는 항상 연결을 닫아야 한다. 여기서 단점은 새로운 쿼리마다 연결을 생성하기 위해 코드를 재실행해야 한다는 점이다.
이때 데이터를 가져오고 쓰고 삭제하는 작업을 통해 쿼리가 많이 발생하게 된다. 매번 새 연결을 생성하는 것은 코드와 생성된 db에 비효율적으로 적용하게 된다.
다른 방법에는 커넥션 풀(Connection pool)개념이 존재한다.
커넥션 풀(Connection pool)
웹 컨테이너(WAS)가 실행되면서 일정량의 Connection 객체를 미리 만들어서 pool에 저장했다가,
클라이언트 요청이 오면 Connection 객체(=콘센트)를 빌려주고, 해당 객체의 임무가 완료되면 다시 Connection(=콘센트) 객체를 반납 받아서 pool에 저장하는 프로그래밍 기법이다. 일종의 콘센트들을 pool에 저장해서 콘센트를 뺏다 꼇다를 반복할 수 있게 하는 모음집이라고 생각할 수 있다.
const mysql = require("mysql2");
const pool = mysql.createPool({
host: "localhost",
user: "root",
database: "dev-node",
password: "????",
});
module.exports = pool.promise();createPool()로 pool객체를 생성하고 연결할 db의 정보를 기입하여 준다.
이제 이 모듈을 내보내기를 통해서 다른 파일에서도 사용할 수 있게 해준다.
이때 pool객체를 내보낼때 promise()를 호출하였다. promise()를 사용함으로써 콜백 대신 비동기적 일과 비동기적 데이터를 다룰 수 있게 된다. 만약, 서버로 부터 데이터를 받아오기도 전에 마치 데이터를 다 받아온 것 마냥 화면에 데이터를 표시하려고 하면 오류가 발생하거나 빈 화면이 발생한다. 이를 예방하기 위해 promise()를 호출한다.
TABLE 설정하기
create Table을 통해 'products'table의 뼈대를 만든다.
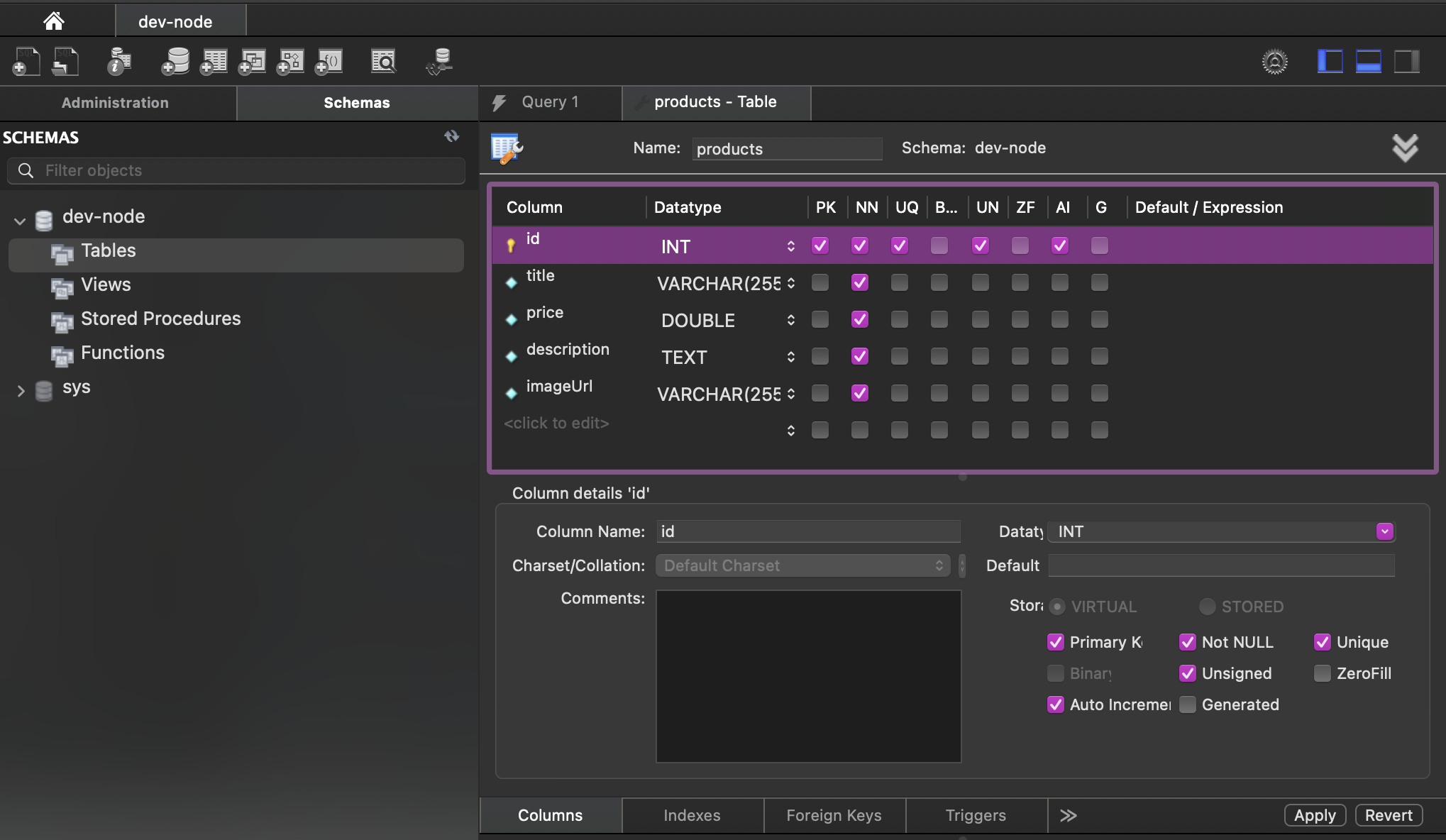
app.js에서 내보낸 모듈을 임포트 한다.
const db = require('./util/database')
db.execute('SELECT * FROM products').then().catch()module을 export시에 promise()를 호출하였기 때문에 then()과 catch()를 사용할 수 있다.
then()과 catch()의 결과를 excute()와 연결할 수 있다.
Promise는 Node 전용이 아닌 기본 JS의 객체로 브라우저에서 Javascript를 사용해 비동기적 코드를 작업 할 수 있다.
then()블록을 배치하면 익명함수를 가져와서 실행하게 된다.
then((result)=>{console.log(result)})
catch()블록에는 만약 오류가 발생하는 겨웅 실행되는 함수를 작성한다.catch((err)=>{console.log(err)})
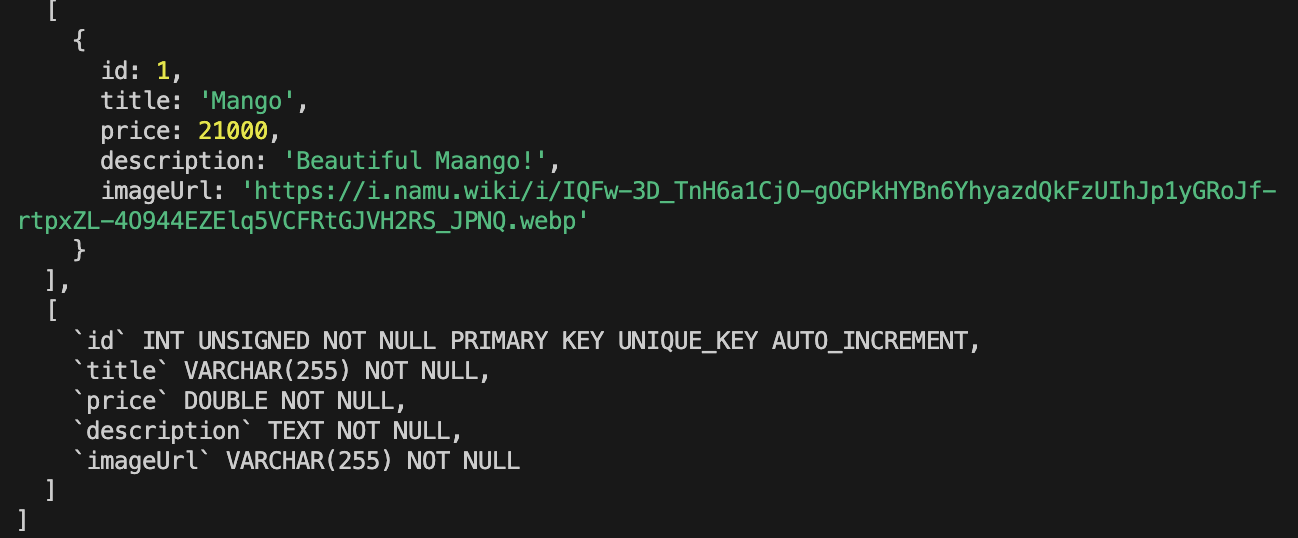
돌려받은 data를 확인해 본 결과 db에 dummy data로 생성한 행이 출력이 돼고 중첩된 배열을 지닌 배열 형태로 들어오는 것을 확인 할 수 있다.
