목표 : 인구수 대비 CCTV 설치 현황 파악
1. 데이터 확보
🍳 CCTV 데이터
https://data.seoul.go.kr/dataList/OA-2734/F/1/datasetView.do
🍳 인구 데이터
https://data.seoul.go.kr/dataList/419/S/2/datasetView.do?stcSrl=419
CSV 파일 읽기
https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html
CCTV = pd.read_csv("파일 경로", encoding="utf-8")
CCTV.head() # 앞의 5개 데이터만 출력
CCTV.tail() # 끝의 5개 데이터만 출력✔ 컬럼명 조회
컬럼명이 리스트 형태로 반환됨
CCTV.columns
CCTV.columns[0]✔ 컬럼명 변경
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.rename.html
inplcace=True : 변경한 작업을 저장
CCTV.rename(columns={CCTV.columns[0]: "구별"}, inplcace=True)excel 파일 읽기
https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html
pop = pd.read_excel(
"파일 경로", header=2, usecols="B, D, G, J, N"
)✔ 컬럼명 변경
pop.rename(
columns={
pop.columns[0]: "구별",
pop.columns[1]: "인구수".
pop.columns[2]: "한국인",
pop.columns[3]: "외국인",
pop.columns[4]: "고령자",
},
inplace=True,
)데이터 확인하기
✔ 데이터 정렬
CCTV.sort_values(by="소계", ascending=True).head(5)
CCTV.sort_values(by="소계", ascending=False).head(5)✔ 최근 증가율
CCTV["최근 증가율"] = (
(CCTV["2014년"] + CCTV["2015년"] + CCTV["2016년"])
/ CCTV["2013년도 이전"]
* 100
)
CCTV.sort_vaules(by="최근 증가율", ascending=False).head(5)✔ unique 조사
pop["구별"].unique() # 배열로 출력
len(pop["구별"].unique()) # 배열의 길이 확인2. 데이터 합치고 정리하기
data_result = pd.merge(CCTV, pop, on="구별")
data_result.head()불필요한 컬럼 제거
del data_result["2013년도 이전"]
del data_result["2014년"]
del data_result["2015년"]
del data_result["2016년도"]인덱스 지정하기
unique한 데이터를 인덱스로 설정해야 한다.
data_result.set_index("구별", inplace=True)인구수와 CCTV 개수의 상관관계?
상관관계(correlation)
한쪽이 증가하면 다른 쪽도 증가/감소하는 경향이 있을 때
상관관계 ➡ 인과관계 ❌
- 0.2 이하 : 상관관계가 없거나 무시해도 좋은 수준
- 0.4 이하 : 약한 상관관계
- 0.6 이상 : 강한 상관관계
data_result.corr()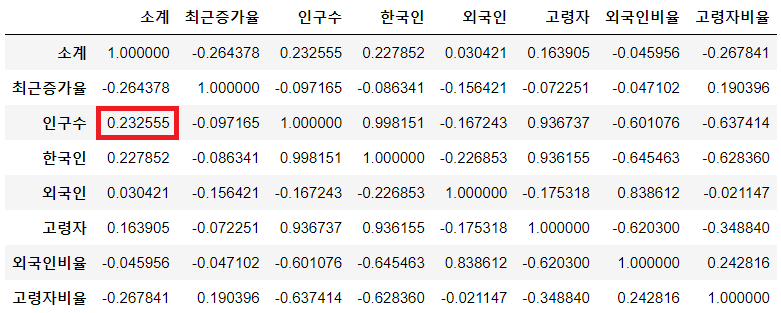
➡ CCTV 전체 수(소계)와 가장 상관관계가 있는 데이터 = 인구수
CCTV비율 컬럼 만들고 정렬하기
data_result["CCTV비율"] = data_result["소계"] / data_result["인구수"] * 100
data_result.sort_values(by="CCTV비율", ascending=False).head(5)
data_result.sort_values(by="CCTV비율", ascending=True).head(5)✨pandas 기초
Pandas는 표로 되어 있는 숫자 데이터를 읽을 때 많이 사용한다.
import pandas as pd
import numpy as np버전에 따라 허용되는 문법이 조금씩 다르기 때문에, 인터넷에서 찾은 소스코드를 돌릴 때 버전을 확인하자!
Series
pandas의 가장 기본적인 데이터형
https://pandas.pydata.org/docs/reference/api/pandas.Series.html
s = pd.Series([1, 3, 5, np.nan, 6, 8])data_range
https://pandas.pydata.org/docs/reference/api/pandas.date_range.html
# 2023년 1월 1일부터 6일간
datas = pd.data_range("20230101", periods=6)DataFrame
pandas에서 가장 많이 사용되는 데이터형
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html
df.DataFrame(✨여기에 커서를 두고 Shitf+Tab 누르면 사용법 확인 가능)df = pd.DataFrame(
np.random.randn(6, 4),
index=datas,
columns=["A", "B", "C", "D"]
)✔ 데이터 프레임 정보 확인
df.head()
df.index
df.columns
df.values
df.info() # 기본 정보
df.describe() # 통계적 기본 정보
df.sort_values(by="B", ascending=False)df["A"]
df[0:3] # 끝을 포함하지 않음
df["20230101":"20230104"] # 끝을 포함✔ df.loc ➡ 이름으로 접근
df.loc[:, ["A", "B"]] # 모든 행의 열 "A", "B" 선택
df.loc["20230101":"20230104", ["A", "B"]]
df.loc["20230101", ["A", "B"]]✔ df.iloc ➡ 번호로 접근
df.iloc[3] # 4번 행
df.iloc[:, 1:3] # 모든 행, 1-2번 컬럼
df.iloc[3:5, 0:2] # 3-4번 행, 0-1번 컬럼
df.iloc[[1, 2, 4], [0, 2]] # 1, 2, 4번 행, 0, 2번 컬럼✔ 조건으로 접근
df[df["A"] > 0]
df[df > 0]
df["E"] = ["one", "one", "two", "three", "four", "three"]
df[df["E"].isin(["two", "four"])] # 특정 요소가 있는 행만 선택✔ 특정 컬럼 제거
del df["E"] # 특정 컬럼 제거✔ 데이터 프레임에 함수 적용 : apply(function)
# 각 컬럼 누적 합
df.apply(np.cumsum)# 함수를 만들어서
def plusminus(num):
return "plus" if num > 0 else "minus"
# 적용 가능
df["A"].apply(plusminus)데이터 병합
pd.merge(left, right, how="inner", on="key") # 기본
pd.merge(left, right, how="left", on="key")
pd.merge(left, right, how="right", on="key")
pd.merge(left, right, how="outer", on="key")🚗 EDA 첫 번째 프로젝트 강의를 듣기 시작했다.
문법이 조금 어색해서 버벅거리면서 들었다.😂
주문에 따라 데이터가 뿅! 정돈되는 걸 보니까 신기하고 재밌다.
🚕 내일은 파이썬 프로그래밍 테스트 날이다.
준비해놓은 답안을 최종 점검하면서 글로 리뷰해보려고 한다.
