seaborn은 matplotlib과 함께 실행된다.
seaborn을 import하면 matplotlib 그래프 스타일이 seaborn로 바뀐다.
sns.set_style()
"white", "dark", "whitegrid", "darkgrid"
x = np.linspace(0, 14, 100)
y1 = np.sin(x)
y2 = 2 * np.sin(x + 0.5)
y3 = 3 * np.sin(x + 1.0)
y4 = 4 * np.sin(x + 1.5)
sns.set_style("darkgrid")
plt.figure(figsize=(10, 6))
plt.plot(x, y1, x, y2, x, y3, x, y4)
plt.show()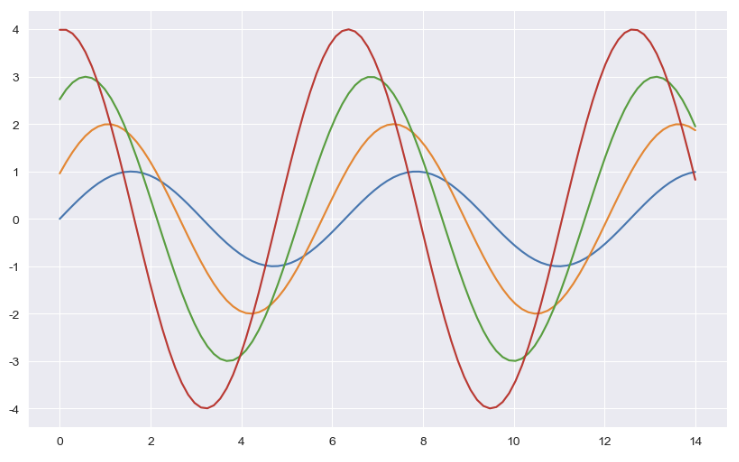
seaborn에 내장된 실습용 데이터를 사용해서 연습해보자.
sns.boxplot()
https://seaborn.pydata.org/generated/seaborn.boxplot.html
hue ➡ 카테고리 데이터 표현
palette ➡ 스타일 넣기
# 데이터셋 가져오기
tips = sns.load_dataset("tips")
# boxplot()
plt.figure(figsize=(8, 6))
sns.boxplot(x="day", y="total_bill", data=tips, hue="smoker", palette="Set2")
plt.show()sns.swarmplot()
https://seaborn.pydata.org/generated/seaborn.swarmplot.html
color ➡ 0~1(검은색~흰색)
plt.figure(figsize=(8, 6))
sns.boxplot(x="day", y="total_bill", data=tips)
sns.swarmplot(x="day", y="total_bill", data=tips, color="0.25")
plt.show()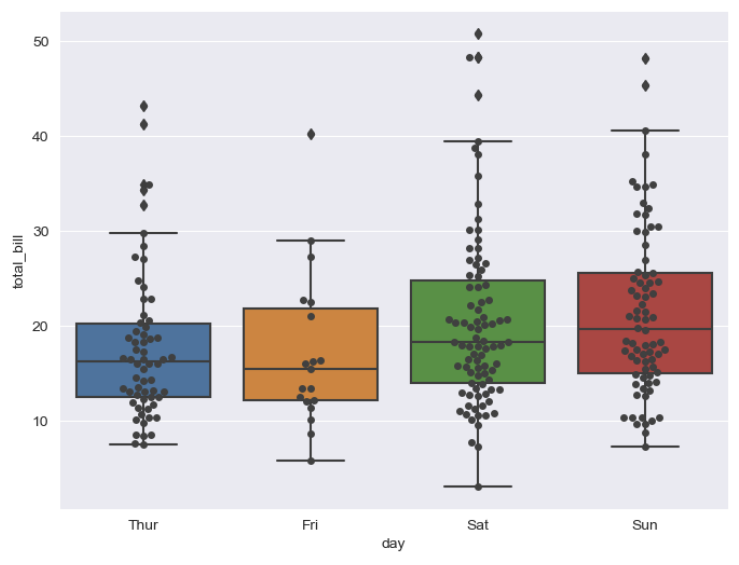
sns.lmplot()
https://seaborn.pydata.org/generated/seaborn.lmplot.html#seaborn.lmplot
hue ➡ 카테고리 데이터 표현
size(height) ➡ 크기 설정
# total_bil과 tip 사이의 관계 파악
sns.set_style("darkgrid")
sns.lmplot(
x="total_bill",
y="tip",
data=tips,
height=7,
hue="smoker"
)
plt.show()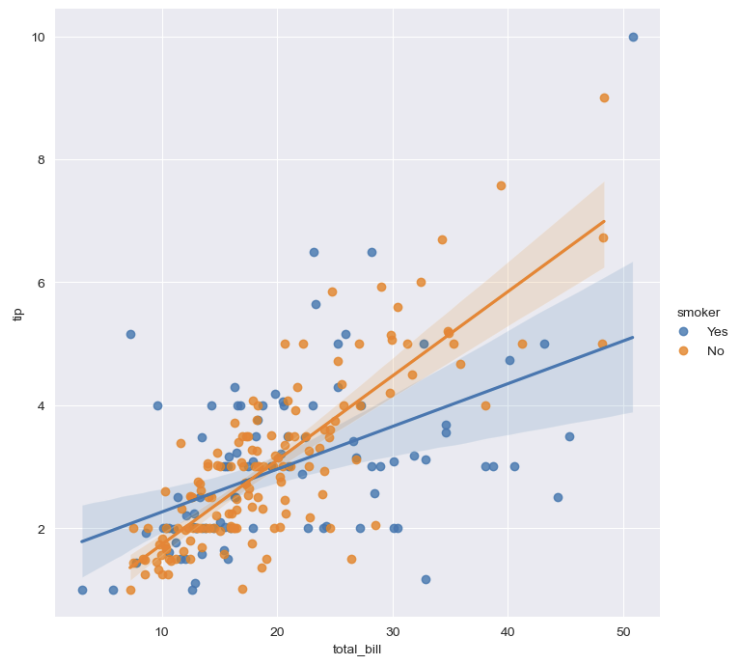
sns.lmplot() 더 알아보기
ci ➡ 신뢰 구간 선택
scatter_kws ➡ 점의 크기 설정
order ➡ If order is greater than 1, use numpy.polyfit to estimate a polynomial regression.
# 데이터셋 가져오기
anscombe = sns.load_dataset("anscombe")
# lmplot()
sns.lmplot(
x="x",
y="y",
data=anscombe.query("dataset == 'I'"),
order=1,
ci=None,
height=5,
scatter_kws={"s":20}
)
plt.show()dataset 'III'는 이상치(outlier)가 포함된 데이터이다.
이상치로 인해 직선이 위로 올라간 것을 조정하기 robust 옵션을 사용한다.
sns.lmplot(
x="x",
y="y",
data=anscombe.query("dataset == 'III'"),
robust=True,
ci=None,
height=5,
scatter_kws={"s":20}
)
plt.show()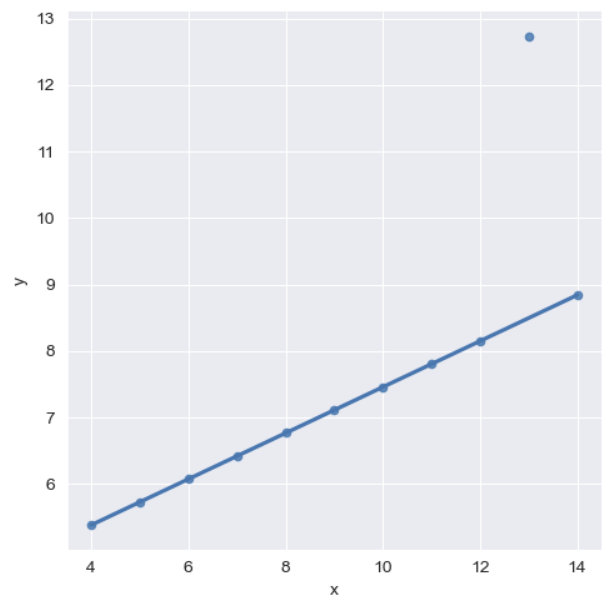
sns.heatmap()
2차원 숫자 배열을 색상으로 표현하는 기능으로, 여러 데이터의 경향을 한 번에 확인할 수 있다.
https://seaborn.pydata.org/generated/seaborn.heatmap.html#seaborn.heatmap
annot ➡ 값을 표현할 것인지
fmt ➡ 값을 어떻게 표현할 것인지(정수, ..)
cmap ➡ 색상 바꾸기
# 데이터셋 가져오기
flights = sns.load_dataset("flights")
# 피벗 테이블 적용
flights = flights.pivot_table(index="month", columns="year", values="passengers")
# heatmap()
plt.figure(figsize=(10, 8))
sns.heatmap(data=flights, annot=True, fmt="d", cmap="YlGnBu")
plt.show()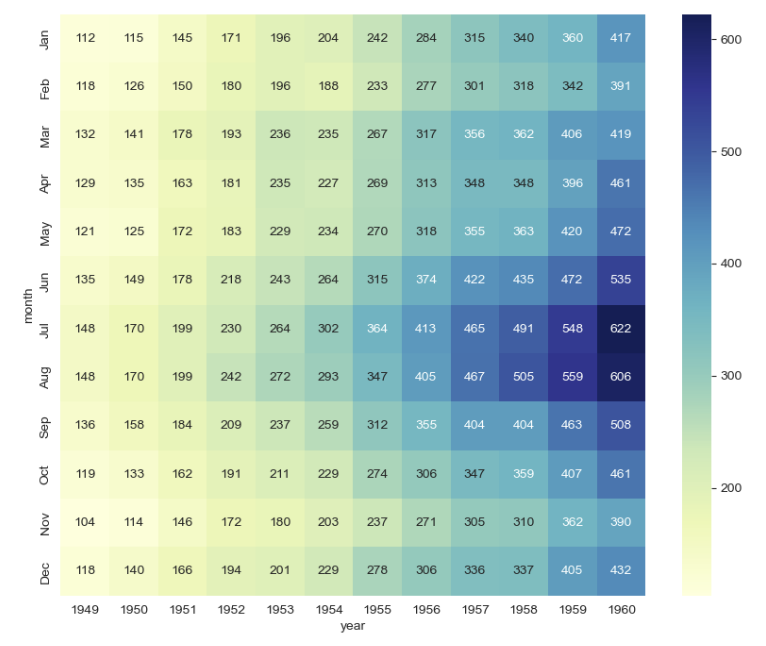
sns.pairplot()
전체 데이터에 대한 모든 경우의 수를 그래프로 보여준다.
각 컬럼별 데이터에 대한 상관관계나 분류적 특성을 파악할 수 있다.
https://seaborn.pydata.org/generated/seaborn.pairplot.html#seaborn-pairplot
# 데이터셋 가져오기
iris = sns.load_dataset("iris")
# pairplot()
sns.set_style("ticks")
sns.pairplot(iris)
plt.show()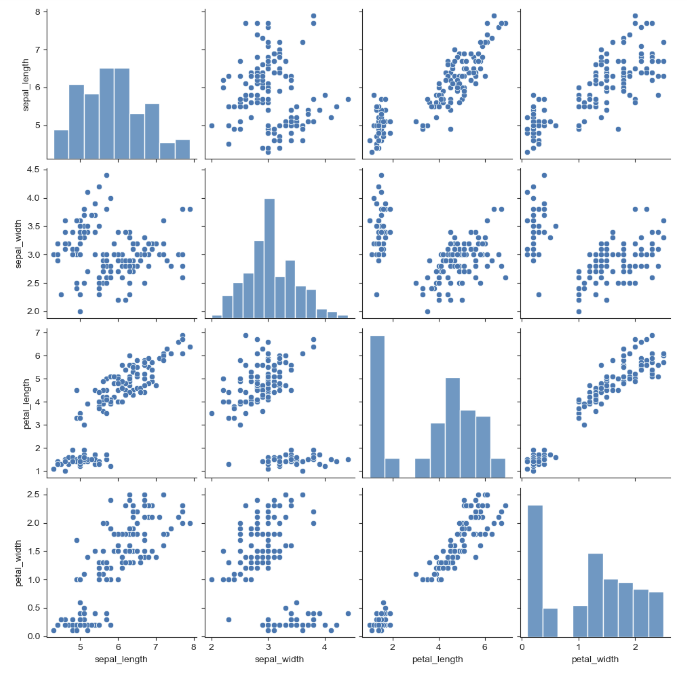
hue 옵션을 적용하면 데이터 분포를 더 쉽게 파악할 수 있다.
sns.pairplot(iris, hue="species")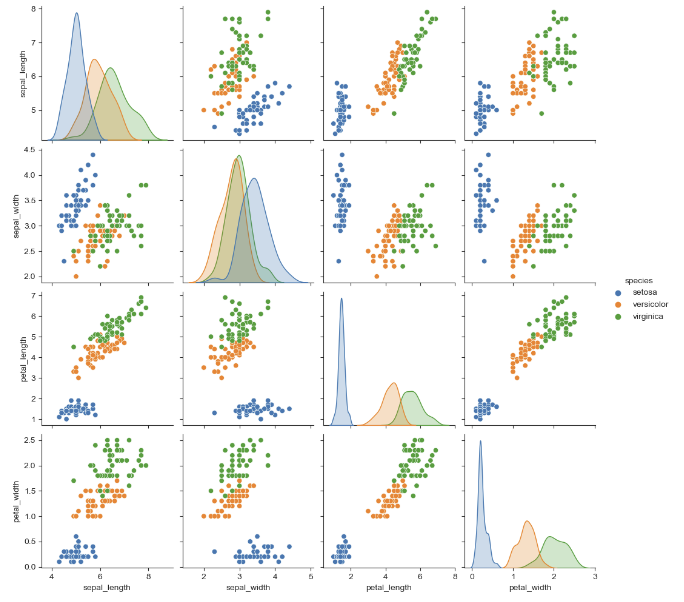
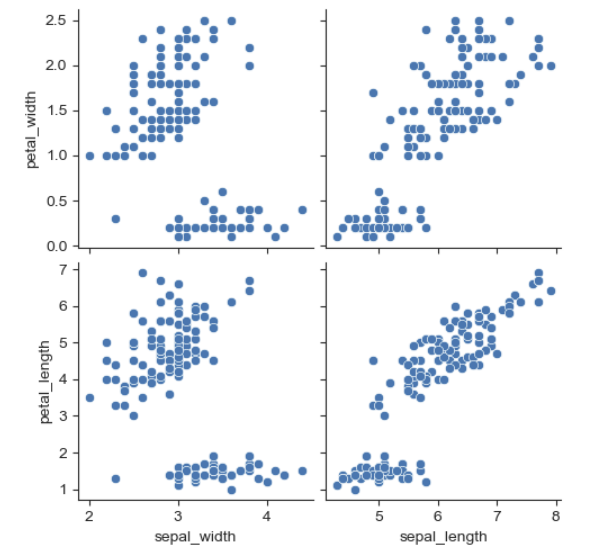
원하는 부분만 선택해서 pairplot을 그릴 수도 있다.
sns.pairplot(
iris,
x_vars=["sepal_width", "sepal_length"],
y_vars=["petal_width", "petal_length"]
)
plt.show()