새로운 프로젝트 시작에 앞서, 프로젝트를 시작할 때마다 고민하는 '어디서부터 시작해야하는가'에 대한 문제를 해결하기 위해, 모델 학습을 진행하는 파이프라인(Pipeline)에 대해 정리해보고자 한다.
전반적인 진행 과정
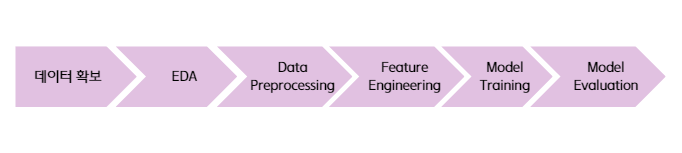
전반적인 과정은 위와 같이 진행된다.
먼저 프로젝트에 사용할 데이터를 확보하고, 확보한 데이터를 EDA하며 데이터를 확인한 뒤, 데이터를 전처리하고 추가적인 파생 지표를 생성하거나, 모델 학습에 사용할 피처를 선택한다. 그리고 모델을 선택하여 학습시킨 뒤, 해당 모델의 성능을 평가한다.
이제 전반적인 진행 과정을 파악했으나 각 단계별로 세부적으로 해야할 일을 짚어보자.
EDA
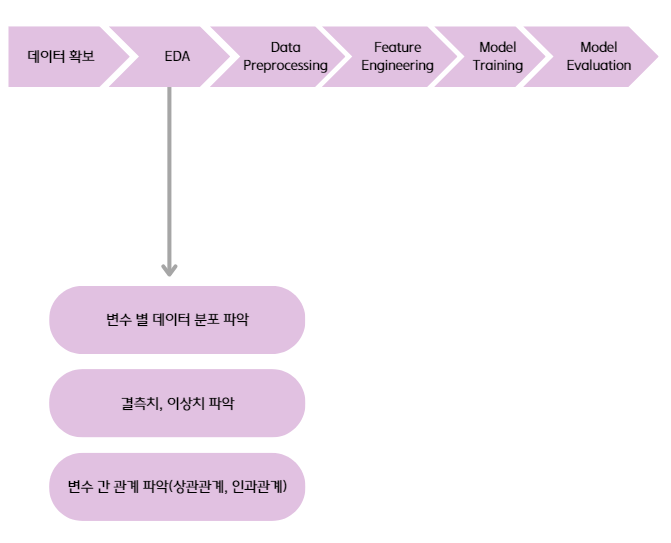
EDA는 Exploratory Data Analysis의 줄임말로, 탐색적으로 데이터를 분석하는 것을 말한다. 보통 이 단계에서 데이터를 시각화해보며 데이터의 특성을 파악한다.
- 변수 별 데이터 분포를 파악할 때는 주로 히스토그램을 사용하여 분포를 시각화한다. hist() 함수를 사용할 때 kde 매개변수를 True로 전달하면 곡선 플롯도 확인할 수 있다.
- 결측치는 pandas의 info() 메소드를 이용하면 데이터 프레임에 대한 정보를 확인할 수 있는데, 그 중 결측치가 아닌 데이터 개수를 통해 확인할 수 있다. 또는 seaborn 라이브러리의 heatmap()을 통해 결측값을 시각화해서 확인할 수도 있다.
- 이상치는 boxplot()을 통해 사분위수를 시각화하여 box 끝의 가로선을 벗어나는 위치에 있는 데이터들을 이상치라고 판단할 수 있다.
- 변수 간 상관관계는 corr() 메소드를 통해 상관계수를 계산할 수 있다. 이를 heatmap()을 통해 시각화하여 표현할 수도 있다. 상관계수를 계산하지 않고 산점도를 통해 직접 변수 간 선형적인 관계가 존재하는지 확인하는 것도 가능하다.
Data Preprocessing
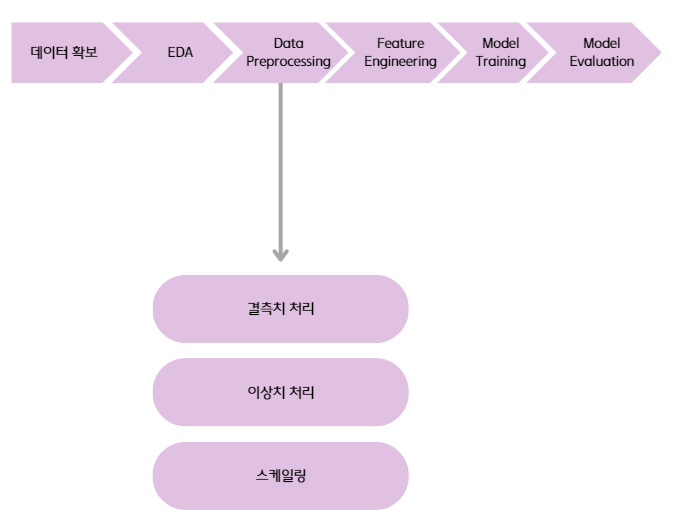
데이터 전처리 과정에서는 모델 학습에 왜곡이 생기지 않도록 결측치, 이상치를 적절하게 처리하고 데이터 분포를 스케일링하여 변수별 범위를 맞춰준다.
- 결측치 처리 방법은 결측값을 삭제하거나, 대체하는 방식이 있다. 삭제는 결측값을 포함하는 행 또는 열을 삭제하는 것이고, 대체는 통계값, 회귀 모델을 사용한 예측값 등으로 대체하는 것이다.
- 이상치 처리는 데이터 특성, 패턴에서 벗어난 값을 적절한 값으로 대체하거나 제거하는 것이다. 이 때 이상치를 판단하는 기준에는 Z-Score, IQR, DBSCAN 등을 사용할 수 있다. 이상치를 제거할 때는 데이터의 패턴을 해치치 않도록 신중한 판단 기준이 필요하고, 대체할 때는 평균, 중앙값 등을 사용하여 대체한다.
- 스케일링은 변수의 크기를 일정하게 맞춰서 모델일 특정 변수에 지나치게 의존하거나 변수 별 관계를 왜곡하지 않도록 한다. 트리 기반 모델을 제외하고는 스케일링을 적용하는 것이 모델 성능에 도움이 된다. 스케일링 시에는 데이터의 분포나 특성에 따라 Standard Scaling, Min-Max Scaling, Robust Scaling, MaxAbs Scaling 등을 사용할 수 있다.
Feature Engineering
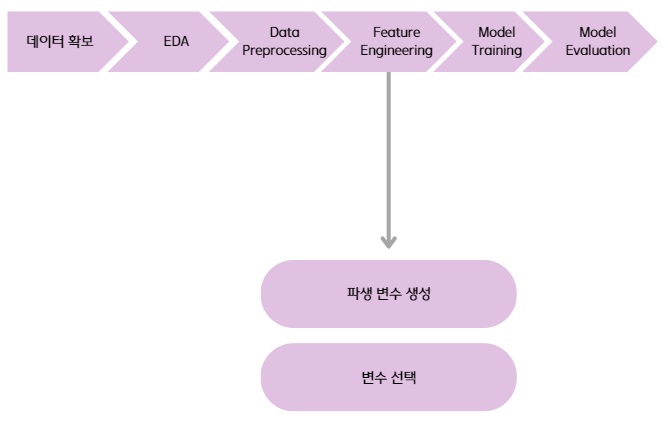
Feature Engineering 과정에서는 모델 학습에 도움이 될 만한, 데이터를 더 잘 표현할 수 있는 파생 변수를 생성하거나 노이즈가 될 수 있는 변수를 제외하여 모델 학습 시 사용할 변수들을 선택한다.
- 파생 변수 생성 시에는 변수 간의 상호작용을 고려하여 결합 가능한 두 개 이상의 기존 변수들로 파생 변수를 생성한다. 변수 간의 곱이나 차, 합 등으로 나타낼 수 있다.
Model Training
이제 준비된 데이터를 이용하여 모델 학습을 진행할 수 있다. 목표에 맞게 적절한 모델을 선택하고, 모델 학습을 진행한 뒤 하이퍼 파라미터 튜닝을 통해 적절한 하이퍼 파라미터 튜닝을 선택한다.
Model Evaluation
모델 학습이 끝났다면 모델의 성능을 평가해야 한다. 모델 평가 시에는 데이터의 특성이나 목적에 따라 적절한 평가 방식을 선택해야 한다. 모델을 평가하는 지표는 다양하지만 회귀 모델에는 MSE, MAE 등의 평가 지표를 주로 사용하고 분류 모델에는 Accuracy, F1 score, 정밀도, 재현율 등의 지표를 사용한다.
평가 결과를 통해 다시 Feature Engineering 과정으로 돌아가 변수들을 변경하거나, 스케일링 방식을 변경하기도 하고, 모델을 바꾸는 등 조정을 통해 원하는 성능이 나올 때까지 파이프라인을 반복한다.
