GANs (Generative Adversarial Networks)
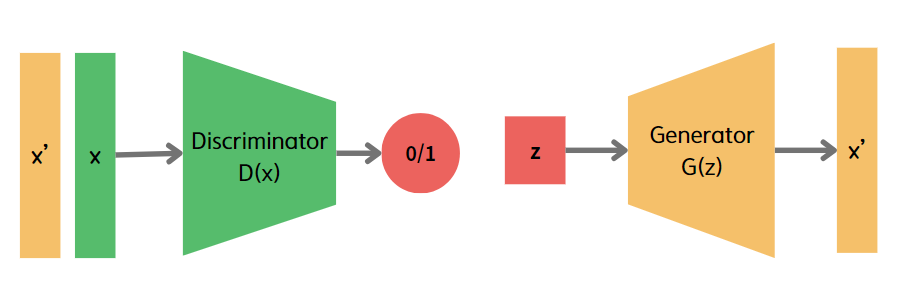
GAN은 판별자(Discriminator)와 생성자(Generator)로 구분되는 구조를 가진다.
판별자와 생성자는 서로 적대적인 관계로, 훈련 과정에서 판별자는 생성자가 생성해낸 이미지가 진짜인지 가짜인지를 구분하고, 생성자는 판별자가 이미지를 분간할 수 없도록 진짜와 가까운 이미지를 생성한다.
GAN 모델을 정의하고 학습시키기 위해 생성 모델 G와 판별 모델 D를 정의해야 한다.
생성 모델 G
입력 : 잠재 공간(latent space)에서 샘플링한 무작위 노이즈 벡터(z)
출력 : 진짜 데이터와 구분이 어려운 생성 데이터
생성 모델 G는 학습 데이터의 분포를 모사하여, 그와 흡사한 데이터를 생성하는 방향으로 학습한다.
판별 모델 D
입력 : 생성 모델 G가 생성한 가짜 데이터
출력 : 입력으로 받은 데이터가 실제 데이터일 확률을 0~1 사이의 확률로 출력
판별 모델 D는 생성 모델 G가 생성해낸 데이터가 실제 데이터인지 가짜 데이터인지를 판별하기 위한 방향으로 학습한다.
결론적으로 두 모델이 서로 경쟁적으로 학습하면서 GAN이 높은 품질의 생성 데이터를 만들어낼 수 있도록 한다.
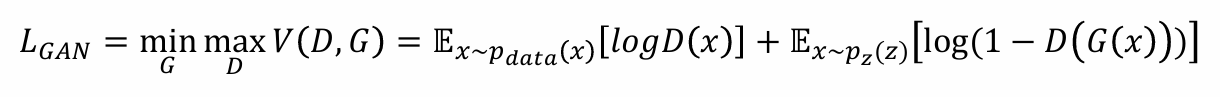
즉, 생성 모델 G는 값을 최소로 만들기 위한 방향으로 학습하고, 판별 모델 D는 값을 최대로 만들기 위한 방향으로 학습한다.
cGAN (Conditional Generative Adversarial Networks)
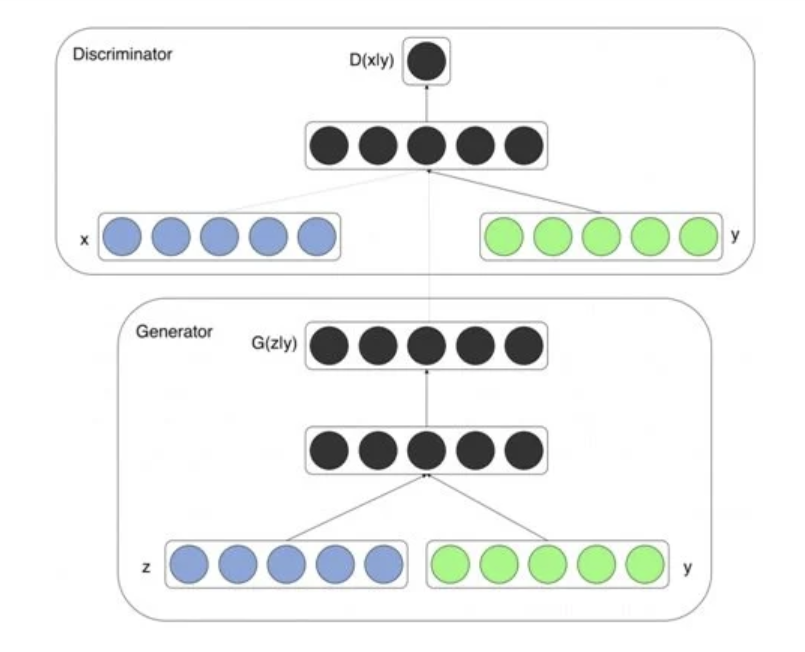
기존의 GAN 모델에 조건(Condition)을 추가한 모델이다.
여기서 조건은 클래스 레이블, 특정 속성, 데이터 특성 등이 포함될 수 있다.
전반적인 구조는 GAN과 동일하지만 레이블(y) 형태의 조건을 D, G의 입력에 추가한다. 이를 바탕으로 데이터를 생성하는 과정하거나 판별하는 과정에서 데이터를 제어할 수 있다.
Pix2Pix
cGAN에서 조건을 이미지로 받아 새로운 이미지를 생성하는 경우를 뜻한다. 즉, 이미지를 입력으로 받아 해당 이미지를 조건으로 목표 이미지를 생성한다.
입력 이미지와 출력 이미지 간의 1:1 매핑 관계를 갖는다. 지도 학습 방식을 사용하기 때문에 학습 과정에 반드시 입력, 출력 이미지 쌍이 필요하다.
CycleGAN
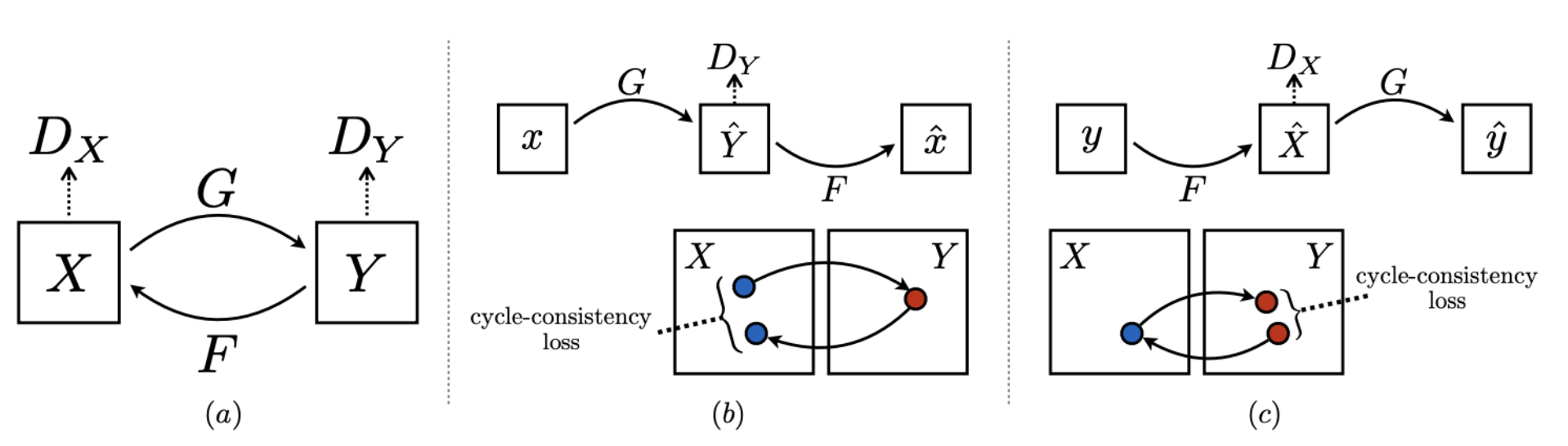
Pix2pix 방식에서 학습을 위해 많은 입출력 쌍의 이미지가 필요하다는 단점을 보완하기 위한 모델이다.
비지도 학습 방식을 사용하기 때문에 입출력 쌍의 이미지가 존재하지 않아도 학습이 가능하다.
각 도메인에서 이미지를 제공받아 도메인 별로 이미지를 변환하고, 다시 원래대로 변환한 뒤 재복원된 이미지와 원래의 입력 데이터가 최대한 유사하도록 학습한다. 이 것을 Cycle Consistency Loss라고 한다. 여기서 도메인은 이미지의 특성을 의미한다. (ex. 우는 표정, 웃는 표정, 화난 표정 등)
CycleGAN은 학습 과정에서 두 가지 목적함수를 사용한다.
1. 기존의 GAN에서 사용하는
2. Cycle Consistency Loss인
- : unpaired image X를 조건으로 Y 생성, Y가 얼마나 실제 데이터와 흡사한지에 대한 loss
- : unpaired image Y를 조건으로 X 생성, X가 얼마나 실제 데이터와 흡사한지에 대한 loss
- : X -> Y -> X' 과정을 거친 뒤 X'와 X가 얼마나 유사한지에 대한 cycle consistency loss
StarGAN
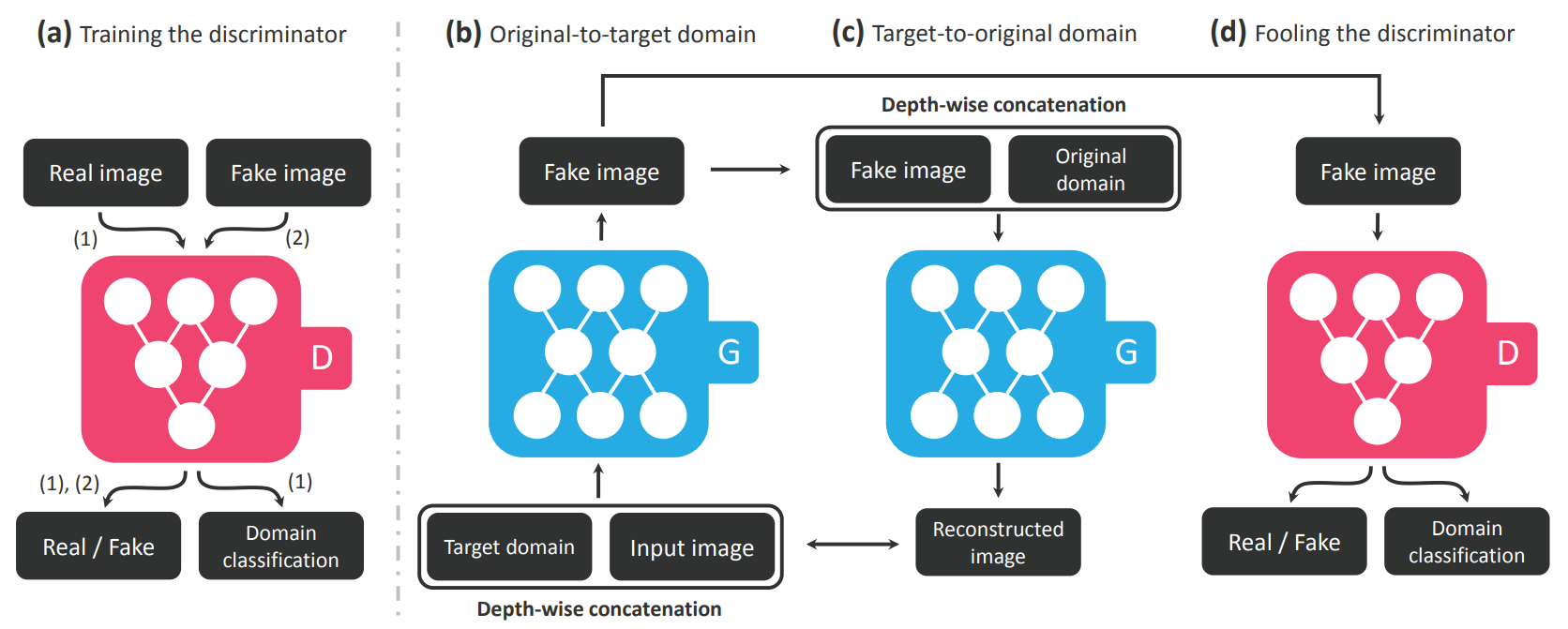
CycleGAN을 통해 도메인 간의 변환을 효율적으로 학습시킬 수 있게 되었지만, 도메인 별로 별도의 생성 모델을 만들어야 한다는 단점이 존재한다.
이를 해소하기 위한 모델이 StarGAN으로, 단일 생성 모델만으로 여러 도메인을 모두 반영할 수 있는 구조를 제시한다. 기존의 CycleGAN 구조에 변환할 도메인을 나타내는 도메인 레이블을 추가함으로써 이를 제어한다.
StarGAN은 모델 학습을 위해 세 가지 목적함수를 사용한다.
1. 기존의 GAN에서 사용하는
2. 도메인을 판단하기 위한
3. Cycle Consistency Loss인
ProgressiveGAN
처음부터 고해상도 이미지를 생성하기 위해서는 많은 비용이 필요한데, 이를 해결하기 위해 저해상도 이미지 생성 구조에서 시작해서 단계적으로 증강하여 적은 비용으로 고해상도 이미지를 생성할 수 있는 모델이다.
저해상도 이미지를 먼저 생성한 뒤에 이를 고해상도로 변환하는 과정을 여러 번 거친다. 이미지 해상도를 키우는 과정에서 저해상도 이미지의 결과를 고해상도 이미지의 결과와 weighted sum함으로써 활용한다.
점진적으로 해상도를 키우는 과정에서 각 단계 별로 새로운 레이어가 추가되고, 점차 복잡한 세부 정보를 학습하게 된다.
StyleGAN
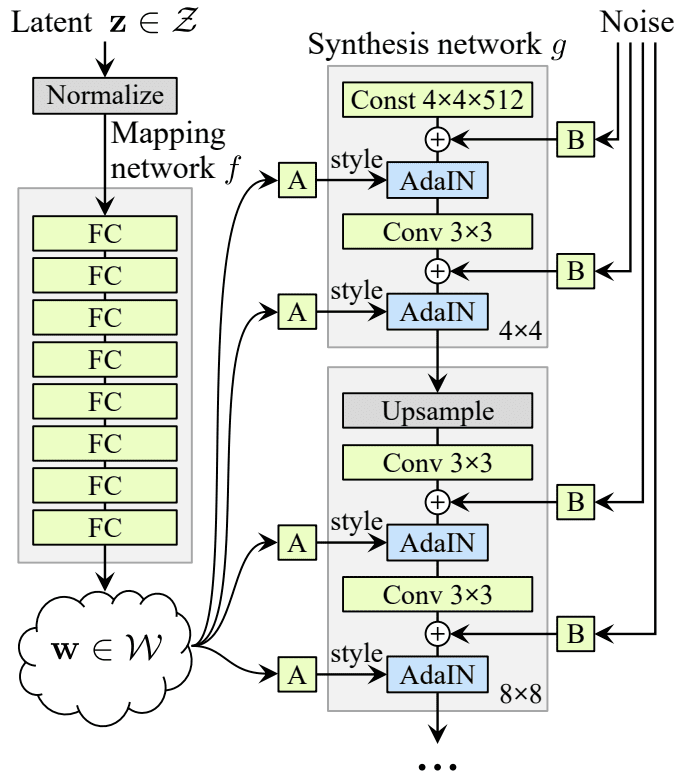
ProgressiveGAN의 구조에서 각 레이어의 생성 단계에 스타일 벡터를 주입함으로써 고해상도의 다양한 스타일 정보를 가진 이미지를 생성할 수 있다.
기존의 GAN에서는 잠재 벡터(z)가 바로 생성 모델의 입력으로 전달되지만, StyleGAN에서는 이를 별도의 스타일 네트워크 f를 통해 스타일 벡터(w)로 변환하여 입력으로 사용한다.
기존의 잠재 벡터(z)는 가우시안 분포를 가정하기 때문에 데이터가 복잡하게 얽혀 있는데, 이 얽힘을 데이터 분포에 맞춰 적절하게 풀리도록 하기 위해 스타일 네트워크 f를 사용한다.
이렇게 얻은 스타일 벡터(w)를 affine transform을 통해 변환하고, 이를 AdaIN(Adaptive Instance Normalization)을 통해 반영한다.
Reference
- Karras, T., Laine, S., & Aila, T. (2018). A Style-Based Generator Architecture for Generative Adversarial Networks.
- Choi, Y., Choi, M., Kim, M., Ha, J. W., Kim, S., & Choo, J. (2018). StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation.
- Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks.
