이번 주는 자연어처리를 주로 다뤘다. 병원진료, 회사 업무 등으로 몇 번
수업을 빠졌는지라(병원진료 받은 게 공가처리 될지 걱정되긴하네) 이번
주말은 자연어처리 관련 내용 복습하고 정리하는데 할애할 생각이다.
01. AI기초 개념
- AI정의 : 컴퓨터가 사람이 정한 기준에 따라 자동으로 판단하는 기술
- 문제 해결 과정
- 수치화(Numericalization) : 데이터를 숫자로 표현
- 벡터 임베딩(Vector Embedding) : 의미를 보존하여 벡터 공간에 매핑
- 판단 기준: 벡터 공간에서 결정 경계(Decision surface)로 표현
02. 2010년대 이후 AI급성장 이휴
- Computing Power 향상
- Parallel Processing 가능 (GPU, TPU)
- Automatic Differentiation (자동미분, Chain Rule 기반)
- 딥러닝 학습 안정화 및 대규모 모델 훈련 가능
예: PyTorch, TensorFlow의 핵심 기능
- 딥러닝 학습 안정화 및 대규모 모델 훈련 가능
03. NLP 개요
- 정의: 컴퓨터가 인간의 언어를 이해·처리·생성하는 기술
- 하위 분야:
- NLU (자연어 이해): 의도 인식, 개체명 인식, 감정 분석 등
- NLG (자연어 생성): 문장 생성, 번역, 요약 등
04. LLM으로 인한 NLP 변화
- 대형언어모델(LLM)로 인해 자연어처리(NLP) 분야에서의 과업 수행에도
영향이 생김

- LLM 시대에 주목받는 과제들
- Prompt Engineering
- Instruction Following
- RAG (Retrieval-Augmented Generation)
- Multi-agent Communication
- Tool-augmented LLMs
- Alignment / Fine-tuning
- Robustness / Hallucination Mitigation
05. 텍스트 전처리
01) 토큰화(Tokenization)
- 단어, 형태소, subword 단위 분리
- subword 토큰화: BPE, WordPiece(OOV 문제 해결)
- 형태소 품사 태그 예시
- NNG 일반명사, VV 동사, JKS 주격조사
02) 정제(Cleaning)
- HTML, 특수문자, 이모지, 중복 공백 제거
03) 정규화(Normalization)
- 대소문자 통일, 반복 문자 축약, 구어체 표준화
04) 불용어 제거(Stopwords Removal)
- 의미 없는 단어 제거 (주의: 과도한 제거는 정보 손실)
05) 형태소 분석(Morphological Analysis)
- 어근·접사 분리, 품사 태깅, 어간 추출
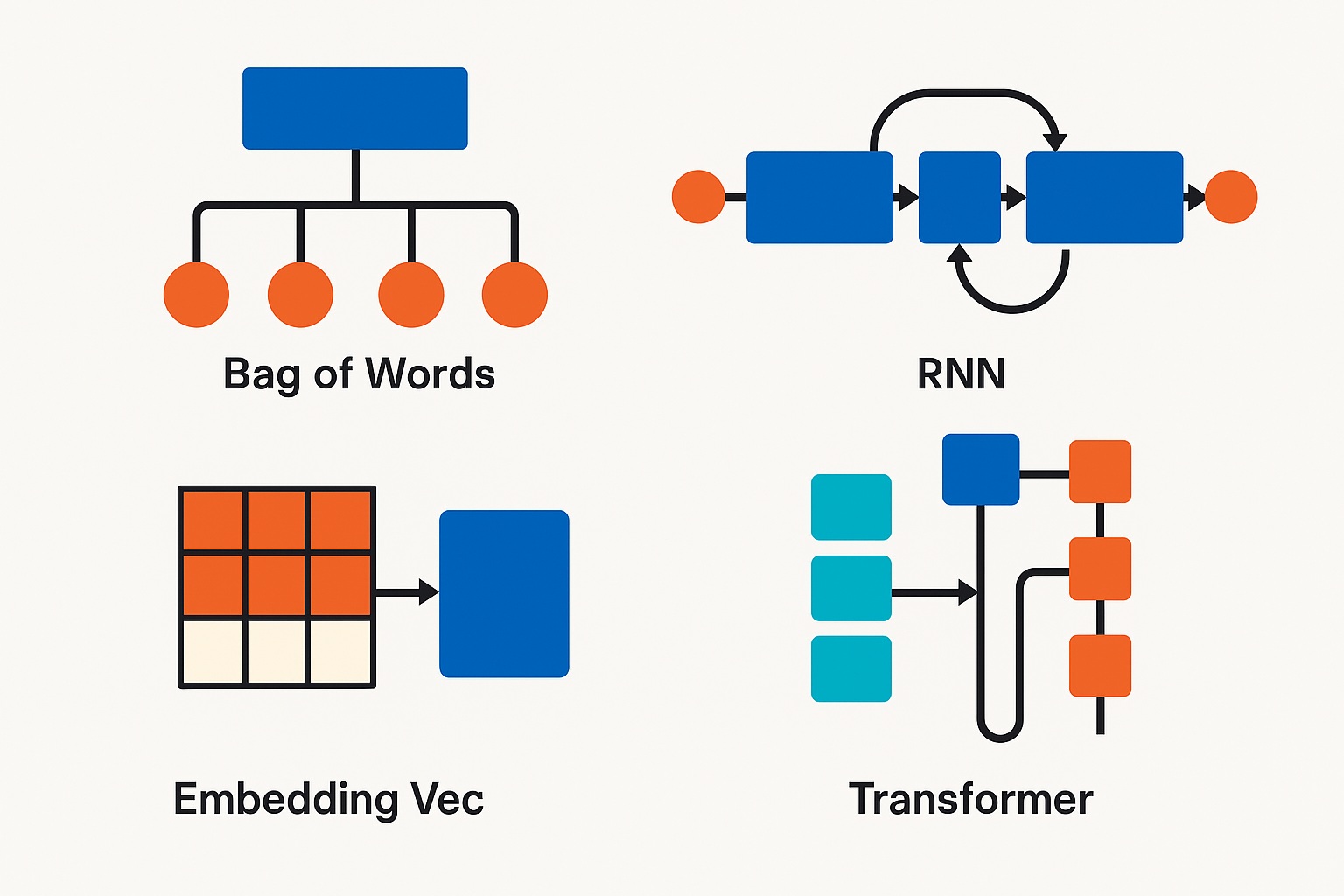
06. 인코딩 기법
01) 정수 인코딩
- 각 단어에 정수 ID 부여
- 단점 : 의미 유사성 반영 불가
02) 원-핫 인코딩
- 해당 단어 익덱스만 1, 나머지는 0
- 장점 : 간단, 독립성 유지
- 단점 : 차원 폭발, 의미 정보 손실
07. RNN (Recurrent Neural Network)
- 목적 : 순차 데이터(시퀀스) 처리
- 구조 수식:
- 종류
- One-to-One: 일반 ANN
- One-to-Many: 이미지 캡셔닝
- Many-to-One: 감정 분류
- Many-to-Many: 번역
08. BPTT (Backpropagation Through Time)
- 시퀀스 전체를 펼친 후 역전파
- Gradient 계산시 Chain Rule 적용:
- 문제점: 긴 시퀀스 → Gradient Vanishing/Exploding
09. RNN의 한계와 발전
- 한계: 장기 의존성 문제(Long-Term Dependency)
- 대안
- LSTM: 셀 상태, 게이트 구조로 장기 정보 보존
- GRU: 구조 간소화 + 연산 효율 향상

2025화이팅!