벌써 7주차다. 9월 중순이면 10주 간의 일정이 끝나니까, 7주차 내용도
힘내서 정리해 봐야겠다.
01. 주요 Computer Vision Task
- Classification: 이미지 전체를 분류 (ex. 고양이, 강아지)
- Localization: 객체 위치를 bounding box로 찾기
- Object Detection : 여러 객체를 찾고 분류 + 위치 확인
- Semantic Segmentation : 픽셀 단위로 분류 (객체별 구분 X)
- Instance Segmentation: 픽셀 단위 + 객체별 개별 구분
02. Semantic Segmentation
- 기본 아이디어
- Sliding Window: 각 픽셀 주변 patch를 CNN으로 분류
→ 너무 비효율적 (겹치는 부분 연산 낭비) - Fully Convolutional Network (FCN):
- Conv Layer만 사용해 입력 전체에 대해 한 번에 예측
- Sliding Window: 각 픽셀 주변 patch를 CNN으로 분류
- 구조
- Downsampling: Max Pooling, Strided Conv
- Upsampling:
- Unpooling (Nearest Neighbor, Bed of Nails, Max Unpooling)
- Transposed Convolution (= Deconvolution)
03. FCN과 U-Net (Skip Connection)
- FCN은 원본 해상도가 줄어들면서 세부 정보 손실 → 이를 보완하기 위해 Skip Connection 추가 (U-Net 구조).
- 고해상도 feature map을 upsampling 과정에 합쳐 의미적 정보 + 위치 정보 동시에 유지 가능
04. 평가지표(Segmentation)
- IoU (Intersection over Union)
- mIoU : 각 클래스 IoU의 평균
05. Classification + Localization
-
분류(Softmax Loss) + 위치 회귀(L2 Loss) → Multitask Loss
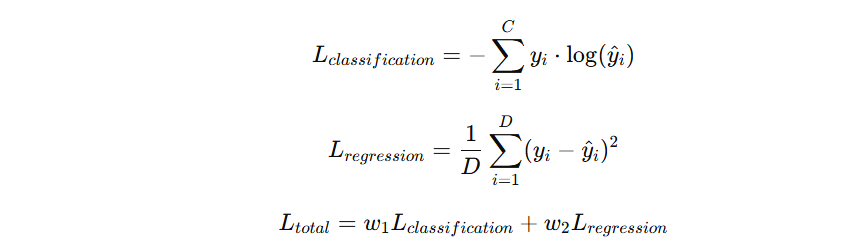
-
Localization은 회귀 문제로 다룸
06. Keypoint Detection (= Regression)
- Human Pose Estimation: 관절 위치를 좌표로 예측
- Facial Landmark: 얼굴의 점(눈, 코, 입 등)을 좌표로 회귀
- Loss: 주로 L2 Loss 사용
07. Transfer Learning
- 대규모 데이터셋 (ImageNet)으로 pretraining
- Target task에 맞게 마지막 layer 재학습 (fine-tuning)
- 데이터 양이 적으면 앞쪽 layer freeze, 많으면 더 많은 layer 업데이트
08. VGGNet (2014)
- 핵심 아이디어: 작은 필터(3x3 Conv)만 사용, 깊게 쌓기
- AlexNet (8 layers) → VGG16 (16 layers), VGG19 (19 layers)
- 단순하지만 파라미터 수가 매우 많아 계산량 큼
09. ResNet (2015)
-
단순히 layer를 깊게 쌓으면 학습이 어려워짐 → 기울기 소실 문제
-
해결책: Skip Connection (Residual Block)
-
즉, 전체 를 학습하는 대신 잔차(residual) 를 학습
→ 네트워크가 더 깊어져도 안정적으로 학습 가능
10. 핵심 정리
- Segmentation: 픽셀 단위 분류 (FCN, U-Net, IoU/mIoU 평가)
- Classification + Localization: Multitask Loss (분류 + 회귀)
- Keypoint Detection: 좌표 회귀 문제
- Transfer Learning: 사전학습 + fine-tuning
- VGGNet: 단순, 깊은 네트워크 (3x3 Conv)
- ResNet: Residual Block으로 깊은 네트워크 학습 가능

2025화이팅!