안녕하세요, 슬로우 CTO Tony입니다.
슬로우 크루들을 대상으로 최근 각광받는 AI의 한분야인 LLM(Large Language Model)에 대해 기초적인 지식을 고양하기 위해 초보자들도 이해할 수 있는 수준으로 가볍게 세미나를 진행했습니다.
대부분은 제가 경험했고 공부했던 내용을 기반으로 하고 있으나 다양한 블로그나 사이트를 참고했습니다.
다음은 발표 내용 중 일부를 정리한 것입니다.
언어 모델(Language Model)은 무엇인가?
언어 모델(Language Model, LM)은 언어라는 현상을 모델링하고자 단어 시퀀스(문장)에 확률을 할당(assign)하는 모델입니다.
언어 모델을 만드는 방법은 크게는 통계를 이용한 방법과 인공 신경망(Neural Network)을 이용한 방법으로 구분할 수 있습니다. 최근에는 통계를 이용한 방법보다는 인공 신경망을 이용한 방법이 더 좋은 성능을 보여주고 있습니다. 자연어 처리의 기술인 GPT나 BERT 또한 인공 신경망 언어 모델의 개념을 사용하여 만들어졌습니다. 이번 챕터에서는 언어 모델의 개념과 언어 모델의 전통적 접근 방식인 통계적 언어 모델에 대해서 배웁니다.
언어 모델(Language Model)
언어 모델은 단어 시퀀스에 확률을 할당(assign) 하는 일을 하는 모델입니다. 이를 조금 풀어서 쓰면, 언어 모델은 가장 자연스러운 단어 시퀀스를 찾아내는 모델입니다. 단어 시퀀스에 확률을 할당하게 하기 위해서 가장 보편적으로 사용되는 방법은 언어 모델이 이전 단어들이 주어졌을 때 다음 단어를 예측하도록 하는 것입니다.
다른 유형의 언어 모델로는 주어진 양쪽의 단어들로부터 가운데 비어있는 단어를 예측하는 언어 모델이 있습니다. 이는 문장의 가운데에 있는 단어를 비워놓고 양쪽의 문맥을 통해서 빈 칸의 단어인지 맞추는 고등학교 수험 시험의 빈칸 추론 문제와 비슷합니다. (이 유형의 언어 모델은 BERT 모델로 자세한 내용은 다루지 않겠습니다.)
언어 모델에 -ing를 붙인 언어 모델링(Language Modeling)은 주어진 단어들로부터 아직 모르는 단어를 예측하는 작업을 말합니다. 즉, 언어 모델이 이전 단어들로부터 다음 단어를 예측하는 일은 언어 모델링입니다.
자연어 처리로 유명한 스탠포드 대학교에서는 언어 모델을 문법(grammar)이라고 비유하기도 합니다. 언어 모델이 단어들의 조합이 얼마나 적절한지, 또는 해당 문장이 얼마나 적합한지를 알려주는 일을 하는 것이 마치 문법이 하는 일 같기 때문입니다.
단어 시퀀스의 확률 할당
자연어 처리에서 단어 시퀀스에 확률을 할당하는 일이 왜 필요할까요? 예를 들어보겠습니다. 여기서 대문자 P는 확률을 의미합니다.
기계 번역(Machine Translation):
P(나는 버스를 탔다) > P(나는 버스를 태운다): 언어 모델은 두 문장을 비교하여 좌측의 문장의 확률이 더 높다고 판단합니다.
오타 교정(Spell Correction)
선생님이 교실로 부리나케
P(달려갔다) > P(잘려갔다): 언어 모델은 두 문장을 비교하여 좌측의 문장의 확률이 더 높다고 판단합니다.
언어 모델은 위와 같이 확률을 통해 보다 적절한 문장을 판단합니다.
언어 모델의 역사
-
LLM의 역사
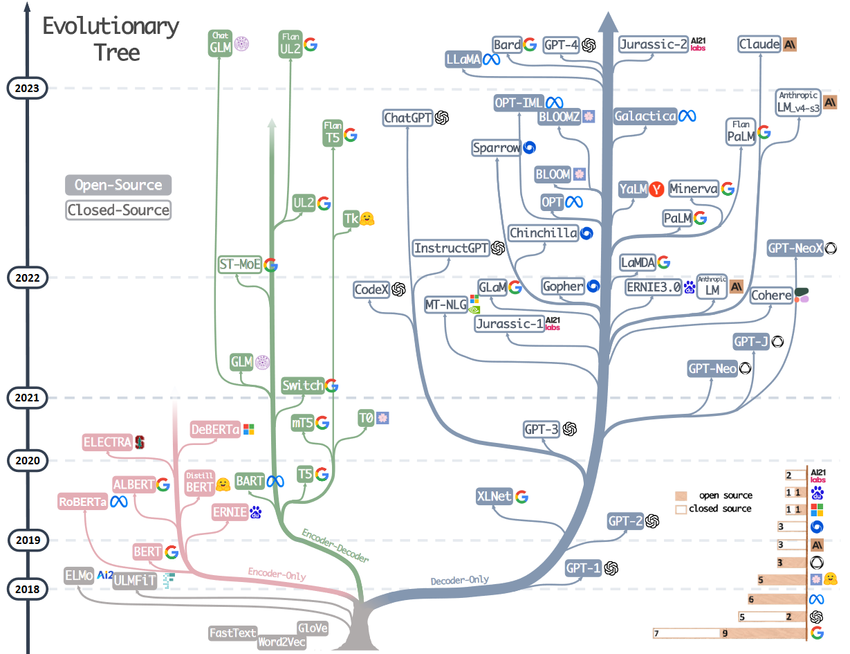
2019년 이후 수많은 LLM들이 나오고 있습니다. -
LLM의 종류
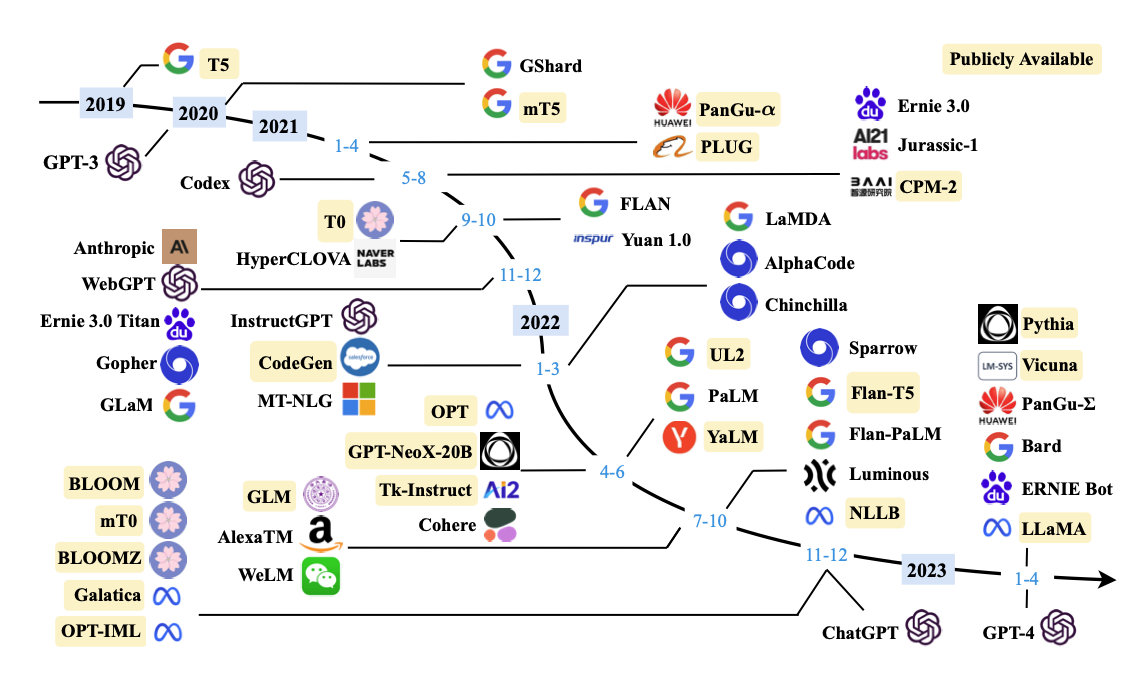
LLM(Large Language Model)이란
LLM(거대 언어 모델, Large Language Model)이란, 거대한 데이터 셋을 사용해서 훈련된 대용량의 언어 모델을 의미합니다. 딥러닝 알고리즘과 통계 모델링을 사용해서 자연어를 처리(NLP, Natural Language Processing)하는 용도로 활용되는데요. 사전에 대규모의 언어 데이터를 학습해서 문장의 구조나 문법, 의미들을 이해하고 이를 활용해 사람이 말하는 것과 유사하게 자연어를 생성할 수 있게 합니다.
거대 모델이란?
도대체 어느정도 커야 초거대 언어 모델일까요?
언어모델(Language Model)과 거대언어모델(Large Language Model) 이라고 부를 수 있을까요? 기준점이 명확하게 정의되어 있지는 않습니다.
크기로 생각한다면 1980년대, 90년대에 사용했던 언어모델에 비하면 요즘의 딥러닝 언어모델은 모두 거대언어모델입니다. 하지만 모든 딥러닝 언어모델이 모두 거대언어모델이라 불리지는 않죠. 도대체 어떻게 기준을 잡아야 할가요?
ChatGPT(GPT-4o) 에게 물어보면 다음과 같이 대답해 줍니다.
Q : 어느정도의 모델이라야 거대 언어모델로 볼 수 있을까? 거대모델의 정의를 조금 더 확실한 기준으로 해줘
A : 거대 언어 모델(Giant Language Model, LLM)은 보통 매개변수(parameter) 수와 훈련 데이터의 양에 따라 정의됩니다. 하지만 "거대"라는 표현은 상대적이기 때문에 그 기준은 시간이 지나면서 발전하고 있습니다. 그래도 현재 기준에서 거대 언어 모델로 볼 수 있는 기준은 다음과 같습니다:
- 매개변수 수
수십억 개 이상의 매개변수를 가진 모델: 일반적으로 10억 개 이상의 매개변수를 가진 모델은 거대 언어 모델로 간주됩니다.
예를 들어, GPT-3는 1750억 개의 매개변수를 가지고 있으며, 이는 현존하는 가장 큰 LLM 중 하나로 인정받고 있습니다.
매개변수 수가 수백억~수천억 단위로 증가하면 "초거대 언어 모델"이라고 부르기도 합니다. - 훈련 데이터의 양
수십 테라바이트 이상의 텍스트 데이터: 거대 언어 모델은 일반적으로 인터넷에 존재하는 방대한 텍스트 데이터를 기반으로 훈련됩니다.
이 데이터에는 뉴스 기사, 책, 웹사이트, 코드 등이 포함될 수 있으며, 그 양은 수십 테라바이트(TB) 또는 그 이상일 수 있습니다. - 모델의 활용 범위
거대 언어 모델은 다양한 자연어 처리(NLP) 작업을 다룰 수 있는 범용 모델로 설계되며, 텍스트 생성, 번역, 요약, 질문 답변 등 다양한 작업에 적용될 수 있습니다.
예를 들어, GPT 시리즈, BERT, T5, PaLM 등은 다목적 용도로 설계된 LLM입니다. - 인프라 요구사항
이러한 모델을 훈련하고 추론하는 데는 대규모 컴퓨팅 인프라가 필요합니다. 수천 개의 GPU/TPU 클러스터, 수백 테라플롭스(TFLOPS) 이상의 연산 성능이 요구되며, 대규모 분산 훈련이 필요합니다.
결론
거대 언어 모델의 기준은 매개변수 수가 10억 개 이상, 훈련 데이터 양이 수십 테라바이트 이상인 경우라고 할 수 있습니다. 이는 범용 NLP 작업에 사용할 수 있는 고도의 성능을 가진 모델을 의미합니다. 이 정의는 시간이 지나면서 더 큰 모델이 등장함에 따라 변화할 수 있습니다.
10억개의 매개변수라면 1B 정도의 매개변수를 가진 모델인데 실제로 1B 정도의 모델을 가지고 테스트를 해보면 거대모델이라고 하기에는 조금 부족한 성능을 보여줍니다. 적어도 7B, 혹은 12.8B 정도는 되야 그래도 괜찮은 성능이 나오는 것을 경험했습니다.
(개인적인 경험상 12.8B 정도만 되도 양자화를 하지 않으면 Colab이나 4090과 같은 소비자용 GPU에서는 서빙이 힘들고 A100 정도 되야 무난하게 서빙이 가능합니다.)
NLP(Natual Language Process)란?
자연어 처리(NLP)는 컴퓨터와 사람들이 인간의 언어를 사용하여 상호 작용할 수 있는 방법에 초점을 맞춘 인공 지능(AI)의 한 형태입니다. NLP 기술은 컴퓨터가 우리의 자연스러운 의사소통 모드인 음성과 서면 텍스트를 사용하여 우리를 분석하고, 이해하고, 응답하는 데 도움이 됩니다.
자연어 처리는 컴퓨터 언어학의 하위 전문 분야입니다. 컴퓨터 언어학은 인간 언어의 컴퓨터적 측면을 연구하기 위해 컴퓨터 과학, 언어학, 그리고 인공 지능을 결합한 학제간의 분야입니다.
LLM의 발전과정
자연어를 처리하는 기술을 개발하는 과정에서 언어모델에 대한 연구도 점차 발전하게 되었습니다. 언어모델의 개발단계를 구분하자면 SLM → NLM → PLM → LLM의 단계로 구분할 수 있습니다.
- SLM(Small Language Model) : 제한된 양의 텍스트 데이터를 학습하여, 국소적인 문맥 이해에 초점을 둠. 작은 규모이기 때문에 가볍고 빠르게 실행가능한 특성을 가진다.
- NLM(Neural Language Model) : 단어 임베딩, 문장 완성, 기계 번역 등의 NLP작업에 활용되는 언어모델로, 기존의 통계 기반 언어 모델보다 더 정확한 성능을 제공하는 것으로 알려져 있습니다.
- PLM(Pretrained Language Model) : 대규모 데이터 셋으로 미리 학습된(Pre-trained) 언어모델로, 전이학습(Transfer Learning)을 통해 다양한 NLP 작업에 활용됩니다. BERT와 GPT와 같은 주요 모델들이 이 PLM에 해당한다고 할 수 있습니다.
PLM의 데이터 셋 규모가 점차 증가한 것을 대형 PLM이라고 칭하다가, '대규모 언어모델(LLM)'이라는 용어로 사용하는 것이 지금의 LLM입니다.
대표적인 LLM
GPT-3, ChatGPT, GPT-4, LLaMA, PALM, Bard, Gemini 등 대중적으로도 잘 알려져 있는 대표적인 LLM 모델들이 있습니다.
이중 가장 유명한 것은 단연 ChatGPT입니다.
ChatGPT의 학습 방법
대표적인 LLM 모델인 ChatGPT의 기본 구조와 학습 방법에 대해 알아보겠습니다.
ChatGPT는 GPT-3 기반의 언어 모델로서 Instruction Fine-tuning과 RLHF를 통해 미세조정된 모델로서 정확한 모델명은 GPT-3.5-Turbo이다.
GPT(Generativew Pre-trained Transformer)
GPT는 생성 모델 중 하나로, 트랜스포머, 언어 모델을 기반으로 문장을 생성하는 모델입니다. 입력된 문장을 일정한 단위로 분할하고, 다음 단어를 생성하는 방식으로 동작합니다. 생성된 다음 단어와 입력된 단어를 반복하여 문장 생성을 진행하는데, 이를 '자기 회귀'라고 합니다. 현재 대부분의 언어 생성 모델이 이와 같은 방식으로 생성되고 있습니다.GPT를 구성하는 3개의 단어를 보면 GPT가 무엇인지 조금 더 쉽게 알 수 있는데요.
- Generative (생성 모델)
- Pre-Trained (사전 훈련)
- Transformer (Transformer AI 모델)
RLHF(Reinforcement Learning from Human Feedback)
RLHF는 사람의 피드백을 활용하여 강화학습을 진행하는 방식으로, ChatGPT에서 사용되고 있습니다. 이 방법은 보상함수의 점수를 높이는 강화학습과 달리 모델이 생성한 여러 결과물을 순서대로 평가하여 사람이 선호하는 순서대로 순위를 매기는 방식으로 진행됩니다. 이후 모델의 결과물을 입력으로, 순위를 출력으로 하는 RM(Rank Model) 모델을 학습하고, 이를 GPT 모델의 강화학습에 사용하여 매번 사람이 피드백하는 것을 모델에게 넘겨 사람의 선호를 반영하는 강화학습을 진행합니다.
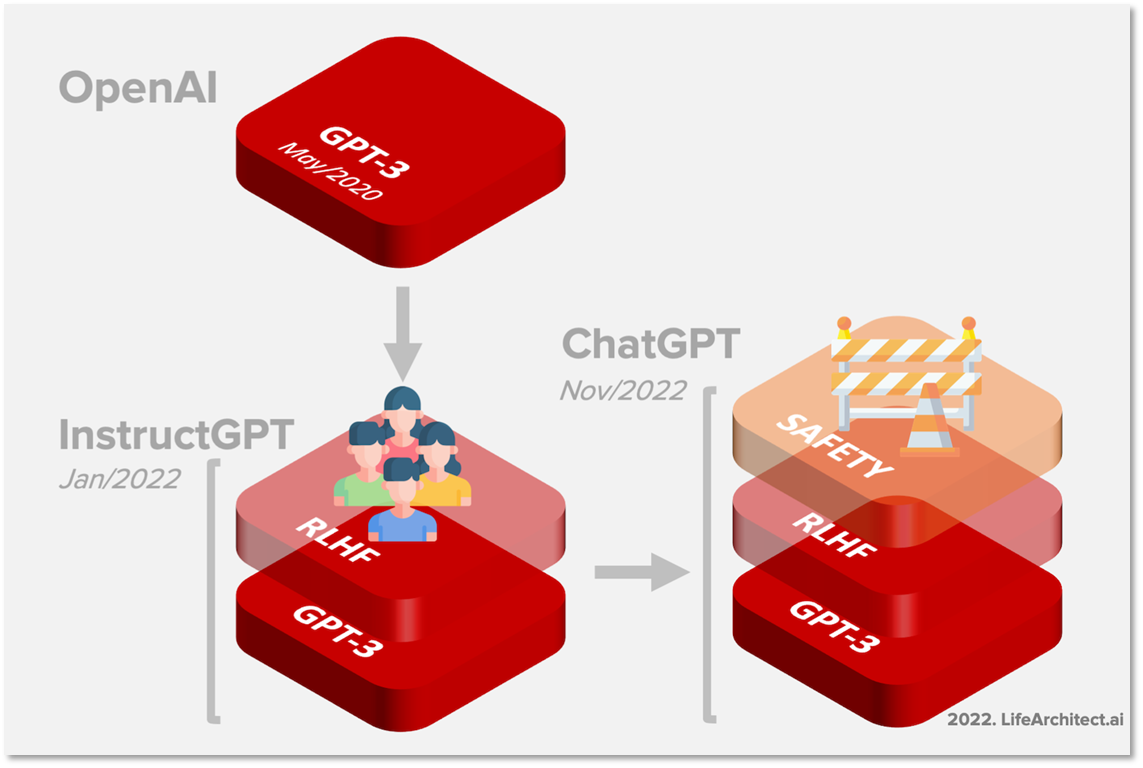
ChatGPT 학습 과정
- Pretraining
- Instruction Fine-tuning
- RLHF(Reinforcement Learning from Human Feedback
Pretraing
첫 번째 단계는 사전 훈련입니다. 이 단계에서는 대규모 데이터를 사용해 다음 단어를 예측하는 방법을 학습합니다. 이 과정에서 모델은 언어의 문법과 구문을 익히고, 세상에 대한 많은 지식과 다른 여러 능력도 습득하게 됩니다. 하지만 여기서 한 가지 문제가 있습니다. 사전 훈련을 통해 모델이 주로 학습한 것은 단순히 주제에 대해 길게 말하는 능력입니다. 그러나 질문에 답하거나 명령을 수행하는 것과 같은 사용자의 의도에 맞는 반응을 잘하지 못합니다. 이는 모델이 AI 비서로서의 역할을 배우지 않았기 때문입니다.예를 들어, 사전 훈련된 모델에 "너의 이름이 뭐니?"라고 묻는다면, "네 성은 뭐니?"라고 답할 수 있습니다. 이는 모델이 사전 훈련 중에 본 데이터와 유사한 패턴을 따르는 것이기 때문입니다. 이처럼 모델이 사용자 지시에 따르지 못하는 이유는 지시와 이에 대한 응답이라는 언어 구조가 훈련 데이터에서 흔히 나타나지 않기 때문입니다. 따라서 이 단계에서는 모델이 인간의 의도에 맞지 않는다고 할 수 있습니다. 그러나 이 문제는 해결할 수 있으며, 사전 훈련된 모델도 지시를 따르는 법을 배울 수 있습니다.
Instruction Fine-tuning과 RLHF
이제 지시 미세 조정이 필요합니다. 사전 훈련된 모델을 가져와 이번에는 고품질의 지시와 응답 쌍을 사용하여 한 단어씩 예측하는 방식으로 다시 학습시킵니다. 이를 통해 모델은 단순한 텍스트 완성기에서 벗어나 사용자의 의도에 맞는 유용한 비서로 변하게 됩니다. 이때 사용되는 지시 데이터셋은 사전 훈련 때보다 훨씬 적지만, 더 고품질의 인간이 생성한 데이터입니다. 이를 지도 학습 지시 미세 조정이라고도 합니다.또한, ChatGPT와 같은 일부 모델은 인간의 피드백을 통한 강화 학습(RLHF) 단계를 거치기도 합니다. 이 단계는 지시 미세 조정과 유사한 목적을 가지고 있으며, 모델의 출력을 인간의 가치와 선호에 맞추도록 도와줍니다. 초기 연구에 따르면 이 단계가 인간 수준의 성능을 달성하는 데 중요하다고 합니다. 강화 학습과 언어 모델링의 결합은 향후 큰 발전을 이끌어 낼 가능성이 높습니다.
RLHF에 대해 조금 더 살펴보면 다음과 같은 3단계로 이루어져 있습니다.
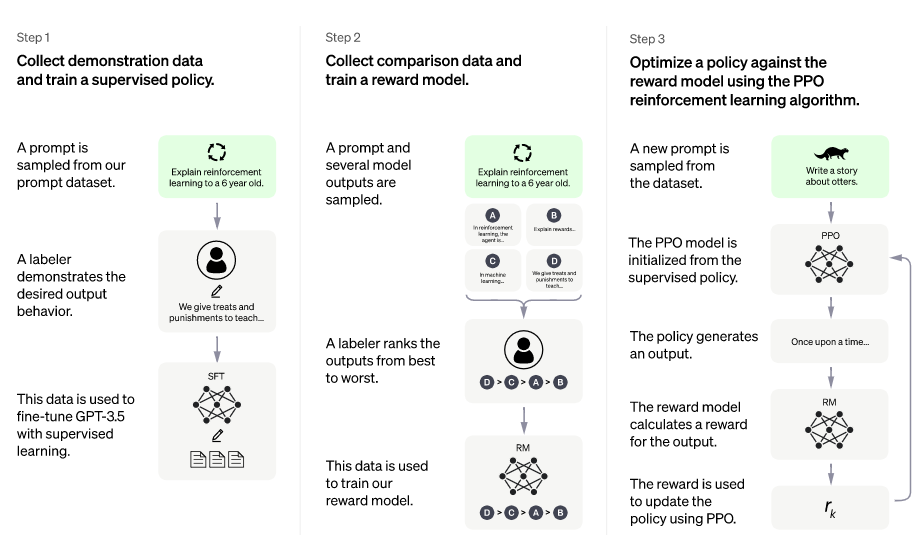
Step 1. Pretraining Language Model
Step 1을 살펴보면 OpenAI는 인터넷에서 떠도는 데이터 전체를 신뢰하지 않았습니다.
그렇기 때문에 신뢰할 수 있는 질문과 답안만을 가지고 지도 학습(Supervised find-tuning)을 시켰습니다.
데이터 양이 제한되어 있기 때문에 질문자의 의도와 다르게 답변을 내놓는 모델이었고 여기까지는 일반적인 언어 모델과 동일합니다.
Step 2. Reward Model training
Step 1의 언어 모델에 질문을 하고 여러 답변을 받습니다. 그렇게 생성된 여러 답변 중 질문자의 의도와 부합하는지 평가해 순위를 매깁니다.
이를 별도로 데이터베이스화하고 이 데이터를 이용해 학습을 반복하면서 답변 우선순위를 예측하도록 합니다.
Step 3. Fine-tuning with RL
Step 3는 PPO(Proximal Policy Optimization) 알고리즘을 사용하여 언어 모델의 파라미터 일부 또는 전체를 fine-tuning 하는 방법을 사용합니다.
학습에 사용한 데이터가 아닌 새로운 질문으로 생성된 답변을 보고 문제점을 미세하게 조정하는 단계입니다.
선별된 데이터세트로 진행한 Step1 ~ Step2 과정의 결과가 갖고 있는 한계를 극복하고 정확도를 높이기 위함입니다.
ChatGPT 이후의 언어모델들
ChatGPT는 언어모델에 대한 대중적인 관심을 이끌어 냈으며 약 2달만에 1억명의 월간 사용자를 달성하는 기록을 세웠습니다.
ChatGPT 이후 수많은 모델들이 속속 발표되었으며 2023년은 언어모델의 개발속도가 정말 비약적으로 올라간 시기라고 생각합니다. (Google의 Bard, Meta의 LLaMA, Anthropic의 Claude, OpenAI GPT-4 등)
특히나 Meta의 LLama 모델의 경우 연구 및 비상업적인 용도록 제한적이긴 하지만 대중들에게 공개된 모델로써 다양한 파생모델들을 만들어낸 케이스로 조금 더 자세히 살펴볼 필요가 있습니다. (LLaMA-1에만 해당하는 내용이고, LLaMA-2 부터는 Open Source로 Liscense 정책이 바뀌었습니다.)
sLLM(smaller Large Language Model)
경량 언어모델(smaller Large Language Model)은 일반적으로 알려진 거대언어모델(LLM)보다 작은 매개변수 크기로 운영이 가능하다. 통상적으로 매개변수가 1000억개(100B) 이하인 모델이 sLLM으로 분류된다고 한다 (개인적으로 100B 모델은 경량이라고 부르기 좀 애매한 것 같다)
LLM보다 매개변수 크기는 작지만 성능은 LLM 못지 않고 매개변수가 작은 덕분에 빠른 데이터 처리 속도 및 응답이 가능합니다. 특히 학습 데이터량이 적어지면서 개발 비용과 유지 비용이 적게 들어가는 장점이 있습니다.
최근엔 LLM 개발 중이던 대기업들도 sLLM에 눈을 돌리고 있다. 구글은 최근 sLLM인 'Gemini nano'를, 마이크로소프트(MS)는 'Phi-3 mini'를, META는 'LLaMA-3'를 각각 공개했다.
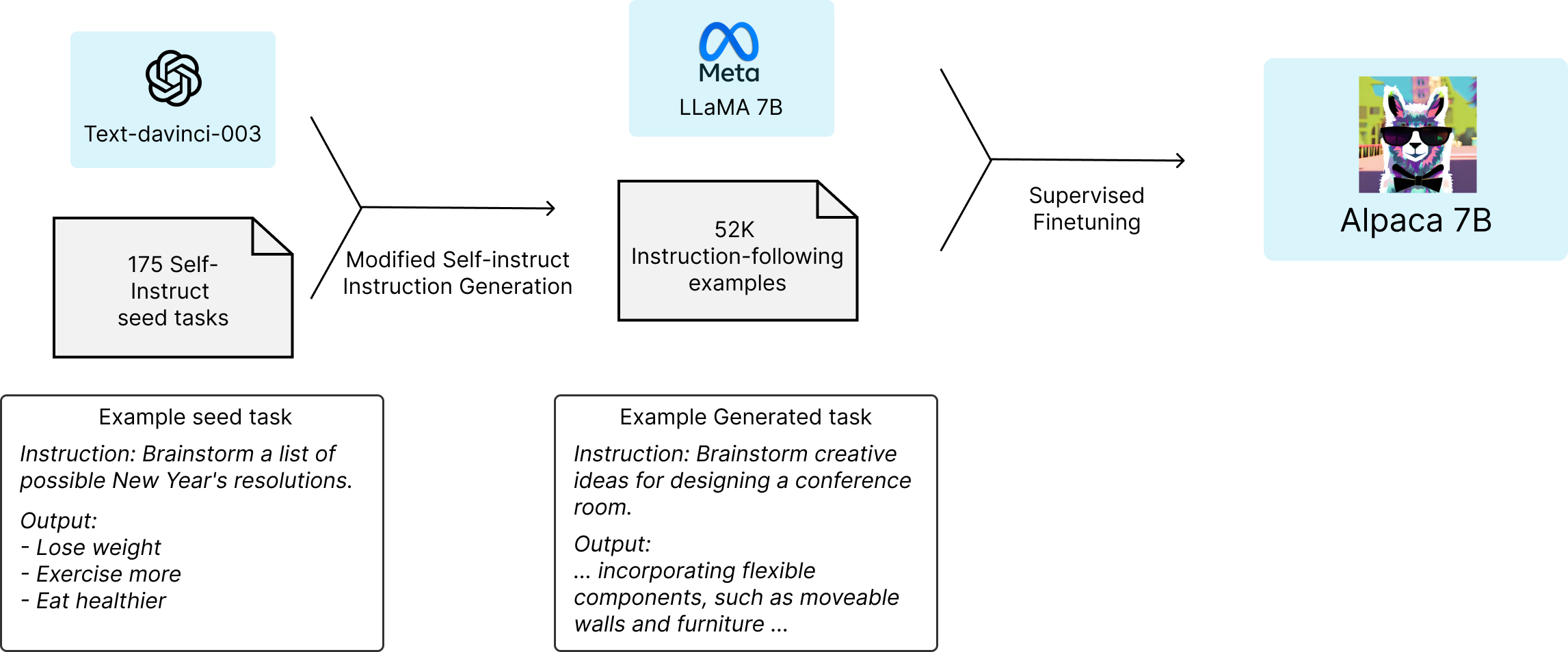
Stanford Alpaca
![]()
Alpaca 모델은 LLaMA의 발표를 계기로 Foundation Model이란 용어를 최초로 고안해낸 스탠퍼드 대학의 CRFM (Center for Research Foundation Models)는 학술 연구 목적으로 Meta의 LLaMA-7B 모델을 finetuning한 Alpaca라는 모델을 공개했습니다.
$600 미만의 비용으로 Alpaca를 학습시키는 과정
ChatGPT와 GPT-4와 같은 독점 foundation model이 득세한 가운데, 스탠퍼드의 Alpaca가 갖는 의미는 Instruction-Following Model을 학습하는 방법(self-instruction)과 저렴한 학습 비용(<500$)에 있다.
제한된 학습 예산으로 고품질의 Instruction-Following Model을 만들기 위해선 1) 강력한 pre-trained LM, 2) 고품질의 Instruction-Following 데이터셋이 필요하다.
CRFM은 1)의 문제를 해결하기 위해 Meta의 LLaMA-7B 모델을 사용하였으며, 2)의 문제는 self-instruct 논문이 제안한 것처럼 기존의 강력한 언어 모델을 사용하여 자동으로 학습 데이터셋을 확보하여 해결하였다.
Self-Instrcut
Self-Instruct는 LM이 인간의 지시를 따르는 능력을 향상시키는 데 도움을 주주는 프레임워크이다. Self-Instruct이 제안된 배경은 “instruction-tuned” 모델이 사람이 만든 학습 데이터의 품질과 양에 크게 의존하며 다양성과 창의성을 제한받을 수 있다는 문제점을 극복하기 위한 것이다.
이를 위해 대량의 instuction 데이터셋을 생성하기 위해 사람이 아닌 LLM을 활용하는 것이다. (Self-Instruct라는 이름이 붙여진 이유이다.)
Self-Instruct 과정은 사람이 작성한 instruction seed 세트로 시작하는 반복적인 부트스트래핑 알고리즘이다. instruction seed 세트는 새로운 지시와 해당 입력-출력 인스턴스를 생성하기 위해 LLM의 프롬프트로 제공된다. (물론 최초 instruction seed는 사람이 작성한다!!)
LLM이 생성한 결과 중 품질이 낮거나 유사한 항목을 필터링하고 결과 데이터를 task pool에 다시 추가한다. (필터링이 필요한 이유는 GPT-3와 같은 LLM이 생성한 데이터는 불가피하게 오류와 bias를 포함하기 때문이다. CFRM의 연구원에 따르면 생성된 데이터 품질을 분석하였을 때 데이터의 46 %에 문제가 있을 수 있음을 발견하였다.)
이 과정을 여러 번 반복하면 지시를 보다 효과적으로 따르도록 LM을 fine-tuning하는데 사용할 수 있는 대량의 학습 데이터 모음이 생성된다.
Meta의 LLaMA-1 7B 모델을 base model로 사용하였고 ChatGPT의 학습 방법 중 하나인 Instruction-following Supervised Finetuning을 한 모델입니다.
Alpaca 모델의 학습 방법은 다음과 같습니다.
KoAlpaca
스탠포드의 알파카에 한국어를 학습시킨 모델
KoAlpaca는 백본 모델로 두 가지 모델을 사용
- Polyglot-ko 5.8B 기반 -> https://huggingface.co/beomi/KoAlpaca-Polyglot
- Meta LLAMA 7B 기반 -> https://huggingface.co/beomi/KoAlpaca
데이터셋은 Stanford Alpaca의 데이터셋을 DeepL API 서비스를 사용하여 instruction과 input을 번역. output은 애초에 text-davinci-003을 활용했기 때문에 번역하지 않음.
- LLAMA 7B 모델학습은 A100 80GB 4대로 학습을 진행.
- Polyglot-ko 5.8B 모델 학습 A100 80GB 1대로 진행.
대표적인 Parameter efficient tuning 방법중 하나인 LoRA를 적용해 파인튜닝한 모델 가중치와 코드를 공개하고 있기 때문에, 고성능 컴퓨팅 리소스에 접근하기 어려운 여러 개인 연구자에게 굉장히 유용한 오픈소스 모델이기도 합니다.
KoAlpaca 개발자인 이준범 연구원의 KoAlpaca 개발기 Youtube - 언어모델에 관심이 있다면 한번쯤 보기를 권합니다.
Polyglot은 비영리 AI 연구단체인 EleutherAI에서 개발한 GPT-NeoX 기반의 multilingual pretrained 모델입니다.
한국어 데이터로 사전학습된 Polyglot-ko모델은 TUNiB에서 수집한 1.2TB의 한국어 데이터를 다양한 방식의 전처리를 거쳐 가공한 뒤 사전학습시켰습니다.(전처리 후 863GB 규모의 데이터) 자세한 학습과정에 대해서는 EleutherAI에서 Polyglot 개발 팀 리드를 맡으신 고현웅님의 발표자료에서 확인해보실 수 있습니다. (링크)
모델 평가 데이터셋으로는 한국어로 구성된 5개의 벤치마크 데이터셋이 들어있는 skt/kobest를 사용했습니다.
KoVicuna
KoVicuna는 Vicuna 모델을 한국어 데이터로 학습시킨 fine-tuned 모델입니다.
Vicuna 모델은 다음과 같은 Fine-tuned 모델입니다.
- LLaMA를 sharegpt 데이터셋(70k개)로 파인튜닝한 모델
- Alpaca와 유사하지만 다음과 같은 개선점을 가지고 있음
context length를 늘리고(512->2048), 이에 따른 메모리 요구량을 gradient checkpointing와 flashattention을 통해 최적화시킴
training loss를 multi-turn 대화를 고려하여 조정하고 fine-tune시 챗봇의 출력 결과만을 고려해 loss를 계산함
SkyPilot의 spot instance 도입을 통해 학습 비용을 절감함(spot instance란?)
KoVicuna는 Vicuna를 학습시킨 shareGPT 데이터셋을 deepL로 번역한 뒤 학습시킨 모델입니다.
LLaMA 2
메타는 LLaMA의 다음 버전인 LLaMA 2를 소개하면서, 다음과 같은 이야기를 했습니다.
"소프트웨어가 개방돼 있으면 더 많은 사람이 빠르게 문제를 찾아내고 식별하고 해결할 수 있어 안전과 보안을 향상시킬 수 있다." - 마크 저커버그(메타 CEO)
이처럼 메타는 LLaMA 2를 상업적으로도 이용 가능한 오픈 소스로 세상에 공개했습니다. 이 점이 LLaMA 2의 차별적인 강점으로 꼽히고 있죠. 이어서 경량화가 있습니다. Llama 2는 매개변수 규모에 따라 세 가지 모델(70억 개, 130억 개, 700억 개)로 제공되는데요. 거대 컴퓨팅 자원을 갖출 수 없는 신생 기업이나 개발자도 적절한 모델을 선택해 연구 및 상업적 활용을 가능하도록 했어요. AI 윤리와 책임성(Responsible AI)에 대해 사회적 관심이 높은만큼, 안전성과 유용성에 대한 보상 모델을 제작한 것 또한 임팩트 있는 점인 것 같아요.
Llama 2 특징
LLaMA 2는 기존 버전보다 40% 더 많은 2조 개의 토큰으로 학습되었어요(1.4T→2T 토큰).
컨텍스트 길이도 2배 증가한 4096으로 설정됐습니다(2K→4K).
매개변수 규모에 따라 세 가지 모델이 제공됩니다(Llama-2-7B, 13B, 70B).
안전성(Safety)과 유용성(Helpfulness)을 위한 두 보상 모델(Rewards Model, RM)을 만들었어요.
추론, 코딩, 지식 태스크를 포함하는 벤치마크 테스트에서 ‘MPT’, ‘Falcon’ 등의 타 LLM들보다 성능이 뛰어났어요.
무료로 상업적 이용이 가능합니다. 단, 월간 활성 사용자(MAU)가 7억 명⁺의 회사가 활용할 경우 메타와 별도의 라이센스 계약이 필요해요.
현재는 LLaMA 3도 나와있습니다. (2024/4/18)
덧붙이는 말
최근에는 보다 다양한 모델들이 나와있으나 개인적으로 직접 다뤄보지 못한 모델들이이라 발표에는 포함하지 않았습니다.
추후 개인적인 경험치가 추가되면 내용을 보강해보겠습니다. ^^
Refrences
