
https://www.youtube.com/watch?v=w_O4ybqu9Ro&list=PLFgS-xIWwNVX-zm4m6suWC9d7Ua9z7fuT&index=16
📌 정렬 알고리즘
| 정렬 알고리즘 | 정의 |
|---|---|
| 버블 (bubble) | 데이터의 인접 요소끼리 비교하고 swap 연산을 수행하여 정렬 |
| 선택 (selection) | 대상에서 가장 크거나 작은 데이터를 찾아가 선택을 반복하며 정렬 |
| 삽입 (insertion) | 대상을 선택해 정렬된 영역에서 선택 데이터의 적절한 위치를 찾아 삽입하면서 정렬 |
| 퀵 (quick) | pivot 값을 선정해 해당 값을 기준으로 정렬 |
| 병합 (merge) | 이미 정렬된 부분 집합들을 효율적으로 병합해 전체를 정렬하는 |
| 기수 (radix) | 데이터의 자릿수를 바탕으로 비교해 데이터를 정렬 |
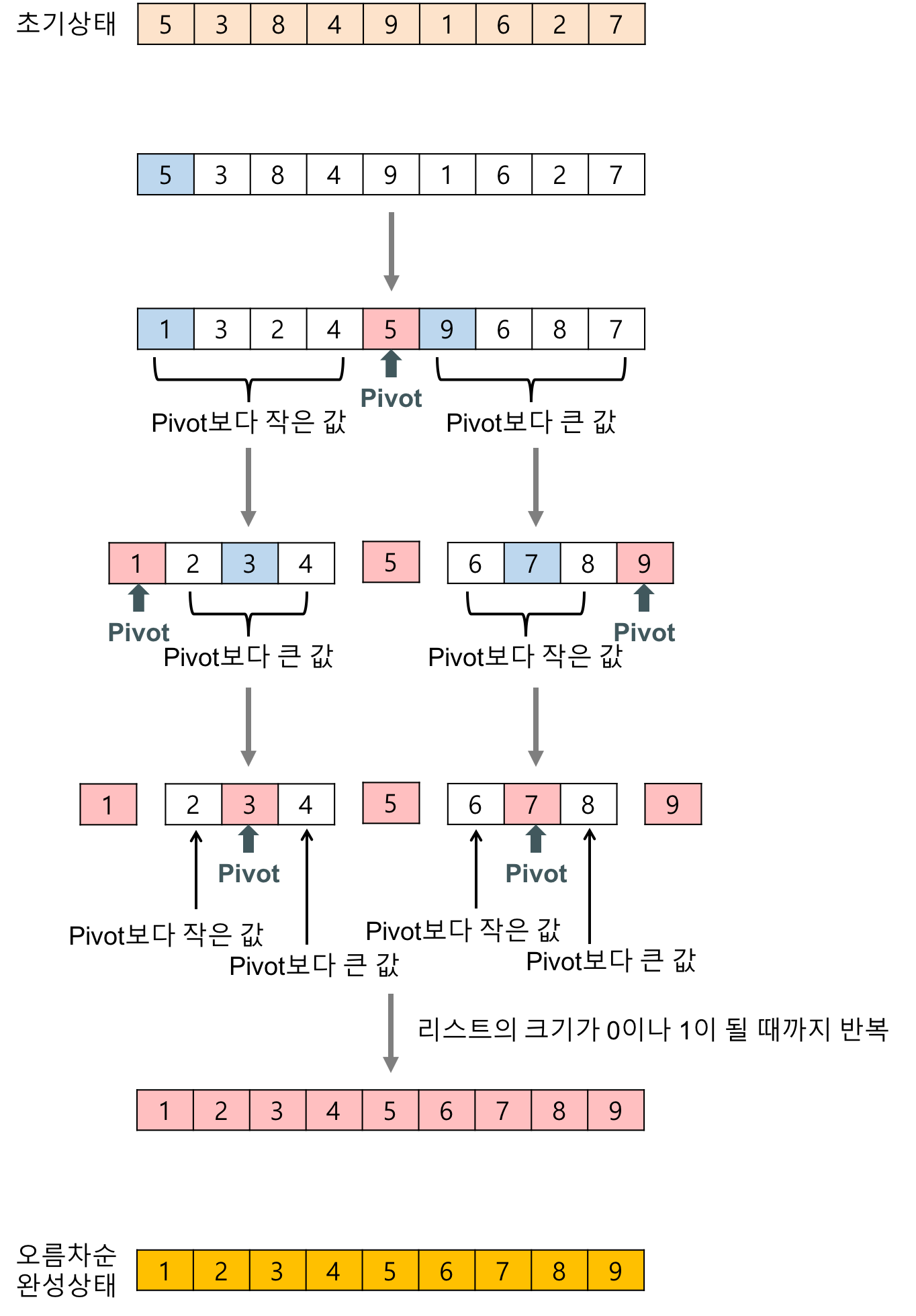
📌 퀵 정렬
- 기준값을 설정해 해당 값보다 작은 데이터와 큰 데이터로 분류하는 것을 반복해 정렬하는 알고리즘
- 기준값이 어떻게 선정되는지가 시간복잡도에 영향을 미침
- 평균 시간 복잡도는 O(nlogn)이며 최악의 시간복잡도는 O(n²)
◾ 퀵 핵심 이론
- pivot을 중심으로 데이터를 2개의 집합으로 나누면서 정렬
출처 : https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html
◾ 퀵 정렬 수행 방식
- 데이터를 분할하는 pivot 설정
- pivot을 기준으로 2개의 집합으로 분리
→ start가 가리키는 데이터가 pivot 보다 작으면 start를 오른쪽으로 1칸 이동
→ start가 가리키는 데이터가 pivot 보다 크면 start를 왼으로 1칸 이동
→ end가 가리키는 데이터가 pivot이 가리키는 데이터보다 크고 end가 가리키는 데이터가 pivot이 가리키는 데이터보다 작으면 start, end가 기리키는 데이터를 swap하고 start는 오른쪽 end는 왼쪽으로 1칸씩 이동 - start와 end가 만날 때 까지 반복
- start와 end가 만나면 만난 지점에서 가리키는 데이터와 pivot이 가리키는 데이터를 비교하여 pivot이 가리키는 데이터가 크면 만난 지점의 오른쪽에, 작으면 만난 지점의 왼쪽에 pivot이 가리키는 데이터를삽입
- 분리집합에서 각각 다시 pivot 선정, 분리집합이 1개 이하가 될 때까지 반복
