1. Replication
1-1. Replication이란?
"데이터 복제는 조직 내에서 데이터의 가용성, 신뢰성 및 내구성을 보장하기 위한 방법으로, 동일한 데이터의 여러 복사본을 다른 위치에 생성하고 유지하는 과정입니다."
데이터베이스 리플리케이션(Replication)은 실시간 복제본 데이터베이스 서버를 운용하는 것을 의미한다. 기준이 되는 서버를 마스터 서버라 하고, 마스터 서버와 동일한 내용을 갖는 또 다른 서버를 ‘리플리카(Replica)’라 한다.
어플리케이션은 데이터베이스에 SQL 명령을 보내 데이터를 삽입/변경/삭제하게 되는데, 마스터 서버는 SQL 명령을 수신하면 그 SQL 명령을 리플리카 서버에도 똑같이 보낸다. 이렇게 되면 마스터 서버와 리플리카 서버의 데이터가 동일한 상태로 유지된다.
1-2. Replication의 목적
데이터베이스 리플리케이션의 목적은 크게 실시간 Data 백업과 부하 분산으로 볼 수 있다.
Data의 백업
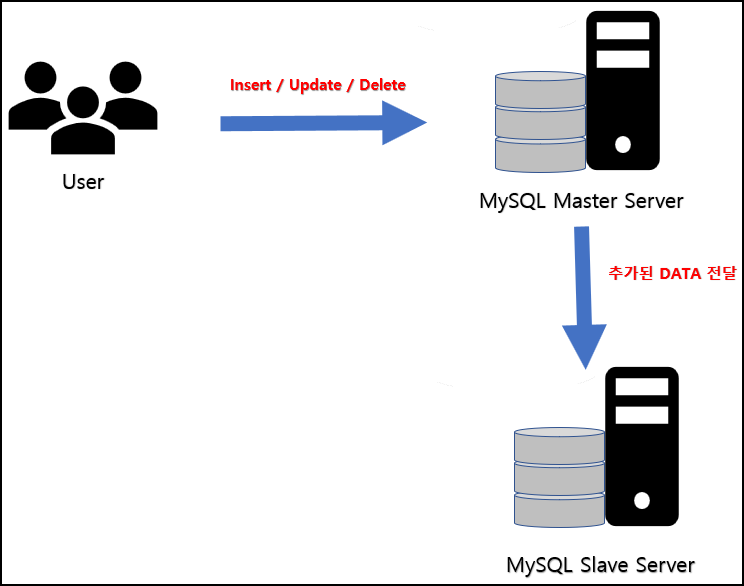
Master 서버에 DBMS의 INSERT/UPDATE/DELETE가 생기면 Slave 서버에 변경된 데이터를 전달하게 된다. 이러한 과정으로 데이터의 백업을 할수 있으며, Master 서버의 장애가 생겼을 경우 Slave 서버로 변경하여 사용할 수 있다.
부하 분산
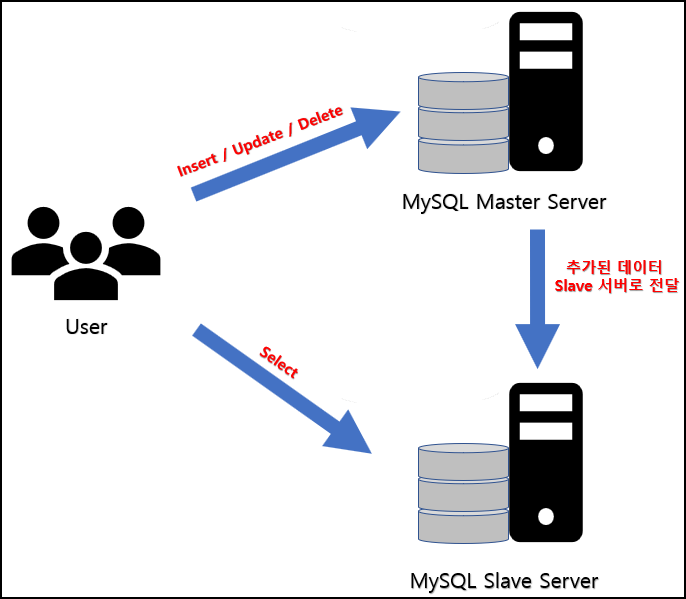
Master 서버를 INSERT/UPDATE/DELETE를 사용하는 서버로 사용하고, Slave 서버를 데이터를 읽는 용도로 사용하게 되면 DBMS의 부하를 분산하는 용도로 사용할 수 있다.
이외에도 분석용 쿼리들을 실행하기 위한 리플리카 서버를 구축하는 데이터 분석용 목적, 어플리케이션 서버와 DB 서버가 서로 떨어져 있는 경우 두 서버 간 통신 시간이 거리에 비례해 늘어나 서비스 응답 속도에도 영향을 끼치므로 어플리케이션 서버 위치에 리플리카 서버를 구축함으로써 응답 속도를 개선하는 데이터의 지리적 분산 목적 등이 있다.
2. Replication Architecture
MySQL에서 복제 동기화가 처리되는 전반적인 과정은 다음과 같다.
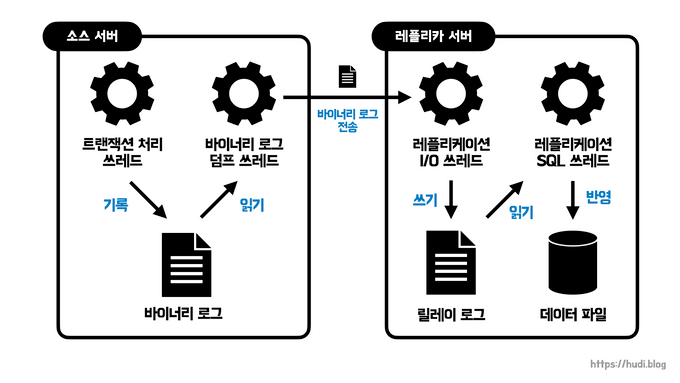
- 바이너리 로그: MySQL 서버에서 발생하는 모든 변경 사항의 기록
- 릴레이 로그: 리플리카 서버에서 소스 서버의 바이너리 로그를 읽어 들여 따로 로컬 디스크에 저장 해둔 파일
MySQL의 복제는 세 개의 스레드에 의해 작동한다. 스레드 하나는 소스 서버에 존재하고, 나머지 두 개는 리플리카 서버에 존재한다.
-
바이너리 로그 덤프 스레드: 바이너리 로그의 내용을 소스 서버에서 리플리카 서버로 전송한다. 리플리카 서버로 보낼 각 이벤트를 읽을 때 일시적으로 바이너리 로그에 잠금을 수행하며, 이벤트를 읽고난 후에 잠금을 해제한다.
-
리플리케이션 I/O 스레드: 복제가 시작되면 생성되어 소스 서버의 바이너리 로그 덤프 스레드로부터 바이너리 로그 이벤트를 가져와 로컬 서버의 파일로 저장한다. 복제가 멈추면 종료된다.
-
리플리케이션 SQL 스레드: I/O 스레드에 의해 작성된 릴레이 로그 파일의 이벤트들을 읽고 실행한다.
3. Replication Type
MySQL의 복제는 소스 서버의 바이너리 로그에 기록된 변경 내역들을 식별하는 방식에 따라 바이너리 로그 파일 위치 기반 복제와 글로벌 트랜잭션 ID 기반 복제로 나뉜다.
각 방식의 동작원리를 살펴보자.
3-1. 바이너리 로그 파일 위치 기반 복제
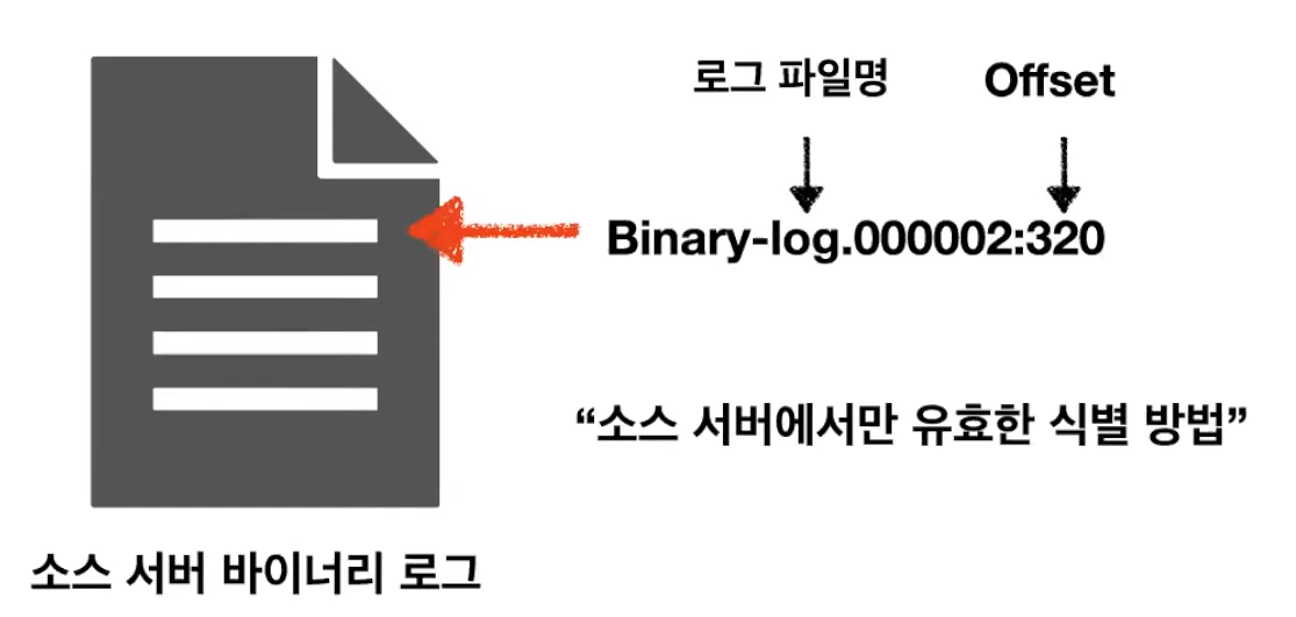
바이너리 로그 파일 위치 기반 복제는 MySQL에 복제 기능이 처음 도입됐을 때부터 제공된 방식으로, 리플리카 서버에서 소스 서버의 바이너리 로그 파일명과 파일 내에서의 위치로 개별 바이너리 로그 이벤트를 식별해서 복제가 진행되는 형태를 말한다.
이 방식은 다음과 같은 단점이 존재한다.
-
소스 서버에서만 유효한 식별 방식이라는 단점이 존재한다.
-
소스 서버에 문제가 생겨 다른 리플리카 서버가 소스 서버로 승격이 되면, 이 복제에 참여하는 다른 데이터베이스 서버들은 이 위치를 다시 찾아야 하기 때문에 복구에 시간이 걸린다.
-
동일한 이벤트가 레플리카 서버에서도 동일한 파일명의 동일한 위치에 저장된다는 보장이 없다.
-
이로 인해 복제의 토폴로지 변경이 어려워 복제를 이용한 장애 복구가 어렵다.
MySQL 5.6 버전부터는 이러한 단점을 해결하기 위해 글로벌 트랜젝션 아이디 기반 복제를 기본 복제 방식으로 사용하고 있다.
3-2. 글로벌 트랜잭션 아이디(GTID) 기반 복제
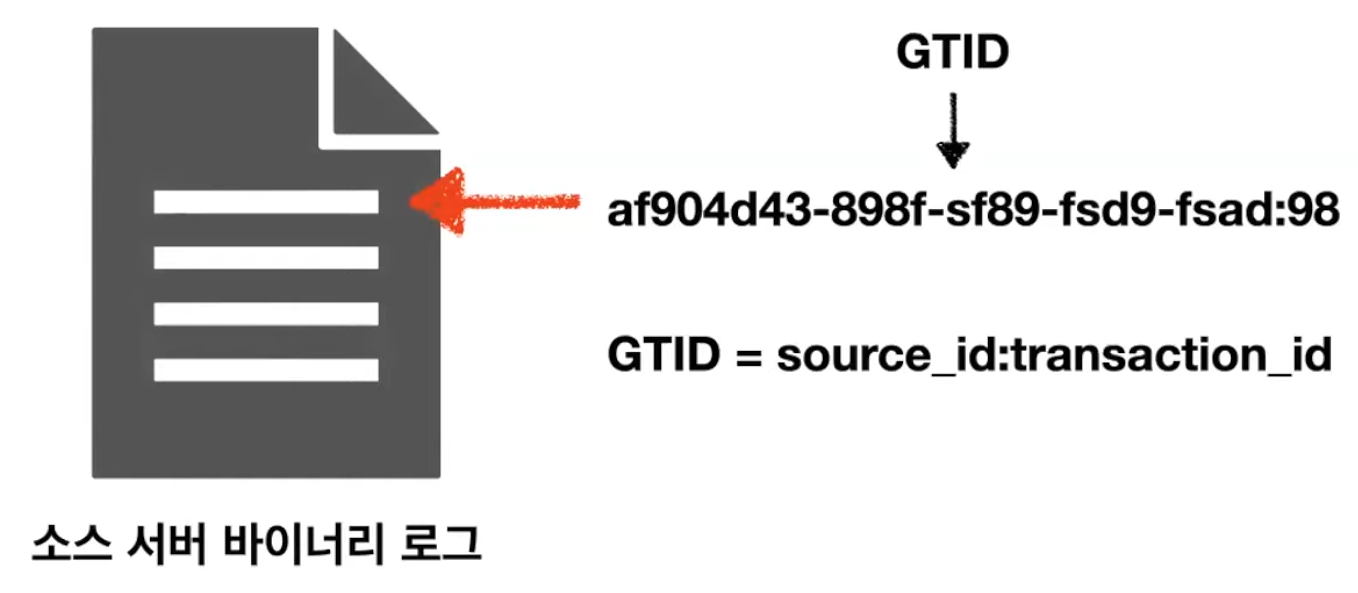
글로벌 트랜잭션 아이디 기반 복제는 복제에 참여한 전체 MySQL 서버들에서 고유하도록 각 이벤트에 부여된 식별 값인 GTID를 기반으로 복제가 진행되는 형태다. 이 값들은 모두 동일하기 때문에 동일한 이벤트에 대해서 동일한 글로벌 트랜젝션만 읽어오면 반영할 수 있다.
4. Replication Data Format
바이너리 로그에 이벤트가 어떤 포맷으로 기록되는지는 복제가 처리되는 과정에 영향을 준다.
MySQL에서는 다음과 같은 두 종류의 바이너리 로그 포맷을 제공한다.
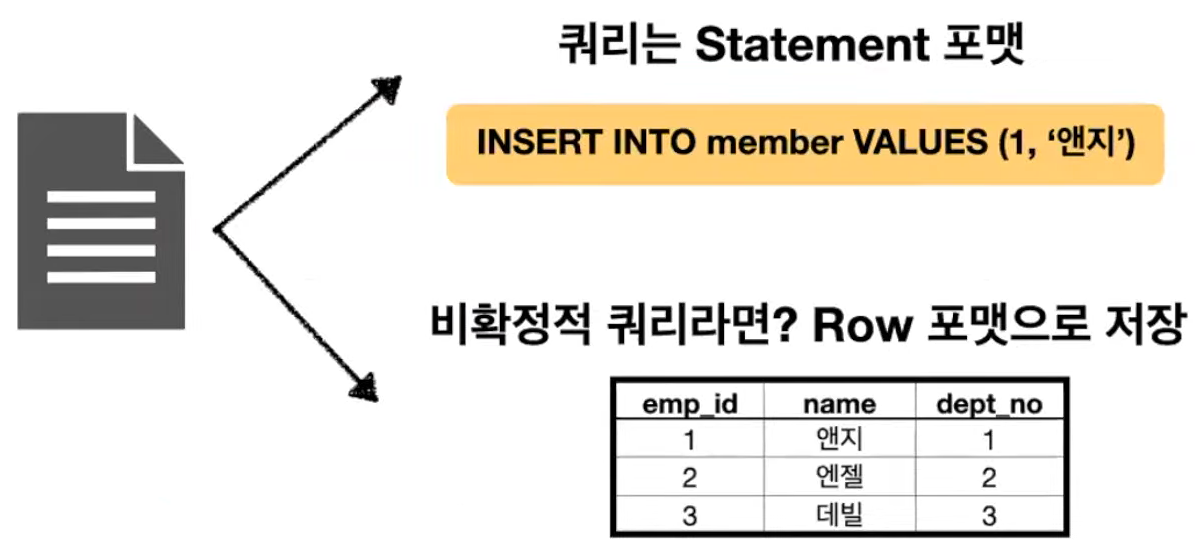
- Statement 방식: 실행된 SQL문을 바이너리 로그에 기록
- Row 방식: 변경된 데이터 자체를 기록
사용자는 binlong_format 시스템 변수를 통해 이 두 가지 종류 중 하나로 설정하거나 혼합된 형태로 사용할 수 있다.
각 포맷 방식에 대해 살펴보자.
4-1. Statement 기반 바이너리 로그 포맷

Statement 기반 바이너리 로그 포맷은 변경 이벤트에 대해 이벤트를 발생시킨 SQL문을 바이너리 로그에 기록하는 방식이다.
장점
- 저장 공간에 대한 부담 감소
- 빠른 처리 가능
단점
- 비확정적 처리 쿼리의 경우 데이터 동기화 문제 발생 (실행할 때마다 결과값이 달라지는 쿼리의 경우 데이터 동기화 문제가 발생할 수 있다.)
EX) DELETE, UPDATE 쿼리에서의 ORDER BY절 없이 LIMIT 사용 - Row 포맷 방식보다 데이터에 락을 더 많이 건다.
- 하나의 트랙잭션 내에서도 각 쿼리가 실행되는 시점마다 데이터 스냅샷이 달라질 수 있어 트랜잭션 격리 수준이 REPEATABLE-READ 이상만 가능하다.
이러한 단점들을 해결하기 위해 MySQL 5.7.7 버전부터는 Row기반 바이너르 로그 포맷을 기본으로 사용하고 있다.
4-2. Row 기반 바이너리 로그 포맷
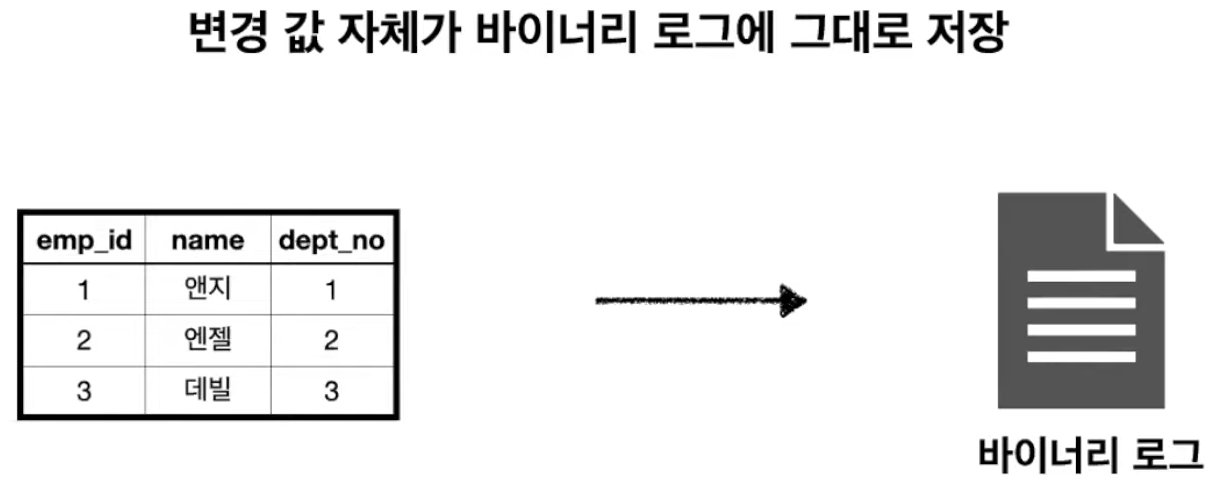
Row 기반 바이너리 로그 포맷 방식은 MySQL 서버에서 데이터 변경이 발생했을 때 변경된 값 자체가 바이너리 로그에 기록되는 방식이다.
장점
- 모든 트랜젝션 격리 수준에서 사용 가능
단점
- 데이터를 많이 변경하는 SQL문이 실행될 경우 바이너리 로그 파일 크기가 커질수 있다.
- 어떤 쿼리들이 넘어왔는지 육안으로 확인 불가능
4-3. Mixed 포맷
MySQL 서버가 두 가지 바이너리 로그 포맷을 혼합해서 사용하도록 설정할 수 있다.
5. Replication Synchronization
MySQL에서는 소스 서버와 레플리카 서버 간의 복제 동기화에 대해 다음과 같은 두 가지 방식을 제공한다.
- 비동기 복제(Asynchoronous Replication)
- 반동기 복제(Semi-synchronous Replication)
각 방식의 동작 방식과 장단점에 대해 살펴보자.
5-1. Asynchoronous Replication
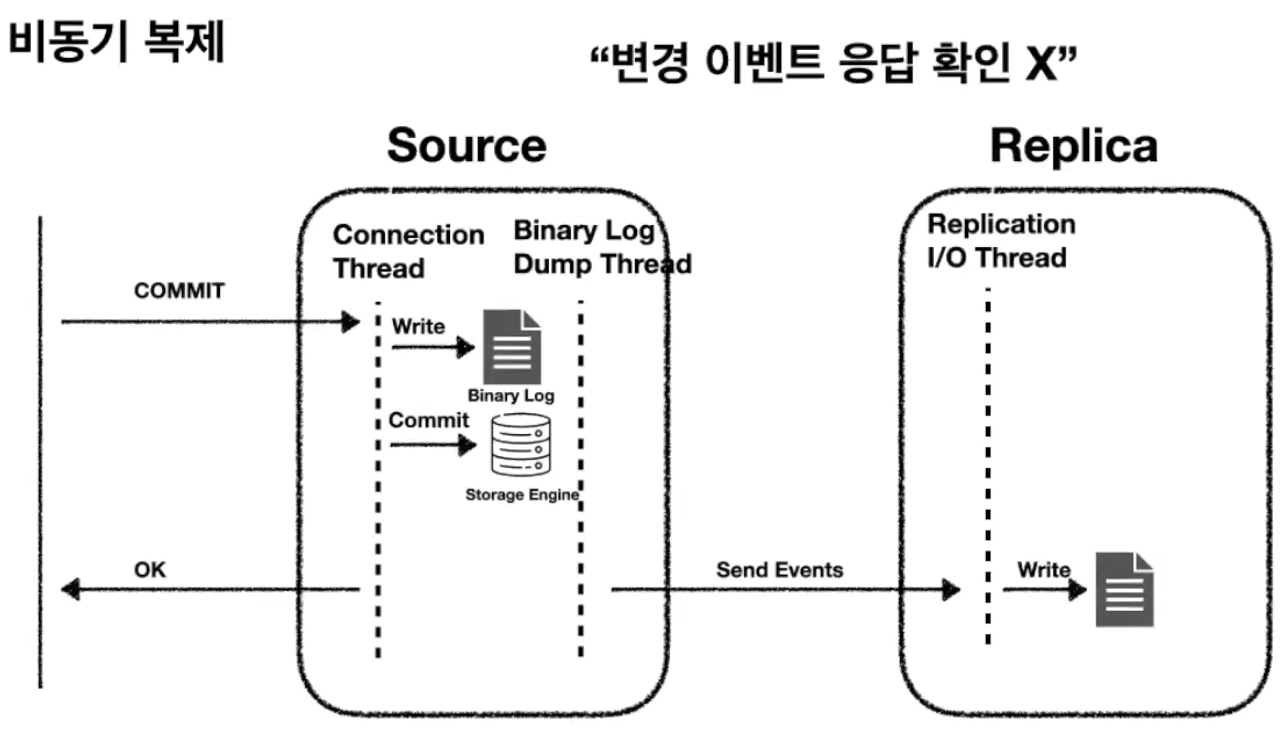
비동기 복제는 MySQL의 기본적 동작 방식으로 소스 서버가 자신과 복제 연결된 리플리카 서버에서 변경 이벤트가 정상적으로 전달되어 적용되었는지를 확인하지 않는 방식이다.
장점
- 빠른 트랜잭션 처리 성능
- 리플리카 서버에 문제가 생겨도 소스 서버에는 영향 X
- 여러 리플리카 서버가 연결되도 소스 서버에 큰 성능 저하가 없으므로 리플리카 서버를 확장해서 읽기 트래픽을 분산하는 용도로 제격
- 리플리카 서버에서 무거운 쿼리를 실행하여도 소스 서버에 영향이 없어서 분석 용도로 적합
단점
- 소스 서버에 장애가 발생하면 트랜잭션이 리플리카 서버로 전송되지 않아 누락된 트랜잭션이 존재할 수 있다.
- 소스 서버 장애로 리플리카 서버가 소스 서버로 승격되면 누락된 트랜잭션을 직접 확인하고 수동으로 적용해야 한다.
5-2. Semi-synchoronous Replication
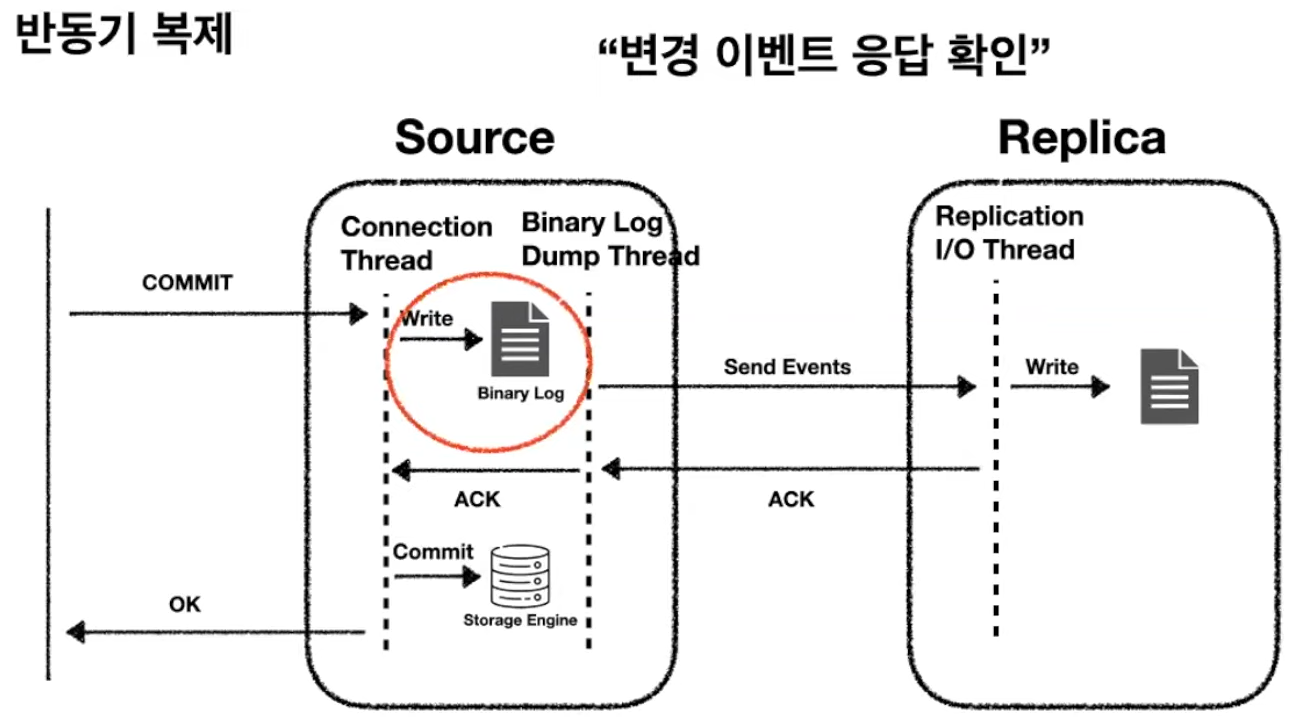
반동기 복제는 비동기 복제보다 좀 더 향상된 데이터 무결성을 제공하는 복제 동기화 방식이다.
반동기 복제에서 소스 서버는 리플리카 서버가 소스 서버로부터 전달받은 변경 이벤트를 릴레이 로그에 기록 후 응답(ACK)을 보내면 그때 트랜잭션을 완전히 커밋시키고 클라이언트에 결과를 반환한다.
반동기 복제 방식은 리플리카 서버에 전송됐음을 보장하지만, 실제로 복제된 트랜잭션이 리플리카 서버에 적용되는 것까지는 보장하지 않는다.
장점
- 반동기 복제는 기본 데이터베이스에 커밋하기 전에 하나 이상의 리플리카 서버가 트랜잭션 수신을 확인하도록 하여 비동기 복제에 비해 데이터 손실 위험을 줄인다.
- 반동기 복제는 트랜잭션을 커밋하기 전에 하나 이상의 리플리카 서버로부터 승인을 받아야 하므로 비동기 복제에 비해 데이터베이스 전체에서 더 나은 일관성을 유지하는 데 도움이 된다.
단점
- 비동기 방식보다 트랜잭션 처리 속도가 느리다.
- 리플리카 서버가 멀리 떨어져 있거나 네트워크 문제가 발생하는 경우 리플리카 서버의 승인을 기다려야 하기 때문에 기본 데이터베이스의 성능이 영향을 받을 수 있다.
6. Replication Topology
MySQL의 여러 복제 토폴로지를 살펴보자.
6-1. 싱글 레플리카 복제 구성
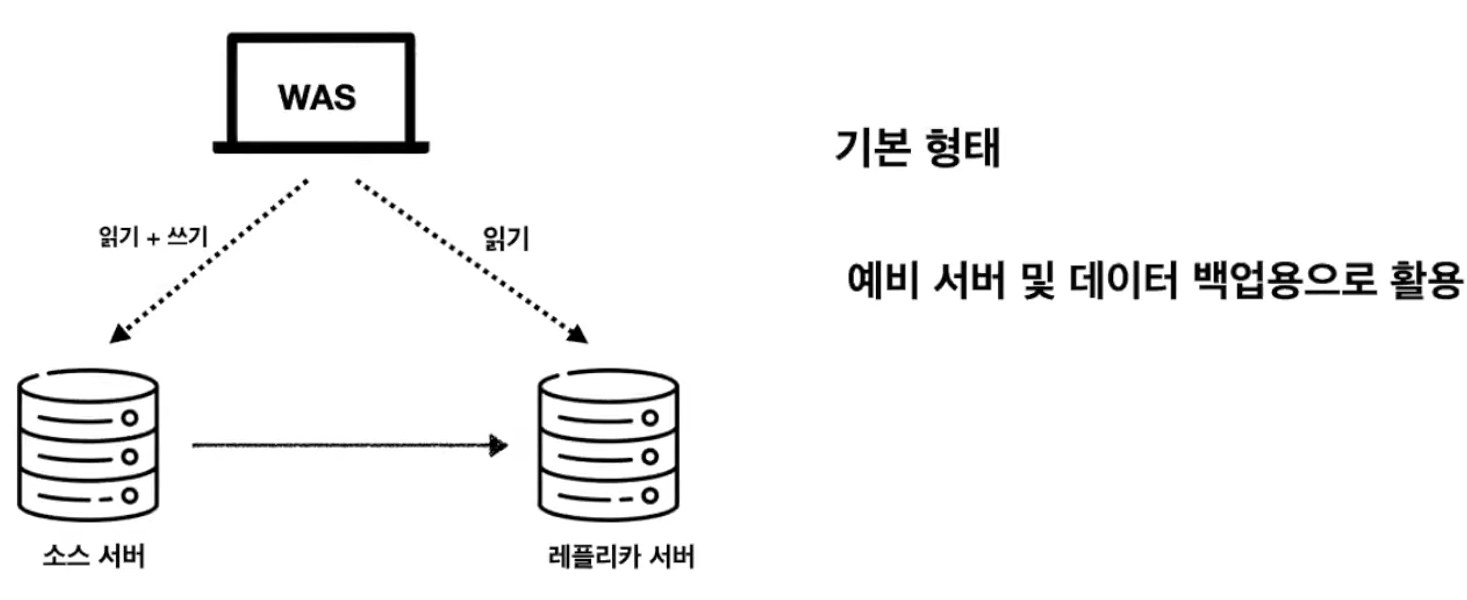
- 소스서버 한대와 리플리카 서버를 한대 두는 싱글 리플리카 방식
- 리플리카 서버는 예비 서버 및 데이터 백업 용으로 활용
6-2. 멀티 레플리카 복제 구성
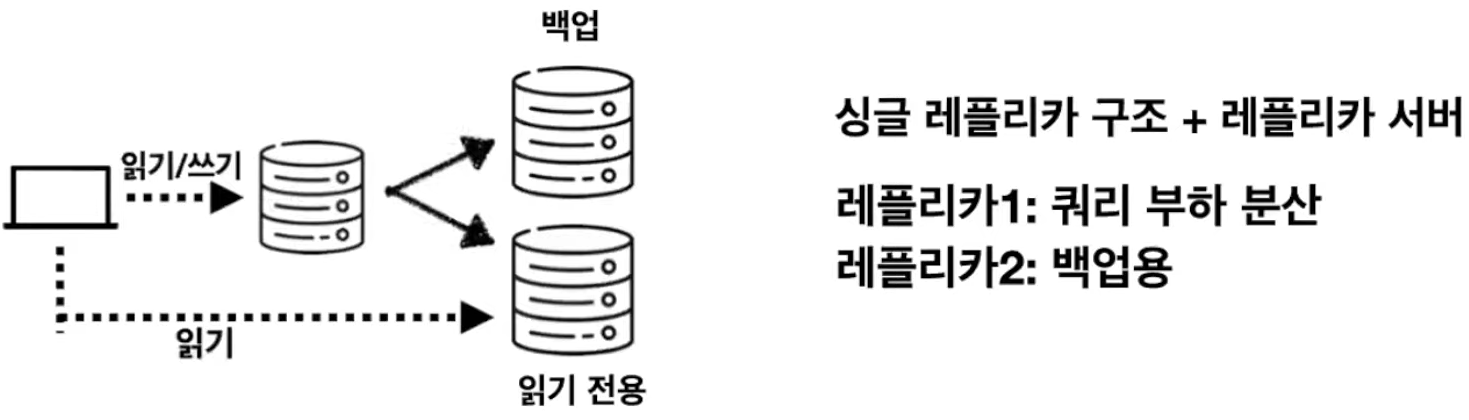
- 싱글 리플리카 구조에 리플리카 서버를 한대 더 준 멀티 리플리카 방식
- 백업 용 디비가 필요한 경우
- 읽기 요청이 많은 경우
- 배치나 통계, 분석 등의 여러 작업을 처리해야 하는 경우
6-3. 체인 복제 구성
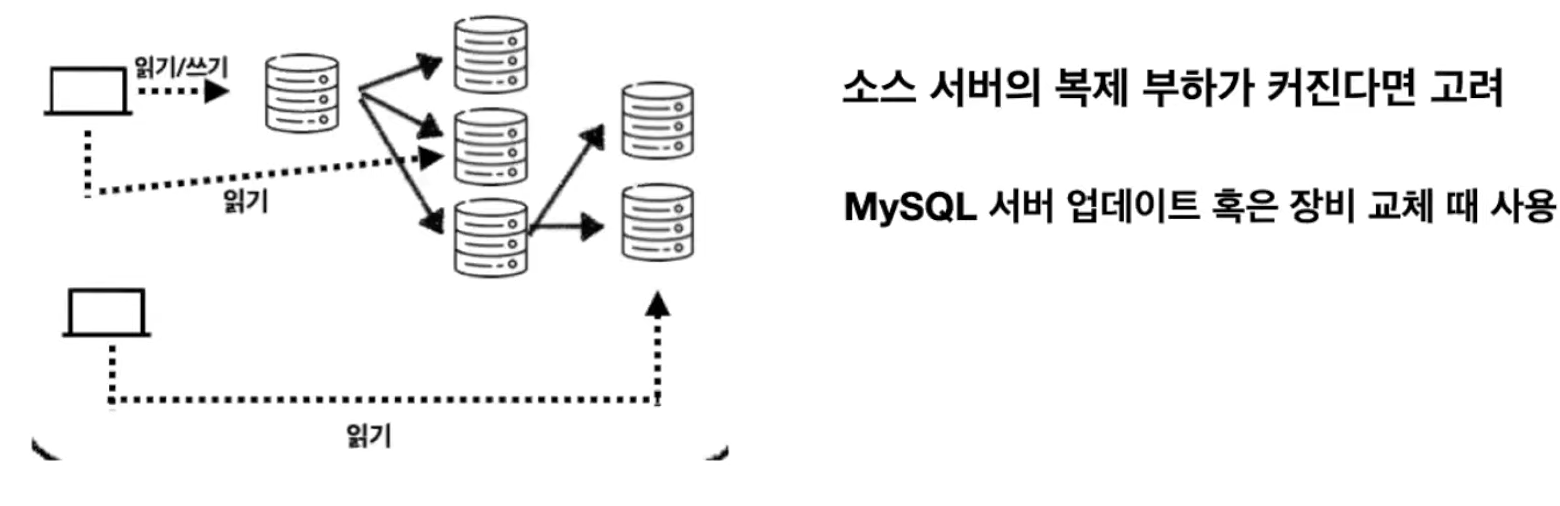
- 소스 서버에 연결된 리플리카 서버가 많다면 소스 서버에 복제부하가 커지게 된다. 이런 경우 다른 리플리카 서버를 소스 서버로 활용해 복제 부하를 분산시키는데 사용할 수 있다.
- 서버 업데이트 혹은 장비 교체 때도 체인 복제 구성을 사용할 수 있다.
6-4. 듀얼 소스 복제 구성
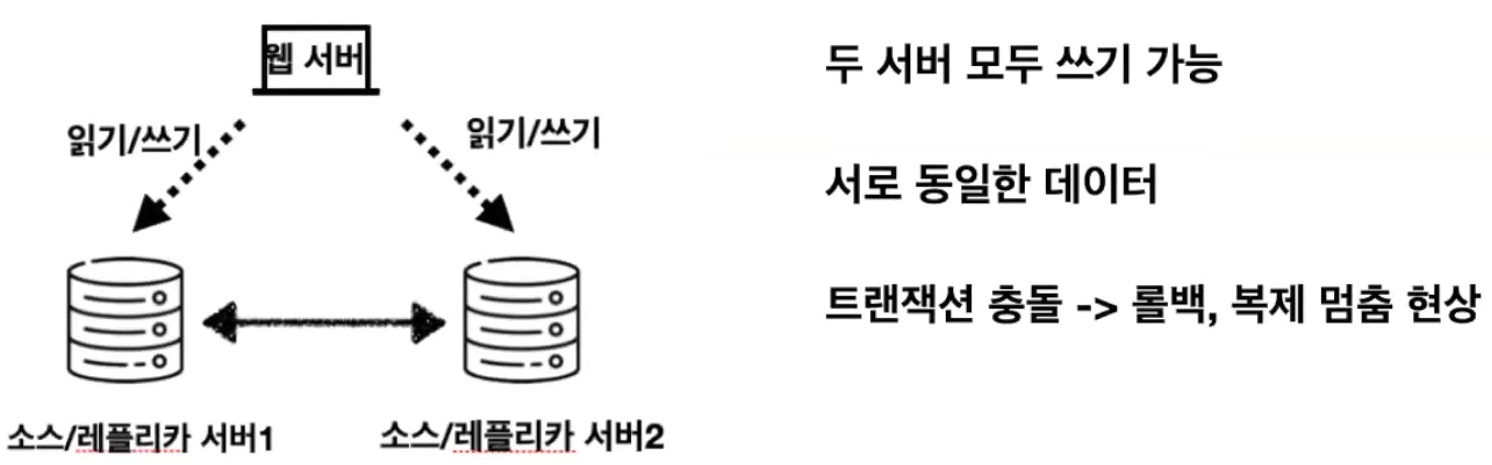
- 두 서버 모두 쓰기가 가능한 형태
- 두 서버 모두 서로 동일한 형태의 데이터를 가지고 있다.
- 한 서버에서 다른 서버로 바로 쓰기가 전환될 수 있는 환경이 필요한 경우 사용
- 트랜잭션 충돌이 일어날 경우 롤백, 복제 멈춤 현상이 일어나기 때문에 잘 사용되지 않는 토폴리지 이다.
6-5. 멀티 소스 복제 구성

- 리플리카 서버 한대에 소스 서버가 여러대 연결된 형태
- 소스서버에 흩어져 있는 데이터들을 한데 모아 데이터를 분석할 때 사용할 수 있다.
참고
우아한테크코스 테코톡 앤지의 DB Replication
Real MySQL 8.0 - 2
