데이터베이스는 적절한 설계가 이루어지지 않으면 성능 저하와 데이터 불일치 등의 문제를 야기할 수 있다. 이를 해결하기 위한 중요한 기술 중 하나가 바로 "데이터베이스 정규화"이다.
데이터베이스 정규화는 데이터를 효율적으로 구조화하여 중복을 최소화하고 데이터 일관성을 유지하는 과정이다. 이를 통해 데이터베이스의 성능을 최적화하고, 유지보수를 용이하게 만든다.
데이터베이스 정규화의 개념, 이점 및 주요 정규화 기법에 대해 살펴보자.
1. 정규화
1-1. 정규화란?
관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화(Normalization)라고 한다. 데이터베이스 정규화의 목표는 이상이 있는 관계를 재구성하여 작고 잘 조직된 관계를 생성하는 것에 있다.
정규화는 단계별로 제 1 정규화부터 제 6 정규화까지 존재한다.
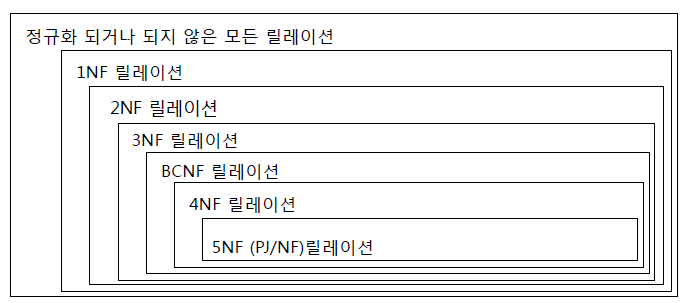
대부분의 경우에는 BCNF 정규화를 거치면 실질적인 이상 현상이 없어지기 때문에 BCNF 이상으로 정규화를 진행하는 경우는 드물다.
각 정규화를 좀 더 자세히 살펴보자.
이상 현상 종류
- 삽입 이상(Insertion Anomaly)
데이터 삽입 시 의도와 다른 값들도 삽입됨- 삭제 이상(Delete Anomaly)
데이터 삭제 시 의도와 다른 값들도 연쇄 삭제됨- 갱신 이상(Update Anomaly)
속성값 갱신 시 일부 튜플만 갱신되어 모순 발생
1-2. 제 1 정규형(1NF)
제1 정규화란 테이블의 컬럼이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것이다.
아래와 같은 이름과 수강과목 테이블이 존재하는 예시를 살펴보자.
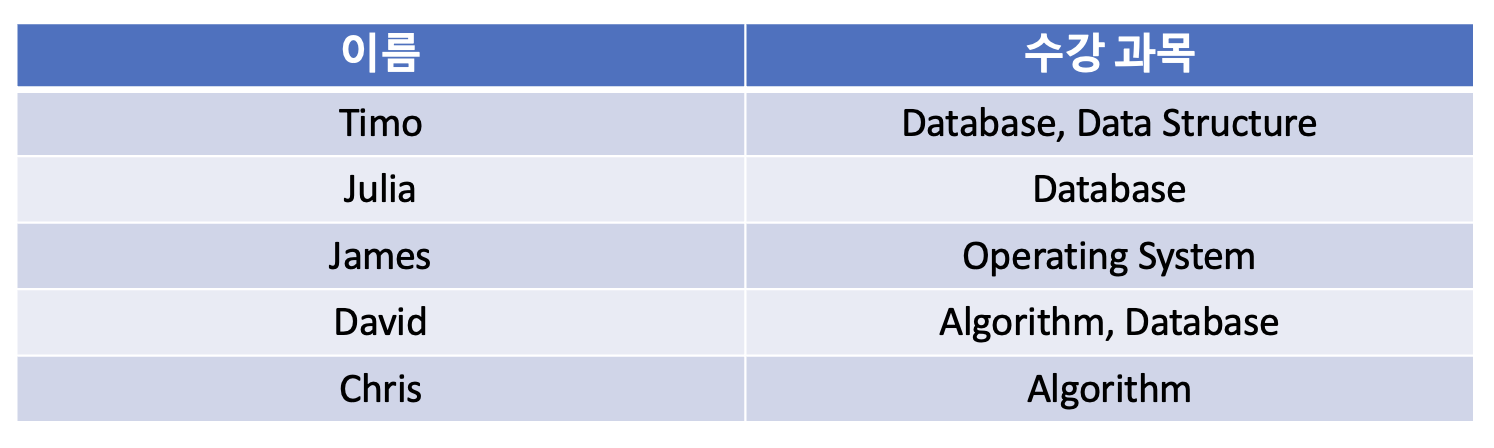
Timo와 David는 여러개의 수강과목을 가지고 있기에 제 1 정규형을 만족하지 않는다.
이 상태로 데이터가 계속 입력된다면 INSERT, UPDATE, DELETE 모든 상황에서 작업 중 반드시 데이터가 꼬이거나 오류가 발생하게 된다.
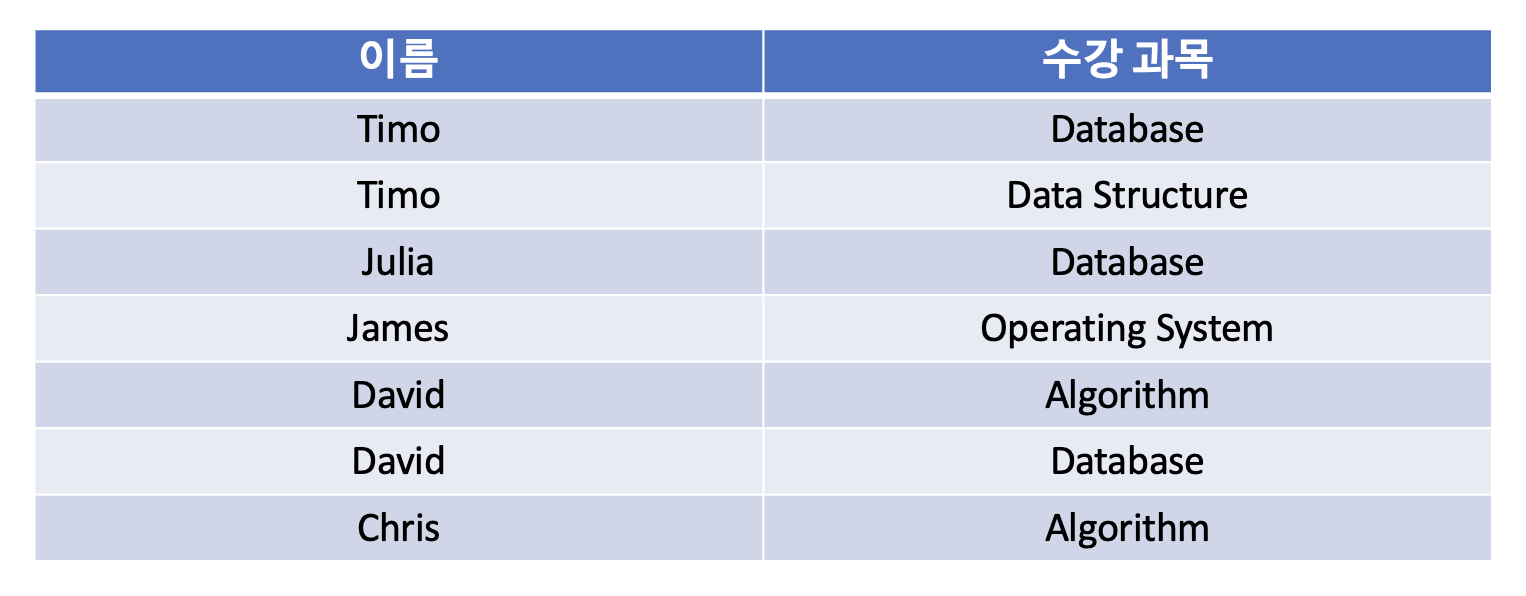
다음과 같이 제 1 정규화를 통해 분해할 수 있다.
1-3. 제 2 정규형(2NF)
제 2 정규화란 제 1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것이다.
함수 종속
X의 값을 알면 Y의 값을 바로 식별할 수 있고, X의 값에 Y의 값이 달라질 때, Y는 X에 함수적 종속이라고 한다.
완전 함수 종속
기본키의 부분집합이 결정자가 되어선 안된다.
아래와 같은 예시를 살펴보자.
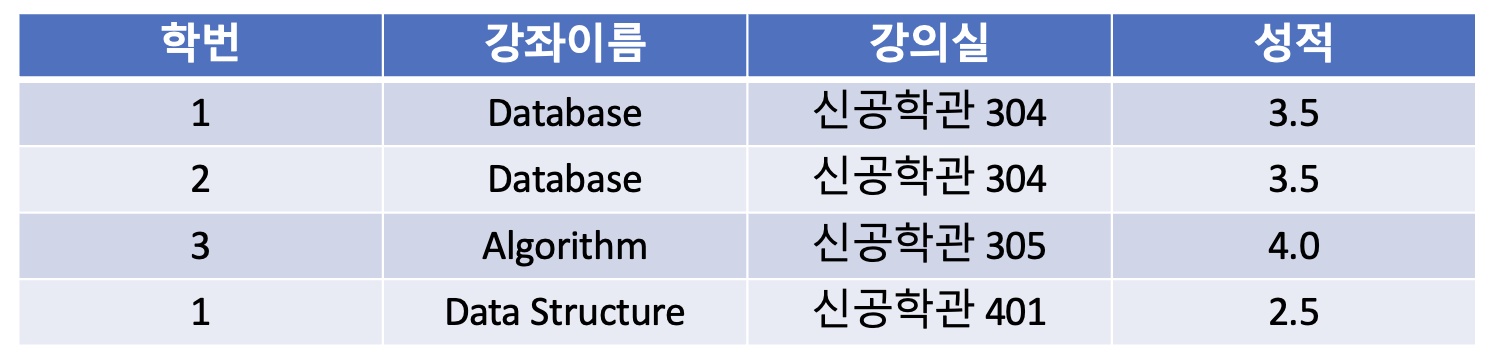
이 테이블의 기본키는 복합키로 (학번, 강좌이름)으로 이루어져 있다.
성적은 (학번, 강좌이름)으로 결정이 되는 반면에 강의실은 강좌이름으로만 결정이 된다.
즉, 기본키의 부분집합인 강좌이름이 강의실을 결정 짓는 결정자가 되었다.
위과 같은 경우 학번을 추가하지 않으면 새로운 강좌를 등록하지 못하는 문제가 생긴다.
또한, 강좌의 강의실 정보가 바뀌거나 삭제되면 학번에도 영향을 끼치는 문제가 발생한다.
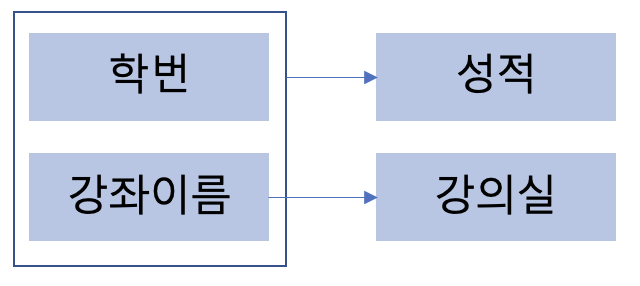
위의 테이블을 다음과 같이 제 2 정규화를 진행하여 분리할 수 있다.
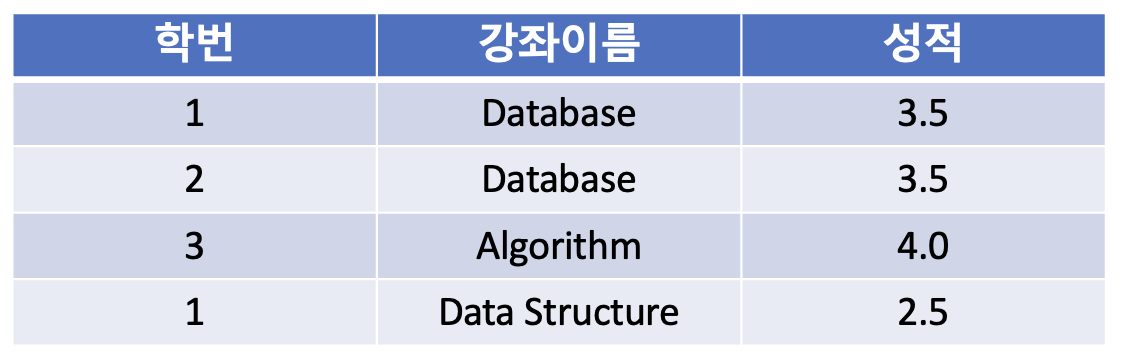
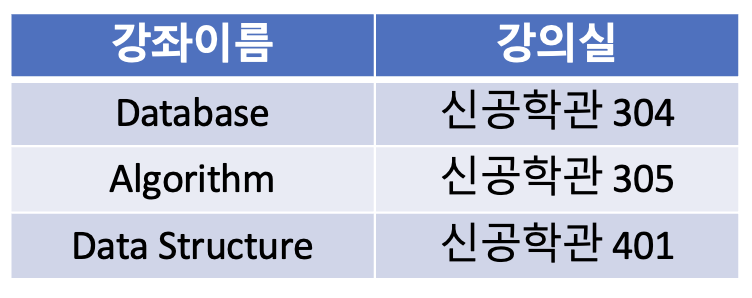

1-3. 제 3 정규형(3NF)
제3 정규화란 제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것이다.
이행적 종속
릴레이션에서 X, Y, Z라는 3 개의 속성이 있을 때 X → Y, Y → Z 이란 종속 관계가 있을 경우, X → Z가 성립될 때 이행적 함수 종속이라고 한다.
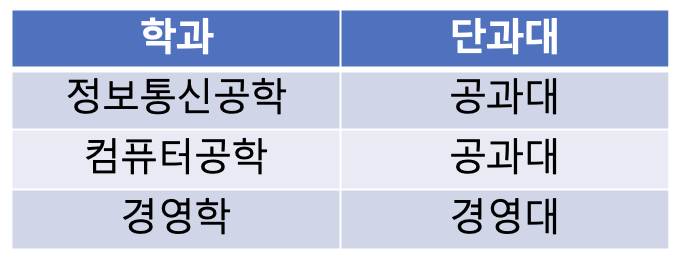
아래와 같은 예시를 살펴보자.


위의 테이블에서는 학번은 학과를 결정하고, 학과는 단과대를 결정하는 이행적 종속이 존재한다.
위와 같은 경우, 학과와 단과대가 중복으로 입력되는 문제가 발생한다.
위의 테이블을 제 3 정규화를 통해 분리할 수 있다.
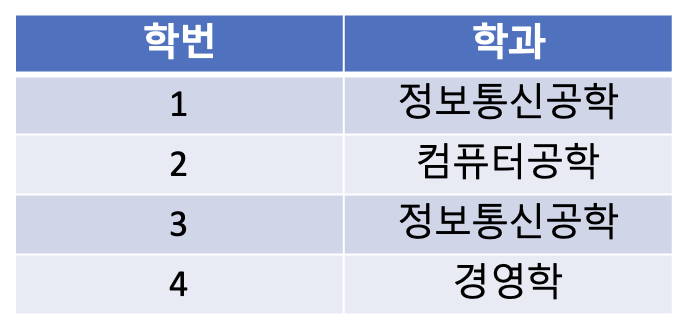
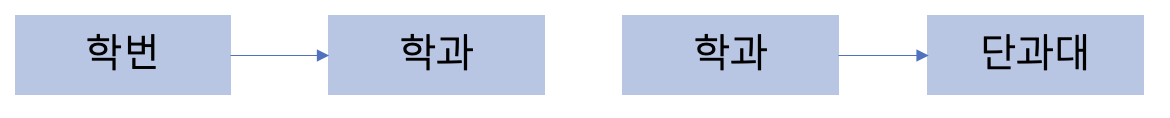
1-4. BCNF 정규형
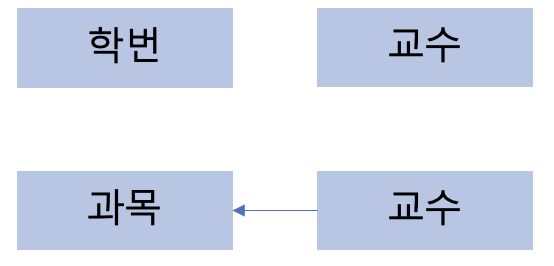
BCNF 정규화란 제3 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해하는 것이다.
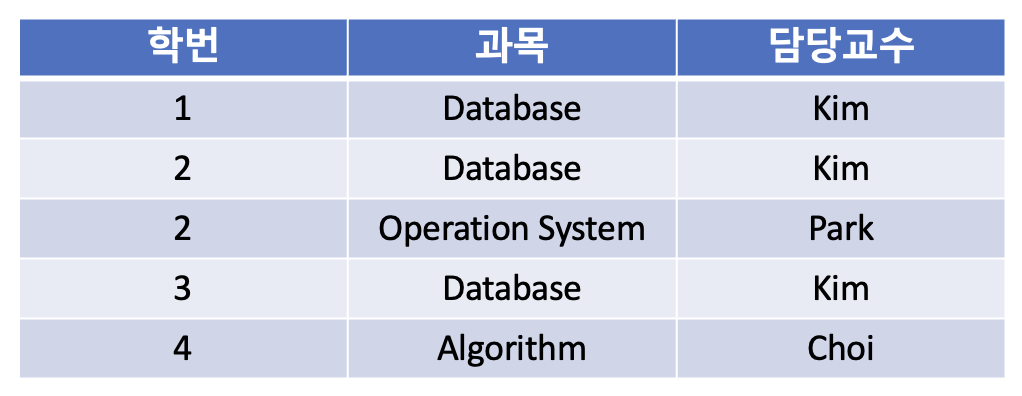
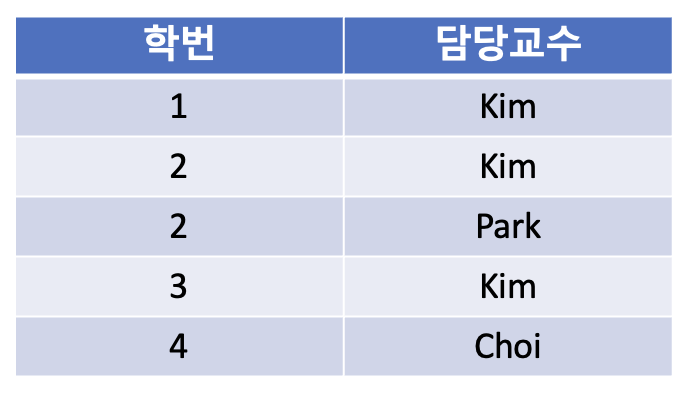
아래의 예시를 살펴보자.
제약사항
- 한 학생은 동일한 과목에 대해 한 교수에게만 수강 가능
- 각 교수는 하나의 과목만 담당
- 한 과목은 여러 교수가 담당 가능
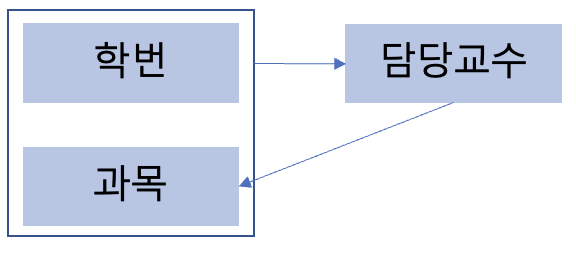
학번과 과목이 기본키로 담당 교수를 결정 짓고 있다. 담당교수 또한 과목을 결정 지을 수 있는 결정자이지만 후보키가 아니다.
위와 같은 경우, 과목과 담당교수의 중복이 발생하고, 갱신 이상이 생길 수 있다.
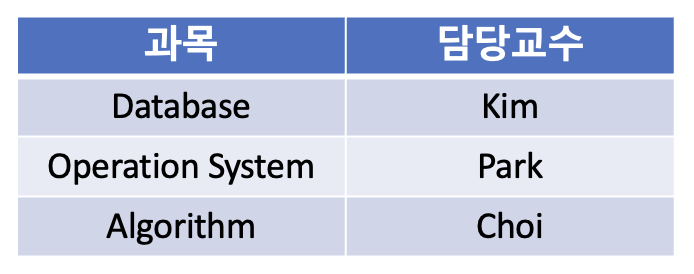
위의 테이블을 BCNF 정규화를 통해 분리할 수 있다.
2. 반정규화
2-1. 반정규화란?
- 데이터베이스의 성능 향상을 위하여, 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법이다.
- 반정규화는 조회(select) 속도를 향상시키지만, 데이터 모델의 유연성은 낮아진다.
다음과 같은 경우에 반정규화를 고려해볼 수 있다.
- 정규화에 충실하여 종속성, 활용성은 향상 되었지만 수행속도가 느려진 경우
- 다량의 범위를 자주 처리해야하는 경우
- 특정 범위의 데이터만 자주 처리하는 경우
- 요약/집계 정보가 자주 요구되는 경우
2-2. 반정규화 절차
- 반정규화 대상조사
- 범위처리빈도수 조사
- 대량의 범위 처리 조사
- 통계성 프로세스 조사
- 테이블 조인 개수
- 다른 방법유도 검토
- 뷰(VIEW) 테이블
- 클러스터링 적용
- 인텍스의 조정
- 응용 애플리케이션
- 반정규화 적용
- 테이블 반정규화
- 속성의 반정규화
- 관계의 반정규화
2-3. 반정규화 기법
테이블 반정규화
- 테이블 병합
-1:1 관계 테이블 병합 : 1:1 관계를 통합하여 성능향상
-1:M 관계 테이블 병합 : 1:M 관계를 통합하여 성능향상- 슈퍼/서브타입 테이블병합 : 슈퍼/서브 관계를 통합하여 성능향상
- 테이블 분할
- 수직분할 : 하나의 테이블의 속성을 분할하여 두 개 이상의 테이블로 분할
- 수평분할 : 하나의 테이블에 있는 값을 기준으로 테이블을 분할
- 테이블 추가
- 중복 테이블 추가 : 동일한 테이블 구조를 중복하여 원격조인을 제거
- 통계 테이블 추가 : SUM, AVG 등을 미리 수행하여 계산
- 이력 테이블 추가 : 마스터 테이블에서 자주 조회되는 레코드를 중복하여 테이블 추가
- 부분 테이블 추가 : 자주 이용하는 칼럼을 모아놓은 별도의 테이블 추가
- 속성 반정규화
- 중복 칼럼 추가 : 조인 감소를 위해 중복된 칼럼을 추가
- 파생 칼럼 추가 : 미리 값을 계산하여 칼럼에 보관
- 이력 테이블 칼럼 추가 : 대량의 이력 데이터를 처리할 때 기능성 칼럼(최근값 여부, 시작과 종료일자 등)을 추가
- PK에 의한 칼럼 추가 : 여러 칼럼으로 이루어진 PK를 가진 테이블을 조인할 경우 단순성을 위해서 인공키를 PK로 지정하고 활용
- 응용시스템 오작동을 위한 칼럼 추가 : 이전 데이터를 임시적으로 중복하여 보관
- 관계 반정규화
- 중복 관계 추가 : 여러 경로를 거쳐 조인 할 수 있지만, 성능 저하를 예방하기 위해 추가적인 관계를 맺음
참고
