ELK STACK 로그 모니터링 적용기
발단
공장 제어 기기 데이터 수집/모니터링/제어를 위한 서버를 구축하는 업무를 맡고 있다.
사내 IoT 테스트 서버였던 Node-Red 서버에서 express 서버로 마이그래이션이 종료되고
해당 서버에서 나오는 로그성 데이터를 수집/저장/모니터링 할 수 있는 솔루션이 필요하다는 요구사항이 백엔드 개발팀 내에서 발생하여 기술 스택 서칭 후 ELK를 활용하여 로그 수집부터 모니터링까지 하기로 결정하였다.
모니터링을 하고자 하는 목적의 경우 다음과 같다
- 서버에서 발생하는 에러 트래킹
이상 상황이 있을 경우 알람으로 이어져야 한다.- 로그 성 데이터 분석
현재 k6 라이브러리를 통해 부하 테스트 진행했는데, 자체 그라파나가 아닌 일원화된 솔루션에서 분석가능해야한다.- 다양한 서버에서 오는 다양한 데이터를 통합해서 수집할 수 있어야 한다.
전개
로그에 사용할 수 있는 솔루션 서칭
위 요구조건을 만족하기 위해 고려했던 기술 스택을 다음과 같았다
- express + winston + s3에서 데이터 단순 적재
- express + winston + fluentd + 모니터링 웹 자체 제작
- express + winston+ AWS openSearch
- express + winston + ELK STACK
이중 다음과 같은 상황이 주요 고민 요소 였다.
- 문제 상황에 대해서 경영진에 대한 설득이 필요하기에 시각화 툴은 필수라 생각했다
- 프론트 팀의 협조를 받을 수 없는 상황에서 모니터링 웹 자체 제작을 하기에는 배보다 배꼽이 큰 행위
- 회사에서 AWS를 사용하고 있으나, AWS를 계속 사용할 지 말 지에 대한 논의가 진행되고 있음.
- 다양한 서비스 환경이 예상(폐쇠된 Farm 형태, 오픈된 완전 솔루션 형태의 Farm 등) 사업 모델이 정해져 있지 않음.
- 그로인해 서버 아키텍쳐가 정확하게 확정이 되고 있지 않음.
- 다양한 기기와 센서가 추가될 가능성이 높기에 데이터에 대한 유동성이 높아야 하고, 구축 복잡성이 낮아야 한다.
따라서 유동성이 높으면서 자체적으로 조작을 할 수 있는 ELK를 활용하여 모니터링을 하기로 결정이 되었다.
- ELK를 사용하게 되면 데이터 정형화가 안된 상황에서도 모니터링을 도입할 수 있으며(물론, 향후 Index를 정하는 과정이 필요) 모니터링을 구성하기에도 적합.
- Filebeat라는 경량화된 수집 시스템이 존재
- 아주 잠깐이지만 사용을 해본 경험이 있으며
- 알람 등 지원하는 서비스가 많음
- 향후 다른 목적으로 사용을 할 수 있는(회사 내 솔루션 검색 등) 확장성이 있을 것이라 판단.
elk 버전
먼저 ELK를 사용하기에 앞서 다양한 ELK 버전 중 사용을 할 버전을 선택해야 한다.
현재 지원하고 있는 ELK 버전이 다양하여 선택하는 데 어려움이 있었다.
제일 처음 고민했던 것은 최신 버전이었는데, 보안 부분 등 이전 버전에서는 xpack에서 해주던 것을 자체 내장을 하여 사용할 수 있었기에 선정을 했다
하지만 ELK와 AWS의 라이센스 문제로 인해(정확하지는 않다) ELK의 오픈소스 라이센스가 복잡하게 나뉘게 되었고, 자체 사용이 아닌 솔루션으로 제공을 하게 되면 라이센스에 대한 문제가 발생한다는 사실로 인해 oss버전을 사용하기로 선정했다.
=> 향후 elk만으로 센서 데이터를 보여 줄 수 있는 가능성이 존재(프론트 팀의 퇴사로 인해..)
=> aws openSearch로 갈아탈 때, 호환되는 elk 버전은 oss 버전으로 해야만 가능
oss 버전을 사용하더라도 기본 기능 및 xpack의 시큐리티 기능은 오픈소스로 무료 이용이 가능했기에 최소 요구 사항은 만족한다고 판단했다.
현재 9버전이 나온 다는 소식이 있었고, 변동 사항이 많다는 정보를 들었기에, 향후 회사 지침이 정해지면 9 버전으로 마이그레이션을 할 각오로 7.10.2-oss 버전을 사용하기로 선택하였다.
로그에 필요한 데이터 정하기
로그를 할 정보는 다음과 같이 나누어 생각했다.
시스템
application 상태
1. 서버 시작 및 종료
시스템 종료 시
// NOTE node 종료
process.once('exit', code => {
// 정상 종료
if (code === 0) {
new Logger('warn', {
message: `Server is cloed by ${code} code within ${config.serverMode} Server Mode`,
instanceId: global.awsMetadata
? global.awsMetadata['instance-id']
: 'localhost',
});
return;
}
// 비정상 종료
new Logger('fatal', {
message: `Server is cloed by ${code} code within ${config.serverMode} Server Mode`,
instanceId: global.awsMetadata
? global.awsMetadata['instance-id']
: 'localhost',
});
});- 각 로그에서는 어디(서버/프로세/앱/EC2)에서 나온 정보인지 확인이 되어야 한다.
1. 일단 EC2를 구분하기 위해서 instance-id를 사용하기로 하였다.

Aws metaData 가져오기.
export const getAWSMetaData = async () => {
try {
const awsMetadataUrl = 'http://169.254.169.254/latest/meta-data/';
const awsMetadata = {};
const metadataPaths = (await (await fetch(awsMetadataUrl)).text()).split(
'\n',
);
for (const path of metadataPaths) {
const url = awsMetadataUrl + path;
const response = await fetch(url);
if (response.ok) {
const data = await response.text();
awsMetadata[path] = data;
}
}
return awsMetadata;
} catch (error) {
// 에러 핸들러
}
async function runServer(serverMode) {
const awsMetadata = await getAWSMetaData();
global.awsMetadata = awsMetadata;
};2. 프로세스 상태
1. 도커의 노드 상태
2. pm2 로그 활용
DB 상태
- 쿼리 상태 (Slow Log, Error Log)
- DB 동작 상태
네트워크 상태
- 네트워크 이상 탐지 로그
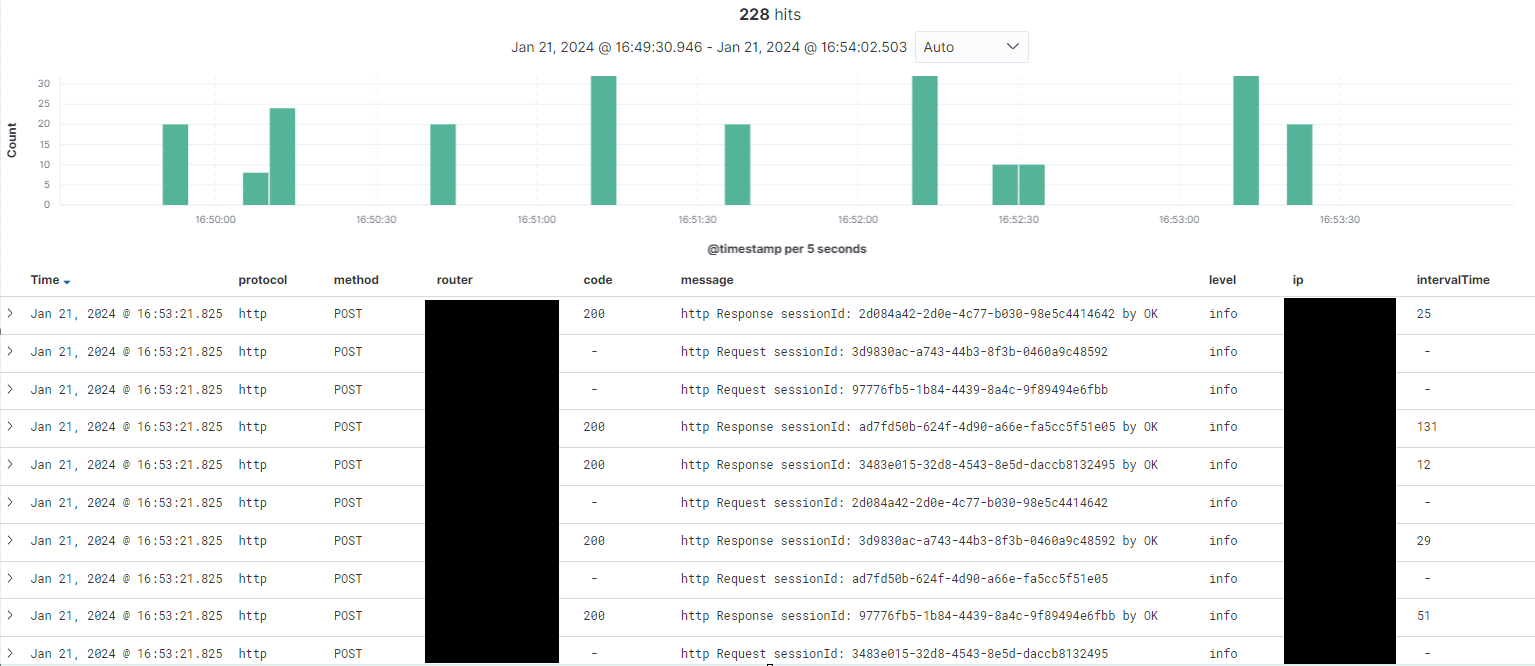
API 별 REQ와 RES
HTTP
request
- protocol
- sessionId
- 요청 ip
- time
- router
- method
- 요청 내용
- 어떤 user
- 어떤 EC2/프로세스/앱에서 나는 에러인지?
response
- protocol
- sessionId
- time
- interval time
- 응답 ip
- 응답 내용
- 성공
- level: INFO
- code : 200
message: 응답 내용 (?)
- 실패
- level: WARN/ERROR/FATAL
- warn/error 인지 에러
- fatal 인지 못한 에러
- code: error.code
- message: error.message
- level: WARN/ERROR/FATAL
- 성공
websocket
ERROR 상황
- AUTH 실패
- 현재 코드 상으로 소켓은 연결되나, Router로 넘어가지 않는 상태
- 어짜피 연결이 되었다면, Auth () ⇒ ws 연결 오류를 주는 게 좋을 것 같다
- 메시지를 전송하려는 데 , ws 연결이 되어 있지 않을 때,
- 정상적인 연결 해제가 아닌 데, 연결이 종료가 되었을 때
-
유휴시간이 지나서 자동적으로 종료
→ 프론트 엔드가 처리를 하도록 ⇒ 비정상적 종료
→ 유휴시간이 되기전에 ping/pong을 하는 로그 ⇒ pong이 오지 않는 에러의 경우, 연결이 해제 되었음을 로깅
-
Connection 상태 로그
http와 동일
MQTT
-
데이터 요청/응답 latency 로그 반영
-
mqtt publish/subscribe 토픽
-
mqtt 통신 상태 로그
인덱스 정보
인덱스의 경우 일단 간단하게 가져가기로 했다.
인덱스의 경우, RDBMS의 데이터베이스와 대응되는 개념으로
실제 프로덕션 환경에서는 인덱스 별로 template을 활용하여 type(table에 대응)을 지정해야 하기에 목적에 맡게 분리를 하는 것이 중요하다.
아래는 동적 템플릿을 사용하여 들어온 데이터를 저장할 때의 인덱스의 예시이다.
- 동적 템플릿을 사용하게 되면 스키마를 구성하지 않아도 된다는 장점이 있지만, keyword 자동 생성 등 불필요한 공간을 사용하게 된다.
- 인덱스는 보통 일단위로 구성을 하는 경우가 많은데,
만약 처음 들어오는 데이터가 잘못된 데이터일 경우, 인덱스 생성이 잘못되는 상황이 발생.
이후 잘 들어오는 스키마와 conflict가 나게 된다. - 또한 스키마를 동적으로 생성하기 위해 데이터 입력 시 마다 내부에서 자원을 소모하기에 입력 속도가 느려질 수 있다는 단점 또한 존재한다.
GET /{index}/_mapping
{
"인덱스 명" : {
"mappings" : {
"dynamic_templates" : [
{
"message_field" : {
"path_match" : "message",
"match_mapping_type" : "string",
"mapping" : {
"norms" : false,
"type" : "text"
}
}
},
{
"string_fields" : {
"match" : "*",
"match_mapping_type" : "string",
"mapping" : {
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
},
"norms" : false,
"type" : "text"
}
}
}
],
"properties" : {
"@timestamp" : {
"type" : "date"
},
"@version" : {
"type" : "keyword"
},
"IntervalTime" : {
"type" : "long"
},
"hostname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"norms" : false
},
...PUT /{인덱스 명}
{
"mappings": {
"properties": {
"category": {
"type": "keyword"
},
"pages": {
"type": "byte"
},
"title": {
"type": "text"
}
}
}
}PUT {인덱스 명}/_doc/1
{
"title": "Romeo and Juliet",
"author": "William Shakespeare",
"category": "Tragedies",
"publish_date": "1562-12-01T00:00:00",
"pages": 125
}아직 회사에서 데이터 정리가 정확하게 되지 않은 상황이라
현재는 동적 템플릿을 활용하여 스키마리스로 가도록 조치했다.
만약 필요한 것이 있다면
logstash의 filter 옵션을 통해 수정하기로 했다.
향후 로그가 다양해졌을 때, 스키마 템플릿을 활용하고자 한다.
- dev/prod는 develop환경인지 prod 환경인지를 나타냄
- 로그 남기는 주체
- 로그가 어떤 곳에서 발생한 것인지
- server(serverName/code/appName) 혹은 DB(DB 명, DB 고유 ID) 혹은 (IoT 기기→ ThingName)
서버의 구성은 다음과 같다.

- filebeat를 활용하여 express서버에서 winston으로 수집한 log를 logstash 서버로 전송(인증서로 ssl 적용)
- logstash에서 .conf 에서 설정된 대로 데이터 수집 및 가공
- elasticsearch에서 해당 데이터를 인덱싱하고 적재
현재 프로젝트에서는 샤딩과 레플리카를 위한 최소 요구치인 3개의 node를 사용
<레플리카가 유지되기 위한 최소 요구치, master, node1, node2> - kibana를 활용하여 데이터 모니터링
위기
- 스키마 생성 실패
1. 동적 템플릿을 사용하고 있기에 초기 데이터가 잘못 들어올 시 이후 데이터가 들어오지 못하는 문제가 발생
2. kibana Index Management의 Health를 보게 되면 특정 property에서 conflict가 나는 것을 확인
3. 해결을 위해서는- 스키마를 생성해서 스키마에 맞는 데이터만 들어오도록 하기
- logstash 사용 시 filter에서 문제가 되는 데이터의 타입을 동적으로 지정하도록 조치
- conflict가 되는 인덱스 삭제 후 다시 쌓기
=> 하지만 2번과 3번의 경우, 근본적인 해결 방안이 아님
- 노드 클러스터를 활용하지 못하는 문제 발생
uncaught exception in thread [main]
java.lang.IllegalStateException: node does not have the data role but has shard data
- cluster에는 master, node1, node2 3개의 노드가 있는데, node1,node2에 데이터가 쌓이지 않고 master에 데이터가 몰아서 쌓이는 현상 발생
- 원래라면 master는 node 상태 체크 등 다른 node를 관리하는 역할이어야 하는데 데이터가 쌓이고 있었음
- 기존 설정에서 node.master: true라는 설정으로 명확히 할당하지 않았기에 생겼던 문제
- cluster.initial_master_nodes: "master", node.master: true
node.data: false라고 설정으로 하고 "elasticsearch-node repurpose" 명령어 실행 샤드 내의 데이터 clean up완료
이후 분할하여 데이터 저장하는 것을 확인
- 알람 기능 사용
oss 버전에서는 alarm 기능은 xpack을 사용하여 알람을 사용해야 함.
절정
- 적들의 침공
참고2
어느날 쌓여있던 index들이 모두 삭제 되었던 현상이 발생
인덱스 목록을 살펴보니 해당 readme 인덱스가 있어고 내용은 아래와 같았다.
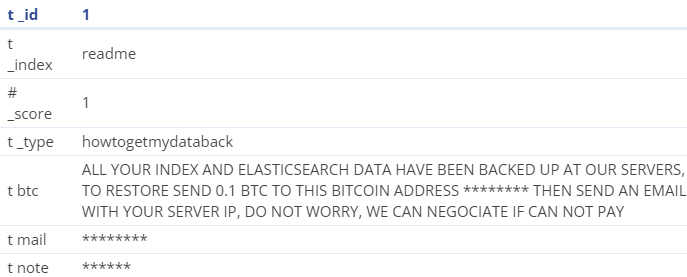
???:응 니꺼 털었으니 찾으려면 돈줘
응 그거 테스트 데이터야 마음껏 가져
해당 상황이 발생한 원인은 8 버전에서 당연히 해주던 auth 기능을 7.10.2 버전으로 변경을 했을 때, 설정해주지 않았기 때문이었다.
테스트 중이기에 설정을 하지 않은 것이었지만 실제로 이런 상황이 있다보니 보안에 신경을 쓰지 않을 수 없었다.
그래서 원래 하려했던 auth 뿐 아니라, filbeat와 elk 사이에 ssl까지 적용하여 구성을 하였다.
- 인증서 폴더 경로에 ca.crt를 위한 Dockerfile 및 instance.yml파일 생성
- logstash.crt, logstash.key를 위해 instance.yml에 logstash추가
- 인증서 폴더 경로에 crt생성을 위한 entrypoint.sh파일 생성
- docker-compose에 crt생성을 위한 인증서 서비스 추가
- logstash서비스에 인증서 폴더경로 logstash컨테이너 볼륨에 마운트
- logstash.conf의 input beats에서 ssl설정
// logstash
beats {
port => 5044
ssl => true
ssl_key => '/usr/share/logstash/config/logstash.pkcs8.key'
ssl_certificate => '/usr/share/logstash/config/logstash.crt'
}
//filebeat
output.logstash:
hosts: ['${LOGSTASH_HOST}:${LOGSTASH_PORT}']
ssl.certificate_authorities:
- /usr/share/filebeat/ca.crt결말
간단히 elasticsearch를 올려서 사용해보니 문제 상황에 대한 원인과 성능 테스트 및 로그 확인 등 유용하게 사용할 수 있는 가능성을 알 수 있었다.
일례로 외부에서 우리 서버로 brute force로 다양한 Router에 요청을 보내서 취약점을 파악하려는 시도를 포착하기도 하였다.
또한 DB가 죽었을 때에도 원인을 파악하는 데 간접적으로도 활용을 할 수 있었다.
하지만 여러 문제를 겪으면서 단순히 데이터를 올리는 것은 아주 간단하나 실제 운영을 위해서는 elasitcsearch에 대해 알아야하는 내용이 많다는 것을 느낀다.
