최근 스마트팜 모니터링 및 제어를 위한 웹 어플리케이션 프로토타입을 완성하고, 솔루션화를 하기 위해 필요한 데이터를 모델링하는 일을 하고 있다. 스마트팜은 식물을 키우기 위해 많은 센서와 시설들이 존재한다. 식물을 잘 키우기 위해서는 복잡하게 연결되어 있는 시설 데이터와 센서 데이터를 연계해서 분석을 해야하는 경우가 많다. 또한 식물에 따라서 봐야하는 센서 데이터가 다르고, 식물의 상태에 따라 빈번하게 여러 시설들을 설치/제거하기도 한다.
해당 시설 데이터들을 RDB를 사용한다는 것은 식물의 종류가 늘어가고 그에 맞는 설비와 센서들이 다양해지게 되고, 사용하는 요구사항이 늘어나게 된다면 지속해서 스키마와 테이블을 늘려나가야 할 것을 말한다. 복잡한 센서 데이터들의 관계를 어떻게 하면 복잡한 데이터 베이스 모델링 없이 사용자가 생성/수정할 수 있는 방안이 없을까? 고민하다가 그래프 데이터 베이스를 찾았고, 그중 가장 많이 사용하는 neo4j를 사용해보면서 어떤 성격을 가지고 있는 지 알아보고자 한다.
그래프 데이터 베이스란?
정형 데이터 관계만 표시할 수 있었던 RDB의 한계를 보완하기 위해 만들어진 NoSQL 데이터 베이스.
수학적으로 그래프 이론에 토대를 두고 있다.
간단히 설명하자면
그래프는
공집합이 아닌 꼭짐점(정점, vertex, node)들의 집합인 V와
두 꼭지점 간의 연결선(edge)의 집합 E로 구성된다.
- 방향 그래프 : Edge에 시작과 끝 방향이 있는 그래프
- 무방향 그래프: 방향이 없는 그래프
 [사진 출처]
[사진 출처]
주로 집합과 경로를 찾는데 사용되며,
소프트웨어 알고리즘에서 배우는
Dijkstra’s algorithm
Bellman–Ford algorithm
등이 그래프 활용 사례라고 할 수 있다.
위 그래프 이론을 바탕으로 그래프 데이터 베이스는
- 저장소 : 데이터를 저장하기 위한 공간
- 그래프 프로세싱 엔진: 그래프 데이터 실시간 처리를 위한 엔진
- 질의 언어 : 효율적으로 데이터를 지원하기 위한 질의 언어
로 이루어져 있다.
Graph DB
그래프 이론은 IT에서 여러 방면에서 사용되곤 하는데, MySQL에서 사용하는 인덱스의 B-TREE도 일종의 그래프로서 탐색에서 성능 향상을 위해 사용된다.
그래프DB는 이런 성능향상 뿐 아니라 모델링 자체에도 그래프 이론을 적용한다.
RDB와 비교
DB 스키마를 설계해야하는 RDB와는 달리 그래프DB는 Entity의 관계만 설계 하고 이후 컬럼 설계는 실제 데이터를 넣는 것으로 정해진다. 새로운 Column이 추가되더라도 스키마 변경없이 단순히 Node를 추가하고 관련 Node와의 관계를 연결시켜주기만 하면 된다.
아래는 RDB와 GraphDB의 용어를 비교한 표이다.
| RDB | GraphDB |
|---|---|
| 테이블 | 레이블 |
| 행(Row) | 노드(node) |
| 열(column)과 Data | 속성과 값 |
| 조인(Join) | 순회(Traversal) |
Node
데이터가 저장 되는 기본 단위
Key-Value 단위 로 데이터가 저장이 된다.
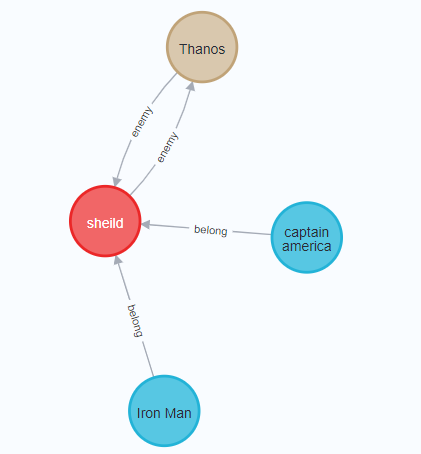
위 사진에서 보이는 원은 neo4j에서 지원하는 그래프 시각화로
사진의 원이 Node에 해당한다.
아래는 실제 Node가 저장되는 형태인데,
Type에 구애 받지 않고 다양한 데이터를 저장할 수 있다.
{
"identity": 0,
"labels": [
"Hero"
],
"properties": {
"name": "Iron Man"
},
"elementId": "0"
}Lable
엔티티를 말한다.
라벨을 적용하여 노드 멤버를 그룹화 할 수 있다.
neo4j 코드
import neo4j from "neo4j-driver";
// user Infromation
const uri = "neo4j://<IP>:7687";
const user = "<유저 아이디>";
const password = "<비밀번호>";
// Drive 연결
const driver = neo4j.driver(uri, neo4j.auth.basic(user, password));
// session 획득
const session = driver.session();
// CREATE
try {
const IronMan = await session.run("CREATE (a:Hero {name: $name}) RETURN a", {
name: "Iron Man",
});
const captain = await session.run("CREATE (a:Hero {name: $name}) RETURN a", {
name: "captain america",
});
const Thanos = await session.run(
"CREATE (a:villain {name: $name}) RETURN a",
{
name: "Thanos",
}
);
const avengers = await session.run(
"CREATE (a:avengers {belong: $belong}) RETURN a",
{
belong: "sheild",
}
);
} catch (error) {
console.error(error);
}
// Edge 연결
await session.run(
"MATCH (p1:Hero), (a1:avengers) WHERE ID(p1) = $person1Id AND ID(a1) = $avengersId CREATE (a1)-[:belong {position: captain}]->(p1)",
{ person1Id: parseInt(3), avengersId: parseInt(2) }
);
// Read
try {
const result = await session.run(
"MATCH (a1:avengers)-[:belong]-(p1:Hero) WHERE ID(a1) = $aId RETURN p1",
{ aId: parseInt(3) }
);
const connectedNodes = result.records.map(
(record) => record.get("p1").properties
);
console.log("Connected Nodes:", connectedNodes);
} catch (error) {
console.error("Error:", error.message);
}
// DELETE
const nodeId = 1;
try {
await session.run(`MATCH (n) WHERE ID(n) = $nodeId DELETE n`, {
nodeId: parseInt(nodeId),
});
} catch (error) {}
노드 생성
"CREATE (a:villain {name: $name}) RETURN a"
노드를 생성하기 위해서는 CREATE 쿼리를 사용한다.
(<식별자>:<label 이름> <프로퍼티>) RETURN <반환값>
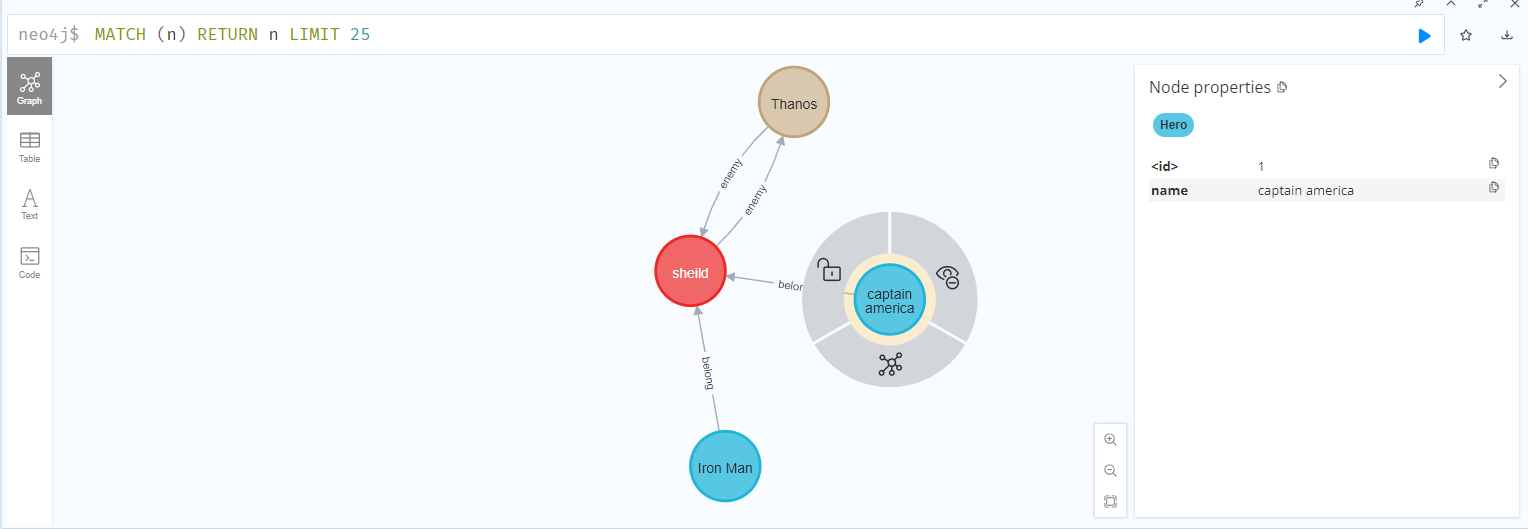
노드 간 간선 연결
MATCH (p1:avengers), (a1:villain) WHERE ID(p1) = $person1Id AND ID(a1) = $avengersId CREATE (a1)-[:enemy {position: $position}]->(p1)"
노드 간 간선을 연결을 위해서는 Match와 CREATE를 사용하며
노드 간의 관계 혹은 노드의 행위를 저장할 수 있다.
MATCH (<식별자>:<label 이름>), (<식별자>:<label 이름>) WHERE ID(p1) = $person1Id AND ID(a1) = $avengersId
CREATE (<식별자>)-[:<label 이름> <프로퍼티>]->(<식별자>)"
MATCH를 통해 조건에 부합하는 노드를 찾고,
CREATE를 통해 간선을 생성하는 방식이다.
위 쿼리는 캡틴 아메리카는 shield(avengers)에 속해 있으며, Position은 catain을 맡고 있다는 것을 표현하고 있다.
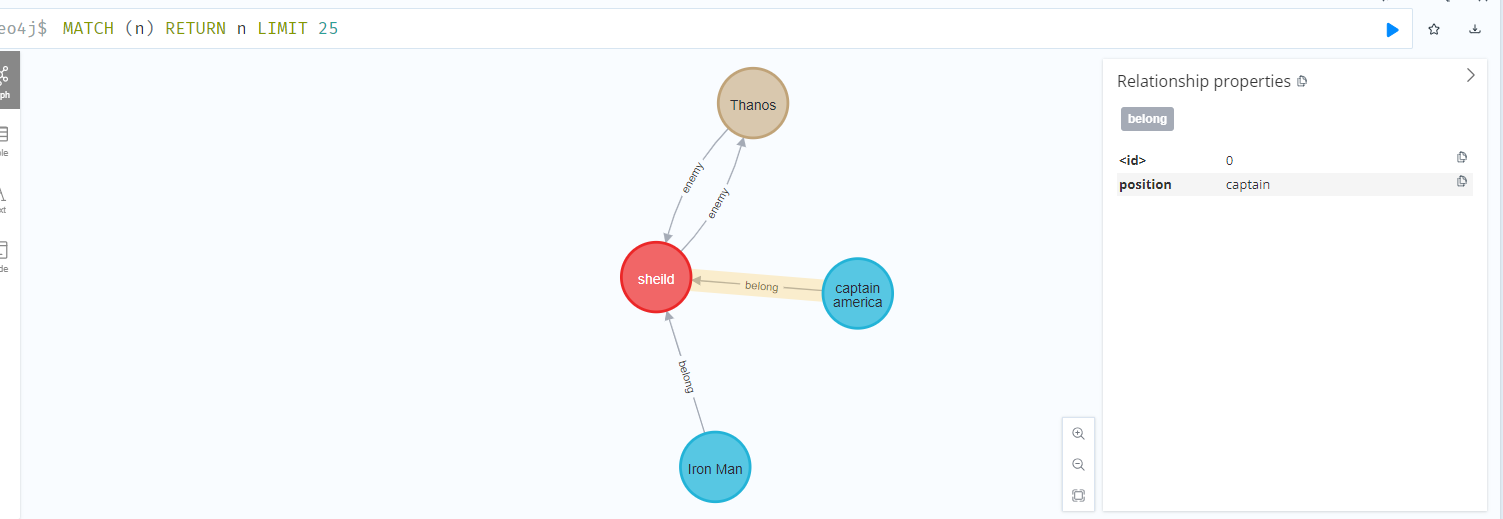
쿼리
쉴드에 속해있는 Hero를 검색하기 위해서는 MATCH를 활용하면 된다.
MATCH (a1:avengers)-[:belong]-(p1:Hero) WHERE ID(a1) = $aId RETURN p1

모델링
추후 수정 !!
마치며
짧게 사용을 해보면서 든 생각은 그래프 데이터 베이스라고 무작위로 데이터를 집어 넣게 되면 당연히 쿼리 성능이 떨어질 것이다(하나의 노드에서 필요한 데이터까지 Depth가 커진다면). 그렇기에 뭇 NoSQL이 그러하듯 그래프 데이터 베이스 역시 목적에 맞는 모델링이 필요하다.
하지만, 현실 세계의 데이터가 단순히 객체의 집합이 아니며, 그것들의 관계(행위)가 훨씬 중요한 것(작게는 양자 세계 부터 AI 모델에서 가중치, 현실세계 까지)이라 생각하는데, 그래프 데이터 베이스는 그 '관계 마저도 엣지를 통해 데이터 베이스로 표현을 할 수 있다는 점이 매력이지 않나'라는 생각을 해본다.
VR과 AR에 관심이 많은 나로써 그래프 데이터 베이스는 데이터를 표현하기에 비교적 적합하지 않나 생각을 해본다.
다음 시간에는 실제 코드와 더불어 스마트 팜에서 활용을 어떻게 할 수 있을 지 알아보고, RDB와 성능 비교를 해보고자 한다.
참고 자료
< NEO4J 공식문서 >
https://neo4j.com/developer/get-started/
< NEO4J 블로그 >
https://neo4j.com/blog/data-modeling-basics/
< The study on data migration from relational database to graph database >
:Zhihong Nan and Xue Bai 2019 J. Phys.: Conf. Ser. 1345
<[Upstage Talks] Graph Database 입문자가 1년동안 배운 것들>
https://www.youtube.com/watch?v=YJjsI8zQvno
<기타 참고>
http://bigdata.dongguk.ac.kr/lectures/disc_math/_book/%EA%B7%B8%EB%9E%98%ED%94%84.html

NEO4J 처음 알게됐는데 신기하네요~