2026.03.30. 월요일
- 데이터 분석 실습을 위한 mysql과 vscode 설치
2026.03.31. 화요일
- 깃허브 특강
2026.04.01. 수요일
크롤링을 이용한 웹 데이터 수집
- HTML 태그
<!DOCTYPE html>
<html>
<head>
<title>페이지 타이틀</title>
</head>
<body>
<h1>제목</h1>
<p>들어갈 문장</p>
<!-- 순서 없는 리스트 -->
<ul>
<li>첫 번째</li>
<li>두 번째</li>
</ul>
<!-- 순서 있는 리스트 -->
<ol>
<li>첫 번째</li>
<li>두 번째</li>
</ol>
<!-- 링크 -->
<a href="https://example.com">링크</a>
</body>
</html>
- 개발자 도구 (F12)와 요소 선택 아이콘

- Copy selector
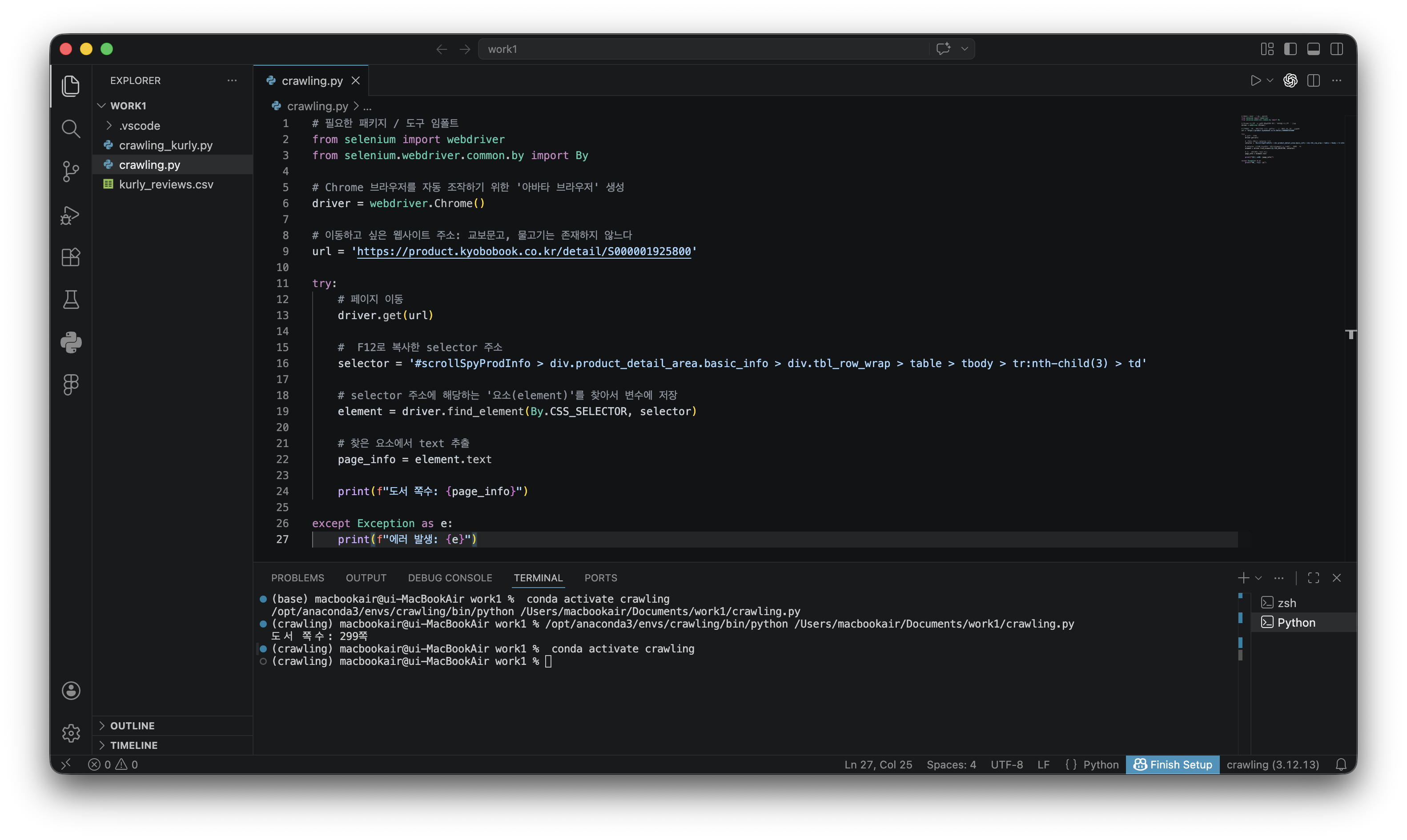
- '물고기는 존재하지 않는다'의 쪽수 정보 수집하기
- 생성형 AI와 selenium 라이브러리를 이용한 웹 데이터 수집
당신은 Selenium을 사용한 동적 웹사이트 크롤링에 특화된 경력 10년 이상의 경험 많고 우수한 전문가입니다. 다음과 같이 내가 <요청>하는 url 상의 상품에 대한 정보를 수집할 수 있는 정확한 코드를 제시해 주세요. 나의 수집 환경은 아나콘다로 가상 환경을 만들고 vs code에서 파이썬으로 수집합니다.
<요청>
1. 수집 대상 url: "https://www.kurly.com/goods/5026468"
2. 사용 라이브러리: selenium, webdriver 등 undetected-chromedriver는 사용하지 않습니다
3. 봇 탐지를 우회할 수 있는 강력한 설정 필수
4. 수집 항목: 상품명(첨부파일: 상품명 정보.png 참조), 리뷰 본문(첨부파일: 리뷰본문정보.png 참조)
5. 수집 범위: 1페이지부터 5페이지까지
6. 저장 형식: 수집된 모든 데이터를 2개의 컬럼(상품명, 리뷰)으로 구성된 csv 파일로 저장(인코딩 utf-8-sig 적용)
7. 사이트 특징: 다음 페이지 버튼(첨부파일: 페이지연결버튼.png)을 눌러야 다음 페이지로 이동할 수 있음위에 언급한 첨부파일 세 개랑 이 프롬프트로 대답으로 받은 파이썬 코드를 활용하여 마켓컬리 상품 중 하나를 골라 리뷰를 크롤링해봤어요
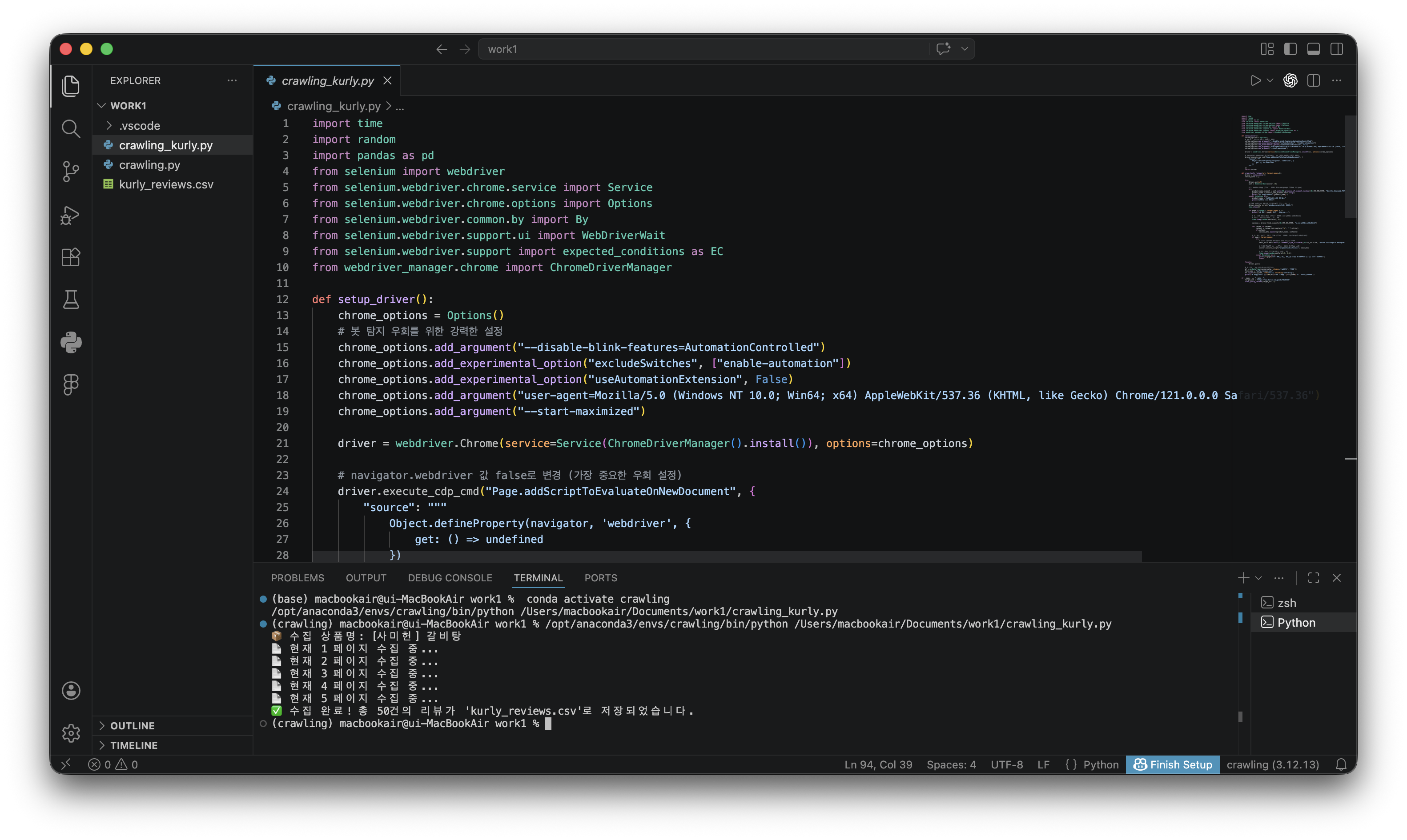
왼쪽에 보면 kurly_review.csv 생김!
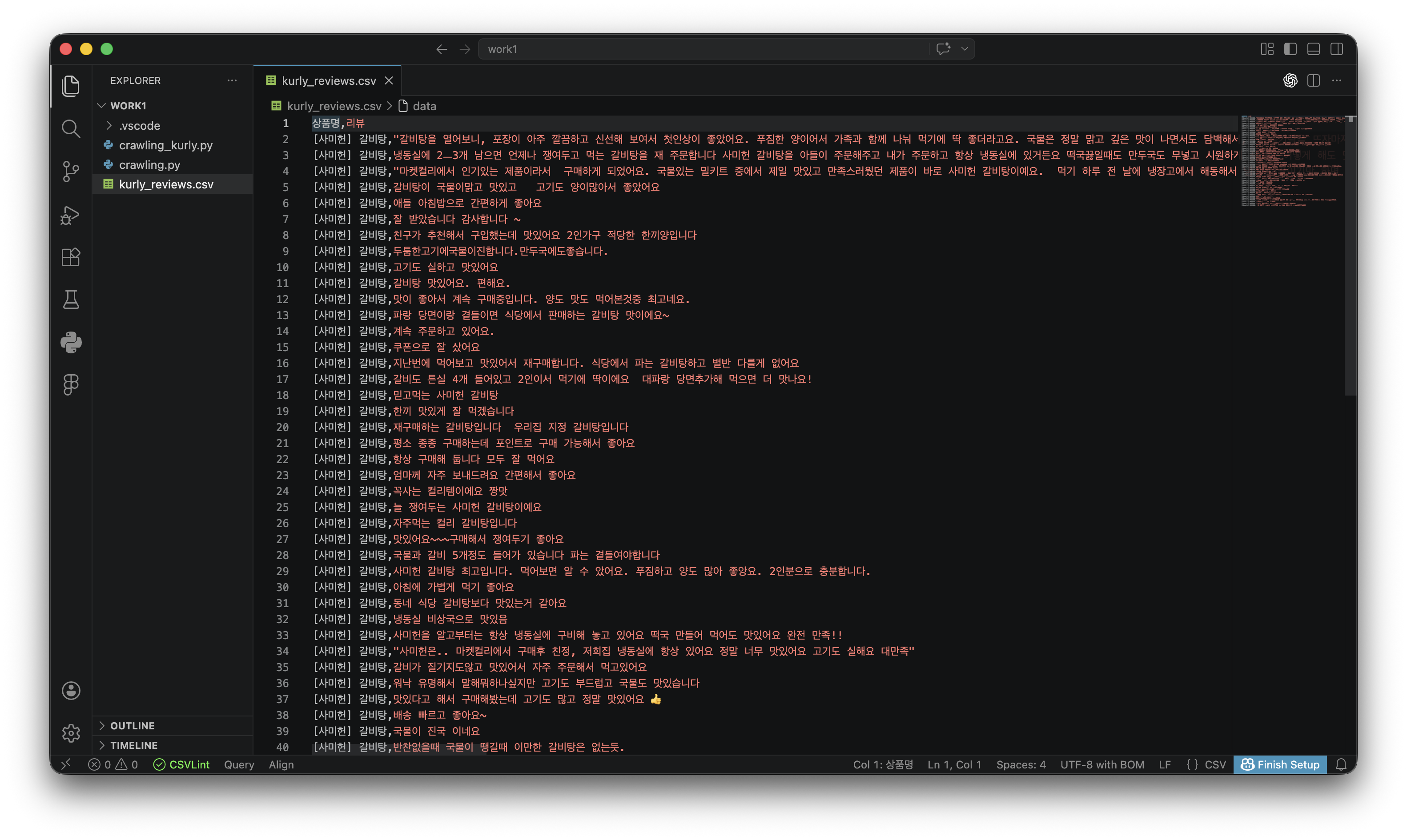
들어가보면 이렇게 떠요 🤩
- 스스로 해보는 '생성형 AI와 selenium 라이브러리를 이용한 웹 데이터 수집'
(생략)
오픈 API를 이용한 데이터 수집
- API 개념
2026.04.02. 목요일
오픈 API를 이용한 데이터 수집
- API 개념
- 호출 URL 작성
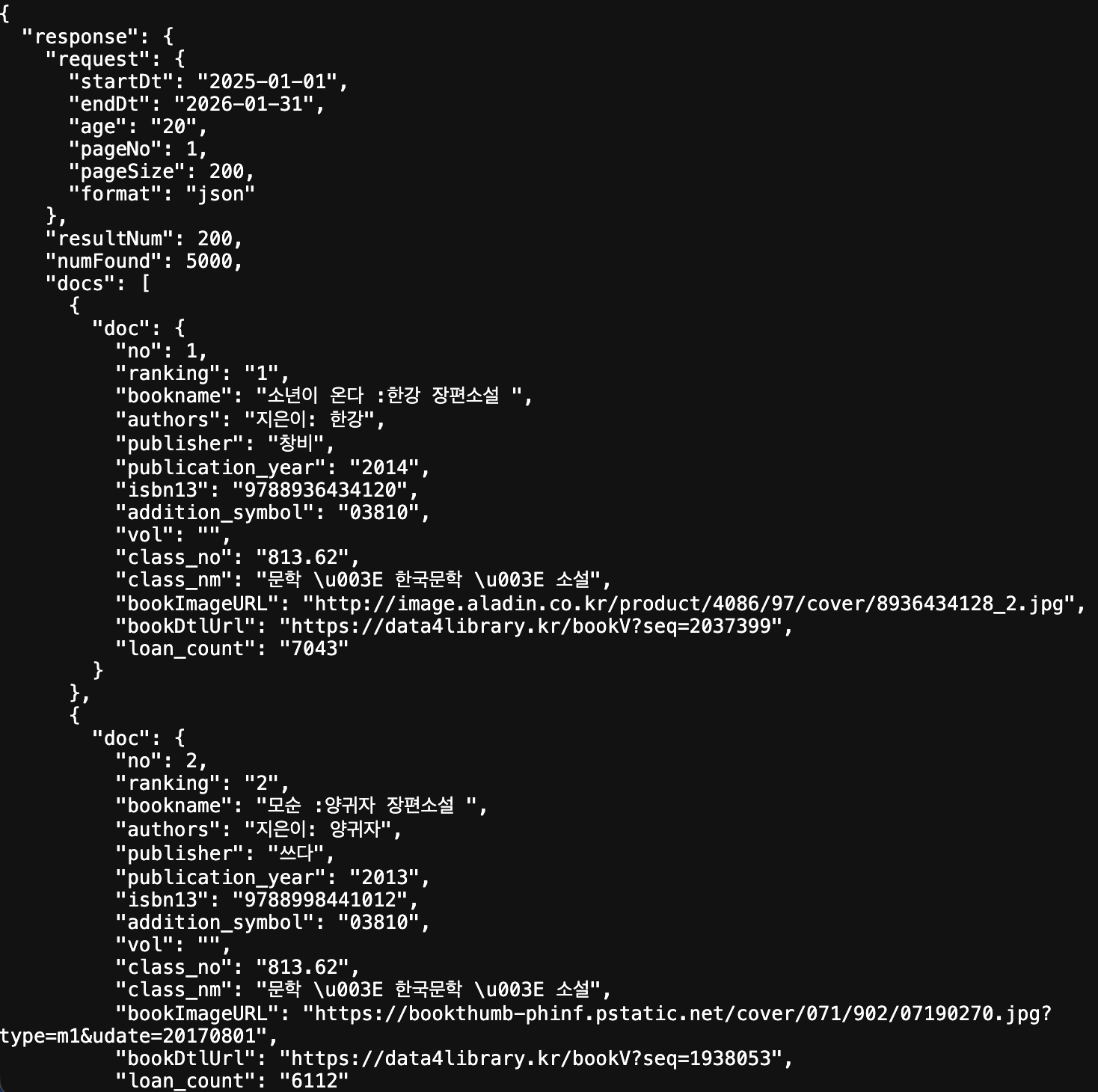
도서관정보나루에 API 매뉴얼 일부.. (3. 인기대출도서조회)

url = """
http://data4library.kr/api/loanItemSrch?
authKey=[발급받은키]
&startDt=2022-01-01&endDt=2022-03-31
&pageNo=1&pageSize=10
"""호출 결과
- JSON(JavaScript Object Notation) 정리
| Python dict 자료형 | JSON | |
|---|---|---|
| 구조 | {key : value} | {key : value} |
| 자료형 | dict 자료형 | string 자료형 |
| URL을 통한 데이터 전송 가능성 | 불가능 | 가능 |
- python으로 API 호출하기
→ requests 라이브러리 사용
① 설치
!pip install requests
② 라이브러리 import
import requests
③ HTTP GET의 호출 URL 완성
url = """http://data4library.kr/api/loanItemSrch?authKey=[인증키]&startDt=2025-01-01&endDt=2026-01-31&age=20&pageNo=1&pageSize=200&format=json"""
④ request.get() 함수 사용
response = requests.get(url)
⑤ text 속성을 통해 문자열 형태의 데이터를 받을 수 있음
data = response.text
- 생성형 AI와 Open API를 이용한 데이터 수집 실습
import requests
import pandas as pd
def collect_popular_books():
# 1. 설정 정보
url = "http://data4library.kr/api/loanItemSrch"
# [주의] 여기에 도서관 정보나루에서 발급받은 본인의 인증키를 입력하세요
auth_key = "YOUR_API_KEY"
params = {
"authKey": auth_key,
"startDt": "2025-01-01",
"endDt": "2026-03-31",
"age": "20", # 20대
"pageSize": "200", # 1위부터 200위까지
"pageNo": "1",
"format": "json" # 처리가 쉬운 JSON 형식
}
print(f"데이터 수집 중: {params['startDt']} ~ {params['endDt']} (20대 인기 대출 도서)")
try:
# 2. API 호출
response = requests.get(url, params=params)
response.raise_for_status() # 접속 에러 확인
data = response.json()
# 3. 데이터 파싱
# 매뉴얼상 구조: response -> docs -> [ {doc: {...}}, {doc: {...}} ]
docs = data.get('response', {}).get('docs', [])
if not docs:
print("수집된 데이터가 없습니다. 인증키나 파라미터를 확인하세요.")
return
# 리스트 내부에 중첩된 'doc' 키를 벗겨내어 평탄화 작업
book_list = [item['doc'] for item in docs]
# 4. 데이터프레임 변환
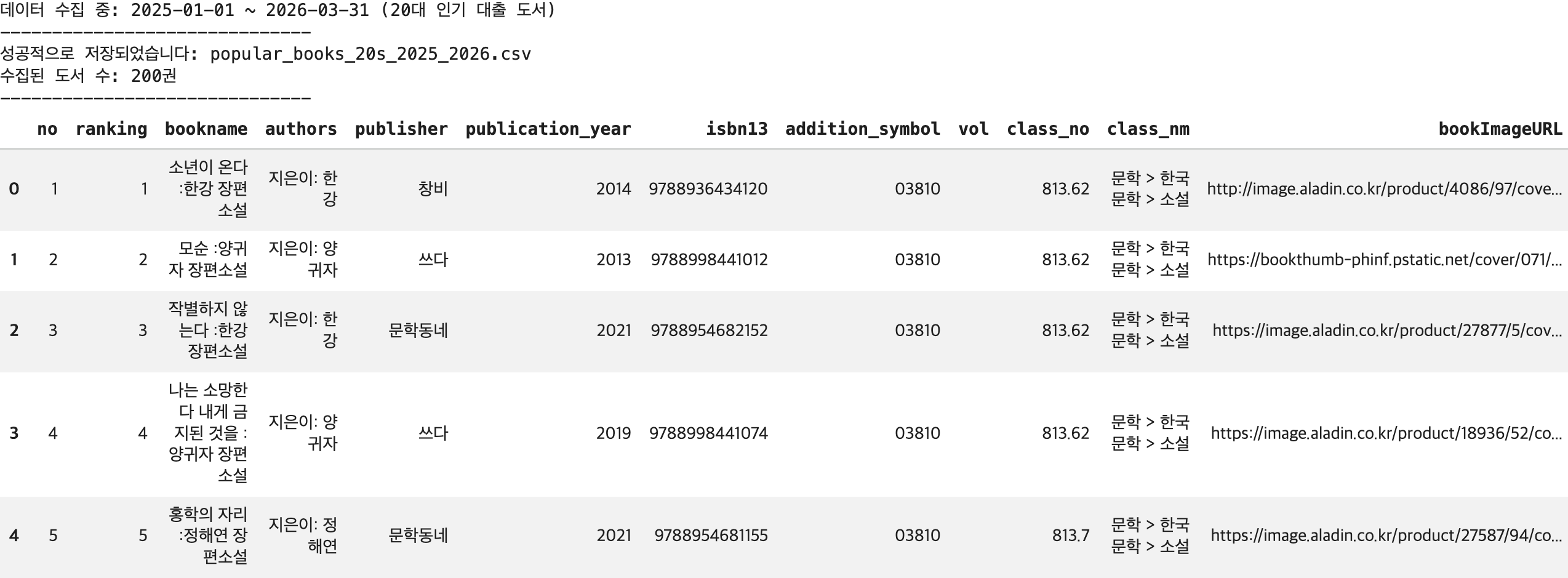
df = pd.DataFrame(book_list)
# 5. CSV 저장 (한국어 깨짐 방지를 위해 utf-8-sig 사용)
file_name = "popular_books_20s_2025_2026.csv"
df.to_csv(file_name, index=False, encoding='utf-8-sig')
print("-" * 30)
print(f"성공적으로 저장되었습니다: {file_name}")
print(f"수집된 도서 수: {len(df)}권")
print("-" * 30)
# 데이터 상위 5개 미리보기
display(df.head())
except Exception as e:
print(f"에러 발생: {e}")
# 함수 실행
collect_popular_books()결과
- 생성형 AI와 서울 열린데이터광장 API를 이용한 데이터 수집 실습 (.env파일을 사용해 인증키를 안전하게 관리)
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')import os
import requests
import pandas as pd
import time
from dotenv import load_dotenv
from google.colab import drive
# .env 파일이 저장된 경로를 지정하세요 (예: /content/drive/MyDrive/.env)
env_path = '/content/drive/MyDrive/KDT/.env'
load_dotenv(env_path)
API_KEY = os.getenv('SEOUL_DATA_API_KEY')
SERVICE_NAME = 'VwsmTrdarSelngQq' # 추정매출-상권 서비스명
if not API_KEY:
print("API Key를 찾을 수 없습니다. .env 파일 경로와 변수명을 확인해주세요.")
def fetch_seoul_market_data(api_key, quarter_code):
"""
특정 분기의 모든 데이터를 페이지네이션하여 수집하는 함수
"""
all_rows = []
start_index = 1
end_index = 1000
print(f"\n>>> [{quarter_code}] 분기 데이터 수집 시작...")
while True:
# 서울시 API URL 구조: http://openapi.seoul.go.kr:8088/{KEY}/{TYPE}/{SERVICE}/{START_INDEX}/{END_INDEX}/{STDR_YYQU_CD}
url = f"http://openapi.seoul.go.kr:8088/{api_key}/json/{SERVICE_NAME}/{start_index}/{end_index}/{quarter_code}"
try:
response = requests.get(url)
response.raise_for_status()
data = response.json()
# 응답 데이터 존재 여부 확인
if SERVICE_NAME in data:
total_count = data[SERVICE_NAME]['list_total_count']
rows = data[SERVICE_NAME]['row']
all_rows.extend(rows)
# 수집 현황 출력
print(f"진행 상황: {len(all_rows)} / {total_count} 완료", end='\r')
# 모든 데이터를 다 가져왔으면 루프 종료
if end_index >= total_count:
break
# 다음 페이지 설정을 위해 인덱스 증가
start_index += 1000
end_index += 1000
# API 서버 부하 방지를 위한 미세 지연 (전문가의 디테일)
time.sleep(0.1)
else:
# 데이터가 없는 경우 처리 (예: INFO-200 등)
error_msg = data.get('RESULT', {}).get('MESSAGE', '데이터 없음')
print(f"\n분기 {quarter_code}: {error_msg}")
break
except Exception as e:
print(f"\n에러 발생 ({quarter_code}): {e}")
break
return all_rows
# 2. 수집 대상 분기 리스트 (2024년 1분기 ~ 2025년 3분기)
target_quarters = ['20241', '20242', '20243', '20244', '20251', '20252', '20253']
final_data = []
validation_report = {}
# 3. 메인 수집 루프
for q in target_quarters:
q_data = fetch_seoul_market_data(API_KEY, q)
final_data.extend(q_data)
# 데이터 검증용 데이터 개수 저장
validation_report[q] = len(q_data)
# 4. 데이터프레임 변환 및 검증 결과 출력
df = pd.DataFrame(final_data)
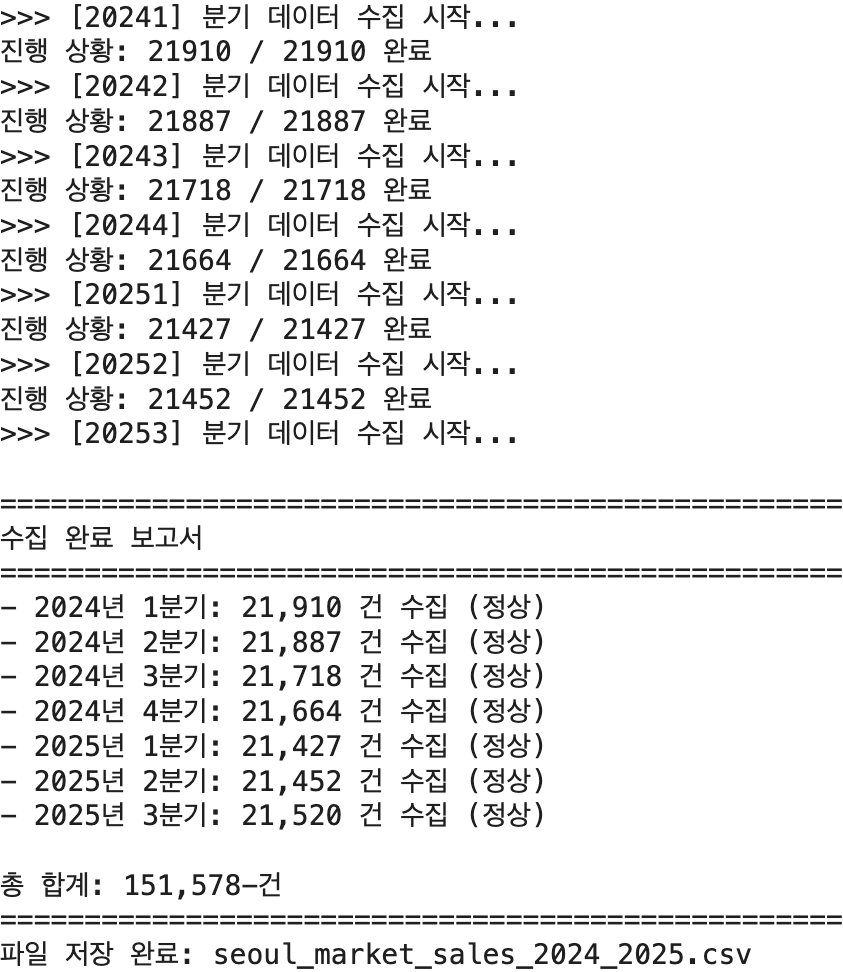
print("\n" + "="*50)
print("수집 완료 보고서")
print("="*50)
for q, count in validation_report.items():
status = "정상" if count > 0 else "데이터 없음/오류"
print(f"- {q[:4]}년 {q[4]}분기: {count:,} 건 수집 ({status})")
print(f"\n총 합계: {len(df):,}-건")
print("="*50)
# 5. CSV 파일로 저장
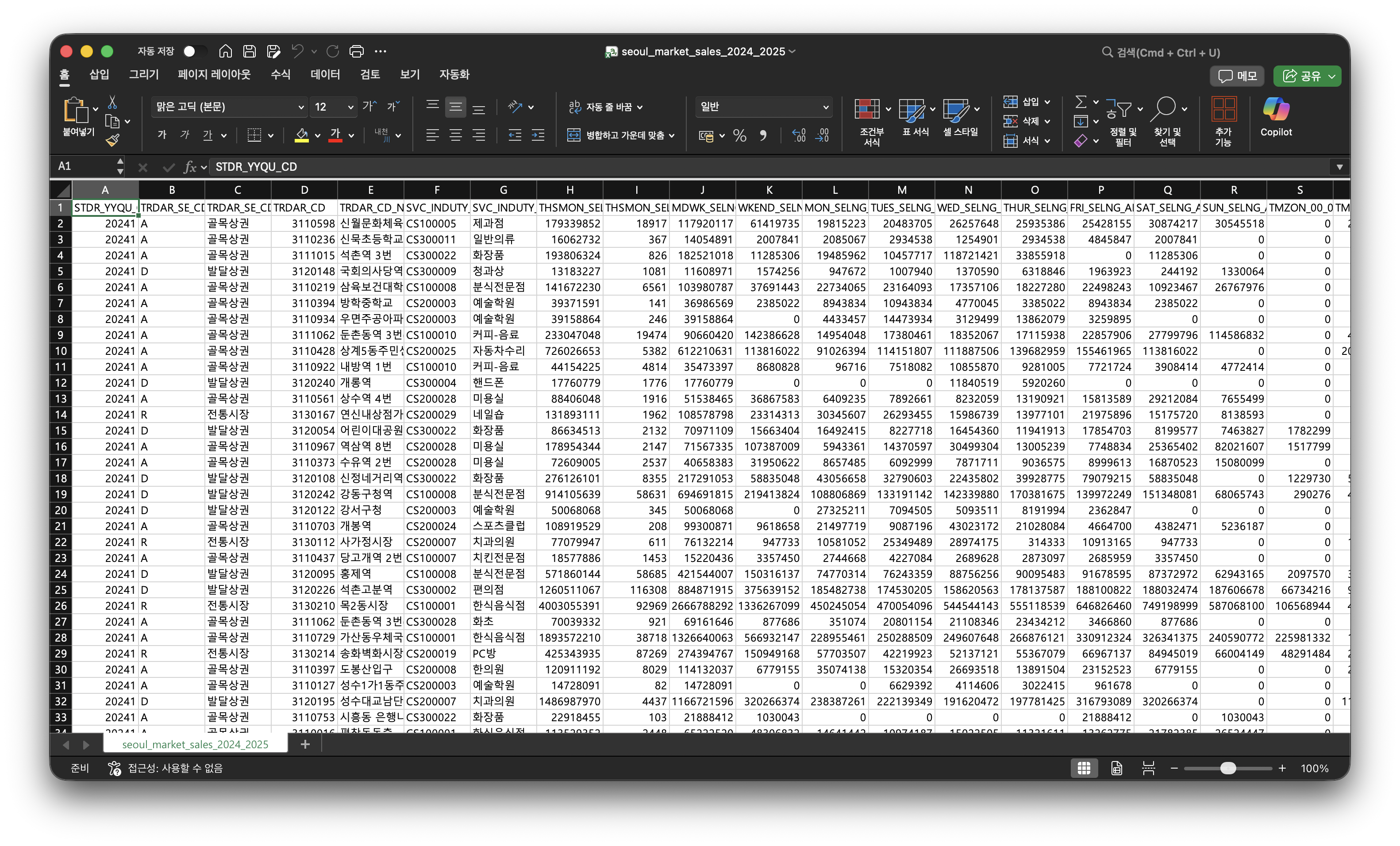
file_name = "seoul_market_sales_2024_2025.csv"
df.to_csv(file_name, index=False, encoding='utf-8-sig')
print(f"파일 저장 완료: {file_name}")결과
데이터베이스(DB)
- 개념
- 실습 환경 설정
가상 환경 설치 & 활성화 (맥북 ver)
conda create -n db python=3.12
conda activate db
필요한 라이브러리 설치 : pip install pandas PyMySQL SQLAlchemy cryptography
- SQL 연습
구조를 다루는 명령어(DDL) ← 데이터가 아니라 데이터를 담는 틀(뼈대)를 관리
show(테이블 목록이나 정의 보기), create(테이블 생성), alter(컬럼 추가/삭제/타입 변경), drop(테이블 삭제)
데이터를 다루는 명령어(DML) ← 테이블 안에 들어있는 실제 값을 조작
select(조회), insert(삽입), update(수정), delete(삭제)
2026.04.03. 금요일
데이터베이스(DB)
- 주요 테이블 및 컬럼 속성
- PRIMARY KEY (기본키)
테이블에 단 하나만 존재할 수 있음
not null
다른 테이블과의 관계를 설정하는 데 중요한 역할 담당 (FOREIGN KEY와 함께 사용)
- AUTO_INCREMENT
주로 기본키랑 같이 사용, 정수형 컬럼에 새로운 행이 삽입될 때마다 자동으로 고유한 순차적인 값을 할당하는 속성
수동으로 고유한 ID 값을 관리할 필요가 없어 개발 및 유지보수 효율성을 높임
테이블 당 하나의 컬럼만 AUTO_INCREMENT 속성을 가질 수 있음
새로운 행이 삽입될 때 자동으로 1씩 증가하는 값을 할당
- FOREIGN KEY (외래키)
참조 무결성 유지
데이터 일관성 확보
외래키 컬럼은 참조하는 테이블의 기본키와 데이터 유형이 일치해야함
외래키 컬럼은 NULL 값을 가질 수 있음
하나의 테이블에 여러 개의 외래 키를 설정할 수 있음
create database 데이터베이스;
insert into 테이블 (컬럼1, ..., 컬럼n) values (값1, ..., 값n);
select * from 테이블;
update 테이블 set 컬럼=변경할 값 where 조건;
# 일시적으로 safe mode 해제 ← 데이터의 전체 데이터를 수정할 때 사용
set sql_safe_update=0;
update 테이블 set 칼럼=변경할 값;
delete from 테이블 where 조건;- join
Inner Join
use sakila;
select c.customer_id, c.first_name, c.last_name, c.email, c.address_id, a.address, a.district, a.city_id, a.postal_code
from customer as c
inner join address as a on c.address_id = a.address_id;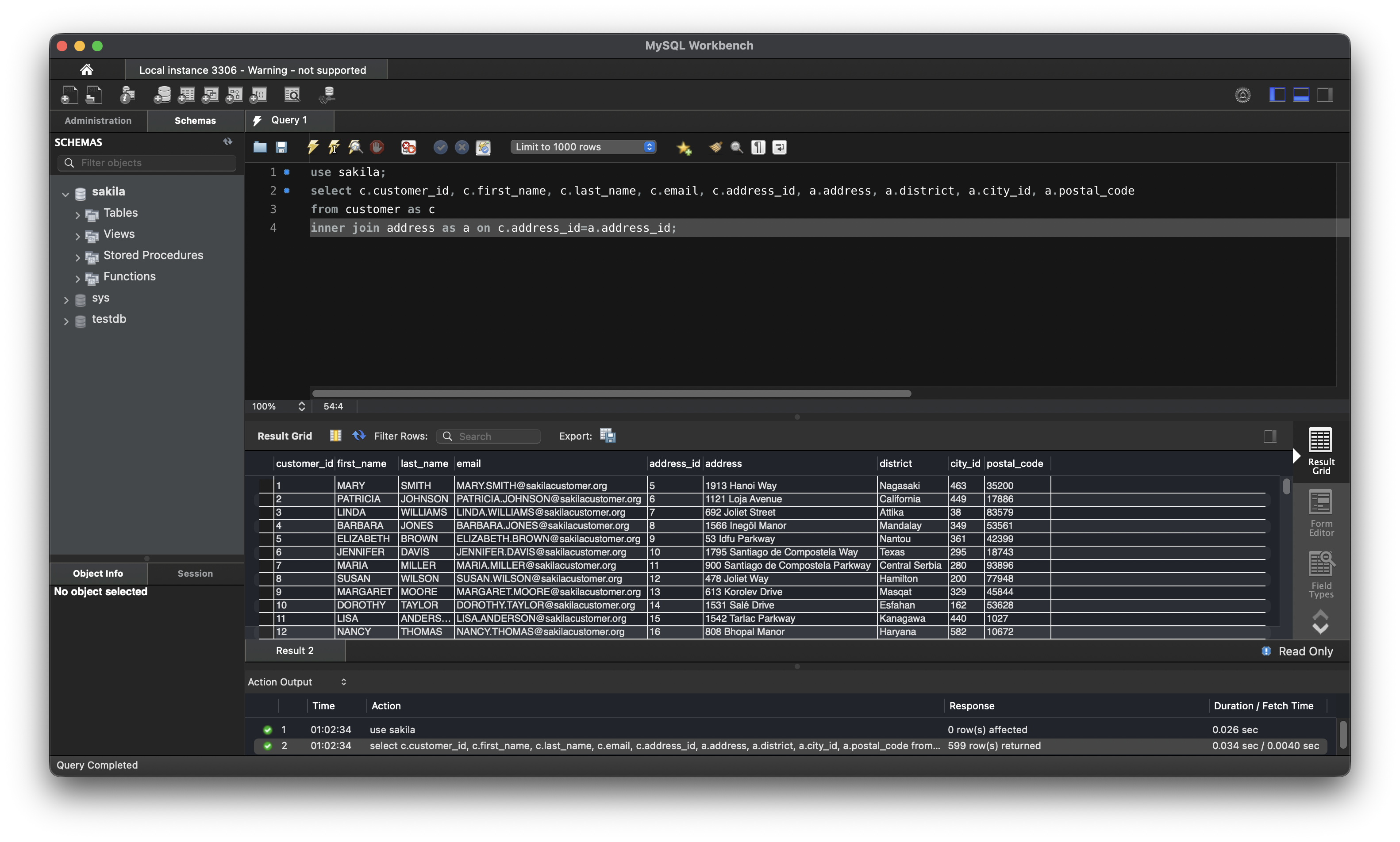
Outer Join
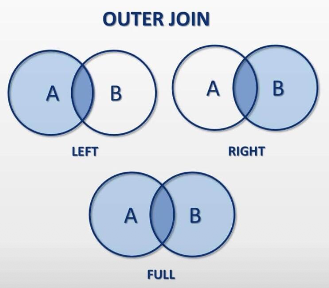
select a.customer_id, a.first_name, a.last_name, b.address_id, b.address, b.district, b.postal_code, c.city_id, c.city
from customer as a
inner join address as b on a.address_id = b.address_id
inner join city as c on b.city_id = c.city_id;
- python으로 DB 연결하기
#1. 필요한 라이브러리 / 함수 임폴트
import pandas as pd
from sqlalchemy import create_engine
#2. 데이터 불러오기
## csv 파일 경로 설정
file_path = 'popular_books.csv'
## DataFrame 생성
df = pd.read_csv(file_path)
## 결과 확인하기
print(df)
print('-'*80)
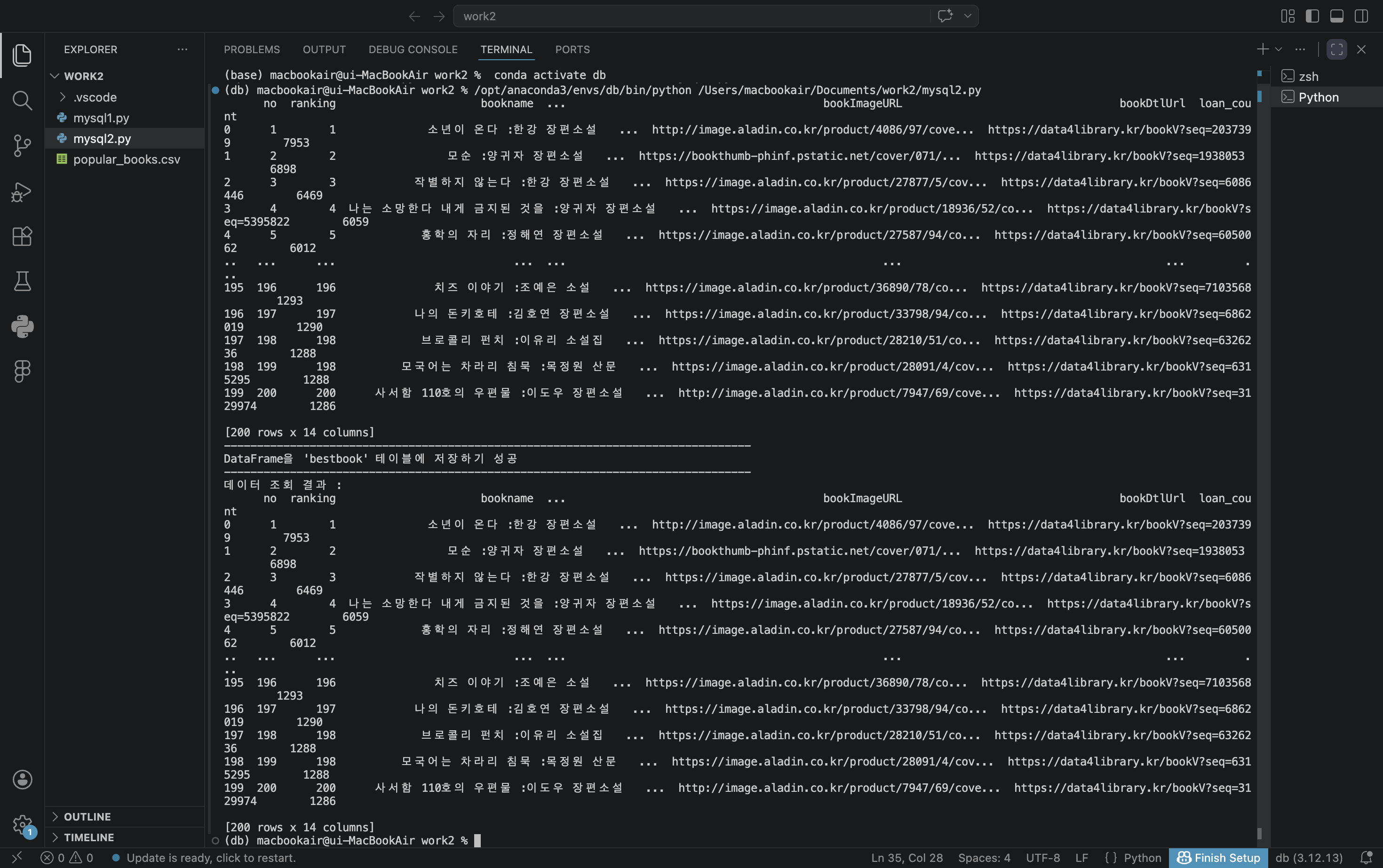
#3. DataFrame을 MySQL DB 테이블에 저장하기
## SQLAlchemy 이용: database 연결 정보 생성
db_config = {
'host': 'localhost', # MySQL 서버 주소 (예: localhost)
'user': 'root', # MySQL 사용자 이름
'password': '****', # MySQL 비밀번호
'database': 'testdb', # 사용할 데이터베이스 이름(반드시 workbench에서 먼저 생성)
'charset': 'utf8mb4' # 문자 인코딩 설정 (필요에 따라 변경)
}
## 저장할 테이블 이름
table_name = 'bestbook'
try:
## connection_string 생성
connection_string = f"mysql+pymysql://{db_config['user']}:{db_config['password']}@{db_config['host']}/{db_config['database']}"
## database 연결
engine = create_engine(connection_string)
## DataFrame을 MySQL 테이블에 저장
df.to_sql(name=table_name, con=engine, if_exists='append', index=False)
print(f"DataFrame을 '{table_name}' 테이블에 저장하기 성공")
except Exception as e:
print(f"Error saving DataFrame to MySQL: {e}")
print('-'*80)
### 결과 확인
# select문 작성 및 실행
sql = "select * from bestbook"
df_best = pd.read_sql(sql=sql, con=engine)
print(f'데이터 조회 결과 : \n{df_best}')
#1. 필요한 라이브러리 / 함수 임폴트
import pandas as pd
from sqlalchemy import create_engine
#2. 데이터 불러오기
## csv 파일 경로 설정
file_path = 'popular_books.csv'
## DataFrame 생성
df = pd.read_csv(file_path)
## 결과 확인하기
print(df)
print('-'*80)
#3. DataFrame을 MySQL DB 테이블에 저장하기
## SQLAlchemy 이용: database 연결 정보 생성
db_config = {
'host': 'localhost', # MySQL 서버 주소 (예: localhost)
'user': 'root', # MySQL 사용자 이름
'password': '1234', # MySQL 비밀번호
'database': 'testdb', # 사용할 데이터베이스 이름(반드시 workbench에서 먼저 생성)
'charset': 'utf8mb4' # 문자 인코딩 설정 (필요에 따라 변경)
}
## 저장할 테이블 이름
table_name = 'bestbook'
try:
## connection_string 생성
connection_string = f"mysql+pymysql://{db_config['user']}:{db_config['password']}@{db_config['host']}/{db_config['database']}"
## database 연결
engine = create_engine(connection_string)
## DataFrame을 MySQL 테이블에 저장
df.to_sql(name=table_name, con=engine, if_exists='append', index=False)
print(f"DataFrame을 '{table_name}' 테이블에 저장하기 성공")
except Exception as e:
print(f"Error saving DataFrame to MySQL: {e}")
print('-'*80)
### 결과 확인
# select문 작성 및 실행
sql = "select * from bestbook"
df_best = pd.read_sql(sql=sql, con=engine)
print(f'데이터 조회 결과 : \n{df_best}')