
2026.04.06. 월요일
정형 데이터 분석 및 시각화 - 데이터 전처리
- 누락 데이터 처리 (누락 데이터의 수 확인)
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 데이터 불러오기
## 필요한 라이브러리 임포트
import pandas as pd
## 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/ad_performance.csv'
## DataFrame 생성
df = pd.read_csv(file_path)
## 결과 확인
display(df)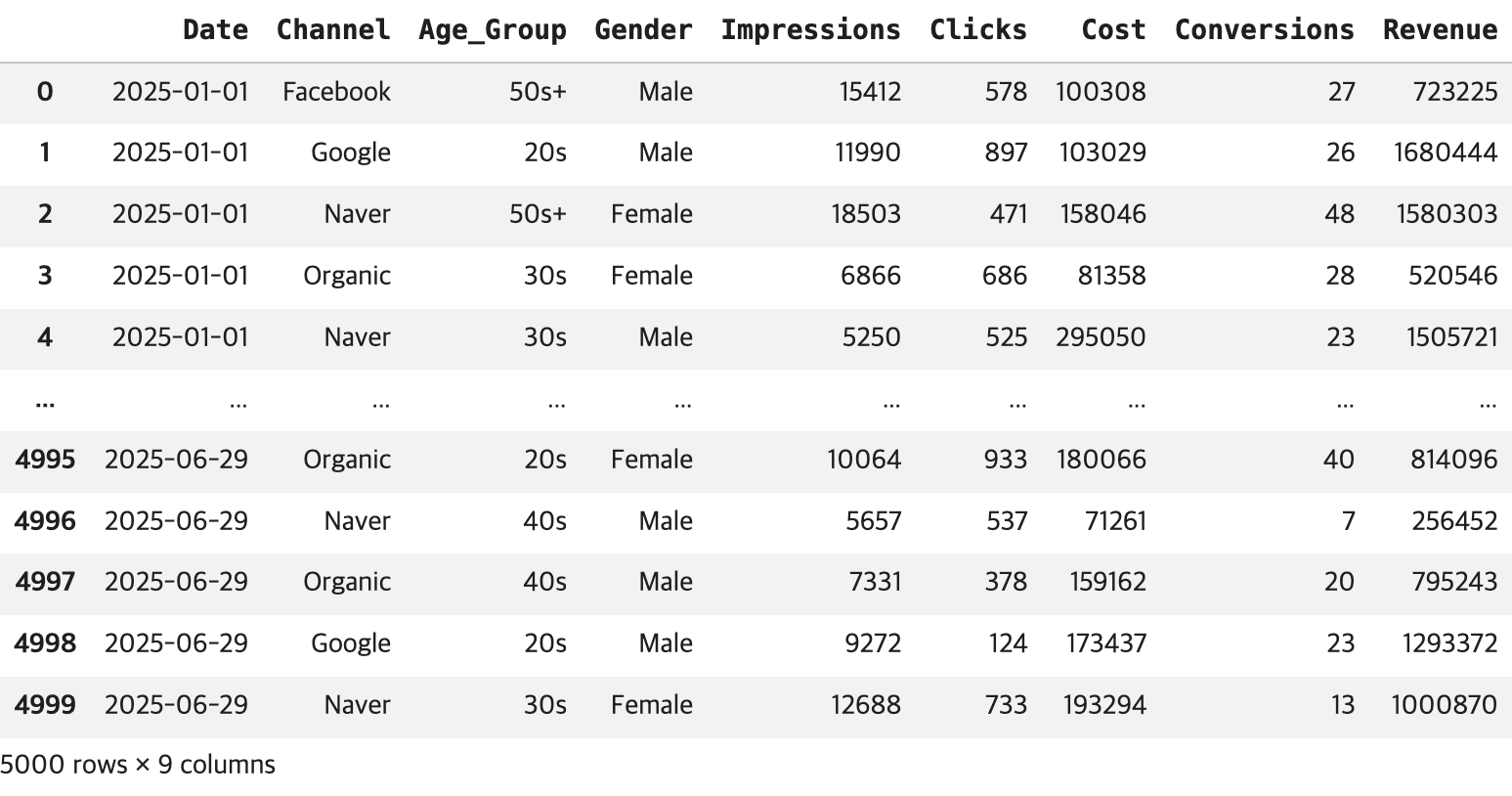
# 각 컬럼별 누락 데이터의 수 확인
## 1단계: isnull() 함수 적용
df_bool = df.isnull()
display(df_bool)
print('-'*80)
## 2단계: sum() 함수 적용 -> 누락 데이터(True)의 총합 연산
# num_nulls = df_bool.sum()
num_nulls = df.isnull().sum()
print(f'각 컬럼별 누락 데이터의 수: \n{num_nulls}')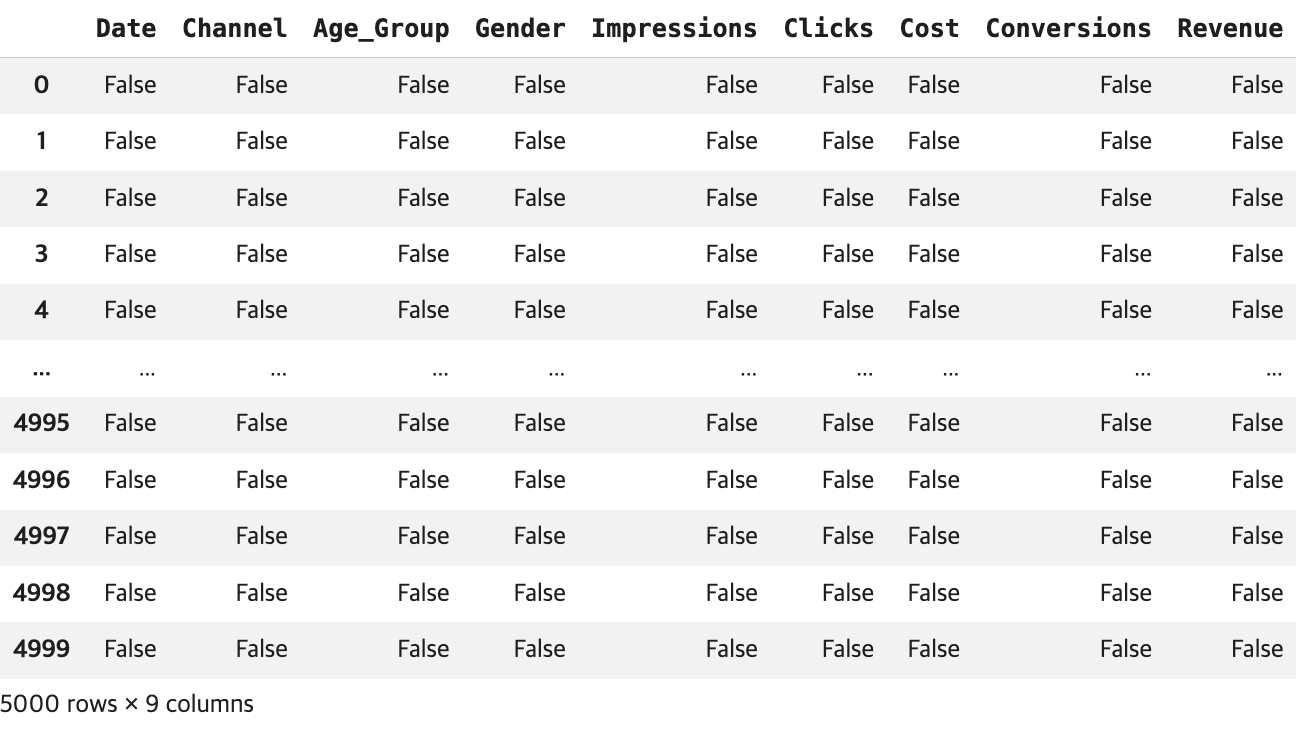

- 중복 데이터 처리
# Channel 컬럼의 항목별 빈도수 분석 -> 데이터의 중복 확인
## 1단계: Channel 컬럼 인덱싱
channel = df['Channel']
print(channel)
print('-'*80)
## 2단계: value_counts() 함수 적용
channel_counts = channel.value_counts()
print(f'Channel 컬럼의 항목별 빈도수: \n{channel_counts}')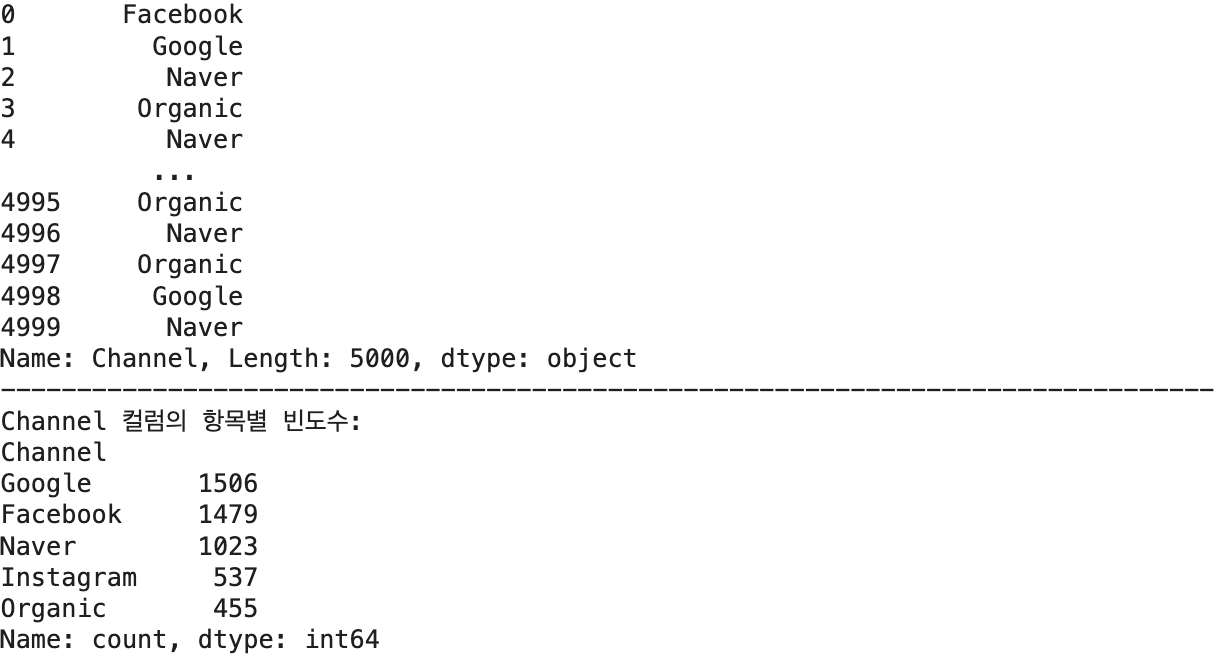
# groupby 함수: 채널별 평균 매출 계산
## 분석의 목적: "채널별 평균 매출 분석"
## 채널별 평균 매출 계산 -> 결과: Channel 알파벳 순서
channel_rev = df.groupby(by='Channel')['Revenue'].mean()
print(f'채널별 평균 매출: \n{channel_rev}')
print('-'*80)
## 채널별 평균 매출 계산 -> 결과: '매출' 크기 순으로 정렬 -> sort_values() 함수 호출 -> 기본값: 오름차순 정렬
channel_rev_sorted_ascend = df.groupby(by='Channel')['Revenue'].mean().sort_values()
print(f'채널별 평균 매출을 오름차순으로 정렬: \n{channel_rev_sorted_ascend}')
print('-'*80)
## 채널별 평균 매출 계산 -> 결과: '매출' 크기 순으로 정렬 -> sort_values() 함수 호출 -> 내림차순 정렬
channel_rev_sorted_desend = df.groupby(by='Channel')['Revenue'].mean().sort_values(ascending=False)
print(f'채널별 평균 매출을 내림차순으로 정렬: \n{channel_rev_sorted_desend}')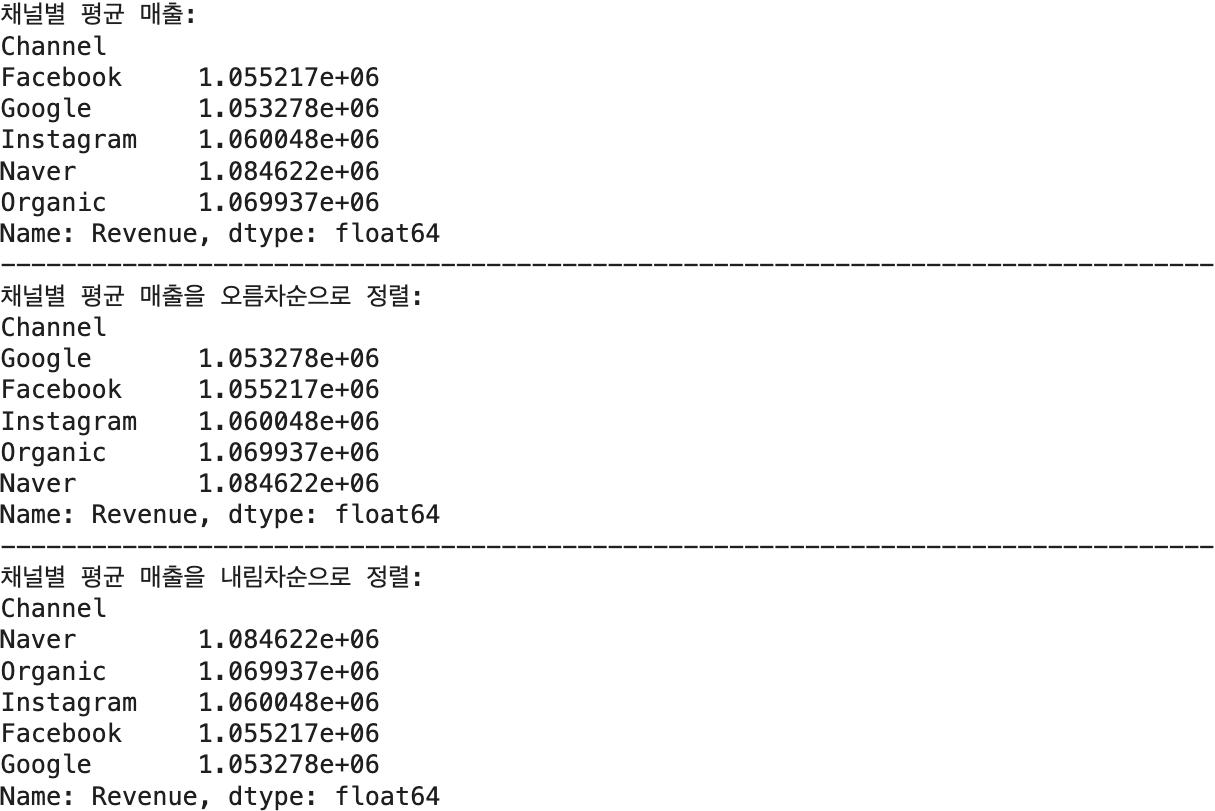
# groupby().agg() 함수
## 분석 목표: 각 광고 채널별 지출한 비용의 총합과 평균, 매출액의 총합과 평균 비교 분석
## agg() 함수 호출 -> 결과값: 채널별 알파벳 순으로 정렬
channel_summary = df.groupby(by='Channel').agg(
total_cost=('Cost', 'sum'),
avg_cost=('Cost', 'mean'),
total_rev=('Revenue', 'sum'),
avg_rev=('Revenue', 'mean')
)
## 결과 확인
print("분석 결과")
display(channel_summary)
print('-'*80)
## agg() 함수 호출 -> 결과값: 분석 결과를 평균 매출이 높은 순으로 내림차순 정렬
channel_summary_sorted = df.groupby(by='Channel').agg(
total_cost=('Cost', 'sum'),
avg_cost=('Cost', 'mean'),
total_rev=('Revenue', 'sum'),
avg_rev=('Revenue', 'mean')
).sort_values(by='avg_rev', ascending=False)
## 결과 확인
print('분석 결과')
display(channel_summary_sorted)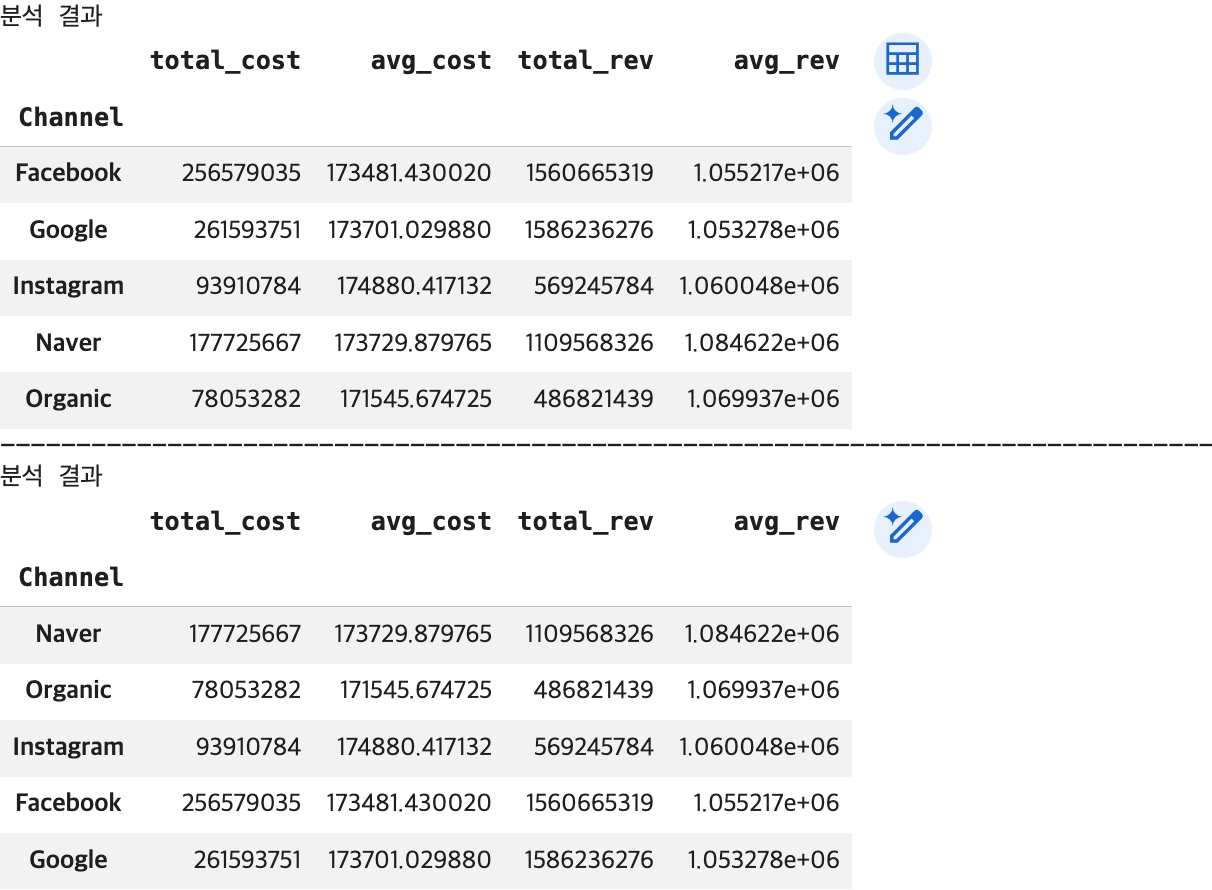
- Feature Engineering (파생 변수 생성 / One-Hot Encoding)
# 컬럼 추가 -> 파생 변수 생성
## 목표: 기존 데이터를 활용, 마케터에게 유의미한 새로운 컬럼(마케팅 KPI 컬럼) 생성
## CTR (Click-Through Rate): 클릭률
df['CTR'] = (df['Clicks'] / df['Impressions']) * 100
## CPC (Cost Per Click): 클릭당 비용
df['CPC'] = (df['Cost'] / df['Clicks'])
## CVR (Conversion Rate): 전환율
df['CVR'] = (df['Conversions'] / df['Clicks']) * 100
## CPA (Cost Per Acquisition): 전환당 비용
df['CPA'] = (df['Cost'] / df['Conversions'])
## ROAS (Return On Ad Spend): 광고비 대비 수익률
df['ROAS'] = (df['Revenue'] / df['Cost']) * 100
## 결과 확인
display(df)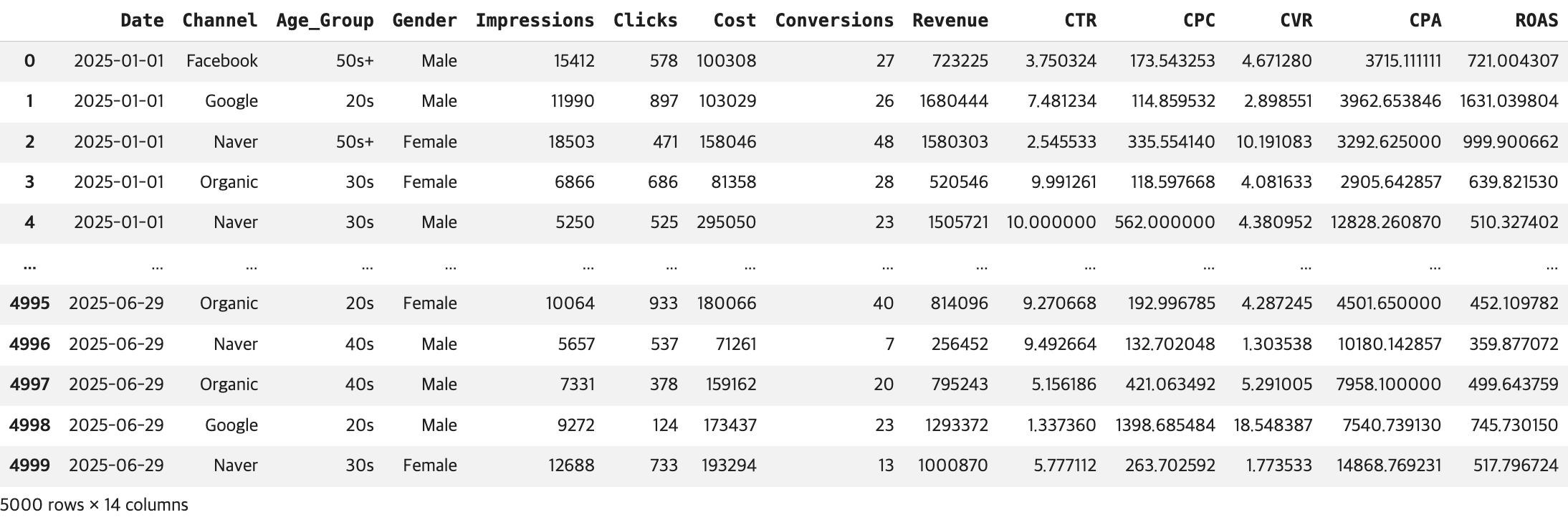
# pd.get_dummies() 함수 호출
df_onehot = pd.get_dummies(data=df, columns=['Channel','Age_Group','Gender'], dtype=int)
display(df_onehot)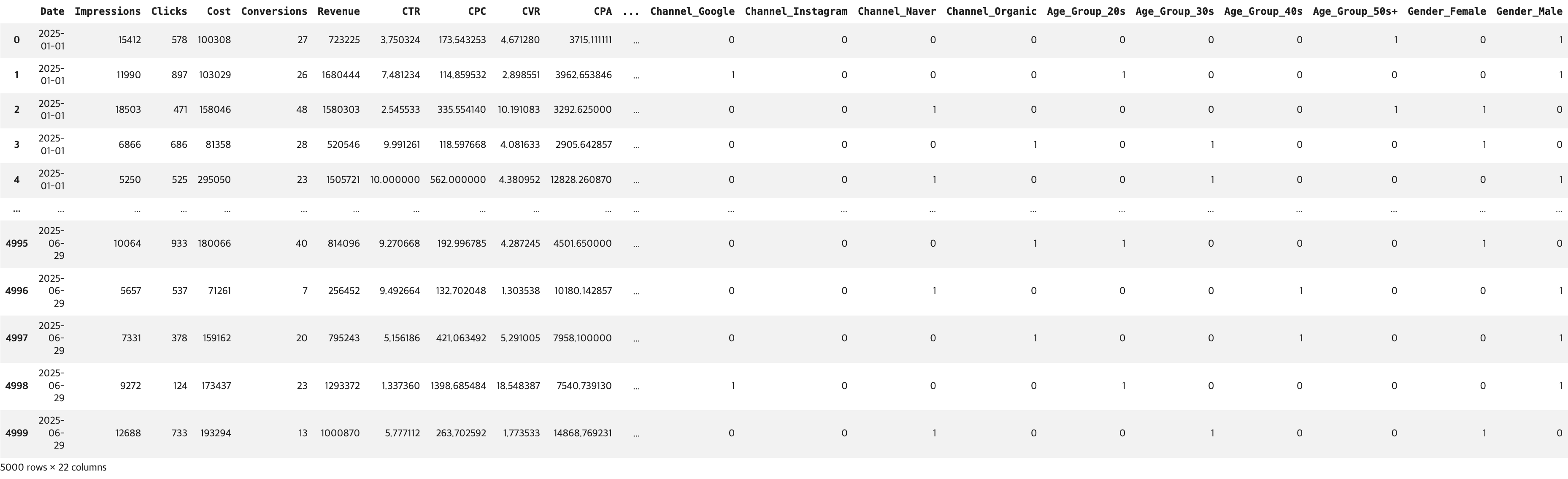
- 데이터 전처리 연습 문제(1)
- 데이터 전처리 연습 문제(2)
정형 데이터 분석 및 시각화 - 데이터 탐색
from google.colab import drive
drive.mount('/content/drive')
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 데이터 불러오기
## 필요한 라이브러리 임포트
import pandas as pd
## 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/ad_performance.csv'
## DataFrame 생성
df = pd.read_csv(file_path)
## 결과 확인
display(df)
- 요약 통계량
# 수치형 컬럼에 대한 요약 통계량
df_stats = df.describe()
print("요약 통계량")
display(df_stats)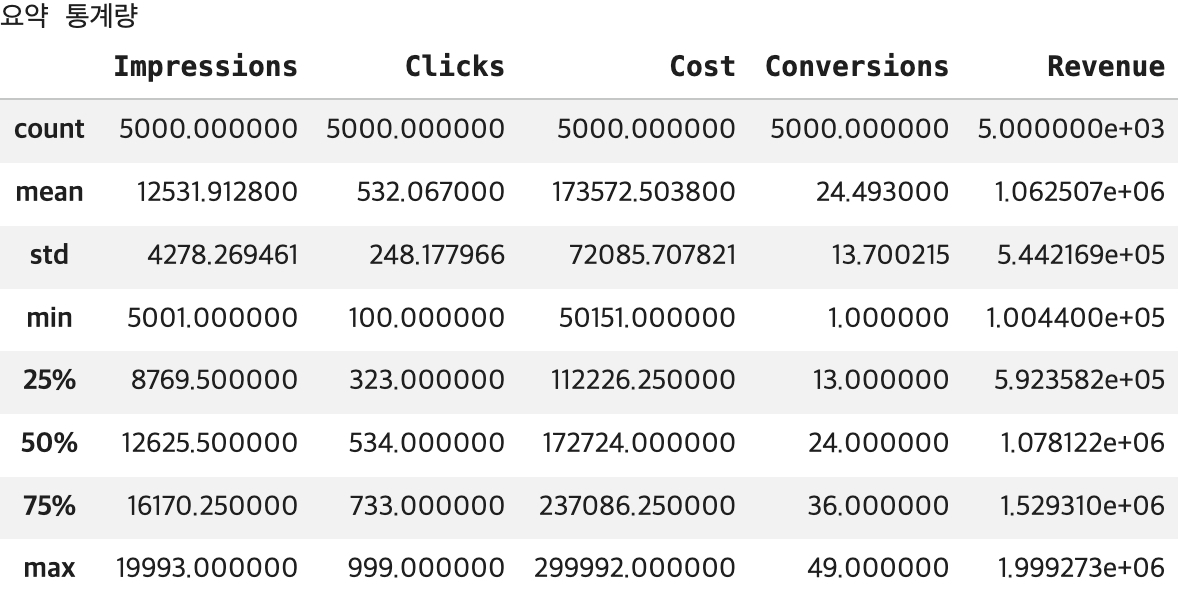
- 평균 구하기
# 방법1: 요약 통계량 -> Cost 컬럼의 평균값 추출
## 소수점 첫째 자리 반올림 -> 파이썬 round(숫자값, 자리수)
avg_cost = df_stats.loc['mean', 'Cost']
avg_cost = round(avg_cost, 1)
print(f"Cost 컬럼의 평균값: {avg_cost}")
# 방법2: 특정 컬럼 인덱싱 -> mean() 함수 호출
## 소수점 첫째 자리 반올림 -> 파이썬 round(숫자값, 자리수)
avg_cost = df['Cost'].mean()
avg_cost = round(avg_cost, 1)
print(f'Cost 컬럼의 평균값: {avg_cost}')
- 최소값 / 최대값 구하기
# 요약 통계량 -> Revenue 컬럼의 최소값 / 최대값 추출
## 최소값 -> round 함수 적용(소수점 첫째 자리 반올림)
min_revenue = df_stats.loc['min', 'Revenue']
min_revenue = round(min_revenue, 1)
print(f"Revenue 컬럼의 최소값: {min_revenue}")
print('-'*80)
## 최대값 -> round 함수 적용(소수점 첫째 자리 반올림)
max_revenue = df_stats.loc['max', 'Revenue']
max_revenue = round(max_revenue, 1)
print(f"Revenue 컬럼의 최대값: {max_revenue}")
# Revenue 컬럼 -> 최소값 / 최대값 추출
## Revenue 컬럼 인덱싱 -> min() 함수 호출 + round() 함수 호출
min_revenue = df['Revenue'].min()
min_revenue = round(min_revenue,1)
print(f'Revenue 컬럼의 최소값: {min_revenue}')
print('-'*80)
## Revenue 컬럼 인덱싱 -> max() 함수 호출 + round() 함수 호출
max_revenue = df['Revenue'].max()
max_revenue = round(max_revenue,1)
print(f'Revenue 컬럼의 최대값: {max_revenue}')
df_stats.loc['min', 'Revenue]는 discribe()에서 가져옴. describe()는 모든 값을 통일해서 float(실수)로 만들기 때문에 100440.0 / 1999273.0으로 출력됨
df['Revenue].min() 컬럼은 int(정수)이기 때문에 100440 / 1999273으로 출력됨
df['Revenue'].dtype
2026.04.07. 화요일
데이터 탐색
- 분위수 구하기
# Revenue: 요약 통계량 -> 중앙값 추출
median_revenue = df_stats.loc['50%', 'Revenue']
print(f'Revenue 컬럼의 중앙값: {median_revenue}')
# Revenue 컬럼 인덱싱 -> quantile 함수 -> 중앙값 추출
# median_revenue = df['Revenue'].median()
median_revenue = df['Revenue'].quantile(q=0.5)
print(f'Revenue 컬럼의 중앙값: {median_revenue}')

# Revenue 컬럼 분석 : 중앙값과 평균값 비교
## Revenue 컬럼의 중앙값
median_revenue = df['Revenue'].median()
print(f'Revenue 컬럼의 중앙값: {median_revenue}')
print('-'*80)
## Revenue 컬럼의 평균값
avg_revenue = df['Revenue'].mean()
print(f'Revenue 컬럼의 평균값: {avg_revenue}')
- 생성형 AI를 이용한 분석 (요약통계량~분위수)
import pandas as pd
# 1. 데이터 로드
# Google Colab에 파일이 업로드된 상태라고 가정합니다.
# file_path = 'ad_performance.csv'
# df = pd.read_csv(file_path)
# 2. 요약 통계량 산출 (전체 수치형 컬럼 대상)
# describe()를 사용하여 count, mean, std, min, 25%, 50%, 75%, max를 한꺼번에 구합니다.
summary_stats = df.describe().round(1)
# 3. 개별 통계 함수를 이용한 지표 산출
# Cost 컬럼의 평균값
cost_mean = round(df['Cost'].mean(), 1)
# Revenue 컬럼의 최소값 및 최대값
revenue_min = round(df['Revenue'].min(), 1)
revenue_max = round(df['Revenue'].max(), 1)
# Revenue 컬럼의 중앙값 (Median)
revenue_median = round(df['Revenue'].median(), 1)
# --- 결과 출력 ---
print("==================================================")
print("1. 전체 데이터 요약 통계량 (Summary Statistics)")
print("==================================================")
print(summary_stats)
print("\n")
print("==================================================")
print("2. 특정 지표 분석 결과")
print("==================================================")
print(f"• Cost 컬럼의 평균값: {cost_mean:,}")
print(f"• Revenue 컬럼의 최소값: {revenue_min:,}")
print(f"• Revenue 컬럼의 최대값: {revenue_max:,}")
print(f"• Revenue 컬럼의 중앙값: {revenue_median:,}")
print("==================================================")- 표준 편차 구하기
# 방법1: 요약 통계량 이용
std_revenue = df_stats.loc['std','Revenue']
print(f'Revenue 컬럼의 표준 편차: {std_revenue}')
print('-'*80)
# 방법2: Revenue 컬럼 인덱싱 -> std() 호출
std_revenue = df['Revenue'].std()
print(f'Revenue 컬럼의 표준 편차: {std_revenue}')
- 상관 분석
# 상관 행렬 구하기
df_corr = df.corr(numeric_only=True)
print(f'상관 행렬: \n{df_corr}')
# 광고비(Cost)와 매출(Revenue)의 상관 분석
df_cost_revenue = df[['Cost', 'Revenue']].corr()
print(f'광고비와 매출의 상관 계수: \n{df_cost_revenue}')
- 데이터 탐색 연습 문제 (1)
- 데이터 탐색 연습 문제 (2)
탐색적 데이터 분석 (EDA, Exploratory Data Analysis)
- 직선 그래프
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 파이썬 경고 무시 설정 파이썬 경고 무시 설정
import warnings
warnings.filterwarnings('ignore')
# 필요한 라이브러리 / 모듈 임포트
import pandas as pd
import plotly.express as px
# 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/tips.csv'
# DataFrame 생성
df = pd.read_csv(file_path)
display(df)
# 시각화 목표: 요금의 총합과 팁의 관계 비교
## x축: 요금의 총합 컬럼 -> 크기 순(오름차순 정렬: 기본 값)으로 정렬
df_sorted = df.sort_values(by='total_bill')
display(df_sorted)
print('-'*80)
## 그래프 생성 및 출력
fig1 = px.line(data_frame=df_sorted, x='total_bill', y='tip')
fig1.show()
print('-'*80)
## color: time 추가 -> 식사 시간대별로 분석
fig2 = px.line(data_frame=df_sorted, x='total_bill', y='tip', color='time')
fig2.show()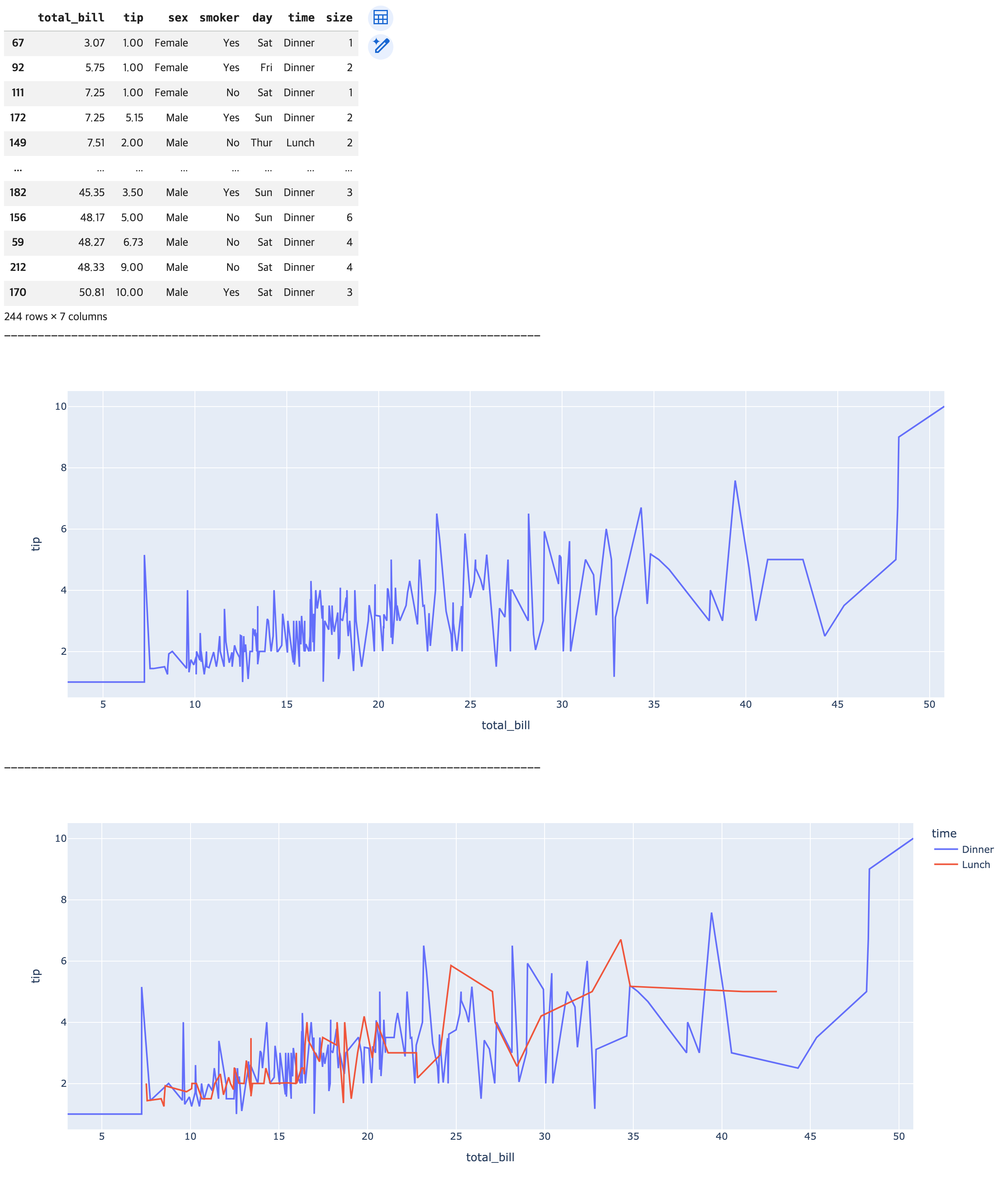
- 막대 그래프 (수직 막대 그래프 / 생성형 AI를 이용한 분석 코드 / 수평 막대 그래프)
# 시각화 목표: 요일 별 평균 요금 비교
## 통계 분석: 요일별 평균 요금(total_bill 평균) 계산 -> 요일별 그룹핑 + total_bill 컬럼 인덱싱 + mean() 함수
day_total_bill_mean = df_grouped = df.groupby(by='day')['total_bill'].mean()
print(day_total_bill_mean)
print('-'*80)
## Series -> DataFrame 변환(행 인덱스 -> 컬럼 + 번호 행 인덱스 추가)
df_day_mean = day_total_bill_mean.reset_index()
display(df_day_mean)
print('-'*80)
## 그래프 생성 및 출력: 요일 -> 알파벳 순으로 정렬(기본값) -> 요일별로 정렬(목,금,토,일)
fig3 = px.bar(data_frame=df_day_mean, x='day', y='total_bill', category_orders={'day':['Thur','Fri','Sat','Sun']})
fig3.show()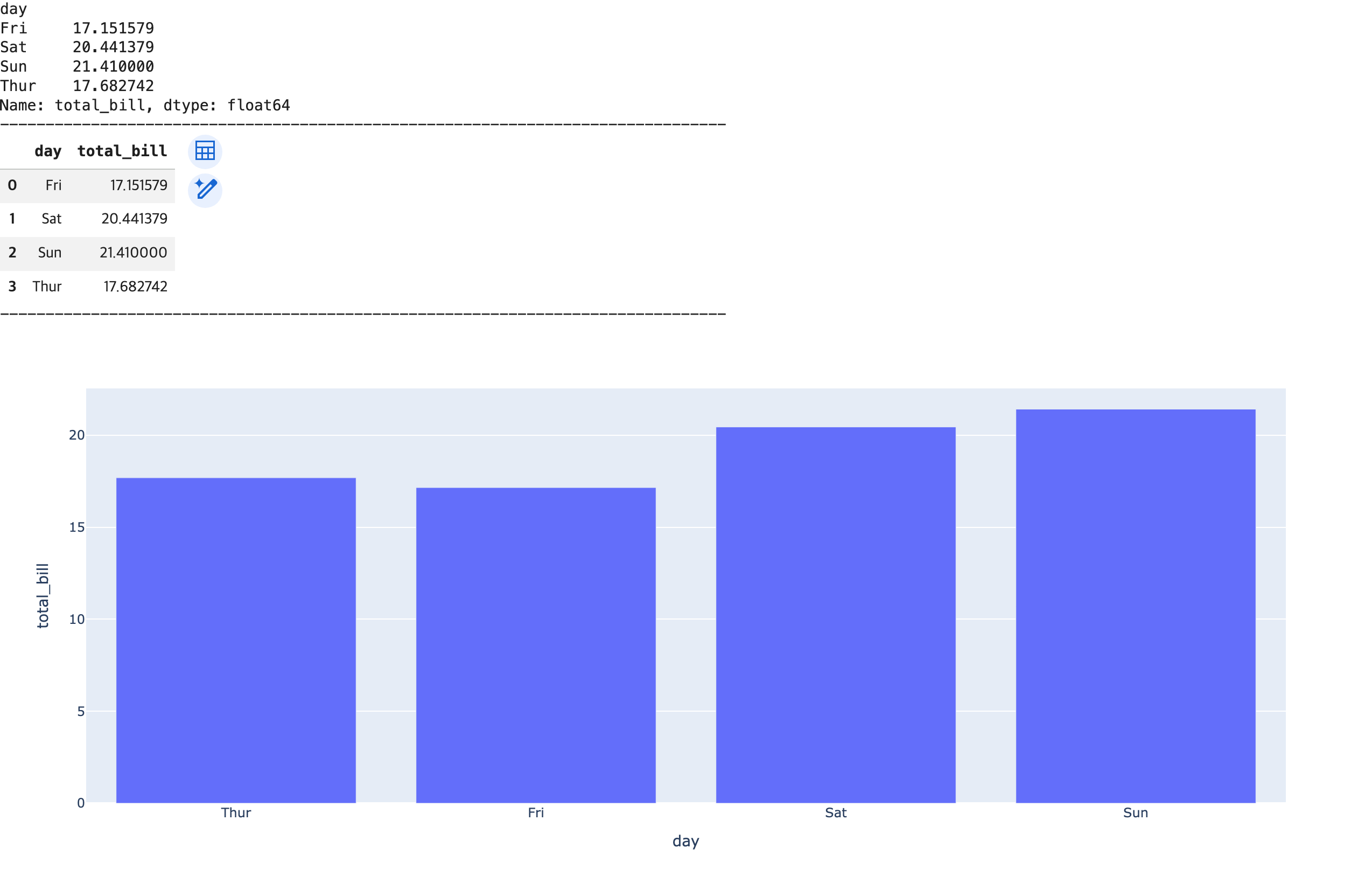
import pandas as pd
import plotly.express as px
# 1. 데이터 불러오기 (파일 업로드 후 진행하거나 경로를 맞춰주세요)
# Colab에서 파일을 직접 업로드했을 경우 'tips.csv' 그대로 사용
# try:
# df = pd.read_csv('tips.csv')
# except FileNotFoundError:
# # 파일이 없을 경우를 대비해 Seaborn 내장 데이터를 샘플로 활용하는 로직
# import seaborn as sns
# df = sns.load_dataset('tips')
# 2. 요일별 total_bill의 평균값 계산
# groupby를 통해 요일별 평균을 구하고 인덱스를 재설정합니다.
df_day_mean = df.groupby('day')['total_bill'].mean().reset_index()
# 3. 요일 순서 정렬 (그래프의 가독성을 위해 목->금->토->일 순으로 정렬)
day_order = ['Thur', 'Fri', 'Sat', 'Sun']
df_day_mean['day'] = pd.Categorical(df_day_mean['day'], categories=day_order, ordered=True)
df_day_mean = df_day_mean.sort_values('day')
# 4. Plotly Express를 이용한 수직 막대 그래프 시각화
fig = px.bar(
df_day_mean,
x='day',
y='total_bill',
title='요일별 평균 결제 금액 (Average Total Bill by Day)',
labels={'day': '요일', 'total_bill': '평균 결제 금액 ($)'},
text_auto='.2f', # 막대 위에 소수점 둘째 자리까지 수치 표시
color='day', # 요일별로 색상 구분
color_discrete_sequence=px.colors.qualitative.Pastel
)
# 그래프 레이아웃 세부 설정
fig.update_layout(
xaxis_title="요일",
yaxis_title="평균 결제 금액 ($)",
plot_bgcolor='white', # 배경색 하얗게 설정
showlegend=False # 범례 숨김 (X축과 중복 방지)
)
# 그래프 출력
fig.show()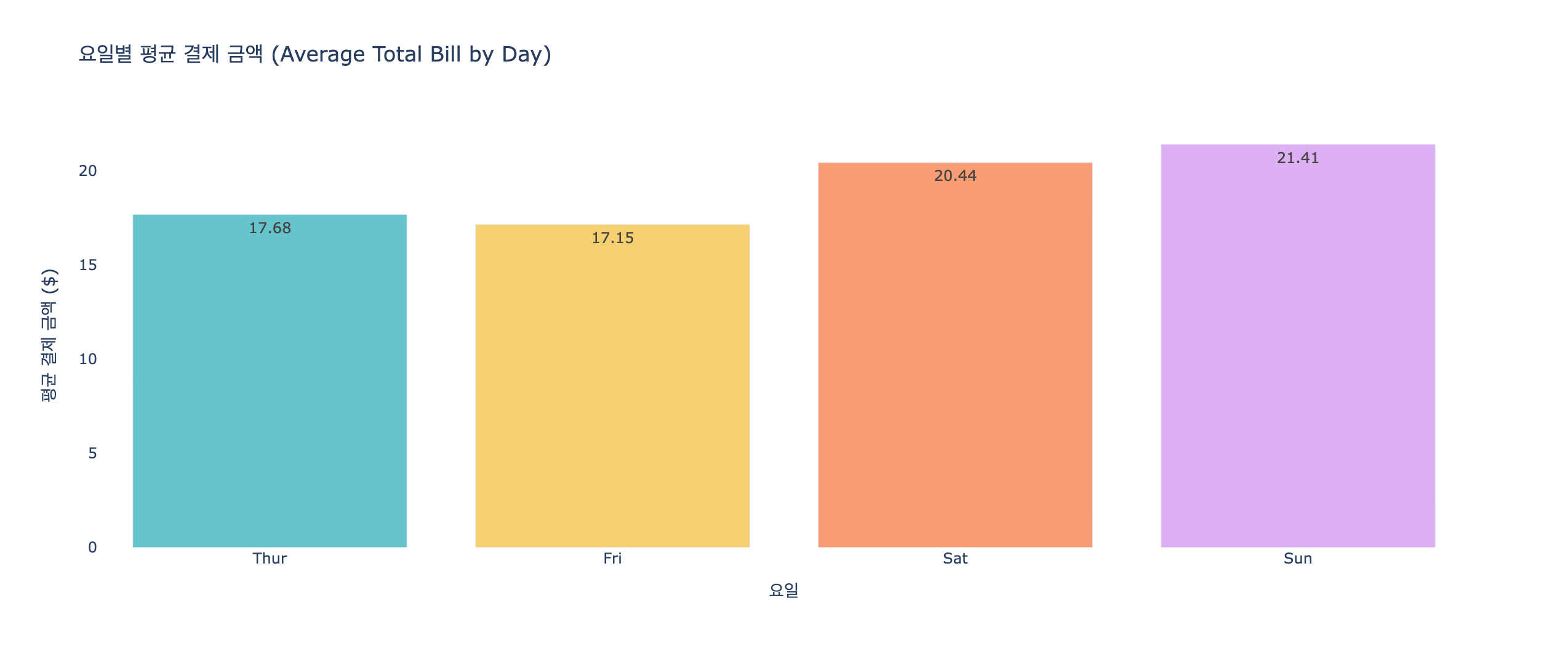
# 시각화 목표: 요일별 total_bill 평균값 비교
## 그래프 생성 및 출력
fig4 = px.bar(data_frame=df_day_mean,
x='total_bill',
y='day',
category_orders={'day':['Thur','Fri','Sat','Sun']},
orientation='h')
fig4.show()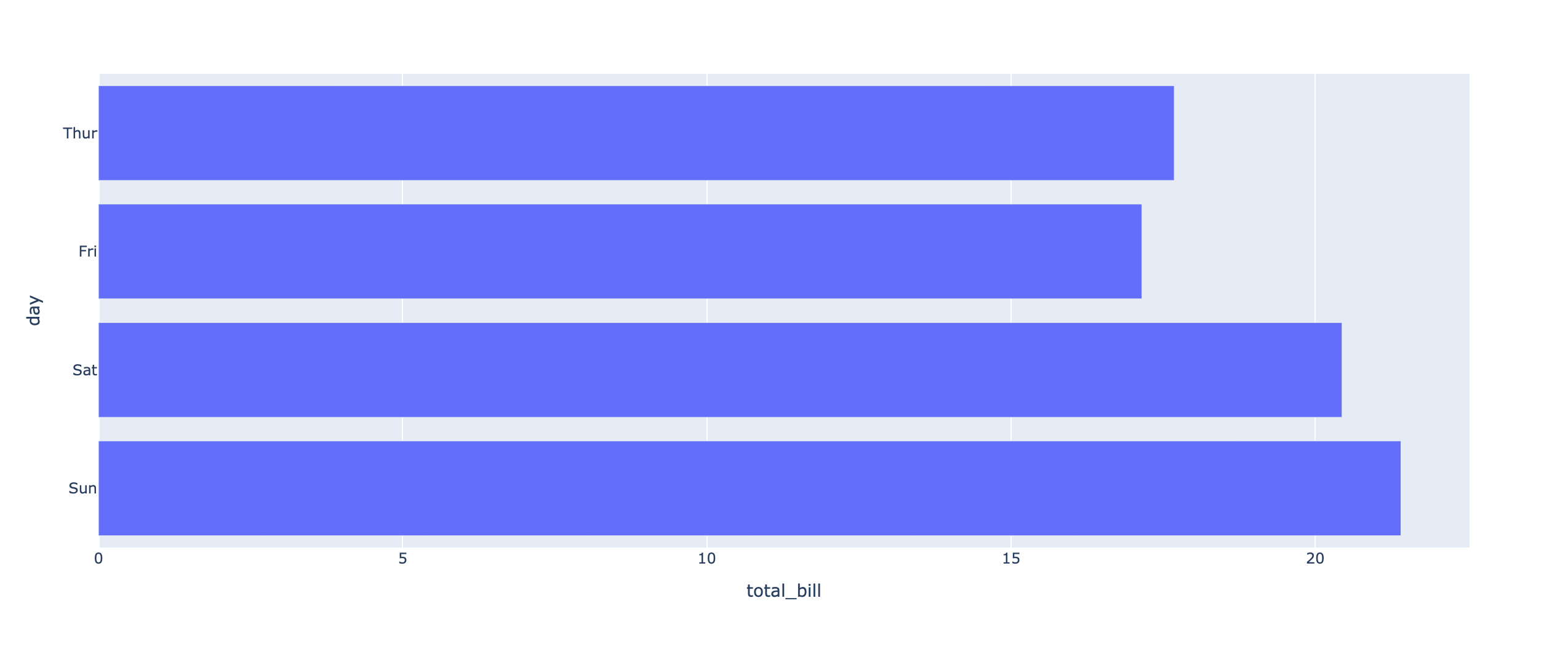
- 원 그래프
# 시각화 목표: 고객의 성별 빈도수를 비율로 비교
## 통계 분석: 고객의 성별 비율 -> 'Sex' 컬럼 인덱싱 + value_counts() 함수
gender_ratio = df['sex'].value_counts(normalize=True)
print(gender_ratio)
print('-'*80)
## Series -> DataFrame 변환(행 인덱스 -> 컬럼 + 번호 행 인덱스 추가)
df_gender_ratio = gender_ratio.reset_index()
display(df_gender_ratio)
print('-'*80)
## 그래프 생성 및 출력
fig5 = px.pie(data_frame=df_gender_ratio, names='sex', values='proportion', hole=0.3)
fig5.show()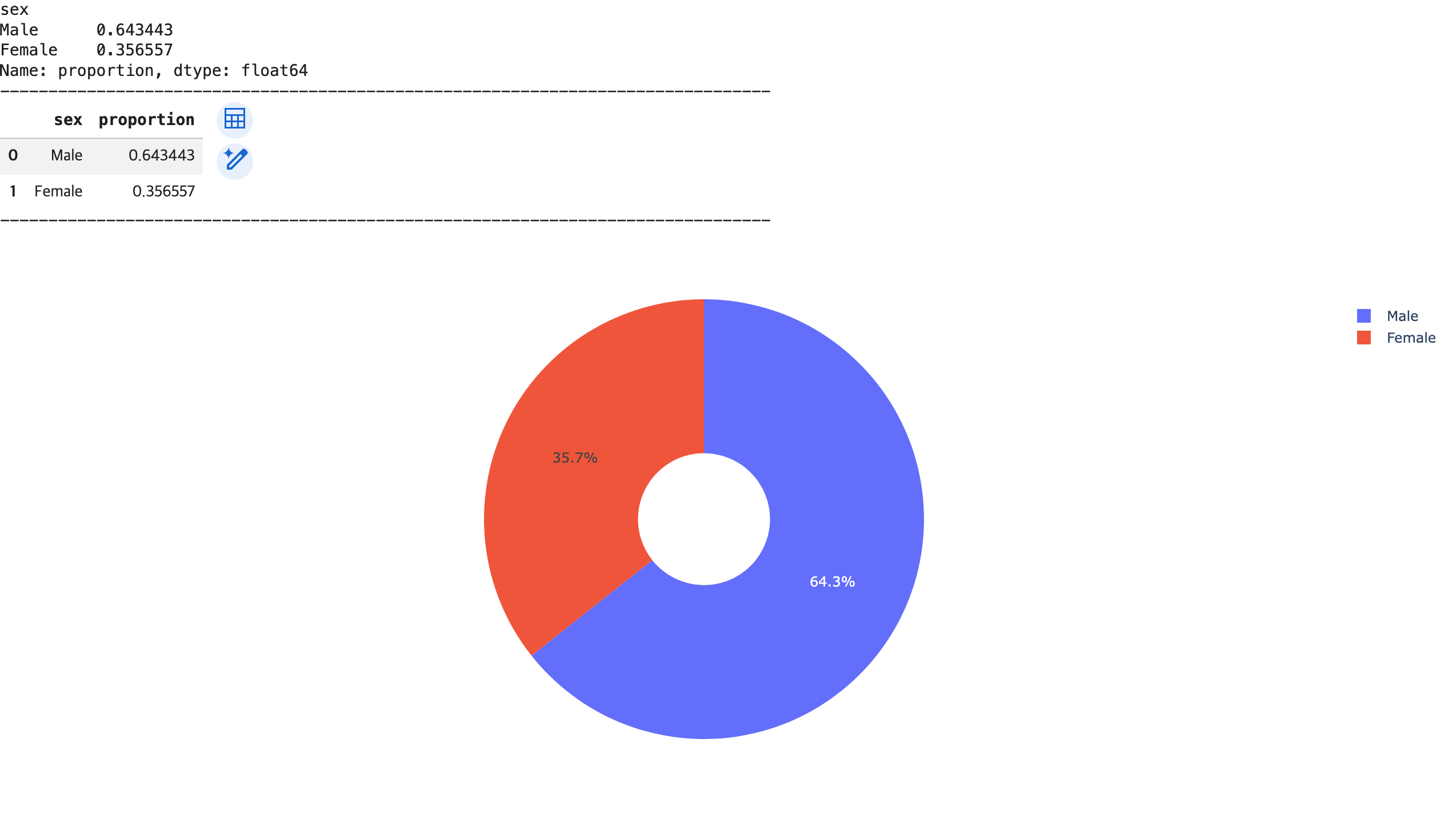
- 히스토그램 (수직 히스토그램 / 수평 히스토그램)
# 시각화 목표: total_bill 금액별 빈도수 비교
print(df['total_bill'].value_counts())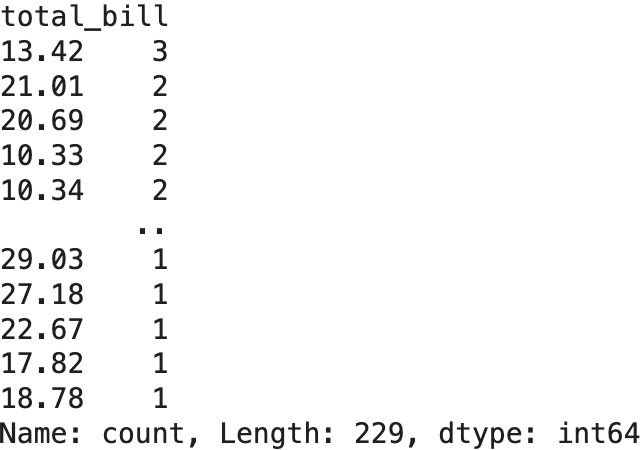
# 시각화 목표: total_bill 금액 구간별 누적 빈도수 비교
## 그래프 생성 및 출력
fig6 = px.histogram(data_frame=df, x='total_bill')
fig6.show()
print('-'*80)
## color='time'추가 -> 식사 시간대별, total_bill 금액 구간별 누적 빈도수 분석
fig7 = px.histogram(data_frame=df, x='total_bill', color='time')
fig7.show()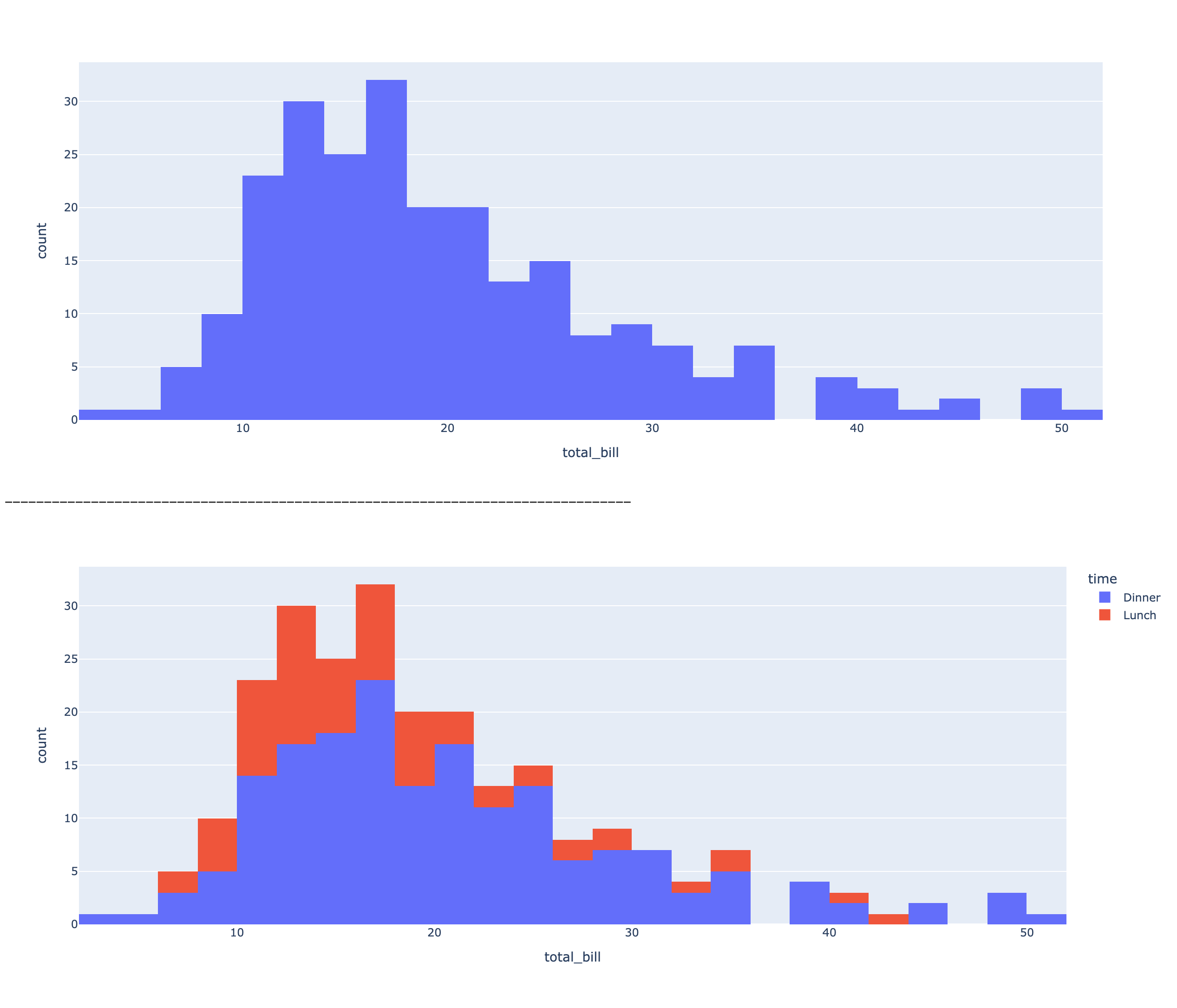
# 시각화 목표: total_bill 금액 구간별 누적 빈도수 비교
## 그래프 생성 및 출력
fig8 = px.histogram(data_frame=df, y='total_bill')
fig8.show()
print('-'*80)
## color='time'추가 -> 식사 시간대별, total_bill 금액 구간별 누적 빈도수 분석
fig9 = px.histogram(data_frame=df, y='total_bill', color='time')
fig9.show()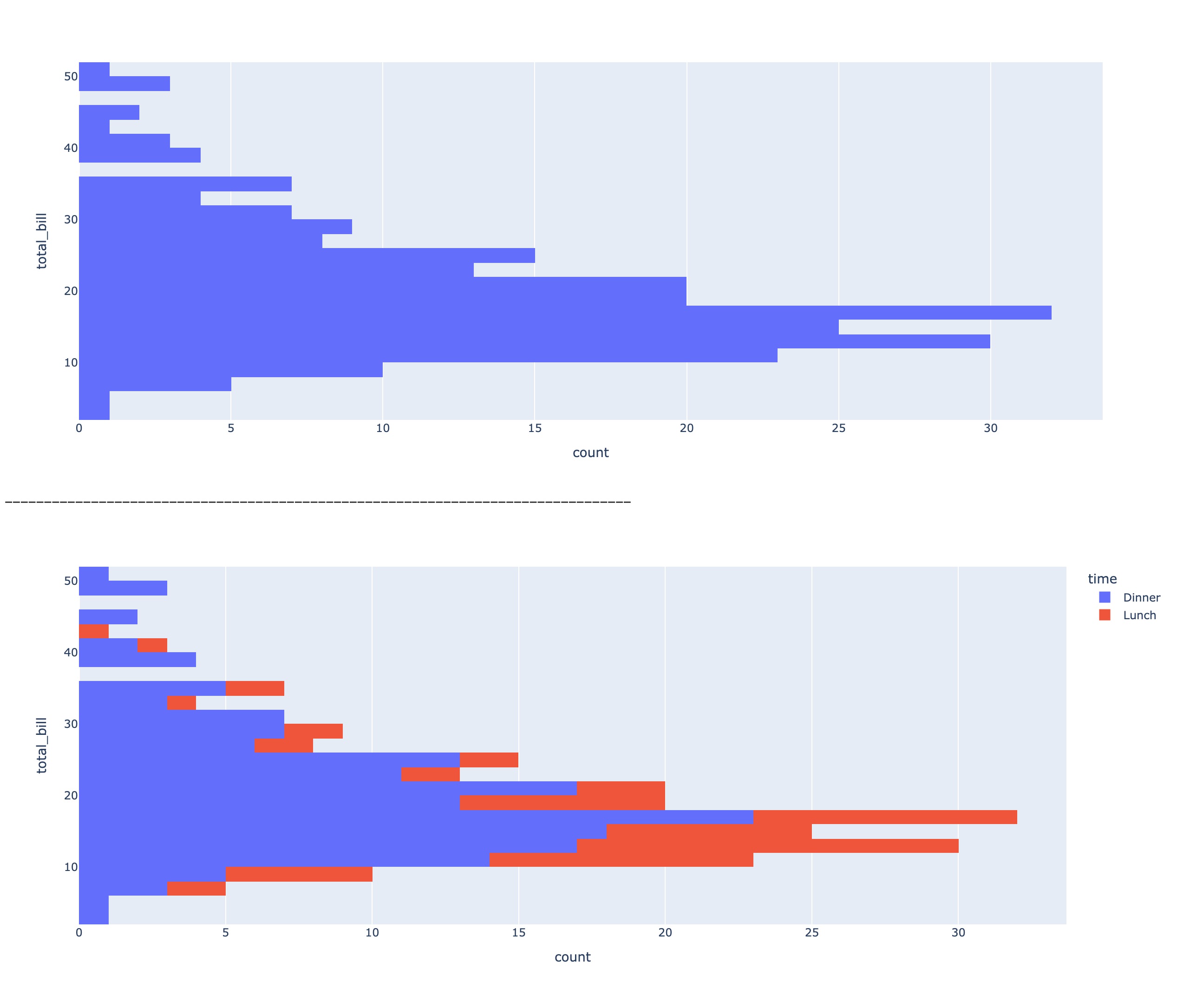
- EDA 연습문제 (1)
2026.04.08. 수요일

Today is... Wine Wednesday 🍷
But... after studying… 😅😂
탐색적 데이터 분석(EDA, Exploratory Data Analysis)
- 박스플롯 (boxplot)
# 시각화 목표: 요일별 tip의 분포 비교
## 수직 그래프 생성 및 출력
fig10 = px.box(data_frame=df, x='day', y='tip', category_orders={'day':['Thur','Fri','Sat','Sun']})
fig10.show()
print('-'*80)
## 수평 그래프 생성 및 출력
fig11 = px.box(data_frame=df, x='tip', y='day', category_orders={'day':['Thur','Fri','Sat','Sun']})
fig11.show()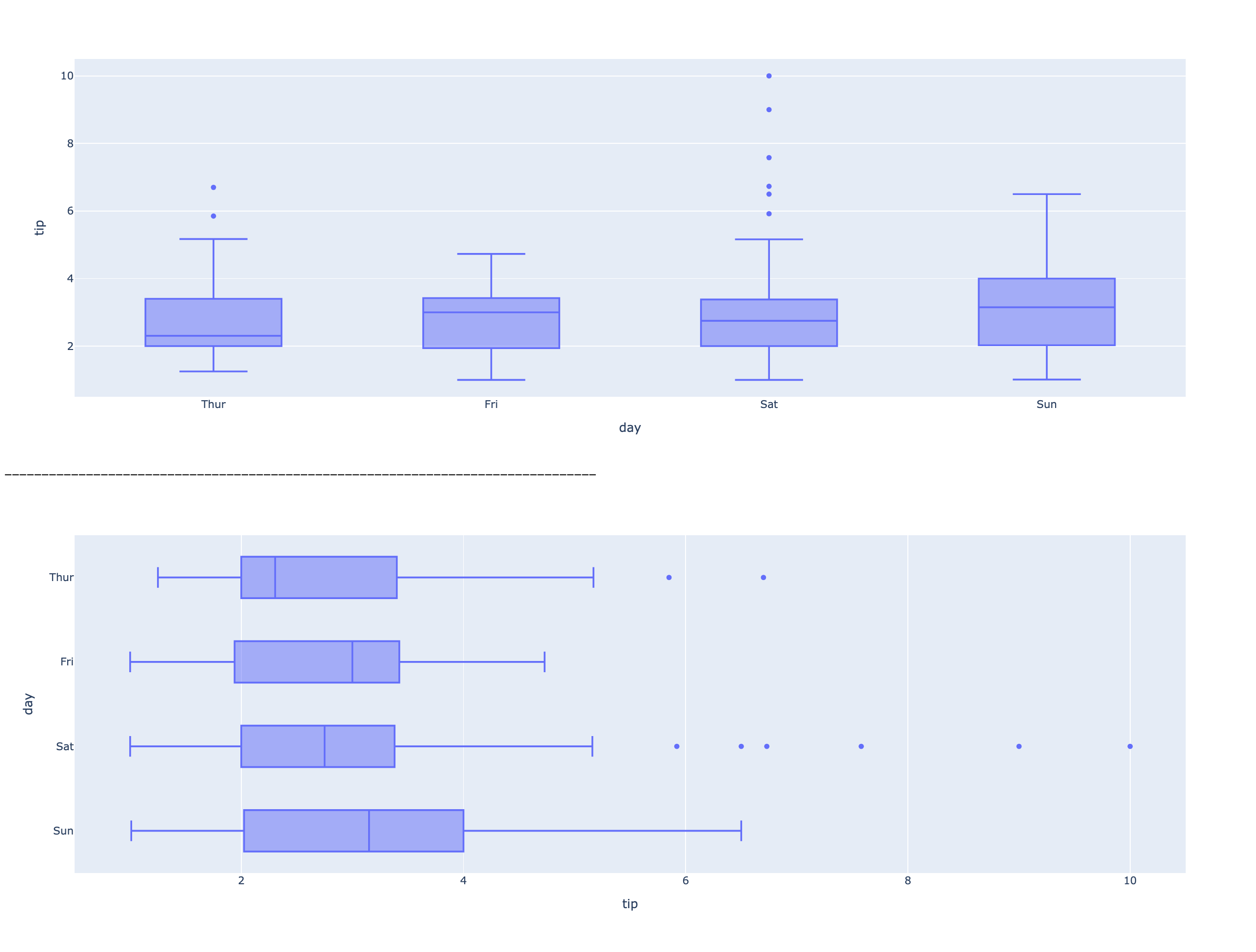
- 산점도 그래프 (scatterplot)
# 시각화 목표: 요금 총합과 팁의 관계(상관 관계)
## 그래프 생성 및 출력
fig12 = px.scatter(data_frame=df, x='total_bill', y='tip')
fig12.show()
print('-'*80)
## color='time' -> 식사 시간대별로 분할 후 요금의 총합과 팁의 관계 분석
fig13 = px.scatter(data_frame=df, x='total_bill', y='tip', color='time')
fig13.show()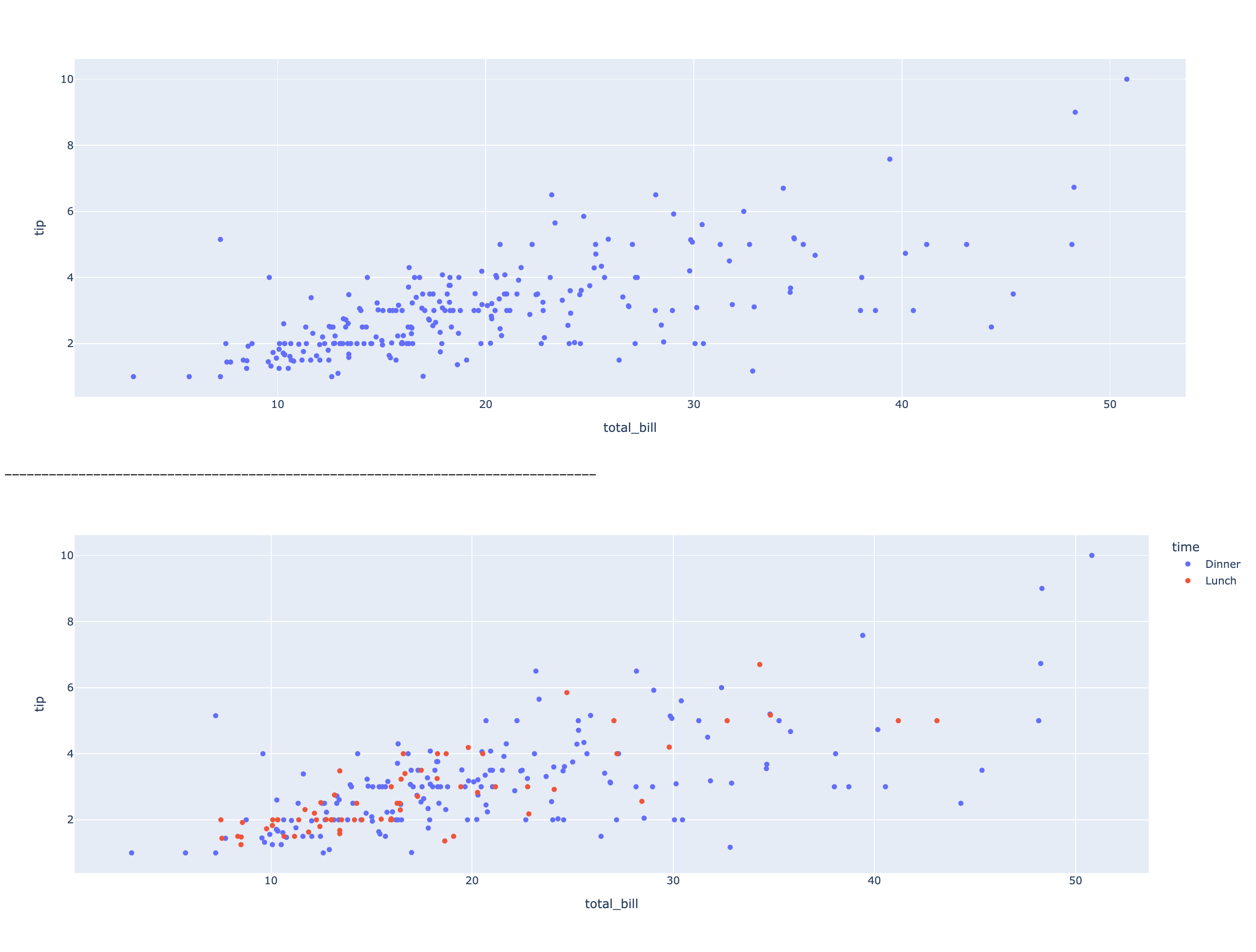
- 히트맵 그래프 (heatmap)
# heatmap 그래프 생성 절차
## 상관 분석 실행 -> 상관 행렬(DataFrame) 생성
df_corr = df.corr(numeric_only=True)
# df_corr = df[['total_bill','tip','size']].corr()
print(f'상관 분석의 결과: \n{df_corr}')
print('-'*80)
## heatmap 그래프 생성 및 출력
fig14 = px.imshow(df_corr, text_auto='.2f', color_continuous_scale='RdBu_r')
fig14.show()
# 그래프 저장: 인터랙티브 html 파일
fig14.write_html('/content/drive/MyDrive/KDT/heatmap.html')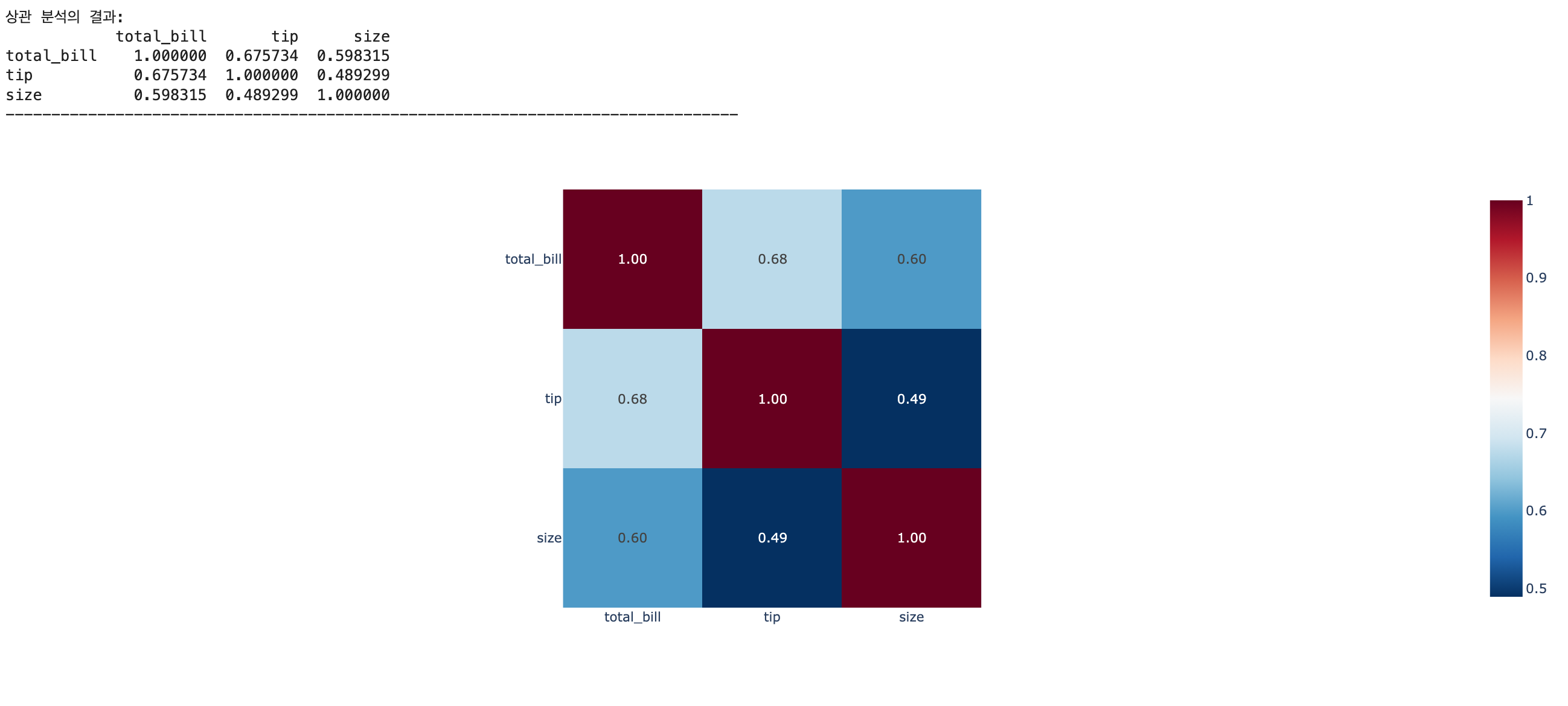
인터랙티브 html 파일 생성은 처음 해봤는데.. 신기하네요..!
- EDA 연습문제 (2)
시계열 데이터 분석
- pd.to_datetime() 함수 → 기능: datetime 자료형으로 변환
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 경고 무시 설정
import warnings
warnings.filterwarnings('ignore')
# 필요한 라이브러리 임포트
import pandas as pd
# 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/ad_performance.csv'
# DataFrame 생성
df = pd.read_csv(file_path)
display(df)
# Date 컬럼의 자료형 변환
## 목표: Data 컬럼 자료형: 문자열 -> datetime
## 변환 전 DataFrame 기본 정보 확인 -> info()
df.info()
print('-'*80)
## 'Date' 컬럼의 자료형을 datetime 자료형으로 변환
df['Date'] = pd.to_datetime(df['Date'])
## 결과 확인
df.info()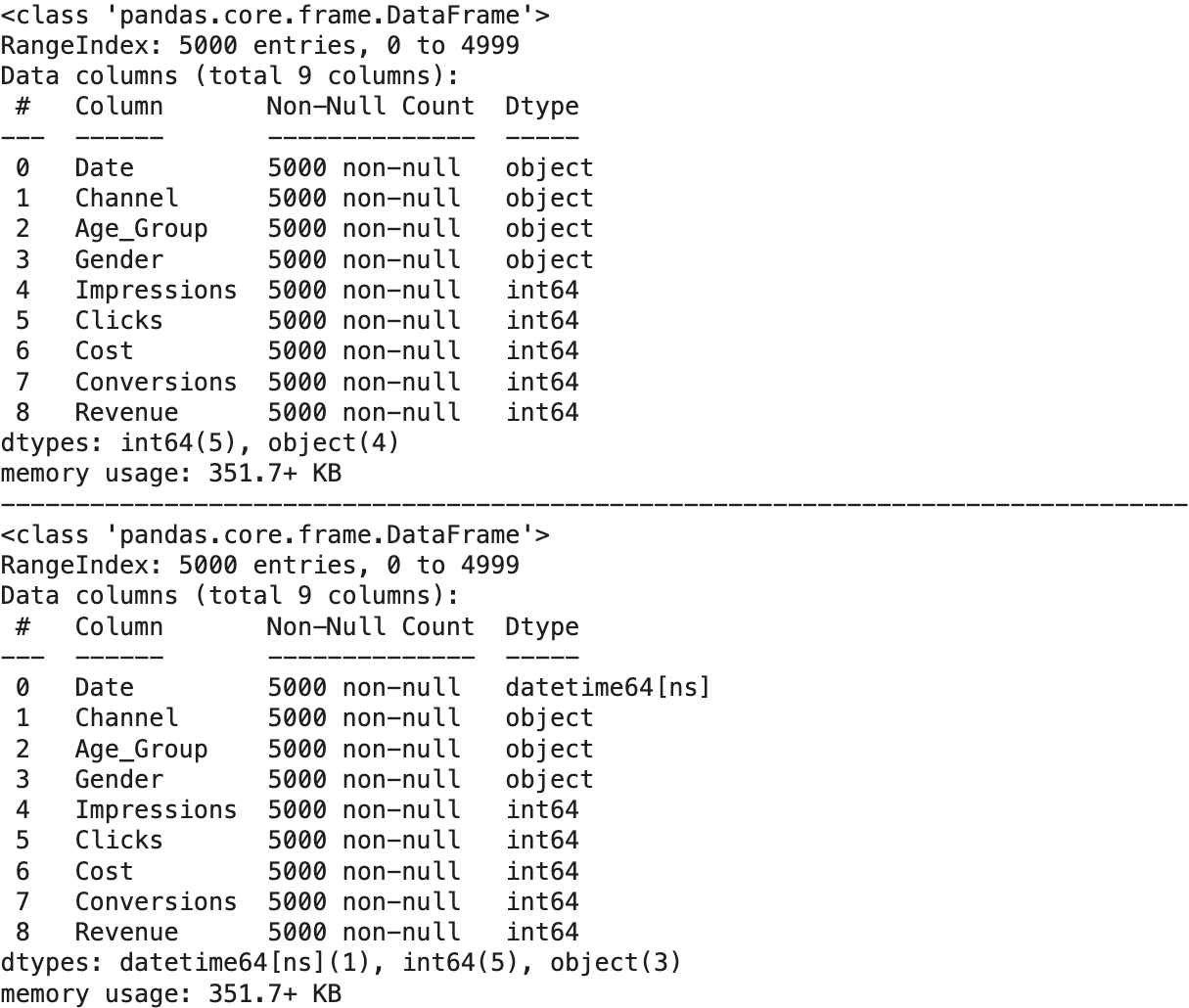
- pd.to_datetime() 함수 - .dt 속성(접근자)
# 'Date' 컬럼 -> 년, 월, 일, 요일 정보를 추출하여 새로운 컬럼으로 추가
## '년도' 정보 추가
df['Year'] = df['Date'].dt.year
## '월' 정보 추가
df['Month'] = df['Date'].dt.month
## '일' 정보 추가
df['Day'] = df['Date'].dt.day
## '요일' 정보 추가
df['Weekday'] = df['Date'].dt.day_name()
## 결과 확인
display(df)
# 월별 총 매출 분석
## 목표: 월 별로 Revenue 컬럼(매출)의 합
### 월 별 Revenue 컬럼(매출)의 합 추출
monthly_revenue = df.groupby(by='Month')['Revenue'].sum()
print(f'월별 총 매출: \n{monthly_revenue}')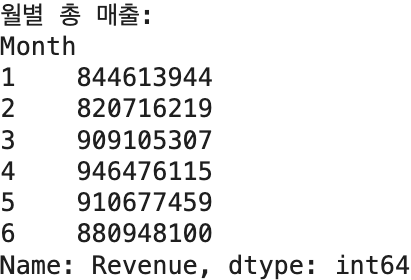
# 월별 총 매출 분석에 대한 시각화
## 필요한 모듈 임포트
import plotly.express as px
## 시각화
### monthly_revenue -> reset_index() 함수 -> DataFrame으로 변환
df_monthly_revenue = monthly_revenue.reset_index()
display(df_monthly_revenue)
print('-'*80)
### 직선 그래프 생성 및 출력
fig1 = px.line(data_frame=df_monthly_revenue, x='Month', y='Revenue', title='Monthly Total Revenue')
fig1.show()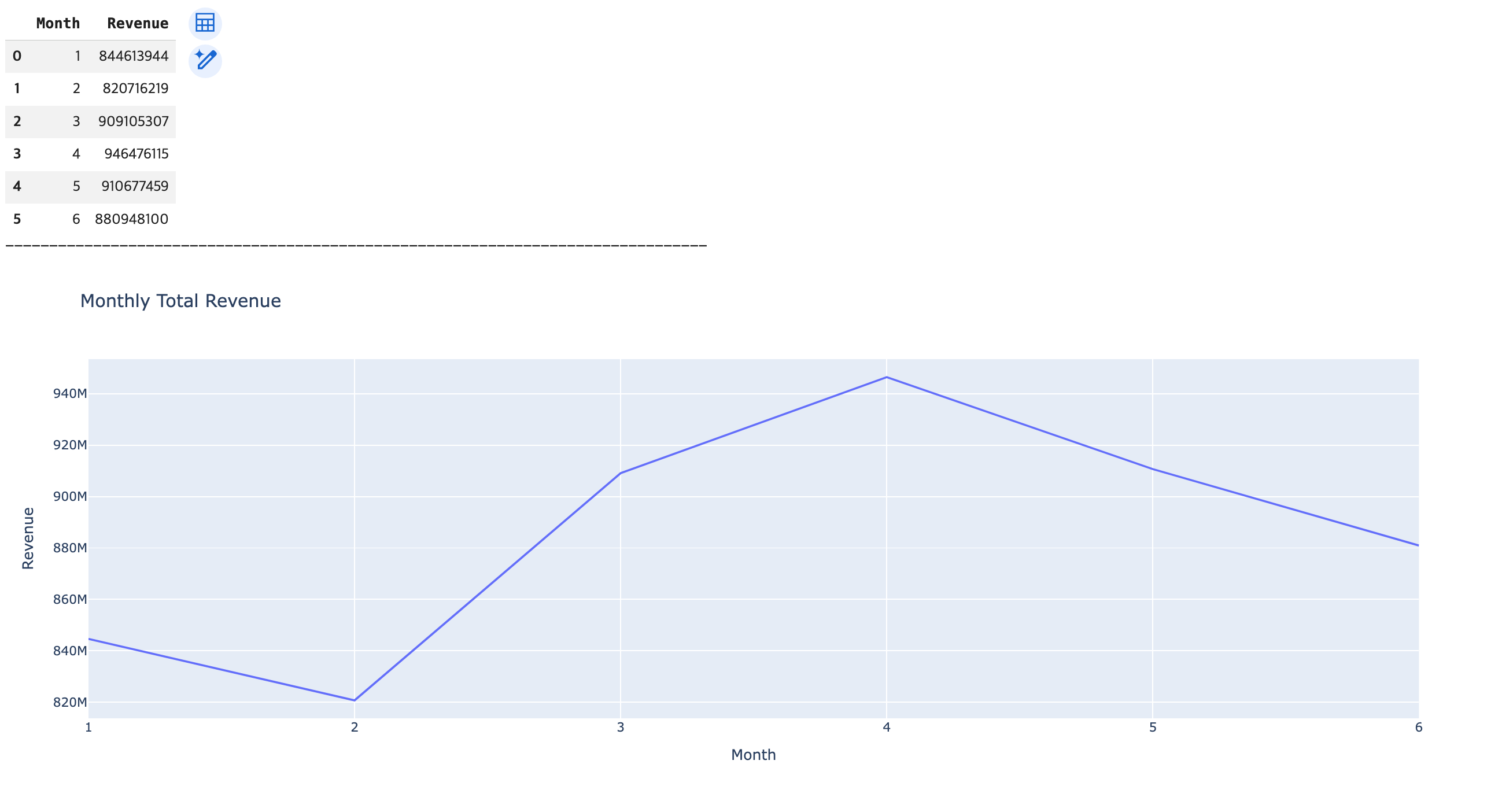
# 요일별 평균 클릭률(CTR) 분석
## 목표: 요일별로 클릭률(CTR)에 대한 평균값 측정
### 요일별로 Clicks와 Impressions의 '총합(sum)'을 계산
df_weekday_ctr = df.groupby('Weekday').agg(
Total_Clicks=('Clicks', 'sum'),
Total_Impressions=('Impressions', 'sum')
)
display(df_weekday_ctr)
print('-'*80)
### 'CTR' 컬럼 생성(파생 변수 생성)
df_weekday_ctr['CTR'] = (df_weekday_ctr['Total_Clicks'] / df_weekday_ctr['Total_Impressions']) * 100
display(df_weekday_ctr)
print('-'*80)
### CTR 컬럼 기준 -> 내림차순 정렬
df_weekday_ctr1 = df_weekday_ctr.sort_values(by='CTR', ascending=False)
display(df_weekday_ctr1)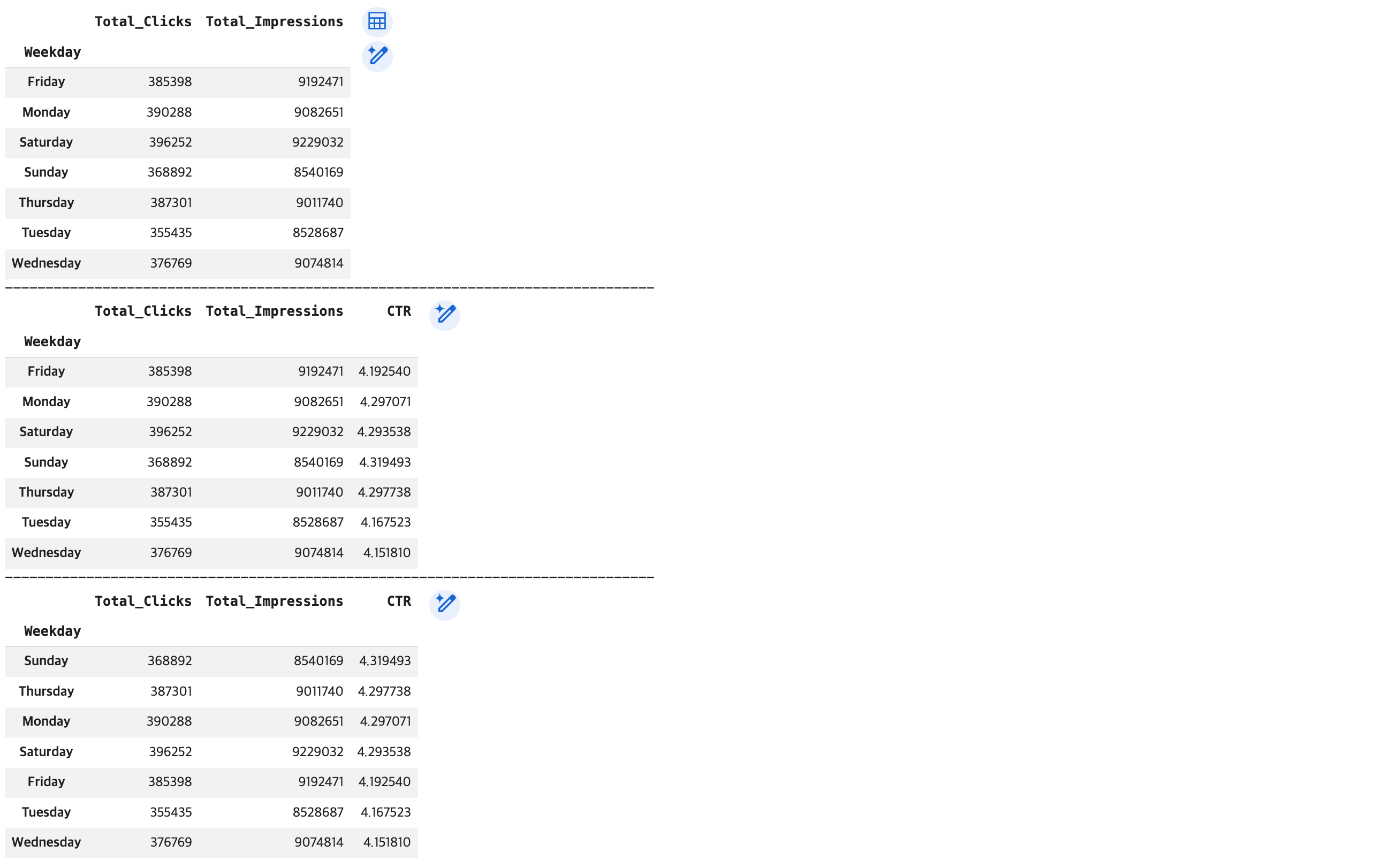
# 요일별 평균 클릭률(CTR) 시각화 -> 생성형 AI 이용
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
# 1. 데이터 로드
# df = pd.read_csv('ad_performance.csv')
# 2. 날짜 데이터 전처리
df['Date'] = pd.to_datetime(df['Date'])
# 요일 추출 (월요일~일요일 순서 정렬을 위해 카테고리형 설정)
days_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
df['Day_of_Week'] = df['Date'].dt.day_name()
# 3. CTR 계산 (클릭 수 / 노출 수 * 100)
# 개별 행 단위가 아닌 요일별 전체 합계 기반으로 평균을 구하는 것이 더 정확합니다.
day_grouped = df.groupby('Day_of_Week').agg({
'Clicks': 'sum',
'Impressions': 'sum'
}).reset_index()
day_grouped['CTR'] = (day_grouped['Clicks'] / day_grouped['Impressions']) * 100
# 요일 순서 정렬
day_grouped['Day_of_Week'] = pd.Categorical(day_grouped['Day_of_Week'], categories=days_order, ordered=True)
day_grouped = day_grouped.sort_values('Day_of_Week')
# 4. Plotly 시각화 (직선 그래프)
fig = px.line(
day_grouped,
x='Day_of_Week',
y='CTR',
title='요일별 평균 클릭률(CTR) 추이',
markers=True,
text=day_grouped['CTR'].apply(lambda x: f'{x:.2f}%'),
labels={'Day_of_Week': '요일', 'CTR': '평균 클릭률 (%)'}
)
# 그래프 디자인 고도화
fig.update_traces(
line=dict(width=3, color='#1f77b4'),
marker=dict(size=10),
textposition='top center'
)
fig.update_layout(
xaxis_title="요일",
yaxis_title="CTR (%)",
hovermode="x unified",
template="plotly_white",
yaxis=dict(ticksuffix="%")
)
# 그래프 출력
fig.show()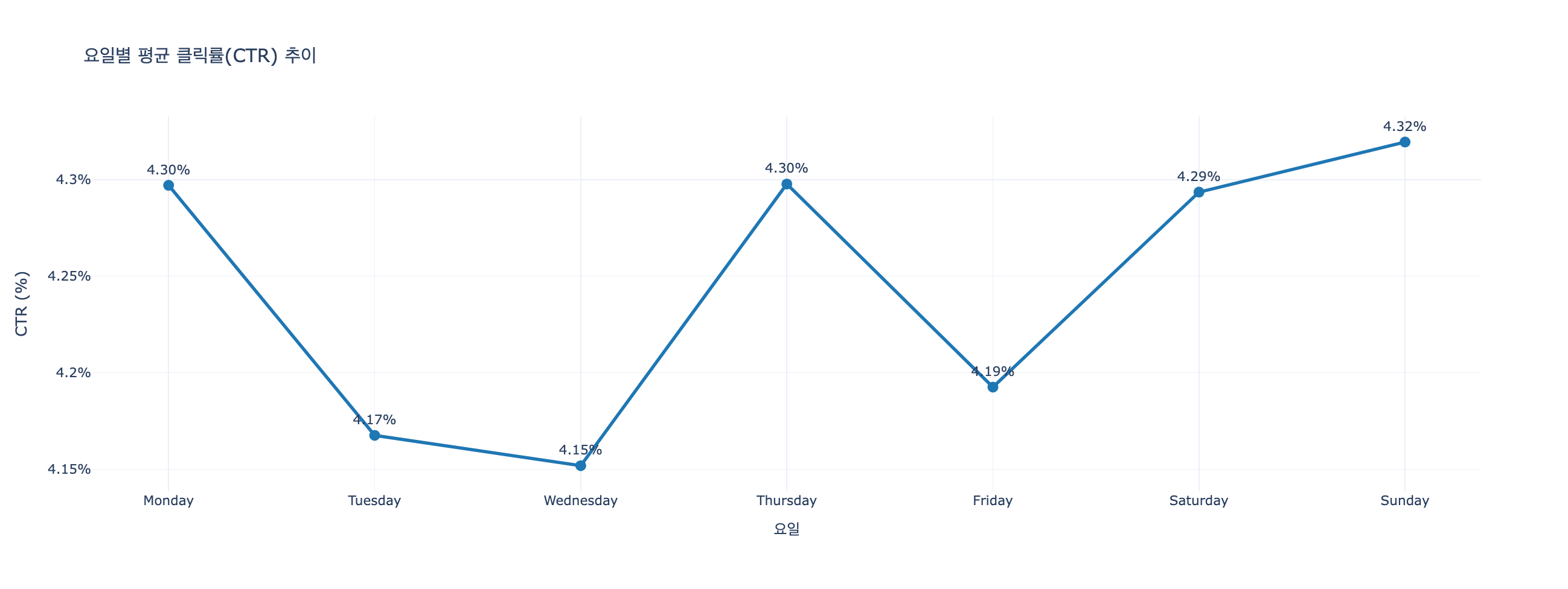
- resample() 함수
# 전제 조건: 수집된 데이터 -> DataFrame 변환 -> pd.to_datetime(df['Date']) 사용
df.info()
# 'Date'컬럼을 인덱스로 설정
df1 = df.set_index('Date')
display(df1)
# 월(Month) 단위로 리샘플링하여 월별 총 매출 계산
## resample('M') 함수 호출 -> 'M'은 'Month'를 의미
monthly_revenue = df1['Revenue'].resample('M').sum()
print(monthly_revenue)
print('-'*80)
## 월별 총 매출 -> reset_index() 함수 -> DataFrame으로 변환
df_monthly_revenue = monthly_revenue.reset_index()
display(df_monthly_revenue)
print('-'*80)
## 직선 그래프 시각화 및 출력
fig2 = px.line(data_frame=df_monthly_revenue, x='Date', y='Revenue', title='Monthly Total Revenue')
fig2.show()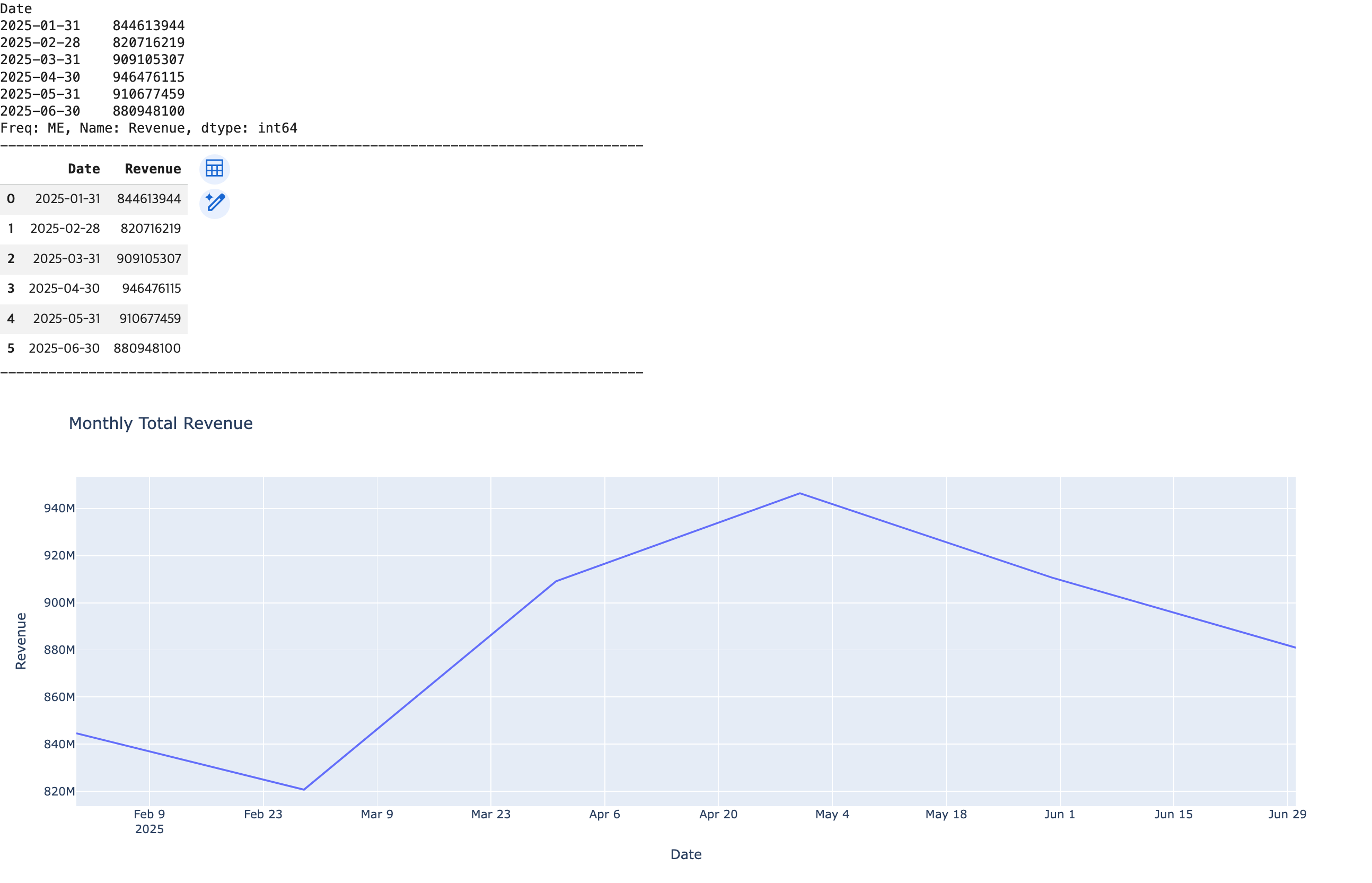
# 월(Month) 단위로 리샘플링하여 월별 총 비용 계산
## resample('M') 함수 호출
monthly_cost = df1['Cost'].resample('M').sum()
print(monthly_cost)
print('-'*80)
## 월별 총 비용 -> reset_index() 함수 -> DataFrame으로 변환
df_monthly_cost = monthly_cost.reset_index()
display(df_monthly_cost)
print('-'*80)
## 직선 그래프로 시각화 및 출력
fig3 = px.line(data_frame=df_monthly_cost, x='Date', y='Cost', title='Monthly Total Cost')
fig3.show()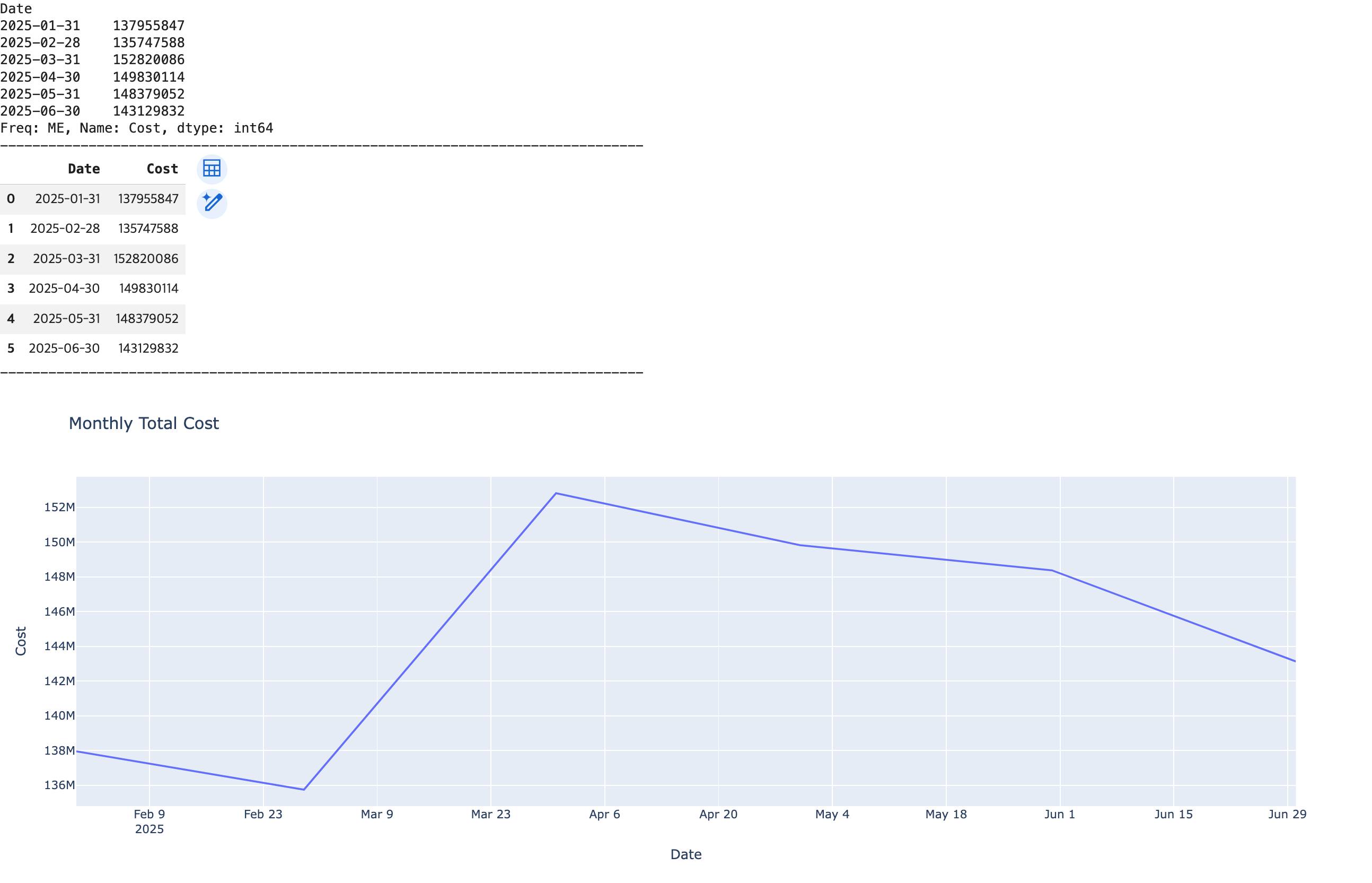
# 월(Month) 단위로 리샘플링하여 월 별 ROAS 계산
## 월 별 ROAS: 월 단위로 계산한 총 매출 / 총 비용 계산
monthly_roas = (monthly_revenue / monthly_cost) * 100
print(monthly_roas)
print('-'*80)
## 월 별 ROAS -> reset_index() 함수 -> DataFrame으로 변환
df_monthly_roas = monthly_roas.reset_index()
display(df_monthly_roas)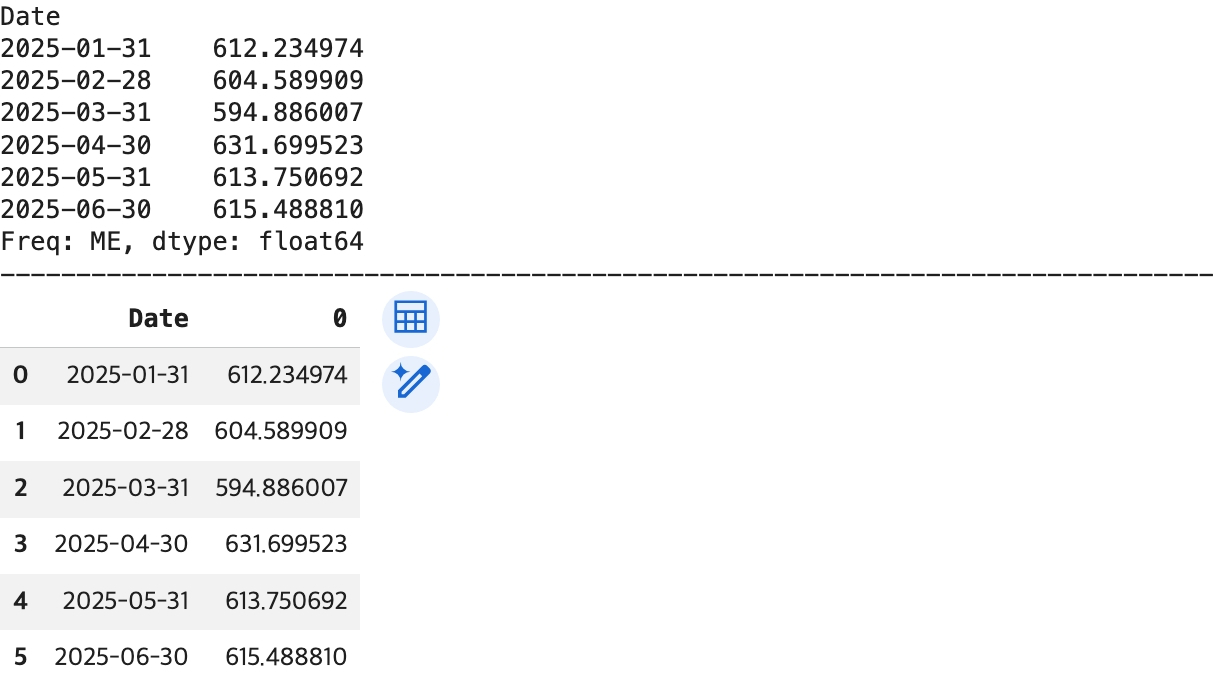
# DataFrame 컬럼 이름 확인
print(df_monthly_roas.columns)
# DataFrame 컬럼 이름 변경
df_monthly_roas.columns = ['Date', 'ROAS']
display(df_monthly_roas)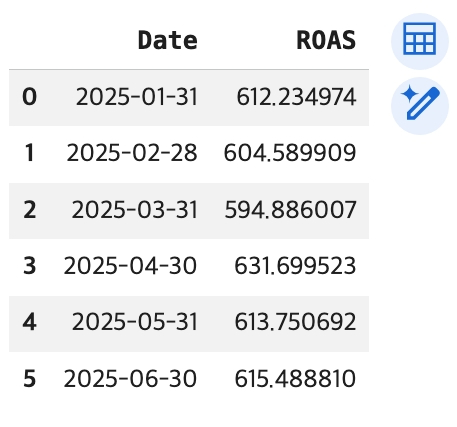
# 월 별 ROAS 시각화
fig4 = px.line(data_frame=df_monthly_roas, x='Date', y='ROAS', title='Monthly ROAS')
fig4.show()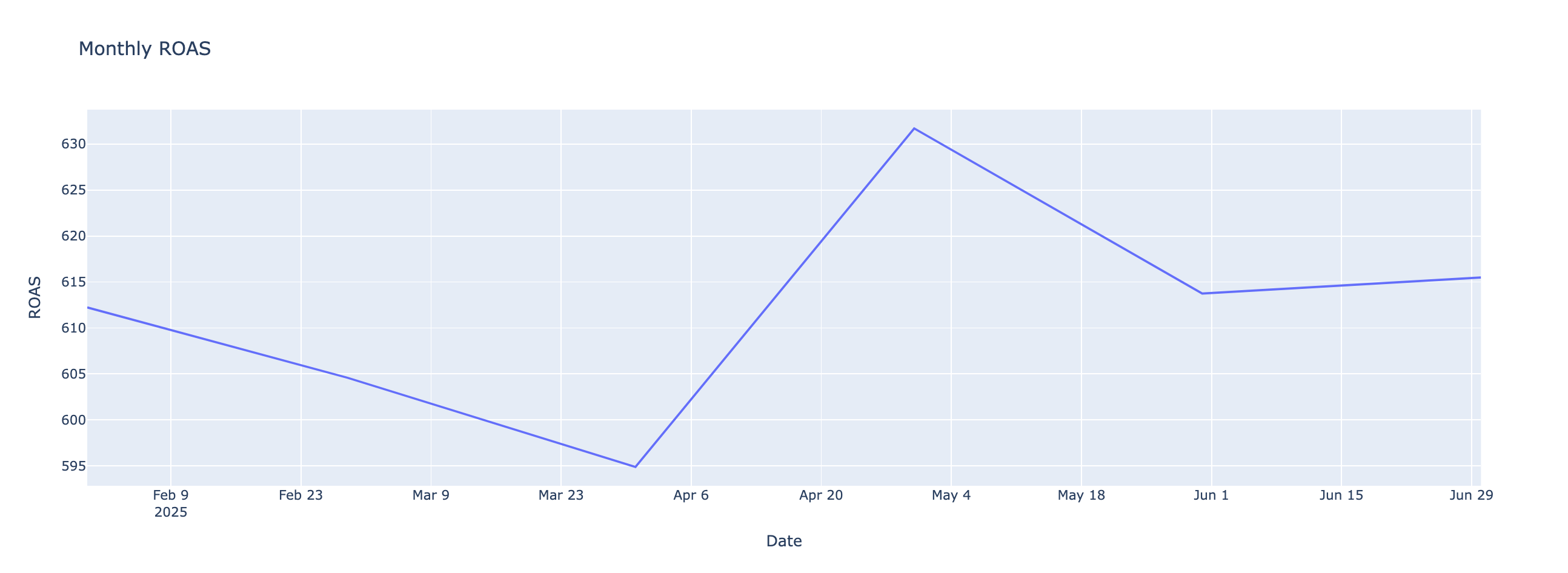
- 정리: 생성형 AI를 이용한 시계열 분석
import pandas as pd
import plotly.express as px
from plotly.subplots import make_subplots
import plotly.graph_objects as go
# 1. 데이터 로드
# df = pd.read_csv('ad_performance.csv')
# 2. Date 컬럼을 datetime 자료형으로 변환
df['Date'] = pd.to_datetime(df['Date'])
# 3. Date를 인덱스로 설정 후 월 별(Monthly) 집계
# Revenue와 Cost는 합계(sum)를 구함
df.set_index('Date', inplace=True)
monthly_df = df.resample('ME').agg({
'Revenue': 'sum',
'Cost': 'sum'
})
# 4. 월 별 ROAS 계산 (Revenue / Cost)
monthly_df['ROAS'] = monthly_df['Revenue'] / monthly_df['Cost']
# 시각화를 위해 인덱스를 다시 컬럼으로 변환
plot_df = monthly_df.reset_index()
# 5. Plotly를 이용한 시각화
# 각 항목(Revenue, Cost, ROAS)의 단위 차이가 크므로,
# facet_row를 사용하여 각 지표를 개별 영역에서 비교할 수 있도록 시각화합니다.
# 데이터 재구조화 (Wide to Long)
melted_df = plot_df.melt(id_vars='Date', value_vars=['Revenue', 'Cost', 'ROAS'],
var_name='Metric', value_name='Value')
fig = px.line(melted_df,
x='Date',
y='Value',
facet_row='Metric',
color='Metric',
markers=True,
title='월별 광고 성과 지표 비교 (Revenue, Cost, ROAS)',
labels={'Value': 'Value', 'Date': 'Month'},
template='plotly_white')
# 각 서브플롯의 Y축 스케일을 독립적으로 설정 (서로 다른 단위 반영)
fig.update_yaxes(matches=None, showticklabels=True)
# 레이아웃 조정
fig.update_layout(height=800, showlegend=False)
# 차트 출력
fig.show()inplace=True : 덮어쓰기
resample('ME') : 월말(Month End) 기준으로 묶기
⭐️ Date ⭐️
처음에 그냥 컬럼
--df.set_index('Date', inplace=True)-->
인덱스(기준축)으로 바뀜
--plot_df = monthly_df.reset_index()-->
다시 컬럼으로!
이렇게 하는 이유 :
resample은 시간 인덱스를 기준으로 동작하기 때문에 먼저 인덱스로 바꾸고, Plotly는 x='Date'처럼 컬럼 기반으로 사용하기 때문에 다시 컬럼으로 되돌림
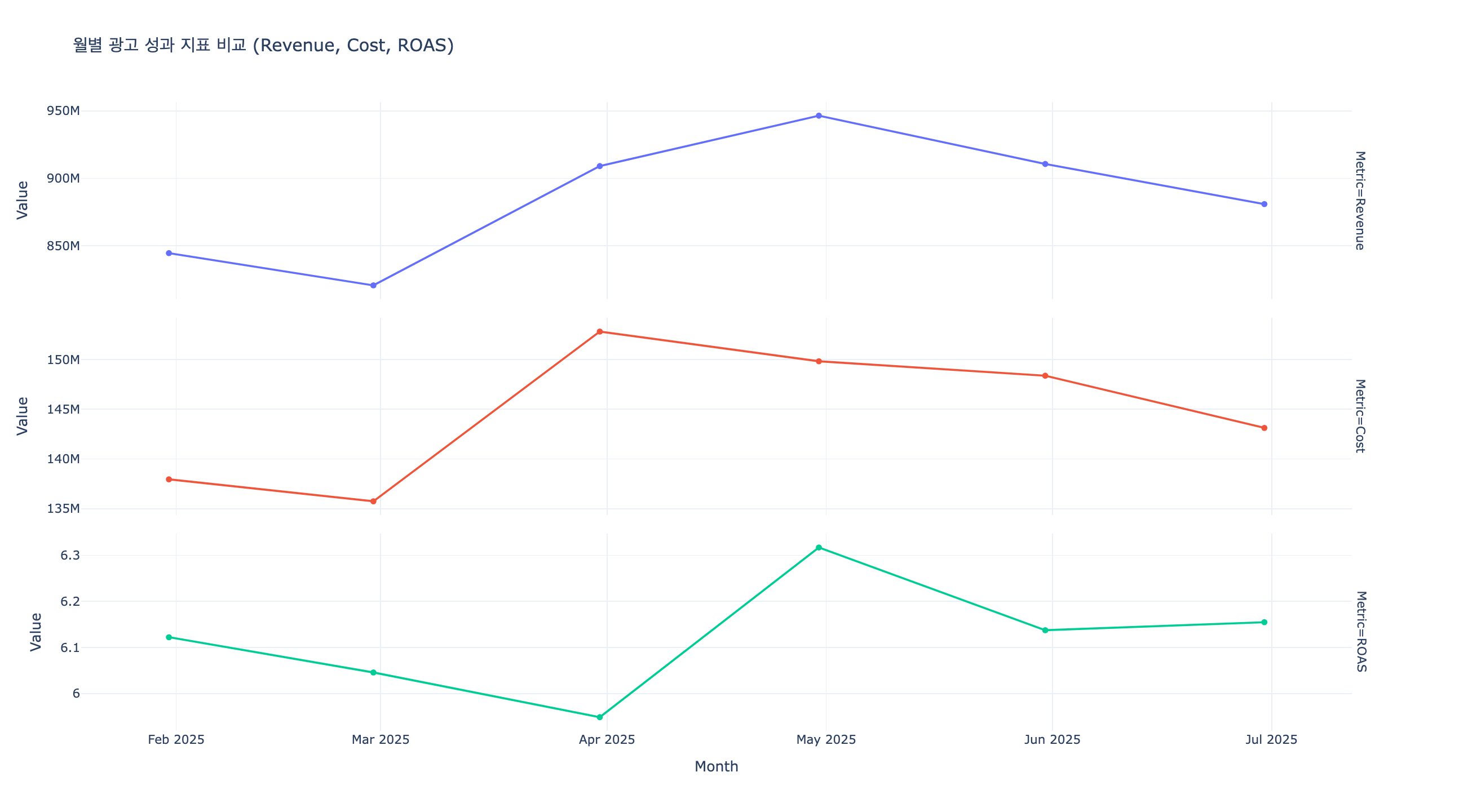
- 연습 문제
2026.04.09. 목요일
- 과제1 (EDA&시계열분석)
- 과제2 (ad_performance_csv 데이터 EDA&시계열분석)
- 과제3 (넷플릭스 사용자 분석)
2026.04.10. 금요일
- 구조화된 바이브 코딩
- 개인별 데이터 분석 코드 생성 지시서 생성 / 생성형 AI를 이용한 분석 코드 생성 및 실행 / 개인별 보고서 생성 지시서 생성 / 생성형 AI를 이용한 보고서 생성
데이터 분석 코드 생성 지시서.txt
1. 분석 배경 및 목적
1) 대상 데이터: ad_performance.csv (마케팅 성과 데이터)
2) 분석 목표: 채널(Naver, Google)과 성별에 따른 성과 차이 비교, 각 채널에서 어떤 성별 타겟이 더 높은 전환율(CVR)과 수익성(ROAS)을 보이는지 파악.
3) 실행 환경: Google Colab (Python 3)
2. 데이터 처리 및 분석 로직 (Logic)
1) 데이터 정제: df_filtered = df[(Channel ∈ {Naver, Google}) AND (Gender ∈ {Male, Female})] → 결측치 및 이상치 제거 후 분석 대상 컬럼만 유지
2) 지표 계산: CVR(전환율) = Conversions / Clicks, ROAS(광고 수익률) = Revenue / Cost
3) 시계열 변환: Date 컬럼을 datetime 형식으로 변환한 후, 주차별(Weekly)로 그룹화하여 CVR와 ROAS를 평균(mean) 기준으로 집계.
3. 시각화 요구사항
Plotly를 활용하여 채널(Naver, Google) × 성별(Male, Female) 조합별, 주차별 CVR 및 ROAS 추이를 Line Chart로 시각화한다.
각 그래프에는 전체 평균선을 추가하여, 특정 시점에서 성과가 평균 대비높거나 낮은 구간을 직관적으로 파악할 수 있도록 한다.
또한, 채널 및 성별별 성과 비교가 용이하도록 색상 또는 라인 스타일을 구분한다.
4. 코드 생성 시 주의사항
Google Colab 환경에 맞춰 한글 폰트 설정 코드를 반드시 포함할 것.
pandas, plotly 라이브러리를 사용할 것.
결과값은 텍스트(Print)와 그래프(Plot)로 모두 출력되게 작성할 것.
친절하고 자세한 주석을 포함할 것.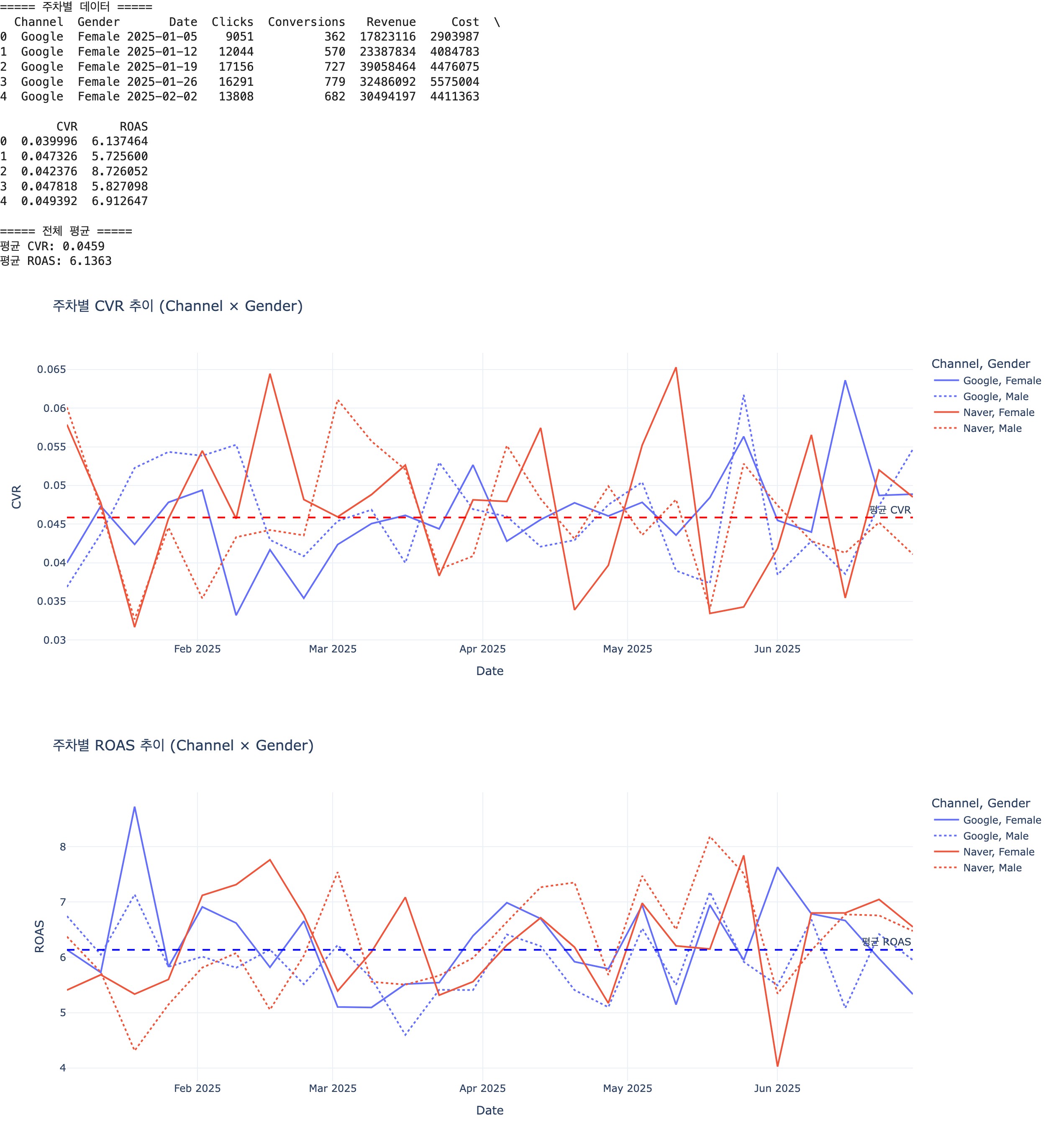
프롬프트
보고서 생성 지시서.txt
1. 보고서 페르소나 및 타겟
1) 작성자: 데이터에 근거해 의사결정하는 10년 차 그로스 마케터.
2) 수신자: 효율적 예산 배분을 고민하는 경영진.
2. 전략 수립 가이드라인
1) 현상 파악: 채널(Naver, Google) × 성별(Male, Female) 조합별 CVR 및 ROAS를 비교하여, 각 채널에서 성과가 높은 주요 타겟과 상대적으로 성과가 낮은 구간을 식별한다. 또한 주차별 추이를 통해 성과의 변동 패턴 및 안정성을 함께 확인한다.
2) 문제 진단: 성과가 낮은 채널 × 성별 조합에 대해 CVR 및 ROAS 관점에서 비효율이 발생하는 원인을 분석한다. 특히 클릭 대비 전환이 낮은 경우(CVR 저조)와 비용 대비 매출이 낮은 경우(ROAS 저조)를 구분하여 문제의 원인을 진단한다.
3) 대안 제시: 성과가 우수한 채널 × 성별 조합에는 예산을 확대 배분하고,
성과가 낮은 조합에 대해서는 타겟 재설정, 광고 소재 개선, 또는 예산 축소 등의 전략을 제안한다.
또한 성과 변동성이 큰 구간에 대해서는 추가 모니터링 및 테스트 전략을 병행한다.
3. 작성 금지 사항
제공되지 않은 수치를 임의로 만들어내지 말 것.
"매우 훌륭하다", "최고다" 같은 모호한 수식어 대신 "ROAS 15% 상승"과 같은 수치 중심 서술을 할 것.
[ 마케팅 성과 분석 및 예산 전략 보고서 ]
1. 개요
분석 대상은 Channel(Naver, Google)과 Gender(Male, Female) 조합이며, 주요 지표는 CVR과 ROAS이다. 분석 기간은 2025년 1월부터 6월까지의 주차별 데이터이다.
2. 핵심 요약
CVR 기준으로는 Google 채널이 상대적으로 안정적인 흐름을 보이며, Naver 채널은 변동성이 크게 나타난다.
ROAS의 경우 두 채널 모두 변동이 존재하나, Naver에서 변동폭이 더 크게 나타난다.
성별 간 차이는 채널 영향에 비해 뚜렷하지 않으며, 특히 Naver 채널에서 변동성이 확대되는 경향이 관찰된다.
3. 현상 파악
Google 채널은 CVR 기준으로 평균 수준 근처에서 비교적 안정적인 흐름을 보이며, ROAS 또한 5~7 수준 범위 내에서 움직이며 큰 변동 없이 유지된다.
Naver 채널은 CVR과 ROAS 모두에서 변동폭이 상대적으로 크게 나타난다. 일부 구간에서는 CVR이 0.06 이상, ROAS가 7 이상으로 상승하는 고성과 구간이 존재하지만, 반대로 CVR이 0.03대, ROAS가 4 수준까지 하락하는 구간도 함께 나타난다.
성별 기준으로는 채널 대비 뚜렷한 차이가 확인되기 어렵고, 특히 변동성은 성별보다는 Naver 채널에서 더 크게 나타나는 경향이 확인된다.
4. 문제 진단
Naver 채널은 CVR과 ROAS 모두에서 변동성이 크게 나타나며, 이는 특정 시점에 성과가 집중되고 지속성이 부족한 구조로 해석된다. 이러한 패턴은 타겟 정합성, 광고 소재 일관성, 또는 특정 캠페인 의존도와 관련이 있을 가능성이 있다.
Google 채널은 전반적으로 안정적인 성과를 유지하고 있으나, 성과 상승 폭이 제한적이며 추가적인 효율 개선 여지는 크지 않은 상태로 판단된다.
성별 기준에서는 일관된 성과 차이가 명확히 나타나지 않으며, 일부 변동은 채널 특성에 의해 발생했을 가능성이 높다.
5. 전략 제안
Google 채널은 CVR과 ROAS 모두에서 안정적인 흐름을 보이므로, 예산 확대를 통한 규모 확장이 적합하다.
Naver 채널은 변동성이 크지만 고성과 구간이 존재하므로, 전체 예산을 상시 확대하기보다는 성과가 확인된 구간 및 캠페인을 중심으로 선택적으로 예산을 배분하는 전략이 필요하다.
특히 Naver 채널에서는 타겟 세분화, 광고 소재 테스트, 랜딩페이지 개선을 통해 성과의 일관성을 높이는 방향의 최적화가 요구된다.
운영 전략 측면에서는 안정형과 테스트형으로 구분하여 접근하는 것이 효과적이다. 전체 예산의 약 70%는 Google 중심으로 안정적으로 운영하고, 나머지 30%는 Naver 채널을 활용한 테스트 및 확장 전략으로 활용한다.
또한 Naver 채널은 주차별 모니터링을 통해 성과 상승 구간에서는 예산을 확대하고, 성과 하락 구간에서는 즉각적인 조정이 가능한 운영 체계를 구축하는 것이 필요하다.
6. 결론
Google 채널은 안정적인 성과를 기반으로 예측 가능한 매출 확보에 적합한 채널로 활용할 수 있다.
Naver 채널은 변동성이 존재하지만 일부 구간에서 높은 성과를 기대할 수 있는 채널로, 성과 기반의 선택적 운영이 요구된다.
따라서 Google 중심으로 안정적인 성과를 확보하면서, Naver 채널은 테스트 및 성과 검증을 기반으로 점진적으로 확대하는 전략이 적합하다.- 종합 문제


개발도, 데이터분석도, 디자인도 애매하게 아는 사람.. 😅