오토인코더의 개요
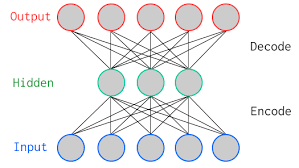
오토인코더는 대표 학습을 수행하는 비지도 학습 기법
간단하게 말해, 이미지의 불필요한 정보를 없애서 학습의 효율을 높이는것,
국가자격증을 딸때, 개념 하나하나 다 공부하는것이 아닌 기출문제로 시험보는 느낌,
개념하나 하나 다 외우는것은 올바를지 모르지만, 자격증을 취득하는데 있어 불필요한 부분들은 줄여서
효율을 늘리는것과 같다.
이미지 데이터셋을 사용하여 CNN이 학습하는 높은 수준의 패턴과 낮은 수준의 특징을 활용한다.
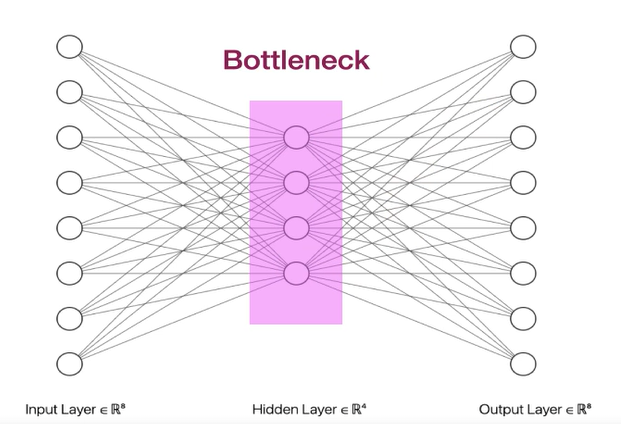
오토인코더 아키텍처
오토인코더 아키텍처에는 병목 계층이 포함

데이터의 차원을 줄여 더 작은 벡터 표현으로 압축하며, 이를 통해 데이터를 효과적으로 압축한다.
요약
오토인코더는 비지도 학습 기법으로, 이미지 데이터를 압축하고 재구성하는 능력을 가지고 있다.
데이터 압축과 잡음 제거, 이미지 복원 등의 다양한 응용에 사용될 수 있다.
CNN을 활용한 오토인코더는 이미지 데이터에서 우수한 성능을 발휘한다.
Keras, PyTorch 에서 이미지를 처리해보고 각자의 특징을 확인하자.
Keras
1. MNIST 데이터셋 로드 및 전처리

MNIST 데이터셋을 로드하고 전처리합니다. 이 단계에서는 데이터셋을 로드하여 정규화하고, 신경망에 입력할 수 있도록 적절한 형식으로 변환합니다.
2. 오토인코더 모델 생성

오토인코더 모델을 생성합니다. 인코더와 디코더 부분으로 나누어 입력 이미지를 작은 차원으로 압축하고, 다시 원래의 차원으로 복원하는 모델을 구성합니다.
3. 오토인코더 훈련

오토인코더를 훈련시킵니다. 훈련 데이터와 검증 데이터를 사용하여 모델을 학습시키고, 학습 과정에서 손실 함수를 통해 모델의 성능을 평가합니다.
4. 오토인코더 예측

훈련된 오토인코더를 사용하여 입력 이미지의 예측을 얻습니다. 오토인코더를 통해 생성된 출력 이미지를 시각화하여 모델의 성능을 평가합니다.
5. 오토인코더를 잡음 제거기로 사용

오토인코더를 잡음 제거기로 사용합니다. 잡음이 추가된 이미지를 입력으로 사용하여 깨끗한 이미지를 복원하는 능력을 평가합니다.
6. 잡음이 있는 테스트 데이터에서 성능 평가

잡음이 있는 테스트 데이터에서 오토인코더의 성능을 평가합니다. 오토인코더가 잡음이 있는 이미지를 얼마나 잘 복원하는지 확인합니다.
PyTorch
-
오토인코더 훈련

에포크가 깊어질수록 Loss의 값이 작아진다. -
압축 결과 표시

이미지의 적지않은 수의 옷들이 약간의 블러(흐림) 현상이나 세부적인 부분에서 품질 저하가 발생 -
원본 이미지 보기

원본 이미지를 표시하여 재구성된 이미지와 비교합니다. 원본 이미지와 복원된 이미지 간의 차이를 확인합니다.
결론
오토인코더(Autoencoder)는 데이터 압축과 복원을 통해 입력 데이터를 학습하는 방법이다.
데이터 압축을 통해 불필요한 정보가 제거되면서, 데이터의 중요한 특성을 유지하면서 불필요한 노이즈나 세부사항을 줄이는 데 사용된다.
전체적으로 원본 데이터와 유사한 형태를 유지하는것이 목표이다.
한마디로 기출문제만 쏙쏙 봐서 시험보는 느낌이다.
