Modern Computer Vision
1.Computer Vision?

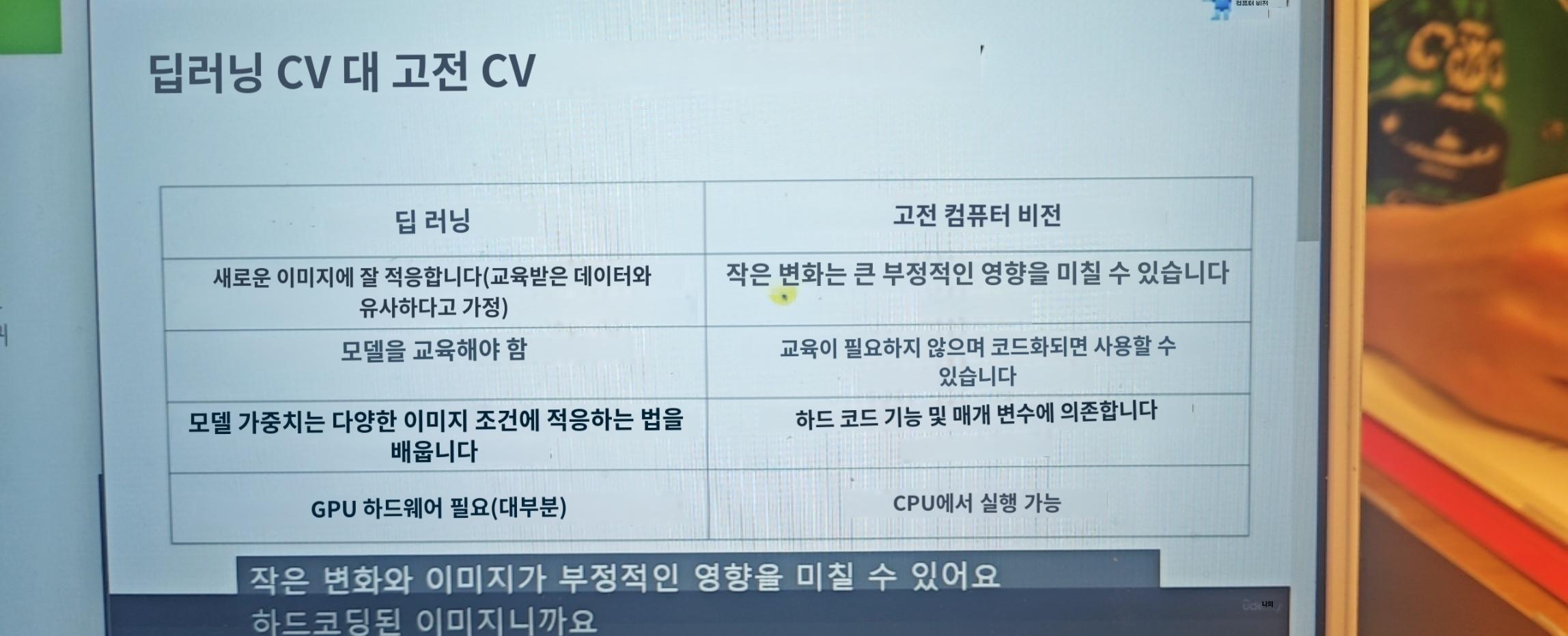
Computer Vision 이란?컴퓨터나 소프트웨어가 이미지와 비디오에서 보이는 것을 이해할 수 있도록 하는것을 목표로 하는것ex)그럼 Computer Vision은 인공지능인가? > YESComputer Vision은 인공 지능의 주요 부분 집합으로 다양한 분야를
2.Computer Vision 2
Computer Vision을 어떻게 만들것인가?가장 많이 사용하는 것중MatlabC++ & Java Python Python을 사용할 것이다. 사용한 이유는 접근이 쉽다 애초에 현대 데이터 과학인 딥러닝 라이버리는 기본적으로 Python 을 염두에 두고 작업하도록 만
3.프로젝트 셋업
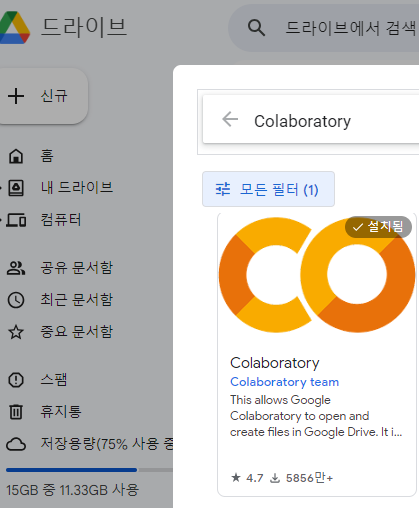
강의에서 제공하는 코드를 다운로드해서 Google Drive에 올려준다. Google Drive에 python 파일을 사용할때 연결 앱을 클릭하면 Google Colaboratory가 뜨는데 해당 툴을 설치해줘야 Drive상에서 사용할 수 있다.Google Drive에
4.OpenCV 시작하기

목표1\. Python에서 OpenCV 모델 가져오기2\. 이미지 로드3\. 이미지 표시4\. 이미지 저장5\. 이미지 치수 가져오기저번에 github에 업로드했던 OpenCV의 첫 챕터의 시작Python에서 OpenCV 모델 가져오기개방형 CV 기능을 사용하기 전에C
5. Grayscaling Images
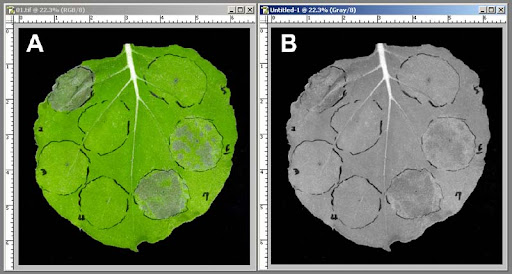
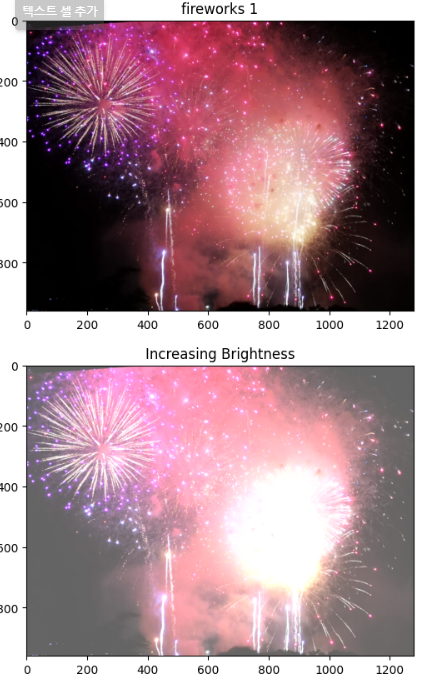
Grayscaling Images? Grayscaling Images 는 이미지를 흑백처리 한다는 말인데, 위의 사진처럼 흑백으로 처리하는것이다.그러면 이걸 왜 사용하냐면계산량 감소RGB는 3차원의 색공간을 가지고 있다. 즉, R : 0~255, G : 0~255,
6.Colour Spaces - RGB and HSV
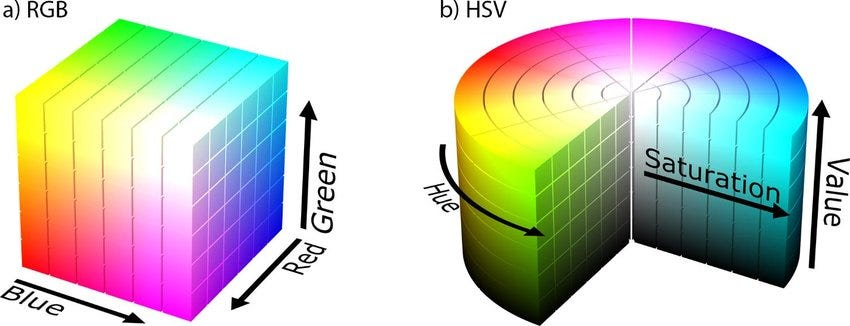
이번시간은 Colour Spaces( 색 공간) 에 대해서 알아본다.RGB와 HSV가 있는데 HSV는 RGB와 색에대해 다른방식으로 표현한 방법으로Hue(색상) Saturation(채도) Value(명도) 세가지의 약자이다.RGB Space사진을 img에 넣어주고 cv
7.Drawing on images
너비랑 높이의 비율을 계산해서 이미지 비율을 망가뜨리지 않고 비율을 조정할수 있게 하는 imshow라는 함수를 생성코드를 설명하자면, BGR 포맷형태로 이미지를 저장하는 cv2의 이미지를 plt에서 사용하려면 RGB의 이미지 포맷형식으로 변경해주는 cvtColor 함수
8.Translations & Rotations
이미지의 크기를 조절할때 가로세로 비율을 계산하고 조절했던것처럼 변환 및 회전도 이미지가 뒤틀리지 않게 조절을 해줘야한다.먼저 imshow라는 함수를 만들어주고 이미지를 다운로드해준다.변환 - Translations 이미지를 translation 하는 코드이다. 그냥
9.Scaling, Re-sizing, Interpolations and Cropping
저번에 이미지를 이동 과 회전을 했었는데, 이번 시간에는 스케일링, 크기 조정, 보간 및 자르기를 볼건데,여기 이미지에서 스케일링과 크기 조정 두 가지는 다른 것 같은데 엄밀히 따지면 아니다.하지만 기본적으로 이미지를 바꾼다는것은 동일하다.이미지 크기를 조절하는 함수부
10.Arithmetic and Bitwise Operations

제목의 뜻은 번역하면 "산술 및 비트 단위 연산" 으로이미지의 강도나 값을 더하거나 빼는 연산이다.그레이스케일 이미지로 이미지를 로드할 예정이다.앞서 라이브러리를 불러오고 이미지를 출력하는 함수를 만드는것은 이전 글에서 설명돼있으므로 생략하겠다.Arithmetic Op
11.Convolutions, Blurring and Sharpening Images

목표컨볼루션 연산블러링노이즈 제거샤프닝컨볼루션 연산 & 블러링 Convolutions 필터링 작업 및 컨볼루션 연산에 사용될 3x3 커널을 생성이미지와 커널간의 컨벌루션을 수행하는 부분인데,컨벌루션이란 두 함수를 결합해서 새로운 함수를 만든다는 뜻이고이미지 처리에서 컨
12.Thresholding, Binarization & Adaptive Thresholding

이번 글의 목표인 original 스캔, 촬영된 사진을 제목에 적힌 기법들을 이용해서 글자랑 배경이랑 구분짓게 만들예정이다.스캔이미지 다운로드위의 original 이미지를 다운로드한다.그리고 다운받은 이미지를 흑백(grayscale)으로 변환하고 출력한다.해당 사진은
13.Dilation, Erosion and Edge Detection

(확장, 침식 및 에지 탐지)오늘 배울 내용은 아래 5가지 이다.DilationErosionOpeningClosingCanny Edge DetectionDilation – Adds pixels to the boundaries of objects in an image이미
14.Contours 1 - Drawing, Hierarchy and Modes

What are Contours?윤곽?정의: "윤곽선은 개체의 전체 경계를 묶거나 덮는 연속선 또는 곡선입니다."pcx508 이라 적혀있으며 우리가 물체의 경계선을 그리거나 곡선으로 그을때 우리가 보여주고 싶은 경계선이 P 정도 라고 가정했을때,윤곽은 가장자리 주변에
15.★ Contours 2 -Moments, Sorting, Approximating and Matching Contours
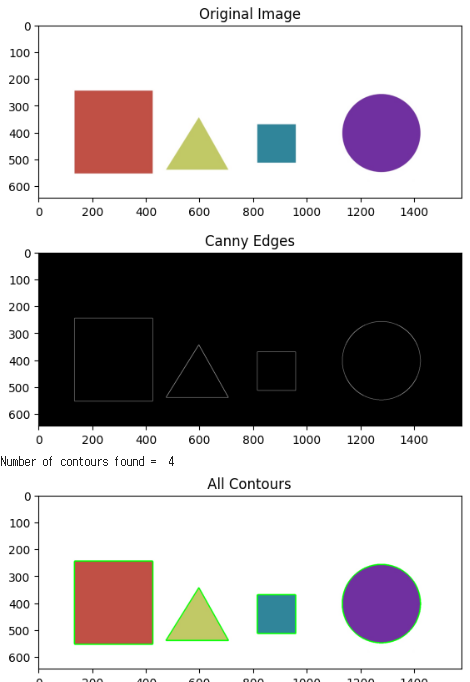
저번 시간에 이어서 이미지의 윤곽을 추출하고 색을 칠해준다.grayscale > canny edge를 사용해서 윤곽을 추출하고 색을 입혀줬다.윤곽을 찾을 때 사용된 인자는 cv2.RETR_EXTERNAL 으로 가장 외각의 윤곽만 찾을때 사용되는 인자를 사용했다.여기서
16.Line, Circle and Blob Detection
이 코드는 이미지에서 직선을 검출하는 Hough 변환을 수행그레이스케일 및 엣지 검출:주어진 이미지를 그레이스케일로 변환하고, Canny 엣지 검출을 사용하여 엣지를 추출이 단계에서는 이미지에서 주요한 선들을 찾기 위해 엣지를 추출하는데 사용Hough 변환 실행:cv2
17.Counting Circles, Ellipses and Finding Waldo with Template Matching

(원형블롭 세는 미니프로젝트)(Template Matching을 이용한 Waldo 찾기 미니프로젝트)이미지에서 내가 원하는 이미지를 찾는 미니 프로젝트이다.이미지 내에 여러 원들이 있겠지만 그중에 내가 원하는것들은 볼록한것과 높은 관성을 가진 원들을 찾아내는것이 목표이
18.Finding Corners
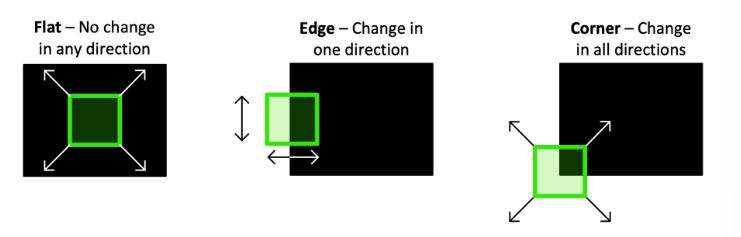
시작하기 앞서,Corner가 무엇일까?코너(모서리)란 이미지 밝기의 급격한 변화인 두 모서리의 접합점으로 해석될 수 있다.아래이미지를 보면 위의 설명이 이해가 된다.Harris Corner Detection은 1988년에 개발된 알고리즘이다.함수는 이렇게생겼고 바로 실
19.Haar Cascade Classifiers를 이용한 얼굴 및 눈 감지

Haarcascade Classifer를 사용하여 얼굴을 탐지하는 방법Haarcascade Classifer를 사용하여 눈을 감지하는 방법Haarcascade Classifer를 사용하여 웹캠에서 얼굴과 눈을 감지하려면 다음과 같이 하십시오웹캠(노트북 웹캠사용)함수 선
20.Vehicle and Pedestrian Detection

자동차 및 보행자 인식
21.원근법적 변환 - Perspective Transforms

OpenCV의 get Perspective Transform 사용 찾기를 사용하여 모서리를 찾고 관점 전환 자동화
22.Histogram 표현

분포의 정보를 담고있는 Histogram에 대한 공부Histograms and K-Means Clustering for Dominant Colors이미지의 RGB 히스토그램 표현 보기K-평균 클러스터링을 사용하여 지배적인 색상과 비율을 이미지로 표시해당 이미지의 색상
23.이미지 비교
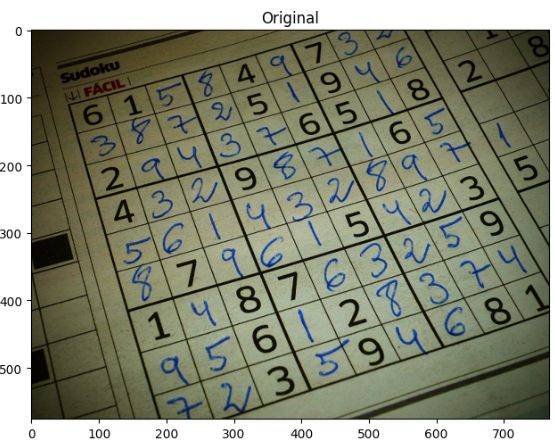
Comparing Images MSE and Structual Similarity평균 제곱 오차(MSE)을 이용해서 이미지를 비교하는 법구조적으로 유사한 이미지를 비교하는 법을 공부할 예정이다.두 이미지 간의 MSE는 두 이미지 간의 차이 제곱의 합이다. 이는 nump
24.Filtering Colors
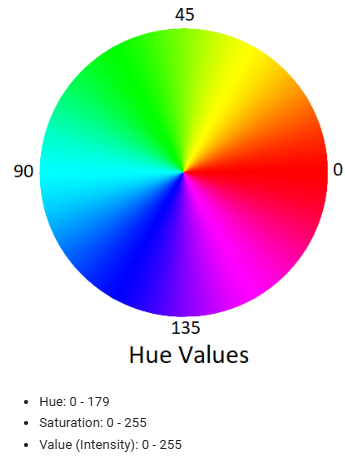
HSV 색공간을 이용하여 색별로 필터링하는 방법색조 채도 명도 값을 갖는 HSV 색공간을 이용해서 필터를 할것이다.RGB가 아닌 HSV를 사용해서 필터하는 이유는 RGB는 조합에 따라 바뀌는 색이 많아서 어렵기 때문이다.해당 이미지의 파란색 부분만 표현하는것이 목표그러
25.유역 알고리즘 마커 기반 영상 분할

Watershed Algorithm for marker-based image segmentationWatershed 알고리즘을 사용하여 이미지 세그멘테이션을 수행이미지 세그멘테이션이미지에서 특정 객체 또는 물체를 식별하고 분할하는 프로세스를 의미Watershed 알고리
26.배경 및 전경 제거
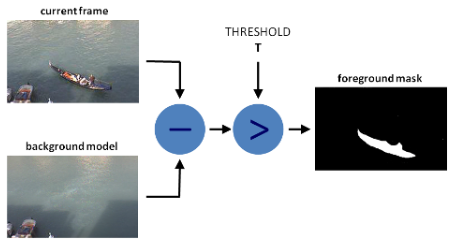
가우시안 혼합물 기반 배경/전경 분할 알고리즘을 이용해서 이미지의 사람을 지운다.아래 사진에서 사람을 지우기 위해 배경/전경 분할 알고리즘을 사용했다.처음 넣은 사진에서는 사람들이 확실하게 보이는데알고리즘이 적용된 사진은 낮은 수준이지만 사람이 조금 희미해진게 보인다.
27.모션 트래킹

한글로 번역하면 "평균 이동" 이며 객체 추적에 사용되는 알고리즘이다.작은 윈도우(박스)에서 시작해 윈도우 내에 픽셀 밀도가 가장 높은곳으로 이동한다.이렇게 밀도가 가장 높은곳으로 이동하고, 결국 수렴할 때까지 이 과정을 반복한다.아래 애니메이션을 보면 이해하기에 도움
28.Object Tracking with Optical Flow
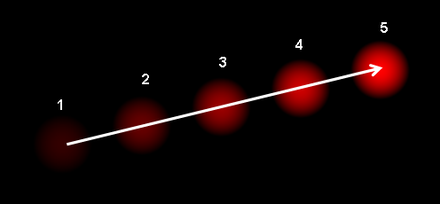
OpenCV에서 광류를 사용하는 방법고밀도 광학 흐름을 사용연속된 5개의 프레임으로 움직이는 공을 보여주는데, 화살표는 그것의 변위 벡터를 보여준다.변위 벡터를 보여준다는 뜻은 객체의 움직임을 시각화 한다는 뜻이다.이번시간에 배우는것은 빛을 이용해서 객체의 움직임을 시
29.색상별 단순 객체 추적

HSV 컬러 필터를 사용하여 마스크를 만든 다음 원하는 개체를 추적(How to use an HSV Color Filter to Create a Mask and then Track our Desired Object)https://youtu.be/KJmd92nA
30.얼굴 인식 - 얼굴 랜드마크 예측 모델 사용
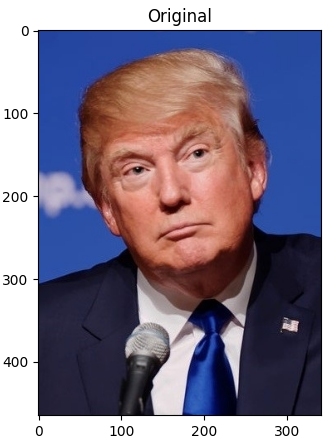
얼굴 이미지와 얼굴 랜드마크를 예측하기 위한 모델을 다운로드해당 인물의 얼굴에서 특징들을 감지하고 아래와 같이 주석을 달아준다.해당 기술을 이용해서 눈을 감았는지 입을 열었는지와 같이 얼굴의 특징을 표현할 수 있다.A. PREDICTOR_PATH얼굴 랜드마크를 예측하기
31.얼굴 인식 - Face Swapping

저번 포스팅의 Facial Landmark Detection with Dlib 을 이용해서 얼굴의 특징을 랜드마크 했다면두 이미지의 랜드마크를 서로 바꾼다.결론부터 확인하면 서로 얼굴이 바뀌어 있는것을 확인할 수 있다.각 이미지에서 얼굴 랜드마크를 감지하고 얼굴 특징을
32.Tilt Shift Effects

두 개의 이미지를 섞어서 새로운 이미지를 생성하는 이미지 블렌딩 기술을 구현이미지에 강조하고싶은 부분을 강조하기 위해 특정 위치를 제외한 나머지 부분을 블러 처리한다.
33.배경 제거를 위한 GrabCut 알고리즘

정보처리기사 필기를 시험보고 일주일정도 완전히 쉬어버렸다. 기간으로 보니 공부기간과 쉰 기간을 포함해 2주동안이나 computer vision을 하지 않았으니 다시 공부를 시작하자.
34.PyTesseract, EasyOCR를 이용한 OCR
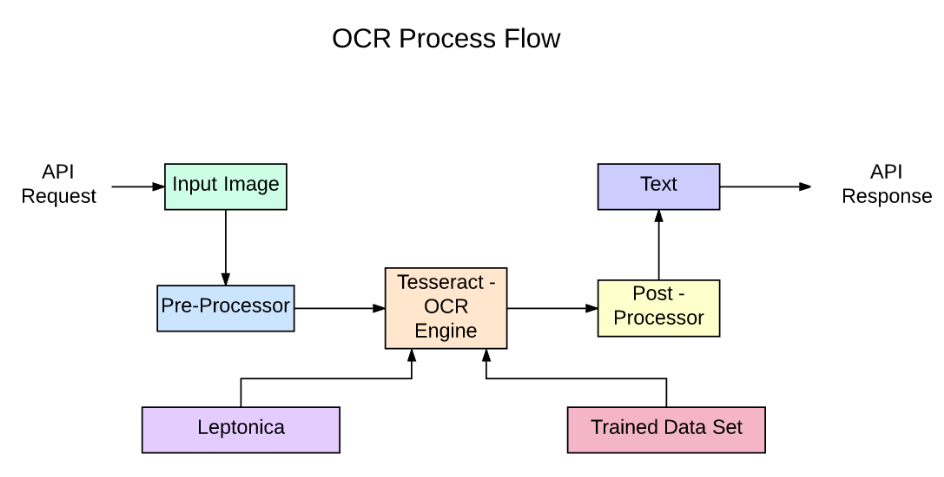
이번 시간에는 Optical Character Recognition (OCR, 광학 문자 인식) 을 이용해서 그림에서 글을 추출할 예정이다.PyTesseract API를 사용하는 프로세스 흐름이다.API를 요청 후 이미지를 입력하면Pre-Processor 에서 이미지
35.바코드, QR 생성 및 판독

바코드 및 QR 코드를 디코딩,인코딩하기 위해 라이브러리를 설치pyzbar 라이브러리는 libzbar0의 python 바인딩인데,여기에서 python 바인딩 이라는 말은 다른 프로그래밍 언어로 작성된 라이브러리나 도구를 Python에서 사용할 수 있도록 하는 인터페이스
36.OpenCV 의 YOLOv3
사전 교육된 YOLOV3 모델을 로드하고 OpenCV를 사용하여 몇 개의 이미지에 대한 추론을 실행하는 방법을 배운다.Colab에서 yolo 모델파일을 다운로드 받으면,images 와 yolo 안에 3개의 파일이 존재한다.coco.namesYOLO 모델이 식별하고자 하
37.Neural Style Transfer를 활용한 OpenCV
Neural Style Transfer의 개요와 OpenCV를 활용한 구현뉴럴네트워크나 딥 러닝을 이용해서 input image의 스타일을 추출해서 원하는 이미지에 그 스타일을 적용시킨다는 것사전 학습된 모델을 사용하여 Neural Style Transfer 구현''c
38.SSD를 이용한 객체 탐지

SSD는 "Single Shot MultiBox Detector"의 약자이는 객체 탐지(Object Detection) 알고리즘 중 하나로, 한 번의 신경망 패스만으로 여러 객체의 위치와 종류를 동시에 예측할 수 있는 모델이다.SSD는 빠른 속도와 비교적 높은 정확도로
39.OpenCV를 사용한 흑백 사진 컬러화: Caffe 모델 활용

originalcolorized위 사진들을 보면 이번 학습때 무엇을 배우는지 알 수 있다.왼쪽의 흑백 사진을 오른쪽의 컬러화 시켰는데,그 반대로 흑백화를 해야 납득이 갈 수준으로 컬러화를 해놨다.신기하다.Colorful Image Colorization 기법 개요작업에
40.이미지 복원 : TELEA

OpenCV의 손상 복원 알고리즘인 TELEA 을 이용하여 전처리 한 이미지를 복원한다.손상된 이미지 로드2\. 이미지는 손상된 영역을 표시손상된 영역을 표시하기 위해 그레이스케일3\. 손상된 영역 표시손상된 영역을 표시한 마스크 이미지에서 임계값을 기준으로 이진화를
41.이미지에 노이즈 추가 및 제거와 대조 향상을 위한 히스토그램 평활화
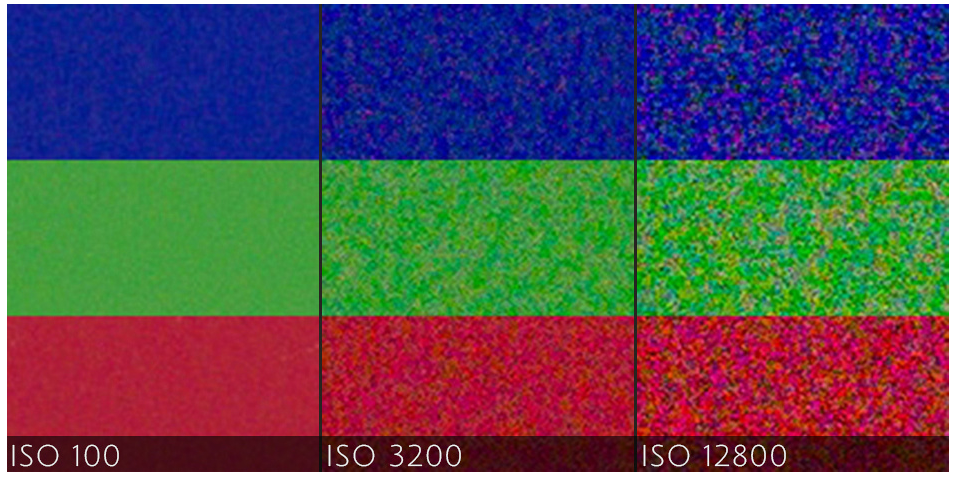
노이즈(Noise)란?노이즈란 이미지나 오디오 등에서 발생하는 임의의 불규칙한 신호를 말한다.노이즈는 주로 디지털 카메라 센서나 스캐너 등에서 발생하는데, 이는 빛이 부족한 상황에서 카메라 센서가 받아들이는 신호의 무작위한 변동으로 인해 발생한다.위의 이미지도 카메라의
42.블러(흐림) 점수 출력

블러(흐릿)를 감지하기 위해 정도를 다르게 한 블러 이미지를 생성했다.입력 이미지 확인 및 그레이스케일 변환이미지가 컬러(BGR) 이미지인 경우(image.shape의 길이가 3인 경우),cv2.cvtColor를 사용하여 그레이스케일로 변환라플라시안 변환 및 분산 계산
43.얼굴 인식 : face-recognition
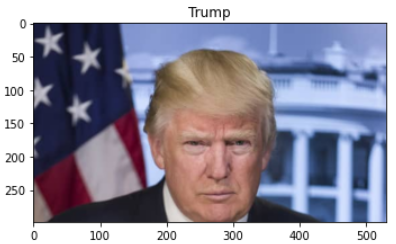
얼굴을 파이썬 라이브러리 중 face-recognition을 이용해서 분석하고,둘의 유사성을 비교해서 두개의 이미지가 같은 인물인가? 하는 물음을 해결한다.1 트럼, 2바이든을 불러왔다.1트럼프와 1바이든을 비교를 했을때, 당연히 False가 출력이 된다.그렇다면 같은
44.실시간 웹캠 스케치 변환

이번 시간에는 jupyter를 사용해서 실습이유는 예제의 코드가 jupyter 에서 테스트하는것이 편하기 떄문설치는 생략하고jupyter을 실행할때 토큰을 입력하라고 나오면 cmd 에서위 내용을 입력하면이런 출력을 주는데 token= 뒤에있는 부분을 넣어주면된다.우선
45.OpenCV로 비디오 열기: 기본 개념과 사용 방법
아래 코드는 드럼치는 영상을 실행하고 영상이 끝나면 자동으로 꺼지게 하는 코드이다.jupyter notebook 폴더안에 드럼을 치는 영상이 있고,그 영상을 코드로 실행시키기 위해드럼치는 영상의 상대위치를 cv2.VideoCapture로 넣어줬고,메서드(isOpened
46.동영상 흑백화(그레이스케일) - OpenCV

video 폴더안에 있는 드럼치는 영상이다.원 영상의 각 프레임이 독립적으로 그레이스케일로 변환되어 새로운 비디오에 추가돼서drummer.avi로 저장영상을 시작하면, 흑백 영상으로 출력업로드중..
47.실시간 비디오 스트리밍: RTSP
"RTSP(Real Time Streaming Protocol)는 실시간 멀티미디어 데이터(예: 오디오/비디오)를 클라이언트와 서버 간에 전송하는 데 사용되는 프로토콜"특별한 이유 없이 사용 가능한 무료 RTSP 스트리밍 주소를 사용해서 테스트 하겠다. Big Buck
48.실시간 비디오 스트리밍: RTSP - 2 스트리밍 재연결

이번에는 스트리밍 도중 인터넷이 끊기고 재연결 됐을때, 스트리밍이 자동으로 재시작 하는 코드이다.현재 스트리밍중에 wifi를 끊어버리면,저 화면에서 멈춰버리고 만다,일반 스트리밍만 하는 코드라면 인터넷이 재연결 돼도 프로그램을 다시 실행시켜야지스트리밍이 돌아갔지만, 연
49.모니터 스트리밍 확대(30,60 fps)
Pillow : 이미지 로딩, 저장, 크기 조정, 회전, 필터링 등에 사용되며 이번에는 크기 조정에 사용pyscreenshot : 스크린샷을 쉽게 찍을 수 있도록 도와주는 패키지 pyscreenshot 라이브러리에서 ImageGrab 모듈을 가져와서ImageGrab.g
50.CNN(Convolution Neural Networks) 소개

좌 냥이 우 댕댕 사람은 보는 즉시 인식이 가능하다.그럼 사진에서 뭘 보고 냥, 댕이라는걸 알 수 있었을까?고양이, 개로 추정되는 정보들이 많다.수염, 눈동자, 생김새 등 우리가 겪은 모든 것들하지만 컴퓨터나 알고리즘 또는 소프트웨어가 어떻게 이런걸 할까?그걸 가능하게
51.CNN 1 - Convolution
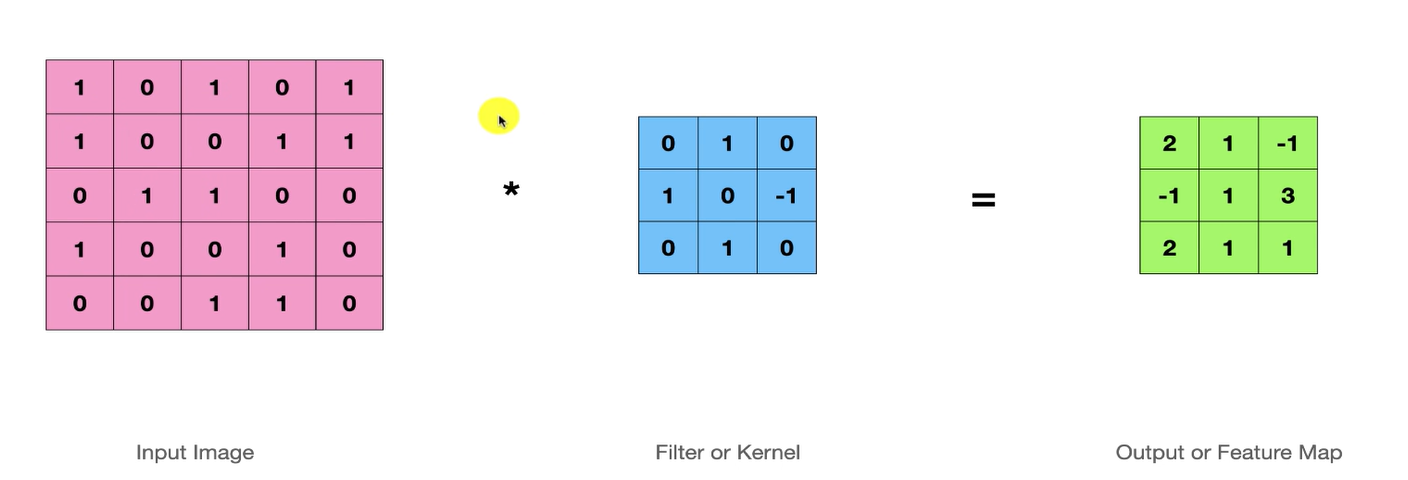
두 함수를 결합해 튜브를 만드는 과정input image는 이진 이미지(1:흰, 0:흑)로 아무의미없는 흑백 이미지로 생각하고filter는 input image와 곱해 출력 또는 기능 맵(feature Map)을 생성하기 위한 필터이다.다시, 1은 흰색 0은 검은색 실
52.CNN 2 - Feature Detectors(기능 검출기)
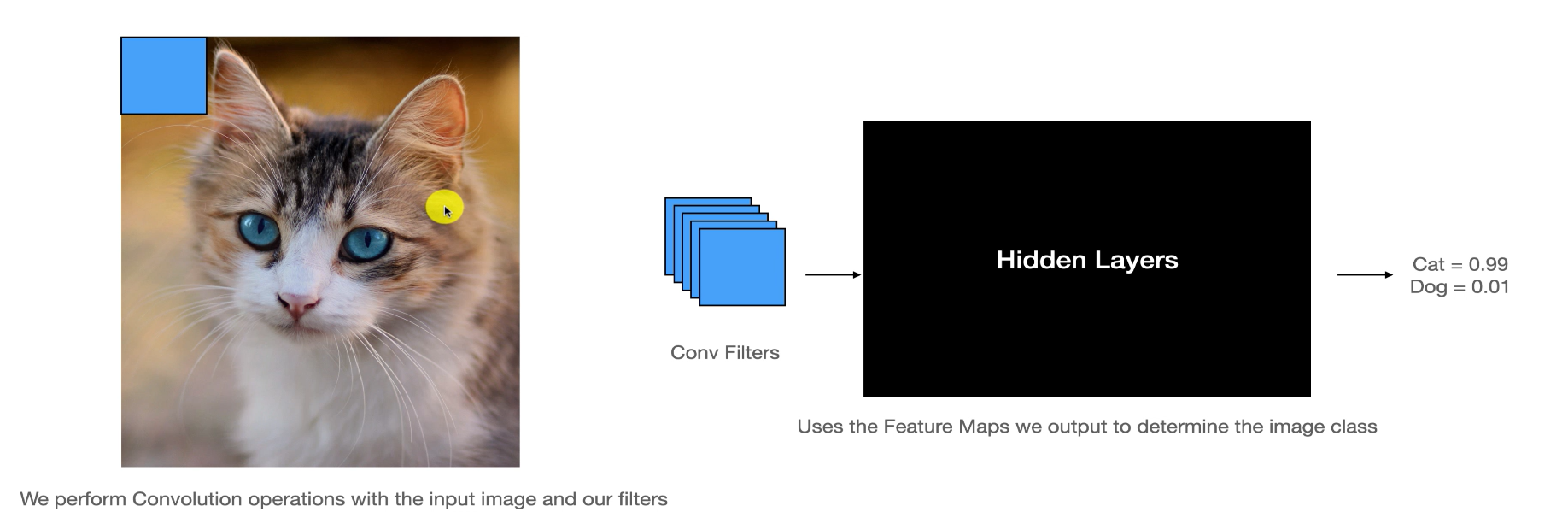
매번 언급되지만 고양이인것을 보자마자 인식한다.사람은 본능적으로 패턴을 보고 우리뇌는 자기도 모르게 절단면에서 보이는 작은 특징을 결합해서자동으로 그걸 절단면과 연관 짓는다.위 사진처럼 필터들이 input image를 돌아다니면서 연산을 한다.다시 고양이로 오면그 필터
53.CNN 3 - 컬러이미지(3D) 에서의 Convolution
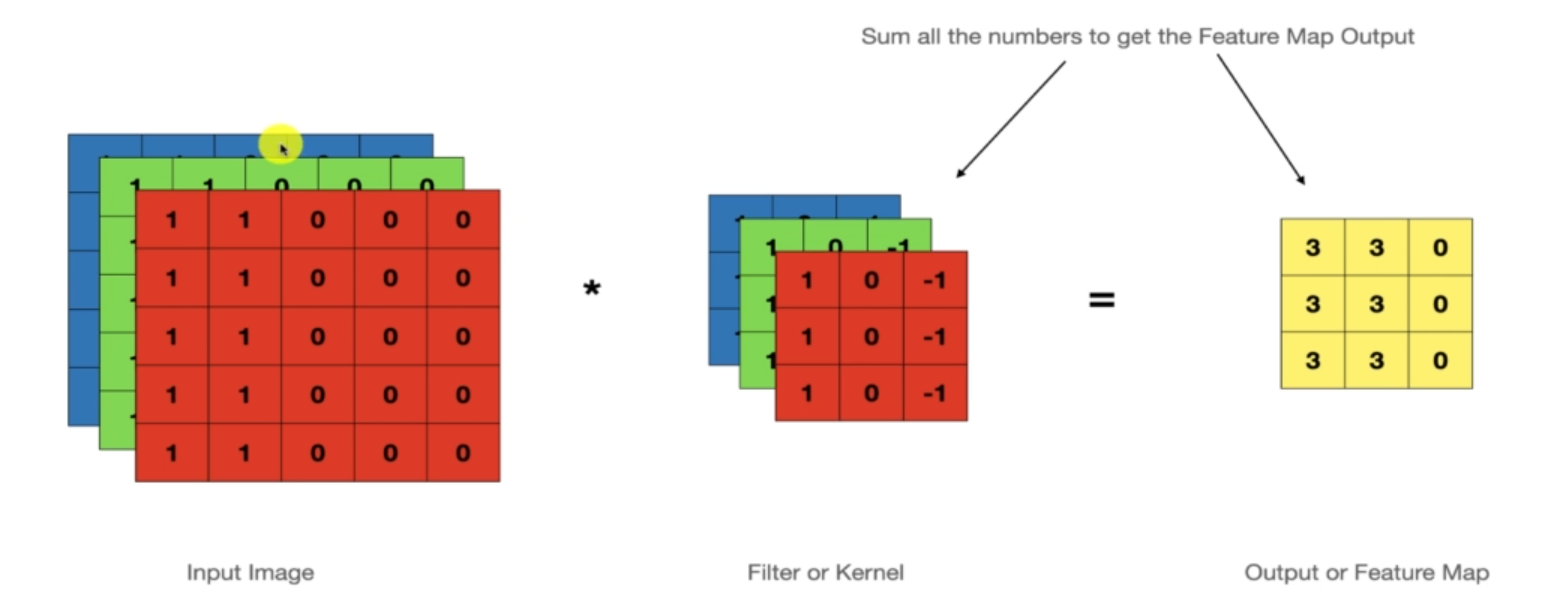
컬러 이미지에서 컨볼루션이 어떻게 작동되는지 확인이전까지 연산했던 내용들은 그레이스케일이 된 것으로 하나의 차원만 연산을 했다.하지만 컬러 이미지는, 3개의 차원으로 이루어져있다.이러한 채널을 모두 고려하여 컨볼루션 필터를 적용해야한다.input image가 나무라 생
54.CNN 4 - Kernel 크기와 깊이

Kernel 들은 콘볼루션 필터의 크기를 조절하고 기능 지도의 크기를 조절한다.이미지에 나온것처럼 깊이는 3D(RGB)를 뜻한다.Stride, Padding은 다음에~기능맵의 크기는 6-5+1로 2가 나왔고커널은 인풋 이미지와 연산할때 4개의 포지션이 나온다.근데 여기
55.CNN 5 - Padding
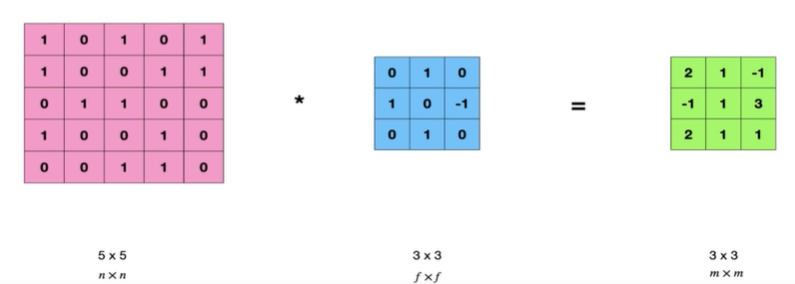
Paddin은 콘볼루션 신경망을 통과하면서 기능 맵 크기를 조작하는 놈패딩 그대로 겨울철에 입는 그걸로 생각해도 될 것 같다.찬바람에 대신 상처 입어줌위 사진도 그렇고, 앞서 봤던 내용들도 그렇고 입력보다 출력이 무조건 작은데 이 사실을 알 수 있다.저번시간 복습으로
56.CNN 6 - Stride
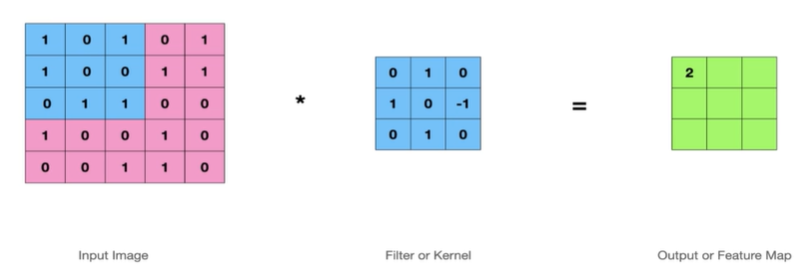
스트라이드는 필터가 입력 이미지를 가로지르며 이동하는 스텝 사이즈를 나타내며,출력 특징 맵의 크기와 연산 효율성을 조절하는 중요한 파라미터이고,Stride = 스텝 사이즈 로 보여진다.Stride는 번역하면 "~을 성큼 넘어서다"Stride = 1 일때,한칸씩 이동하면
57.CNN 7 - Activation Functions ( ReLU)
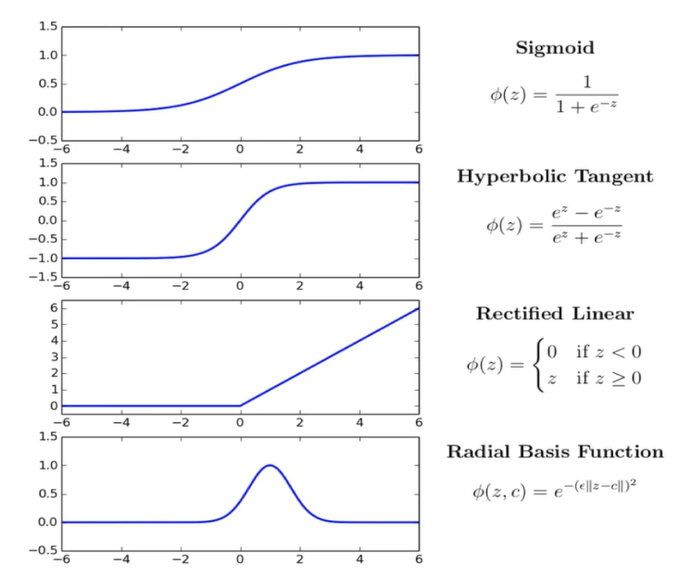
활성화 함수, 즉 무언가 활성한다는건데 이 행위의 목적이 뭘까활성화 함수를 사용해야하는 두 가지 이유가 있다.첫째, 데이터에서 복잡한 패턴을 배워야 한다복잡한 패턴은 데이터가 방대하다는 뜻이고 그 변화도 아주 다양해서 숫자 식별하는 상상을 할 때처럼 작은 변화를 줄 수
58.CNN 8 - Max Pooling
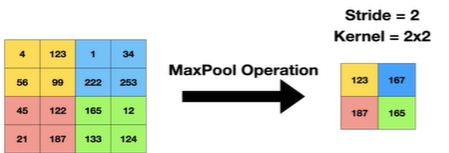
"풀링은 피처 맵의 크기나 차원을 줄이는 프로세스"이를 통해 네트워크의 매개 변수 수를 줄이는 동시에 중요한 기능을 유지할 수 있다.서브샘플링 또는 다운 샘플링이라고도 함2개의 매개 변수(Stride, Kernel)를 이용해 Pooling을 진행하는데,pooling의
59.CNN 9 - Fully Connected Layer

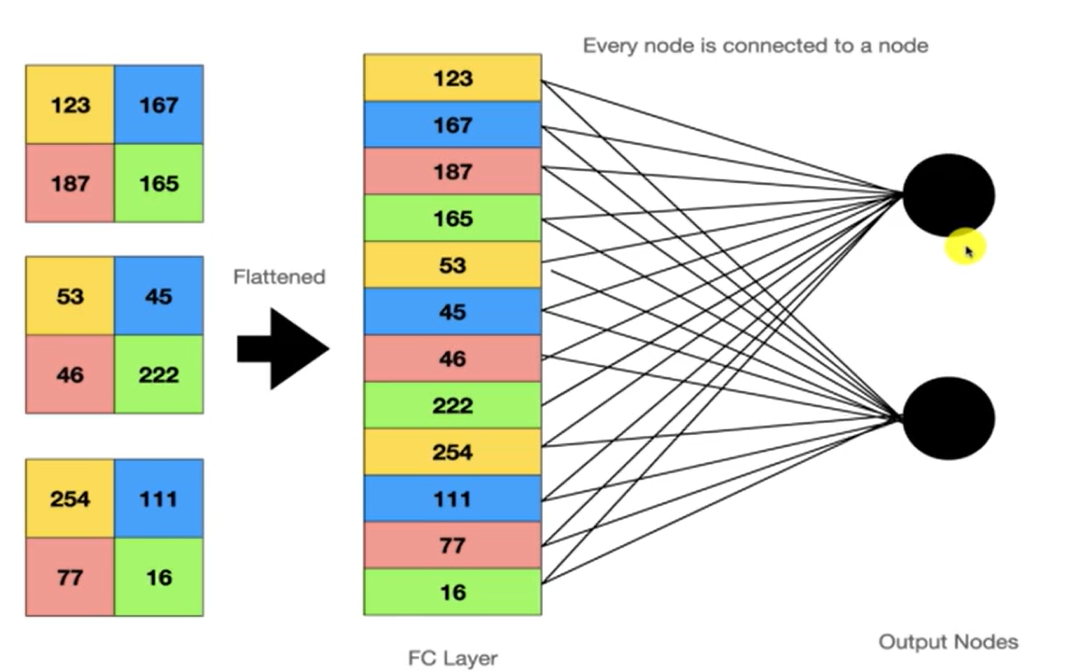
Fully Connected Layer(완전히 연결된 레이어)이 뭐고 이 행위의 목적이 뭔지 CNN을 통해 살펴보자Fully Connected Layer?목적한 계층의 모든 노드가 다음 계층의 출력과 연결돼 있다3개의 필터를 연결해서 FC Layer를 만든 모습이다.그
60.CNN 10 - Softmax Layer
이번엔 저번 FC Layer에 이어서 Softmax Layer에 대해 알아본다.FC layer는 신경망의 마지막 단계에서 중요한 역할을 하는데, Softmax Layer와 결합되어 최종 분류 결과를 제공한다.이때의 결합되는 Softmax Layer에 대한 내용이다.최종
61.CNN 11 - CNN의 구조
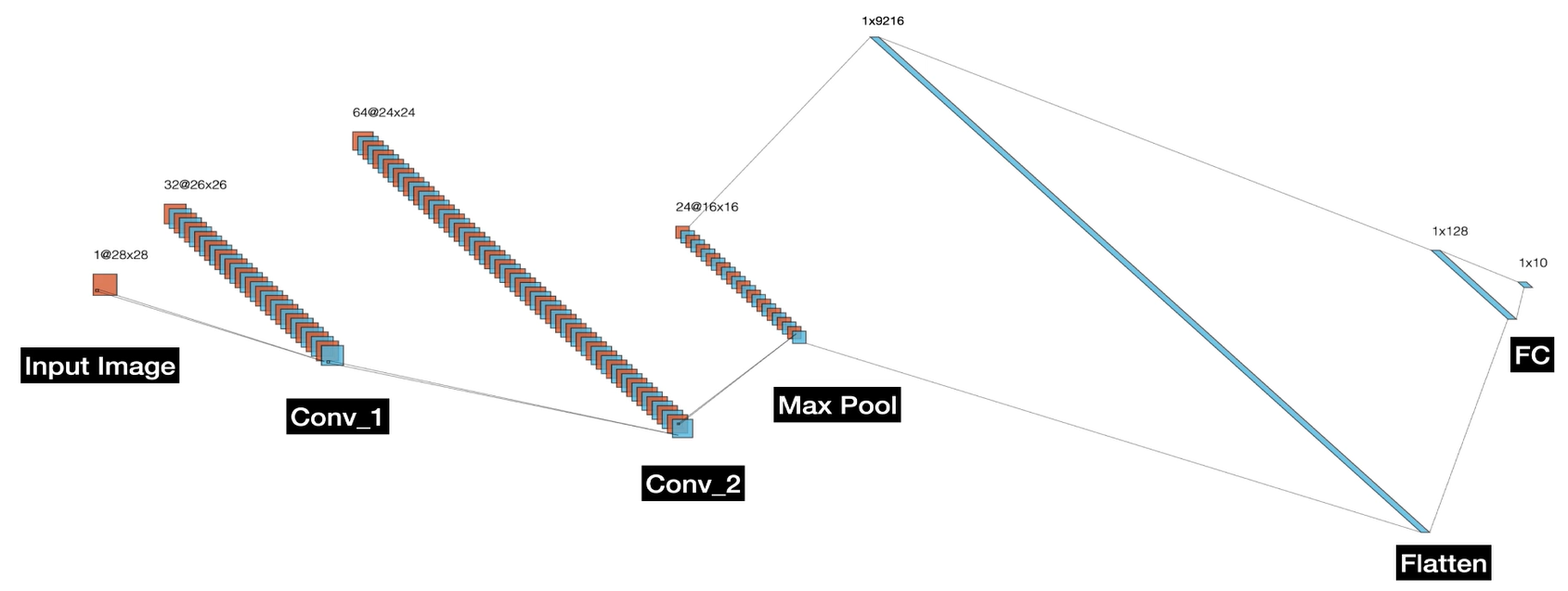
CNN의 구조와 각 구성들의 사이즈를 계산하는 방법을 확인한다.
62.CNN 12 - CNN에서 파라미터 수 계산
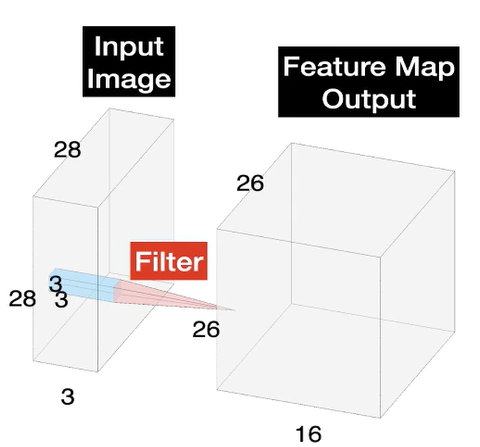
CNN이 갖고 있는 파라미터(매개 변수)의 수를 계산하고학습 가능한 매개 변수가 뭔지 확인한다.파라미터는 모델을 생성할 때 학습해야 하는 변수들CNN에서는 주로 가중치(weights)라고 불리며, 초기에는 무작위로 초기화 된다. 이런 걸 학습 매개 변수라고 한다.학습
63.CNN 13 - CNN이 이미지에 효과적인 이유

일반 신경망이 있고 모든 노드가 서로 연결돼있다.예를 들어 입력이미지가 28x28 일 경우,단일 은닉 계층에서도 연결 수가 엄청나게 많을 수 있다.이러한 구조는 하나의 은닉 계층만으로도 수천만 개의 파라미터를 가질 수 있음을 의미CNN은 필터(또는 커널)를 사용하여 입
64.CNN 14 - CNN 트레이닝

합성곱 신경망(CNN)에서 "필터" 또는 "커널"은 입력 이미지의 특정 특징이나 패턴을 감지하는데 사용되는 작은 행렬기능 감지기로 이미지의 물체를 구성하는 기능을 감지해서 이미지에 뭐가 있는지 알 수 있다.일반적으로 CNN은 낮은 수준의 특징(Low-Level Feat
65.CNN 15 - PyTorch로 CNN 구현 1

1. PyTorch 라이브러리 및 함수 가져오기 라이브러리를 가져오고 CUDA가 사용한지 확인한다. CUDA는 NVIDIA의 GPU에서 동작하는 병렬 컴퓨팅 플랫폼 및 API 모델이며 PyTorch와 같은 딥러닝 프레임워크에서 GPU를 활용하여 연산을 가속화 해
66.CNN 16 - PyTorch로 CNN 구현 2

데이터 로더는 지정된 배치 크기(여기서는 128)를 사용하여 훈련 중에 데이터를 가져오는 함수이다.나누는 이유는 모든 데이터를 한 번에 네트워크에 입력할 수 없기 때문이다.dataiter = iter(trainloader)images, labels = next(data
67.CNN 17 - PyTorch로 CNN 구현 3
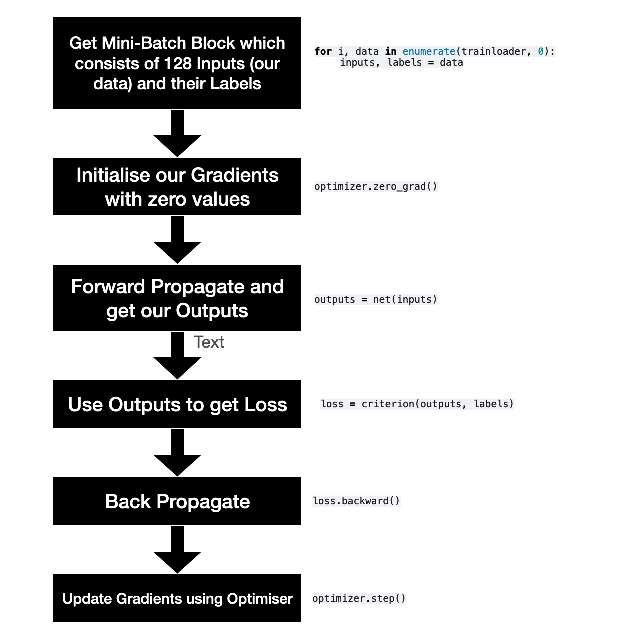
PyTorch를 사용하여 신경망 모델의 최적화(학습) 설정을 하는 예제이 예제를 수행하기 전에 신경망 모델 net은이미 정의되어 있어야 한다.optimizer 함수 선언PyTorch의 최적화 도구(optimizers)를 가져온다.이는 모델 학습 시 가중치를 조정하는 알
68.CNN 18 - PyTorch로 CNN 구현 4
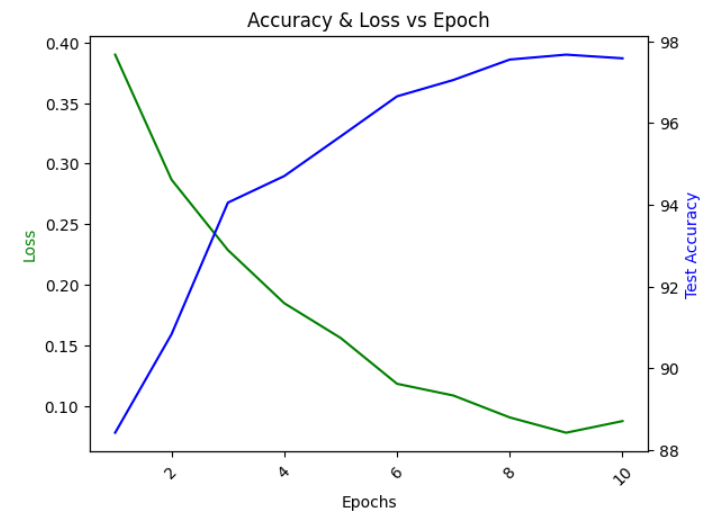
플롯을 통해 모델의 학습 진행 상황을 시각적으로 평가할 수 있으며, 손실과 정확도의 변화를 명확히 파악할 수 있다.에포크 수에 따른 손실(Loss)과 테스트 정확도(Test Accuracy)를 보여준다.에포크(학습수)가 늘어날수록손실값이 줄어들고 정확도가 늘어난다.에포
69.CNN 19 - Building CNNs in TensorFlow with Keras 1
시작하기 앞서 Colab을 너무 많이 사용해서 업그레이드 시켜줬다.알아보니 런타임 종료시 업그레이드를 해야 다시 사용할 수 있지만,계정을 여러개 돌려서 사용하면 된다.TensorFlow의 Keras 모듈에서 MNIST 데이터셋을 가져오기 위해 mnist를 임포트MNIS
70.CNN 20 - Building CNNs in TensorFlow with Keras 2
또 이 CNN을 빌드를 할건데, 텐서플로우랑 케라스를 사용해서 빌드를 한다.라이브러리는 요래 있다.와중에 Dense가 뭔지 몰라 검색Dense는 평탄화 다음 층인데평탄화된 벡터를 입력으로 받아 분류 작업을 수행하고,사용예시Dense(128, activation='rel
71.CNN 21 - Building CNNs in TensorFlow with Keras 3
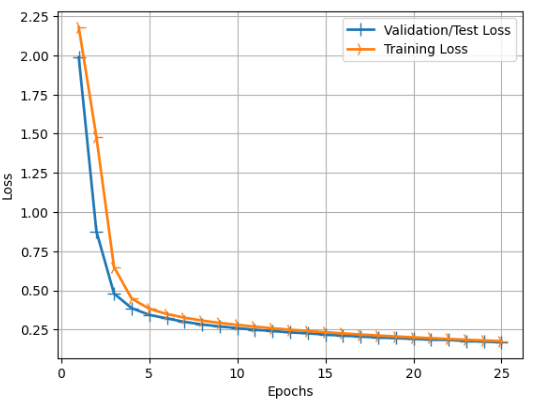
6. 모델 학습(Training Model) 겁나짧다, PyTorch로 구현한 코드보다 3배는 짧다. 학습하는데 총 2분이 걸렸다. 7분이 걸린 PyTorch 모델과 많은 차이가 난다. 학습 로그도 되게 깔끔하고 직관적으로 표현을 잘 해놨다. Keras를 이용
72.CNN 22 - 딥러닝 라이브러리 PyTorch VS Keras
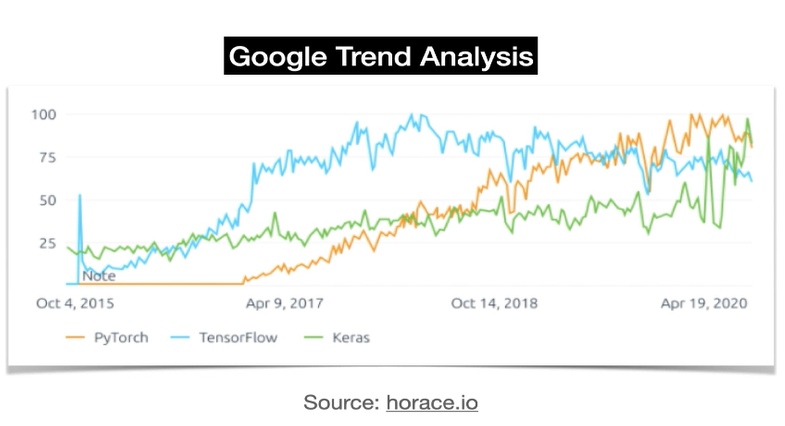
PyTorch와 Keras를 사용하여 두 가지 다른 컨볼루션 신경망(CNN)을 훈련시켜 보았기 때문에두 라이브러리의 차이점을 이해하고 있다.이번 글에는 PyTorch와 Keras의 차이점을 좀 더 자세히 설명하고,두 라이브러리에 대한 이해를 강화하는 글이다.Keras(
73.CNN 23 - 모델 검증

모델을 훈련할 때 데이터셋을 두 개 또는 세 개의 부분으로 나누어야 한다.모델을 훈련할 때 사용하는 데이터는 훈련 데이터(train 데이터 셋, x_train)이다.모델은 이 데이터를 보고 학습한다.그러나 모델이 훈련 데이터만 학습하고 실제로 보지 못한 새로운 데이터를
74.CNN 24 - Confusion Matrix and Classification Report
저번에 이런 정확도가 높아도 예측이 실패하는 경우가 있다.이런 경우에 모델의 예측 오류를 상세히 분석할 수 있는 도구들을 사용한다.혼동 행렬(Confusion Matrix)분류 보고서(Classification Report)범주형 출력값을 가지는 분류 모델에서 사용된다
75.CNN 25 - Keras 오분류 및 모형 성능 분석
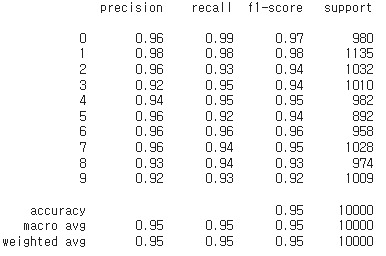
사용하기 쉽게 다운로드 하기 위해,저번에 Keras로 MNIST를 학습해 만든 모델을 구글 드라이브에 올렸다.10회의 에포크를 가진 CNN 모델이 다운로드 됐다.해당 파일을 모델로 로드두 종류를 다운로드 했는데train 셋과 test 셋이다.x_train 에는 학습할
76.CNN 26 - PyTorch 모델 성능 분석
저번 CNN 25에서는 Keras로 만든 모델을 분석 및 해석했다.이번에는 맨 처음에 PyTorch로 만들었던 모델의 분석모델을 불러 오기전에 다시한번 CUDA에 대해서 확인하자.CUDA(Compute Unified Device Architecture)한글로 번역하면
77.CNN 27 - Overfitting & Generalisation

여태 학습을 하면서 나왔던 과적합 및 일반화에 대해서 다루어보자.과적합은 모델이 훈련 데이터에 너무 맞춰져 있어서 테스트 데이터나 검증 데이터에서는 성능이 저하되는 현상거북이만 잡다가 토끼를 잡으려고 할때 대처법을 모르는 상황이는 충분한 데이터가 없거나, 너무 많은 특
78.CNN 28 - 정규화(Regularization) 소개

과적합을 방지하거나 줄이기 위한 정규화(Regularization) 기법에 대해서 알아보자.정규화는 모델의 복잡성을 조절하여 올바른 특징을 학습하도록 도와주며, 모델의 일반화를 개선한다.강아지 이미지를 학습할 때 풀이나 나무를 학습하는 대신, 강아지의 형태, 코, 눈
79.CNN 29 - Keras를 활용한 정규화 X / FNIST(Fashion Classifier) Training
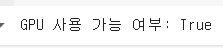
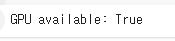
classes0 > 'T-shirt/top' 1 > 'Trouser'모델을 학습하기 위해선 GPU를 사용해야한다.GPU부분에 저렇게 출력이 되면 GPU를 사용하고 있다는 뜻이다.Fashion-MNIST 훈련 데이터셋의 처음 50개 이미지를 시각화Fashion-MNIST
80.CNN 30 - Keras를 활용한 정규화 O / FNIST(Fashion Classifier) Training

전에 했던것처럼 Fashion MNIST와 GPU를 사용하고 있는지 확인하는 부분은 생략이전과 같이 데이터 유형을 재구성하고 변경여기 위에 총 3개의 정규화 방식을 사용했다.L2 정규화kernel_regularizer=regularizers.l2(L2)정규화의 강도로
81.CNN 31 - PyTorch를 이용한 정규화 X / FNIST(Fashion Classifier) Training
Keras를 이용해서 정규화가 있고 없고의 학습데이터 결과를 확인했다.이번에는 PyTorch로 학습하여 확인한다.transform = transforms.Compose( transforms.ToTensor(), transforms.Normalize((0.
82.CNN 32 - PyTorch를 이용한 정규화 O / FNIST(Fashion Classifier) Training

앞 초기 설정 부분은 저번 내용과 똑같다.컨볼루션 신경망(CNN)에서는 드롭아웃을 주로 CONV-RELU 층 뒤에 추가예시: CONV -> RELU -> DROPOUT비율은 0.1~0.3 사이의 값이 잘 작동하고, 0.2를 사용할 것이다.CNN에서 BatchNorm은
83.CNN 33 - CNN 필터 시각화
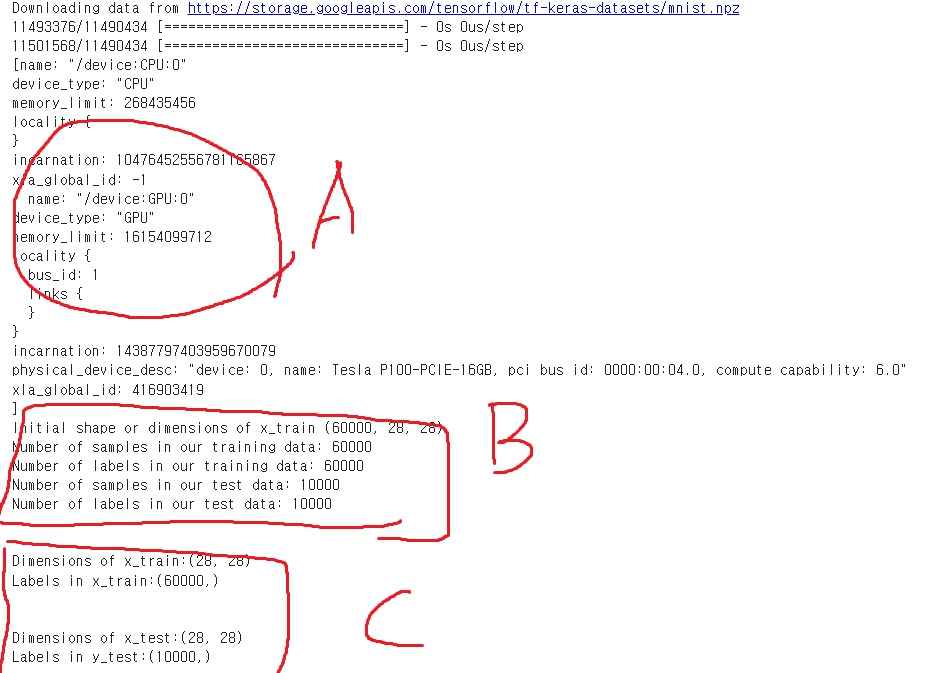
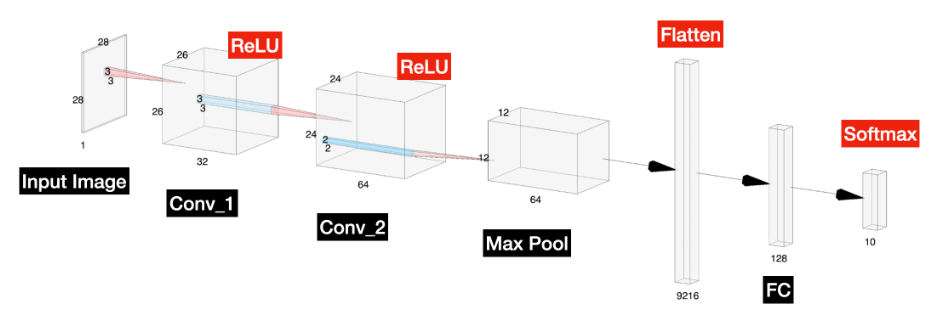
코드를 여러개 나눠서 말고 한번에 실행A : GPU 사용중인지 확인 - CUDA 이용해 학습 위함B : Train, Test 데이터 셋 갯수와, 형태 확인 - 28x28 그레이스케일C : Dimensions(차원), Labels(레이블)Dense = FC1, Dense
84.CNN 34 - 필터 극대화와 클래스 극대화: 딥러닝 시각화 이해하기

주어진 컨볼루션 레이어에서 주어진 필터의 값을 최대화하는 손실 함수를 구축할 것이다스토캐스틱 그래디언트 데상트(Stochastic Gradient Descent)를 사용하여 이 활성화 값을 최대화하도록 입력 영상의 값을 조정할 수 있습니다.VGG16 모델은 레이어가 엄
85.CNN 35 - GradCAM 알고리즘

이번 내용의 목적은 CNN이 특정 클래스를 예측할 때 어디를 주목하는지 시각화 하는것으로,이는 모델의 작동 방식을 더 잘 이해하고, 모델의 신뢰성을 높이며, 디버깅을 도울 수 있다.너무 깊게 이해하지말고, 간단하게 3가지 방식을 사용해서 무슨 말인지 이해하자.Grad-
86.CNN 36 - CNN 역사
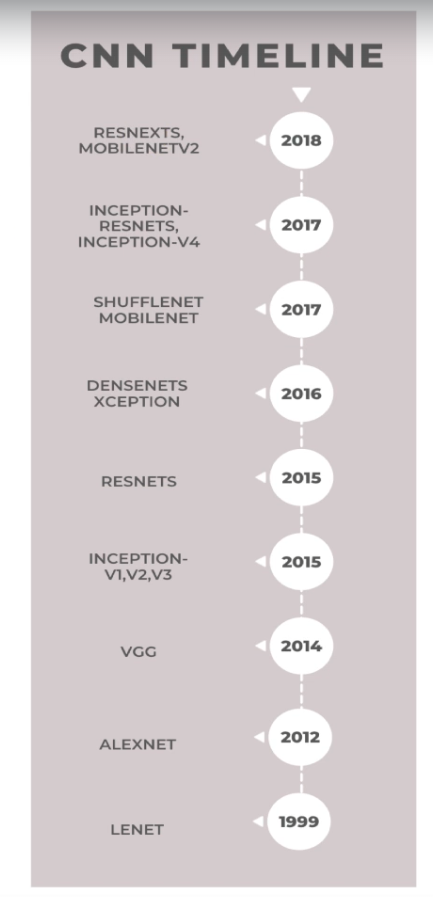
이번 내용은 각 네트워크들이 무엇을 해결하기 위해 개발됐는지를 확인하면서 넘어가자.CNN(Convolutional Neural Networks)의 발전에 대한 타임라인2018년 이후로는 주로 ResNet(Residual Networks)와 관련된 내용이 많으며, Res
87.CNN 37 - Keras에서 LeNet & AlexNet 구현
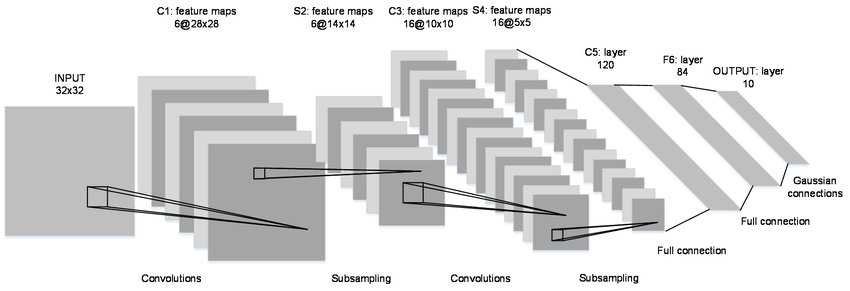
에포크 50 으로 모델을 학습시켰고Loss, 정확도의 값이 출력됐다. 93%로 나쁘지 않다.트레이닝 데이터셋으로 50000개, 32x32 크기의 3차원 이미지를 다운로드, 같은 규격의 테스트 데이터셋 10000개를 다운로드했다.25회 에포크로 테스트 했을때, 1.26의
88.CNN 38 - PyTorch로 사전 교육(Pre-trained) 모델 사용

아래 사전 학습된 모델들을 사용 1\. VGG162\. ResNet3\. Inception v34\. MobileNet v25\. SqueezeNet6\. Wide ResNet7\. MNASNet추가정보30개 레이어가 있고 15개의 ReLU처리가 돼있다.각 레이어의 파
89.CNN 39 - Keras로 사전 교육(Pre-trained) 모델 사용

저번 글에서는 PyTorch로 모델을 불러와 이미지를 예측 했다.VGG16의 모델이 가장 좋은 예측결과를 냈으며 특정 이미지에서는 다른 모델이 VGG 모델보다 좋은 결과를 내는 경우도 있었다.Keras에서도 어떻게 작동을 하는지 확인하자.Keras의 applicatio
90.CNN 40 - Top-1 및 Top-N 정확도: 분류 모델의 성능 평가 지표

모델이 예측한 가장 높은 확률의 클래스가 실제 클래스와 일치하는 경우.모델이 예측한 상위 N개의 클래스 중 하나가 실제 클래스와 일치하는 경우.Top-N 정확도는 모델의 성능을 평가하는 데 더 많은 여유를 제공예를 들어, 모델이 실제 클래스를 두 번째, 세 번째, 네
91.CNN 41 - Rank-1 및 Rank-5 정확도 구현을 통한 분류 모델 성능 평가 with PyTorch

Rank-1 및 Rank-5 알고리즘을 구현하여 Rank-1 및 Rank-5 정확도 기반으로 정확도 메트릭스를 계산텐서(tensor)는 다차원 배열 또는 행렬이다.딥러닝 프레임워크에서는 이미지나 데이터를 텐서 형태로 변환하여 모델에 입력한다.test_transforms
92.CNN 42 - Rank-1 및 Rank-5 정확도 구현을 통한 분류 모델 성능 평가 with Keras
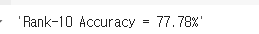
Keras에서 사전 훈련된 모델을 사용하여 1위 및 5위 정확도를 획득먼저 사전 교육된 ImageNet 모델 MobileNetV2를 로드PyTorch 결과Rank-1 Accuracy: 77%Rank-5 Accuracy: 88%Rank-10 Accuracy: 100%Ke
93.Keras와 PyTorch의 콜백(Callbacks)

콜백은 훈련 과정의 다양한 단계에서 특정 작업을 수행조기 종료, 모델 체크포인팅, 학습률 조정, 로깅, 원격 모니터링 및 사용자 정의 함수 등을 위해 유용각 에포크(epoch) 후에 모델을 저장할 수 있다.과적합이 감지되면 훈련을 중지할 수 있다.훈련 중 정보를 기록하
94.PyTorch에서 콜백을 이용한 고양이 vs 개 분류기

!gdown --id 1Dvw0UpvItjig0JbnzbTgYKB-ibMrXdxk!unzip -q dogs-vs-cats.zip!unzip -q train.zip!unzip -q test1.zip train_dir = './train'test_dir = './test1
95.고양이, 개 분류기 데이터 수정 후 학습 조기종료(early stopping), with Keras
패키지 호출 1. 데이터 다운로드 및 탐색 이미지를 다운로드해주고, 이미지의 사이즈를 정의해준다. 데이터 로드시, 데이터 프레임에 레이블(개, 식별 표) 표시 https://github.com/
96.PyTorch Lightning

PyTorch Lightning은 PyTorch를 위한 고수준 인터페이스를 제공하는 오픈 소스 Python 라이브러리아래는 라이트닝을 위한 스냅샷파이토치 라이트닝에 대해 설명한 내용이다.이 기술을 사용하는 이유는"PyTorch Lightning은 복잡한 네트워크 코딩을
97.PyTorch Lightning 2

먼저 PyTorch Lightning 및 Torch Metrics를 설치그리고 사용할 라이브러리를 호출데이터는 kaggle의 dog vs cat 이미지를 다운로드했다.데이터 로더(DataLoader)는 딥러닝 모델을 훈련시키거나 평가할 때 데이터를 효과적으로 공급하기
98.전이 학습 (Transfer Learning)
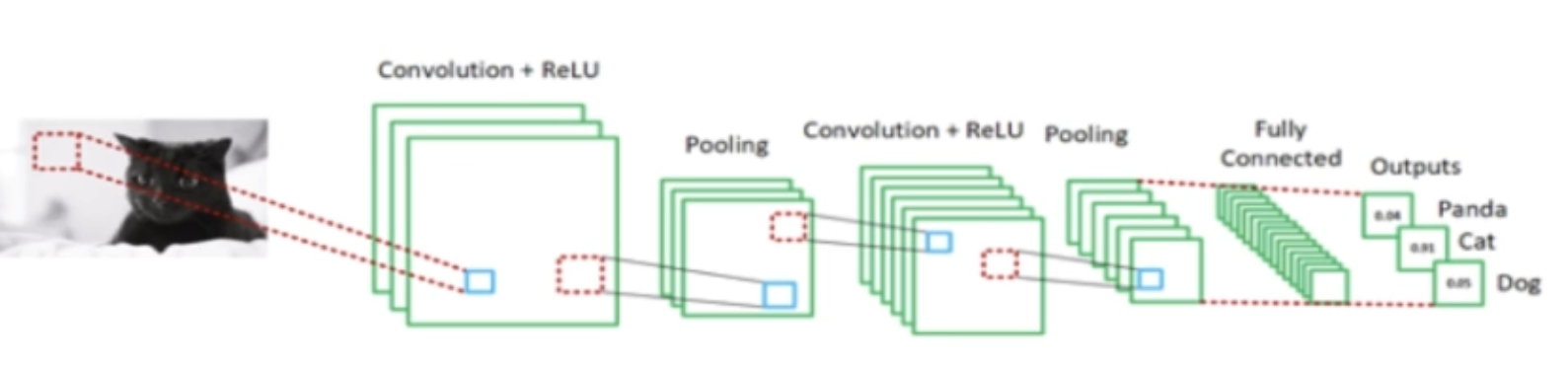
전이 학습은 대부분의 사람들이 CNN을 처음부터 끝까지 훈련하지 않는 이유와 관련이 있다.즉, 랜덤 초기화 대신에 대규모 데이터셋으로 사전 훈련된 네트워크를 활용하여 훈련 시간을 줄이고 성능을 향상시키는 기법이기 때문이다.전이 학습의 필요성대규모 네트워크를 훈련하기에
99.PyTorch Lightning 사용 - 전이 학습(Transfer Learning) 구현

사전 학습된 ResNet-50 모델을 활용하여 이미지를 분류하는 작업을 수행!gdown --id 1Dvw0UpvItjig0JbnzbTgYKB-ibMrXdxk!unzip -q dogs-vs-cats.zip!unzip -q train.zip!unzip -q test1.zi
100.Keras Transfer Learning, Fine Tuning

라이브러리 호출 Keras를 사용하여 Dense 레이어를 생성하고, 그 레이어에 대한 가중치를 초기화한 다음 가중치의 수를 출력 Dense 레이어의 가중치 행렬과 바이어스 벡터가 각각 하나씩 포함되어 있으며, 이들은 모두 학습 가능한 가중치임을 나타낸다.
101.Google DeepDream - Keras, PyTorch 비교

Keras와 PyTorch로 DeepDream을 실습해보고, 차이점을 확인위 사진과 같이 깊은 꿈에서, 이상한 꿈들에 나오는 동물 모습의 이미지이다.일부 구름의 일반 이미지를 입력한 다음, 여기에 여러 종류의 이미지를 생성한다.그 생선한 이미지들을 확대를 했을때, Ad
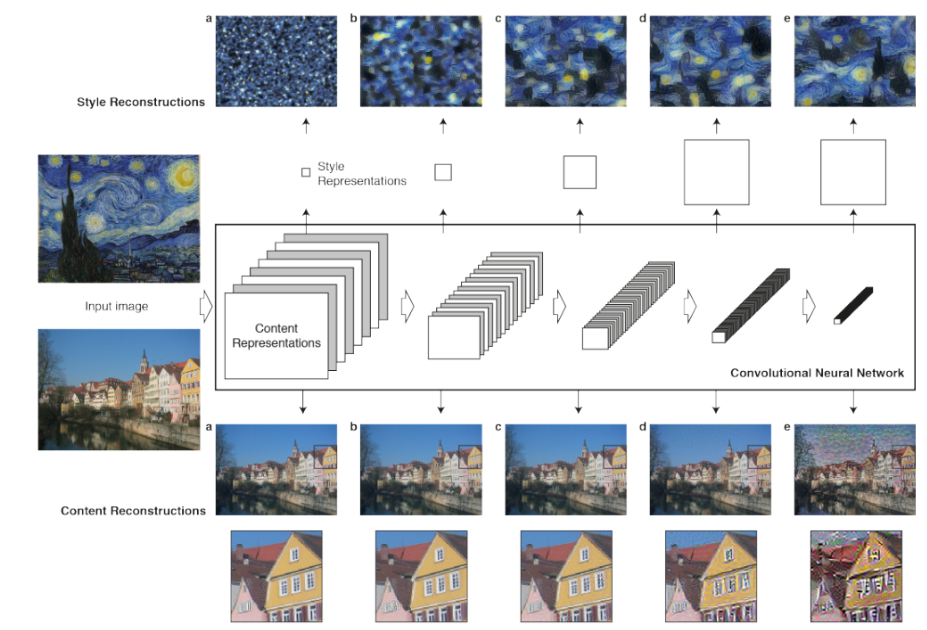
102.Neural Style Transfer 알고리즘

이 알고리즘은 한 이미지의 예술적 스타일을 다른 이미지에 복사할 수 있게 해준다.너무 깊게 이해하려하지말고 알고리즘의 작동원리 흐름을 보고 Keras, PyTorch에서 실습한 결과를 비교해보자.Neural Style Transfer는 두 개의 이미지를 필요로 한다.기
103.AutoEncoder
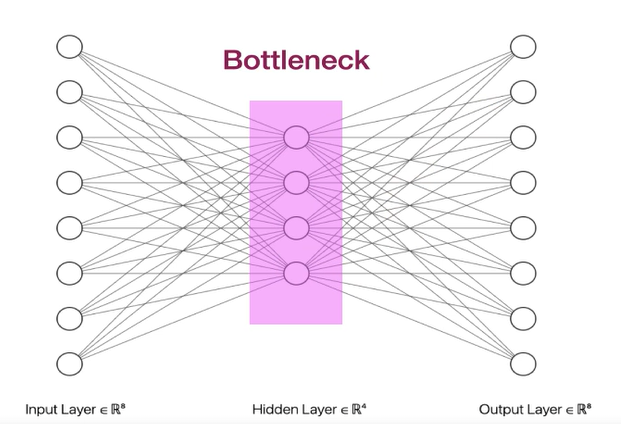
오토인코더는 대표 학습을 수행하는 비지도 학습 기법이미지 데이터셋을 사용하여 CNN이 학습하는 높은 수준의 패턴과 낮은 수준의 특징을 활용한다.오토인코더 아키텍처에는 병목 계층이 포함데이터의 차원을 줄여 더 작은 벡터 표현으로 압축하며, 이를 통해 데이터를 효과적으로
104.GANs 1 - 소개

여기 보이는 얼굴들은 모두 GAN이 생성한 인공적인 얼굴들이며, 실제 인물이 아니다.진짜 GANs이 생성한 이미지이다, 즉 실제 사람이 아닌 사진들을 데이터셋을 기반으로 생성해줬다.실제처럼 보이는 가짜 이미지를 생성한다.위의 강아지, 여우, 음식 등 다 만들어진것이다.
105.GANs 2 - 실제로 어떻게 동작?

리처드 파인먼의 띵언이며"내가 창조할 수 없는 것, 나는 이해할 수 없다." 라는 뜻을 갖고있다.GAN이 기존 데이터셋에서 온 것처럼 보이는 새로운 이미지를 생성한다면, 이들이 실제로 데이터셋을 이해하고 있는 것일까?아마도 아닐 것, 하지만 GAN은 생성자(Genera
106.GANs 3 - 훈련(Training)

이 글은 아래 세가지의 내용을 다룰것GAN 훈련의 어려움훈련 과정문제점우선 GANs 학습은 Neural Networks 보다 훨씬 어렵다Neural Networks은 하나의 네트워크, 간단한 손실함수가 있고 손실을 줄이기 위해 경사하강법과 역전파를 사용한다.복잡해 보이
107.GANs 4 - 실질적인 활용 사례

창의적인 산업 : 예술, 음악, 디자인 생성\+)딥페이크를 통해 얼굴 스타일과 비디오를 복제보안 산업 : 프라이버시를 유지하면서 데이터를 생성, 저해상도 CCTV 영상을 향상의료분야 : 데이터 증강과 신약 개발사진 분야 : FaceApp과 같은 앱이 GAN을 사용하여
108.GANs 5 - Keras,PyTorch DCGAN with MNIST

GAN에 대해서 알아봤는데 DCGAN은 뭘까요약부터 먼저 말하자면GAN은 생성자와 판별자를 포함하는 기본 구조로, 다양한 데이터 생성을 위한 일반적인 프레임워크DCGAN은 GAN의 확장판으로, 컨볼루션 신경망을 사용하여 특히 이미지 생성 및 변환에 강력한 성능을 발휘이
109.GANs 6 - 초해상도 GAN(Super Resolution GAN)

참고자료Efficient Subpixel CNN이라고 불리는 모델을 구현Berkeley의 Computer Vision Group에서 제공하는 BSD 500 데이터셋을 사용데이터셋을 훈련용과 검증용으로 나누고, 전처리 0~1YUV는 인간이 이미지를 인식하는 방식과 유사하
110.GAN 7 - Anime GAN

StyleGan2을 이용해서 애니메이션 캐릭터를 생성참고1참고2주의 tensorflow 버전 및 라이브러리 지원을 안하게 될경우 최신 버전에 맞게 다시 수정해줘야함사전 학습된 GAN 모델(stylegan2)을 사용하여 랜덤 시드를 통해 애니메이션 캐릭터를 생성9개의 랜
111.GAN 8 - ArcaneGAN

ArcaneGan github예전에 아케인 롤 애니메이션이 나왔다.나오기 전에 ArcaneGAN이라는 기술을 누가 만들었고 이 기술을 이미지에 적용하면롤 애니메이션에 나온 그림체로 바뀐다.2분정도 걸렸다.추가) facenet_pytorch 다운로드할때 에러발생한다종속성
112.GAN 9 - 시아미즈 네트워크(Siamese Network) 소개

시아미즈라는 용어는 샴쌍둥이(신체가 결합된 쌍둥이)를 의미한다.시아미즈 네트워크는 동일한 서브 네트워크를 갖는다.시아미즈 네트워크 인코딩 과정시아미즈 네트워크의 개념을 보여주며, 두 개의 입력 이미지가 동일한 컨볼루션 네트워크를 통과하여 각각의 인코딩을 생성한다.이 인
113.GAN 10 - 시아미즈 네트워크(Siamese Network) 테스트Keras,PyTorch

train, test 데이터셋을 다운로드x_train, x_val = x_train_val:30000, x_train_val30000:y_train, y_val = y_train_val:30000, y_train_val30000:del x_train_val, y_tra
114.Face Recognition(안면 인식) 소개
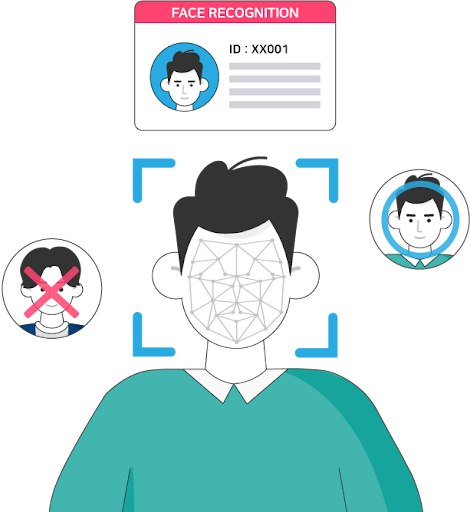
먼저, 얼굴 인식이란 무엇일까?얼굴 인식이란 개인의 얼굴을 자동으로 인식하여 그 사람의 신원을 확인하는 능력을 말한다.기계는 얼굴 인식 알고리즘을 사용하여 사람의 얼굴을 인식한다.OpenCV에는 역사적인 얼굴 인식 라이브러리 세 가지가 내장되어 있으며, 이들은 모두 비
115.얼굴 인식 실습

VG Face 모델 모델의 구성의 층이 굉장히 많다.확실하게 하기 위해 총 페이커 사진3개, 침착맨 사진 2개각각 비교해보겠다.우선 페이커부터솔직히 위에 두개까지 두려웠다. 모델이나 가중치 무언가가 잘못됐을까 하는 마음에하지만 마지막 2,3 이 같은 사람으로 인식을 하
116.DeepFace
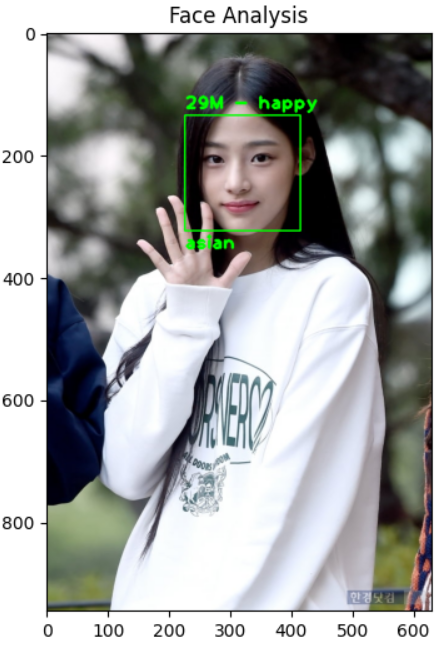
랜드마크 모델을 사용해서 이미지에 랜드마크 건설얼굴의 랜드마크를 찾는 모델만있나?그건 아니다 세상 똑똑이들이 만들어둔 모델들이 많다.그럼 저위의 오리지널 미식가 아저씨의 정보를 예측해보자.나이..를 제외하고는 다 맞다.얼추 잘못봤을때 표정이 화난걸로 오해할수도 있는데,
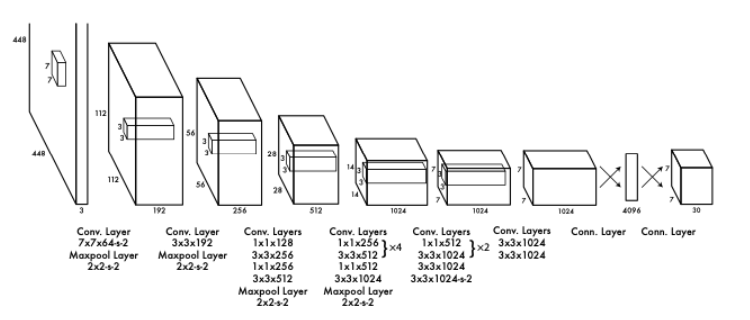
117.Object Detection - YOLO 소개
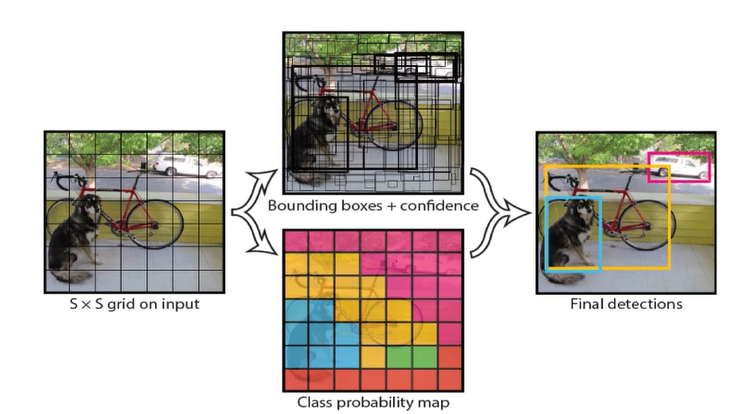
YOLO는 'You Only Look Once'의 약자YOLO는 단일 단계 탐지기이다.이름에서도 알 수 있듯이 '한 번만 본다' 는 의미로, 이것이 R-CNN이나 Faster R-CNN보다 시간을 절약할 수 있는 이유이다.Faster R-CNN의 가장 큰 단점은 느리다