Rank-1 및 Rank-5 알고리즘을 구현하여 Rank-1 및 Rank-5 정확도 기반으로 정확도 메트릭스를 계산
VGG16 모델 로드
# 사전 교육된 VGG16 로드
import torchvision.models as models
model = models.vgg16(pretrained=True)정규화
from torchvision import datasets, transforms, models
data_dir = '/images'
test_transforms = transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),])ImageNet 클래스 이름 및 테스트 이미지 다운로드
# Get the imageNet Class label names and test images
!wget https://raw.githubusercontent.com/rajeevratan84/ModernComputerVision/main/imageNetclasses.json
!wget https://moderncomputervision.s3.eu-west-2.amazonaws.com/imagesDLCV.zip
!unzip imagesDLCV.zip
!rm -rf ./images/class1/.DS_Store모듈 추출
import torch
import json
from PIL import Image
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
with open('imageNetclasses.json') as f:
class_names = json.load(f)사전 교육된 모델을 통해 단일 이미지 로드 및 실행
from PIL import Image
import numpy as np
# 이미지를 로드합니다.
image = Image.open('./images/class1/1539714414867.jpg')
# 이미지를 텐서로 변환합니다.
# 1. 이미지 변환을 위해 정의한 test_transforms를 사용하여 이미지를 텐서로 변환합니다.
# 2. .float() 메서드를 사용하여 텐서를 실수형(float) 데이터로 변환합니다.
image_tensor = test_transforms(image).float()
# 4차원 텐서로 변환합니다. (배치 크기, 채널 수, 높이, 너비)
# unsqueeze_ 메서드를 사용하여 배치 차원을 추가합니다.
image_tensor = image_tensor.unsqueeze_(0)
# 변환된 텐서를 변수로 감싸고, GPU가 사용 가능하면 GPU로 이동합니다.
input = Variable(image_tensor)
input = input.to(device)
# 모델을 사용하여 예측을 수행합니다.
output = model(input)
# 예측된 클래스 인덱스를 가져옵니다.
index = output.data.cpu().numpy().argmax()
# 클래스 이름을 가져옵니다.
name = class_names[str(index)]
# 이미지를 플롯팅합니다.
fig = plt.figure(figsize=(8,8))
plt.axis('off')
plt.title(f'Predicted {name}')
plt.imshow(image)
plt.show()
텐서로 변환?
텐서(tensor)는 다차원 배열 또는 행렬이다.
딥러닝 프레임워크에서는 이미지나 데이터를 텐서 형태로 변환하여 모델에 입력한다.
test_transforms, float, GPU로 이동해서 딥러닝 모델에 입력할 수 있는 형식으로 변환시키는 것

부리토로 예측됐다.
이미지를 경로로 불러오고, 텐서로 변환하기 위해 일련의 작업을 수행한 후, 모델에 입력하여 출력하고
클래스 확률 얻기
Rank-1 또는 Rank-N을 계산하려면 상위 확률 클래스의 순위를 알아야한다.
그래서 softmax 확률을 사용하여 상위 클래스들을 가져올 것이다.
import torch.nn.functional as nnf
# 모델의 출력을 소프트맥스 함수로 변환하여 각 클래스의 확률을 구합니다.
prob = nnf.softmax(output, dim=1)
# 상위 5개의 확률 값과 그에 해당하는 클래스 인덱스를 가져옵니다.
top_p, top_class = prob.topk(5, dim=1)
print(top_p, top_class)
# 출력 예시:
# tensor([[0.8718, 0.0177, 0.0176, 0.0162, 0.0066]], grad_fn=<TopkBackward0>)
# tensor([[965, 924, 931, 933, 923]]) top_p는 상위 5개의 확률 값
top_class는 상위 5개의 클래스 인덱스

# 클래스 인덱스를 넘파이 배열로 변환합니다.
top_class_np = top_class.cpu().data.numpy()[0]
print(top_class_np)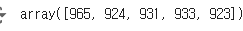
클래스 이름을 알려주는 클래스 만들기
모델이 예측한 상위 클래스 인덱스를 입력으로 받아, 해당 클래스 인덱스를 클래스 이름으로 변환하여 리스트로 반환
# 클래스 인덱스를 CPU로 이동하고 넘파이 배열로 변환:
def getClassNames(top_classes):
top_classes = top_classes.cpu().data.numpy()[0]
all_classes = []
#클래스 인덱스를 클래스 이름으로 변환하여 리스트에 추가:
for top_class in top_classes:
all_classes.append(class_names[str(top_class)])
return all_classes
getClassNames(top_class)
랭크-N 정확도를 제공하기 위한 함수 구성
주어진 디렉토리의 이미지들에 대해 모델을 사용하여
상위 N개의 클래스를 예측하고, 예측된 클래스가 실제 클래스와 일치하는지
확인하여 랭크-N 정확도를 계산
from os import listdir
from os.path import isfile, join
import matplotlib.pyplot as plt
fig=plt.figure(figsize=(16,16))
def getRankN(model, directory, ground_truth, N, show_images = True):
# 디렉토리 내의 이미지 파일 이름을 가져옵니다.
onlyfiles = [f for f in listdir(directory) if isfile(join(directory, f))]
# 상위 N개의 클래스 이름을 저장할 리스트를 초기화합니다.
all_top_classes = []
# 테스트 이미지들을 반복하여 처리합니다.
for (i, image_filename) in enumerate(onlyfiles):
image = Image.open(directory + image_filename)
# 이미지를 텐서로 변환합니다.
image_tensor = test_transforms(image).float()
image_tensor = image_tensor.unsqueeze_(0)
input = Variable(image_tensor)
input = input.to(device)
output = model(input)
# 소프트맥스 확률과 상위 N개의 클래스 이름을 가져옵니다.
prob = nnf.softmax(output, dim=1)
top_p, top_class = prob.topk(N, dim=1)
top_class_names = getClassNames(top_class)
all_top_classes.append(top_class_names)
if show_images:
# 이미지를 플롯에 표시합니다.
sub = fig.add_subplot(len(onlyfiles), 1, i+1)
x = " ,".join(top_class_names)
print(f'Top {N} Predicted Classes {x}')
plt.axis('off')
plt.imshow(image)
plt.show()
return getScore(all_top_classes, ground_truth, N)
def getScore(all_top_classes, ground_truth, N):
# 랭크-N 점수를 계산합니다.
in_labels = 0
for (i, labels) in enumerate(all_top_classes):
if ground_truth[i] in labels:
in_labels += 1
return f'Rank-{N} Accuracy = {in_labels/len(all_top_classes)*100:.2f}%'
이 코드의 단점으로는 지표에 맞는 라벨을 수동으로 설정해야한다.
ground_truth = ['basketball',
'German shepherd, German shepherd dog, German police dog, alsatian',
'limousine, limo',
"spider web, spider's web",
'burrito',
'beer_glass',
'doormat, welcome mat',
'Christmas stocking',
'collie']Rank-5 Accuracy
Rank-5 Accuracy = 88.89%
각 이미지의 상위 5개의 클래스를 출력한다.
getRankN(model,'./images/class1/', ground_truth, N=5)

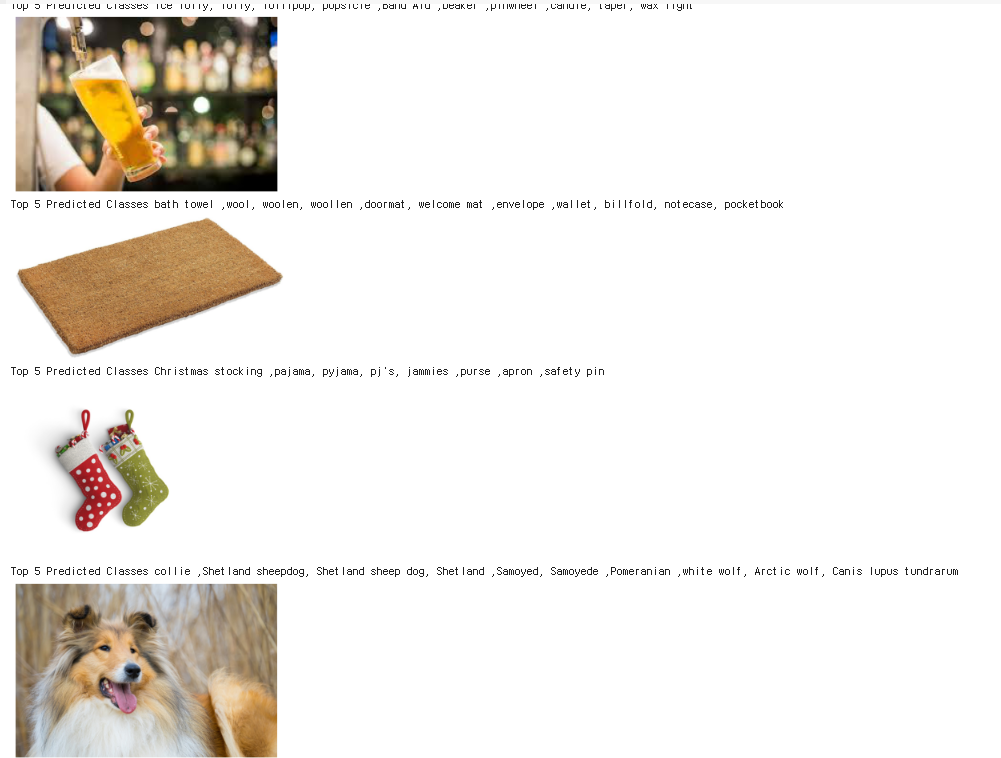
상위 5개 클래스의 정확도는
모델이 상위 5개 클래스 중에서 정확하게 예측한 비율이 88.89%
즉, 모델이 예측한 상위 5개 클래스 내에 실제 클래스가 포함된 경우가 88.89%라는 뜻이다.
Rank-1 Accuracy:
Rank-1 Accuracy = 77.78%
모델이 상위 1개 클래스(가장 높은 확률을 가진 클래스)로 정확하게 예측한 비율이 77.78%
Rank-10 Accuracy:
Rank-10 Accuracy = 88.89%:
모델이 상위 10개 클래스 중에서 정확하게 예측한 비율이 88.89%
결론
이 결과들을 통해 모델이 단일 클래스 예측에는 약간의 어려움을 겪을 수 있지만,
상위 여러 개의 클래스 중에서 올바른 클래스를 포함시키는 데는 상당히 성공적임을 알 수 있다.
이 특징은 여러 클래스가 혼재되어 있을 수 있는 복잡한 데이터셋에서 유용한 지표가 될 것 같다.
