분포의 정보를 담고있는 Histogram에 대한 공부
Histograms and K-Means Clustering for Dominant Colors
-
이미지의 RGB 히스토그램 표현 보기
-
K-평균 클러스터링을 사용하여 지배적인 색상과 비율을 이미지로 표시
1. 이미지의 RGB 히스토그램 표현 보기

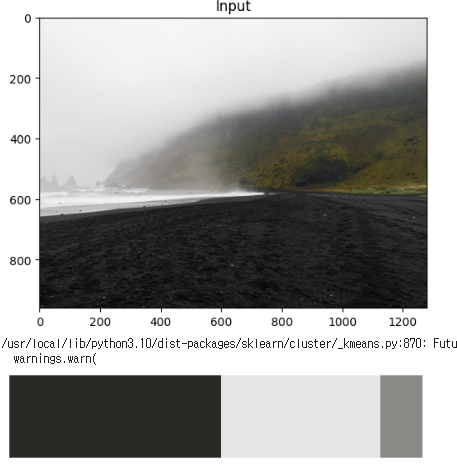
해당 이미지의 색상 정보를 Histogram에 표현
image = cv2.imread('images/input.jpg')
imshow("Input", image)
# 히스토그램 = cv2.calcHist([image], [0], 없음, [256], [0, 256])
# 히스토그램을 표시하고, 영상 배열을 평평하게 합니다
plt.hist(image.ravel(), 256, [0, 256])
plt.show()
# 별도의 색상 채널 보기
color = ('b', 'g', 'r')
# 이제 색상을 분리하고 히스토그램에 각각 그림을 표시합니다
for i, col in enumerate(color):
histogram2 = cv2.calcHist([image], [i], None, [256], [0, 256])
plt.plot(histogram2, color = col)
plt.xlim([0,256])
plt.show()plt.hist(image.ravel(), 256, [0, 256])
plt.show()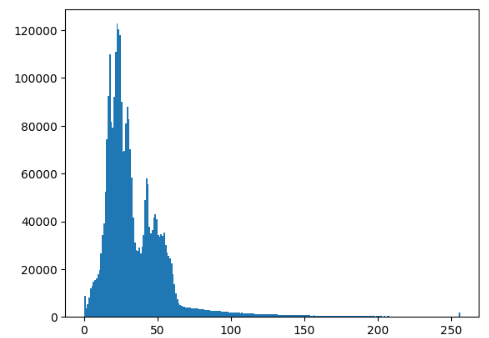
0: 어두움
256: 밝음
y좌표 값: 밀도
이 세가지 정보를 알고 다시 Histogram을 보면 왼쪽에 그래프가 분포해있는 저건
전체적으로 어두운 색상에 30정도 되는 색상의 어두움이 이미지 내에 가장 많은 밀도를 갖고 있다.
그럼 이 이미지를 RGB에 대핸 정보를 Histogram에 담아보자
# 별도의 색상 채널 보기
color = ('b', 'g', 'r')
# 이제 색상을 분리하고 히스토그램에 각각 그림을 표시합니다
for i, col in enumerate(color):
histogram2 = cv2.calcHist([image], [i], None, [256], [0, 256])
plt.plot(histogram2, color = col)
plt.xlim([0,256])
반대로 밝은 사진 해보자.
아래 이미지의 밝기, RGB 정보가 담긴 두개의 Histogram
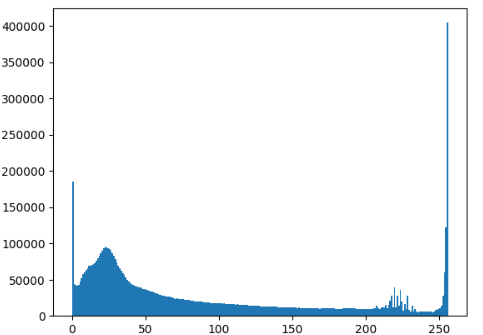
image = cv2.imread('images/tobago.jpg')
imshow("Input", image)
histogram = cv2.calcHist([image], [0], None, [256], [0, 256])
# We plot a histogram, ravel() flatens our image array
plt.hist(image.ravel(), 256, [0, 256]); plt.show()
# Viewing Separate Color Channels
color = ('b', 'g', 'r')
# We now separate the colors and plot each in the Histogram
for i, col in enumerate(color):
histogram2 = cv2.calcHist([image], [i], None, [256], [0, 256])
plt.plot(histogram2, color = col)
plt.xlim([0,256])
plt.show()밝기에 대한 정보는 밝은 부분이 밀도가 가장높고 나머지는 적절한 밀도를 갖고 있다는 것을 알수있고,

RGB Histogram을 봤을땐, 따뜻한 색상인 빨간색이 가장 많은것을 알수있다.
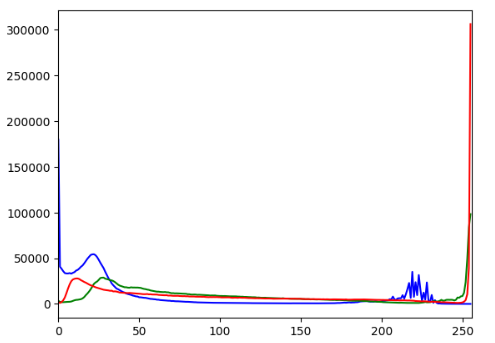
이렇게 이미지를 보지 않아도 Histogram 만 보았을때 이미지가 어떤 특징을 갖고있는지 간략하게 알수있다.
그러면 이어서 이 이미지를 색상 구성 요소별로 나누면 어떨까?
이 그림에서 가장 지배적인 5가지 색을 뽑고 싶다면?
2. K-평균 클러스터링을 사용하여 지배적인 색상과 비율을 이미지로 표시
우선 시작하기 전에 함수를 선언해준다.
def centroidHistogram(clt):
# Create a histrogram for the clusters based on the pixels in each cluster
# Get the labels for each cluster
numLabels = np.arange(0, len(np.unique(clt.labels_)) + 1)
# Create our histogram
(hist, _) = np.histogram(clt.labels_, bins = numLabels)
# normalize the histogram, so that it sums to one
hist = hist.astype("float")
hist /= hist.sum()
return hist
def plotColors(hist, centroids):
# Create our blank barchart
bar = np.zeros((100, 500, 3), dtype = "uint8")
x_start = 0
# iterate over the percentage and dominant color of each cluster
for (percent, color) in zip(hist, centroids):
# plot the relative percentage of each cluster
end = x_start + (percent * 500)
cv2.rectangle(bar, (int(x_start), 0), (int(end), 100),
color.astype("uint8").tolist(), -1)
x_start = end
return bar함수를 선언후 이미지를 처리하고
from sklearn.cluster import KMeans
image = cv2.imread('images/tobago.jpg')
imshow("Input", image)
# We reshape our image into a list of RGB pixels
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
print(image.shape)
image = image.reshape((image.shape[0] * image.shape[1], 3))
print(image.shape)
number_of_clusters = 5
clt = KMeans(number_of_clusters)
clt.fit(image)
hist = centroidHistogram(clt)
bar = plotColors(hist, clt.cluster_centers_)
# show our color bart
plt.figure()
plt.axis("off")
plt.imshow(bar)
plt.show()클러스터를 5개로 선언을 하고 이미지를 해석한 것을 보면 아래와 같다.
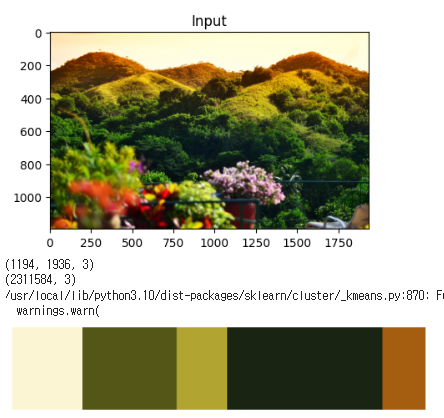
우선 결과를 보면
(1194, 1936, 3)
(2311584, 3)
이 두개와
5가지 클러스터, 색상으로 이루어져있다 라는걸 한눈에 확인할수있는 색상표가 있다.
여기서 저 shape에 대한 내용인데, 아래 코드의 결과이다.
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
print(image.shape)
image = image.reshape((image.shape[0] * image.shape[1], 3))
print(image.shape)이미지의 형태: (1194, 1936, 3)
(높이, 너비, 채널) 3개 채널(RGB)를 가진 1936x1194 이미지 를 나타내며,
해당 이미지를 1차원 배열로 변환한것이
(2311584, 3)
이 배열은 2311584개의 픽셀이며, 각 픽셀은 3개의 채널(RGB) 값을 가지고 있다는 뜻이다.
클러스터를 10개로 늘렸을때에 대한 결과이다.
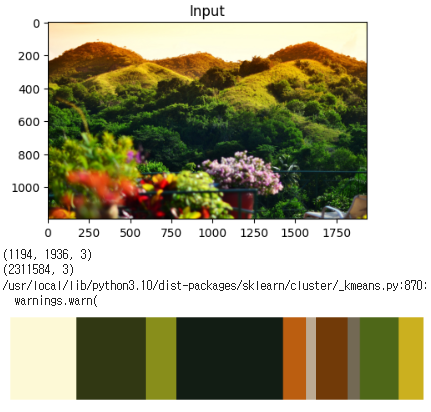
다른 이미지도 해보았다.