이번 시간에는 Optical Character Recognition (OCR, 광학 문자 인식) 을 이용해서 그림에서 글을 추출할 예정이다.
PyTesseract
이론
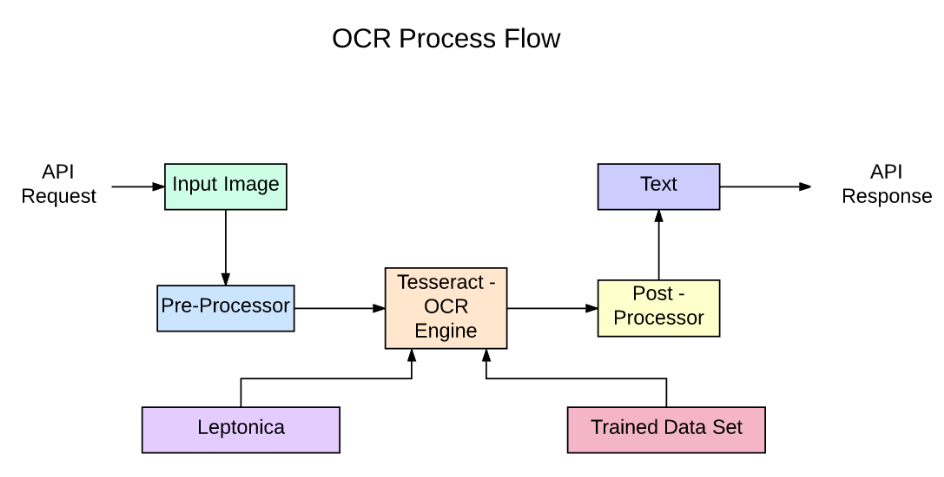
PyTesseract API를 사용하는 프로세스 흐름이다.
API를 요청 후 이미지를 입력하면
Pre-Processor 에서 이미지 전처리를 진행한다.
이미지 전처리 종류에는
그레이스케일 변환, 이진화, 노이즈 제거, 경계선 정리, 크기 조정 등이 있다.
그리고 해당이미지에서 Tesseract-OCR Engine과 Leptonica를 사용해서 이미지 내의 텍스트들을 추출한다.
Tesseract-OCR Engine, Leptonica
Tesseract는 Google에서 개발한 오픈 소스 OCR 엔진
Leptonica는 이미지 처리 및 분석을 위한 오픈 소스 라이브러리
Leptonica는 이미지 처리 및 전처리를 담당하고, Tesseract는 실제 문자 인식을 수행하여 이미지에서 텍스트를 추출
- Post-Processor
인식된 텍스트를 더 정확하게 만들기 위해 후처리 과정
실습
Tesseract-OCR을 사용하기 위해 라이브러리를 설치
!sudo apt install tesseract-ocr
!pip install pytesseractpytesseract를 사용하기 위해 설치된 위치를 선언
import cv2
import pytesseract
import numpy as np
from matplotlib import pyplot as plt
pytesseract.pytesseract.tesseract_cmd = (
r'/usr/bin/tesseract'
)
일반글씨

해당 이미지의 글자를 추출
img = cv2.imread('OCR Samples/OCR1.png')
imshow("Input Image", img)
# Run our image through PyTesseract
output_txt = pytesseract.image_to_string(img)
print("PyTesseract Extracted: {}".format(output_txt))결과로 이미지가 출력되고, 그 이미지의 글자를 pytesseract로 이용해서 글자를 뽑아낸 결과가 나온다.

검은배경 & 흰 글씨
그러면 반대로 검은배경에 흰 글씨도 인식을 하는지 확인해보자.

img = cv2.imread('OCR Samples/OCR2.png')
imshow("Input Image", img)
# Run our image through PyTesseract
output_txt = pytesseract.image_to_string(img)
print("PyTesseract Extracted: {}".format(output_txt))결과를 확인하면 전과 동일하게 결과가 출력이 잘 된다.

지저분한 배경

배경이 지저분한 경우에도 인식을 하는지 확인
img = cv2.imread('OCR Samples/OCR3.png')
imshow("Input Image", img)
# Run our image through PyTesseract
output_txt = pytesseract.image_to_string(img)
print("PyTesseract Extracted: {}".format(output_txt))지저분할 경우에는 인식이 되지 않는 모습

실제 이미지 스캔

텍스트 서적에서 이미지를 추출
img = cv2.imread('OCR Samples/scan2.jpeg')
imshow("Input Image", img, size = 48)
# Run our image through PyTesseract
output_txt = pytesseract.image_to_string(img)
print("PyTesseract Extracted: {}".format(output_txt))추출 결과 결과가 좋지 않다.

사진 - 적응형 임계값 처리(이진 이미지)

적응형 임계값 처리를 통해 지역 임계값을 계산하고,
임계값을 적용하고 이진 이미지를 생성 후 텍스트 추출
from skimage.filters import threshold_local
image = cv2.imread('OCR Samples/scan2.jpeg')
imshow("Input Image", image, size = 48)
# We get the Value component from the HSV color space
# then we apply adaptive thresholdingto
V = cv2.split(cv2.cvtColor(image, cv2.COLOR_BGR2HSV))[2]
T = threshold_local(V, 25, offset=15, method="gaussian")
# Apply the threshold operation
thresh = (V > T).astype("uint8") * 255
imshow("threshold_local", thresh, size = 48)
output_txt = pytesseract.image_to_string(thresh)
print("PyTesseract Extracted: {}".format(output_txt))
전처리를 하지 않았을때보다 더 나은 OCR 결과
임계값 처리 방식
1. Bluring
2. Thresholding
3. Deskewing
4. Dilation/Erosion/Opening/Closing
5. Noise Removal
위 방식들은 이미지 작업을 하기 전에 했을경우 도움이 많이 된다.
영수증 OCR


from skimage.filters import threshold_local
image = cv2.imread('Receipt-woolworth.jpg')
# We get the Value component from the HSV color space
# then we apply adaptive thresholdingto
V = cv2.split(cv2.cvtColor(image, cv2.COLOR_BGR2HSV))[2]
T = threshold_local(V, 25, offset=15, method="gaussian")
# Apply the threshold operation
thresh = (V > T).astype("uint8") * 255
imshow("threshold_local", thresh)
output_txt = pytesseract.image_to_string(thresh)
print("PyTesseract Extracted: {}".format(output_txt))PyTesseract를 이용해 이미지 데이터 결과를 딕셔너리 형식으로 받기
from pytesseract import Output
d = pytesseract.image_to_data(thresh, output_type = Output.DICT)
print(d.keys())PyTesseract의 image_to_data 함수를 사용하여 이미지에서 텍스트 데이터를 추출
output_type=Output.DICT를 지정하면 결과를 딕셔너리 형식으로 반환
dict_keys(['level', 'page_num', 'block_num', 'par_num', 'line_num', 'word_num', 'left', 'top', 'width', 'height', 'conf', 'text'])
이 정보를 통해 이미지 내 텍스트의 위치와 내용, 인식 신뢰도를 자세히 알 수 있으며, 이를 바탕으로 추가적인 처리나 분석을 수행할 수 있다.
예를 들어, 특정 위치의 텍스트만 추출하거나 신뢰도가 낮은 텍스트를 재검토하는 등의 작업이 가능
신뢰도 60 이상만 확인
방금 딕셔너리 정보로 받는것을 기반으로, 신뢰도 60보다 큰 텍스트만 처리하고, 해당 텍스트의 요소의 좌표와 크기를 가져와서, 이미지에 초록색 사각형을 그린다.

n_boxes = len(d['text'])
for i in range(n_boxes):
if int(d['conf'][i]) > 60:
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
image = cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
imshow('Output', image, size = 6)EASY OCR
pytesseract 보다 더 좋은 효율로 이미지를 처리하지만, CPU는 느리므로 Colab에서
수정- 노트설정에 들어가서, GPU 로 설정을 해준다.
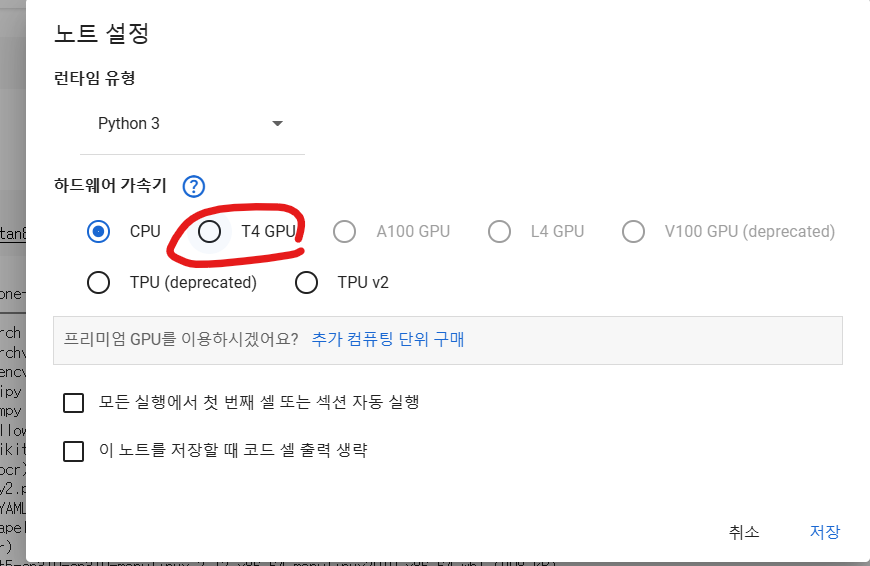
그 다음 easyocr을 설치해주는데, GPU로 변경을 했을경우 라이브러리들을 GPU에 맞게 다시 설치해줘야한다.
# GPU 선택시 추가 설치
!pip install opencv-python-headless
!pip install opencv-contrib-python우선 나는 간단한 영수증 이미지를 처리할것이므로 오래걸리더라도 CPU를 이용해서 처리하겠다.
# easyOCR 사용
!pip install easyocr
!wget https://github.com/rajeevratan84/ModernComputerVision/raw/main/whatsapp_conv.jpeg채팅방 Easy OCR
# 필요한 패키지 임포트
from matplotlib import pyplot as plt
from easyocr import Reader
import pandas as pd
import cv2
import time
# 이미지를 화면에 표시하는 함수 정의
def imshow(title = "Image", image = None, size = 6):
w, h = image.shape[0], image.shape[1]
aspect_ratio = w/h
plt.figure(figsize=(size * aspect_ratio,size))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title(title)
plt.show()
# 이미지 로드 및 표시
image = cv2.imread("whatsapp_conv.jpeg")
imshow("Original Image", image, size = 6)
# EasyOCR을 사용하여 OCR 수행
# 영어 텍스트를 인식하도록 설정, GPU 사용을 비활성화
print("Detecting and OCR'ing text from input image...")
reader = Reader(['en'], gpu = False)
ts = time.time()
# 이미지에서 텍스트를 추출하고 결과를 반환
results = reader.readtext(image)
te = time.time()
td = te - ts
print(f'Completed in {td} seconds')실행을 하니까 실제로 easyocr은 GPU가 더빠르다고 알려준다.
WARNING:easyocr.easyocr:Using CPU. Note: This module is much faster with a GPU.
Detecting and OCR'ing text from input image...
Completed in 17.743825435638428 seconds결과 출력
result[([[24, 12], [192, 12], [192, 38], [24, 38]],
'bmobile _ill < 82',
0.12457802840124284),
([[396, 12], [510, 12], [510, 38], [396, 38]],
'"\'0 ^ (50%',
0.3369437989007717),
([[546, 12], [594, 12], [594, 36], [546, 36]], '8.04', 0.9920759797096252),
([[114, 74], [302, 74], [302, 122], [114, 122]],
'Saffiya Khan',
0.7756983803537445),
([[110, 174], [200, 174], [200, 204], [110, 204]],
'God of',
0.9911833572848934),
([[254, 173], [476, 173], [476, 206], [254, 206]],
'Last of Us, Mortal',
0.908146954391923),
([[110, 206], [454, 206], [454, 238], [110, 238]],
'Kombat 11 and Ratchet and',
0.859354745826267),
([[110, 240], [250, 240], [250, 270], [110, 270]],
'Clank__and',
0.7085109262712401),
([[264, 238], [558, 238], [558, 270], [264, 270]],
'still have tomb raider to',
0.9720005937874658),
([[107, 279], [167, 279], [167, 315], [107, 315]],
'play',
0.8657418620480265),
([[452, 294], [544, 294], [544, 322], [452, 322]],
'12.41 pm',
0.9843809665778231),
([[119, 345], [263, 345], [263, 381], [119, 381]],
'Saffiya Khan',
0.999708485053947),
([[122, 380], [550, 380], [550, 412], [122, 412]],
'Have to come by you to get back my wii',
0.5865775302137902),
([[120, 408], [380, 408], [380, 438], [120, 438]],
'remote to give it to him:',
0.5583260503477024),
([[109, 448], [560, 448], [560, 489], [109, 489]],
'Yea come anytime, U can pass today',
0.7715208356185533),
([[107, 483], [251, 483], [251, 519], [107, 519]],
'if you want',
0.6966904264739778),
([[452, 494], [542, 494], [542, 522], [452, 522]],
'12.41 pm',
0.7272555678202796),
([[120, 546], [262, 546], [262, 578], [120, 578]],
'Saffiya Khan',
0.9999021218386963),
([[132, 579], [556, 579], [556, 612], [132, 612]],
'still want to play out my Zelda game on',
0.832092667190886),
([[122, 608], [434, 608], [434, 636], [122, 636]],
'wii. One of my friends said to',
0.7832432176337331),
([[494, 608], [534, 608], [534, 634], [494, 634]], 'the', 1.0),
([[122, 636], [378, 636], [378, 664], [122, 664]],
'wii to see if he can fix it.',
0.694576434065318),
([[109, 679], [230, 679], [230, 717], [109, 717]],
'Oh greatl',
0.8535487198480594),
([[452, 690], [544, 690], [544, 716], [452, 716]],
'12.41 pm',
0.9533533665500311),
([[52, 752], [100, 752], [100, 780], [52, 780]], 'You', 0.9999642796429743),
([[54, 785], [496, 785], [496, 814], [54, 814]],
'God of War; Last of Us, Mortal Kombat 11',
0.6162563129503879),
([[52, 812], [352, 812], [352, 842], [52, 842]],
'and Ratchet and Clank__and',
0.9520379308893259),
([[366, 814], [466, 814], [466, 840], [366, 840]],
'still have',
0.8658766519396697),
([[52, 842], [260, 842], [260, 874], [52, 874]],
'tomb raider to play',
0.8735859964270906),
([[41, 883], [284, 883], [284, 923], [41, 923]],
'Nice. Plenty games.',
0.9155009062719714),
([[41, 917], [485, 917], [485, 955], [41, 955]],
'You have to try and play tomb raider',
0.6072571022662319),
([[432, 958], [510, 958], [510, 984], [432, 984]],
'1.32 pm',
0.5670399275930226),
([[51, 1039], [467, 1039], [467, 1076], [51, 1076]],
'Yea come anytime; U can pass today if',
0.7988027369537078),
([[52, 1074], [154, 1074], [154, 1102], [52, 1102]],
'you want',
0.9997755154475764),
([[39, 1113], [469, 1113], [469, 1152], [39, 1152]],
'IIl msg later and if yourll home will',
0.6413453641063497),
([[40, 1152], [106, 1152], [106, 1182], [40, 1182]],
'pass',
0.9999975562095642),
([[432, 1158], [510, 1158], [510, 1184], [432, 1184]],
'1.33 pm',
0.8142617831162016),
([[79, 1217], [313, 1217], [313, 1257], [79, 1257]],
'IType a message',
0.7454646053111488),
([[198.8713347040338, 169.16253799371492],
[259.7479208191453, 177.60247020303058],
[254.1286652959662, 210.83746200628508],
[193.25207918085474, 202.39752979696942]],
'War;',
0.5791705696065985),
([[435.0513167019495, 604.1539501058485],
[495.8555816735702, 611.0804059017316],
[491.9486832980505, 639.8460498941515],
[431.1444183264298, 631.9195940982684]],
'bring',
0.927852030761682),
([[53.02202795004179, 1007.1638810551212],
[101.80157025508849, 1013.9270582001789],
[96.97797204995821, 1041.8361189448788],
[49.19842974491151, 1034.0729417998211]],
'You',
0.9999233287696258)]결과를 보았을때 잘 모르겠지만, 글자들은 잘 추출이 된 모습이다.
해당 내용은 이미지에서 추출된 텍스트와 관련된 정보를 담고 있는 리스트이다.
([[435.0513167019495, 604.1539501058485],
[495.8555816735702, 611.0804059017316],
[491.9486832980505, 639.8460498941515],
[431.1444183264298, 631.9195940982684]],
'bring',
0.927852030761682)우선 하나만 가져와서 보면
[[435.0513167019495, 604.1539501058485],
[495.8555816735702, 611.0804059017316],
[491.9486832980505, 639.8460498941515],
[431.1444183264298, 631.9195940982684]]이 부분은 텍스트 영역 좌표이고,이미지 텍스트 영역의 네 모서리 좌표를 나타낸다.
'bring'해당 영역에서 추출된 텍스트
0.927852030761682신뢰도 점수, 1에 가까울수록 OCR 결과가 신뢰할 만함을 의미한다.
EasyOCR을 이용해서 채팅창 분석
글자의 좌표를 알면 글자를 담고있는 박스를그리고, 해당 글자를 따라 써보자.

1. 리스트 초기화
all_text = []추출된 텍스트를 저장할 빈 리스트를 초기화
2. 추출된 텍스트 반복 처리
for (bbox, text, prob) in results:OCR 결과에서 각 텍스트 영역에 대해 반복 작업을 수행합니다.
bbox는 텍스트 영역의 좌표
text는 추출된 텍스트
prob는 텍스트의 신뢰도 점수
- 텍스트와 신뢰도 출력
print(f" Probability of Text: {prob*100:.3f}% OCR'd Text: {text}")각 텍스트와 그 신뢰도를 출력
신뢰도는 백분율로 변환하여 소수점 셋째 자리까지 표시
- 경계 상자 좌표 가져오기
(tl, tr, br, bl) = bbox
tl = (int(tl[0]), int(tl[1]))
tr = (int(tr[0]), int(tr[1]))
br = (int(br[0]), int(br[1]))
bl = (int(bl[0]), int(bl[1]))
bbox에서 좌표를 가져와 각각 상좌(tl), 상우(tr), 하우(br), 하좌(bl) 좌표로 분리합니다.
좌표 값을 정수로 변환합니다.
- 비 ASCII 문자 제거
text = "".join([c if ord(c) < 128 else "" for c in text]).strip()
추출된 텍스트에서 ASCII 문자가 아닌 문자를 제거
이 작업은 텍스트를 이미지에 표시할 때 비 ASCII 문자가 포함되지 않도록 하기 위해 수행
- 텍스트 저장
all_text.append(text)비 ASCII 문자가 제거된 텍스트를 all_text 리스트에 추가
- 이미지에 텍스트 영역 및 텍스트 표시
cv2.rectangle(image, tl, br, (255, 0, 0), 2)
cv2.putText(image, text, (tl[0], tl[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255, 0, 0), 2)원본 이미지에 텍스트 영역을 둘러싸는 사각형을 그린다.
사각형의 색상은 파란색 (255, 0, 0)이며, 두께는 2픽셀
텍스트를 텍스트 영역 위에 표시
텍스트의 위치는 텍스트 영역의 좌측 상단 바로 위
all_text = []
# iterate over our extracted text
for (bbox, text, prob) in results:
# display the OCR'd text and the associated probability of it being text
print(f" Probability of Text: {prob*100:.3f}% OCR'd Text: {text}")
# get the bounding box coordinates
(tl, tr, br, bl) = bbox
tl = (int(tl[0]), int(tl[1]))
tr = (int(tr[0]), int(tr[1]))
br = (int(br[0]), int(br[1]))
bl = (int(bl[0]), int(bl[1]))
# Remove non-ASCII characters from the text so that
# we can draw the box surrounding the text overlaid onto the original image
text = "".join([c if ord(c) < 128 else "" for c in text]).strip()
all_text.append(text)
cv2.rectangle(image, tl, br, (255, 0, 0), 2)
cv2.putText(image, text, (tl[0], tl[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255, 0, 0), 2)
# show the output image
imshow("OCR'd Image", image, size = 6)
print(all_text)['bmobile _ill < 82', '"\'0 ^ (50%', '8.04', 'Saffiya Khan', 'God of', 'Last of Us, Mortal', 'Kombat 11 and Ratchet and', 'Clank__and', 'still have tomb raider to', 'play', '12.41 pm', 'Saffiya Khan', 'Have to come by you to get back my wii', 'remote to give it to him:', 'Yea come anytime, U can pass today', 'if you want', '12.41 pm', 'Saffiya Khan', 'still want to play out my Zelda game on', 'wii. One of my friends said to', 'the', 'wii to see if he can fix it.', 'Oh greatl', '12.41 pm', 'You', 'God of War; Last of Us, Mortal Kombat 11', 'and Ratchet and Clank__and', 'still have', 'tomb raider to play', 'Nice. Plenty games.', 'You have to try and play tomb raider', '1.32 pm', 'Yea come anytime; U can pass today if', 'you want', 'IIl msg later and if yourll home will', 'pass', '1.33 pm', 'IType a message', 'War;', 'bring', 'You']EasyOCR 을 이용해서 영수증 분석

import cv2
from easyocr import Reader
import numpy as np
from matplotlib import pyplot as plt
# Define our imshow function
def imshow(title = "Image", image = None, size = 5):
w, h = image.shape[0], image.shape[1]
aspect_ratio = w/h
plt.figure(figsize=(size * aspect_ratio,size))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title(title)
plt.show()
def clean_text(text):
# remove non-ASCII text so we can draw the text on the image
return "".join([c if ord(c) < 128 else "" for c in text]).strip()
image = cv2.imread('Receipt-woolworth.jpg')
reader = Reader(["en","ar"], gpu=False)
results = reader.readtext(image)
# loop over the results
for (bbox, text, prob) in results:
# display the OCR'd text and associated probability
print("[INFO] {:.4f}: {}".format(prob, text))
# unpack the bounding box
(tl, tr, br, bl) = bbox
tl = (int(tl[0]), int(tl[1]))
tr = (int(tr[0]), int(tr[1]))
br = (int(br[0]), int(br[1]))
bl = (int(bl[0]), int(bl[1]))
# clean text and draw the box surrounding the text along
text = clean_text(text)
cv2.rectangle(image, tl, br, (0, 255, 0), 2)
cv2.putText(image, text, (tl[0], tl[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
# Apply the threshold operation
#thresh = (V > T).astype("uint8") * 255
imshow("EASY OCR", image)
print("EASY OCR Extracted: {}".format(text))