YOLO는 'You Only Look Once'의 약자
YOLO는 단일 단계 탐지기이다.
이름에서도 알 수 있듯이 '한 번만 본다' 는 의미로, 이것이 R-CNN이나 Faster R-CNN보다 시간을 절약할 수 있는 이유이다.
Faster R-CNN의 가장 큰 단점은 느리다는 것
강력한 GPU를 사용하더라도 비디오를 실시간으로 처리하기에는 실용적이지 않았다는 점이다.
YOLO는 COCO 데이터셋에서 사전 훈련된 모델이 많이 존재한다.
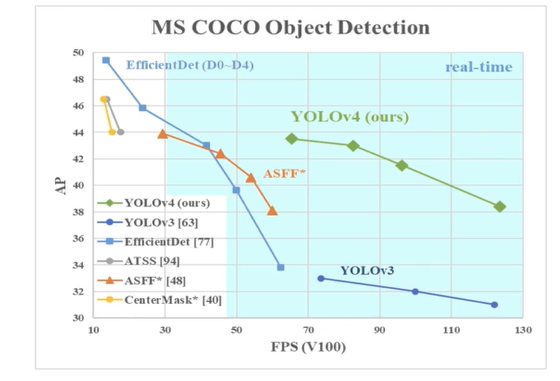
최근에는 YOLOv8이 나왔고 눈에 많이 보였었다.
YOLOv8
YOLOv8의 새로운 기능

- 개선된 성능
YOLOv8 모델은 이전 버전보다 더 높은 정확도와 속도를 자랑
- 다양한 작업에 대한 다재다능함
YOLOv8은 객체 탐지뿐만 아니라 세분화(YOLOv8-seg), 자세 추정(YOLOv8-pose), 분류(YOLOv8-cls) 모델을 포함하여 기능을 확장
- AI 플랫폼과의 통합
Roboflow, ClearML, Comet과 같은 플랫폼과 통합되어 모델 관리 향상
- Ultralytics HUB
이 새로운 기능은 YOLOv5와 YOLOv8 모델 모두에 대해 데이터 시각화, 모델 훈련 및 배포를 위한 올인원 솔루션을 제공
YOLO.. 어떻게 동작
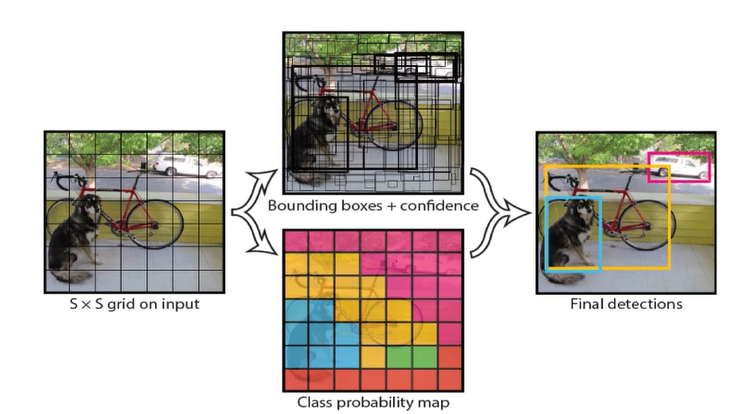
먼저, YOLO는 이미지를 7x7 그리드로 나눈다.
이는 매우 중요한 부분이며, 다른 값으로 구성할 수 있다.

49개의 서로 다른 셀이 있다. 모델, 즉 신경망을 실행하면
각 셀이 B개의 바운딩 박스를 예측하고, 각 바운딩 박스가
객체를 포함할 확률 점수를 제공한다.
따라서 각 셀에 대한 바운딩 박스를 찾을 수 있다.

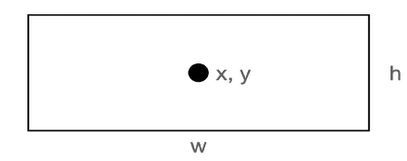
바운딩 박스는 중심 좌표(x, y)와 너비 및 높이로 주어진다.
다음으로, 모든 바운딩 박스를 생성
이미지를 보면 바운딩 박스가 많이 생성되며, 각 박스가 이미지를 포함할 확률도 함께 얻는다.

각 셀에 대해 분류기를 실행하여 확률 점수를 얻으면 된다.
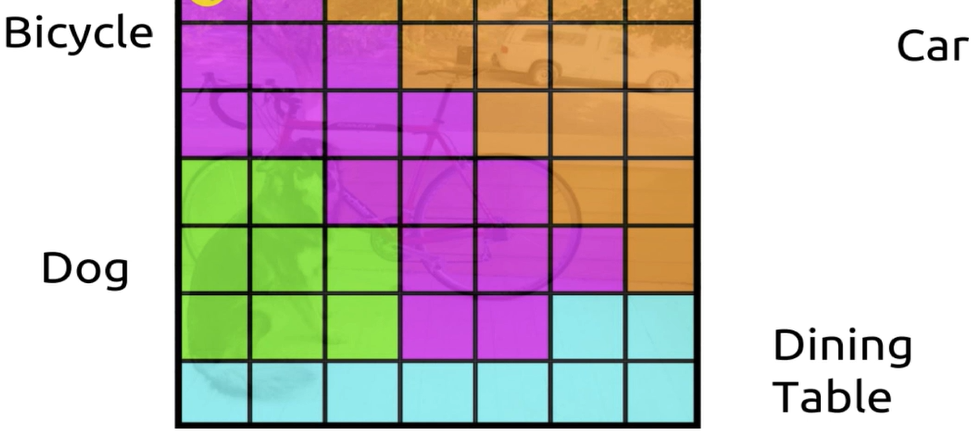
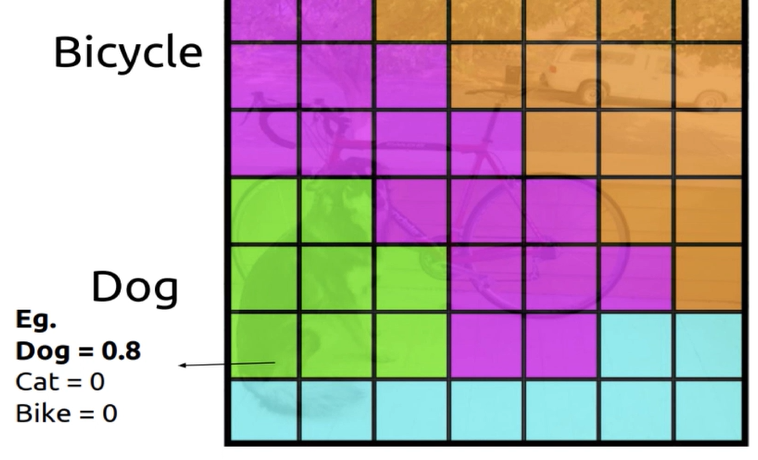
앞서 각 영역에 대해 제안한 바운딩 박스의 객체 존재 확률과 클래스 확률을 결합하여 클래스 예측을 얻는 것

비최대 억제(non-maximum suppression)
임계값 이하의 모든 탐지를 제거하는 것
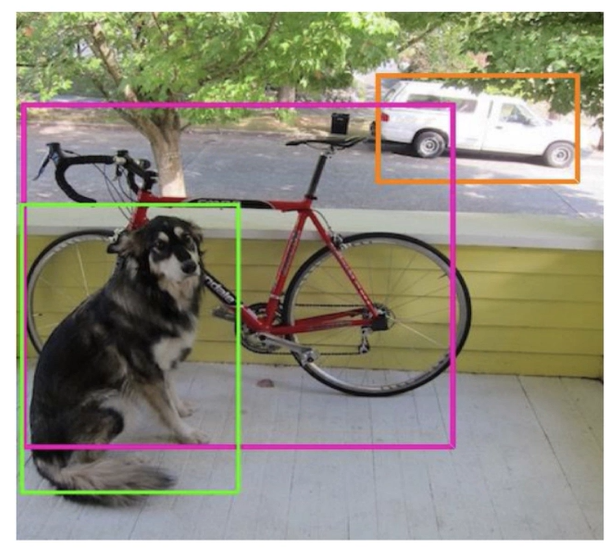
최종 출력
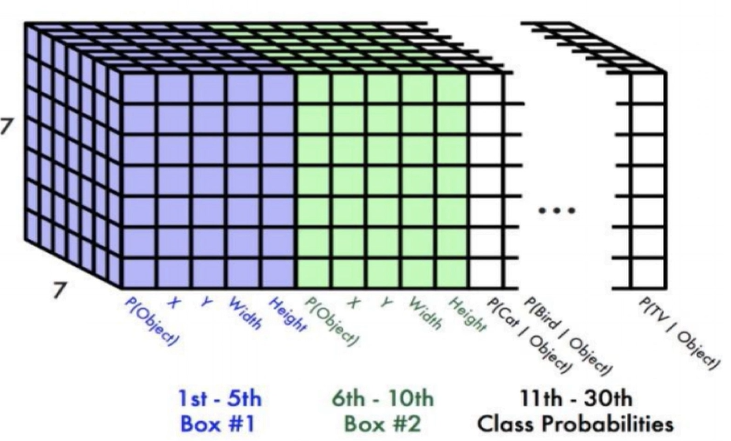
7x7 그리드와 객체 존재 확률, x, y 좌표, 너비와 높이가 포함된다.
마지막 오른쪽은 데이터의 세부 내용을 더 깊이 이해할 수 있으며,
이미지를 처리한 후 네트워크를 통과하여 얻은 출력 블록이다.
너무 깊게는 들어가지 않으며 실습을 통해서 알아가 보자.
