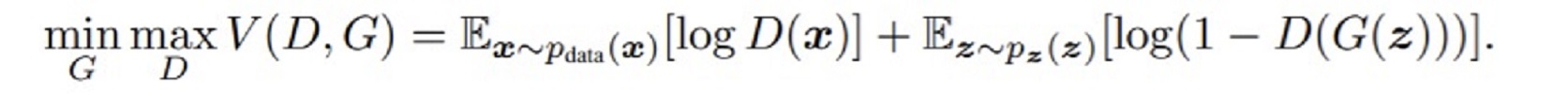
0. 포스팅을 시작하기에 앞서...
해당 포스트는 카이스트의 연구기업인 다임리서치와 함께 프로젝트를 수행하며 배운 지식들을 정리하기 위해 만들어졌다.
기업에서 제공해준 데이터와 각종 자료들을 공개할 순 없으므로
최대한 기술 관점에서 포스팅하려고 한다.
AnoGAN이 궁금하거나 이 모델을 다양한 데이터와 상황에서 적용하고 싶은 사람들에게 도움이 되었으면 좋겠다.
또한, 해당 분야 전문가가 아닌 평범한 학부생이 혼자 공부해서 작성하는 글이므로 부족한 설명이나 오류가 발생할 수 있다고 생각한다. 혹시 피드백을 받으면 꼭 수정하겠다.
1) 필요한 사전지식
GAN에 대한 기본적인 것부터 최대한 쉽게 설명해보겠지만
적어도 CNN(Convolutional Neural Network)은 알아야한다.
그리고 다른 regularization , Batch , Dropout등 딥러닝 기법들의 설명은 포스팅할 범위를 넘어가므로 따로 검색해보길 추천한다!
2) 목차
포스팅이 끝나면 작성
1. GAN
2. Anomaly Detection(feat. GAN?)
3) 참고 논문
- Generative Adversarial Nets
- Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery
- Time Series Anomaly Detection Based on GAN
앞 두개의 논문은 링크를 통해 간단하게 다운로드 가능하고
세번째 논문은 직접 다루진 않을 것이며 참고용도이다.
1. GAN이 뭔데?
Generative Adversarial Nets
(논문을 참고했으며 이미지를 누르면 논문을 바로 볼 수 있다)
CNN을 배운적이 있는 사람이라면 강의 끝쯤에 최신 트렌드의 기술이라며 GAN을 한번쯤 들어본적이 있을 것이다.
GAN은 Generative Adversarial Networks의 약자로
한국어로는 생성적 적대 신경망이다.
GAN의 중요 특징은 데이터를 생성하는 점에 있다.
가장 많이 드는 예는 지폐 위조범과 경찰의 예시로
간단히 말해, 위조지폐범은 지폐와 최대한 유사하게 만드려하고
경찰은 주어진 지폐가 위조인지 진짜인지 알아내려고 학습한다.
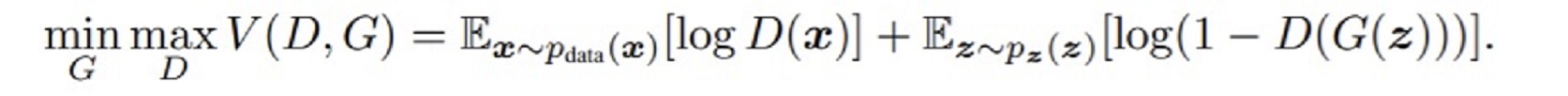
수식을 보면 GAN의 목표? 동작?을 알 수 있다.
- D( )는 들어온 값이 실제 데이터인 확률값을 출력한다.
실제 데이터일 확률이 높으면 1에 가까운 값을 출력한다.- G( )는 임의의 값이 들어오면 실제와 유사한 data를 출력
- x는 실제 데이터이다.
- z는 임의의 벡터 값이다. 주로 Generator에 입력된다.
수식을 보면 Generator는 위 수식을 최소화 시키려고하고
Discriminator는 위 수식을 최대화하려고 한다.
식을 쉽게 바꾸고 간단한 예를 들면 이해하기 용이한데
위 수식에서 단순히 학습을 위해 존재하는 log를 빼고
D(x) + (1-D(G(z)))라고 쉽게 바꿔서 생각해보자
예1) Discriminator가 우수하고 Generator가 멍청하다면?
D(x)==1, D(G(z))==0 으로 판별자는 완벽하게 구분할 것이다.
그렇다면 1-D(G(z))는 1이되며 결국 D(x) + (1-D(G(z))) 수식에서
결과값은 1 + 1이 되어 최대값이 된다.
예2) 반대로 D가 멍청하고 G가 우수하다면?
실제 데이터 x를 봐도 가짜 데이터로 판별하는 멍청한 D이므로
D(x)==0일 것이고 G가 생성한 가짜 데이터를 진짜로 판별하는게 최악의 Discriminator일 것이다. 따라서, D(G(z)) == 1
이렇게 되면 위에서 정리한 D(x) + (1-D(G(z)))
수식에서 0 + 0이 되므로 최소값이 된다.
Generator와 Discriminator는 예1과 예2의 극단적인 상황을 위해 함께 학습하게 되며 GAN에서 원하는 학습은 다음과 같다.
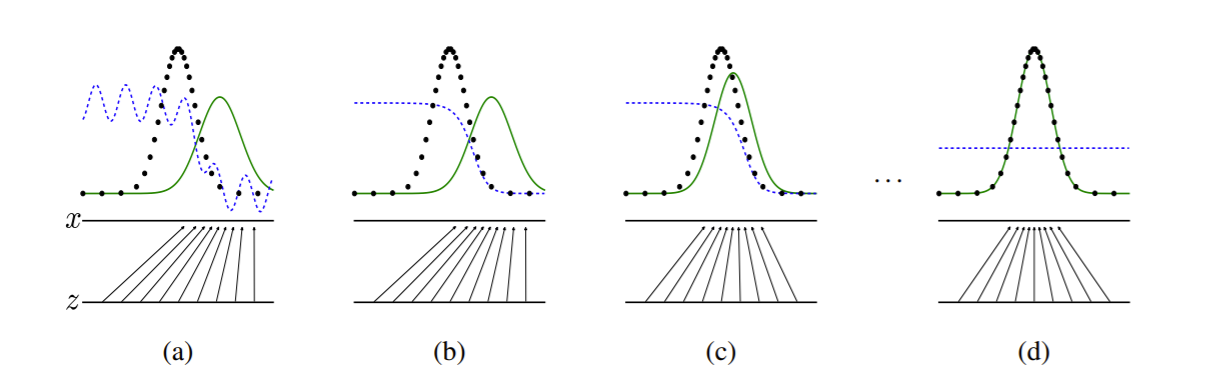
- 검은 점선 -> Real Data Distribution
- 초록색 곡선 -> Generator 가 생성해낸 Data Distribution
- 파란색 점선 -> Discriminator가 판별한 확률 (0~1)
둘을 경쟁시키며 서로 최선을 다해 발전시키다 보면
위조 지폐범은 실제와 굉장히 유사한 이미지를 만들어내고
판별자인 경찰은 제대로 판별하지 못하게 된다. (1/2확률)
(a)에서 (d)로 학습됨에 따라 Generator의 분포가 점점
실제 Data의 분포와 일치되는 것을 알 수 있다.
그에 따라 Discriminator는 1/2의 확률을 가지게 된다. (뭐가 실제 데이터인지 정확하게 모르는 상태)
이를 통해 우리는 GAN의 Generator로 실제 데이터와 유사한 이미지를 생성해낼 수 있게 되는것이 GAN의 최종목표이다.
해당 논문을 참고하면 위의 수식이 minmax problem을 해결할 수 있는지 해가 존재할 수 있는지 등의 검증을 제시하고 있다.
그러나, 본 포스팅의 목표는 AnoGAN이므로 GAN에 대한 일반적인 설명은 여기 까지만 하려고 한다. 혹시 검증에 대해서도 알고 싶다면 위 논문을 참고하기 바란다.
PR-001: Generative adversarial nets by Jaejun Yoo (2017/4/13)
유튜브의 딥러닝 논문읽기 영상인데 한국어로 잘 설명해주셔서 처음 이해할 때 크게 도움이 되었던 영상이다. 시간이 된다면
위 영상을 시청해서 GAN의 이해를 더욱 깊게 할 수 있을 것이다.
