AutoRec: Autoencoders Meet Collaborative Filtering (0) - autoencoder
 Autoencoder란?
Autoencoder란?
오토인코더는 차원이 축소된 입력데이터를 얻기 위해 비슷한 데이터로 표현하는 것을 배우기 위한 인공신경망이다.
입력데이터는 일반적으로 더 좋은 결과를 위해 PCA 혹은 CNN의 filtering같은 기법을 이용해서 차원을 축소하는 경향이 많다.
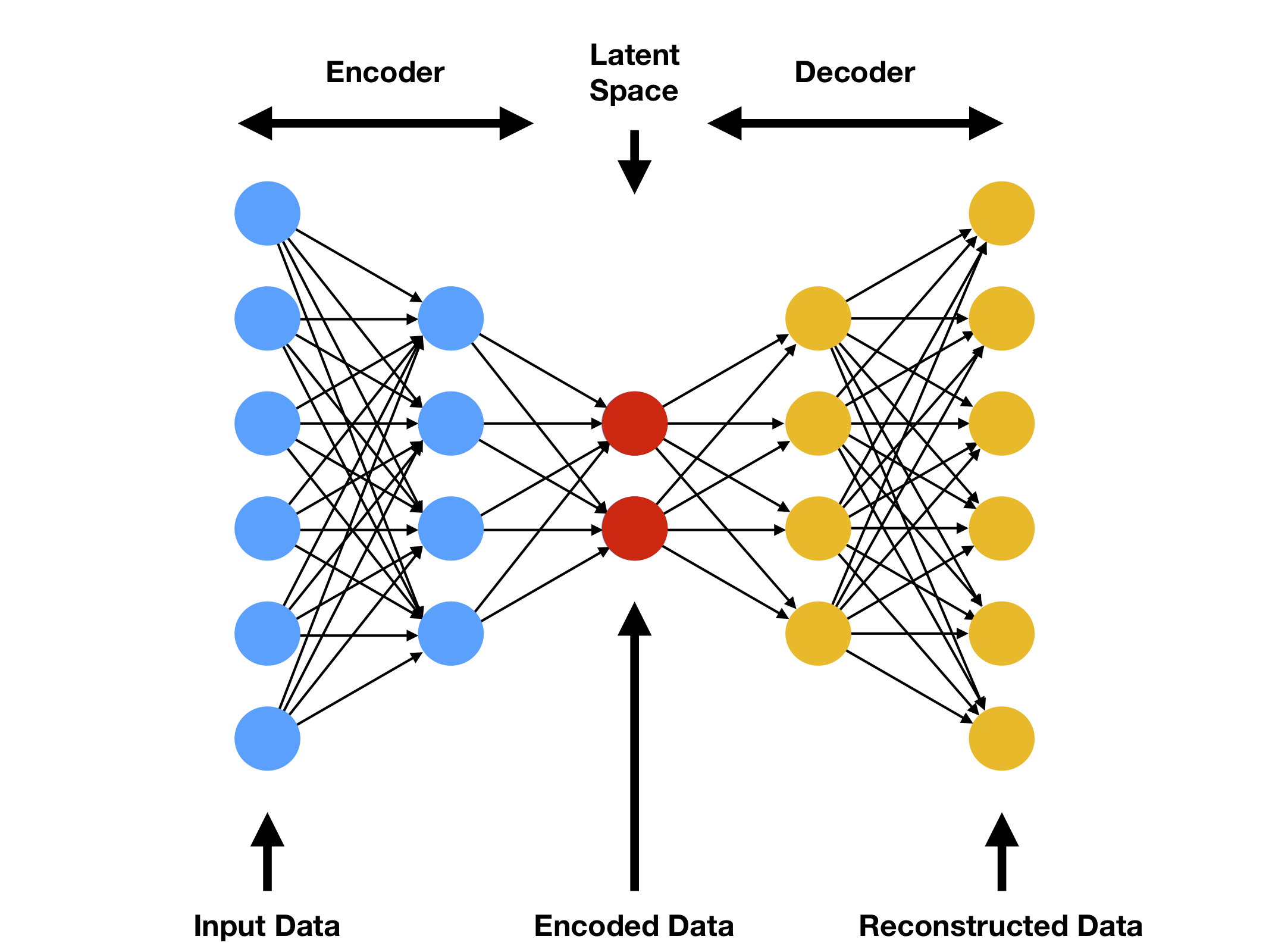
간단한 오토인코더를 설명해보면 신경망에서 입력데이터와 출력데이터는 같은 개수의 뉴럴을 가진다. 이는 오토인코더가 비지도 학습이며 라벨링된 데이터가 필요없다는 것을 의미한다.
또한, 중간의 히든레이어가 입력/출력레이어에 비해 뉴런이 작은 것으로 알려져있는데 오토인코더는 데이터의 상관관계를 학습해서 은닉층이 데이터에 대한 압축된 정보(표현)을 가짐으로 효과적인 성능을 얻을 수 있다.
입력층 -> 은닉층을 Encoding step
은닉층 -> 출력층을 Decoding step이라고 부른다.
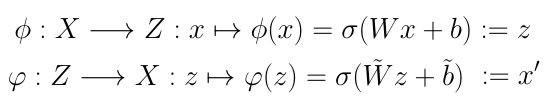
위 수식을 보면 X-> Z 그리고 Z-> X로 이동하는데
X -> Z로 이동한 결과를 z
Z -> X로 다시 이동한 결과를 x'라고 지칭한다.
이때, W와 b는 weight와 bias로 학습을 위해 각 뉴런에 계산되어지는 값인데 처음엔 랜덤값이 들어가고 학습이 끝난 이후엔 결과물의 오차가 가장 적은 W와 b를 얻을 수 있게 된다.
(Wx+b)앞의 시그마는 통계학의 표준편차가 아닌 비선형 함수를 의미하는데 sigmoid나 tanh같은 함수들이 들어간다.
이후 학습을 시작하게 되는데 특수한 가중치와 바이어스를 가진 z를 거쳐 얻게 되는 X'가 X와 동일하게 표현하도록 만들어지는 것이 가장 최고의 시나리오겠지만 X를 정확하게 표현하는 것은 불가능하다. 따라서, 가장 유사한 X'를 만드는 것이 최대 목표이다.
학습을 위해 Loss값을 MSE(Mean Square Error)로 지정하고(일부 논문에서는 overfitting을 막기위해 Regularization term을 추가할 것을 권장한다.) 최소화하는 W와 b를 찾기위해 stochastic gradient descent알고리즘을 사용하게 된다.
이런게 가장 기본적인 오토인코더이고 히든레이어가 한개가 아닌 깊게 쌓은 것을 Deep autoencoder라고 한다. 대부분 오토인코더라고 하면 Deep autoencoder를 지칭한다.
정리해보면 오토인코더란, 인코딩, 디코딩 과정을 거치면서 입력데이터와 최대한 유사한 데이터를 뽑아내는 딥러닝 기법이다. 애초에 라벨링 데이터를 입력할 수 없기에 비지도학습이며 가장 큰 특징으로는 은닉층이 작아졌다가 다시 커지는 경향을 가지고 있는 것이다.
그럼 이게 추천시스템에서 왜 쓰일까?
가장 주로 쓰이는 추천 알고리즘인 Collaborative Filtering은 데이터가 항상 Sparse하다는 약점을 가지고 있는데 현실적으로 우리만 보더라도 모든 카테고리 혹은 모든 아이템에 대한 리뷰를 남기진 않는다. 몇개의 관측치를 제외한 나머지는 전부 결측치가 될 것이다.
차원 축소를 위해 SVD 같은 기법이 사용되어 왔지만 결측치를 대체하는 방법을 사용했는데 이러한 대체는 신뢰도를 떨어뜨리는 주요 요인이 될 수 있다.
최근엔 주로 Matrix Factorization이라는 기법을 사용한다. 이 MF기법은 행렬분해를 이용한 일종의 차원축소 형태로 비어있는 행렬을 계산하기 위한 기법인데 기존 결측치가 문제였던 것을 해결했고 실제로 Netflix에서 사용되어 아주 좋은 성능을 보였다.
이런 Sparse한 데이터의 문제를 해결하는데 최근 연구중인 오토인코더는 매우 유용할 것이다. 두가지의 이점이 있는데
첫번째는 오토인코더는 x와 매우 유사한 x'를 만들면서 은닉층에 latent vector가 생성된다. 이 latent vector는 x'를 생성해내기 위해 x의 정보를 효과적으로 압축해서 가지고 있으며 이는 MF 기법이 하고자 하는 차원축소를 의미한다.
두번째는 Dense한 X'를 얻을 수 있다는 점이다. X는 매우 sparse하지만 X'는 모든 결측치가 채워져있는데 이를 활용할 수 도 있다. 실제 Training Deep Autoencoders for collaborative filtering, Oleksii Kuchaiev, Boris Ginsburg 논문에서는 이런 Dense한 X'를 활용하는 기법을 소개한다. 잘훈련된 Autoencoder라면 X와 유사하면서도 Dense한 X'를 생성해낼 것이고 이 X'를 대상으로 다시 X''를 만들어내면서 가중치를 업데이트하는것을 re-feeding이라고 한다.
