1. AWS에 카프카 클러스터 설치, 실행
https://blog.voidmainvoid.net/325
2. 카프카 프로듀서 애플리케이션
👉 Producer 역할
- Topic에 해당하는 메시지 생성
- 특정 Topic으로 데이터를 publish
- 처리 실패/재시도
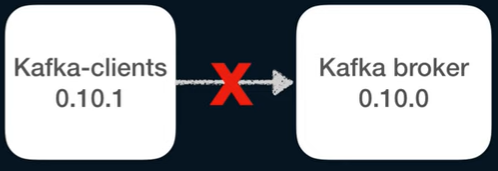
⚠️ 카프카는 브로커 버전과 클라이언드 버전의 호환성을 꼭 확인해야한다.
🖥️ Producer.java
Properties configs = new Properties();
configs.put("bootstrap.servers", "localhost:9092");
configs.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
configs.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");- Kafka 서버 주소와 직렬화 방식 설정
- 실제 서비스에서는 2개 이상의 브로커 주소를 넣는 것을 권장!
KafkaProducer<String, String> producer = new KafkaProducer<>(configs);
ProducerRecord record = new ProducerRecord<>("click_log", "login");
producer.send(record);
producer.close();- 위 설정을 기반으로
KafkaProducer객체 생성 - click_log 토픽에 "login" 메시지 전송
- 키를 지정하지 않으면 Kafka가 파티션을 자동으로 분배
.send()로 메시지를 비동기 전송.close()는 리소스를 해제하는 필수 작업
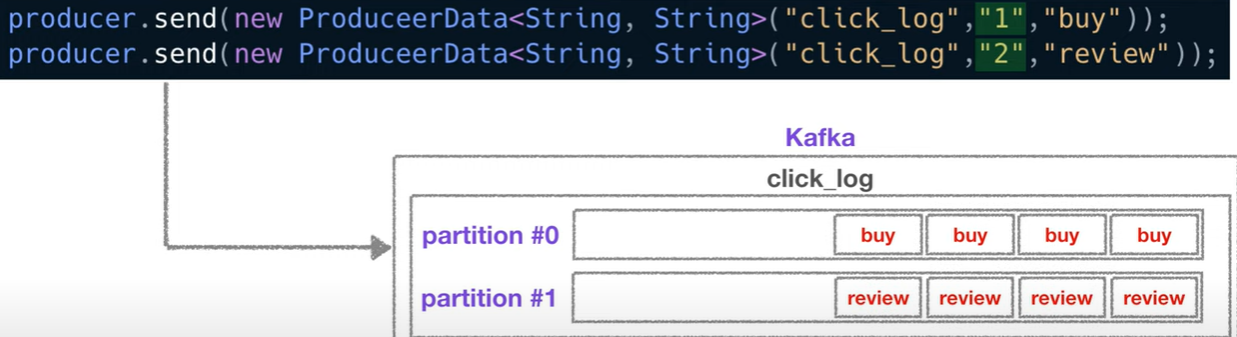
⚠️ send에 key값을 "1","2"와 같이 설정을 한다면 그림과 같이 데이터가 나뉘어지지만, 파티션이 하나 추가된다면 key와 파티션 매칭이 깨져서 key <-> 파티션 일관성이 보장되지 않는다.
3. 카프카 컨슈머 애플리케이션
👉 Consumer 역할
- Topic의 partition에서 데이터 polling
- Partition offset 위치 기록 (commit)
- Consumer group을 통해 병렬처리
🖥️ Consumer.java
configs.put("bootstrap.servers", "localhost:9092");
configs.put("group.id", "click_log_group");
configs.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
configs.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");- Kafka 브로커 주소 및 컨슈머 그룹 ID 설정
- Key/Value 디시리얼화 -> Kafka 메시지 읽기 준비 완료!
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList("click_log"));- "click_log" 토픽을 구독
subscribe()는 전체 파티션을 자동 분배받음- 특정 파티션만 읽고 싶다면
assign()을 사용해야 함
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(500));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
}- 0.5초 동안 메시지를 기다렸다가 처리
- 한 번에 여러 개의 메시지를 받아오고
record.value()로 개별 처리 - 실제 서비스에서는 DB, 로그 저장 등으로 확장 가능
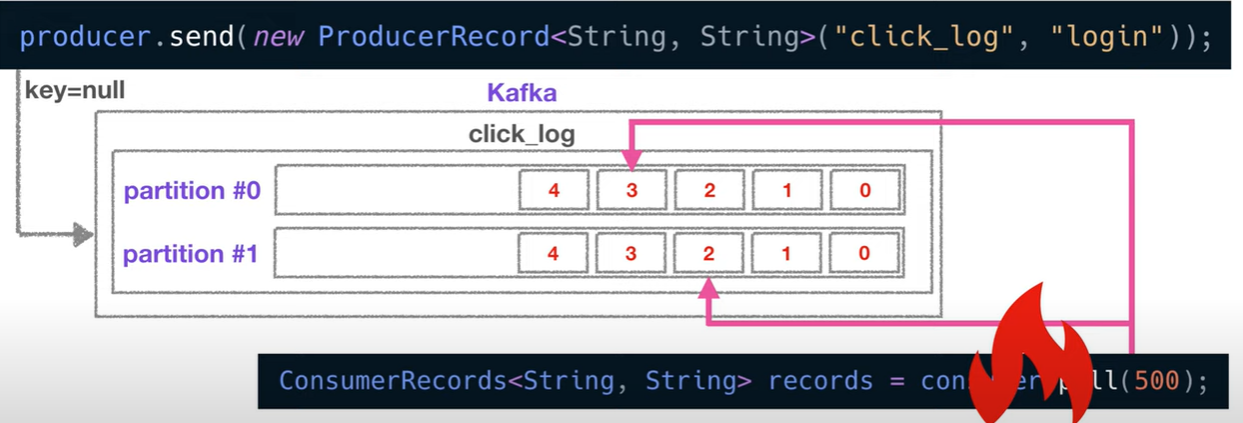
⚠️ 컨슈머가 파티션이 2개인 click_log 토픽에서 데이터를 가져가는 중에 실행이 중지되어도, 어느 offset까지 읽었는지 consumer_offset 에 저장되어 있어 오류 시작위치부터 다시 복구할 수 있다.
= ✔️고가용성의 특징
⚠️여러 파티션에 대해 병렬처리를 원한다면 컨슈머 수는 파티션 수보다 적거나 같아야한다.
⚠️하나의 토픽에 들어온 데이터는 여러 컨슈머 그룹이 독립적으로 소비하여 서로 간섭 없이 각자의 역할에 따라 처리한다.
4. 카프카 스트림즈 애플리케이션
Kafka Streams는 카프카에서 공식으로 제공하는 Java 기반의 스트림 처리 라이브러리이다.
기존의 Kafka Consumer를 사용하는 방식보다 더 빠르고 안정적인 데이터 처리가 가능하고 실시간 데이터 파이프라인 구축에 적합하다.
✅ Kafka와 완벽하게 호환
Kafka Streams는 Kafka의 버전에 맞춰 함께 업데이트되므로 보안 기능이나 트랜잭션 처리 등 최신 기능과의 호환성이 뛰어나다.
-> 즉 Kafka 클러스터와 항상 완벽하게 맞물려 돌아가는 구조!!
+Exactly Once Processing(정확히 한 번 처리) 기능을 기본 지원해 데이터 유실이나 중복 없이 안전하게 처리 가능
✅ 별도의 클러스터 없이 운영 가능
컨슈머처럼 애플리케이션 단독으로 배포하면 된다.
-> 즉, 클러스터나 스케줄러 없이도 운영이 가능하다는 점에서 구조가 단순하고 유연!!
데이터 양이 적다면 애플리케이션 몇 개만 띄워도 충분하고 처리량에 따라 자연스럽게 수평 확장할 수 있다.
✅ DSL과 Processor API 제공
스트림 처리에 필요한 대부분의 기능을 DSL로 제공한다.
ex) filter, map, join, window 등은 모두 간단한 메서드 호출로 구현 가능
-> 복잡한 로직이 필요한 경우에는 Processor API를 통해 직접 로직을 정의해 더 세밀한 제어도 가능하다.
5. 카프카 커넥트
Kafka에서 공식적으로 제공하는 데이터 파이프라인 컴포넌트이다.
데이터 송수신을 반복적으로 처리해야 하는 환경에서는 도입을 적극 검토할 만한 플랫폼이다.
➡️ 커넥트 vs 커넥터
- Connect는 커넥터를 실행시키는 플랫폼 역할, 일종의 실행환경(Processor)
- Connector는 실제 데이터를 송수신하는 로직이 담긴 코드 뭉치(JAR 패키지)
➡️ 커넥터의 종류
- Source Connector: 외부 데이터 소스(DB 등) → Kafka 토픽으로 데이터를 보내는 역할 (프로듀서 역할)
- Sink Connector: Kafka 토픽 → 외부 저장소(DB, Elasticsearch 등)로 데이터를 저장하는 역할 (컨슈머 역할)
- ex) 오라클 DB 데이터를 Kafka로 가져오고 싶다면 → Oracle Source Connector
➡️ 커넥트 실행 방식
- 단일 모드 (Standalone Mode): 개발/테스트용으로 간단히 실행 가능
- 분산 모드 (Distributed Mode): 프로덕션 환경에서 사용하는 방식
여러 커넥트 인스턴스를 클러스터로 구성하여 장애 발생 시 자동 복구(Failover)가 가능하다.
➡️ 실행 방법: REST API로 간단하게
커넥트는 REST API 기반으로 커넥터를 실행할 수 있다.
즉, 커넥터 코드를 별도로 배포하거나 다시 개발할 필요 없이 JSON 설정 파일 하나로 파이프라인을 반복적으로 생성한다.
ex) 동일한 Kafka 토픽 데이터를 오라클 테이블 A, 테이블 B에 각각 저장하고 싶다면? JSON 설정을 두 개 만들고 REST API로 두 번 요청만 하면 되는 것이다.
-> 복잡한 배포, 컨슈머 개발 없이 템플릿 기반으로 빠르고 효율적인 데이터 흐름 구성이 가능해진다.
