@Algorithms
Copyrigh 2006 S. Dasgupta, C. H. Papadimitriou, and U. V. Vazirani July 18, 2006
2단원
Divide and conquer 의 전략
- 하나의 큰 문제를 같은 type의 subproblems로 쪼갠다.
- Subproblems를 재귀적으로 푼다
- 적절하게 subproblems의 답을 합친다
1. Multiplication
인데,
이 경우를 보면 real value의 곱이 4번 이루어지는 것처럼 보일 수 있지만 사실은 3개로 계산이 될 수 있다.
로 가능!
4개의 계산을 3개의 계산으로 줄이는 것이 큰 의미가 없어 보일 수 있지만, 재귀적으로 실행이 된다면 꽤나 큰 의미가 될 것이다.
복소수 말고 일반적인 상황을 이제 생각해보자.
가 n-bit integer라고 해보자. 그리고 편의상 n은 2의 제곱수라고 두자.
를 계산할 때, 와 를 크기가 n/2인 왼쪽, 오른쪽 부분으로 나눠보자.
예를 들어, 2진수를 표현할 때
이면, 이라 표현할 수 있다. 그리고 .
이러면 계산을
로 볼 수 있다.
더하기는 linear time이 걸리고, 2의 제곱수에 의한 곱셈(left-shift) 또한 그렇다. 중요한 계산은 4개의 n/2 bit의 곱셈이다.() 이는 4번의 재귀로 처리할 수 있다.
그래서 n-bit의 숫자들을 곱하는 방법은 4개의 n/2-bit 수(4개의 사이즈가 반으로 줄은 subproblems)를 곱하는 재귀적 호출을 만들며 시작한다. 그리고 이전 표현을 이라고 해보자.
그러면 n-bit 입력의 전체 계산 시간을 으로 쓰면서, 이라는 recurrence relation을 얻을 수 있다.
이렇게 되면 전통적인 초등학교 곱셈 기술의 실행 시간과 같게 시간 복잡도가 이 되어버린다. 그렇다면 어떻게 하면 줄일 수 있을까??
이 때 Gaussian trick을 쓰는거다. 의 표현이 n/2 - bit의 곱셈이 4번 필요한 것처럼 보이지만 3개가 필요할 것이다!
()
이 알고리즘을 이용하면 실행 시간이 줄어든다.
으로!
여기서 포인트는 constant factor가 개선되었다는 것이고, 이것은 재귀의 모든 레벨에서 일어난다는 것이다.
그리고 이 compounding effect는 시간 복잡도를 로 크게 낮춰준다.
이 실행시간은 tree 구조의 재귀로 측정했다. level에서 subproblems의 사이즈는 1이 되고 재귀가 끝남. 그래서 Tree의 높이는 이 되고, branching factor는 3이 된다.(깊이가 k일 때, 크기가 인 subproblems를 개 만드는..)
For each subproblem, a linear amount of work is done in identifying further subproblems and combining their answers. Therefore the total time spent at depth k in the tree is
subproblems에 대해, 추가 하위 문제를 식별하고 답을 조합하는 데 선형 작업량이 수행된다. 그래서 깊이가 k인 tree에 쓰이는 총 시간은
가장 위의 top level에서(k=0 일 때) .
가장 아래의 bottom level에서(k= 이고, 이라고 쓸 수 있다.
두 end points 사이에서 수행된 작업은 level당 a factor of 3/2에 의해서 기하학적으로 증가함.
Constant factor를 가진 아무 증가하는 기하학적 급수의 합은 단순히 급수의 마지막 항이다. 총 running time은
Gaussian trick이 없었다면, recursion tree는 같은 높이에 branching factor가 4였을 것이다. 그러면 개의 잎들이 있을 것이고, 실행 시간도 적어도 이정도 일 것이다.
Divide-and-conquer algorithms에서, subproblems의 수가 recursion tree의 branching factor이 된다. 여기서의 작은 변화는 실행 시간에 큰 영향을 줄 것이다.
Practical Note
일반적으로 1비트까지 재귀를 계속할 필요가 없다. 대부분의 프로세서에서는 16비트 또는 32비트 곱셈이 단일 작업(single-operation)으로 처리되므로 숫자가 이 범위로 들어가면 내장 프로시저로 전달해야 한다.
2. Recurrence relations
Divide-and-conquer 문제는 일반적인 패턴이 있다 : 사이즈가 n인 문제를 푸는 것을 크기가 인 개의 subproblems를 재귀적으로 풀고, 이 답들을 시간에 합치는 것이다. (for some )
그래서 실행 시간을 라는 식으로 볼 수 있다.
이 때, 실행 시간 generalize.
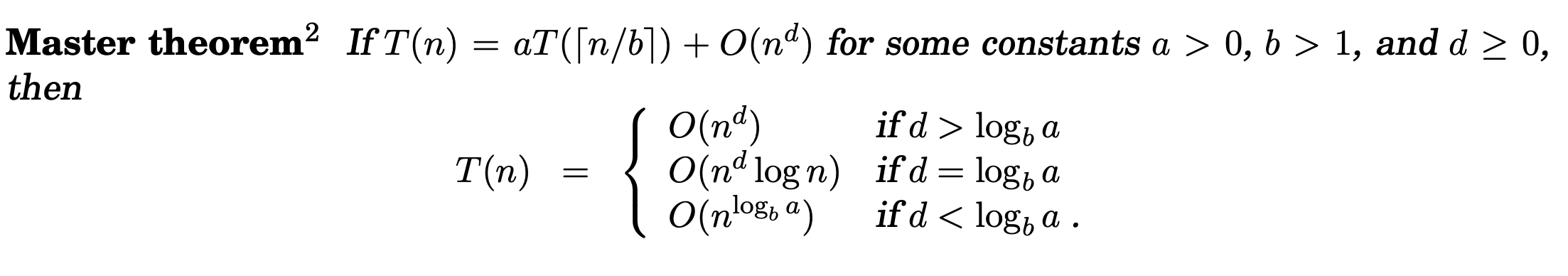
branching factor가 일 때, 마지막 level의 subproblems는 개 있고 그 때 size는 이다.
그러면 total work at last level은
여기서 의 범위를 나눠서 확인하면 된다!
ex) 일 때, 일 때, 일 때로
3. Mergesort
divide-and-conquer 전략을 이용해서 sort하는 방법 : 반으로 나눠 재귀적으로 sort! 그리고 정렬된 sublists들을 합쳐줌!
function mergesort (a[1...n])
Input: An array of a[1...n]
Output: A sorted version of this array
if n > 1:
return merge(mergesort(a[1...⌊n/2⌋], mergesort(a[⌊n/2⌋+1...n])
else:
return a만약에 sort가 잘 되었다면 어떻게 합칠까?
function merge(x[1...k], y[1...l])
if k = 0: return y[1...l]
if l = 0: return x[1...k]
if x[1] <= y[1]:
return x[1] ◦ merge(x[2...k], y[1...l])
else:
return y[1] ◦ merge(x[1...k], y[2...l])여기서 "◦"기호는 concatenate를 뜻한다.
Merge의 총 실행시간은 이다. Merge의 작업 시간은 linear하고, 그래서 mergesort의 총 시간은
or
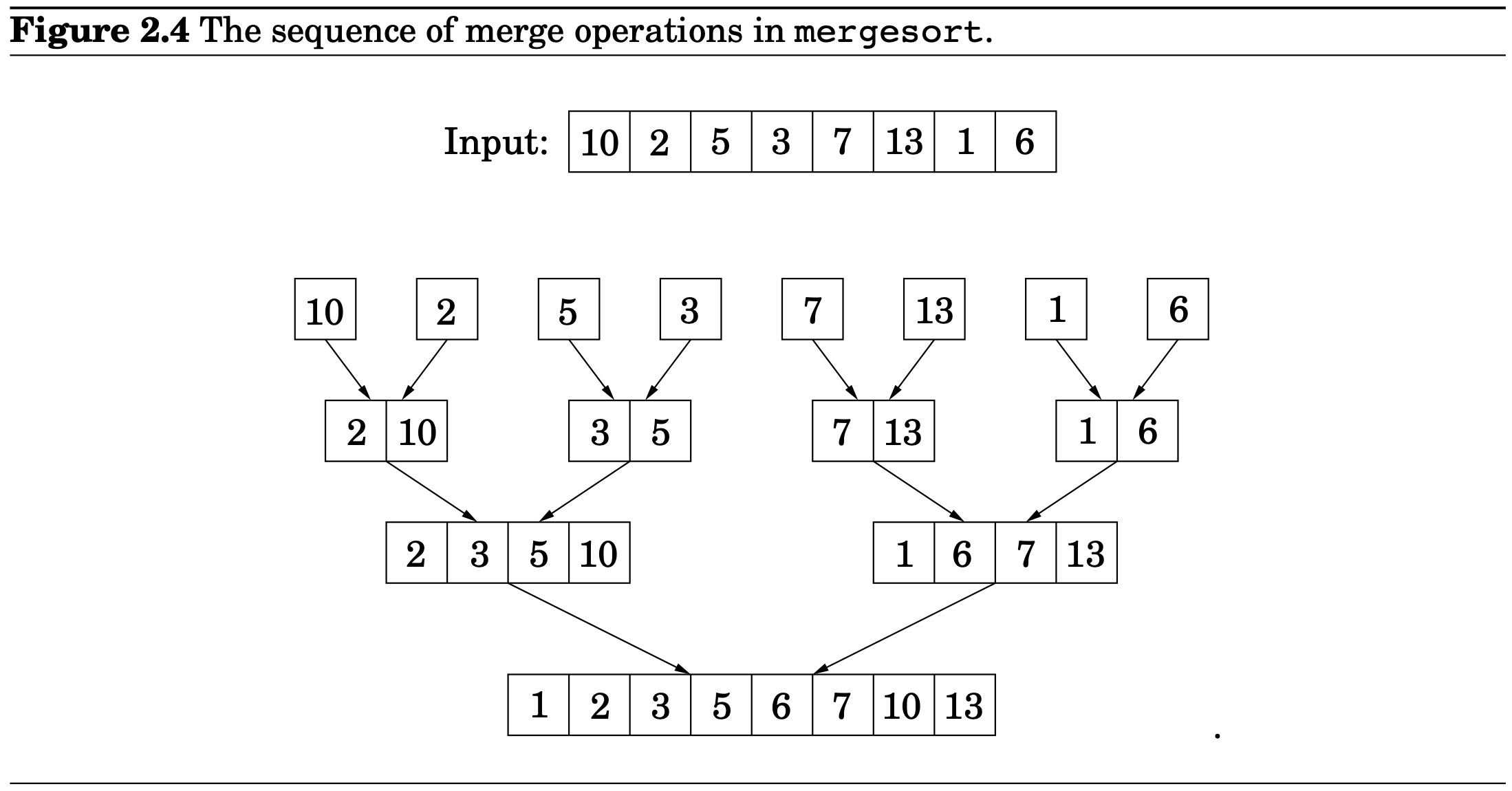
이걸 Queue를 이용해서 표시할 수 있다. Queue에서 앞의 2개의 배열을 뽑아 merge 시킨 후, Queue의 뒤에 넣는 형식을 반복하면서!
function iterative-mergesort(a[1 . . . n])
Input: elements a1,a2,...,an to be sorted
Q = [ ] (empty queue)
for i=1 to n:
inject(Q, [ai])
while |Q| > 1:
inject(Q, merge(eject(Q), eject(Q)))
return eject(Q)해석 및 예시)
1,10,5,7,8 이 있다고 해보자!
에 다 넣어준다 (for i=1 to n: inject(, ))
에서 앞의 두 개 꺼냄 merge 해서 Q에 넣음(merge는 위에서 정의로 나타내었다.)
또 여기서 2개 꺼냄 merge 해서 Q에 넣음
또 여기서 2개 꺼냄 merge 해서 Q에 넣음(위에 있는 뭐가 큰 지 비교하면서 merge하는 방법)
2개 꺼냄
이렇게 되면 이제 에 array가 1개 있으니 while문 끝내고 Eject!!
4. Medians
list에서 median(중앙값)은 50%인 수이다: 리스트의 반은 median보다 크고, 반은 median보다 작은.
list의 길이가 짝수이면 median 값으로 고를 수 있는 2가지의 선택지가 있는데, 이 경우 우리는 작은 값을 고르자고 하자!
중앙값을 이용하는 이유는 set of numbers를 하나의 값으로 요약하기 위해서 이다. 이 경우 평균을 이용하기도 하지만, 중앙값은 데이터에 대하여 어떤 의미에서 더 대표적이다: 평균과 달리 중앙값은 데이터 값 중에 하나이며, 평균보다 이상치에 덜 민감하다.
개 숫자들의 중앙값을 계산하는 방법은? Just sort!
근데 그렇게 하면 이 걸린다는 단점이 있고, 좀 더 선형적인 것을 원한다. 여기서 희망을 가져도 되는 이유는 median을 중앙값을 찾는 것이라 sort 전부 할 필요가 없다는 것이다.
A randomized divide-and-conquer algorithm for selection
랜덤하게 하나의 숫자를 뽑아서 list를 3개의 부분으로 나눠보자: 랜덤하게 뽑은 숫자보다 작은 elements, 같은 elements, 큰 elements
이렇게 되면, searching은 즉시 sublists들 중 하나로 좁혀질 수 있다.
selection(List, k) List에서 k번째로 작은 수를 뽑아라.
General하게 말하면,
을 통해서 sublists를 만들어 searching을 수행할 수 있다.
비교해 주는 값 v는 어떻게 특정할까?
빠르게 선택되어야하고, array를 잘 줄여야한다.
가장 이상적인 상황은 다. 만약 이렇게 계속 나눌 수 있는게 보장이 된다면 running time은
하지만 이것은 우리의 궁극적인 목표인 가 list에서 중앙값을 뽑아야 한다는 것이 필요하다. 대신에 우리는 간단하게 S에서 를 random하게 뽑는 대안을 따른다.
Efficiency analysis
우리의 알고리즘의 running time은 를 고르는 것에 달려있다. 운이 안좋아서 list에서 가장 작은 숫자나 가장 큰 숫자를 고르는 상황이 계속 발생하면 각 시간 당 array의 크기는 하나씩 줄어든다. Median을 고를 때 최악의 상황이 발생한다면 (일어날 일은 거의 없지만)
만약 가장 좋은 상황이 발생한다면(를 정확히 array를 반으로 갈라줄 수 있는 것으로 고르면) running time은 이 될것이다. (이 땐 median을 고르는 특정 task가 아닌 일반적인 k번째 작은 수를 뽑는 task 인 듯)
그러면 결국 이 방법을 사용하면 running time의 범위는 to 인데, 평균은 어디일까?
운이 좋게도, best case time 근처에 있다!
lucky 와 unlucky 를 본다면,
만약 가 25%엥서 75% 배열의 사이에 있는 수라면 good 이라 부를 것이다. 왜냐면 이렇게 되면 S의 크기를 적어도 3/4로 줄여주고, array를 충분히 줄여준다. 그리고 운이 좋게도, 좋은 들은 배열의 반이므로 풍부하다.
좋은 를 얻기 위해 평균적으로 몇 번 를 골라야 할까?
(밑에 Lemma 확인)
Lemma
On average a fair coin needs to be tossed two times before a “heads” is seen.
Let be the expected number of tosses before a heads is seen. We certainly need at least one toss, and if it’s heads, we’re done. If it’s tails (which occurs with probability 1/2), we need to repeat. Hence , which works out to .
그냥 생각해볼 수 있을 정도. 50% 안에 드는거니까 2번 뽑으면 아마 1번은 good 가 있을 것이다.(평균적으로)
그래서 평균적으로 두 번의 split operations 후에, array는 적어도 3/4 크기로 줄어들 것이다.
을 사이즈가 인 array의 running time의 기댓값이라 한다면,
This follows by taking expected values of both sides of the following statement:
Time taken on an array of size (time taken on an array of size ) + (time to reduce array size to ≤ )
and, for the right-hand side, using the familiar property that the expectation of the sum is the sum of the expectations.
이걸 보고 이라 결론짓는다: 어떤 입력에 대해서도 우리의 알고리즘은 평균적으로 선형적 수 단계 이후에 옳은 답을 반환한다.
5. Matrix multiplication
Matrix multiplication은 시간 복잡도가 이고, 더 효율적인 방법은 없을 것이라고 생각했다. 하지만 1969 독일 수학자 Volker Strassen가 더 효율적인 방법을 발표했다.
Matrix multiplication은 블록 단위로 수행될 수 있기 때문에 쉽게 subproblems로 나눌 수 있다.
크기가 인 matrix를 크기가 인 matrix로 쪼개서!
이러면, 크기가 인 를 재귀적으로 크기가 인 여덟 번의 곱()과 조금()의 덧셈으로 계산한다. 그래서 recurrence relation으로 묘사된 총 running time은
이다.
이는 기본 알고리즘과 같은 으로 나타난다.
근데 여기서 효율성이 증가할 수 있다. 는 7개의 인 subproblems로 계산될 수 있다.
where
이걸 이용한 new running time은
which by the master theorem works out to .
6. The fast Fourier transform
지금까지 divide-and-conquer를 integer과 matrix의 곱에 이용해 fast algorithms을 얻을 수 있었는데, 이젠 polynomial(다항식)에 적용해볼 것이다.
More generally, if and , their product has coefficients
(for , take and to be zero)
이 식을 통해 를 계산하는 것은 의 step이 걸리고, 개의 coefficients를 모두 찾으면 이 필요할 것으로 보인다.
Computing from this formula takes O(k) steps, and finding all 2d + 1 coefficients would therefore seem to require Θ(d2) time.
6-1) An alternative representation of polynomials
Fact)
개의 서로 다른 점들의 값들로 차 다항식이 유일하게 특정지어진다.
인 다항식은 아래의 두 가지 방법 중 하나로 특정할 수 있다.
- Its coefficients
- The values
2번째 방법이 다항식 곱셈에서 더욱 매력적이다. 의 coefficients를 갖는 는 개의 서로 다른 점들로 완벽히 특정할 수 있다. 그리고 주어진 점 는 찾아내기 쉽다. 그냥 니까.
문제점은 우리는 coefficients에 의해 input polynomials와 그들의 곱이 특정되는 것을 기대한다. 그래서 우리는 coefficient에서 value로 바꿔주어야하고(주어진 점들에서 polynomials를 평가하는(evaluating) 방법), 그리고 value representation에서 곱해주어야하고, 마지막으로 다시 coefficients로 바꿔주어야한다.(마지막 과정을 interpolation이라고 함)

6-2) Evaluation by divide-and-conquer
n개의 점들을 뽑아 차수가 n-1보다 작은 polynomial 를 evaluate하는 방법!
Positive-negative 쌍을 고르면 된다. 즉,
이렇게 된다면, 와 의 짝수 차수가 같기 때문에 각 와 에 필요한 계산이 많이 겹친다.
이 부분을 조사하기 위해서 를 (짝수 차수)와 (홀수 차수)로 나누어 준다.
괄호 안의 다항식은 의 다항식이다.
where , with the even-numbered coefficients, and , with the odd-numbered coefficients, are polynomials of degree ≤ n/2 − 1 (assume for convenience that n is even).
주어진 쌍에 대해, 에 필요한 계산은 를 계산할 때 다시 사용할 수 있다.
다르게 말하면, n개의 paired points()에서 를 평가하는(evaluating) 것이 와 (에 비해 차수가 반)를 개의 점()에서 평가하는 것으로 줄었다.
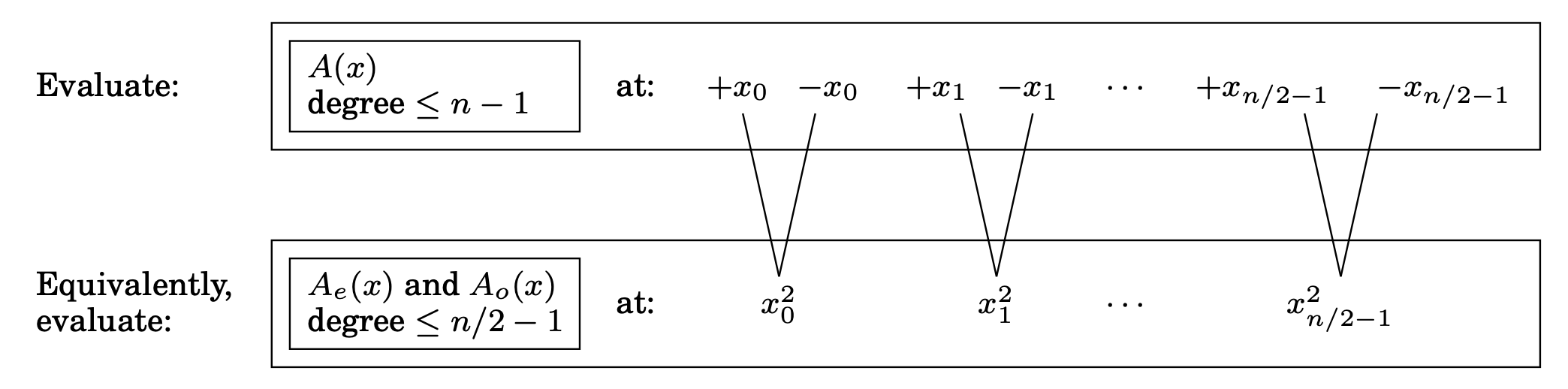
원래의 크기가 n이었던 문제가 크기가 n/2인 subproblem으로 바뀌고 조금의 linear-time 산술이 따라온다. If we could recurse, we would get a divide-and-conquer procedure with running time
which is
(점들의 개수가 1/2로 줄어들고, 식들이 로 2개로 늘어난다.)
근데 이렇게 되어버리면, 가장 상위에서는 이루어 지는데 이후부터는 문제가 생긴다: 개의 evaluation points 이 자기 스스로 plus-minus 쌍이 되기 위해 필요하다. 근데 어떻게 제곱수가 음수가 되나?! 그래서 여기서 복소수를 이용한다!
(Subproblems으로 들어갈 때, 을 로 두니까 이 때의 음수 점을 뽑는다고 해보자. 그러면 에서 이 음수 점이 된 것이다. 이럴 때 complex numbers를 이용한다는 것.)
이 때 어떤 complex numbers를 사용해야 하나?
“reverse engineer” process를 봐보자.
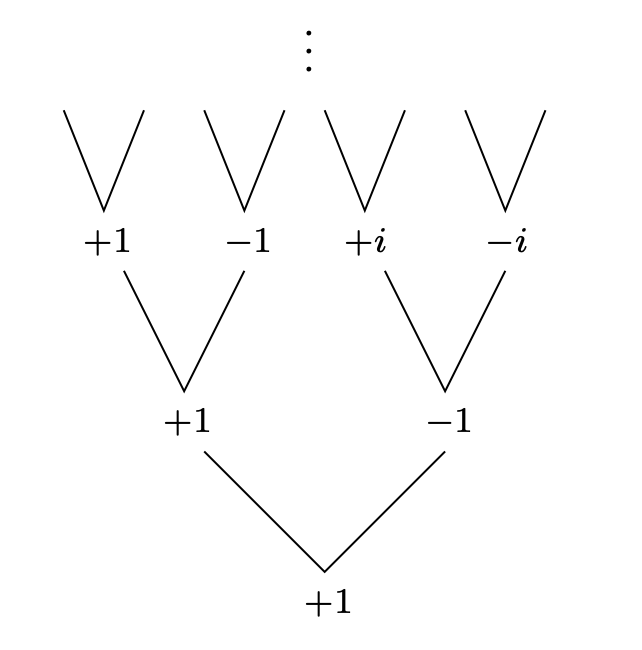
그림을 보고, 아마 어떻게 표현하는지 알 것이다.
The complex roots of unity는 의 n개의 complex solution이다.
roots of unity: the complex numbers where
6-3) Interpolation
Value representation도 다항식을 특정하지만, coefficient representation을 무시할 순 없다. 그래서 점들 {}이 root of unity()일 때, time 만에 coefficient에서 value로 가는 FFT를 만들었다.
<Values> = FFT(<coefficients>, )
이렇게 되면 남은 것은 inverse operation인 interpolation인데, 이것은 이렇게 표현할 수 있다.
<Coefficients> = FFT(<values>,)
Interpolation은 대신 를 이용한 FFT 알고리즘을 이용해 가장 간단하게 풀어졌다.
A matrix reformulation
Interpolation을 잘 보려면, 차수가 인 다항식 에 대한 두 가지의 표현법 간의 관계를 잘 봐야한다. 둘 다 n개의 숫자로 이루어진 벡터이고, 하나는 다른 하나의 linear transformation이다.
중간의 matrix를 이라고 부른다. 그리고 Vandermonde matrix라는 특정한 형식을 가지고 있는데, 이는 주목 할만한 많은 성질을 갖고 있는데 우리와 관련이 있는 것은 바로!
If are distinct numbers, then is invertible.
이 존재한다는 것은 coefficient를 values로 표현할 수 있게 해준다.
간략하게 말하면,
Evaluation은 에 의한 곱이고, Interpolation은 에 의한 곱이다.
일반 행렬이 역행렬을 계산하는데 이 걸리는 것에 비해 Vadermonde 행렬은 특수한 형태와 구조를 갖고 있어 역행렬을 계산하는데 밖에 걸리지 않는 특징이 있다.
하지만 interpolation에 이를 사용해도 여전히 충분히 빠르지 않아서, interpolation 할 때도 complex roots of unity를 이용함.(아까 이용한 것)
Interpolation resolved
FFT는 coefficients vector라고 불리는 임의의 n차원의 벡터에 matrix를 곱해준다.
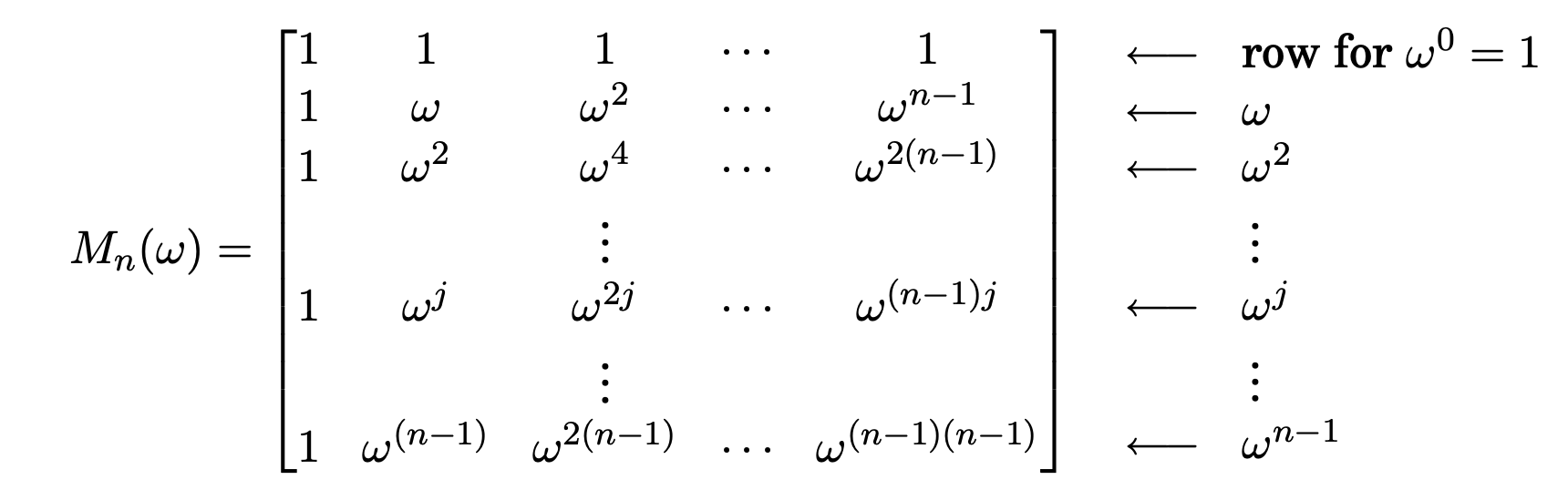
where is a complex root of unity, and is a power of 2.
에 의한 곱셈은 coordinate axis(position이 k인 곳만 1이고 나머지는 0인 vector)를 의 column에 연결해준다.
여기서 중요한 관찰이 있는데, columns of 이 서로에게 orthogonal이라는 것이다.
그래서 columns of 은 Fourier basis라고 불리는 alternative coordinate system의 축이라고 생각할 수 있다.
Vector에 을 곱하는 것의 효과는 vector를 standard basis에서 의 column으로 정의된 fourier basis로 회전시키는 것이다.
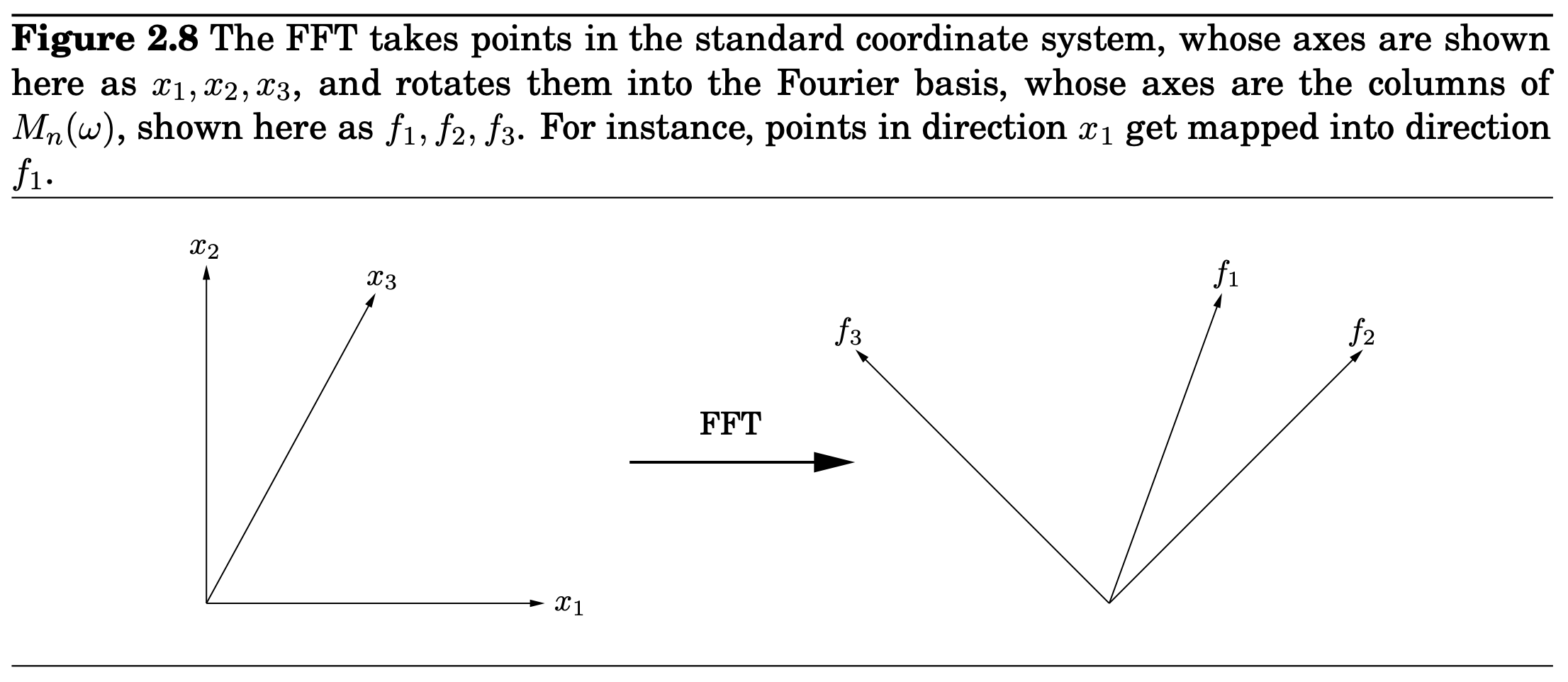
그래서 FFT는 basis를 바꾸는 것이고, rigid rotation이다.
Inverse of 은 fourier basis에서 standard basis로 바꾸는 반대의 rotation이다. 우리가 정확하게 orthogonality condition을 작성하면, 이 inverse transformation을 쉽게 파악할 수 있을 것입니다.
Inverse Formula
또한 root of unity이고, 에 의한 곱인 interpolation도 자체로 FFT operation 이다. (를 로 바꾼)
편의성을 위해 를 으로 두고, 의 column을 의 벡터라고 보겠다.
안의 두 벡터, 과 의 사이각은 크기가 조절된 inner product이다.
where 은 의 켤레 복소수.
Lemma)
The columns of matrix are orthogonal to each other.
Take the inner product of any columns and of matrix ,
이고, which is 0—except when , in which case all terms are and the sum is .
The orthogonality property can be summarized in the single equation
,
가 의 i번째 column과 j번째 column의 inner product이기 때문에.
This implies
Polynomial multiplication은 standard basis 안에서 하는 것보다 fourier basis 안에서 하는 더 쉽다.
그래서 vector를 Fourier basis로 회전시켜주고(evaluation), multiplication을 하고, 마지막으로 다시 회전시켜준다(interpolation).
그러면 처음 vector는 coefficient representation이고, 회전시켜주면 value representation이다.
이들 사이를 효율적으로 바꿔주는 것이 FFT의 영역이다.
6-4) A closer look at the fast Fourier transform
The definitive FFT algorithm
FFT는 vector 와 제곱수들 이 the complex nth roots of unity인 complex number 를 input으로 받는다.
이 행렬-벡터 곱셈에서 분할-정복을 사용할 수 있는 잠재력은 의 columns이 짝수와 홀수로 분리될 때 명백해진다.
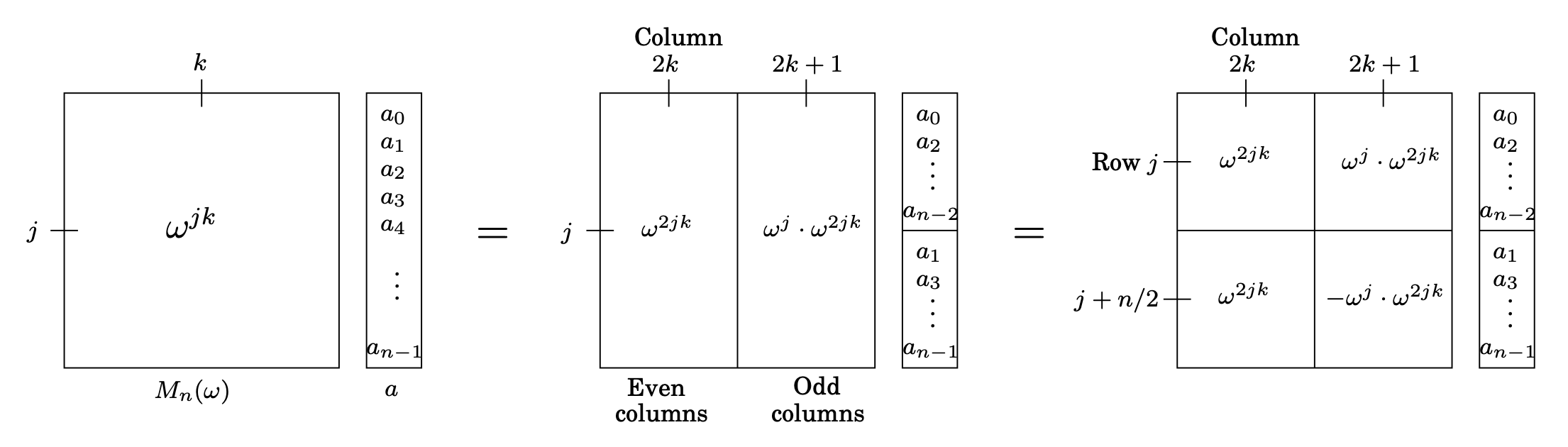
두 번째 step에서, 을 이용해 반으로 나눴을 때 밑의 부분을 단순화 해준다. 이렇게 되면 왼쪽은 아래 위가 같고, 오른쪽은 아래 위가 비슷해진다.
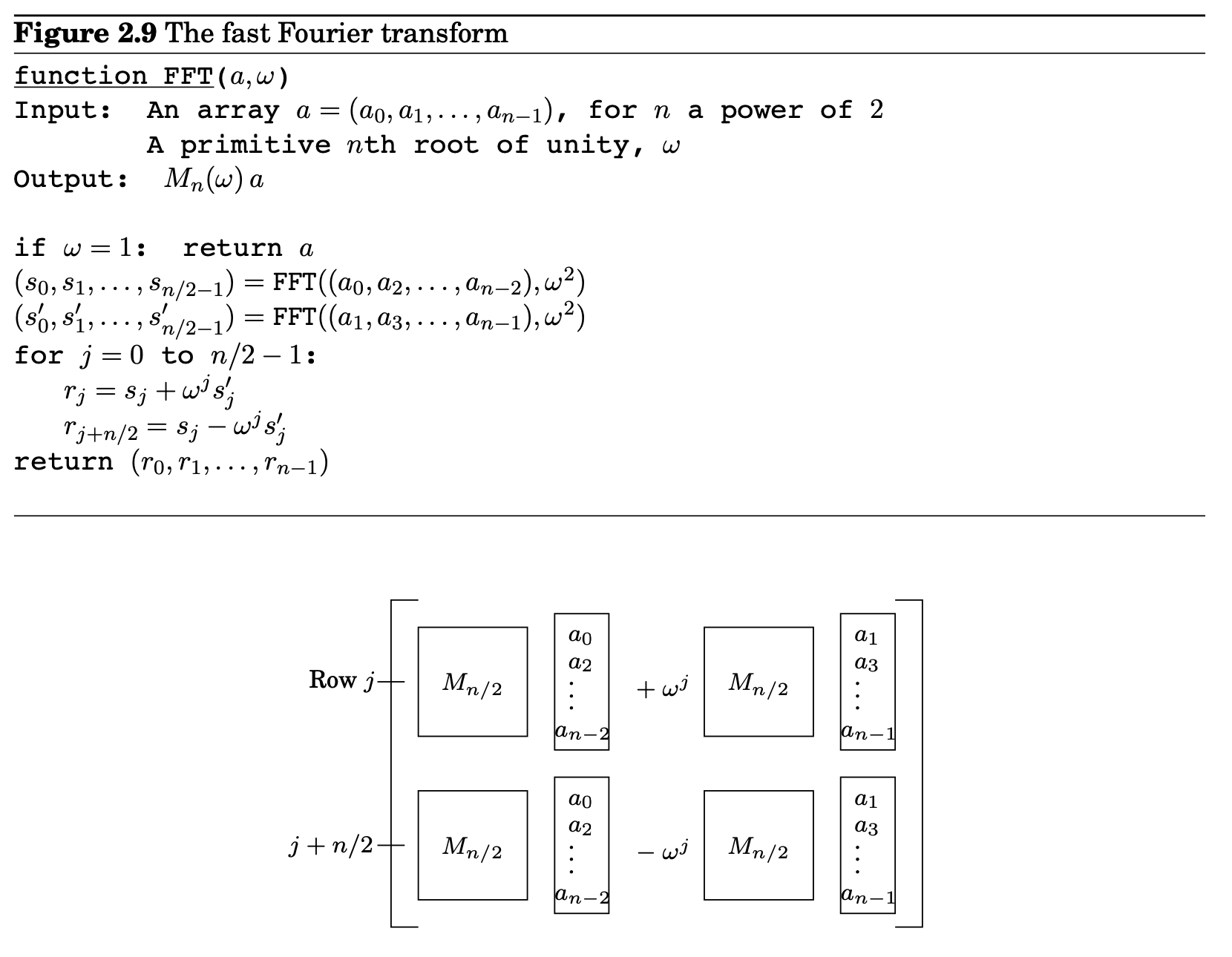
간단히 말해서, 크기가 n인 문제인 와 의 곱은 두 개의 크기가 n/2인 subproblems로 표현될 수 있다: the product of with and with
This divide-and-conquer strategy leads to the definitive FFT algorithm of Figure 2.9, whose running time is
The fast Fourier transform unraveled
구조를 드러내기 위해 재귀를 풀어보자. FFT의 divide-and-conquer step은 매우 간단한 순환으로 그려질 수 있다.
어떻게 크기가 n인 문제가 크기가 n/2인 subproblems로 줄어드는지 보여주겠다.
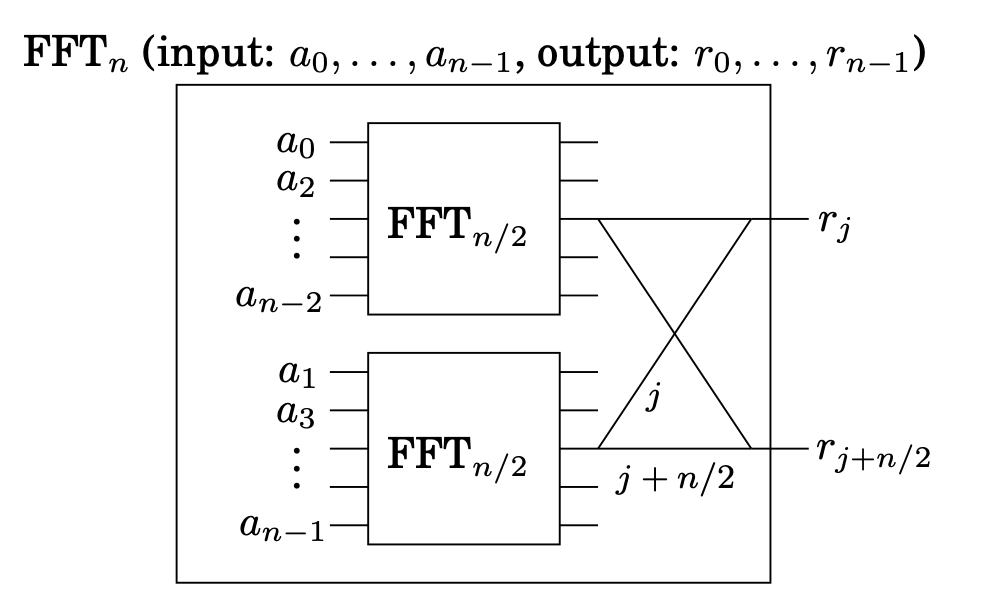
A weight of means “multiply the number on this wire by .” 그래서 두 개의 선이 왼쪽에서부터 교차점으로 들어오면, 그 수들은 더해진다.
뭐 이후에 예시가 나오는데..
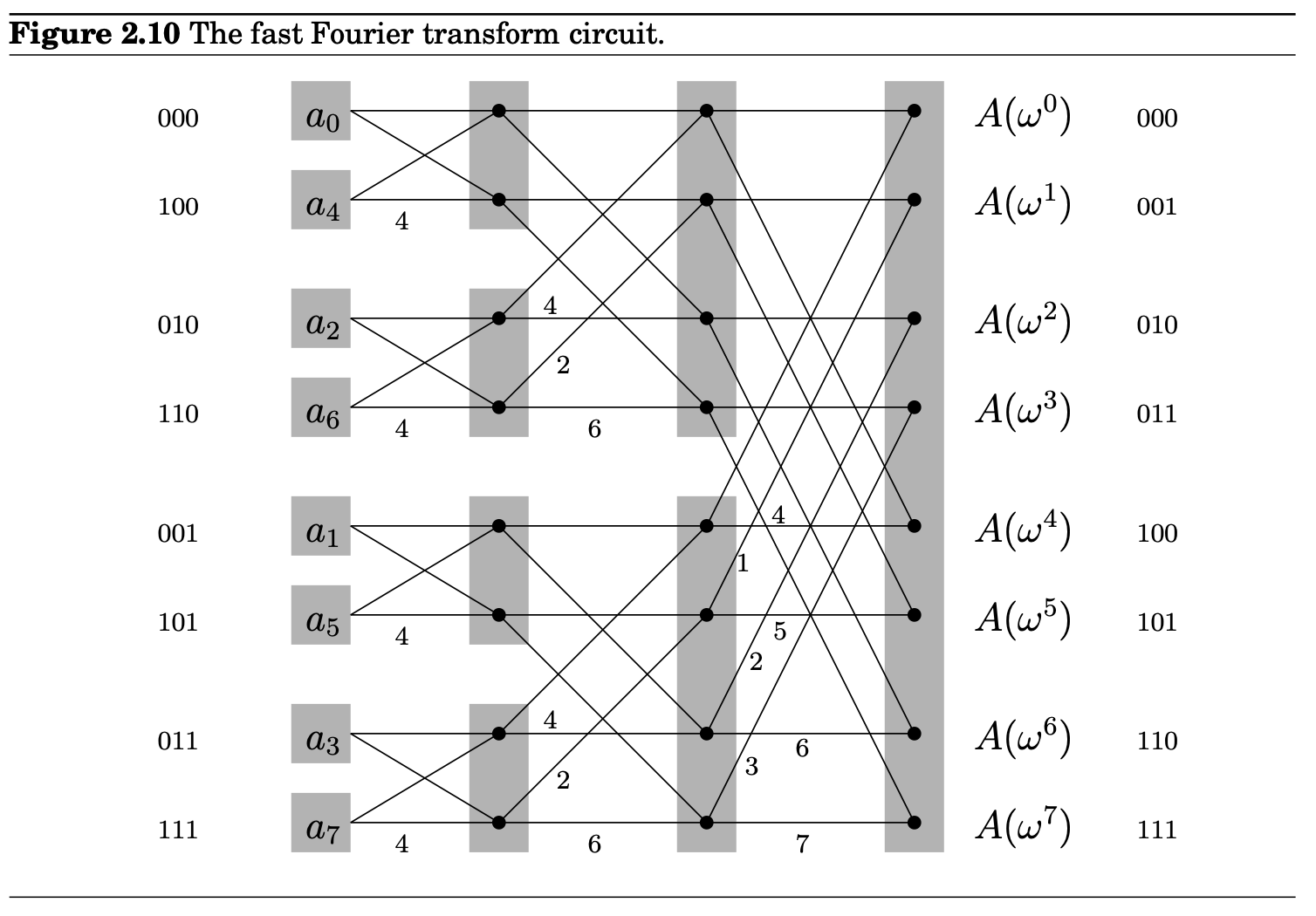
Unraveling the FFT circuit completely for elements, we get Figure 10.4. Notice the
following.
- For n inputs there are levels, each with nodes, for a total of operations
- The inputs are arranged in a peculiar order: 0, 4, 2, 6, 1, 5, 3, 7.
이건 순서를 짤라보면 [0,2,4,6],[1,3,5,7] -> [0,4],[2,6],[1,5],[3,7] 로 짤림 (계속해서 홀수 짝수 나눠주면) - There is a unique path between each input and each output .
- On the path between and , the labels add up to mod 8.
Since , this means that the contribution of input to output is , and therefore the circuit computes correctly the values of polynomial - And finally, notice that the FFT circuit is a natural for parallel computation and direct implementation in hardware.