Abstract
큰 데이터 셋에서 연속적인 단어의 벡터를 표현을 계산하는 2개의 모델 구조를 제안하려함.
이전의 가장 성능이 좋던 모델보다 정확도 증가, 계산 비용이 줄어듦이 있다. (16억개의 높은 quality의 단어 벡터를 하루도 안걸려서 학습 가능)
이 벡터들이 syntactic, semantic 벡터 유사도를 측정하는 test set에 최신 기술 성능을 제공함
1. Introduction
지금까지 NLP 시스템은 단어를 원자로 여김 ( 단어 사이에 유사성 개념이 없었음. 단어를 어휘집에서 index로 여김 )
이것에 대한 장점도 있다.
1. 간결성
2. 견고성
3. 큰 데이터로 학습된 간단한 모델이 적은 데이터를 이용한 복잡한 시스템보다 좋은 결과를 냄
그러나 이 간단한 기술은 한계점이 있음
ex) 자동 음성 인식을 위한 관련 도메인 내 데이터의 양이 제한적
그래서 단순히 basic 기술의 규모확장(단어의 증가)으로는 중요한 발전을 이끌어낼 수 없는 상황들이 있고, 그래서 더 진보된 기술에 초점을 맞춰야 함
최근 머신러닝 기술의 진보로, 더 큰 데이터 셋에 복잡한 모델을 학습하는 것이 가능해졌다. 가장 성공적인 concept은 Distributed Representations of word(단어의 분산적 표현)를 이용하는 것일 것이다. ex) 단어 모델 기반 뉴럴 네트워크가 N-gram model보다 좋은 결과를 냈다.
(N-gram model : 단어의 앞에 (n-1)개의 단어를 참고하여 단어를 유추하는 방법)
1-1. Goal of the Paper
논문 목표는 수십억개의 단어의 큰 데이터셋에서 높은 퀄리티의 단어 벡터를 학습하는 기술을 소개하는 것이다. 전에 모델은 많은 단어와 50-100 단어 벡터 차원을 성공적으로 학습한게 없었다
우리는 유사한 단어가 서로 가까운 경향이 있을 뿐만 아니라 단어가 여러 수준의 유사성을 가질 수 있다는 기대를 가지고 결과 벡터 표현의 품질을 측정하기 위해 최근 제안된 기술을 사용한다 (Linguistic Regularities in Continuous Space Word Representations, 2013 : 여러 수준의 유사성)
이것은 어미 변화 언어의 맥락에서 초기에 관찰되었다 - 예를 들어, 명사는 복수의 단어 끝을 가질 수 있고, 만약 우리가 원래 벡터 공간의 부분 공간에서 유사한 단어를 검색한다면, 유사한 끝을 가진 단어를 찾는 것이 가능하다
단어 표현의 유사성은 단순한 구문(syntactic) 규칙성을 넘어선다는 것이 발견되었다.
단어 표현의 유사성은 단순한 문법 규칙을 넘어서는데, 단어 벡터에 대한 단순한 대수 연산을 수행하는 단어 오프셋 기술을 사용하여 "King" 벡터에서 "Man" 벡터를 뺀 후 "Woman" 벡터를 더한 결과가 "Queen" 벡터 표현에 가장 가까운 벡터임을 보여주었다.
이 논문에서는 단어의 선형적인 규칙성을 보존하는 새로운 모델 발전을 통해 벡터 연산의 정확도를 극대화 시키려 노력할 것이다. 구문 및 의미적 규칙성을 모두 측정하는 포괄적인 새로운 테스트 세트를 디자인하고, 이러한 규칙성 중 많은 것들이 높은 정확도로 학습될 수 있다는 것을 보여준다. 게다가 어떻게 학습 시간과 정확도가 단어 벡터의 차원과 학습 데이터의 양에 어떤 영향을 미치는지 얘기해볼 것이다.
<요약>
단어의 유사성을 가지고 벡터를 표현하고 싶었다.
어미의 변화와 같은 syntatic (구문) 규칙성은 초기에 관찰되었지만, 단어의 유사성은 구문의 규칙성을 넘어 의미에서도 찾을 수 있었다. 예를 들어, 왕 - 남자 + 여자 = 여왕.
즉, 구문적 + 의미적 규칙성을 모두 측정하는 포괄적인 새로운 vector representation을 디자인하고, 이것들이 높은 정확도로 학습될 수 있는 것을 보여준다.
2. Model Architectures
단어 간에 선형적 규칙을 보존하는 것에 LSA보다 더 좋게 나오거 있는 것이 이전에 보여졌기에, 이 논문은 단어의 분산 표현에 초점을 맞출 것이다.
다른 모델 구조와 비교함에 우리는 처음으로 computational 복잡도를 모델을 완전히 학습하기 위해 엑세스해야하는 parameter의 수로 정의한다. 그리고 우리는 computational complexity를 최소화하면서 정확도를 최대화하기 위해 노력할 것이다.
학습 복잡도(training complexity)는
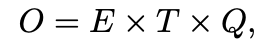
E는 학습 횟수(training epochs), T는 training set에 들어있는 단어의 수, Q는 각 모델 architecture에 의해 자세히 정의됨
일반적으로 E는 3~50, T는 10억까지로 선택함
모든 모델은 확률적 경사 하강법과 오차역전법을 이용해 학습된다
2.1 Feedforward Neural Net Language Model(NNLM)
probabilistic feedforward neural network language model은 'A neural probabilistic language model. Journal of Machine Learning Research' 에서 제안된다. input, projection, hidden, output 층으로 구성되어 있다.
Q = N P + N P H + H V
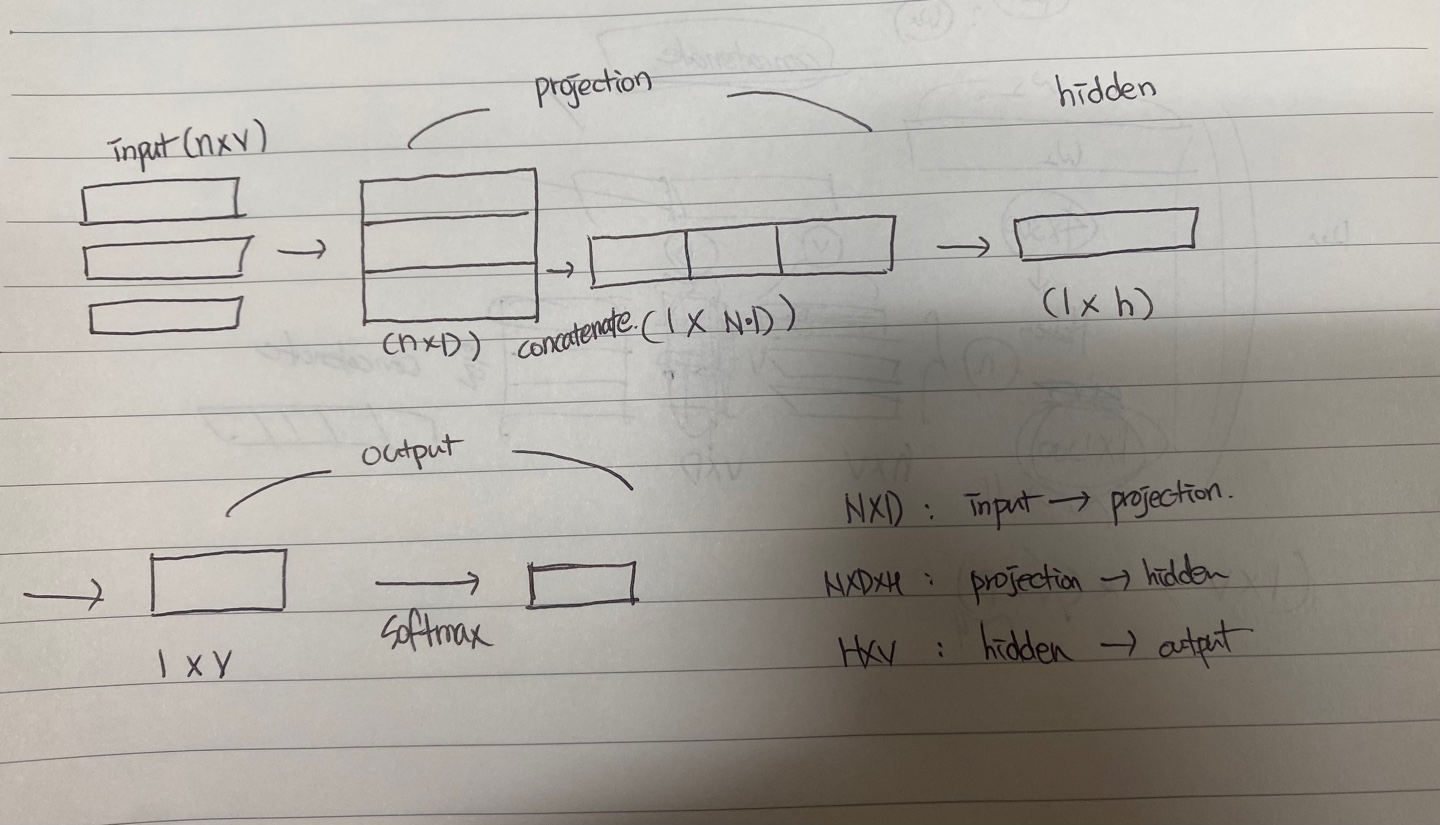
input -> projection 시 이용했던 W의 크기는 (V x D)
projection -> hidden 시 이용했던 W의 크기는 (N*D x H)
hidden -> output 시 이용했던 W의 크기는 (H x V)
여기서 주목할 점은 projection은 linear 하지만, hidden은 non-linear하게 만들어준다. 그림에선 그냥 가중치와 크기에 대해서만 나타내려고 이렇게 적은 것이고 hidden으로 갈 때는 활성화 함수도 계산해 주어야 한다.
Q에서 VxP가 아니라 NxP인 이유는 사실 input은 one-hot vector로 이루어져있기 때문에 가중치 백터의 행을 가져온다고 볼 수 있다. 결국 열의 개수인 D개를 꺼내와야하니까 D만큼 연산을 수행할 것이고, 단어가 N개니까 복잡도는 N x D 라고 볼 수 있다.
여기서 계산을 줄이는 법은 hierarchical softmax을 사용하면 된다.
등장하는 빈도와 관계있게 이진 트리에서 level을 설정해주는 Huffman Tree를 이용.
단어들을 leaf를 두고 계산
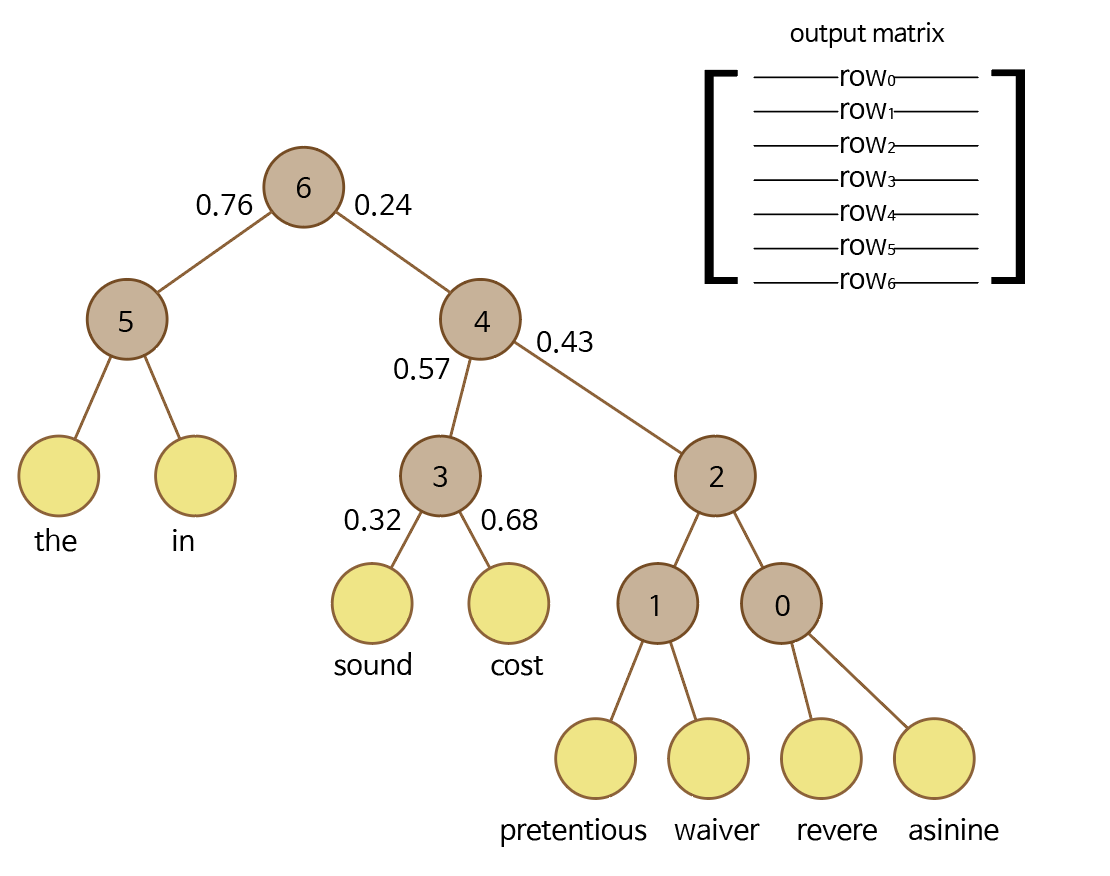
출처 : https://uponthesky.tistory.com/15
"asinine"과 "cost"의 값을 계산하려면
- 우선 오른쪽일지 왼쪽일지 방향을 정한다. (오른쪽이라 하자 여기선)
-
"asinine"과 row6 내적 후 sigmoid 함수 이용
값이 0.24라고 하면 row6에서 오른쪽으로 갈 확률이 0.24, sigmoid 함수의 특징에 따라 왼쪽으로 갈 확률은 1 - 0.24 =0.76 이 된다. -
"asinine"과 row4 내적 후 sigmoid 함수 이용
계산한 값이 0.43이라 하면 row4에서 왼쪽으로 갈 확률은 1 - 0.43 = 0.57 -
"asinine"과 row3 내적 후 sigmoid 함수 이용
계산한 값이 0.68이라면 row3에서 오른쪽으로 갈 확률은 0.68
즉 : "asinine"을 입력했을 때 "cost"를 출력할 확률은 0.76 0.57 0.68
이런 식으로 계산 식을 줄여준다 이진 트리로 만들어주었기 때문에 log2(V) 로 줄어든다
2-2. Recurrent Neural Net Language Model ( RNNLM )
N개 window 지정의 한계를 극복하기 위해 고안되었다
그리고 이론적으로 RNN 모델이 얕은 neural network 보다 복잡한 패턴을 효율적으로 표현할 수 있다
Layer의 구성은 {input layer, output layer, hidden layer} 이 있다. NNLM과 달리 projection layer가 없다
여기서 special type은 time delay connection을 이용해 자기 자신과 hidden layer를 이어주는 recurrent matrix다.
과거로부터의 정보가 이전의 hidden layer state와 현재 input을 기반으로 update되는 hidden state로 표현될 수 있다
Q = H x H + H x V
hidden(t-1) -> hidden(t) 시 계산 복잡도 H x H
hidden -> output 시 계산 복잡도 H x V
( input -> hidden 으로 갈 때는 input이 one-hot vector 이니까 사실 가중치(input에서 hidden으로 갈 때 곱해지는)의 어떤 행을 뽑아오면 되는 것으로 계산 X )
3. New - Log Linear Model
계산 복잡도를 낮추기 위해 2개의 모델을 설명할 제안한다
이 전에서는 계산 복잡도가 non-linear hidden layer에서 증가했다
non-linear hidden layer는 neural network를 매력적으로 보이게 해주는 것이지만, 데이터를 neural network만큼 정확하게 데이터를 표현해줄 수 없을 지 모르지만 효율적으로 학습이 가능한 간단한 모델을 실험해볼 것이다
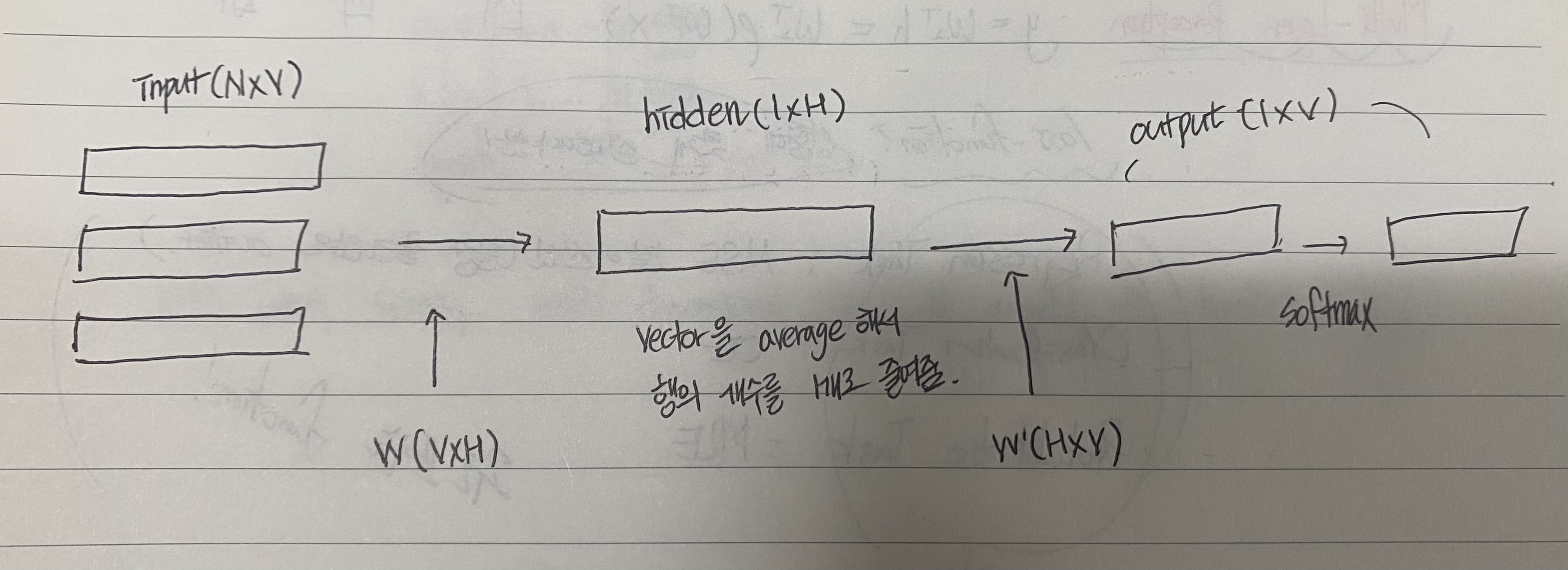
3-1. CBOW Model ( Continuous Bag of Words Model )
context (배경 : 주변의 단어들) 을 이용하여 Target word를 예측하는 model
NNLM과 비슷하다
non - linear hidden layer가 제거되고 projection layer가 모든 단어에 공유된다. 그래서 모든 단어가 같은 위치에 영사된다. ( 벡터 평균화 )
standard bag-of-words model과 달리 배경의 연속적인 분배된 표현을 이용함 (Continuous distributed representation of the context)
=> standard bag-of-words model은 모든 단어를 bag에 담아서 context에 대한 개념이 없지만, CBOW는 window 개수를 정해둠으로써 배경의 분배를 이용함
중요한 것은 Input Layer와 Projection Layer 사이의 가중치 matrix는 NNLM과 같은 방식으로 모든 단어에 공유(shared)된다
Loss Function은 Cross Entropy를 이용해 학습을 한다
계산 복잡도
Q = N x D + D x Log2(V)
여기서 막간 !
Word Embedding 이란 ?
혹시 모를까봐 말하는 것이지만..
one-hot vector 같이 sparse vector을 dense vector로 변환해주는 과정 !
3-2. Skip - Gram Model
center word를 이용하여 context word를 예측하는 Model
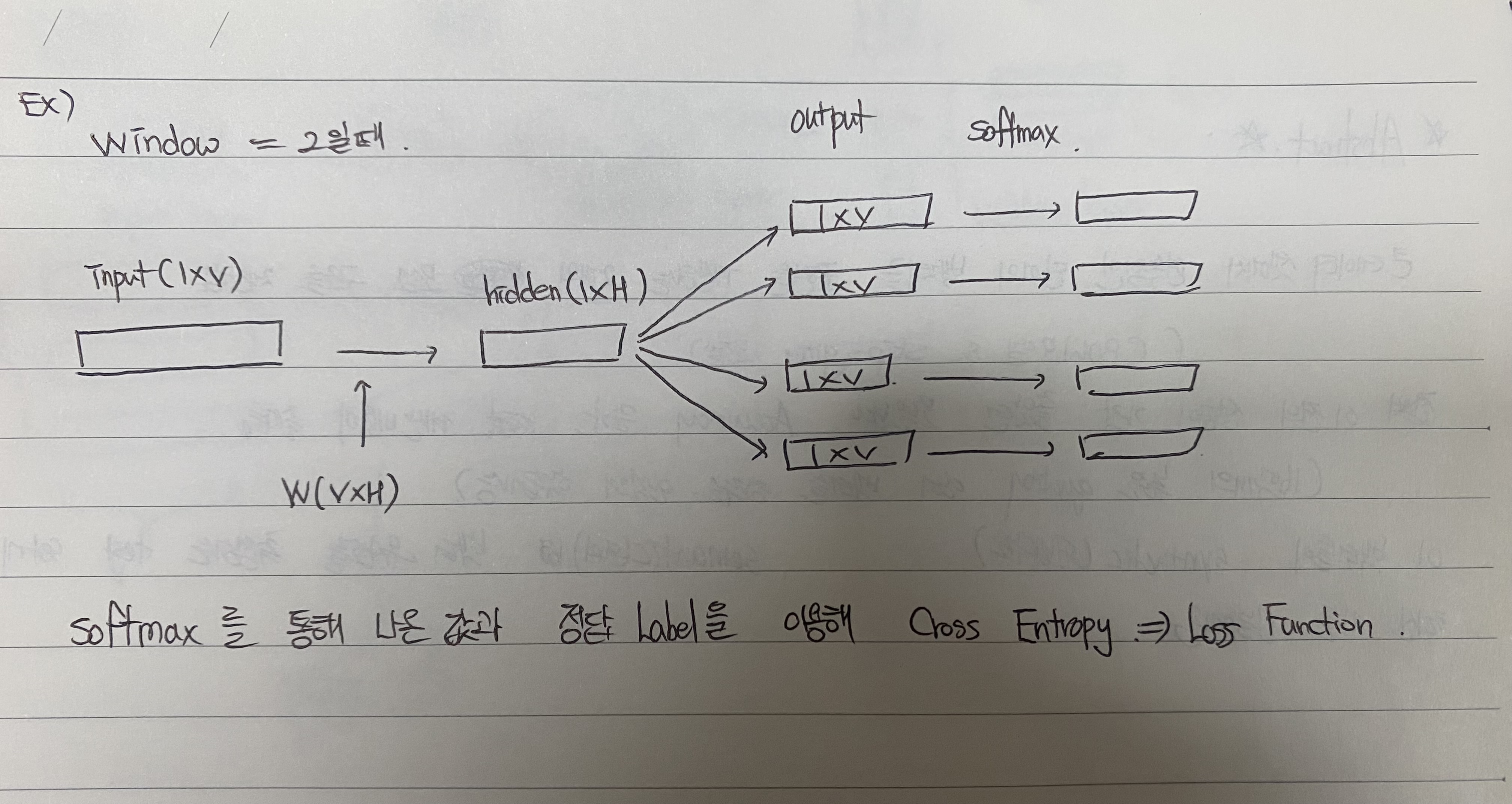
CBow model 보다 좋은 성능을 보인다고 알려졌는데, 이는 output을 학습할 때 window의 크기에 따라 중복적으로 학습하는 경우가 많아서 그렇다.
=> I am a boy you are a girl 을 학습할 때 window가 2이면 am은 I를 center word로 받아올 때도 학습을 하고, a와 boy를 center word로 받아올 때도 학습을 하기 때문에 중복적 학습이 많아져 좋은 성능이 나오는 것으로 보인다
계산 복잡도
Q = C x (D + D x log2(V))
D : input -> hidden
D x Log2(V) : hidden -> output
여기서 C는 maximum distance of the words
Conclusion
구문적(syntactic), 의미적(semantic)을 이용한 모델을 공부했다.
유명한 neural network와 비교되게 간단한 모델 구조를 가지고 높은 quality의 word vector을 학습할 수 있었다.
계산 복잡도가 줄어들면서, 더 큰 데이터셋에서 더 정확한 high - dimensional word vector을 계산할 수 있었다.
공부를 한 내용이므로 정확하지 않을 수 있고, 혹시 수정될 부분이 있다면 말해주세요~
