우선적으로 직역을 바탕으로 논문을 리뷰하는 것을 밝힙니다.
Paper : https://arxiv.org/abs/2101.00190
Abstract
Fine-tuning은 LLM이 downstream task를 수행하는 사실적인 방법!
근데 LLM의 모든 parameters를 바꾸고, 각 task의 전체 복사본을 저장해야 한다.
그래서 “Prefix-finetuning” 제안 : 자연어 생성 task의 fine-tuning에 대한 light weight 대안품
⇒ model parameters를 얼려놓고, prefix라고 불리는 작은 continuous task-specific vector를 최적화 해준다.
Prompt에서 영감을 얻어, 후속 토큰이 “Virtual token(가상 토큰)”인 것처럼 이 prefix에 참여할 수 있도록 함.
- GPT-2 를 이용해서 Table-to-text generation 수행
- BART를 이용해서 Abstractive Summarization 수행
0.1% parameter learning을 통해서 full-data setting에 비교 할만한 성능 얻고, low-data setting에서는 능가. 훈련 중 보이지 않은 주제의 예제에 대해서는 더 나은 추정!
1. Introduction
Fine-tuning은 Large PLM을 이용해 downstream task를 수행하는 일반적인 방법이다. 그러나 LLM의 모든 parameters를 update하고, 저장해야한다. 결과적으로 Large PLM에 의존한 NLP system을 구축하고 배치하려면 각 task에 대한 LM parameters의 수정된 복사본들을 저장해야 함 → 비쌈!
비용적 문제 해결을 위해 “Lightweight fine-tuning” ⇒ 대부분의 pretrained parameters 고정, 작은 훈련 가능한 modules로 모델 증강.
Ex) Adapter-tuning : PLM의 layers 사이에 추가적인 task-specific layers 삽입.
약 2~4% task-specific parameters를 추가했지만서도 Natural Language Understanding, generation benchmarks에서 fine-tuning과 비교할만한 좋은 성능을 냄.
극단적 끝에 GPT-3는 아무 task-specific tuning 없이 배치될 수 있다. Natural language task instruction과 몇몇 예시를 task input 앞에 붙여주며, LM으로부터 결과를 생성한다.
In-context learning or Prompting
Prefix-tuning : prompting에 영감을 받은 NLG tasks의 lightweight alternative
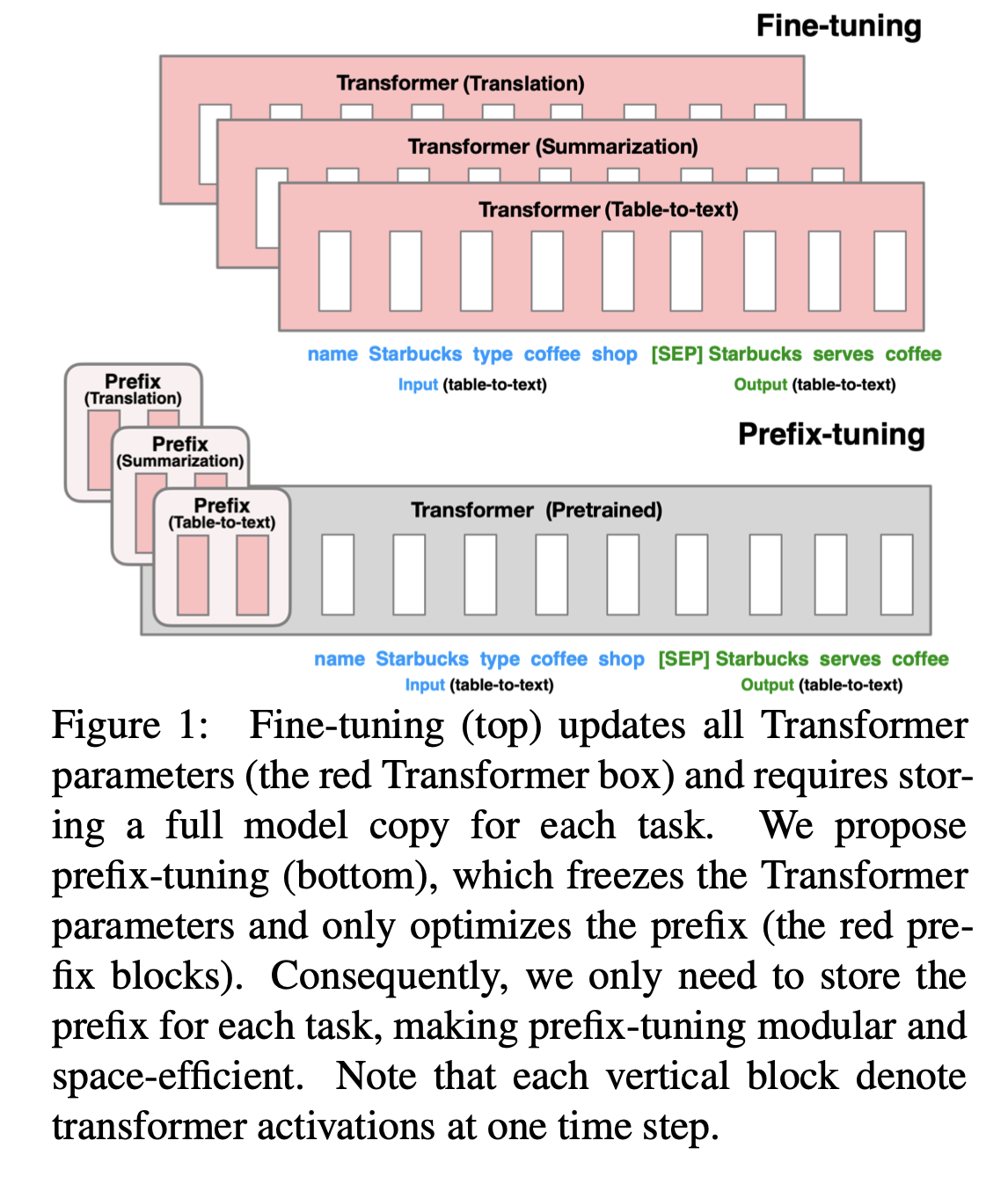
Figure 1에 나와있는 data table의 textual description을 생성하는 task를 봐보자. Task input이 linearized table(e.g. ”name : Starbucks | type : coffee shop”)이고 output은 textual description(e.g. “Starbucks serves coffee.”)이다.
Prefix-tuning은 continuous task-specific vectors(prefix)의 sequence를 input 앞에 붙인다. 후속 토큰의 경우, Transformer는 prefix를 ‘가상 토큰들(virtual tokens)’의 sequence 인 것처럼 처리할 수 있고, prompting과 달리 prefix는 real token에 해당하지 않는 free parameters로 구성되어있다.
Figure 1의 fine-tuning은 transformer의 모든 parameters를 update하고 각 task에대한 모델의 조정된 복사본을 저장하지만, prefix-tuning은 오직 prefix를 최적화한다.
결과적으로 큰 transformer의 한 개의 복사본과 학습된 task-specific prefix만 저장하면 된다.
→ 각 추가작업에 대해 매우 작은 overhead 산출
Prefix는 모듈식(modular)
⇒ 수정되지 않은 채로 남아있는 downstream LM을 조정하는 upstream prefix를 훈련시킴.
그렇기 때문에 하나의 LM은 많은 tasks를 한 번에 support 할 수 있다.
개인화 맥락에서(작업들이 다른 유저들에 대응하는) 각 user의 data에 의해 학습된 분리된 prefix를 가질 수 있고 그래서 cross-contamination(교차 오염)을 피할 수 있다. 게다가 prefix 기반 구조는 하나의 배치에서 다수의 Users/tasks로부터 예시들을 처리할 수 있게 해준다.
⇒ 이는 다른 lightweight fine-tuning 에서는 불가능하다.
Evaluation 측면)
GPT-2 : table - to - text
BART : abstractive summarization
저장 측면)
prefix-tuning은 fine tuning보다 1000배 적게 parameters를 저장한다.
성능 측면)
<Full dataset>
table-to-text : prefix-tuning fine-tuning ( comparable )
summarization : prefix-tuning < fine-tuning ( 차이 small )
<Low-data setting>
평균적으로(2개 tasks) : prefix-tuning > fine-tuning
<extrapolates with unseen topics>
각 tasks 모두 : prefix-tuning > fine-tuning
2. Related Works
Fine-tuning for natural language generation
현재 SOTA(State of the art)
- Table-to-Text : Seq-to-seq & fine-tuned (Kale)
- Natural Language Generation : Pretrained LM & Fine-tuned
- Extractive Summarization : Masked-LM & fine-tuned
- Abstractive Summarization : encoder-decoder model (BART) & fine-tuned
Lightweight fine-tuning
Lightweight fine-tuning : 모델의 대부분의 parameters는 freeze 해놓고, 작은 훈련 가능한 모듈로 pretrained model을 수정한다.
주요 챌린지는 모듈의 고성능 구조를 알아내고, 조정할 수 있는 pretrained parameters의 부분집합들을 알아내는 것이다.
- Parameters를 제거하는 방법
ex) Model parameter에 대해 binary mask를 훈련시키며 몇몇 모델의 가중치들을 제거
- Parameters를 추가하는 방법
ex) 합산(summation)을 통해 pretrained model과 융합되는 “side” 네트워크를 훈련시킨다; Adapter-tuning은 pretrained-LM의 각 layers 사이에 Adapter라고 불리는 task-specific layers를 삽입한다.
Parameter를 추가하는 방법은 LM parameters의 약 3.6%만 조정하지만, 우리가 제안할 것은 이와 비교할만한 성능을 유지하면서 그것보다 30배는 작은 0.1%를 조정한다.
Prompting
Prompting : task input 앞에 instructions과 few examples를 붙이고 LM에서 output을 생성하는 것.
In-context learning : GPT-3의 Framework로, 수동으로 설계된 프롬프트를 사용하여 다른 tasks에 대한 생성을 조정함. 그러나 transformer의 특성상 context length에 제한이 있어서, context-window를 넘어가는 훈련 세트들을 완전히 활용할 수 없다.
Natural Language Understanding tasks에서 BERT나 RoBERTa와 같은 모델에 prompt engineering은 이전부터 연구되었다. AutoPrompt는 discrete trigger words의 sequence를 검색하고, 이들을 각각의 input에 합쳐서 masked LM으로부터 감정이나 사실적 지식을 이끌어낸다.
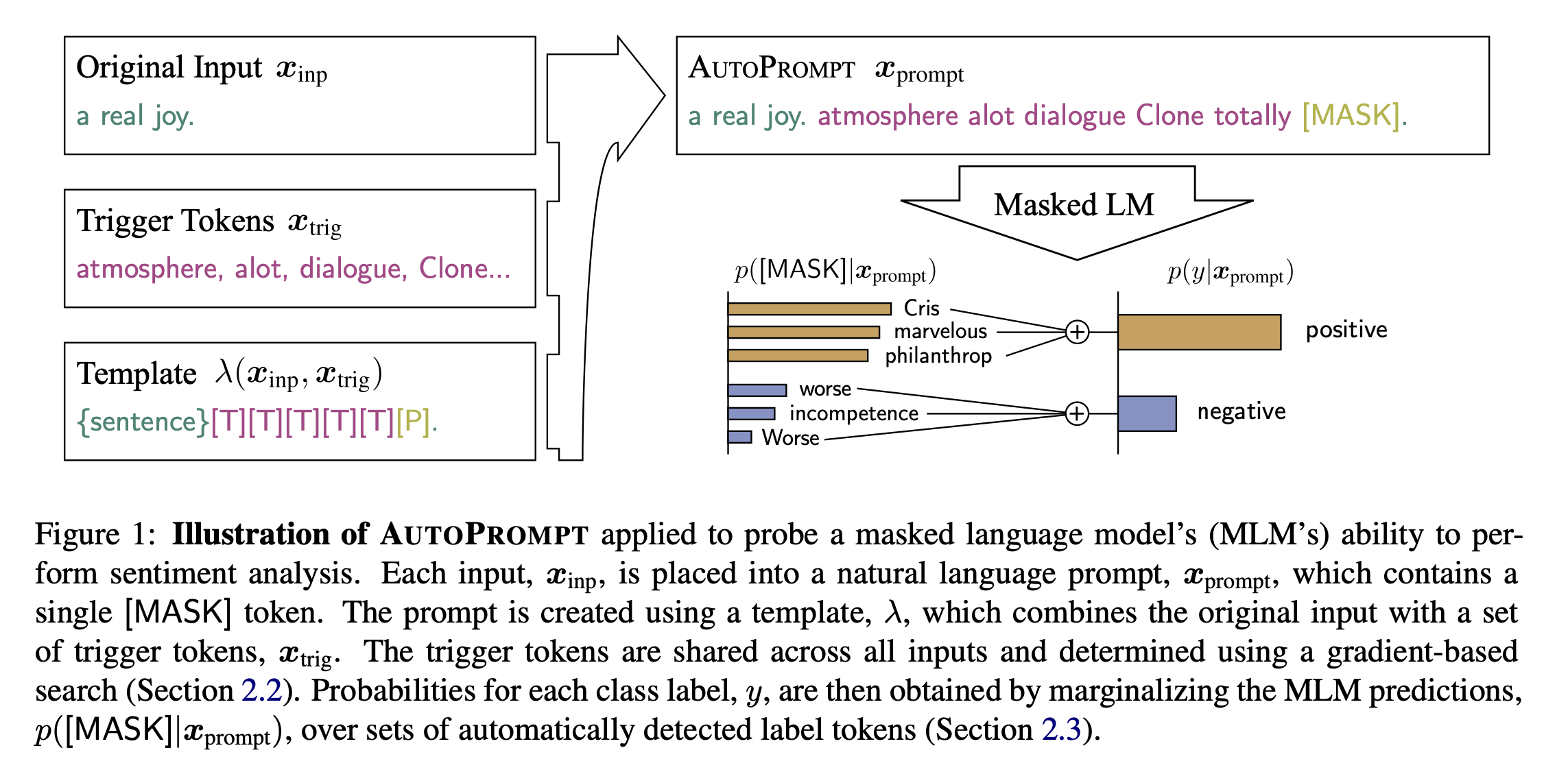
(AutoPrompt의 이해를 돕기 위한 Figure!
출처 : “AUTOPROMPT: Eliciting Knowledge from Language Models with Automatically Generated Prompts” 논문)
이와 대조적으로 우리의 방법은 더 표현적인(more expressive) continuous prefix를 최적화하는 것이며, Language Generation에 초점을 둔다.
Continuous vectors는 LM을 조작하는데 이용되고 있다. 예를들어, pretrained LSTM language model은 각 문장에 대해 continuous vector를 최적화하며 임의의 문장을 재구성할 수 있음을 보였다. 벡터를 input-specific으로 만들면서! 반대로 prefix-tuning은 task의 모든 예시들에 적용될 수 있는 task-specific prefix를 최적화한다. 결과적으로 문장 재구성에만 적용되는 이전 작업과 달리, prefix-tuning은 NLG tasks에도 적용될 수 있다.
Controllable generation
Controllable generation은 문장 수준의 특성에 연결시키기 위해 pretrained-LM을 조작하는 것을 목표로 한다. (ex. 긍정적인 감정 or 스포츠에서 주제 )
이러한 control은 training time에 일어날 수 있다.
→ keywords나 URL과 같은 metadata를 조건화하기 위해 LM을 pretrain 한다.
그리고 decoding time에 일어날 수도 있다.
→ weighted decoding / iteratively updating the past activations
그러나 table-to-text와 요약과 같은 작업에서 요구되는 바와 같이 생성된 콘텐츠에 대해 세분화된 제어를 수행하기 위해 이러한 제어 가능한 생성 기법을 적용할 수 있는 직접적인 방법은 없습니다.
3. Problem Statement
Input이 context 이고 output 는 tokens의 sequence인 조건부 생성 task를 생각해보자. 2개의 tasks를 볼건데, Figure 2의 오른쪽 : table-to-text,에서 는 linearized data table에 해당하고 는 textual description; 요약에서 는 기사이고, 는 짧은 요약이다.
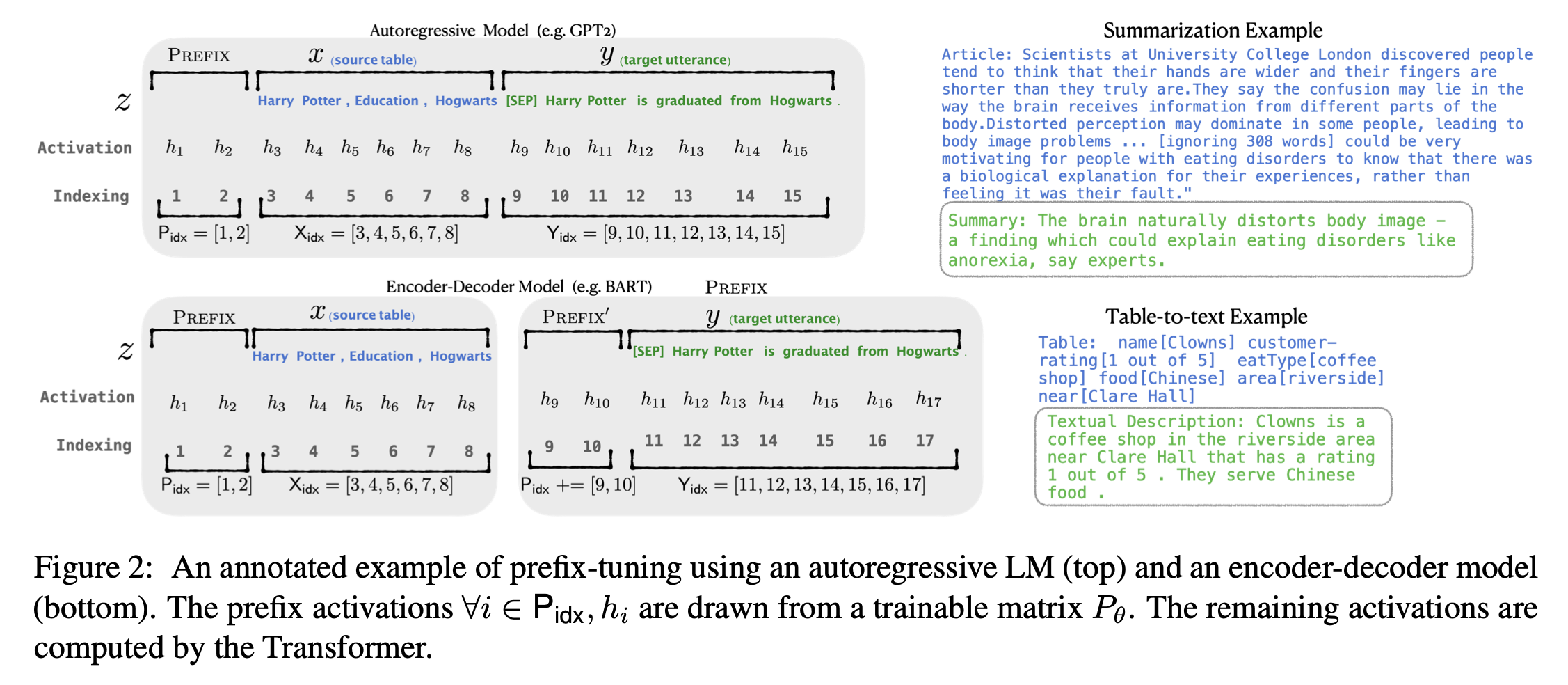
3.1 Autoregressive LM
Trasnformer 구조에 기반을 두고 로 parameterized 되어있는 autoregressive language model 를 가지고 있다고 가정하자. Figure 2의 위쪽부분에서 볼 수 있듯이, 는 와 를 concatenate 것으로 두고, 를 에 대응되는 sequence의 index들, 를 들에 대응되는 sequence의 index들이라고 하자. Time step 에서 activation은 이다. 는 이번 time step에서 모든 activation layers를 합친 것이다. 그리고 는 번째 time step에서 번째 transformer layer의 activation이다.
Autoregressive Transformer model은 와 자신보다 왼쪽의 context에서의 과거 activation의 함수로 다음과 같이 를 계산한다:
Eq (1)
의 마지막 층은 다음 토큰의 분포를 계산하기 위해 사용되었다: 여기서 는 을 vocabulary의 logits에 연결시키는 pretrained matrix다.
3.2 Encoder-Decoder Architecture
를 모델링하는데 encoder-decoder 구조(e.g. BART)도 쓰인다. 는 bidirectional encoder로 인코딩된 것이고, decoder는 자기회귀적으로 를 예측한다(인코딩된 x와 왼쪽 context에 조건부로). Figure 2의 아래쪽에 보인 것과 같이, 같은 indexing과 activation notation을 쓴다. 는 bidirectional transformer encoder에 의해 계산되고, 는 Eq (1)과 같은 식을 이용하여 autoregressive decoder에 의해 계산된다.
3.3 Method: Fine-tuning
Fine-tuning framework에서 pretrained parameters 로 초기화한다. 여기서 는 훈련 가능한 LM 분포이고, 다음과 같은 log-likelihood를 따라 gradient updates를 수행한다:
Eq (2)
4. Prefix-Tuning
조건부 생성 tasks에 대해 fine-tuning의 대체로 Prefix-tuning을 제안한다. 먼저 4.1에서 직관을 제시하고, 4.2 에서 방법을 공식화하여 정의한다.
4.1 Intuition
Prompt 직관에 기반하여, 적당한 context을 가지면 parameter를 바꾸지 않고 LM을 조정할 수 있다고 생각했다. 예를 들어, LM이 Obama를 생성하길 원하면 context로 흔한 collocations인 Barack을 붙일 수 있다. 그러면 LM이 우리가 원하는 단어에 더 높은 확률을 할당한다. 이러한 직관을 하나의 단어나 문장을 생성하는 것을 넘어 LM을 조정하여 NLG tasks를 풀 수 있는 context를 찾길 원한다. 직관적으로 context는 x로부터 무엇을 추출하고 싶은지를 가이드해주며 x를 인코딩하는 것에 영향을 줄 수 있고, 다음 토큰의 분포를 조정하면서 y의 생성에 영향을 줄 수도 있다. 그러나 이런 context가 존재하는지가 확실하지 않다. Natural Language Task instructions (e.g. summarize the following table in one sentence)는 expert annotators가 문제를 해결하는데 도움을 줄 수도 있지만, 대부분의 pretrained LM에서는 실패했다. Discrete instructions에 대한 데이터 기반 최적화는 도움이 될 수 있지만, discrete 최적화는 계산이 어렵습니다.
Discrete tokens에 대해 최적화하는 대신, 모든 transformer activation layers의 위 방향, subsequent tokens의 오른쪽 방향으로 영향이 전파되는 continuous word embeddings로 instruction을 최적화 할 수 있다. 이는 실제 단어의 embedding의 매칭이 필요한 discrete prompt보다 더 표현적이다. 반면, 이는 activations의 모든 계층에 개입을 시키는 것보단 덜 표현적이다. 모든 계층에 개입을 시키는 것은 long-range dependencies를 피하고, 조정 가능한 parameters를 더 많이 포함한다. 그래서 prefix-tuning은 prefix의 모든 layers를 최적화한다.
4.2 Method
Prefix-tuning은 autoregressive LM에 대해서는 를 얻기 위해 prefix를 앞에 붙이거나 를 얻기 위해 encoder와 decoder(encoder라고 쓰여있는데 오타인지 모르겠군,,,?)에 prefixes를 앞에 붙인다. Figure 2에서 볼 수 있듯이. 여기서 는 prefix indices의 sequence이고, prefix의 길이를 나타내기 위해 를 쓴다.
Prefix가 free parameters라는 것을 제외하고, 우리는 Eq (1)의 재귀식을 따른다. Prefix-tuning은 prefix parameters를 저장하기 위해 크기가 인 훈련 가능한 matrix (parameterized by )를 초기화한다.
Eq (3)
훈련 목표는 Eq (2)와 같지만, 훈련시키는 parameteres의 집합이 바꼈다: LM parameters 는 고정되어 있고, 오직 prefix parameter 만 훈련시킬 수 있는 parameters다.
여기서 모든 i에 대해서 는 훈련 가능한 의 함수이다. 일 때는, 가 로부터 직접 복사하기 때문에 당연하다. 일 때는, 는 여전히 에 의존한다. 왜냐하면 prefix activations는 항상 왼쪽 context에 있고, 그렇기에 그것의 오른쪽에 있는 모든 activations에 영향을 끼치기 때문이다.
4.3 Parametrization of $P_θ$
경험적으로 를 직접적으로 업데이트 해주는 것은 불안전한 최적화와 성능에서 약간의 하락을 초래한다. 그래서 matrix를 다시 parameterized 한다.
큰 feedforward neural network()로 구성된 더 작은 matrix 로 matrix를 reparametrized 한다.
와 는 같은 row dimensions(i.e., prefix length)를 가지고 있고, 다른 column dimensions를 가지고 있다. 훈련이 끝나면 이러한 reparametrization parameters는 삭제될 수 있고, 오직 prefix()만 저장하면 된다.
이후는 생략합니다 하하하하
느낀점 및 요약?
결국 prefix vectors를 훈련시키며, 좋은 결과를 이끌어낸다.
LM의 parameters를 학습시키지 않고, 결국 prefix vectors를 업데이트하며 학습한다. 그리고 의 parameters를 직접 업데이트하면 안정성이 감소해서 성능이 떨어진다. 그렇기에 로 reparametrized 해서 를 업데이트한다.
결국 학습시키는 matrix가 이다! 학습시켜야하는 parameters가 현저히 적어지는 것을 알 수 있다!
결국 prefix(적은 비용으로 task-specific vectors)를 추가하며, task에 대해 comparable score를 낸다!
