Position encoding은 최근에 transformer 구조에서 효율적인 것을 보였다. 이는 sequence에서 다른 위치의 elements 간의 dependency modeling을 위한 valuable supervision을 가능하게 한다. 이 논문에서, 먼저 transformer 기반 language model의 훈련 절차에 위치 정보를 통합하는 다양한 방법을 조사한다. 그 다음, 위치 정보를 효과적으로 활용하기 위해 RoPE(Rotary Position Embedding)라는 새로운 방법을 제안합니다. 구체적으로 RoPE는 rotation matrix를 이용해 absolute position을 인코딩하고, 그 동안에 self-attention 공식에서 명시적인 relative position dependency를 통합한다. 특히, RoPE는 sequence 길이의 유연성, 상대적 거리 증가에 따라 감소하는 inter-token 의존성, linear self-attention에 relative position encoding을 장착할 수 있는 능력을 포함한 유용한 특성들을 가능하게 한다. 마지막으로 다양한 긴 텍스트 분류 벤치마크 데이터 세트에 대해 RoFormer라고 불리는 rotary position embedding을 가진 향상된 transformer를 평가한다. 우리의 실험들은 RoFormer가 지속적으로 RoFormer의 대안들을 극복하는 것을 보여준다. 게다가 몇몇 실험 결과를 설명하는 이론적 분석도 제공한다.
Pre-trained Language Models · Position Information Encoding · Pre-training · Natural Language Processing
1. Introduction
단어의 순서는 Natural Language Understanding에서 매우 중요하다. RNN 기반 모델들은 시간 차원을 따라 hidden state를 재귀적으로 계산하며 token의 순서를 인코딩한다. CNN(”Convolutional Sequence to Sequence Learning 2017”)기반 모델들은 일반적으로 위치에 상관 없는 것으로 여겨졌지만, 최근 연구(”How much position information do convolutional neural networks encode? 2020”)는 흔히 사용되는 padding 계산이 암묵적으로 위치 정보를 학습할 수 있다는 것을 보였다. 최근에 Transformer 기반(”Attention is all you need 2017”)으로 구축된 Pre-trained Language models은 context representation learning(Devlin et al. [2019]), machine translation(Vaswani et al. [2017]), language modeling(Radford et al. [2019])를 포함한 다양한 NLP tasks에서 최고의 성능을 달성했다. RNNs, CNN 기반 모델과는 달리, PLM은 self-attention 메커니즘을 활용하여 주어진 corpus의 문맥적 표현을 의미론적으로 포착했다. 결과로써, PLM들은 병렬화 측면에서 RNN보다 상당한 향상을 이뤘고, CNN들과 비교했을 때 더 긴 intra-token 관계를 모델링하는 능력이 향상했다.
주목할 만한 점은 현재 PLM들의 Self-attention 구조는 위치에 구애받지 않는 것으로 Yun et al. [2020]에 나타났다는 것이다. 이 주장에 따라, 훈련 절차에 위치 정보를 인코딩하는 다양한 방법들이 제안되었다. 한쪽에서는 pre-defined 함수를 통해 생성된 absolute position encdoing이 contextual 표현에 추가되었습니다 (훈련가능한 position encoding 도 추가되었다). 다른 한 편, 몇몇 이전 작업들(논문 참고)은 일반적으로 attention 메커니즘에 상대적인 위치 정보를 인코딩하는 relative position encoding에 초점을 맞췄다. 이러한 접근에 더하여, Liu et al. [2020]의 저자들은 Neural ODE Chen et al. [2018a]의 관점에서 위치 encoding의 dependency를 모델링할 것을 제안했고, Wang et al. [2020]의 저자들은 complex space에서 위치 정보를 모델링할 것을 제안했다. 이러한 접근들의 효과에도 불구하고, 이러한 접근들은 위치 정보를 context representation에 추가하므로 linear self-attention 구조에 적합하지 않다.
이 논문에서, PLM들의 학습 절차에 위치 정보를 활용하기 위해 “Rotary Position Embedding(RoPE)”라 불리는 새로운 방법을 소개한다. 구체적으로, RoPE는 rotation matrix를 이용해 absolute position을 인코딩하고, 그 동안에 self-attention 공식에서 명시적인 relative position dependency를 통합한다.
특히, RoPE는 sequence 길이의 유연성, 상대적 거리 증가에 따라 감소하는 inter-token 의존성, linear self-attention에 relative position encoding을 장착할 수 있는 능력을 포함한 유용한 특성들을 통해 기존의 방법들에 우선한다. 다양한 긴 텍스트 분류 벤치마크 데이터셋의 실험 결과들은 RoFormer로 불리는 rotary position embedding으로 향상된 transformer가 baseline alternatives와 비교해 더 나은 성능을 줄 수 있다는 것을 보였고, 그래서 제안된 RoPE의 효과를 증명한다.
간략히 말하면, 우리의 기여는 다음과 같이 3개다:
Relative position encoding에 대한 기존의 approaches를 조사했고, 그 결과 그들은 대부분 position encoding을 context representation에 추가하는 분해 개념을 기반으로 구축되었다는 것을 알게 되었다. PLM들의 학습 절차에 위치 정보를 활용하기 위해 ”Rotary Position Embedding(RoPE)”라 불리는 새로운 방법을 소개한다. 핵심 아이디어는 명확한 이론적 해석을 가진 rotation matrix에 context representation을 곱하여 relative position을 인코딩하는 것이다.
RoPE의 특성을 공부하고, natural language encoding에 요구되는 “상대적 거리가 증가하면 RoPE이 감소하는 것”을 보인다. 이전의 relative position encoding 기반의 접근들이 linear self-attention과 양립할 수 없음(호환되지 않음)을 친절하게 주장한다.
다양한 긴 텍스트 벤치마크 데이서세에 대해 RoFormer를 평가한다. 우리읭 실험들은 RoFormer가 대안들과 비교해서 더 나은 성능을 지속적으로 달성하는 것을 보인다. Pre-trained language models을 이용한 몇 가지 연구들은 Github에서 이용할 수 있다 : https://github.com/ZhuiyiTechnology/roformer
논문의 남은 부분은 다음과 같이 구성되어있다. Self-attention 구조에서 position encoding 문제의 공식적 설명을 확립하고 Section (2)에서 이전의 작업을 재방문한다. 그 다음 rotary position encoding (RoPE)를 설명하고, 특징을 Section (3)에서 공부한다. Section(4)에서 실험들을 보고한다. 마지막으로 Section (5)에서 이 논문의 결론을 짓는다.
2. Background and Related Work
2.1 Preliminary
SN={wi}i=1N이 wi N개의 input tokens sequence라고 하자. SN에 해당하는 word embedding은 EN={xi}i=1N이라고 쓴다. 여기서 xi∈Rd는 위치 정보가 없는 token wi의 d차원의 word embedding vector다. Self-attention은 먼저 위치 정보를 word embedding에 통합하고, 통합시킨 것들을 queries, keys, value representations로 변환시킨다.
Eq (1)
qm=fq(xm,m)kn=fk(xn,n)vn=fv(xn,n)
qm,kn,vn은 가각 fq,fk,fv를 통해 mth,nth 위치를 통합한다. Query, key 값은 attention weight를 계산하기 위해 이용되고, output은 value representation의 가중합으로 계산된다.
Transformer 기반 position encoding의 기존의 approaches는 Eq (1)을 형성하기 위해 적합한 함수를 고르는 것에 초점이 맞춰져 있다.
2.2 Absolute position embedding
Eq (1)의 일반적인 선택은
Eq(3)
ft:t∈{q,k,v}(xi,i):=Wt:t∈{q,k,v}(xi+pi)
여기서 pi∈Rd는 token xi의 위치에 따른 d 차원의 벡터이다. 이전 연구인 Devlin et al. [2019], Lan et al. [2020], Clark et al. [2020], Radford et al. [2019], Radford and Narasimhan [2018]는 훈련 가능한 vector pi∈{pt}t=1L 집합의 사용을 소개했다. 여기서 L은 sequence 길이의 최대값이다. Vaswani et al. [2017]의 저자는 sinusoidal function을 이용하여 pi를 생성하는 것을 제안했다.
Embedding dimension = 4 라고 가정하고,
“I love singing and dancing”라는 문장에서 singing의 sinusoidal function을 이용해 Positional encoding을 하면?
⇒ singing은 문장에서 2번째 단어이다. 그렇기에 위의 식에서 k=2 (index 기준! 0부터 시작하는!) PE(2,0)=sin(100000/42)PE(2,1)=cos(100000/42)PE(2,2)=sin(100002/42)PE(2,3)=cos(100002/42)
그렇기에 PE(3,0),PE(3,1),PE(3,2),PE(3,3)을 concat하면 된다(dimension이 4이니까).
여기서 괄호 안의 첫 번째 숫자 2은 주어진 문장에서 ‘singing’의 위치이고 (2번째 index), 뒤의 0~3 숫자는 embedding dimension에 따른 숫자들이다! 홀수에서는 cosine을 짝수에서는 sine을 이용하여 encoding 한다!(여기서 중요한 점은 홀수이면, 10000의 제곱수에 들어가는 숫자가 자신보다 1작은 수를 넣어준다. → PE(3,1)에는 10000의 제곱수에 1/4가 아닌 0/4가 들어가는 것처럼!! )
다음 단원에서 RoPE가 sinusoidal function 관점에서 이러한 직관과 관계있다는 것을 보여줄 것이다. 그러나 context representation에 position을 직접적으로 추가하는 대신, RoPE는 sinusoidal function을 곱해서 상대적인 위치 정보를 통합해주는 것을 제안한다.
2.3 Relative position embedding
Shaw et al. [2018]의 저자는 Equation (1)에 다음과 같이 다른 세팅을 적용했다:
여기서 p~rk,p~rv∈Rd는 훈련가능한 상대적 position embedding이다. r=clip(m−n,rmin,rmax)는 m과 n위치 사이의 상대적 거리를 나타낸다. 특정 거리를 넘으면 정확한 상대적인 위치 정보는 유용하지 않다는 가설을 가지고 상대적인 거리를 제한했다. Eq (3)을 유지하면서, Dai et al. [2019]의 저자들은 다음과 같은 Eq (2)의 qmTkn 분해를 제안했다:
핵심 아이디어는 3번째, 4번째 부분에 있는 absolute position pm을 query 위치에 관계없이 훈련 가능한 2개의 vectors u,v로 대체해주면서 absolute position embedding pn을 sinusoid-encoded relative counterpart p~m−n으로 대체하는 것이다. 또한 content 기반과 location 기반 key 벡터들인 xn과 pn에 따라 Wk,W~k로 쓰면서 Wk를 구분해준다. 결과적으로:
key의 position embedding은 absolute position encoding에서 query와의 key 간의 상대적인 sinusoid encoding으로 바꿨다. 하지만, query의 absolute position encoding은 상대적(relative : m−n 형태)으로 바꾸지 않음.
그리고 Weight matrix 역시, 이게 x라는 content에 쓰일 때는 그대로 W로 두고,
이게 position encoding이랑 같이 쓰일 때는 W로 바꿔준다.
즉, content의 input key에 쓰이는 가중치와 position key에 쓰이는 가중치랑 다르게 둔다는 것이다.
fv(xj):=Wvxj로 두며, Value 부분의 위치 정보를 지우는 것은 주목할 만하다. 나중에 작업들(어떤 작업들인지는 논문을 확인~)은 attention weights에만 상대적인 위치 정보를 인코딩하며 이러한 설정을 따른다. 하지만 Raffel et al. [2020]의 저자들은 Equation (6)을 다음과 같이 바꿨다:
Eq (8)
qmTkn=xmTWqTWkxn+bi,j
여기서 bi,j는 훈련 가능한 편향(bias)이다.
(→ 그냥 각각의 위치 정보를 넣어주지 않고, 마지막에 bi,j로 위치 관계를 학습할 수 있게 한듯)
ke et al. [2020]의 저자들은 Equation (6)의 중간 두 부분을 조사했고, absolute positions와 단어 사이에 상관관계가 거의 없는 것을 발견했다.. Raffel et al. [2020]의 저자들은 다른 projection matrices를 이용해서 한 쌍의 단어나 위치를 모델링하는 것을 제안했다.
Eq (9) 같은 경우 position으로 구해지는 값(Wqpm or Wkpn)과 input으로 구해지는 값 (Wqxm or Wkxn)이 상관관계가 거의 없어서, 이들이 곱해지는 부분을 없앴다.
즉, (Wqpm과 Wkxn의 계산) 과 (Wkpn과 Wqxm 의 계산) 부분을 없앰!
그리고 Uq,Uk 라는 position information을 만들어주는 새로운 가중 matrix를 새로 만들어 줌!
Eq (9)
qmTkn=xmTWqTWkxn+pmTUqTUkpn+bi,j
He et al. [2020]의 저자들은 두 tokens의 상대적 위치는 오직 Eq (6)의 중간 두 부분을 이용해서만 완전히 모델링 될 수 있다고 주장했다. 결과로 absolute positon embeddings pm과 pn이 간단하게 relative position embeddings p~m−n로 대체되었다.
Eq (10) 에서는 position encoding끼리의 계산은 지워주고, position encoding을 다 상대적(relative)으로 바꿔줌.
즉, pm,pn을 p~m−n으로 바꿔줌!
Relative position embeddings의 4가지 변형을 비교한 Radford and Narasimhan [2018]은 Eq (10) 과 유사한 변형이 나머지 3개에 비해 가장 효율적이라는 것을 보였다. 일반적으로 이 모든 접근법은 Vaswani et al. [2017]에서 제안된 Eq (2)의 self-attention 설정 하에서 Eq (3)의 분해를 기반으로 Eq (6)을 수정하려고 시도한다. 그들은 흔히 위치 정보를 직접적으로 context representations에 추가하는 것을 도입했다. 그와 달리 우리의 approach는 일부 제약 하에서 relative position encoding을 Eq (1)로부터 얻는 것을 목표로 한다. 다음, 우리는 도출된 approach가 상대적 위치 정보를 rotation of context representations와 통합하면서 더 해석가능하다는 것을 보여준다.
3. Proposed approach
이 Section에서는 rotary position embedding에 대해서 설명한다.
먼저 Section (3.1)에서 relative position encoding problem을 공식화하고,
Section (3.2)에서 RoPE를 도출하고,
Section (3.3)에서 RoPE의 특성을 조사한다.
3.1 Formulation
Transformer 기반 language modeling은 일반적으로 self-attention 메커니즘을 통해 각 토큰의 위치정보를 활용한다. Eq (2)에서 알 수 있듯이, qmTkn이 일반적으로 다른 위치의 토큰들 간의 지식을 전달을 가능하게 한다. 상대적인 위치 정보를 통합하기 위해서는 query qm과 key kn의 inner product가 함수 g에 의해 공식화가 되는 것이 필요하다. 함수 g는 input 값들로 word embeddings xm,xn과 그들의 상대적 위치 m−n만 이용한다. 즉, inner product가 오직 relative form으로만 위치 정보를 encoding 하길 바란다 :
Eq (11)
⟨fq(xm,m),fk(xn,n)⟩=g(xm,xn,m−n)
궁극적인 목표는 앞선 관계에 부합하도록 fq(xm,m)과 fk(xn,n)를 해결하는 동등한 인코딩 메커니즘을 찾는 것이다.
3.2 Rotary position embedding
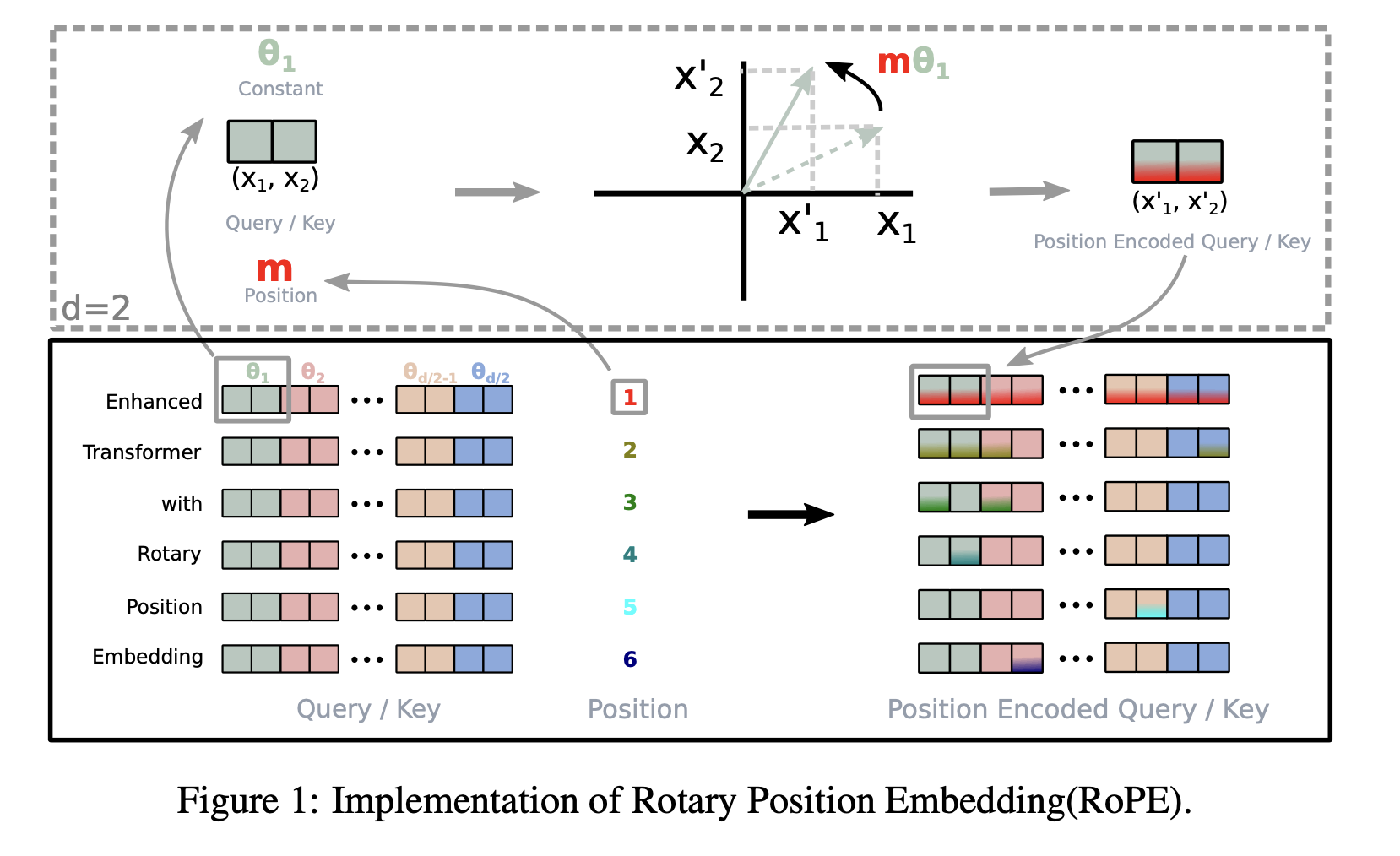
3.2.1 A 2D case
2차원인 간단한 경우부터 시작하자. 이러한 설정 하에서 우리는 2D 평면에 있는 벡터의 기하학적 특성과 복소수 형태를 이용하여 Eq (11)에 대한 답이 다음과 같다는 것을 증명한다 (더 자세한 부분은 (3.4.1) 참조):
여기서 (xm(1),xm(2))는 2차원 좌표로 표현된 xm이다. 비슷하게 g는 matrix로 볼 수 있고, 그래서 2차원 하에서 Section (3.1)의 공식에 대한 답이 될 수 있다. 특히, relative position embedding을 통합하는 것은 간단하다: 단순히 affine-transformed word embedding을 해당 위치 인덱스의 각도의 배수만큼 회전시켜서 Rotary Position Embedding의 직관을 해석합니다.
Something for Understanding
eimθ 가 왜 (cosmθsinmθ−sinmθcosmθ) 인 matrix로 표현될까? eimθ는 각도 변환(회전) 부분이다! 특정 벡터를 mθ 만큼 회전시키는 역할을 함!
아래를 보면서 이해하길 바람! 2차원의 예시!
3.2.2 General form
2차원의 결과를 짝수 차원으로 일반화시키기 위해 d차원을 d/2 하위 차원으로 나누고, inner product의 선형성의 이점으로 하위 차원들을 결합하여 f{q,k}를 다음과 같이 바꾼다:
여기서 RΘ,n−md=(RΘ,md)TRΘ,nd이다 (이건 간단한 예시를 이용해서 그냥 계산해보면 됨). RΘd는 위치 정보를 인코딩해주는 과정동안 안정성을 보장해주는 orthogonal matrix다. 게다가 RΘd의 희소성 때문에 Eq (16)에 matrix 곱을 바로 적용하는 것은 계산적으로 효율적이지 않다; 우리는 이론적 설명에서 또다른 깨달음을 제공한다.
이전 작업 즉 Equation(3) - (10)에 채택된 position embedding 방법의 덧셈적 특성과는 반대로 우리의 접근은 곱셈적이다. 뿐만 아니라, RoPE는 self-attention과 함께 사용될 때 additive position encoding의 확장된 공식에서 항을 변경(위치 정보를 concat해서 넣어주는 : additive position encoding, 항을 변경 : 위치마다 position encoding 변경)하는 대신 rotation matrix 곱셈을 통해 상대적 위치 정보를 자연스럽게 통합한다.
3.3 Properties of RoPE
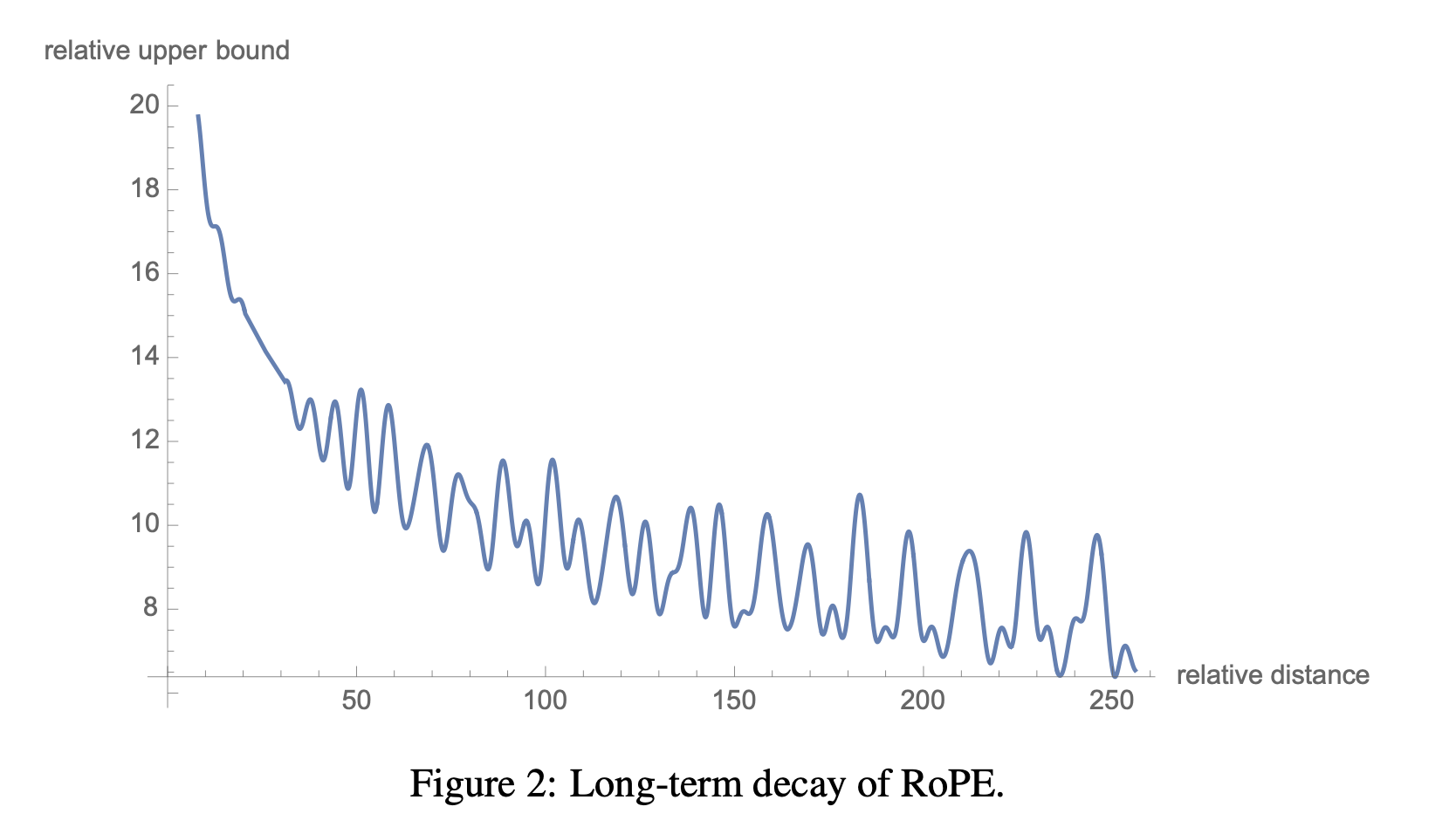
Long-term decay : Vaswani et al. [2017]에 따라 우리도 θi=10000−2i/d로 설정했다. 이러한 세팅이 long-term decay property를 제공하는 것을 설명할 수 있다(section (3.4.3)에 언급됨). 이는 inner product가 상대적 위치가 증가하면 약해진다는 뜻이다. 이러한 특성은 긴 상대적 거리를 가진 한 쌍의 토큰들이 적은 커넥션을 가져야 한다는 직관과 일치한다.
RoPE with linear attention: Self-attention은 더 일반적인 형태로 다시 쓰일 수 있다.
원래의 self-attention은 sim(qm,kn)=exp(qmTkn)/d 를 선택하는데, 이러면 모든 쌍의 inner product를 계산해야 하기 때문에 quadratic complexity O(n2)를 가진다. Katharopoulos et al. [2020]에 따라 linear attentiond은 Eq (17)을 다음과 같이 바꾼다:
여기서 ϕ(⋅),φ(⋅)은 대개 non-negative 함수이다. Katharopoulos et al. [2020]의 저자들은 ϕ(x)=φ(x)=elu(x)+1을 제안했고, 먼저 key와 value 사이의 곱셈을 행렬 곱셈의 결합 법칙을 이용해서 계산했다.
ELU 함수?
ELU(x)={xif x≥0α(ex−1)if x<0
대체로 α=1을 이용한다고 한다. PyTorch 에서도 기본값이 1이다. 하지만 α는 hyperparameter 이기 때문에 변경할 수 있다!
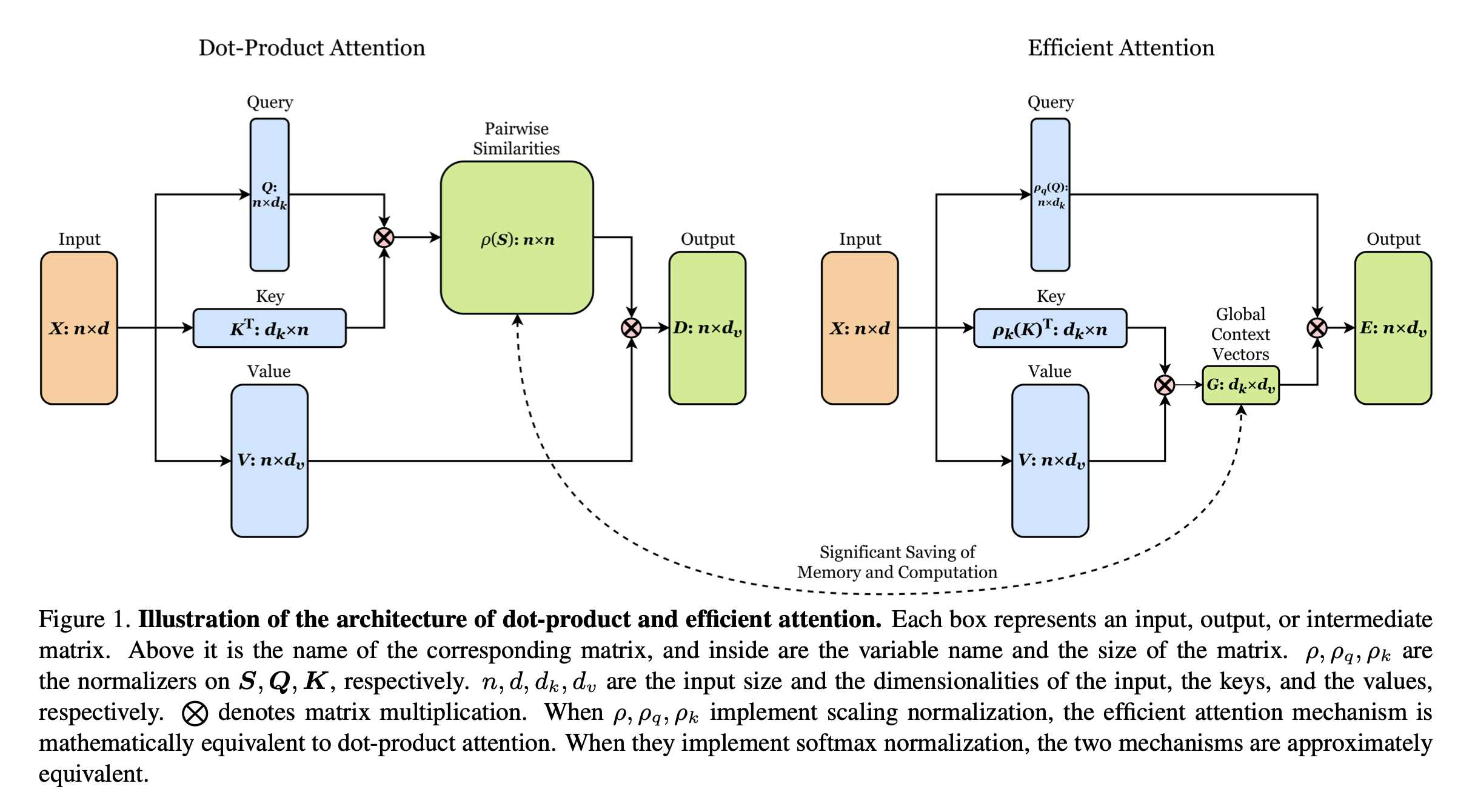
"Efficient Attention: Attention with Linear Complexities"에서는 inner product 전에 queries와 keys를 각각 정규화하기 위해 Softmax 함수를 사용했다. 이는 ϕ(qi)=softmax(qi) and ϕ(kj)=exp(kj)로 동일하게 표현된다. Linear attention에 대한 더 디테일한 것들은, original 논문을 참고하는 것을 장려한다.
→ 즉, ϕ(qi),ϕ(kj)를 처음부터 exponential 형태로 만들어서, softmax로 계산하는 것 같다. 값을 구하고 그 값을 바탕으로 나중에 softmax로 구해주는 것이 아니라. (정확하지 않음. 자세한 것은 original paper를 참고하심이!) (Figure 출처 : "Efficient Attention: Attention with Linear Complexities" Paper)
이 section에서는 RoPE를 Equation (18)과 통합하는 것에 초점을 맞출 것이다. RoPE는 hidden representation의 크기를 바꾸지 않은 채로 유지하는 회전을 이용해 위치 정보를 주입하기 때문에, rotation matrix와 non-negative 함수의 outputs을 곱하면서 RoPE를 linear attention과 합칠 수 있다.
주목할 점은 0으로 나누는 위험을 피하기 위해 분모를 바꾸지 않고 유지하고, 분자의 합이 음수를 포함할 수 있다는 것이다. Eq (19)의 각 value vi의 가중치가 엄격하게 확률적으로 정규화되지 않았더라도, 여전히 계산이 values들의 중요도를 모델링할 수 있다고 부드럽게 주장한다.
3.4 Theoretical Explanation
3.4.1 Derivation of RoPE under 2D
2차원 하에서, 각각 query와 key에 해당하고 위치가 m,n인 두 단어의 embedding vectors xq,xk를 고려한다. Eq (1)에 따르면, 각 position-encoded 대응물은 다음과 같다:
Eq (20)
qm=fq(xq,m)kn=fk(xk,n)
여기서 q와 k의 아래 첨자인 m,n은 인코딩된 위치 정보를 나타낸다. f{q,k}로 두 벡터들의 inner product를 정의하는 g함수가 있다고 가정하자:
Eq(21)
qmTkn=⟨fq(xm,m),fk(xn,n)⟩=g(xm,xn,n−m)
추가로 아래 초기 조건을 만족해야 합니다:
Eq(22)
q=fq(xq,0)k=fk(xk,0)
빈 위치 정보가 인코딩된 벡터로 읽을 수 있다. 이러한 설정이 주어졌을 때, fq,fk의 답을 찾으려고 시도한다. 먼저 2차원에서 벡터와 벡터의 복소수 상대 부분의 기하학적 의미를 이용하여, Eq (20)과 (21)의 함수들을 다음과 같이 분해한다:
이는 Rq,Rk,Rg가 위치 정보와는 독립적이라고 해석한다. 다른 한 편, Eq(26b)에서 알 수 있듯이 Θq(xq,m)−θq=Θk(xk,m)−θk는 angle functions이 query와 key에 의존하지 않는다는 것을 나타낸다. Angle 함수들을 Θf:=Θq=Θk로 설정을 하고, Θf(x{q,k},m)−θ{q,k} 부분은 위치 m의 함수이고 word embedding x{q,k}와 독립적이다. 이 부분을 ϕ(m)이라고 적었고, 다음을 산출한다:
Eq (28)
Θf(x{q,k},m)=ϕ(m)+θ{q,k}
Θq(xq,m)−θq=Θk(xk,m)−θk 인데, 이걸 보면 위치가 m이면 query나 key 모두 같은 값을 갖는다. 즉, query인지, key인지에 의존하지 않는다. 위치에따라 달라진다.
그래서 ϕ(m)으로 표현할 수 있는 것이다.
그리고 Θf라고 두었을 때, xq이던지 xk이던지에 관계 없이 같은 값을 가지니까
→ 이것에 대한 이유는 Θf(xq,m)−θq=Θf(xq,m)−Θq(xq,0)=Θf(xq,m)−Θf(xq,0)이다. 즉 Θf(xq,m)−Θf(xq,0)=Θf(xk,m)−Θ(xk,0)이니까.
쉽게 생각하면 f(x,m) - f(x,0) = f(y,m) - f(y,0) 이니까 사실 f(1,m) - f(1,0) = f(2,m) - f(2,0) = … 이니까 word embedding과는 independent!
그래서 Θf(x{q,k},m)−θ{q,k}가 m과 관계된 함수로 나오는 것을 알 수 있고. 다음과 같은 식을 산출할 수 있는 것이다.
Θf(x{q,k},m)−θ{q,k}=ϕ(m))
또한 Eq(24)에 n=m+1을 연결하고 위의 식을 고려하여, 다음을 얻을 수 있다:
Eq(29)
ϕ(m+1)−ϕ(m)=Θg(xq,xk,1)+θq−θk
RHS가 m에 관계없는 상수이기 때문에, 연속적인 정수 입력의 ϕ(m)는 다음과 같은 등차 수열을 만든다: