Paper : https://arxiv.org/abs/2309.17453
Abstract
LLM을 streaming applications에 배포할 때 2가지 주된 과제가 제기된다.
- Decoding 할 때, 이전 토큰의 Key와 Value 캐싱하는 것은 큰 메모리를 소비함
- 인기있는 LLM들은 훈련할 때의 사용된 시퀀스 길이보다 긴 텍스트에 대해 일반화할 수 없다.
Window attention : 가장 최근의 Key, Value만 캐싱되는 자연스러운 접근 방법
→ text 길이가 캐시 사이즈를 넘어서면 실패한다 (캐싱되는 곳보다 들어오는게 크면 실패하는게 당연!)
'Attention sink' 라는 현상을 발견!
Attention sink : 초기 토큰들의 Key, Value 값을 유지하는 것이 window attention의 성능을 크게 회복하는 것을 발견
본 논문에서는 먼저 attentioin sink의 등장이 초기 토큰들이 의미론적으로 중요하지 않더라도 “sink”로써 첫 토큰들을 향한 강한 attention scores 때문이라는 것을 증명한다.
StreamingLLM 소개!
StreamingLLM : 유한한 길이의 attention window로 학습된 LLM들을 fine-tuning 없이 무한한 시퀀스 길이로 일반화 해줄 수 있는 효율적인 프레임워크.
⇒ StreamingLLM을 통해 LLaMA-2, MPT, Falcon, Pythia가 4 million이나 그 이상 tokens을 이용해 language modeling을 안전하고, 효율적이게 수행할 수 있음을 보여준다.
또한 Pretraining 중에 Dedicated attention sink로 placeholder token을 추가하는 것은 streaming 배포를 향상시킬 수 있음을 확인했다.
Streaming setting에서, StreamingLLM은 sliding window recomputatino baseline보다 최대 22.2배로 속도를 향상시켰다.
1. Introduction
LLM들은 다양한 자연어 적용들(대화, 문서 요약, QA, etc)에 쓰이는 유비쿼터스(시간과 장소에 구애받지 않고 언제나 정보통신망에 접속하여 다양한 정보통신서비스를 활용할 수 있는 환경을 의미)가 되고 있다. LLM의 잠재력을 풀기 위해서는 긴 시퀀스 생성을 효율적이고 정확하게 수행할 수 있어야 한다. 그러나 pretrained된 시퀀스 길이보다 긴 시퀀스들에 대해 일반화하는 것은 LLM에게 매우 어렵다(LLaMA-2의 경우 4K).
그 이유는 LLM이 pre-training 중에 window attention에 의해 제한되고 있기 때문이다. Window 크기를 늘리고, 긴 input들에 대한 training & inference의 효율성을 향상시켜주기 위한 상당한 노력에도 불구하고, 허용 가능한 시퀀스의 길이는 본질적으로 유한하며, 이는 끊임없는 배포를 허용하지 않는다.
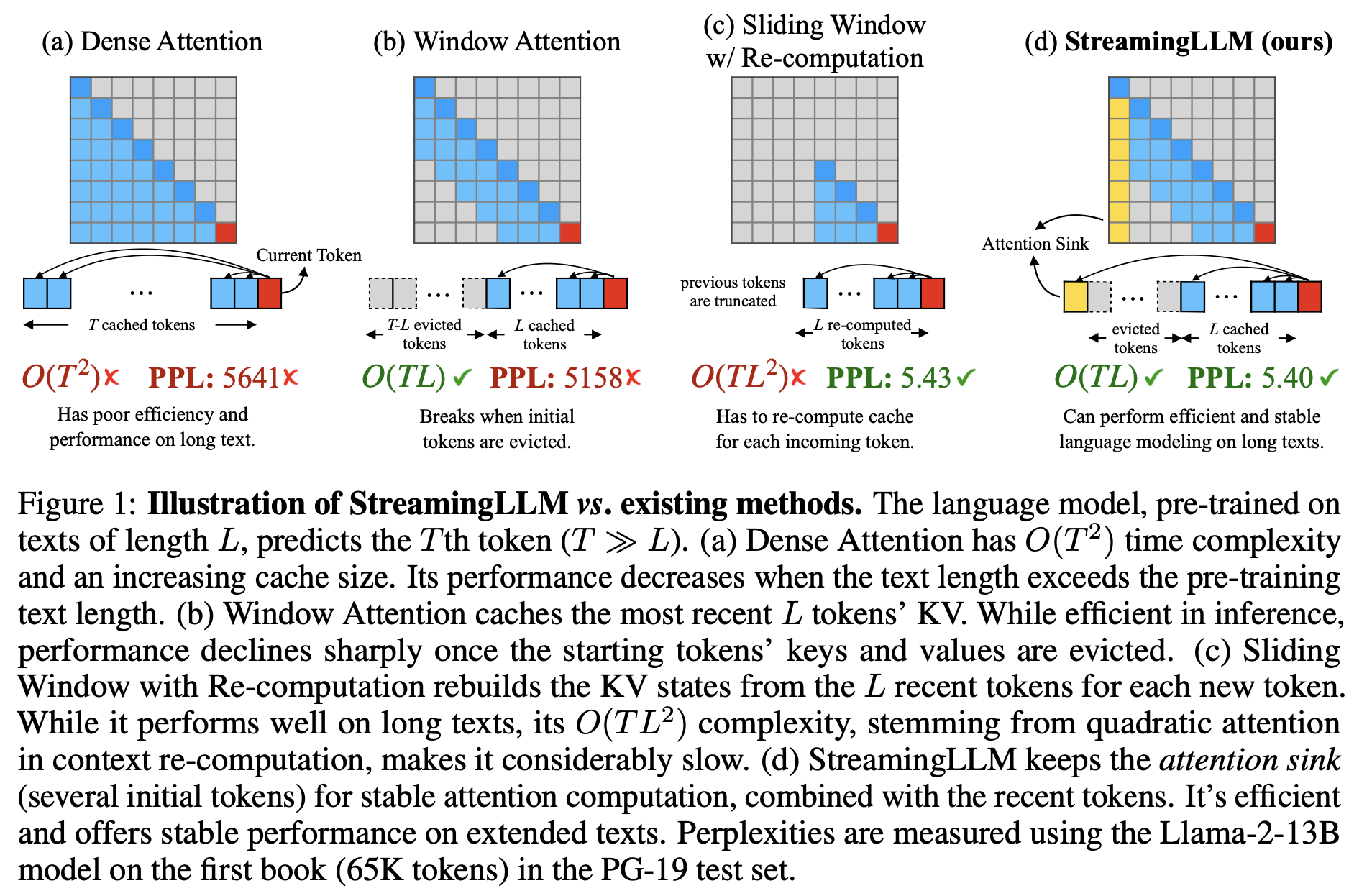
Sliding Window with Re-computation vs. Window Attention:
(출처 : https://github.com/mit-han-lab/streaming-llm/issues/33)
- Sliding Window with Re-computation
Assume we have a token sequence [a, b, c, d, e, f, g], and the model's window size is 4. For predicting token 'g', the sliding window with re-computation truncates the text sequence to [d, e, f], treating it as a whole sequence before inputting it into the language model, predicting only token 'g'. Here, token 'd' is at position 0, 'e' at 1 (seeing only 'd'), and 'f' at 2 (seeing 'd' and 'e').
→ window size가 4이면, 예측하는 것 포함해서 크기가 4로 만든다. 여기서는 [d,e,f,g] 만 남겨놓고 버린다. 그리고 여기서 d : position_0, e : position_1, f : position_2 로 여기고 'g'를 예측한다. 즉, position이 다 reset 되기에 만큼 계산이 되어야하고, 여기서 T번째 단어를 예측하기 위해 T번 계산을 해야하니까
내 생각에는 [d,e,f] 의 key, value 값을 새로운 위치 정보와 함께 다시 구해주기에, 만큼의 계산 과정이 필요한 것 같다.
- Window Attention
In contrast, window attention reuses the previously computed KV states. So, while predicting 'g', the reused tokens [d, e, f]'s KV are based on prior computations: 'd' was computed at pos 3 (seeing a, b, c), 'e' at pos 3 (seeing b, c, d), and 'f' at pos 3 (seeing c, d, e).
- The critical distinction is that in sliding window with re-computation, some key states are treated as initial tokens, whereas in window attention, all previous tokens' KV are computed as if they were middle tokens.
→ [d,e,f]를 이용하여 g를 예측할 때, d,e,f에 해당하는 key, value 값을 이 전에서 가져왔기에, 이미 가져온 값(d,e,f)을 이용하여 g를 예측하기에, g와 [d,e,f] 값의 계산 :
So, T번째의 token을 예측하기 위해 이 계산이 만큼 수행되어져야 하니까, total time complexity :
- 근데 여기서 의문점?
Window attention에서 모든 이전의 토큰들의 KV가 Middle token들인 것처럼 계산된다고 했는데, 예시를 보면 Window Attention을 계산할 때, pos 3으로 계산된 'd'와 pos 3으로 계산된 'e'와 pos 3으로 계산된 'f'를 이용한다고 한다.
이게 왜 middle token인 것처럼 계산된걸까? Middle token이 아니라 last(end) token처럼 계산된 것이 아닌가? window가 4라면??
→ ChatGPT와 대화를 나눈 끝에 이에 대한 생각은, middle tokens라는 것이 초기 token이 아닌 위치에 대한 상대적인 위치를 표현하는 방법인 것 같다. Last(end) token 이라는 말은 여기서 이용되는 용어 선택이 아닌 것 같다. 즉, 초기 위치 정보가 아니고 어떤 값을 기준으로 상대적인 위치 값을 가지고 있으니(여기서는 pos 3), 이를 middle tokens라고 부르는 것 같다.
정확하게는 아직 잘 모르겠고, 혹시 아시는 분이 있으면 알려주시면 감사하겠습니다 ㅠㅠ
LLM을 무한한 길이의 input에 대해 효율성과 성능 저하 없이 배포할 수 있을까?
무한한 길이의 input stream을 LLM에 적용할 때, 2가지 주된 과제가 발생한다:
- Decoding 중에 transformer 기반 LLM들은 모든 이전 토큰들의 Key & Value (KV)를 캐시하는 것은 메모리 사용량 초과와 decoding 지연을 초래할 수 있다. (Figure 1에서 볼 수 있음)
- 기존의 모델들은 제한된 길이 외삽 능력을 가지고 있다. 즉, 시퀀스의 길이가 pre-training 중에 지정된 attention window size를 넘어갈 때, 성능이 저하하는 것이다.
외삽 능력(extrapolation abilities)이란?
외삽(Extrapolation)은 주어진 데이터 범위를 벗어난 영역에서 결과를 추정하는 통계적이나 수학적인 방법을 가리키는 용어. 간단히 말해, 주어진 데이터의 패턴이나 동향을 기반으로 데이터가 주어진 범위를 넘어선 영역에서 어떤 값을 예측하는 것을 의미.
Window attention이라고 알려진 직관적인 접근 방법은 가장 최근의 토큰들의 KV에 대한 고정된 크기의 sliding window를 유지한다. 이는 캐시가 초기에 채워진 후 일정한 메모리 사용량과 디코딩 속도를 보장하지만, 모델은 시퀀스 길이가 캐시 크기를 초과하면, 즉, Figure 3과 같이 첫 번째 토큰의 KV를 제거하는 경우에도 붕괴한다.
Input sequence의 길이가 캐시 크기보다 커지면, 최근 토큰들의 KV를 캐시하는 쪽으로 window가 이동해야하니까 초기 토큰이 빠지게 된다. 즉, 초기 토큰의 KV가 제거되는 순간부터 성능이 무너진다.
초기 토큰이 빠지게 된다면, 그 이후에 예측하는 토큰들은 pos 0에 대항하는 토큰을 이용하지 않고 예측됨.
다른 전략은 Figure 1 c에 나와있는 re-computation을 이용한 sliding window이다. 이는 각각의 생성된 토큰들에 대해 최근 토큰들의 KV를 다시 짓는다
Window마다 pos 0을 의미하는 토큰들을 두며, 새롭게 KV를 계산하는 방식. Window가 이동해도 항상 초기 토큰(pos 0)의 KV를 갖는다
이는 좋은 성능을 내지만, 이 방법은 window에 대한 quadratic attention 계산 때문에 매우 느리게 되고, 그렇기에 실제 세상의 스트리밍 어플리케이션에 실용적이지 않다.
Window 내의 모든 토큰들에 대해 KV를 다시(새롭게) 계산해주어야하기에, 만큼의 시간복잡도가 생긴다
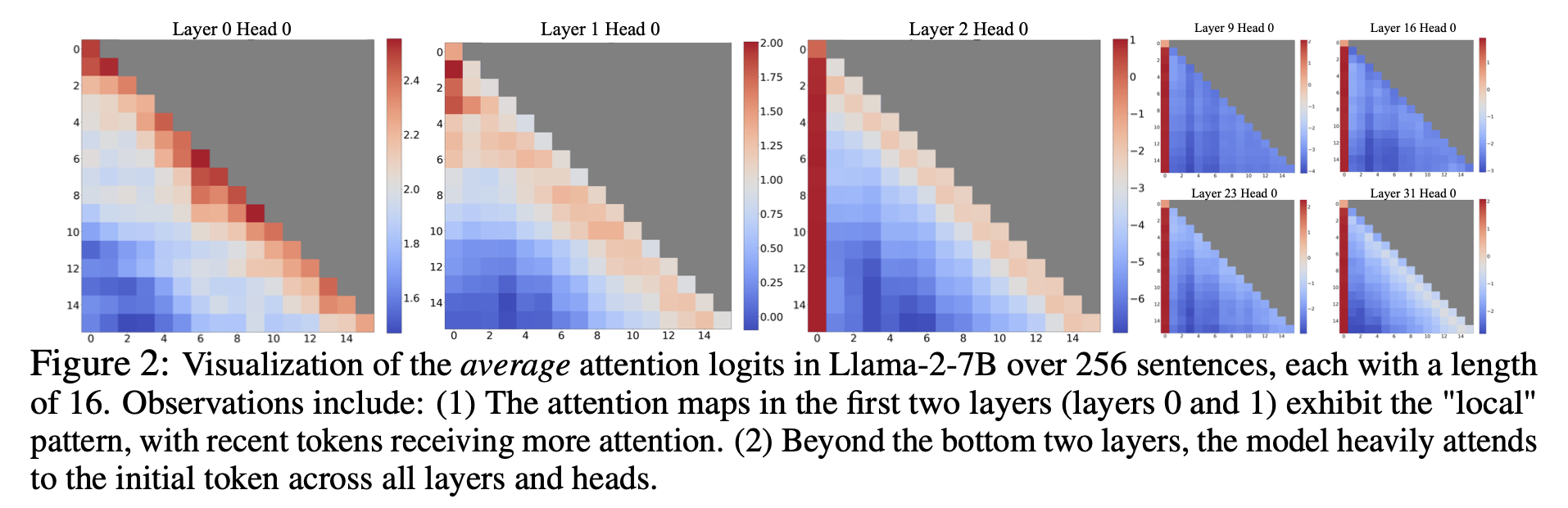
Window attention의 실패를 이해하기 위해, 자기 회귀적인 LLM들의 흥미로운 현상을 찾았다 : Language modeling task에 상관없이 매우 큰 attention score가 첫 토큰들에 할당되었다. (Figure 2에 시각화되어 있다.) 이러한 토큰들을 “attention sinks”라고 부른다. 의미적 중요성이 부족함에도 불구하고, 첫 토큰들은 상당한 attention score를 수집했다. 우리는 그 이유를 모든 배경적 토큰들에 대한 attention score들의 합이 1이 되어야하는 softmax 연산 때문으로 보았다. 그래서 현재의 query가 이전의 토큰들과 강한 매치를 갖지 않아도, attention value들의 합이 1이 되게 하기 위해 필요하지 않은 attention value들의 할당이 여전히 필요하다. 초기 토큰들이 sink token들인 이유는 직관적이다: 자기 회귀적인 Language modeling의 특성 때문에 초기의 토큰들은 거의 모든 그 이후의 토큰들에서 보일 수 있으므로, 초기 토큰들이 attention sinks 역할을 하도록 더 쉽게 훈련된다.
위의 식견을 기반해, 간단하고 효율적인 프레임워크로 유한한 attention window로 훈련된 LLM들을 fine-tuning 없이 무한한 길이의 텍스트에 대해 작동할 수 있게 해주는 StreamingLLM을 제안한다. StreamingLLM은 attention sinks가 높은 attention 값을 가지고, attention sinks를 보존하는 것이 attention score 분포를 보통과 비슷하게 유지할 수 있다는 점을 이용했다. 따라서 StreamingLLM은 attention 계산을 고정하고 모델의 성능을 안정화시키기 위해 attention sink 토큰들의 KV(4개의 초기 토큰들만 해도 충분하다)와 sliding window의 KV를 함께 간단히 유지한다. StreamingLLM을 가지고, Llama-2-[7, 13, 70]B, MPT-[7, 30]B, Falcon-[7, 40]B, and Pythia- [2.9,6.9,12]B 를 포함한 모델들은 4 million 토큰들을 안정적으로 모델링할 수 있고, 잠재적으로는 그 이상을 모델링할 수 있다. 유일하게 실행 가능한 baseline인 재계산을 이용한 sliding window와 비교했을 때, StreamingLLM은 22.2배 속도 향상을 달성하여 LLM의 스트리밍 사용을 실현한다.
최종적으로 우리의 attention sink 가설을 확인하고, streaming 배포를 위해 LM은 오직 하나의 attention sink 토큰만 필요하도록 pre-trained 될 수 있음을 증명한다. 특히, 모든 훈련 샘플들의 시작 부분에 추가적인 훈련 가능한 토큰이 지정된 attention sink 역할을 할 수 있음을 제안한다. 160-million parameter LM들을 처음부터 pre-training 함으로써, 우리는 하나의 sink 토큰을 추가하는 것이 streaming 경우들에서 모델의 성능을 보전하는 것을 증명한다. 이는 같은 성능 수준을 달성하기 위해 다수의 초기 토큰들을 attention sink들로 재도입이 필요한 바닐라 모델들과는 대조적이다.
2. RELATED WORK
LLM을 긴 텍스트에 적용하는 광범위한 연구가 이루어졌고, 3가지 주요 분야에 중점을 두고 있다: Length Extrapolation, Context Window Extension, and Improving LLMs’ Utilization of Long Text.
3가지가 연관되어있는 것 같지만, 그렇진 않다. StreamingLLM 프레임워크는 LLM들이 pre-training window size를 상당히 초과하는 텍스트에 적용되는, 잠재적으로는 무한한 길이의 텍스트에 적용되는 첫 번째 카테고리에 주로 속한다. 우리는 LLM들의 attention window 크기를 늘리거나 긴 텍스들에 대해 모델의 메모리와 사용량을 강화해주지 않는다. ‘Context Window Extension’과 ‘Improving LLMs’ Utilization of Long Text’는 우리의 관점과 수직적이고(관계가 없다, Independent 하다), 우리의 기술들과 통합될 수도 있다.
Length extrapolation
Length extrapolation은 짧은 텍스트들로 훈련된 LM들을 test동안 더 긴 텍스트들을 처리할 수 있게 해주는 것을 목표로 한다. 연구의 주된 방법은 Transformer 모델들의 상대적인 위치 인코딩 방법의 개발을 목표로 하고, 이는 훈련 window 너머에도 기능하게 해준다. 이와 같은 직관적인 방법 중 하나는 Rotary Position Embeddings (RoPE)이다. 이는 상대적인 위치 통합을 위해 모든 attention 층의 queries, keys들을 변환시키는 것이다. 이의 가망성에도 불구하고, 그 이후의 연구는 훈련 window를 넘는 텍스트에 대해 성능이 저하됨을 나타냈다. 다른 연구인 ALiBi는 거리 기반으로 query-key attention score를 편향시켜서 상대적 위치 정보를 도입한다. 이는 향상된 extrapolation을 보여주었지만, MPT 모델들에 대한 우리의 테스트는 텍스트의 길이가 훈련 길이보다 훨씬 큰 경우의 고장을 강조했다. 그러나 현재의 방법론들은 무한한 길이의 extrapolation을 아직 달성하지 못했기에, 기존의 LLM들은 streaming 어플리케이션에 적합하지 않았다.
Context Window Extension
Context Window Extension은 LLM의 context window를 확장하는 것에 중점을 두어, 하나의 forward pass에서 더 많은 토큰이 처리될 수 있도록 한다. 가장 기본적인 작업 라인은 훈련 효율성 문제를 다루는 것이다. 훈련 중 계산의 quadratic 복잡성을 갖는 attention이 주어졌을 때, 긴 배경의 LLM을 발전시키는 것은 계산적으로도 메모리 적으로도 과제이다. 답들은 attention 계산을 가속화해주고, 메모리 사용량을 줄여주는 FlashAttention과 같은 시스템에 초점을 맞춘 최적화부터 효율성을 위해 model의 퀄리티를 교환하는 approximate attention 방법들까지 다양하다. 최근에는 위치 보간법과 fine-tuning을 포함하는 RoPE를 이용한 pre-trained LLM를 넓혀주는 작업이 등장했다. 그러나 앞서 언급한 모든 기술들은 제한된 범위 내에서 LLM의 배경 window를 확장할 뿐이며, 이는 제한 없는 입력을 다루는 본 논문의 주된 관심사에 미치지 못한다.
Improving LLMs’ Utilization of Long Text
Improving LLMs’ Utilization of Long Text는 단순히 LLM들을 input으로 사용하는 것이 아니라 배경 내에서 내용물(content)을 더 잘 포착하고, 활용할 수 있도록 최적화한다. Liu et al. 과 Li et al.에서 강조한 바와 같이, 앞서 언급된 두 가지 방법들의 성공이 반드시 긴 배경들의 유능한 활용으로 해석되진 않는다. LLM 내에서 길어진 배경들의 효과적인 사용을 다루는 것은 여전히 과제이다. 본 논문의 작업은 LLM의 원활한 스트리밍 애플리케이션을 가능하게 하는 최신 토큰을 안정적으로 활용하는 데 중점을 두고 있다.
3. STREAMINGLLM
3.1 THE FAILURE OF WINDOW ATTENTION AND ATTENTION SINKS
Window attention은 inference 동안 효율성을 제공하지만, 이는 매우 높은 language modeling perplexity를 초래한다. 결과적으로 모델의 성능은 streaming 어플리케이션 배포에 적합하지 않는다. 이 부분에서 window attention의 실패를 설명하기 위해 attention sink의 개념을 사용하며, StreamingLLM의 영감으로 사용한다.
Identifying the Point of Perplexity Surge
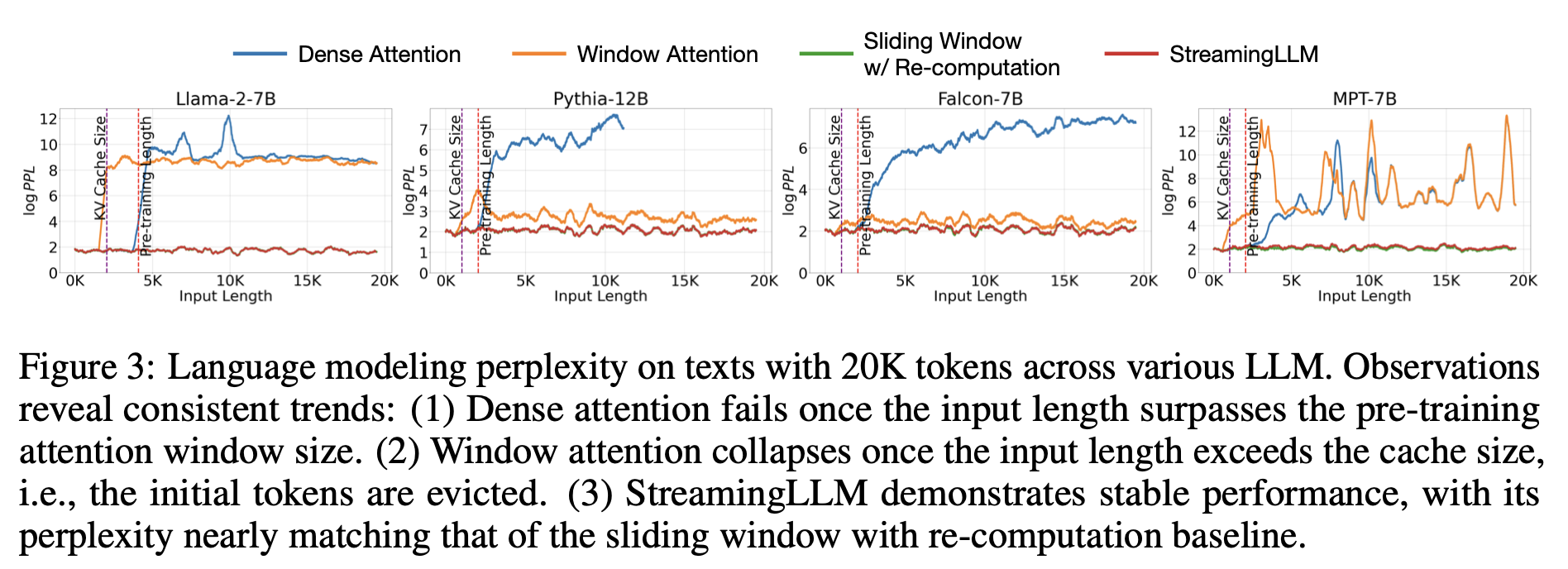
Figure 3은 20k token text에 대한 language modeling의 perplexity를 보여준다. Text 길이가 캐시 사이즈보다 커지면 perplexity가 급증한다는 것을 알 수 있다. 이는 초기 토큰들을 배제한 결과이다. 이는 예측되는 토큰들로부터의 거리와 상관없이, 초기 토큰들이 LLM의 안정성을 유지하는데 중요하다는 것을 보여준다.
Why do LLMs break when removing initial tokens’ KV?
Figure 2에서 LLaMA-2-7B와 모델들의 모든 층과 헤드로부터의 attention map들을 시각화했다. 가장 아래 2층을 넘어, 모델이 모든 층과 헤드에서 초기의 토큰들에 일관적으로 초점을 두고 있는 것을 발견했다. 시사점은 분명하다: 이러한 초기 토큰들의 KV를 제거하는 것은 attention 계산 안의 Softmax 함수(Equation 1)에서 분모의 상당한 부분을 제거하는 것이다. 이 변화는 보통의 inference setting으로 기대된 것으로부터 attention score의 분포의 상당한 이동을 초래한다.
Language modeling에서 초기 토큰들의 중요성을 설명해주는 두 가지 설명이 있다:
(1) 의미가 중요하거나
(2) 모델이 초기 토큰들의 absolute 위치에 대해 편향을 배우는 것이다.
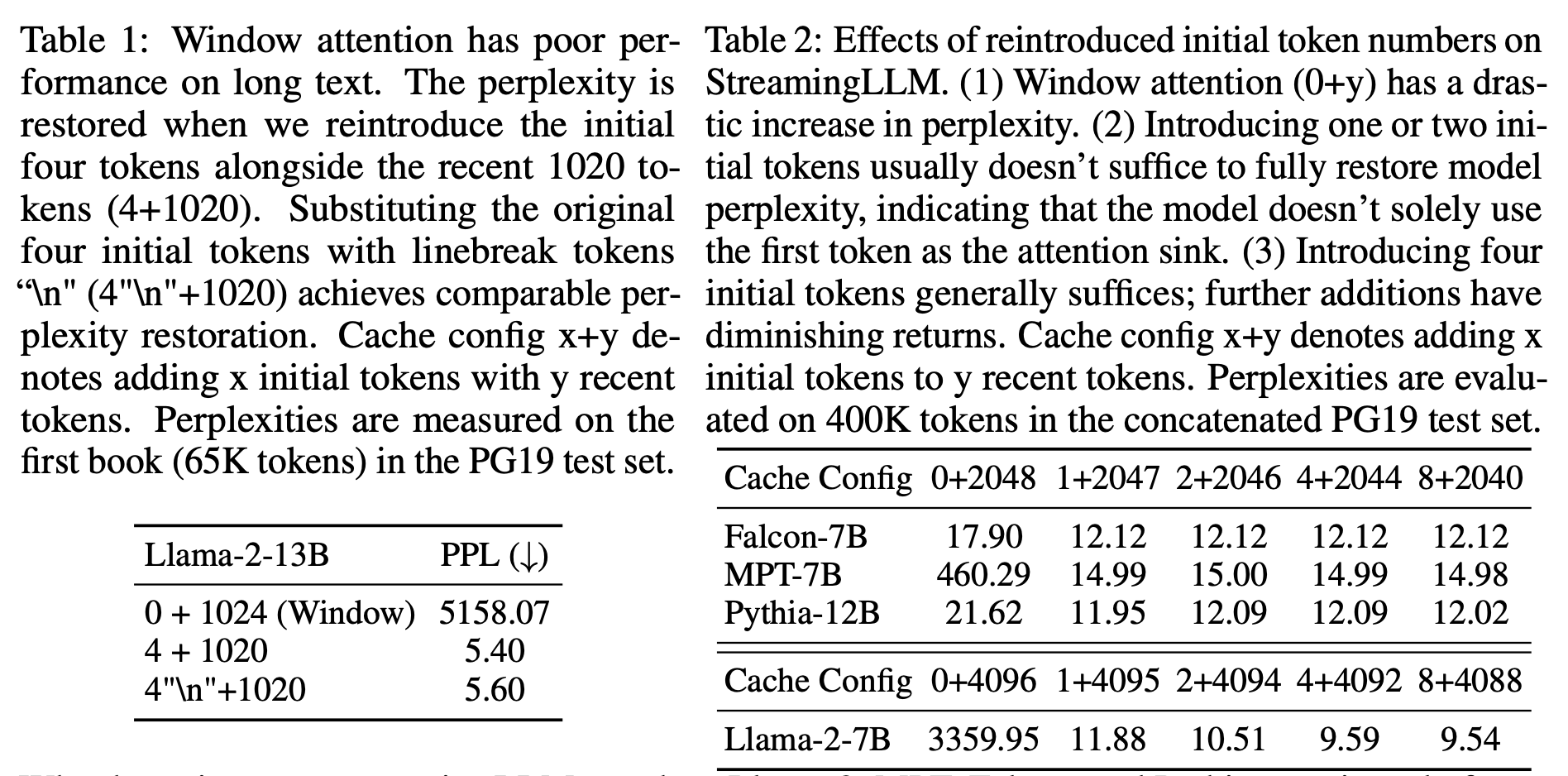
이러한 가능성들을 구분하기 위해, 우리는 첫 4개의 토큰들을 linebreak 토큰 ‘\n’로 대체하는 실험들(Table 1)을 수행한다. 이 실험에서 모델은 여전히 초기의 linebreak 토큰들을 상당히 강조하는 것을 알 수 있다. 게다가 이들을 재도입하는 것은 language modeling perplexity가 원래의 초기 토큰들을 가졌으 때와 비슷한 수준으로 복원된다. 이는 시작 토큰들의 값보다 시작 토큰들의 absolute 위치가 더 큰 중요성을 갖는다는 것을 말한다.
LLMs attend to Initial Tokens as Attention Sinks
Language modeling에서 의미적 연관성에 무관하게 모델이 불균형하게 초기 토큰들에 집중하는 이유를 설명하기 위해서 “attention sink” 라는 개념을 도입한다. Equation 1의 softmax 함수의 특성은 참여한 모든 토큰이 0 값을 갖지 않도록 한다. 이를 위해서는 현재 embedding이 예측을 위한 충분한 자체 포함 정보를 가지고 있더라도 모든 층의 모든 헤드들에 걸쳐 다른 토큰들로부터 약간의 정보를 집계해야 한다. 결과적으로 모델은 특정 토큰들에 불필요한 attention 값을 버리는 경향이 있다(1을 채워야 하니까, 특정 토큰들한테 남은 값들을 할애하는 느낌).
왜 Llama-2, MPT, Falcon, Pythia와 같은 다양한 자기 회귀적인 LLM들이 다른 토큰이 아닌 초기의 토큰들을 attention sinks로 한결같이 집중할까? 우리의 설명은 간단하다: 자기 회귀적인 Language modeling의 순차적인 특성 때문에, 초기 토큰은 그 이후의 모든 토큰들에서 보이지만 다른 토큰들은 자신의 이후 토큰들에서 보이니까 제한된 집합에서만 보인다. 결과적으로 초기의 토큰들은 불필요한 attention을 잡으며, attention sinks로써 훈련되기 쉽다.
LLM들은 전형적으로 하나의 토큰을 attention sink로 쓰기보다 여러 개의 초기 토큰들을 attention sinks로 활용하여 훈련되는 것에 주목했다. Figure 2에서 볼 수 있듯이, attention sinks로써 4개의 초기 토큰들을 도입하는 것은 LLM의 성능을 복원하기에 충분하다. 반면에 한 개나 두 개를 추가하는 것은 성능을 완전히 복원하기에 부족하다. 이러한 패턴이 나오는 이유는 이러한 모델들이 pre-training 동안 모든 input sample들에 대해 일관된 시작 토큰을 포함하지 않았기 때문이라고 생각한다.
LLaMA-2는 각 문단을 <s> 토큰을 접두사로 붙여 이용했지만, 이는 text chunking 이전에 적용되었기에 대부분의 랜덤 토큰은 0번째 위치를 차지한다. 이러한 균일한 시작 토큰들의 부족은 모델이 attention sink로써 다양한 초기 토큰들을 이용하게 만들었다. 모든 훈련 샘플들의 시작부분에 하나의 안전한 훈련 가능한 토큰을 붙임으로써 이는 홀로 committed attention sink로써 동작할 수 있고, 일관된 스트리밍을 보장하기 위해 다수의 초기 토큰이 필요한 것을 없앨 수 있다. 이를 Section 3.3에서 입증할 것이다.
3.2 Rolling KV Cache with attention sinks
이미 훈련된 LLM에서 LLM 스트리밍을 가능하게 하기 위해 모델의 fine-tuning 없이 window attention의 perplexity를 회복하는 간단한 방법을 제안한다. 현재의 sliding window 토큰들과 함께, attention 계산에서 몇 개의 시작 토큰들의 KV를 재도입했다. StreamingLLM에서의 KV 캐시는 개념적으로 두 부분으로 나뉠 수 있다(Figure 4): (1) Attention 계산을 안정화 시켜주는 Attention Sinks (4개의 초기 토큰들) (2) 가장 최근의 토큰들을 포함한, Language modelling에 중요한 Rolling KV 캐시
StreamingLLM의 디자인은 다재다능하고, RoPE과 같은 상대적인 위치 인코딩을 사용하는 어느 자기 회귀 언어 모델에 원활하게 통합될 수 있다.
상대적 거리를 결정하고, 위치 정보를 토큰에 추가할 때, StreamingLLM은 원래 텍스트의 위치보다 캐시 안의 위치에 집중한다. 이 구별은 StreamingLLM의 성능에 중요하다. 예를 들어, Figure 4를 보자. 현재 캐시가 [0,1,2,3,6,7,8] 토큰들을 가지고 있고 9번째 토큰을 디코딩하는 절차에 있으면, 할당되는 위치는 원래 텍스트의 [0,1,2,3,6,7,8,9]가 아니라 [0,1,2,3,4,5,6,7] 이다.
RoPE과 같이 인코딩하는 경우, rotary 변환을 도입하기 이전에 토큰들의 Key들을 캐시한다. 그 다음, 각각의 decoding 단계에서 rolling 캐시 안의 키들에 위치 변환을 적용한다. 반면에 ALiBI와 결합하는 것은 더욱 직접적이다. 여기서 ‘jumping’ 편향 대신에 연속 선형 편향이 attention 점수에 적용된다. 캐시를 가지고 위치 임베딩을 할당하는 이 방법은 StreamingLLM의 기능성에 중요하며, pre-training attention window 크기를 넘어서도 모델이 효율적으로 작동하는 것을 보장해준다.
3.3 Pre-training LLMs with Attention Sinks
3.1절에서 설명한 바와 같이, 모델이 여러 개의 초기 토큰들에 과도하게 주의를 기울이는 중요한 이유는 과도한 주의 점수를 떨쳐 버리기 위해 지정된 sink 토큰이 없기 때문이다. 이 때문에, 모델은 무심코 주로 초기의 토큰들인 전체적으로 볼 수 있는 토큰들을 attention sinks로 지정한다. 잠재적인 해결책은 불필요한 attention 점수의 저장소 역할을 하는 “Sink Token”으로 표시되는 전체적인 훈련 가능한 attention sink 토큰을 의도적으로 포함하는 것일 수 있다. → 즉, 불필요한 점수를 저장할 attention sink 토큰을 의도적으로 포함하는 것이 해결책이 될 수 있다. 또는 관습적인 Softmax 함수를 모든 배경적인 토큰들에 대한 attention 점수의 합이 1이 될 필요가 없는 Softmax-off-by-One과 같은 변형으로 대체하는 것 또한 효과적일 수 있다.
이 Softmax-off-by-One은 attention 계산에서 모든 key, value 가 0인 토큰을 이용하는 것과 동일하다. 우리의 프레임워크에 일관되게 맞추기 위해서 이 방법을 “Zero Sink”라고 적는다.
검증을 위해, 동일한 세팅 아래에서 처음부터 160 million parameters를 가진 3개의 LM을 pre-train 시킨다. 첫 번째 모델은 표준 Softmax attention을 활용하고, 두 번째는 일반적인 attention 메커니즘을 SoftMax1(Zero Sink)로 대체하고, 마지막 하나는 모든 훈련 샘플들에서 훈련가능한 placeholder 토큰(Sink token)을 앞에 붙인다. Table 3에서 볼 수 있듯이, zero sink가 attention sink 문제를 어느정도는 완화할 수 있지만, 모델은 attention sink들로써 다른 초기 토큰들에게 여전히 의존한다. Attention 메커니즘을 안정화시키는 것에는 sink token을 도입하는 것이 매우 효과적이다. 단순히 sink 토큰과 최근의 토큰들을 같이 놔두는 것은 충분히 모델의 성능을 고정시킬 수 있고, 결과적인 평가 perplexity는 심지어 조금 개선되었다. 이러한 연구 결과들을 보아, streaming 배포를 최적화 하기 위해 미래의 LLM들을 모든 샘플들에 대해 sink token을 가지고 훈련하는 것을 추천한다.

<느낀점>
Transformer의 query, key로 계산된 점수를 softmax를 이용하여, 해당 query에서 모든 key와 계산했을 때의 0 ~ 1의 attention score가 계산되는 것은 좋아보였다. 그리고 하나의 query에 대한 모든 key의 attention score의 합계는 1이 되어, attention block의 output이 원래의 value 값들에 비해 너무 커지거나 작아지는 것을 방지할 수 있어 좋은 방법인 듯 보였다. 하지만 이 논문에서 보니, 문장에서 서로 관계가 적은 단어의 쌍도 attention score의 합이 1이 되게 하기 위해서 불필요한 attention score가 할당된다는 점을 생각할 수 있게 되었다.
지금과 같이 attention sink를 만들어주어 불필요한 attention score를 버릴 수 있는 저장소를 만들어 주는 것도 좋아보이나, Softmax 함수가 아닌 다른 함수를 이용하는 것이 더 문제 해결에 도움이 되지 않을까 싶은 개인적인 생각이 든다.
