paper : https://arxiv.org/abs/2309.06180
Abstract
LLM의 높은 처리량 서비스는 한 번에 충분히 많은 요청을 배치해야 한다. 그러나 기존 시스템은 각 요청에 대한 Key-Value 캐시 메모리가 크고, 동적으로 커지고 축소되는 것에 어려움을 겪고 있다. 비효율적으로 관리되면, 분열과 중복 복제로 메모리가 크게 낭비되어, 배치 크기가 제한될 수 있다. 이 문제를 해결하기 위해 운영체제의 고전적인 가상 메모리와 페이징 기술에서 영감을 받은 attention 알고리즘인, PagedAttention을 제안한다. 또, (1) KV 캐시 메모리에서 거의 0에 가까운 낭비와 (2) 메모리 사용량을 더욱 줄이기 위해 요청 내, 요청 간에 KV 캐시를 유연하게 공유하는 것을 달성한 LLM serving system인 vLLM을 만든다. 우리의 평가들은 vLLM이 FasterTransformer와 Orca와 같은 SOTA system에 비해 같은 수준의 latency를 가졌을 때, 인기있는 LLM의 처리량을 2-4배 향상시키는 것을 보였다. 이러한 향상은 더 긴 시퀀스, 더 큰 모델, 더 복잡한 디코딩 알고리즘에서 더욱 두드러진다.
1. Introduction
LLM을 이용하는 것은 비싸다 → LLM serving systems에서 Request 당 비용을 줄이는 것은 중요해졌다.
Transformer 모델의 decoding 시, sequential한 특징이 있다. 이는 비싸다는 특징이 있고, workload memory-bound를 만들어 GPU의 계산 능력을 저하시키고 서빙 처리량을 제한한다.
How 처리량을 향상?? ⇒ 다수의 요청들을 함께 배치함으로써, 처리량을 향상시키는 것이 가능하다.
하나의 batch에서 많은 요청들을 처리하기 위해서는 각 요청에 대한 메모리 공간을 효율적으로 관리해야 한다.

Figure 1)
- 약 65% ⇒ 서빙 중에 정적인(static) 모델의 가중치
- 약 30% ⇒ 요청들의 동적인 상태들 (Transformer로 치면, attention 메커니즘에 연관된 key, value tensor. Commonly KV cache)
- 남은 부분 ⇒ Including activations – LLM을 평가할 때 만들어지는 임시 텐서들
모델의 가중치들은 상수이고(변하지 않고), activation은 GPU 메모리의 아주 작은 부분을 차지하니, maximum batch size를 결정하는데 KV cache를 관리하는 방법이 중요하다. 비효율적으로 관리하면, KV cache memory는 배치 사이즈를 상당히 제한할 수 있고, 결과적으로 LLM의 처리량도 상당히 제한될 수 있다. (Fig 1의 오른쪽 부분)
본 논문에서 기존의 LLM 서빙 시스템이 KV 캐시 메모리를 효율적으로 관리하는데 부족함을 관찰한다. 이는 대부분의 딥러닝 프레임워크는 연속적인 메모리에 저장되는 텐서를 필요로 하기에, 하나의 요청에 대한 KV cache를 연속적인 공간에 저장하기 때문에 주로 발생한다. 하지만 전통적인 딥러닝 workloads의 텐서와 다르게 KV cache는 독특한 특징이 있다: 모델이 새로운 토큰을 생성함에 따라 KV cache가 동적으로 커지거나 줄어들며, KV cache의 수명과 길이는 먼저 알지 못한다. 이러한 특성들은 기존 시스템의 접근 방법을 2가지 측면에서 상당히 비효율적으로 만든다:
- 기존의 시스템들은 Internal & external memory fragmentation으로 어려움을 겪고 있다.
Internal memory fragmentation
연속적인 공간에서 요청의 KV cache를 저장하기 위해서, 요청의 maximum 길이(e.g., 2048 tokens)로 메모리의 연속적인 chunk를 미리 할당한다. 이는 심각한 internal fragmentation을 초래할 수 있다 → 요청의 실제 길이가 maximum 길이보다 훨씬 짧을 수 있기 때문
게다가 실제 길이가 먼저 알려진다고 해도, 미리 할당(pre-allocation)은 여전히 비효율적이다 :
전체 chunk는 요청의 수명 동안 예약이 되어있기에, 다른 더 짧은 요청들은 현재 사용되지 않은 어느 부분의 chunk도 활용할 수 없다.
External memory fragmentation
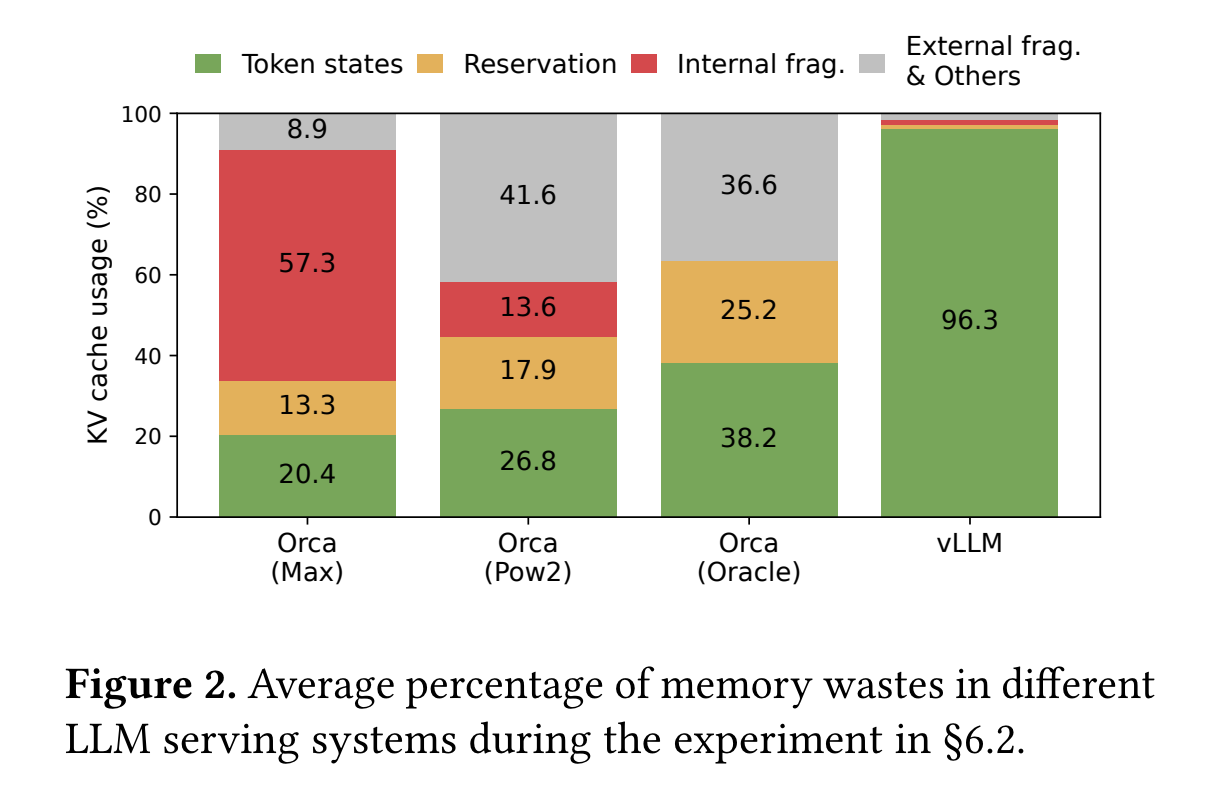
게다가 각 요청에 따라 미리 할당된 사이즈는 다를 수 있기에, external memory fragmentation 또한 매우 중요할 수 있다. 실제로 Figure 2의 프로파일링 결과는 기존의 시스템에서 실제 토큰 상태를 저장하기 위해 오직 20.4% - 38.2%의 KV cache 메모리가 사용되는 것을 보였다.
- 기존의 시스템들은 메모리 공유의 기회를 이용할 수 없다.
LLM 서비스들은 요청(request) 당 다수의 출력을 생성하는 parallel sampling 및 beam search와 같은 진보된 디코딩 알고리즘을 종종 사용한다. 이러한 경우에 요청(request)은 부분적으로 그들의 KV cache를 공유할 수 있는 다수의 시퀀스들로 구성되어 있다. 하지만 기존의 시스템은 시퀀스의 KV cache가 다른 연속적인 공간에 저장되어있기에 메모리 공유가 불가능하다.
이러한 한계들을 해결하기 위해 ”PagedAttention” 제안!
⇒ 메모리 분열과 공유에 대한 운영 체제의 해결책에서 영감을 얻은 attention 알고리즘 : Virtual memory with paging
PagedAttention
요청의 KV cache를 블록들로 나눈다. 각각의 블록들은 고정된 숫자의 토큰들의 attention key들과 value들을 포함한다. PagedAttention 에서는 KV cache 블록들은 연속적인 공간에 저장될 필요가 없다.
⇒ OS의 가상 메모리에서 처럼 KV cache를 더 유연하게 관리할 수 있다 : 블록을 pages로, 토큰들을 bytes로, 요청들을 processes로 생각할 수 있다.
PagedAttention으로 Internal & External fragmentation 완화
- Internal fragmentation : 상대적으로 작은 블록들을 이용하고, 요구에 따라 작은 블록들을 할당함으로써 internal fragmentation 완화.
- External fragmentation : 모든 블록들은 같은 크기를 갖기에 external fragmentation 제거
최종적으로 블록 세분화로 같은 요청에 관련된 다른 시퀀스 간에 또는 다른 요청 간에 메모리 공유를 가능하게 한다.
이 논문에서 vLLM을 설계한다.
⇒ 높은 처리량의 distributed LLM serving engine + PagedAttention(KV cache memory에서 거의 0 낭비)
vLLM은 PagedAttention과 공동 설계된 블록 수준의 메모리 관리와 우선적인 요청 스케줄링을 이용한다. vLLM은 다양한 사이즈의 GPT, OPT, LLaMA와 같은 인기있는 LLM들을 지원하며, 여기에는 단일 GPU의 메모리 성능을 초과하는 것도 포함된다. 다양한 모델들과 workload에 대한 우리의 평가는 vLLM이 LLM 서빙 처리량을 모델의 정확도에 전혀 영향을 주지 않은 채, SOTA 시스템(FasterTransformer, Orca)과 비교해 2-4배 향상시켰다는 것을 보여줬다. 향상된 것은 더 긴 시퀀스, 더 큰 모델, 더 복잡한 디코딩 알고리즘에서 더욱 두드러졌다.
요약하면, 다음과 같은 기여점들을 만들었다 :
- Serving LLM에서 메모리 할당에 어려움들을 식별하고, serving 성능에 미치는 영향을 정량화한다.
- PagedAttention : 연속적이지 않은 paged 메모리에 저장되는 KV cache에 대해 작동하는 attention 알고리즘
- vLLM 설계 & 구현 : A distributed LLM serving engine + PagedAttention
- vLLM 평가 : FasterTransformer & Orca 와 같은 SOTA를 상당히 능가하는 것을 보여줌.
2. Background
일반적인 LLM의 생성과 serving 절차, LLM serving에서 사용된 스케줄링을 iteration 수준으로 설명한다.
2.1 Transformer-Based Large Language Models
Language Modeling의 task : 토큰들의 확률을 모델링하는 것
언어는 자연스러운 순차적 순서를 가지고 있기에, 전체 시퀀스에 대한 joint probability(결합 확률)를 조건부 확률의 곱으로 인수분해하는 것이 일반적이다(a.k.a. Autoregressive decomposition):
Eq(1)
Transformers는 대규모의 확률 모델링에 대한 사실상 표준 구조가 되었다. Transformers 기반 언어 모델에서 가장 중요한 구성 요소는 self-attention 층들이다. Query, Key, Value를 이용해서 attention score를 구한다. (여기서, query, key, value, output의 식은 생략!e.g. )
Transformer 모델의 모든 구성요소들은 형태로 독립적으로 위치별로 적용된다.
2.2 LLM Service & Autoregressive Generation
LLM 서비스에 대한 하나의 요청은 list of input prompt tokens()를 제공하고, LLM 서비스는 list of output tokens()를 생성한다. Prompt와 output lists의 concatenation을 sequence 라고 한다. Eq 1의 decomposition 때문에, LLM은 새로운 토큰들을 샘플링하고 생성하는 것을 오직 하나하나 할 수 있다. 그리고 각 새로운 토큰의 생성 절차는 시퀀스의 모든 이전의 토큰들에 의존한다. 특히, key, value 벡터들. 이러한 순차적인 생성 절차에서 기존의 토큰들의 key, value 벡터들은 미래 토큰들을 생성하기 위해 종종 캐싱된다. 이는 KV cache라고 알려져 있다. 하나의 토큰에 대한 KV cache는 모든 그것의 이전 토큰들에 의존한다. 이는 같은 토큰이지만 sequence 내에서 다른 위치에 있다면 KV cache는 다르다는 것을 의미한다.
요청 prompt가 주어지면 LLM service에서 생성 계산은 두 부분으로 나눠질 수 있다:
- The prompt phase
The prompt phase는 사용자의 prompt ()을 input으로 받고, 첫 번째 새로운 토큰의 확률()을 계산한다. 이 절차동안, key 벡터들 과 value 벡터들 또한 생성한다. Prompt 토큰들 은 모두 알려져 있기 때문에, prompt phase의 계산은 matrix-matrix 곱셈 연산을 사용해서 병렬화 될 수 있다. 그래서 prompt phase는 GPU의 내재된 병렬성을 효율적으로 사용할 수 있다.
- The autoregressive generation phase
Autoregressive generation phase는 남은 새로운 토큰들을 순차적으로 생성한다. t번째 반복에서는 모델이 토큰 하나를 input으로 받고, key 벡터들 와 value 벡터들 를 가지고 확률 를 계산한다. 1에서 n+t-1까지 위치의 key, value 벡터들은 이전의 반복들에 캐싱되어있고, 오직 새로운 key, value 벡터 만 이번 반복에서 계산된다. 이 phase는 sequence가 최대 길이(사용자에 의해 특정되거나 혹은 LLM에 의해 제한된)에 도달하거나 end-of-sequence(<eos>)가 나왔을 때 완성된다. 다른 반복들(different iterations)에서의 계산은 데이터 의존성 때문에 병렬화 될 수 없고, 종종 덜 효율적인 matrix-vector 곱셉을 사용한다. 결과적으로 이 단계는 GPU 연산을 심각하게 활용하지 못하고 memory-bound가 되어, 단일 요청의 지연 시간 대부분을 담당한다.
2.3 Batching Techniques for LLMs
다수의 요청을 일괄 처리하여(batching multiple requests) serving LLM의 계산 활용도를 향상시킬 수 있다. 요청들이 같은 모델의 가중치를 공유하기 때문에, 가중치 이동 오버헤드는 하나의 배치 안의 요청들 간에 일괄적으로 상각되고, 배치 사이즈가 충분히 클 때는 계산 오버헤드에 의해 압도될 수 있다.
계산 오버헤드에 대한 설명
가중치 이동 오버헤드는 메모리에서 모델의 가중치를 불러올 때 생기는 오버헤드이다. 배치 안에서는 같은 가중치를 이용하니까, 한 번 가중치를 가져오면 배치 안의 모든 요청에 대해 가중치를 공유하여 계산할 수 있고, 이는 가중치 이동 오버헤드를 줄일 수 있다.(배치에 1개의 데이터만있고 배치가 10개 있다면 가중치 이동 오버헤드가 10번 발생하지만, 배치에 10개의 데이터가 있고 배치가 1개라면 가중치 이동 오버헤드가 1번 발생하기 때문이다) 또한 배치 안에서의 계산이 커지면 이는 한 없이 작은 부분이 될 수 있다는 것을 의미하는 것 같다.
그러나 LLM 서비스의 요청들을 일괄 처리하는 것은 2가지 이유 때문에 중요하지 않다.
- 요청들이 다른 시간에 도착할 수 있다.
단순한 배치 전략은 나중에 도착하는 것을 위해 일찍 온 요청을 대기시키거나 일찍 온 요청이 끝날 때까지 수신 요청을 지연시킨다. 이는 상당한 대기열 지연을 발생시킬 수 있다.
- 요청들의 입력과 출력 길이가 매우 다를 수 있다.(Fig 11)
간단한 배치 기술은 길이를 맞추기 위해서 요청의 입력과 출력에 패딩처리를 하는데, 이는 GPU 계산과 메모리 낭비다.
이 문제를 해결하기 위해서, cellular batching과 iteration-level scheduling과 같은 fine-grained batching 메커니즘이 제안되었다. Request level에서 작동되었던 기존의 방법들과 달리, 이러한 기술들은 iteration level에서 작동한다. 각 반복 후에 완료된 요청들은 배치에서 제거되고, 새로운 요청들이 추가된다 → 새로운 요청들은 하나의 반복을 기다린 후에 진행될 수 있다(하나의 반복 후에 요청이 빠져 자리가 날 수 있으니까). 게다가 특별한 GPU kernels을 이용하면, 이러한 기술들은 입/출력의 패딩 처리에 대한 필요성을 없앤다. 대기열 지연을 줄이고 패딩 처리의 비효율성을 줄임으로써, fine-grained batching 메커니즘은 LLM serving의 처리량을 상당히 증가시킨다.
3. Memory Challenges in LLM Serving
Fine-grained batching이 계산의 낭비를 줄이고, 요청이 더 유연한 방법으로 배치되게 해주지만, 아직 memory-bound이다. 이러한 memory-bound를 극복하기 위해서는 메모리 관리에서 다음과 같은 과제들을 해결해야 한다 :
Large KV cache
KV cache 크기는 요청의 수에 따라 빠르게 증가한다. 예를 들어 13B OPT 모델 같은 경우, 하나의 토큰의 KV cache는 2 (key, value vectors) x 5120 (hidden state size) x 40 (layers 수) x 2 (bytes per FP16)로 계산되어, 800KB 공간을 요구한다. OPT가 2048개의 토큰까지 시퀀스를 생성할 수 있기 때문에, 하나의 요청의 KV cache를 저장하기에 필요한 메모리는 최대 1.6 GB 정도가 될 수 있다. Cocurrent GPU들은 수십 GB의 메모리 용량을 갖는다. 모든 이용 가능한 메모리가 KV cache에 할당된다고 하더라도, 오직 몇 십개의 요청들만 수용될 수 있을 것이다. 게다가 비효율적인 메모리 관리는 더욱 배치 사이즈를 줄일 수 있다 (Fig. 2). 추가적으로 현재 트렌드를 볼 때, GPU의 계산 속도가 메모리 용량보다 더욱 빠르게 증가하고 있다.
예) NVIDA A100부터 H100까지, FLOPS는 2배 넘게 증가했지만, GPU 메모리는 최대 80GB를 유지한다.
따라서 메모리가 점점 더 큰 병목 현상이 될 것이라고 생각한다(논문의 생각).
Complex decoding algorithms
LLM 서비스는 사용자가 선택할 수 있는 다양한 디코딩 알고리즘을 제공하며, 각각은 메모리 관리 복잡성에 대한 다양한 의미를 갖는다. 예를 들어 사용자가 프로그램 제안에서 일반적인 사용 사례인 하나의 입력 프롬프트로부터 다수의 랜덤 샘플들을 요청할 때, 우리의 실험에서 총 KV 캐시 메모리의 12%를 차지하는 프롬프트 부분의 KV cache는 메모리 사용을 최소화하기 위해 공유될 수 있다. 반대로 Autoregressive generation 단계 동안 KV cache는 다른 샘플 결과와 context, 위치 의존성 때문에 공유되지 않은 채로 남아있어야 한다. KV cache 공유의 범위는 이용된 특정 디코딩 알고리즘에 달려있다. Beam search와 같은 더욱 정교한 알고리즘에서는 다른 요청 beam은 KV cache의 더 많은 부분(최대 55% 메모리 절약)을 공유할 수 있고, 디코딩 절차가 진보함에 따라 공유 패턴이 진화한다.
Scheduling for unknown input & output lengths.
LLM 서비스에 대한 요청의 입/출력 길이는 다양하고, 광범위한 프롬프트 길이를 수용하기 위해 메모리 관리 시스템이 필요하다. 게다가 디코딩을 할 때 요청의 출력 길이가 증가함에 따라, KV cache에 필요한 메모리 또한 증가하고, 수신 요청 또는 기존 프롬프트의 진행 중인 생성을 위한 이용 가능한 메모리가 소진될 수 있다. 시스템은 GPU 메모리에서 몇몇 요청의 KV cache를 지우거나 스왑하는 것과 같이 스케줄링 결정을 해야한다.
3.1 Memory Management in Existing Systems
이전의 LLM serving system들 또한 하나의 요청에 대한 KV cache를 다른 위치에 걸쳐 연속적인 tensor로써 저장한다. LLM의 예측 불가능한 출력 길이 때문에 이전의 LLM serving system은 실제 입력이나 요청의 최종적인 출력에 관계 없이 요청의 가능한 최대 시퀀스 길이에 기반하여 요청을 위한 메모리의 chunk를 정적으로 할당한다.

Fig. 3 ⇒ 요청 A(가능한 최대 시퀀스 길이 2048) & 요청 B (가능한 최대 시퀀스 길이 512)
Chunk pre-allocation scheme은 3가지 주요 메모리 낭비 원인이 있다:
- Reserved slots for future tokens (미래 토큰을 위한 예약된 슬롯)
- Internal fragmentation due to over-provisioning for potential maximum sequence lengths (잠재적 최대 시퀀스 길이를 위한 초과 제공으로 인한 internal fragmentation) → 최대 길이만큼 일단 할당해놓는 거니까, 사용되지 않는 슬롯들에 대한 낭비가 발생
- External fragmentation from the memory allocator like buddy allocator (메모리 할당자로부터의 external fragmentation) → 요청 사이에 발생하는 낭비
External fragmentation은 생성되는 토큰들을 위해 절대 사용되지 않을 것이며, 이는 요청을 처리하기 전에 이미 알고 있다. Internal fragmentation도 사용되지 않지만, 이는 요청이 샘플링을 마친 후에야 인지할 수 있다. ( ⇒ 즉, External fragmentation은 요청들 사이에 공간이니까, 하나의 요청을 처리하기 전에도 알 수 있지만, Internal fragmentation은 최대 길이만큼 over-provisioning 해놓은 것이니까 끝날 때까지 사용하는지 안 하는지 알 수가 없다.)
결국 예약된 메모리가 사용되지만, 특히 예약된 공간이 큰 경우, 전체 요청 기간 동안 이 공간을 예약하는 것은 다른 요청들을 처리하는데 사용될 공간을 차지한다. ( ⇒ 예약했다가 안쓰고 요청이 끝나면 안썼던 공간이라고 인지되어 결국 다른 요청에 쓰일 수 있지만, ‘해당 요청의 진행 기간 동안’에는 다른 요청에 쓰일 수 있는 공간을 차지하게 된다.)
Fig. 2의 실험에서 메모리 낭비의 평균 비율을 시각화하여, 이전 시스템에서의 실제 효율적인 메모리는 20.4%까지 낮을 수 있음을 보여준다.
Compaction은 framentation의 잠재적인 해결책이라고 제안되고 있지만, 큰 KV cache 때문에 성능에 민감한 LLM serving system에서 compaction을 수행하는 것은 비현실적이다. Compaction이 있더라도 각 요청에 대한 pre-allocated chunk space는 기존 메모리 관리 시스템에서의 디코딩 알고리즘에 특화된 메모리 공유를 막는다. [여기서 compaction : “Pacman: An Efficient Compaction Approach for {Log- Structured}{Key-Value} Store on Persistent Memory”]
4. Method

본 논문에서는 section 3의 문제들을 해결하기 위해 ⇒ “PagedAttention & vLLM”
vLLM의 구조는 Fig. 4을 통해 확인할 수 있고, vLLM은 분산된 GPU 작업자들의 실행을 조정하기 위해 중앙 집중식 스케줄러를 채택한다.
KV cache manager은 PagedAttention이 가능하게 해준 paged 방식으로 KV cache를 효과적으로 관리한다. 구체적으로 KV cache manager는 중앙 집중식 스케줄러가 보낸 instructions을 통해 GPU 작업자들에 있는 물리적 KV cache memory를 관리한다.
- § 4.1 : PagedAttention 알고리즘
- § 4.2 : Design of the KV cache manager
- § 4.3 : PagedAttention을 용이하게 하는 방법
- § 4.4 : 이러한 디자인이 다양한 디코딩 방법에 대한 효과적인 메모리 관리를 용이하게 하는 방법
- § 4.5 : 다양한 길이의 입력과 출력 시퀀스를 다루는 방법
- § 4.6 : 분산된 세팅에서 vLLM의 시스템 설계가 작동하는 방법
4.1 PagedAttention
PagedAttention은 연속적이지 않은 메모리 공간에서 강한 연속적인 key, value를 저장할 수 있다. 구체적으로 PagedAttention은 각 시퀀스의 KV cache를 KV blocks으로 나눈다. 각 블록은 고정된 수의 토큰들에 대한 key, value vectors를 포함한다. 여기서 고정된 수는 KV block size ()라고 표시한다.
Key block과 Value block은 다음과 같이 표시한다:
그리고 Attention 계산도 아래와 같이 block-wise 계산으로 바뀐다: (Eq 4)
여기서 는 j번째 KV block의 attention score의 row vector 이다.

Attention 계산 동안, PagedAttention kernel은 서로 다른 KV blocks를 개별적으로 식별하고, 가져온다.
Fig. 5에서 PagedAttention의 예시를 볼 수 있다: key, value vector들이 세 개의 블록들로 뿌려지고, 세 개의 블록들은 물리적인 메모리에서 연속적이지 않다. 각각의 시간에서, 커널은 attention score 를 계산하기 위해 query token “forth”의 query vector 를 블록 안의 key vectors 에 곱해준다. 그 다음 를 블록 안의 value vectors 에 곱해주며 최종 attention output 를 구한다.
요약하면, PagedAttention 알고리즘은 KV blocks을 비연속적인 물리적 메모리에 저장할 수 있게 해주고, 이는 vLLM에서 더 유연한 paged 메모리 관리를 가능하게 해준다.
4.2 KV Cache Manager
vLLM의 메모리 manager의 핵심 아이디어는 운영 체제의 가상 메모리와 유사하다.
< 운영 체제의 가상 메모리 : 메모리를 고정된 크기의 pages로 나누고, 사용자 프로그램의 logical pages를 물리적 pages에 맵핑한다. >
연속적인 logical pages는 연속적이지 않은 물리적 메모리 page에 맵핑될 수 있어서, 사용자의 프로그램들이 연속적인 것처럼 메모리에 엑세스할 수 있다. 게다가 물리적 메모리 공간이 사전에 fully reserved 될 필요가 없으면, OS가 필요함에 따라 동적으로 물리적 pages를 할당할 수 있다. vLLM은 가상 메모리 배후에 있는 아이디어를 이용해서 LLM service의 KV cache를 관리한다. PagedAttention을 통해 가상 메모리에서의 pages와 같이 고정된 크기의 KV blocks으로써 KV cache를 구성한다.
요청 한 개의 KV cache는 logical KV blocks의 시리즈로 표현된다. 이는 새로운 토큰이나 KV cache가 생성됨에 따라 왼쪽에서부터 오른쪽으로 채워진다. 마지막 KV 블록의 채워지지 않은 위치는 미래의 생성을 위해 예약된다. GPU 작업자들에서 block engine은 GPU DRAM의 연속적인 chunk(chunk? 작은 부분을 의미. GPU의 작은 부분이라고 생각하면 될 듯)를 할당하고, 이를 물리적 KV 블록들로 나눈다(swapping을 위해 이는 CPU RAM에서도 수행된다). KV 블록 manager는 또한 블록 테이블을 유지한다. 블록 테이블은 각 요청의 logical KV 블록들과 물리적 KV 블록들을 매핑해놓은 것이다. 각 블록 테이블 entry는 logical 블록에 맵핑되는 물리적 블록들과 채워진 위치의 수를 기록한다.
Logical & 물리적 KV 블록들을 분리하는 것은 미리 모든 위치를 reserved 하지 않음으로써, KV cache 메모리가 동적으로 커질 수 있게 해준다. 이는 기존의 방법에서 만들어지는 대부분의 메모리 낭비를 없애준다. (Fig. 2)
→ Logical & physical KV blocks을 분리하는 것은 KV cache 메모리를 동적으로 쌓을 수 있게 해준다. 그래서 기존의 시스템에서 발생하는 대부분의 메모리 낭비를 없앨 수 있다. (기존 시스템에서 대부분의 메모리 낭비는 사전에 모든 포지션을 reserved 해서 발생하기 때문에)
4.3 Decoding with PagedAttention and vLLM

Fig. 6의 예시를 통해, vLLM이 PagedAttention을 어떻게 실행하고, 하나의 입력 시퀀스의 디코딩 절차 동안 메모리를 어떻게 관리하는지를 설명한다:
-
vLLM은 초기에 가능한 최대 생성 시퀀스 길이에 대한 메모리를 예약할 필요가 없다.
대신에 프롬프트 계산 중 생성되는 KV cache를 수용하기 위해 필요한 KV 블록들만 예약하면 된다. Fig. 6의 예시와 같은 경우, 프롬프트는 7개의 토큰을 가지고 있고, 첫 2개의 logical KV 블록들(0 & 1)을 2개의 물리적 KV 블록들(7 & 1, 각각)에 매핑한다. Prefill 단계에서, vLLM은 일반적인 self-attention 알고리즘을 이용해 프롬프트와 첫 번째 출력 토큰의 KV cache를 생성한다(e.g. flashattention). 그 후, vLLM은 첫 번째 4개 토큰의 KV cache를 logical block 0에 저장하고, 그 다음 3개 토큰의 KV cache를 logical block 1에 저장한다. 남아있는 슬롯은 그 후의 자기 회귀적인 생성 단계를 위해 예약되어 있다. (’fathers’ 부분)
-
첫 번째 자기 회귀적인 디코딩 단계에서 vLLM은 물리적 블록 7 & 1에서 PagedAttention 알고리즘을 이용해 새로운 토큰을 생성한다. 마지막 logical 블록의 하나의 슬롯은 이용 가능하게 남아있기에, 새롭게 생성되는 KV cache는 거기에 저장되고, 블록 테이블의 #filled record(Fig. 6을 보면 이해할 수 있듯이, 해당 블록이 얼마나 채워져 있는지를 나타내냄!)는 업데이트 된다.
( → “fathers” 부분이 처음엔 비워져 있었기에, ‘fathers’가 생성되면 KV cache는 거기에 저장되고 해당 블록(block 1)의 경우 4개가 채워졌으니, #filled를 4로 바꿔준다. )
-
두 번째 디코딩 단계에서 마지막 logical 블록이 꽉 찼기에, vLLM은 새로운 logical 블록에 새롭게 생성된 KV cache를 저장한다; vLLM은 이를 위해 새로운 물리적 블록(물리적 블록 3)을 할당하고, 이러한 매핑을 블록 테이블에 저장한다.
전체적으로 각 디코딩 iteration에 대해, vLLM은 먼저 배치(일괄 처리)를 위한 후보 시퀀스들의 집합을 선택하고(더 많은 정보는 섹션 4.5에서), 새롭게 필요한 logical 블록들에 대해 물리적인 블록들을 할당한다. 그 다음, 현재 iteration의 모든 입력 토큰들(프롬프트 단계 요청들의 모든 토큰들 + 생성 단계 요청의 가장 최근의 토큰들)을 하나의 시퀀스로 합치고(concatenate), LLM에 넣어준다. LLM 계산 중에, vLLM은 logical KV 블록의 형태로 저장되어 있는 이전 KV cache에 접근하기 위해 PagedAttention kernel을 이용하고, 새롭게 생성되는 KV cache를 물리적인 KV 블록들에 저장한다. 하나의 KV 블록을 사용해 다수의 토큰들을 저장하는 것(block size > 1)은 PagedAttention이 KV cache를 모든 위치에 병렬적으로 처리할 수 있게 해주어, 하드웨어 활용률을 높이고 latency를 줄여주었다(위치별로 계산을 하니까, 위치별로 workers들이 붙어서 계산을 하여 병렬적으로 처리하는 듯하다). 그러나 큰 블록 사이즈 또한 메모리 fragmentation을 증가시킨다.

다시, vLLM은 더 많은 토큰들과 그들의 KV cache가 생성됨에 따라 새로운 물리적 블록들을 logical 블록들에 동적으로 할당한다. 모든 블록이 왼쪽에서부터 오른쪽으로 채워지고 모든 이전의 블록이 꽉 차야만 새로운 물리적 블록이 할당되기에, vLLM은 하나의 요청에 대한 메모리 낭비를 한 블록으로 제한할 수 있다. 그래서 Fig.2 에서 보여지는 것과 같이 모든 메모리를 효율적으로 활용할 수 있다. 이를 통해, 배치를 위해 더 많은 요청들을 메모리에 넣어줄 수 있으므로 처리량이 향상된다. 하나의 요청이 생성을 멈추면, 해당 KV 블록은 다른 요청들의 KV cache를 저장할 수 있게 된다. Fig 7을 통해, vLLM의 두 시퀀스에 대한 메모리 관리 예시를 볼 수 있다. GPU 작업자들의 블록 엔진에 의해 예약된 공간 내에서 두 시퀀스의 logical 블록들을 다른 물리적 블록들에 매핑된다. 두 시퀀스의 이웃 logical 블록들은 물리적 GPU 메모리에서 연속적일 필요가 없고, 물리적 블록들의 공간은 두 시퀀스에 의해 효과적으로 활용될 수 있다.
4.4 Application to Other Decoding Scenarios
4.3은 PagedAttention과 vLLM이 어떻게 기본적인 디코딩 알고리즘을 사용하는지를 보여주었다. (하나의 사용자 프롬프트를 입력으로 받고 하나의 출력 시퀀스를 생성하는 Greedy 디코딩 & sampling과 같은) LLM 서비스는 더 복잡한 디코딩 시나리오와 메모리 공유를 위한 더 많은 기회를 제공해야한다.
이번 섹션에서는 vLLM의 일반적인 적용 가능성을 보여준다.
Parallel sampling
LLM 기반 프로그램 어시스턴트들에서 LLM은 하나의 입력 프롬프트에 대해 다수의 샘플링된 출력을 생성한다; 사용자는 다양한 후보들로부터 가장 선호하는 출력을 고를 수 있다. 그래서 우리는 내재적으로 하나의 요청이 하나의 시퀀스를 생성한다고 가정해왔다. 논문의 남은 부분에서는 하나의 요청이 다수의 시퀀스들을 생성하는 더 일반적인 상황을 가정한다.
Parallel sampling에서 하나의 요청은 같은 입력 프롬프트를 공유하는 다수의 샘플들을 포함하여, 프롬프트의 KV cache 또한 공유될 수 있게 한다. PagedAttention과 paged 메모리 관리를 통해, vLLM은 이러한 공유를 쉽게 실현할 수 있고 메모리를 아낄 수 있다.

Fig. 8은 2개의 출력에 대한 parallel 디코딩의 예시를 보여준다. 두 출력들이 같은 프롬프트를 공유하기에, 프롬프트 단계에서 프롬프트 상태의 하나의 복사본을 위한 공간만 예약하면 된다; 두 시퀀스들의 프롬프트에 대한 logical 블록들은 같은 물리적 블록들에 매핑된다: 두 시퀀스들의 logical block 0, 1은 각각 물리적 블록 7, 1에 맵핑된다. 하나의 물리적 블록이 다수의 logical 블록들에 맵핑될 수 있으니, 각 물리적 블록에 대한 reference count를 제안한다.
Reference count란?
하나의 해당 물리적 블록이 몇 개의 logical 블록에 맵핑되어 있는지
이 경우, 물리적 블록 7과 1의 reference count는 2이다. 생성 단계에서 두 출력들은 서로 다른 출력 토큰을 샘플링하고, KV cache를 위해 분리된 저장 공간이 필요하다.
즉, 2개의 생성이 다른 경우가 있는데, 이를 물리적 KV 블록에 저장해야하기에 가장 마지막 물리적 블록은 분리가 되어야한다. 위에서는 ‘mother’, ‘father’ 로 서로 다른 output token이 나온 것이다.
여기서 운영체제 가상 메모리의 copy-on-write 기술과 유사한 copy-on-write 메커니즘을 구현한다.
구체적으로 Fig. 8을 보면, sample A1은 마지막 logical 블록에 적어야하는데, 마지막 logical 블록에 해당하는 물리적 블록(여기서는 물리적 블록 1)의 reference count가 1보다 큰 것(현재 물리적 블록 1의 reference count=2)을 vLLM이 알아차린다. 그러면 새로운 물리적 블록(여기서는 물리적 블록 3)을 할당하여, block engine에게 기존의 블록 정보를 복사하라고 지시한다. 그리고 기존 블록(여기서는 물리적 블록 1)의 reference count를 1 낮춘다. 그리고 sample A2가 물리적 블록 1에 작성을 할 때, 물리적 블록 1의 reference count가 1이므로, 새롭게 생성된 KV cache를 물리적 블록 1에 직접적으로 작성한다.
요약하면 vLLM은 프롬프트의 KV cache를 저장하기 위해 사용된 대부분의 공간을 공유할 수 있게 해준다. Copy-on-write 메커니즘으로 관리되는 마지막 logical 블록을 제외하고! 다양한 샘플 간에 물리적 블록들을 공유함으로써 메모리 사용량은 매우 줄어들 수 있다. 특히, 긴 입력 프롬프트에 대해서!
프롬프트에 대해서 마지막 물리적 블록은 새로 생성되는 토큰들의 KV cache를 저장해야하기 때문에 공유될 수 없지만, 다른 것들은 공유될 수 있다.
마지막 물리적 블록은 서로 다른 출력이 나오게 되면, 다른 값을 저장해주어야하기 때문에 reference count를 이용해 하나의 물리적 블록이 몇 개의 logical 블록에 참조되고 있는지 확인하고, reference count가 1보다 큰 값을 가지고 있다면 copy-on-write를 이용해 해당 물리적 블록의 정보를 다른 물리적 블록에 복사해서 작성시키고 출력 정보를 이동시킨 블록에 작성한다. 그러면 대응되는 물리적 블록의 정보가 바뀌니까 기존의 물리적 블록의 reference count를 1 낮춘다.
그리고 reference count가 1이라면 어차피 참조하는 logical 블록이 하나라는 것이니까 바로 출력의 KV cache를 작성하면 된다!
Beam Search
기계 번역과 같은 LLM task들에서 LLM으로 부터 사용자는 top-k개의 가장 적절한 번역을 기대한다.
Beam Search란? 모든 샘플 스페이스를 보는 것이 아니라, 매 단계 k개의 가장 좋은 후보들을 결정하는 것이다. 그렇기에 계산 복잡도를 완화시켜줄 수 있다.
여기서 k는 beam width parameter이다. 그래서 𝑘 · |𝑉 | 개의 후보 중에서 top-k의 가장 가능성 있는 시퀀스들을 유지한다. 여기서 |𝑉 |는 Vocabulary size이다.
예시)
k = 4라고 해보자.
1단계) ‘I’ 후에 나올 수 있는 top 4개의 단어는 모든 vocabulary의 확률을 비교해서 4개의 단어를 고르는 것이다.
2단계) 예를 들어 “I” 이후에, ‘am’, ‘do’, ‘sing’, ‘dance’ 라는 4개의 단어가 나온다면, (k=4 이기에, 4개의 단어가 선별된 것)
“I”, “am” 후에 올 수 있는 단어들의 확률들 ⇒ |𝑉 |개
“I”, “do” 후에 올 수 있는 단어들의 확률들 ⇒ |𝑉 |개
“I”, “sing” 후에 올 수 있는 단어들의 확률들 ⇒ |𝑉 |개
“I”, “dance” 후에 올 수 있는 단어들의 확률들 ⇒ |𝑉 |개
최종 ⇒ 4 |𝑉 |개 중에 가장 가능성이 있는(가장 확률이 좋은) 4개를 고른다
3단계) 예를 들자면, “I am a”, “I am playing”, “I do something”, “I sing a” 가 올 수 있다.
그러면 또 “I am a”, “I am playing”, “I do something”, “I sing a” 각각 뒤에 올 수 있는 단어들을 비교해 해당 시퀀스의 확률을 계산한다.
또 4 |𝑉 |개의 비교군이 생기고, 이 비교군에서 가장 확률이 좋은 4개를 고른다.
이렇게 계속 진행!
그렇기에 𝑘 · |𝑉 | 개의 후보 중에서 top-k의 가장 가능성 있는 시퀀스를 유지한다는 것!

Parallel decoding과 달리, beam search는 처음의 프롬프트 블록들 공유 뿐만 아니라 다른 후보들 간에 다른 블록들도 공유한다. 운영체제에서 Compound forks에 의해 생성된 process tree와 유사하게 공유 패턴은 디코딩 절차가 진행됨에 따라 동적으로 바뀐다. Fig. 9는 vLLM이 k=4인 beam search에 대한 KV 블록들을 어떻게 관리하는지 보여준다. 점선으로 나뉘어진 곳 전에를 봐보자(Block 5,6,7,8). 해당 시점에서 Block 8을 포함하고 있는 후보 3같은 경우에는 다른 후보들과 block 0(즉, 프롬프트)을 공유하지만, 2번째 블록부터 달라졌다(후보 3은 block 2를 이용하지만, 다른 후보들은 block 1을 이용). 후보 0-2는 3개의 블록을 공유하고, 4번째 블록에서 나뉘어졌다. 그 후의 iteration을 보면(점선 뒤의 iteration), 점선 전의 후보 0, 3은 더 이상 top 후보에 들지 못함에 따라 logical 블록들이 자유로워졌고, 해당 물리적 블록의 reference count은 줄여진다. vLLM은 reference count가 0이 된 모든 물리적 블록들(blocks 2,4,5,8)을 자유롭게 해준다. 그 다음, vLLM은 새로운 후보들로부터의 새로운 KV cache를 저장하기 위해 새로운 물리적 블록들(blocks 9-12)을 할당한다. 현 시점에서는 모든 후보들이 block 0, 1, 3을 공유한다; 후보 0, 1은 block 6을 공유하고, 후보 2, 3은 block 7을 공유한다.
점선 전까지는 4개의 후보가 0-1-3-5, 0-1-3-6, 0-1-3-7, 0-2-4-8 이고, 점선 후에는 4개의 후보가 0-1-3-6-9, 0-1-3-6-10, 0-1-3-7-11, 0-1-3-7-12 이 된다. 이에 점선 전까지 이용되었던 block 2,4,8,5는 free하게 되고, 새로운 KV cache를 저장하기 위해 block 9-12가 할당된다.
이전의 LLM serving 시스템은 beam 후보들 간에 KV cache의 빈번한 메모리 복사본들이 필요했다. Fig. 9 상황을 예를 들어보면, 점선 후에 후보 3은 생성을 이어나가기 위해 후보 2의 KV cache의 많은 부분을 복사해야 했다(copy-on-write를 이용하면, reference count가 2니까 이전까지의 정보를 복사해서 다른 물리적 블록에 작성해줘야하니까). 이러한 빈번한 메모리 복사 overhead는 vLLM의 물리적 블록 공유에 의해 상당히 줄어들었다. vLLM에서 다른 beam 후보들의 대부분의 블록들은 공유될 수 있다(위의 점선 후에 시점을 보면 block 0-3을 모든 후보가 공유하고 있음을 볼 수 있음). Copy-on-write 메커니즘은 parallel 디코딩에서와 같이 새로 생성된 토큰이 이전의 공유된 블록 내에 있을 때만 적용된다.
(→ 이용 가능한 슬롯(공간)이 남아있는 같은 블록에서 2개의 출력이 나온다면 해당 블록을 copy-on-write 하겠지만, 지금과 같은 경우 같은 블록에 2개의 출력을 적어주는 것이 아닌 다른 2개의 블록을 할당해 적어주는 것이므로 copy-on-write를 할 필요가 없다. 이전의 블록들을 공유하면 되므로 굳이 복사해서 쓸 필요가 없는 것이다.)
Copy-on-write는 오직 데이터의 블록 하나를 복사하는 것을 포함한다.
Shared Prefix

흔히 LLM 사용자들은 system prompt라고도 알려진, instruction과 입/출력의 예시를 포함한 (긴) task의 설명을 제공한다. 요청의 프롬프트를 형성하기 위해 설명과 실제 task 입력을 합친다(conatenate). LLM은 full prompt에 기반해 출력을 생성한다. Fig. 10는 예시를 보여준다. Shared prefix는 downstream task의 정확성을 향상시키기 위해 프롬프트 엔지니어링을 통해 더 조절될 수 있다.
이러한 타입의 어플리케이션에서 많은 사용자의 프롬프트들은 prefix를 공유하므로, LLM 서비스 제공자는 prefix에 쓰이는 중복 계산을 줄이기 위해 사전에 prefix의 KV cache를 저장할 수 있다. 이는 vLLM에서는 운영체제가 프로세스 간에 공유 라이브러리를 처리하는 방식처럼 LLM 서비스 공급자가 미리 정의한 shared prefix의 집합에 대한 물리적 블록들의 집합을 예약함으로써 편리하게 달성할 수 있다. Shared prefix를 이용한 사용자의 입력 프롬프트는 입력 프롬프트의 logical 블록들을 캐싱된 물리적 블록들(마지막 블록은 copy-on-write로 표시됨)로 매핑할 수 있다. 프롬프트 단계의 계산은 오직 사용자의 task 입력에 대해서만 실행하면 된다.
⇒ 즉, shared prefix의 KV cache를 물리적 블록에 캐싱해놓은 것에 입력 프롬프트의 logical 블록들로 매핑하면 된다. 그럼 중복 계산을 피하고, 이미 캐싱된 정보를 이용할 수 있고, prompt 계산 시에는 task input만 계산하면 된다.
Mixed decoding methods
앞서 설명한 디코딩 방법들은 다양한 메모리 공유 및 액세스 패턴을 보여줍니다. 그럼에도 불구하고 vLLM은 기존 시스템에서는 효율적으로 수행할 수 없는, 디코딩 선호도가 다른 요청을 동시에 처리할 수 있도록 지원합니다. vLLM은 logical 블록을 물리적 블록으로 변환하는 공통 매핑 layer을 통해 서로 다른 시퀀스 간의 복잡한 메모리 공유를 숨기기 때문입니다. LLM과 그 실행 커널은 각 시퀀스에 대한 물리 블록 ID 목록만 볼 수 있을 뿐 시퀀스 간의 공유 패턴을 처리할 필요가 없습니다. 이 방법은 기존 시스템과 비교하여 다른 샘플링 요구사항을 가진 요청들을 배치처리해주는 기회를 넓히며, 시스템의 전체 처리량을 증가시킨다.
→ 공통 매핑 layer을 이용해서 복잡한 메모리 공유를 숨겨주어, LLM과 실행 kernel은 시퀀스 간의 공유 패턴을 처리할 필요가 없게 해준다. 서로에 대한 공유 패턴을 처리할 필요가 없으니, 다른 샘플링 요구사항을 가진 요청들을 배치처리하는 기회를 넓히며, 시스템의 전체 처리량을 증가시킨다.
즉, 다른 시퀀스 간의 복잡한 메모리 공유를 mapping layer(logical blocks → physical blocks)로 숨긴다. 그래서 매핑된 물리적 블록만 처리하면 되지, 복잡한 공유 패턴을 처리할 필요가 없어진다.
4.5 Scheduling and Preemption
요청 트래픽이 시스템 용량을 초과할 때, vLLM은 반드시 요청의 subset의 우선 순위를 정해야한다. vLLM에서 모든 요청들에 대해 first-come-first-serve(FCFS) 스케줄링 정책을 채택하여, 공평함을 보장하고 starvation을 예방했다. vLLM이 요청들을 선점해야할 때, vLLM은 가장 먼저 도착한 요청들을 먼저 처리하고 가장 최근의(가장 나중의) 요청들을 먼저 선점한다.
LLM 서비스들은 독특한 과제에 직면했다:
LLM의 입력 프롬프트는 길이가 매우 다양할 수 있고, 입력 프롬프트와 모델에 따라 결정되는 결과적인 출력 길이는 사전에 알 수 없다. 요청과 요청의 출력 수가 증가함에 따라, vLLM은 새롭게 생성되는 KV cache를 저장하기 위한 GPU의 물리적 블록들이 부족할 수 있다. 이러한 문맥에서 vLLM이 대답해야 하는 두 가지 classic한 질문들이 있다:
(1) 어떤 블록들을 제거해야 하나?
일반적으로 제거 정책은 휴리스틱을 이용해서 어떤 블록이 미래에 가장 나중에 엑세스 될지 예측하고, 그 블록을 제거한다. 우리의 경우 시퀀스에서 모든 블록들이 함께 엑세스되기에, 시퀀스의 모든 블록을 지우거나 하나도 안지우는 all-or-nothing 제거 정책을 구현한다. 게다가 하나의 요청 내의 다수의 시퀀스들(e.g. 하나의 beam search 요청에서의 beam 후보들)은 시퀀스 그룹으로 집단 스케줄링(gang-scheduled)된다. 하나의 시퀀스 그룹 내의 시퀀스들은 시퀀스들 간에 잠재적인 메모리 공유 때문에 항상 같이 선점되거나 리스케줄된다.
(2) 만약 제거된 블록들이 다시 필요하다면, 어떻게 복구해야 하나?
제거된 블록을 어떻게 복구하냐는 질문에 대답을 하기 위해서는 2가지 기술을 고려해야한다:
- Swapping
Swapping은 제거된 pages를 디스크 안의 swap 공간에 복사해놓는 대부분 가상 메모리 구현에서 사용되는 전통적인 기술이다. 우리의 경우, 제거된 블록들을 CPU 메모리에 복사해 놓는다. Fig 4에서 볼 수 있듯이, vLLM은 GPU block allocator 외에 CPU block allocator을 포함해서 CPU RAM으로 스왑된 물리적 블록들을 관리한다. vLLM이 새로운 토큰을 위한 사용 가능한 물리적 블록들을 소진하면, vLLM은 제거하고 KV cache를 CPU로 옮길 시퀀스들의 집합을 선택한다. 시퀀스를 선점하고 그 시퀀스의 블록들이 제거되기 시작하면, vLLM은 모든 선점된 시퀀스들이 완료될 때까지 새로운 요청들을 받아들이는 것을 멈춘다. 그러다 새로운 요청들 중 하나의 요청이 완료되면, 그 요청에 해당하는 블록들은 메모리에서 해제되고, 선점된 시퀀스의 블록들이 그 시퀀스의 절차를 이어나가기 위해 다시 불러와진다.
이러한 설계를 이용하면, CPU RAM으로 스왑된 블록의 수는 절대 GPU RAM의 총 물리적 블록의 수를 초과할 수 없다. 그래서 CPU RAM의 swap 공간은 KV cache를 위해 할당된 GPU 메모리에 의해 bounded 된다.
⇒ 즉, 메모리 부족하면 선점할 시퀀스들을 찾고 CPU로 옮긴다. 그리고 옮겨질 때동안은 새로운 요청들을 accept하지 않는다. 새로운 요청이 들어와서 완료가 되면 새로운 요청의 블록들을 메모리에서 해제하고 선점된 시퀀스 절차를 계속 이어나가기 위해, CPU에 transfered된 선점된 시퀀스의 블록들을 다시 불러온다.
- Recomputation
이러한 경우는 선점된 시퀀스들이 리스케줄될 때 KV cache를 간단히 재계산한다. 디코딩 시 생성되는 토큰들은 새로운 프롬프트로써 원래의 사용자 프롬프트와 연결될 수 있기 때문에, 재계산 latency는 본래의 latency보다 상당히 작을 수 있다 - 모든 위치에서 그들의 KV cache는 한 번의 프롬프트 단계 iteration으로 생성될 수 있다.
Swapping과 recomputation의 성능은 CPU RAM과 GPU 메모리 사이의 bandwidth와 GPU의 계산 능력에 달려있다.
4.6 Distributed Execution
많은 LLM들은 단일 GPU 용량을 초과하는 파라미터 사이즈를 가지고 있다. 그래서 분산된 GPU에 걸쳐 LLM을 나누고, 모델 병렬 방식으로 실행할 필요가 있다. 이는 분산된 메모리를 다룰 수 있는 메모리 매니저을 필요로 한다. vLLM은 Transformer에서 널리 사용되는 Megatron-LM 스타일 텐서 모델 병렬화 전략을 지원함으로써 분산 설정에서 효과적이다. Block-wise matrix multiplication을 수행하기 위해 Linear layer을 분배시켜주고, GPU가 all-reduce 연산을 통해 중간 결과를 지속적으로 동기화하는 SPMD(Single Program Multiple Data) 실행 스케줄을 준수한다. 구체적으로 attention 연산자는 attention head 차원으로 나눠져, 각 SPMD 절차는 multi-head attention에서 attention heads의 subset을 관리한다.
심지어 모델 병렬 실행에서도, 각 모델 shard는 여전히 입력 토큰의 동일한 집합을 처리하기에, 같은 위치에 대한 KV cache가 필요하다는 것을 발견했다(동일한 위치에서 서로 다른 attention heads를 관리하니까 같은 위치에 대한 KV cache가 필요하다). 그래서 vLLM은 Fig. 4에서와 같이 중앙 집중식 스케줄러 내에 단일 KV cache 매니저를 갖추고 있다. 다른 GPU 작업자들은 logical 블록들을 물리적 블록들로 매핑해주는 것 뿐만 아니라 매니저도 공유한다. 이러한 공통된 매핑을 통해 GPU 작업자들은 각 입력 요청에 대해 스케줄러가 제공하는 물리적 블록을 가지고 모델을 실행할 수 있다. 각 GPU 작업자는 동일한 물리적 블록 ID들을 가지고 있다 하더라도 하나의 작업자는 작업자에 대응하는 attention heads에 대한 KV cache 부분만 저장할 수 있다.
각 단계에서 스케줄러는 각 요청에 대한 block table 뿐만 아니라 배치 안의 각 요청에 대한 입력 토큰 ID로 메세지를 준비한다. 그 다음, 스케줄러는 GPU 작업자들에게 이 컨트롤 메세지를 뿌린다. 그 다음, GPU 작업자들은 입력 토큰 ID들을 이용해 모델을 실행하기 시작한다. Attention layer에서 GPU 작업자들은 컨트롤 메세지의 block table에 따라 KV cache를 읽는다. 실행 중, GPU 작업자들은 스케줄러의 조정없이 all-reduce communication primitive를 이용해 중간 결과를 동기화한다. 끝으로 GPU 작업자들은 이번 iteration에서 샘플링된 토큰들을 스케줄러로 다시 보낸다. 요약하면, GPU 작업자들은 각 디코딩 iteration 시작 부분에 단계 입력과 모든 메모리 관리 정보를 수신하기만 하면 되므로, 메모리 관리를 동기화할 필요가 없다.
느낀점
AI 방법론, 튜닝 이런 것들을 공부하다가, Cache와 같은 컴퓨터 구조로 들어가니까 신기했고 어려움을 느꼈다..
보는데 정말 오래 걸린 것 같다.
부족한 점이 너무 많다~.~
