우선적으로 직역을 바탕으로 논문을 리뷰하는 것을 밝힙니다.
Paper : https://arxiv.org/abs/2301.12652
Abstract
REPLUG : Language Model(LM)을 black box로 처리하고, 조정 가능한 retrieval model을 가지고 증강하는 retrieval-augmented language modeling framework. Language models이 retrieved text를 encode 하는 것을 special cross attention mechanisms으로 학습시키는 이전 retrieval-augmented LM과 달리, REPLUG는 간단하게 frozen black-box LM의 input 앞에 retrieved documents를 붙였다. 이러한 간단한 디자인은 어느 기존의 retrieval model과 language model에 쉽게 적용될 수 있다. 게다가 LM이 retrieval model을 감독하는 데 사용될 수 있음을 보여주며, 이는 retrieval model가 LM이 더 나은 예측을 할 수 있도록 도움이 되는 문서를 찾을 수 있게 해준다. 우리의 실험은 조정된 retriever를 가진 REPLUG가 GPT-3(175B)의 성능을 Language modeling에서 6.3% 향상시키고, five-shot MMLU에서 Codex의 성능을 5.1% 향상시키는 것을 증명했다.
1. Introduction
GPT-3와 Codex 같은 Large Language Model(LLM)들은 다양한 언어 문제에서 좋은 성능을 증명했다. 이러한 모델들은 일반적으로 매우 큰 dataset에 대해 학습되고, 그들의 parameters에 상당한 양의 세계 또는 도메인 지식을 함축적으로 저장한다. 그러나 이러한 모델들은 hallucination에 취약하며 훈련 말뭉치에서 흔하게 나타나지 않고 드물게 나타나는 지식을 완전히 표현할 수 없다. 이와 반대로 retrieval 증강 LM은 필요할 때 외부 datastore로부터 지식을 검색할 수 있으므로 hallucination을 줄이고 적용 범위를 늘릴 수 있다. 이전의 retrieval-augmented language models의 접근 방법들은 내부 LM representations에 access가 필요하거나 datastore를 indexing 하는 것이 필요하므로 매우 큰 LM에 적용하기 힘들다. 또한, 많은 best-in-class LLMs 오직 API를 통해서만 접근할 수 있다. 이러한 모델들의 내부 representations는 노출되지 않으며, fine-tuning은 지원되지 않는다.
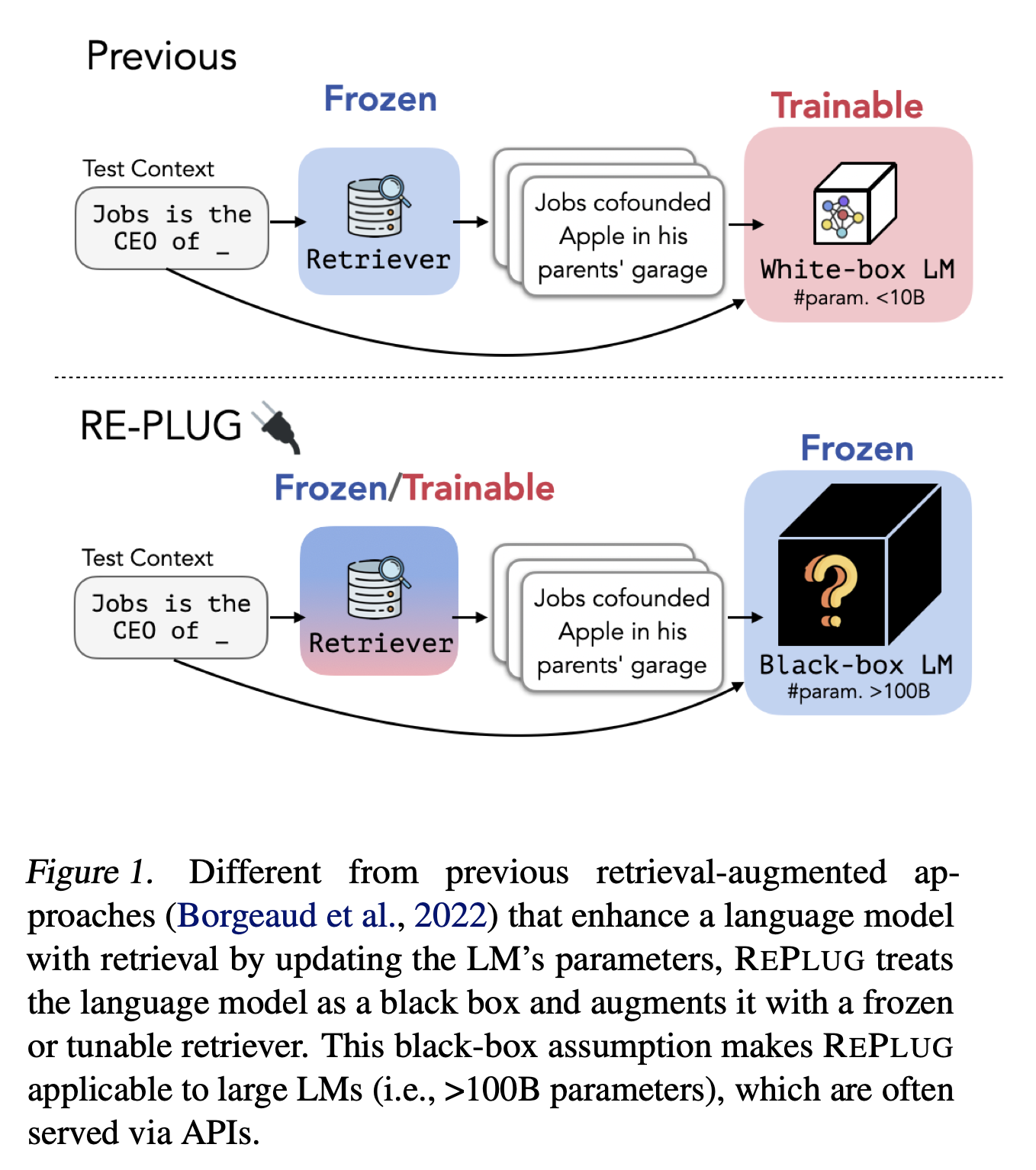
이 논문에서는 새로운 retrieval-augmented LM framework REPLUG(Retrieve and Plug)를 소개한다. REPLUG는 language model을 black box로 보고, 조정가능한 plug-and-play 모듈로써 retrieval component가 더해진다. input context가 주어지면, REPLUG는 먼저 off-the-self retrieval model을 이용해 외부의 말뭉치로부터 연관있는 문서를 retrieve 한다. 검색된 문서들은 input context 앞에 추가되고, 최종 예측을 하기 위해 black-box LM에 입력된다. LM context 길이 제한으로 인해 앞에 붙여질 수 있는 문서의 수가 제한되므로, 동일한 black-box LM과 병렬로 검색된 문서들을 인코딩하는 새로운 앙상블 체계를 소개한다. 이를 통해 정확도 계산을 쉽게 교환할 수 있게 한다. Figure 1에서 보여지듯이, REPLUG는 매우 flexible하고 어느 기존의 black-box LM, retrieval 모델과 함께 사용될 수 있다.
또한 REPLUG LSR(REPLUG with LM-Supervised Retrieval)을 소개한다. 이 훈련 방법은 black-box language model부터의 감독 신호(supervision signals)를 가지고 REPLUG 안의 첫 retrieval model을 더 향상시킨다. 핵심 아이디어는 기존의 Language model을 retreiver에 적응시키는 것과 달리, retriever를 LM에 적응시킨다. LM을 frozen, black-box scoring function으로 취급하면서 Language model perplexity를 향상시키는 문서 검색을 선호하는 훈련 목표를 사용한다.
우리의 실험들은 REPLUG가 MMLU와 open-domain QA를 포함한language modeling과 downstream tasks에서 다양한 black-box LM들의 성능을 향상시켜주는 것을 보인다. 예를 들어, REPLUG는 MMLU에 대해 Codex(175B)의 성능을 4.5% 향상시켜, 540B의 instruction-finetuned Flan-PaLM과 유사한 결과를 얻을 수 있다. 게다가 REPLUG LSR로 조정한 retriever는 language modeling에서 GPT-3 175B의 최대 6.3% 향상을 포함한 추가적인 향상을 이끈다. 우리가 아는 한, 이 논문이 LM의 perplexity를 낮추고 in-context learning 성능을 향상하기 위해 Large LM(>100B model parameters)으로 검색하는 것의 이점을 처음으로 보여준다. 소개할 내용들을 다음과 같이 정리하겠다:
- Retrieval을 가지고 Large black-box language model을 향상시킨 첫 retrieval-augmented language modeling framework : REPLUG
- Language modeling score를 supervision signals로써 이용하여, 기존의 retrieval model을 LM에 적응시키는 training scheme : REPLUG LSR
- Language modeling의 평가들인 open-domain QA와 MMLU는 REPLUG가 175B parameters의 큰 모델을 포함한 GPT, OPT와 BLOOM과 같은 다양한 language models의 성능을 향상시켜줄 수 있음을 증명했다.
2. Background and Related Work
Black-box Language Models
GPT-3, Codex, Yuan 1.0과 같이 100B parameter가 넘는 large language models은 상업적인 측면 때문에 open-sourced가 아니고, user가 queries를 보내고 responses를 받는 black-box API를 통해서만 이용할 수 있다. 반대로, 심지어 OPT-175B와 BLOOM-176B와 같은 open sourced language model도 실행하고, 부분적으로 finetuning하는데 상당한 계산 자원이 필요하다. 예를 들어, BLOOM-176B를 finetuning 하는데 72개의 A100 GPUs (80GB memory, 15k each)가 필요하기에 리소스가 제한된 연구자와 개발자들이 접근할 수 없다. 전통적으로, retrieval-augmented model frameworks는 검색된 문서를 통합하기 위해 language model을 fine-tuning하는 white-box setting에 초점이 맞춰져있었다. 그러나 LLM의 규모와 black-box 특성의 증가는 이러한 접근 방식을 불가능하게 만들었다. LLM으로 부터 제기된 문제들을 해결하기 위해, 사용자가 오직 모델 예측에만 접근 가능하고 parameters에 접근 또는 parameters 수정은 불가능한 black-box setting에서 retrieval-augmentation 을 조사한다.
Retrieval-augmented Models
다양한 지식 창고에서 검색된 관련된 정보를 이용해 LM을 증강하는 것은 language modeling, open-domain QA를 포함한 다양한 NLP tasks에서 성능 향상에 효과적이라는 것을 보였다. 특히, input으로 query를 이용하면, (1) 먼저 retriever가 corpus로부터 문서들의 집합(i.e., sequences of tokens)을 검색하고, (2) 다음 language model은 최종 예측을 만들기 위한 추가적 정보로써 검색된 문서들을 통합한다. 이러한 방식의 retrieval는 encoder-decoder 모델과 decoder-only 모델 모두에 더해질 수 있다. 예를 들어, Atlas는 문서들을 잠재 변수로 modeling 하여 retriever와 encoder-decoder 모델을 공동으로 finetuning 하는 반면, RETRO는 검색된 텍스트를 통합하기 위해 decoder-only 구조를 바꾸고 language model을 처음부터 pretrain(사전교육) 한다. 두 모델 다 black-box LM에는 적용될 수 없는 gradient descent를 통한 모델의 parameter update가 필요하다. kNN-LM과 같은 다른 line의 retrieval-augmented LM들은 tokens의 집합을 검색하고 추론 시 LM의 다음 토큰 분포와 검색된 토큰으로부터 계산된 KNN 분포 사이를 보간한다. kNN-LM은 추가적인 훈련이 필요하지 않아도, kNN 분포를 계산하기 위해 내부 LM representations에 접근은 필요하다. 이러한 access는 GPT-3와 같은 LLMs에게 항상 가능한 것은 아니다. 이 논문에서, retrieval를 가지고 large black-box 언어 모델을 향상시키는 방법을 조사할 것이다. 동시에 작업하고 있는 것에서 frozen retriever를 이용하는 것은 open-domain QA에서 GPT-3의 성능을 향상시킬 수 있다는 것을 증명했지만, 우리는 language modeling과 understanding task을 포함하여 보다 더 일반적인 환경에서 문제에 접근한다. 또한 우리는 더 많은 문서를 통합하기 위한 앙상블 방법과 retriever를 LLM에 더 적응시키기 위한 훈련 방법을 제안한다.
3. REPLUG
언어 모델을 black box로 취급하고 retrieval component를 잠재적으로 조정 가능한 모듈로 추가하는 새로운 retrieval-augmented LM paradigm인 REPLUG를 소개한다.
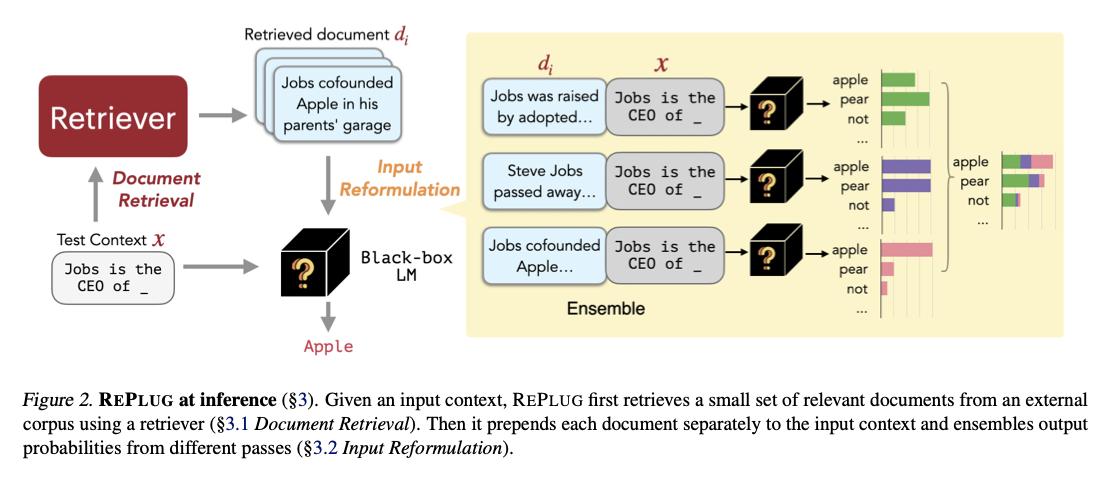
Figure 2에서 보여진 것처럼, input context를 가지고 REPLUG는 먼저 retriever를 이용하여 외부 corpus로부터 관련된 문서의 작은 집합을 검색한다(3.1). 그런 다음 각 검색된 문서와 input context를 concate한 것을 LM을 통해 병렬로(in parallel) 전달하고, 예측된 확률을 앙상블한다(3.2).
3.1. Document Retrieval
Input context 가 주어지면, retriever는 corpus 으로부터 와 관계된 문서들의 작은 집합(small set of documents)을 검색하는 것을 목표로 한다. 이전 작업에 이어, 우리는 input context 와 문서 를 모두 인코딩하기 위해 인코더가 사용되는 dual encoder 구조를 기반으로 한 dense retriever를 이용한다. 구체적으로, 인코더는 의 tokens에 대한 last hidden representation의 mean pooling을 취하면서 각 문서 를 embedding 에 연결시킨다(map). Query time에 query embedding 를 얻기 위해 같은 encoder가 input context 에 적용된다. Query embedding과 문서 embedding의 유사도는 코사인 유사도로 계산된다:
Input 와 비교했을 때 가장 높은 유사도 점수를 가진 top-k개의 문서들이 이번 단계에서 검색된다. 효율적인 retrieval을 위해, 우리는 각 문서 의 embedding을 미리 계산하고, 이 embeddings에 대한 FAISS index를 세운다.
3.2. Input Reformulation
검색된 top-k 개의 문서들은 original input context 에 대해 풍부한 정보를 제공하며, 잠재적으로 LM이 더 나은 예측을 만드는데 도움이 될 수 있다. 검색된 문서를 LM의 input의 일부분으로 통합하는 간단한 방법 중 하나는 모든 k개의 문서를 앞에 붙이는 것이다. 그러나 이 간단한 방법은 언어 모델의 context window size를 고려할 때, 우리가 포함할 수 있는 문서들의 수(즉, k)에 의해 근본적으로 제한된다. 이러한 한계를 해결하기 위해, 다음으로 설명될 앙상블 전략을 채택한다. 는 Eq(1)의 scoring function에 따라 에 가장 연관있는 k개의 문서들을 포함하고 있다고 가정하자. 각 문서 를 앞에 붙이고, 이 합쳐진 것을 LM에 각각 통과시킨다. 그리고 k개의 통과한 것들의 모든 output 확률들을 앙상블한다. 공식적으로, input context 와 그에 가장 관련있는 k개의 문서들 이 주어지면, token 의 output probabilty는 가중 평균 앙상블로 계산된다:
여기서 은 두 sequences의 concatenation을 의미한다.
그리고 가중치 는 문서 와 input context 사이의 유사도 점수를 기반으로 한다:
이 앙상블 방법은 LM을 k번 실행해야하지만, cross attention은 각 검색된 문서와 input context 사이에서 실행된다. 따라서 검색된 모든 문서를 앞에 붙이는 방법과 달리, 이 앙상블 방법은 추가적인 계산 비용 부담이 발생하지 않는다. (개인적인 궁금? -> 모든 문서를 input context 앞에 붙이는 것은 어떤 추가적인 계산 비용이 들까??)
4. REPLUG LSR: Training the Dense Retriever
기존의 neural dense retrieval model들에만 의존하는 대신, 나아가 REPLUG LSR(REPLUG with LM-Supervised Retrieval)을 제안한다. 이는 LM 자체를 이용하여 어떤 문서가 검색되어야 하는지에 대한 감독을 제공하는 REPLUG 안의 retriever를 적응시킨다.
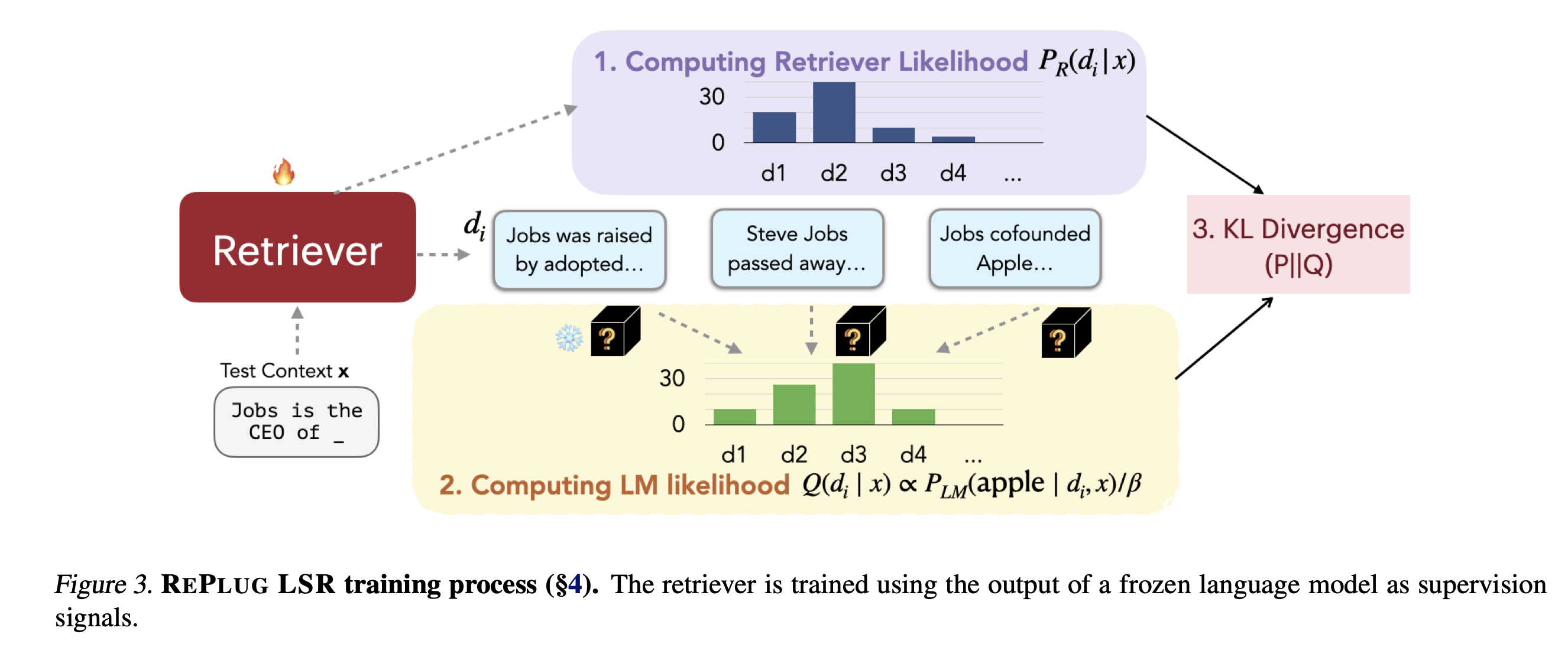
Sanchan et al. (2022)에 영감을 받아, 우리의 접근 방식은 검색된 문서의 확률을 조정하여 언어 모델의 output sequence perplexities의 확률에 맞추는 것으로 볼 수 있다. 다른 말로, 우리는 retriever가 낮은 perplexity score를 초래하는 문서를 찾길 원한다는 것이다. Figure 3에서 볼 수 있듯이, 이 훈련 알고리즘은 4가지 단계가 있다:
(1) 문서를 검색하고 검색 가능성을 계산한다 (4.1)
(2) LM을 이용하여 검색된 문서의 점수를 낸다. (4.2)
(3) 검색 가능성(retrieval likelihood)과 LM의 score distribution 사이의 KL divergence를 최소화하는 방향으로 retrieval model parameter를 업데이트한다. (4.3)
(4) Asynchronous update of datastore index( Datastore index의 비동기 업데이트 ) (4.4)
4.1. Computing Retrieval Likelihood
주어진 input context 로 corpus 에서 유사도 점수가 가장 높은 k개의 문서들 을 검색한다. 그 다음 각 검색된 문서 의 검색 가능성을 계산한다:
여기서 는 softmax의 온도를 조절하는 hyperparameter이다(softmax로 만들어진 확률 분포의 폭을 제어하는 hyperparameter). 이상적으로 검색 가능성은 corpus 의 모든 문서에 대해 marginalizing 함으로써 계산된다. 실제로는 다루기 어렵다.
여기서 marginalizing 이란?
→ 특정 문서의 확률을 계산하기 위해 다른 모든 문서에 대한 확률을 합산하거나 구하는 작업을 의미
그러므로, 우리는 검색된 문서 에 대해서만 marginalizing하여 검색 가능성을 근사한다.
4.2. Computing LM likelihood
얼마나 각 문서가 LM perplexity를 향상시킬 수 있는지 측정하는 scoring function으로 LM을 이용한다. 구체적으로, 처음에 을 계산한다. 이는 주어진 input context 와 문서 에 대한 ground truth output 의 LM 확률이다. 확률이 높을수록, LM의 perplexity를 향상시키는 것 더 좋은 문서 이다. 다음 각 문서 의 LM 가능성을 다음과 같이 계산한다:
여기서 는 또다른 hyperparameter이다.
4.3. Loss Function
주어진 (Input context 와 그에 해당하는 ground truth continuation )로 검색 가능성과 언어 모델 가능성을 계산한다. Dense retriever는 다음 두 분포 사이의 KL divergence를 최소화하는 방향으로 훈련된다:
여기서 는 input context의 집합이다. 손실을 최소화할 때, 검색 모델의 parameters만 업데이트할 수 있다. LM parameters는 black-box 가정 때문에 고정되어있다.
4.4. Asynchronous Update of the Datastore Index
훈련 과정 중에 retriever의 parameter가 업데이트 되기 때문에, 전에 계산된 문서 embeddings은 더 이상 최신 상태가 아니다. 그래서 Guu et al.(2020)을 따라, 문서 embeddings을 다시 계산하고 매 T 훈련 steps마다 새로운 embeddings를 이용하여 효율적인 search index를 다시 짓는다. 그 다음 검색을 위해 새로운 문서 embeddings과 index를 이용하고, training 절차를 반복한다.
5. Training Setup
이 부분에서는 우리의 훈련 절차의 디테일을 설며할 것이다. 먼저 REPLUG의 모델 세팅을 설명하고(5.1), 그 다음 REPLUG LSR에서 retriever 훈련 절차를 설명한다(5.2).
5.1. REPLUG
이론적으로 dense든 sparse든 아무 타입의 retriever은 REPLUG를 위해 사용될 수 있다. 이 전 작업에 따라, Contriever의 좋은 성능이 증명되었기 때문에 우리는 Contriever를 REPLUG의 retrieval model로 이용한다.
5.2. REPLUG LSR
REPLUG LSR에 대해, retriever를 Contriever model로 초기화한다. LM 가능성을 계산하기 위한 감독 LM(supervision LM)으로써 GPT-3 Curie를 이용한다.
Training Data
우리의 훈련 queries로 Pile training data(Gao et al. 2020)로부터 샘플링된 각 sequence마다 256 토큰으로 이루어진, 800K squences를 이용한다. 각 query는 두 파트로 나눠진다 : 처음 128 토큰들은 input context 로써 사용되고, 마지막 128 토큰들은 ground truth continuation 로써 사용된다. 외부 corpus 의 경우, Pile 훈련 데이터로부터 128 토큰의 36M개 문서를 샘플링한다. Trivial retrieval을 피하기 위해서 외부 corpus 문서가 훈련 queries이 sampling된 문서와 겹쳐지지 않도록 한다.
Training details
훈련 절차를 더 효율적으로 만들기 위해서 외부 corpus 의 문서 embedding을 미리 계산하고, 빠른 유사도 검색을 위해 FAISS index를 만든다. 주어진 query 로 FAISS index로부터 상위 20개의 문서를 검색하고, temperature가 0.1로 두고 검색 가능성과 LM 가능성을 계산한다. Learning rate=2e-5, batch_size=64, warmup_ratio=0.1의 Adam optimizer를 이용하여 retriever를 훈련했다. 매 3k steps마다 문서 embeddings를 다시 계산했고, 총 25k steps에서 retriever를 fine-tuning 했다.
Experiment 생략
느낀점
Figure의 그림을 이용하면, REPLUG와 REPLUG LSR의 개념을 이해하기가 용이해질 것으로 보인다.
논문 리뷰 후 느낀점 (2023.11.24)
이 기법은 이해를 했지만, 왜 쓰이는지는 몰랐었다.
스터디원들의 말을 들으니 알게 되었다.
LLM이 훈련이 되면, 다시 훈련시키기 어렵다. 그렇기에 외부 데이터를 retrieval 해와서 그 문서에서 질문에 대한 답을 찾는 것이다. 그렇게 된다면 학습되지 못한 정보도 이용할 수 있을 것이다.
그렇기에 평가 지표도 perplexity를 이용하는 것 같다. 문서에 대한 답이 잘 나오는지 확인하기 위해서!
그리고 내가 느끼기에도 애매했다고 느꼈지만, Output Layer에 대한 정보가 없는 상황에서 (Document1 | query)를 black-box LM에 넣었을 때, output 단어들의 분포를 어떻게 알 수 있는지 모르겠다. 이 분포들을 weighted ensemble을 하는데, output의 점수들을 어떻게 구하는지는 이해하지 못했다.
첫 논문 발표 스터디였는데 논문을 선정한 이유, 논문 내용 말고도 이에 사용된 기법들 등을 알 수 있어서 뜻 깊었다. 많이 부족하다고 느꼈고, 더 열심히 해야겠다!
