본 포스팅은 연세대학교 산업공학과
산업정보관리론의 정리본 + 개인 공부 SQL 정리입니다.
SQL의 이해
데이터베이스란 무엇인가?
데이터베이스는 SQL 관련된 입장에서 보면 구조적인 방식으로 저장된 데이터의 모음이다. 좀 더 쉽게 풀어 말하자면, 구조적인 데이터를 저장하는 컨테이너(파일이나 파일모음)이다.
간혹, DBMS의 개념과 혼동할 수 있는데 DBMS는 데이터베이스 소프트웨어 , 즉 데이터베이스 관리 시스템이며 데이터베이스는 DBMS를 사용하여 만들어지고 제어되는 컨테이너이다.
테이블
테이블은 특정한 방식으로 데이터를 저장할 수 있는 구조적 파일로, 고객 목록, 제목 카탈로그와 같은 특정한 주제에 관한 정보를 담게 된다. 즉 특정한 종류의 데이터를 구조적 목록으로 묶은 것이다.
구조적으로, 테이블에는 한가지 형식의 데이터나 목록이어야 한다. 데이터베이스의 각 테이블에는 이름이 존재하고, 이는 반드시 고유해야한다.
스키마
스키마는 데이터베이스, 테이블 레이아웃 및 속성에 대한 정보이다. 스키마는 데이터베이스 내에서 특정 테이블을 설명할 뿐만 아니라 전체 데이터베이스나 테이블 간의 관계등을 설명하는데에도 사용된다.
열과 데이터 형식
열(row)
열은 테이블 내의 각 필드로, 모든 테이블은 하나 이상의 열로 구성된다. 가령 고객 테이블이라고하면 , 1열에는 이름, 2열에는 번호, 3열에는 이메일 등과 같은 구조이다. 구조적으로 필드를 세분화시켜야 정보 검색에 용이하다.
데이터 형식
데이터 형식은 열이 담을 수 있는 데이터의 종류를 말한다. 하나의 열에는 하나의 데이터 형식으로 제한한다. 이는 올바른 정렬에 도움이 되며, 디스크 사용 방식을 최적화 하는데 일조한다.
행
행은 테이블 내의 레코드이다. 즉, 고객 테이블에서 고객1, 고객2, 고객3 ... 와 같은 형식이다. 테이블의 행의 수는 저장된 레코드의 수와 같다.
기본키 (PRIMARY KEY)
기본키는 테이블 내에서 각 행을 고유하게 구분하는데 사용되는 열이다. 기본 키는 특정한 열을 참조하는 데 사용되며, 기본 키가 없으면 테이블의 특정 열을 업데이트,삭제하기 힘들다. 일의 효율성을 위한 필수적인 요소이다.
- 둘 이상의 행이 같은 기본 키 값을 가질 수 없다.
- 모든 행에는 기본 키 값이 있어야 하며, 기본 키 열에는
null을 할당할 수 없다. - 기본 키 값은 변경이나 업데이트가 불가하다.
- 기본 키 값은 재사용이 불가능하다. 행이 삭제되었다면, 그 기본 키값을 재할당하면 안된다.
SQL이란 무엇인가?
Structured Query Language의 줄임말이다. SQL은 데이터베이스와의 통신을 위해 특별히 고안된 언어이다.
SQL의 장점
-
대부분의 DBMS에서 SQL을 지원하므로 한 언어를 배워 모든 데이터베이스에서 활용할 수 있다.
-
간단하며 이해하기 쉬운 영어 문장과 닮아있고 양이 많지 않다. 활용하여 매우 복잡하고 정교한 데이터베이스 작업을 수행할 수 있다.
데이터 가져오기
SELECT
SQL의 키워드 중 하나로, 가장 많이 사용하게 될 키워드이다. SELECT문은 하나 이상의 테이블에서 정보를 가져온다.
SELECT를 사용하여 데이터를 가져오려면 최소 2가지의 정보를 가져와야 한다. 무엇을 선택할 것이고, 어디서 선택할 것인지이다.
열 가져오기
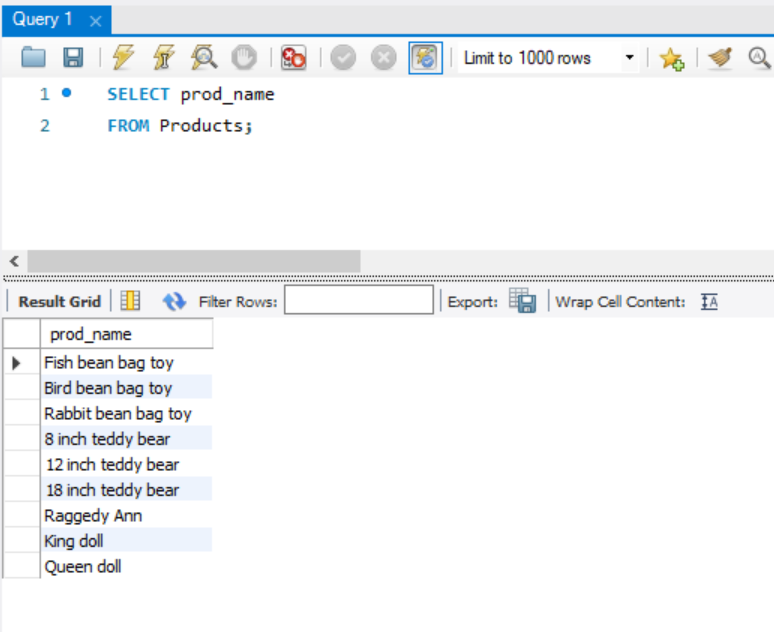
SELECT prod_name
FROM Products;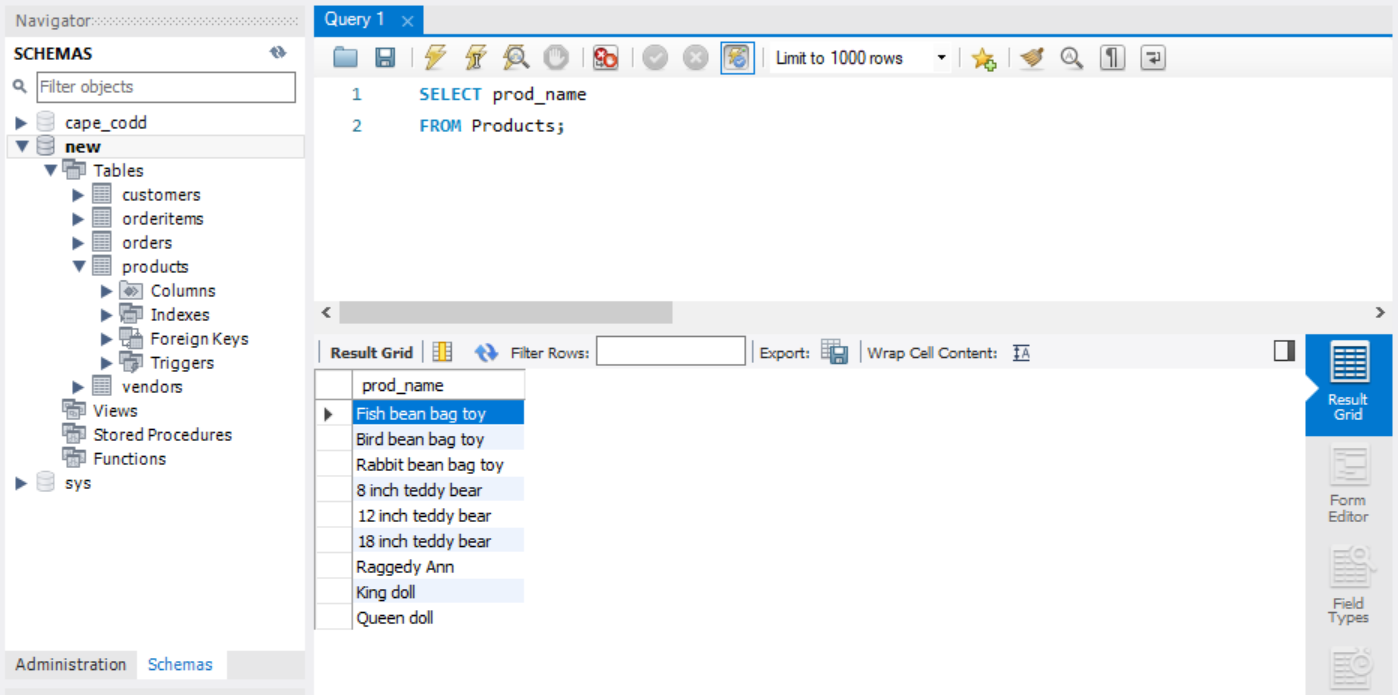
다음과 같은 결과를 얻는다.
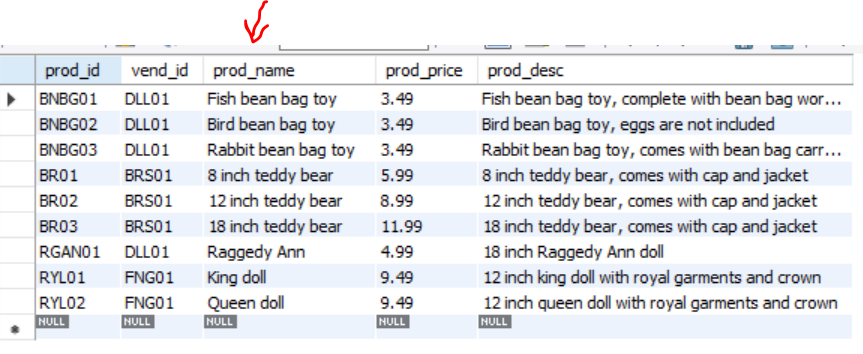
Products 테이블을 열어보면, 어떻게 동작하는지 이해하기 쉽다. SELECT로 필드를 선택하였고, FROM으로 어떤 테이블에서 가져올것인가를 정한다.
여러 열 가져오기
기존의 SELECT 문에서 불러올 열의 이름을 ,로 구분하여 적어주면 된다.
SELECT prod_id, prod_name, prod_price
FROM Products;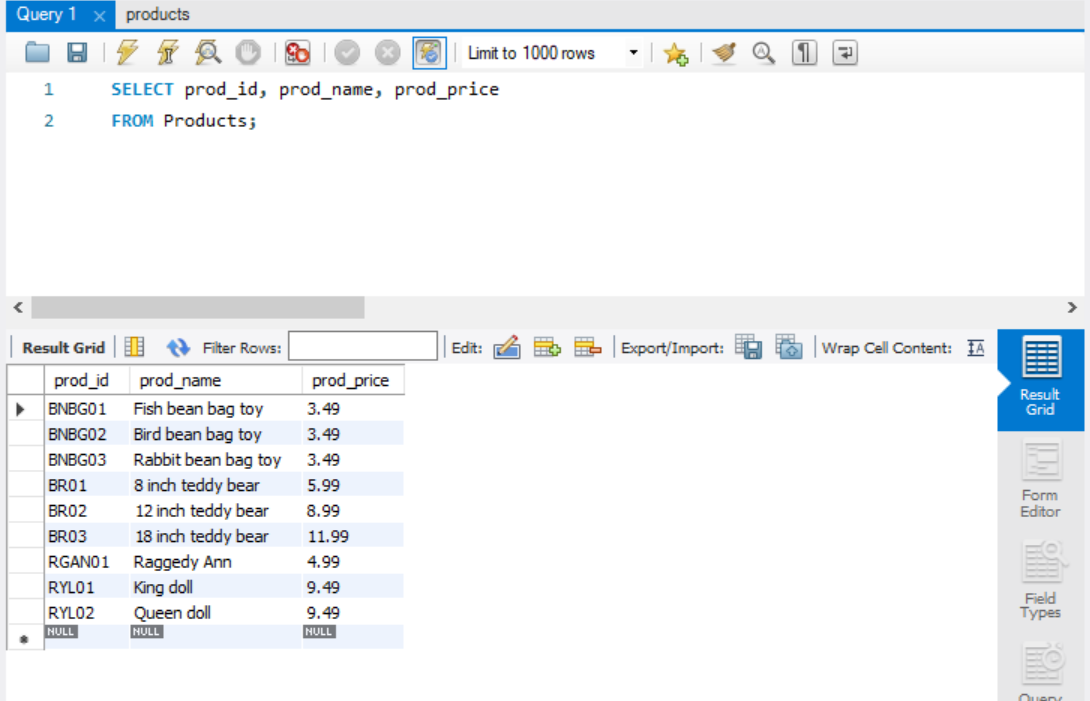
이처럼 여러 열을 불러올 수 있다.
모든 열 가져오기
원하는 열을 지정하지 않고 지정한 테이블의 모든 열을 가져오려면 와일드카드 문자인 *를 SELECT 뒤에 적으면 된다.
SELECT *
FROM Products;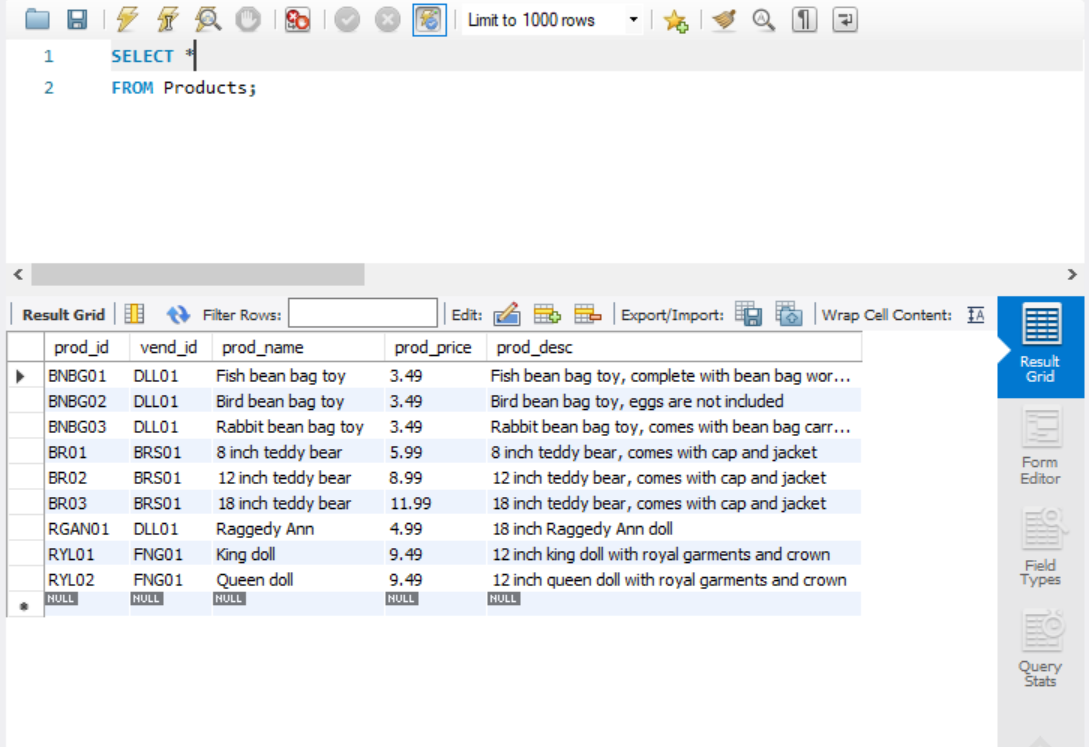
아까 열어본 Products 테이블의 모든열을 가져온 것을 볼 수 있다.
*는 불필요한 정보를 가져오기 때문에 성능 저하의 요인이 될 수 있으므로 주의해야 한다.
열 이름을 모를때는 유용하게 사용할 수 있다.
가져온 데이터 정렬하기
SELECT 문의 ORDER BY 절을 사용하여 가져온 데이터를 필요에 따라 정렬하는 방법.
데이터 정렬
SQL 문을 실행하면 데이터베이스 테이블에서 하나의 열을 가져올 수 있다. 결과를 효율적으로 사용하기 위해 정렬해보자.
가져온 데이터는 무작위 순서로 나타난다. 정렬을 따로 하지 않으면 데이터 테이블에 있는 순서대로 표시되는 것이 일반적이다. 이는 애초에 테이블에 추가된 순서에 해당한다.
이후에 데이터가 업데이트 또는 삭제되면 DBMS가 저장 공간을 어떻게 활용하는가 하는 방식에 따라 순서가 뒤바뀌게 된다. 따라서, 관계 데이터베이스 디자인 이론에 따르면 따로 정렬을 하지 않는 한 데이터는 특정 방식으로 정렬되지 않는다.
절 : SQL 문은 절로 구성된다. 절은 대개 키워드(SELECT, FROM ...)와 공급된 데이터(column name, table name... )로 구성된다.
ORDER BY 절과 하나 이상의 열 이름을 지정하면 , 그 열을 기준으로 출력 결과가 정렬된다.
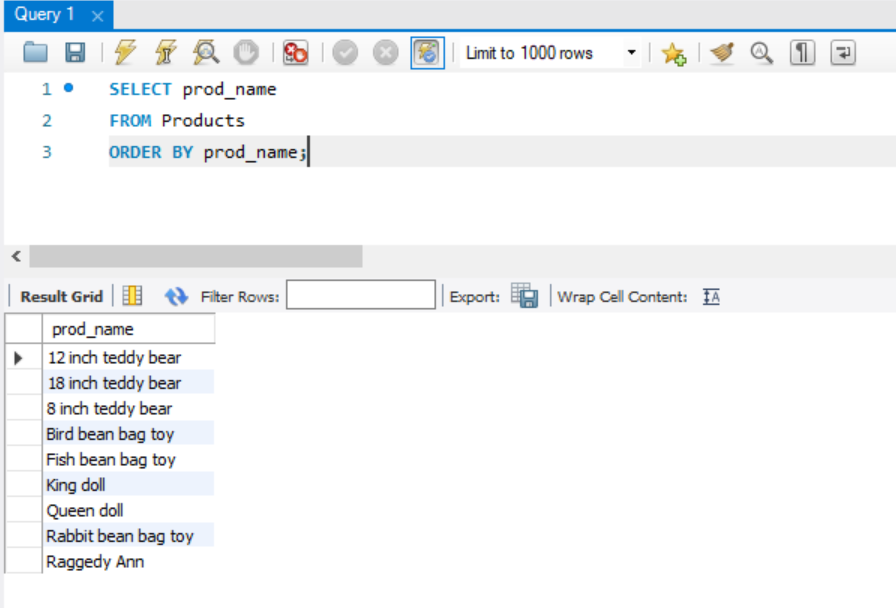
이 문은 ORDER BY절을 지정하여 DBMS 소프트웨어에 데이터를 prod_name 열의 알파벳 순으로 정렬 하는 지시문이다.
ORDER BY절을 지정할 때는,SELECT문의 마지막 절이 되도록 하는 것이 좋다. 절의 순서를 잘못 지정하면 오류가 발생한다.
꼭 출력 대상의 열로 정렬할 필요는 없다. 가져올 열이 아닌 다른 열로 데이터를 정렬할 수 있다.
여러 열로 정렬
가령, 사람의 이름을 정렬할 때, 처음엔 성으로 정렬하고 같은 성을 지닌 사람에 한해서는 이름으로 정렬해야 하는 상황이 발생한다. 이런 상황에서 성 과 이름 두 열로 정렬할 수 있다.
여러 열을 정렬 기준으로 사용하려면 열의 이름을 ,로 구분하여 적어주면 된다. SELECT에서 여러 열을 선택할 때와 동일하다.
다음 예시를 보자.
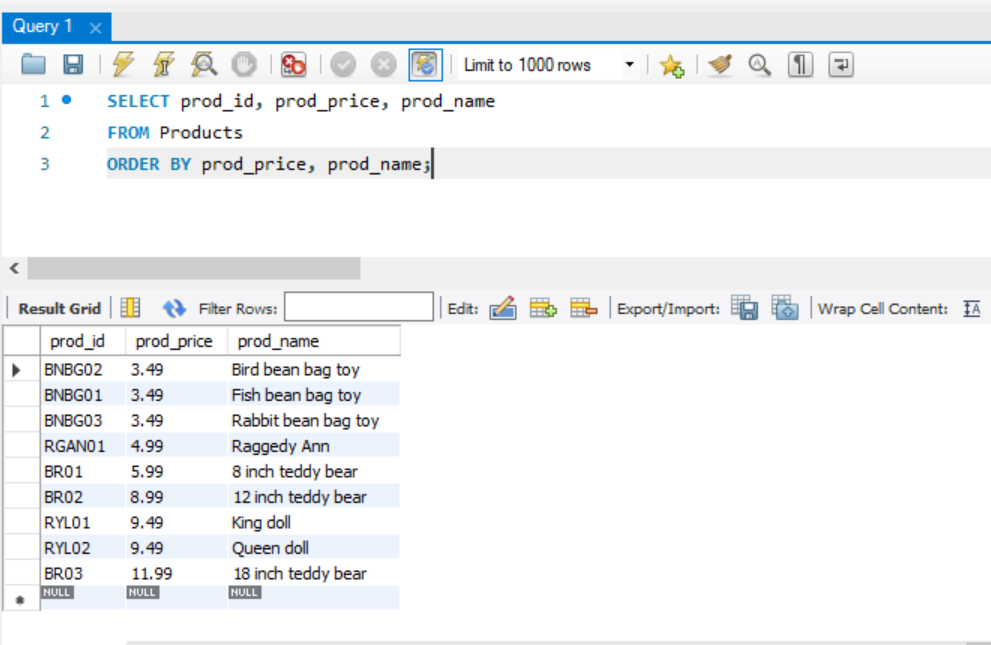
세 열을 가져오고, 가격과 이름을 사용하여 데이터를 정렬한 것이다. 적힌 순서대로 정렬됨을 기억해야 한다. 여기서는 가격으로 먼저 정렬하고, 그다음 이름으로 정렬한다.
열 위치를 기준으로 정렬
ORDER BY에 지정하는 열은 이름으로도 지정할 수 있지만, 상대적인 열의 위치로도 지정할 수 있다. 예시를 보자.
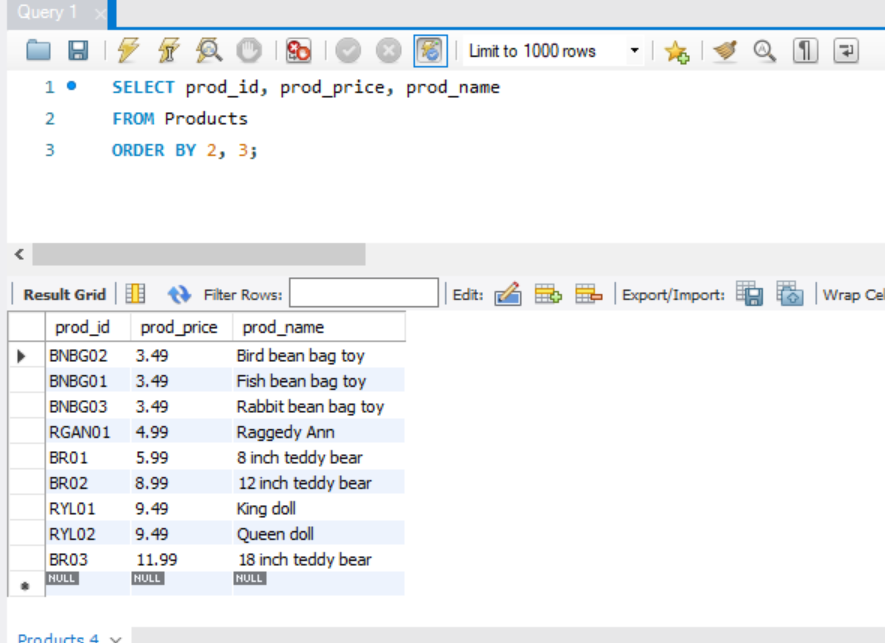
ORDER BY의 2와 3은 SELECT목록의 2번 째, 3번쨰 열로 데이터를 정렬하라는 뜻이다.
정렬 방향 지정
정렬의 디폴트는 오름차순(ASC)이다. DESC 키워드를 이용하여 내림차순으로 정렬할 수 있다.
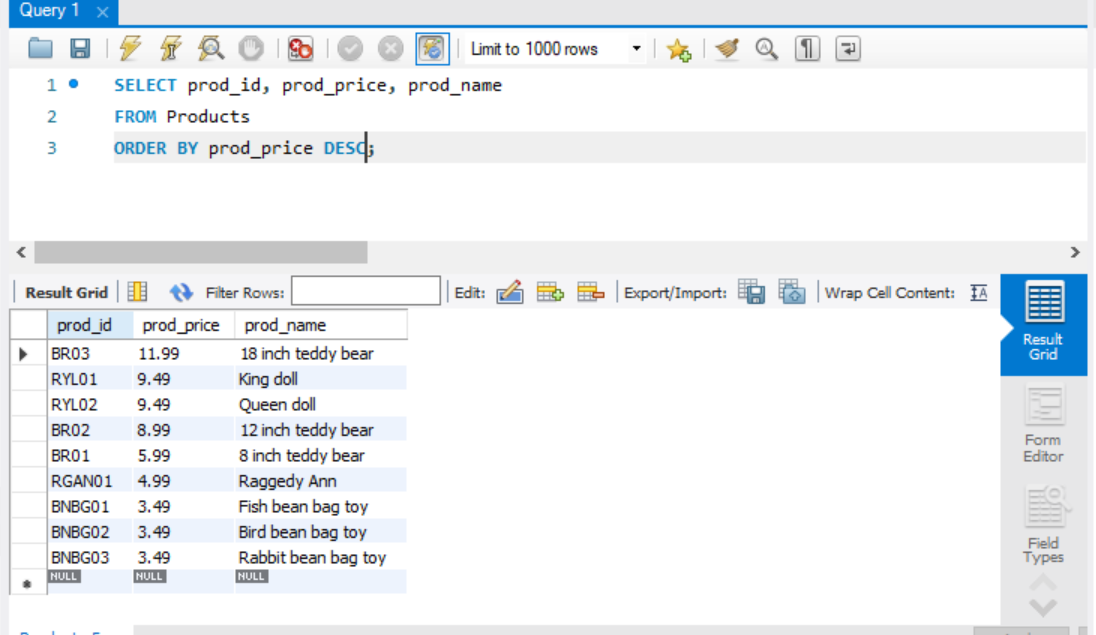
이 상황에서도 여러 열을 지정하게 되면, 순서대로 정렬이 된다. 참고로, DESC 키워드는 키워드 바로 앞에 있는 열에만 적용된다.
데이터 필터링
데이터베이스의 테이블의 데이터 중에서 특정한 용도에 맞는 것만 가져와 작업을 하기위해 검색 조건을 지정하는 것을 필터링이라고 한다.
WHERE
SELECT 문 내에 특정한 조건을 지정하는데 쓰인다. WHERE 절은 다음과 같이 FROM 절에 있는 테이블 이름 바로 뒤에 지정된다.
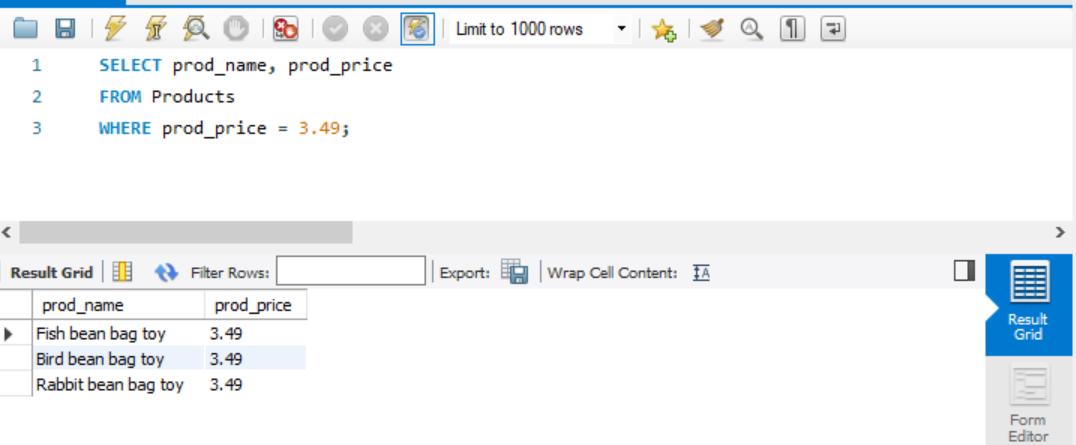
prod_name ,prod_price 두개의 열을 가져올 때, prod_price = 3.49의 조건을 만족하는 데이터만 가져오게 한다.
필터링 데이터를 SQL 문이 아닌 응용 프로그램에서 필터링 할 수도 있으나, 이는 성능을 저하를 유발할 수 있다.
ORDER BY와WHERE절을 모두 사용할 경우는ORDER BY절을WHERE절보다 뒤에 적어주어야 한다.
WHERE 연산자
=: 같음<>: 같지 않음!=: 같지 않음<: ~보다 작음<=: ~ 이하!<: ~보다 작지 않음>: ~보다 큼>=: ~ 이상!>: ~보다 크지 않음BETWEEN: 지정된 두 값 사이에 있음IS NULL: NULL
DBMS 마다 다를 수 있으므로 주의
고급 데이터 필터링
WHERE절을 조합하여 강력하고 복잡한 검색 조건을 만드는 방법을 알아보자. NOT 과 IN에 대해서도 알아보자
WHERE 절의 조합
AND나 OR 연산자를 이용하여 WHERE 절을 조합하여 다양한 방식의 필터 제어가 가능하다.
AND
하나 이상의 열로 필터링 하려면 AND연산자를 사용하여 WHERE 절의 조건을 결합할 수 있다.
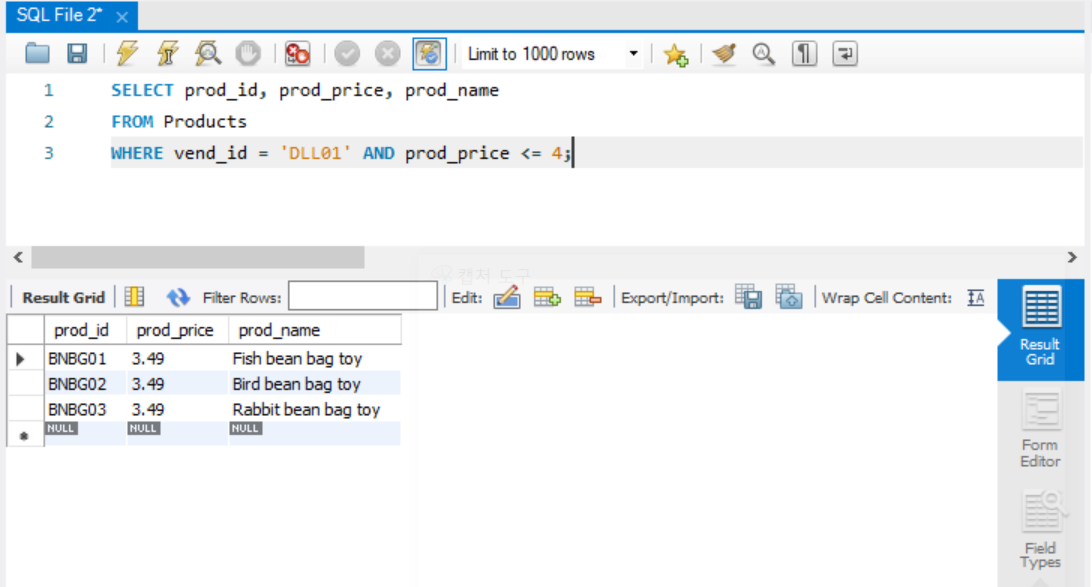
AND 양쪽의 모든 조건을 만족하는 테이블을 반환한다.
OR
둘중의 하나를 만족하면 반환한다.
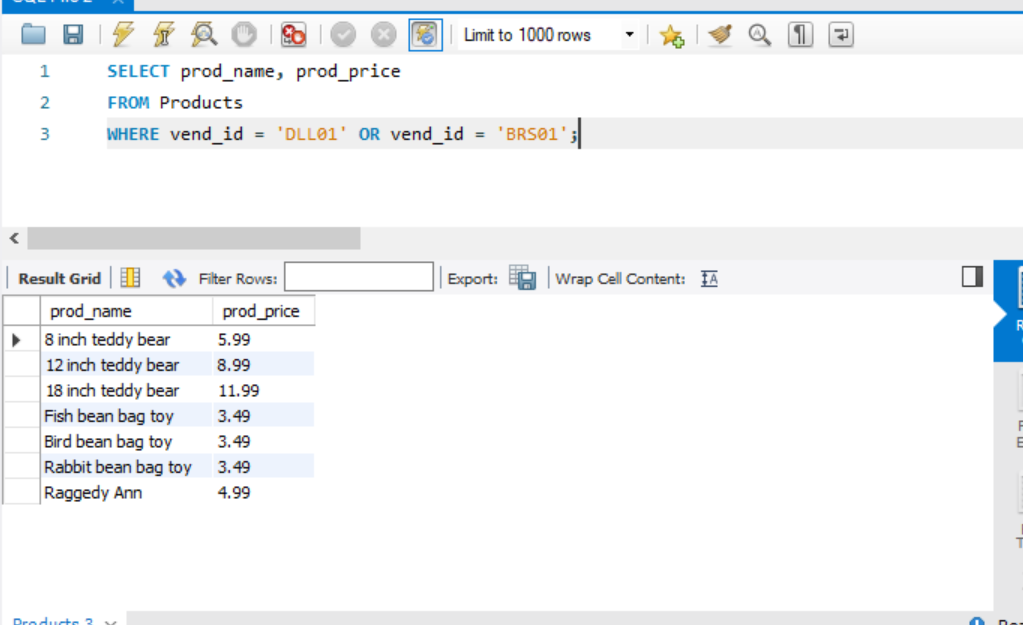
평가 순서의 이해
WHERE 절에는 AND와 OR 연산자를 여러개 사용할 수도 있다. 이때, AND가 우선적으로 처리된다. 괄호를 통해 조절할 수 있다.
IN
IN 연산자는 조건의 범위를 지정하는데 사용된다. 값은 콤마로 구분하여 괄호 내에 묶으며, 집합 관계를 생각하면 된다.
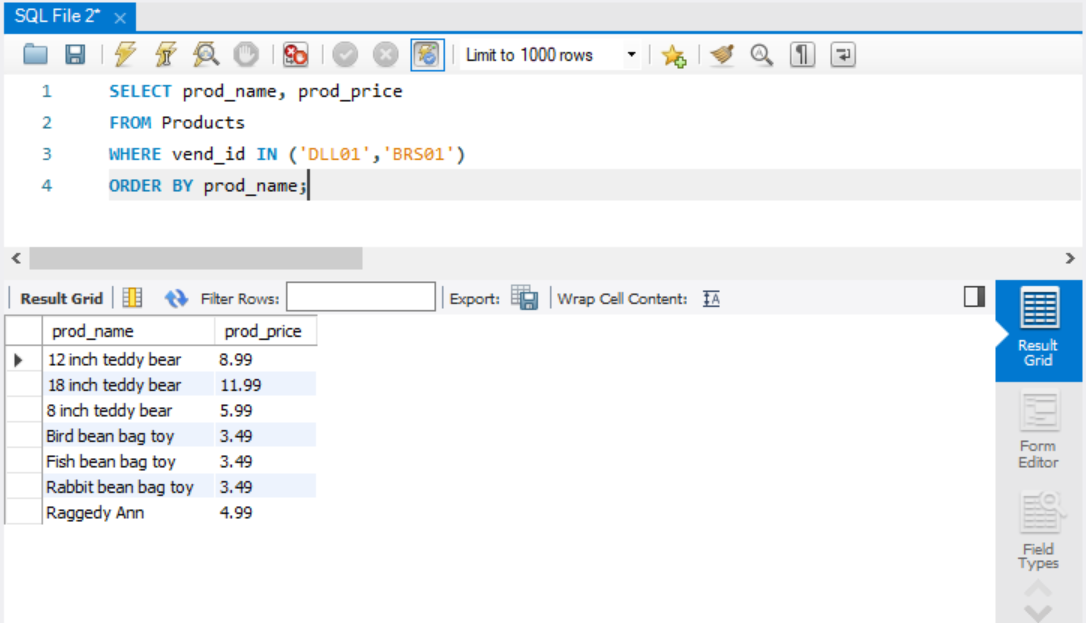
IN 과 OR의 기능이 똑같아보이지만, IN의 장점은 다음과 같다.
-
목록에 넣을 값이 여러 개일 때,
IN연산자가 보다 쓰기도 쉽고 이해하기도 쉽다. -
IN을 사용하면 평가 순서를 보다 쉽게 관리할 수 있고 연산자 수도 줄어든다. -
IN연산자가OR연산자보다 실행 속도가 빠르다. -
IN연산자에 다른SELECT문을 넣을 수 있다.
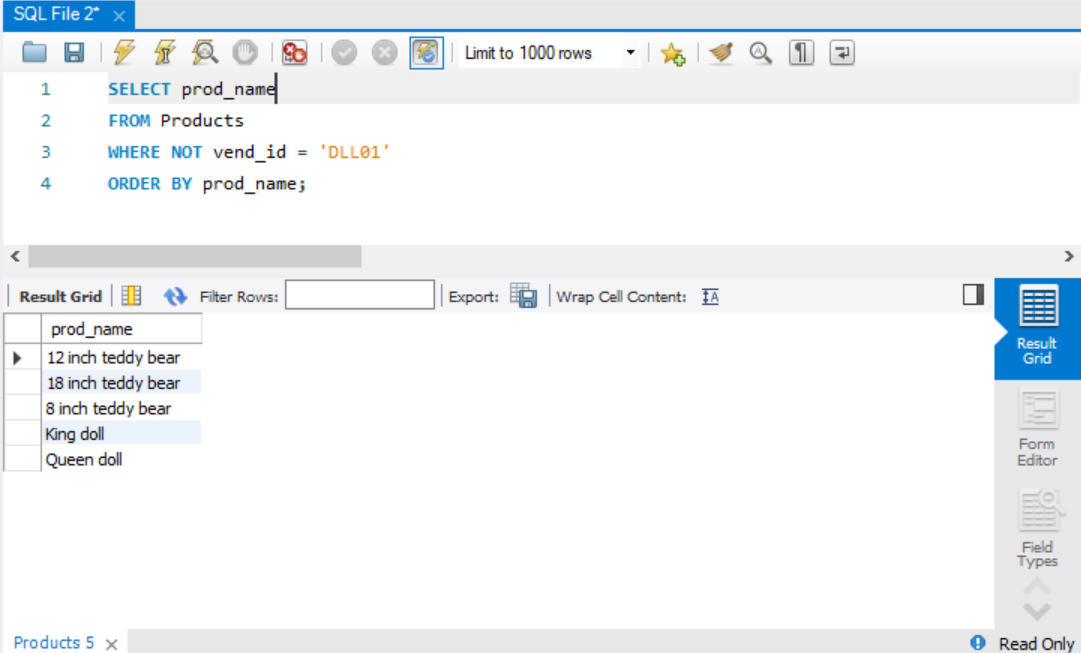
NOT
NOT 뒤에 오는 조건은 부정된다.
와일드카드 필터링
와일드카드가 무엇이고 어떻게 사용하는지, LIKE연산자에 와일드카드를 이용하여 복잡한 필터링 방법을 알아보자.
LIKE
와일드카드를 사용하면 데이터를 대상으로 패턴을 사용한 검색을 할 수 있다.
-
와일드카드 : 값의 일부가 일치하는 경우를 검색하는 데 사용되는 특별한 문자
-
검색 패턴 : 리터럴 텍스트, 와일드카드 문자 또는 이들의 조합으로 만들어지는 조건
와일드카드는 그 자체로 SQL WHERE 절 내에서 특별한 의미를 가지는 문자이며, SQL은 몇 가지 와일드카드 문자를 지원한다.
검색 절에서 LIKE 연산자를 이용해 와일드카드를 사용한다. LIKE 뒤에 오는 패턴에 따라 와일드카드 비교를 수행하여 일치하는 결과를 반환한다. 오직 텍스트 데이터 형식에만 사용할 수 있다.
퍼센트 ( % )
검색 문자열 내에서 %는 모든 문자를 의미한다. 다음 예제를 보자.
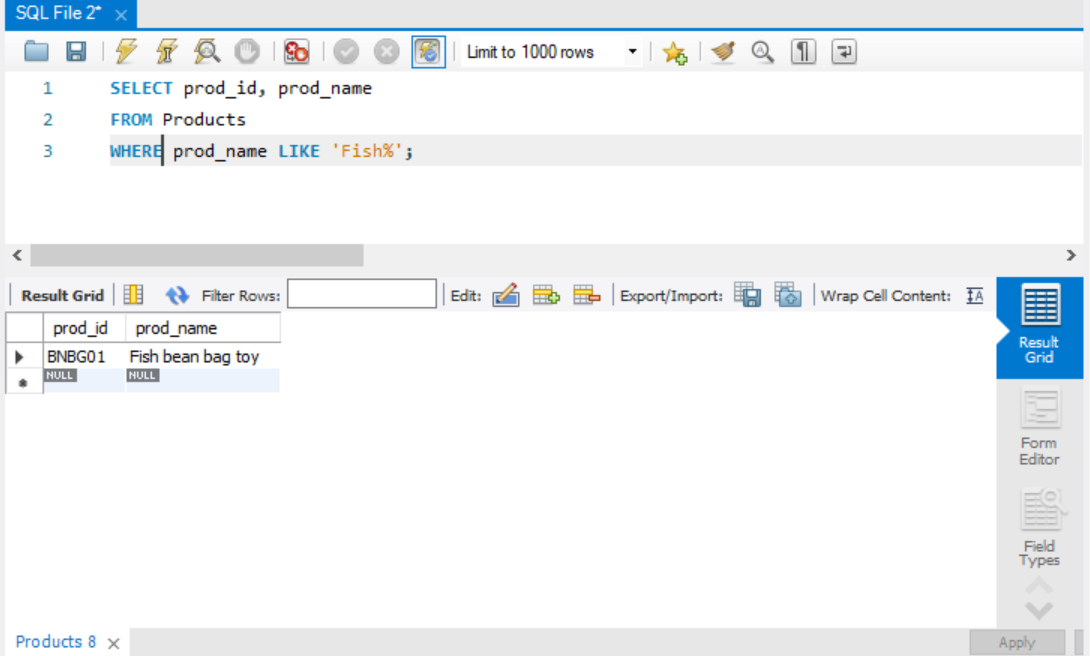
Fish%의 의미는 %기호가 쓰인 순간부터 어떤 문자열이든 상관없다는 뜻이다.
언더스코어( _ )
%가 개수 상관 없는 경우이고, _는 단 하나의 임의의 문자열을 의미한다.
괄호 ( [] )
[] 는 문자의 모음/집합을 의미한다. 다음 예제를 보자. ~~??? 왜안되지..보류 ~~
와일드카드 사용 팁
-
와일드카드를 남용해서는 안된다. 다른 검색 방법이 있다면 그방법을 써라.
-
와일드카드를 사용할 때는 반드시 필요한 경우가 아니라면 검색 패턴의 시작 부분에 쓰지 않는 것이 좋다. 와일드카드로 시작하는 검색 패턴은 처리 속도가 느리다.
-
와일드카드 문자의 위치에 신경 써야 한다. 위치를 잘못 지정하면 엉뚱한 데이터가 검색될 수 있다.
수업내용
09.07
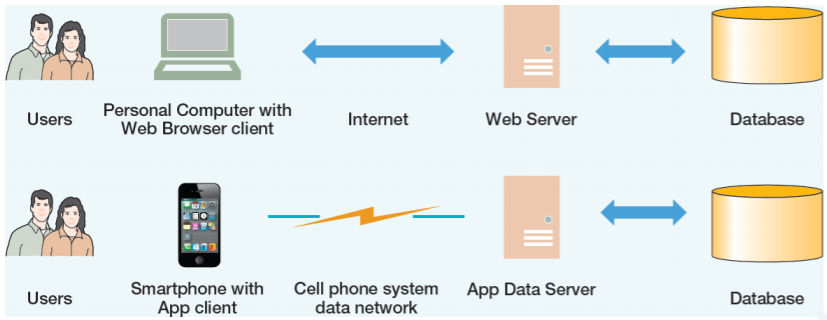
- 직접적으로 데이터베이스를 접근하진 않지만, 간접적으로 모든 IT 시스템에 뭐가 들어가있는가를 보여주는 화면

- 많은 어플리케이션에서 백엔드에서 데이터베이스를 사용한다.
웹 2.0 ... 보통 2.0 은 버전을 의미하는데, 웹의 버전은 바뀐적이 단 한번도 없다. 버즈워드라고 생각하면 편하다.

데이터베이스란....
데이터베이스의 기본적인 목표가 뭐냐 ? 사람들이 관심있는 것에 대해서 정보레벨에서 추적을 할 수 있게 도와준다는 목적으로 db를 만들었다.
우리가 배우는 범위 안에서는 , 전부 table 구조에 저장한다.
table을 쓰기 때문에 , row , column으로 구성된다.
데이터베이스는 기본적으로 하나의 테이블이 아니라 ,복수개의 테이블의 집합으로 형성되고 그 이유는 복수개의 테이블이 있다면 개별적인 테이블들은 different thing에 대한 데이터를 각각 저장한다. thing이 오해의 소지가 있는데, 이를 없애려면 차라리 different kind라고 하는게 나을것이다. 서로 다른 종류의 정보를 저장한다.
테이블이기 때문에 행과 열로 이루어져 있는데, 각 행은 관심있어하는 어떤 종류에 대한 개별 instance , 이러한 테이블들은 어떻게든 연결이 되어 있어야 한다. Connection이 필수적이다. 각 테이블간의 connnection은 realationship 이라 하며, relationship이 있는 테이블의 집합이 데이터베이스라고 할 수 있다.
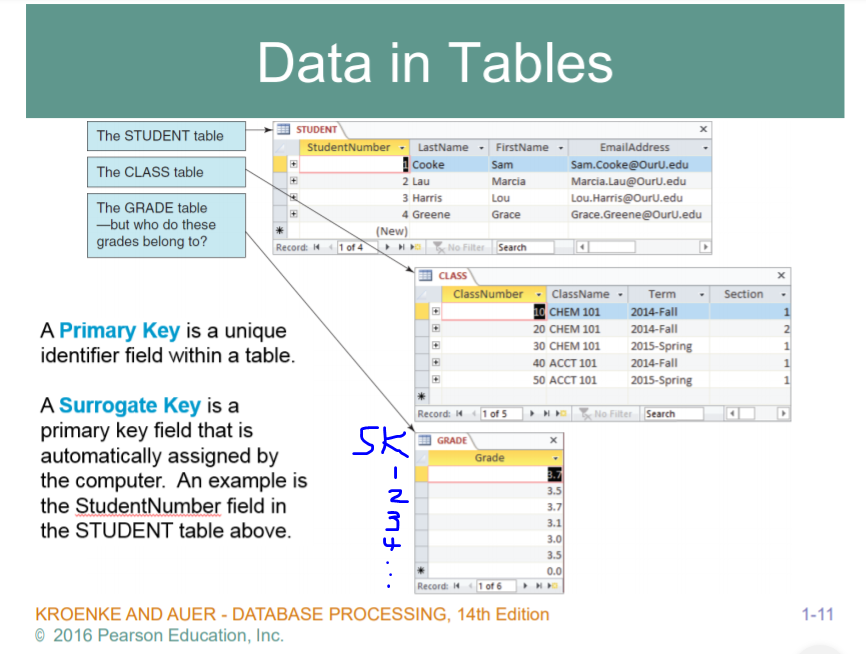
- 예시
용어소개
Student 테이블, Class, Grade 3가지 테이블
각 테이블은 Primary key 를 가져야 한다. PK 중에, 어떤 자연적으로 발생한 키가 아니고 내가 의도적으로 부여한 키가 되면 Surrogate Key 라고 한다. 내가 임의로 데이터를 모델링하거나 관리하는 사람이 임의로 각테이블별로 키값을 만들어내면 SurrogateKey 라고 한다.
Student 테이블에선 Student Number, CLass 에선 Class Number, Grade 에선 Grade 자체가 key.
여기서는 이제 , Grade 테이블에서 3.7 3.7이 같기때문에 절대안된다. 값이 똑같은것은 절대 허용하면 안된다 . Key 의 경우에... 따라서, Grade의 유일한 comlumn이 key가 되고 , 각 행별로 unique한 값을 가져야 한다. 중복 x
이럴때, 추가로 surrogate Key 를 만들어서 부여함으로써 해결할 수 있다.

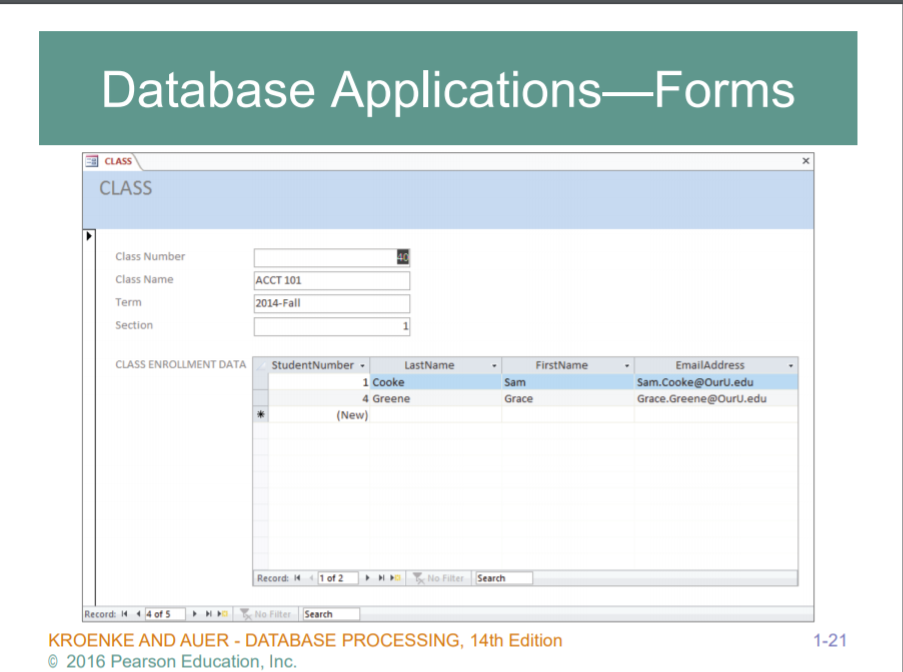
Cooke Sam 의 이메일주소가 나타나있다. Class관점에선, 클래스 고유번호가 있고, 이름이 있고, 어떤 학기에 열리는지 (Term) , Section등이 있다.
Grade 에선, 어떤 학생이 어느 클래스에서 몇점을 받았다.. 이렇게 되어야하기 때문에 관계가 있어야 한다. 이를 Foreign Key 를 받아야한다. 외부에서 키를 빌려오는 것이다.
1번학생이 10번 클래스에서 3.7학점을 받았다.. 1번은 Student Table 에있는 key 값이고, 10번이라는 말은 Class 에 있는 classNumber의 키값이다. 따라서, 1번학생이 10번클래스에서 3.7이라는 학점을 받았다라고 한다면, Grade Table 에서 StudentName , ClassNumber 가 합쳐져서 Grade 테이블의 키가 형성된다. 이를Composite Key (복합키) 라고 한다.
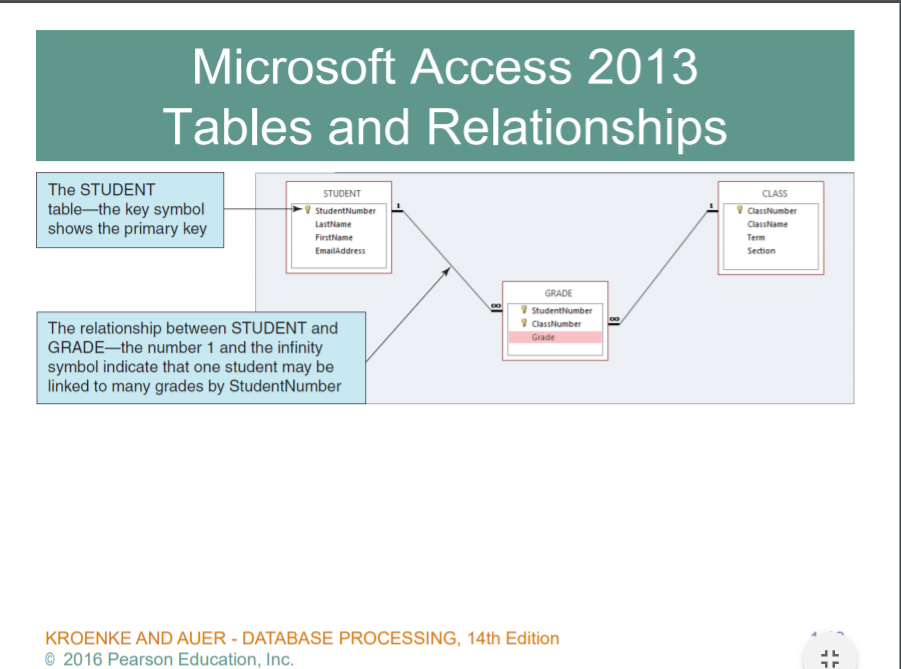
이런식으로 테이블들이 연결되어있다..
데이터베이스는 복수의 테이블들이 서로 연결되어있는 통합되어있는 어떤 집단.

naming Convention 네이밍 규칙... 가급적 서로 가독력을 높히기 위해.. 지키는것이 좋다.
테이블 지칭이름은 무조건 대문자로 쓴다.
Column name : 시작은 대문자, 나머지는 소문자를 쓰자. 복합어의 경우 ComplexTerm 이런식으로.

Data : Raw Data 라는 말을 자주 쓴다. 데이터베이스 입장에서 받아온 어떤 애들(?) fact 나 특징 을 데이터라고 부르고 , 데이터로 부터 가공해서 새로 만들어진 걸 information 이라 한다.
GPA 는 해당시점마다 계산을 새로해야하므로 (GRADE기준으로) , GRADE를 바탕으로 GPA를 만드므로,GRADE(data) GPA(information) 을 만든다.
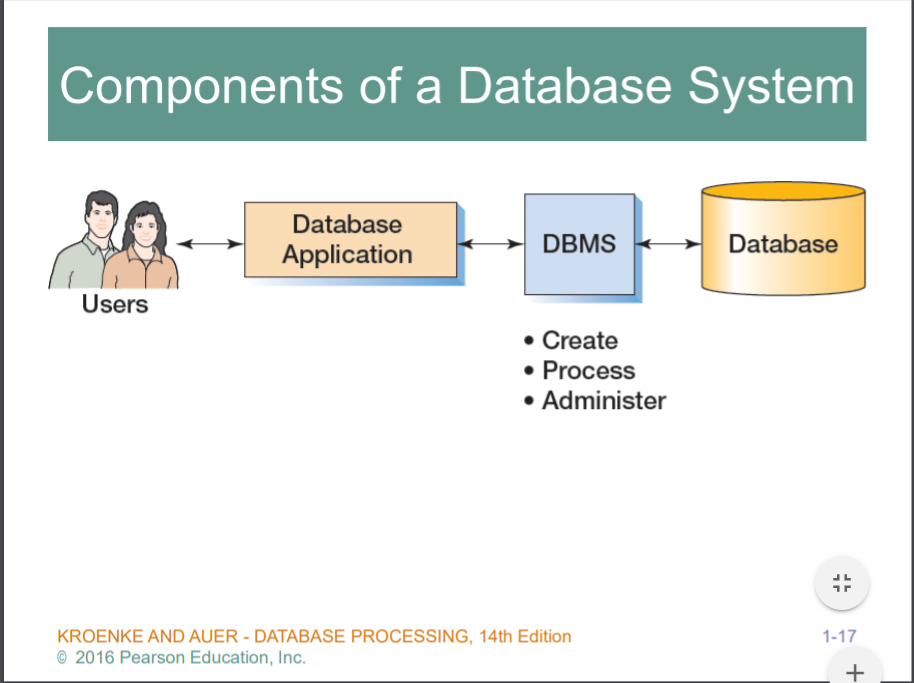
앞으로 배울 db 시스템은 뭐냐 ,,, 사용자는 데이터베이스 어플리케이션에 커뮤니케이션을 하고있음. db App 이 실질적으로는 내부에서 DBMS랑 통신을 한다. DBMS는 궁극적으로 저장된 DB에서 정보의 Create, process 이런것들의 정보를 교류,처리한다.
앱개발자는 DB app 을 개발하고, DB개발자 관리자는 DBMS 를 담당하고 그런다..
DB app 입장에서보면 통신을 해야한다 DBMS랑,, 이떄 DBMS Vendor 가(ex. MS,Oracle,IBM DB2, MySQl,...) 각각의 DBMS 시스템이 있기 때문에, 통신 언어가 다르다. 효율성을위해 DB app 과 DBMS 사이 언어 표준화 -> 그것이 SQL(structured Query Language)
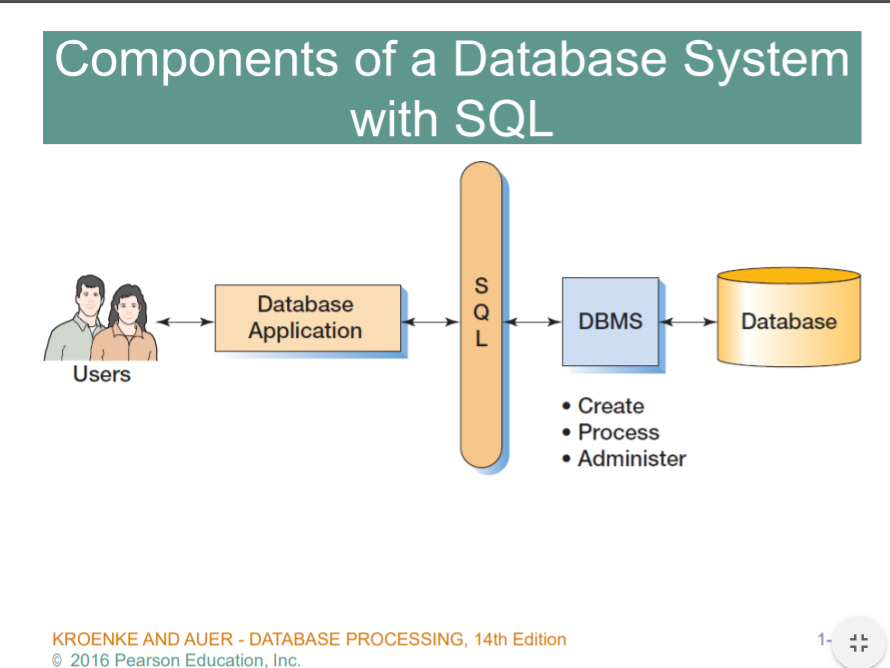
dbapp 에선 sql 알면되고, sql을 이해하는 DBMS를 만드는게 DBMS Vendor...
결국은 SQL이라는 한개의 언어로 통신이 가능해진다. SQL만 배우면 모든 DBMS 와 통신이 가능해진다~

임의의 컴터프로그램을 App 이라하고,
DBMS 는 db를 만들고 누가요구하면 처리해주고,, 관리를 해주는 역할
앞서말했지만 SQL은 국제 표준 DB언어이다. 여러종류의 commercial DBMS들이 지원한다.

데이터베이스랑 연동되는 app 프로그램의 기능 예시..
form processing ( = app ) -> 양식버튼 ( 회원가입 ) 디비에 전송
검색 하면 검색 결과 주는것 -> user query
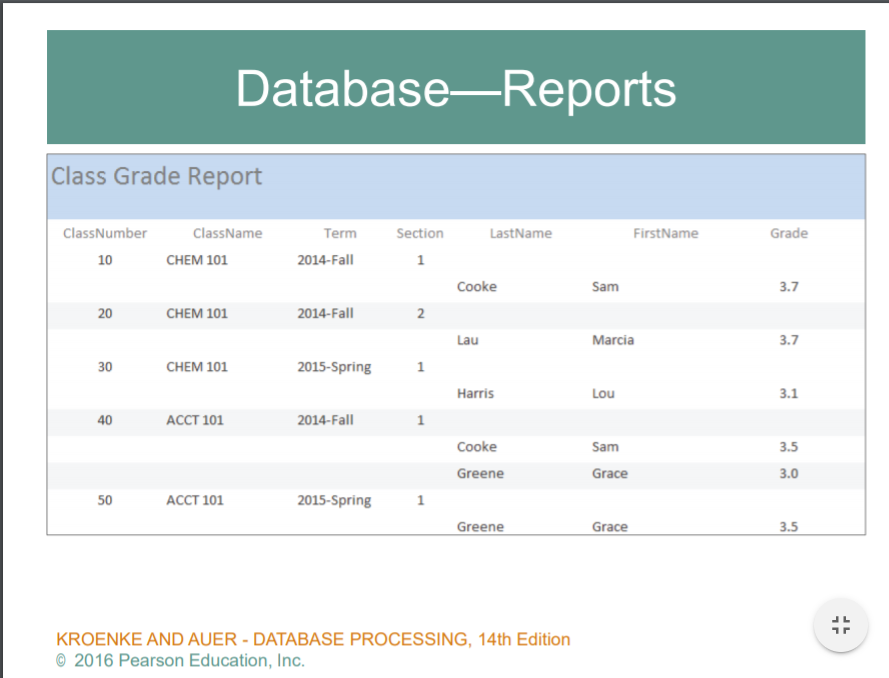
create and process report -> 현재까지의 성적표를 보고싶다 - > 학사관리시스템에 들어가서 우리의 성적표가 뜬다. 그 성적표가 reporting 기능이다.
execute application logic -> ex GPA 계산 같은것
Control the application self(administartion) -> app자체를 통제하려고 할때도 ..

DBMS 자체는 어떤기능을 하는가...
- create DB (데이터베이스 생성)
- create Table (테이블 생성)
- create supporting structures (ex. indexes)
- Modify (operation) .. insert , update, delete 등등..
- Read database data ( 데이터 빼내는 것 읽는것 )
- Maintain databas structures ( 디비 구조 관리 )
- enforce rules ( 규칙 관리 )
- control concurrency ( 대표적 예제 : 은행에가서 돈을 입금할때 동시에 누가 그계좌에서 빼내갈수도있는데 그때 blocking 을시켜서 동시에 이상행위가 발생하지 않도록 하는 통제요소 )

- 디비는 자기 구조에 대한 정보를 같이 가지고 있고 (self-describing) , 각각의 테이블들이 다 연결되어있고 이들의 집합이다.(integrated tables)
integrated 되어있다 -> relationship이 테이블간 존재한다.
self-describing -> 자기 자신에 대한 description을 가지고있다 = 메타 데이타(data about data) 즉, 스키마정보를 가지고 있다. 이 스키마가 어떤 의미에선 메타 데이타의 의미이다. 나중에 깊게...
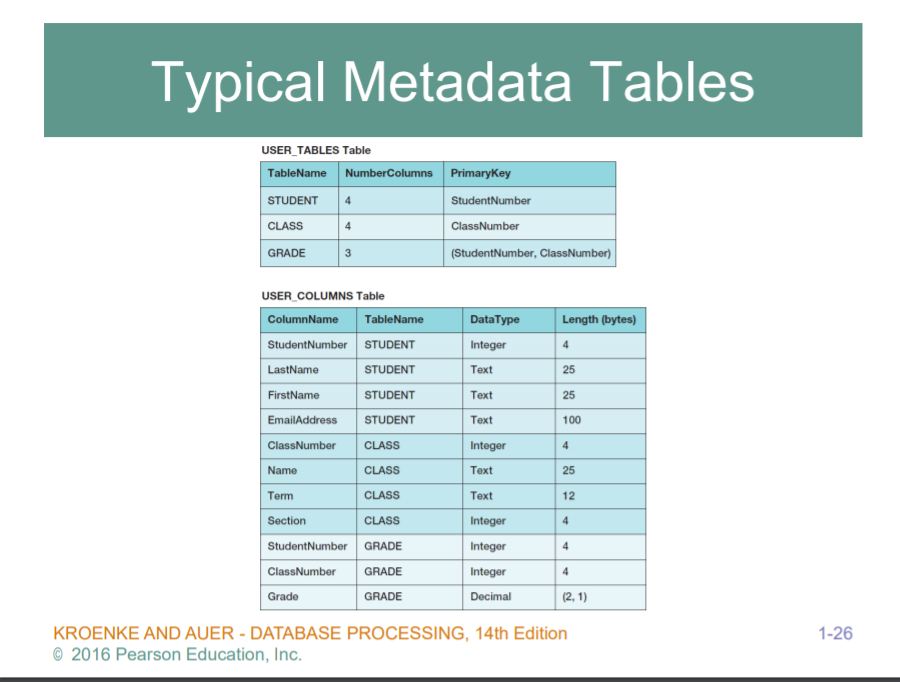
첫번쨰 메타데이타 : 어떤 테이블에 어떤 정보를 가지고 있느냐..
두번쨰 : 각 column 에 대한 정보
- 데이터타입, 바이트를 가지고있다..
즉 내가 가지고 있는 테이블들의 구조와 이름과 속성이 이렇다라는것을 별도로 가지고 있다. 이를 통칭해서 meta Data라고 부른다.
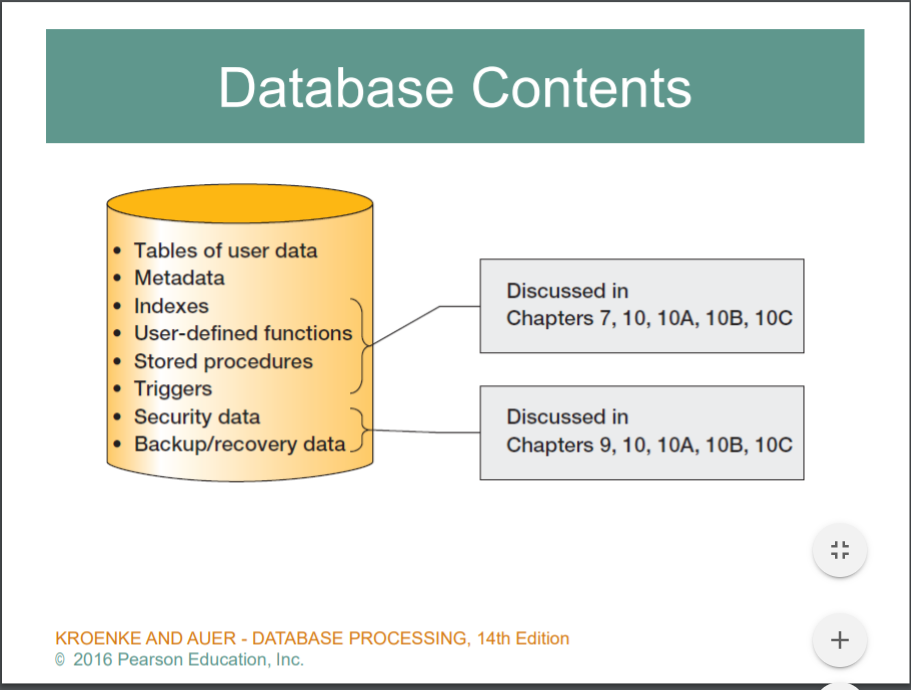
디비는 뭘가지고있냐
저장해야될 데이터, 데이터 배치 구조정보(메타데이터로가지고있다)
추가적으로 인덱스정보를가지고있다. ( 나중에 자세히 )
User-defined function고유 함수를 가지고 있다.
Stored procedures 디비가 제공하는 프로그래밍 언어, 그리고 그 언어로 짠 코드들
Trigger
security Data
Backup/recovery data
단지 데이터만 있는게 아니다~ 또 이러한 정보들을 테이블로 관리한다. U,S,T 뺴고

ms access -> personal dbms
oracle, ibm db2 - > 대규모
mysql -> 중급
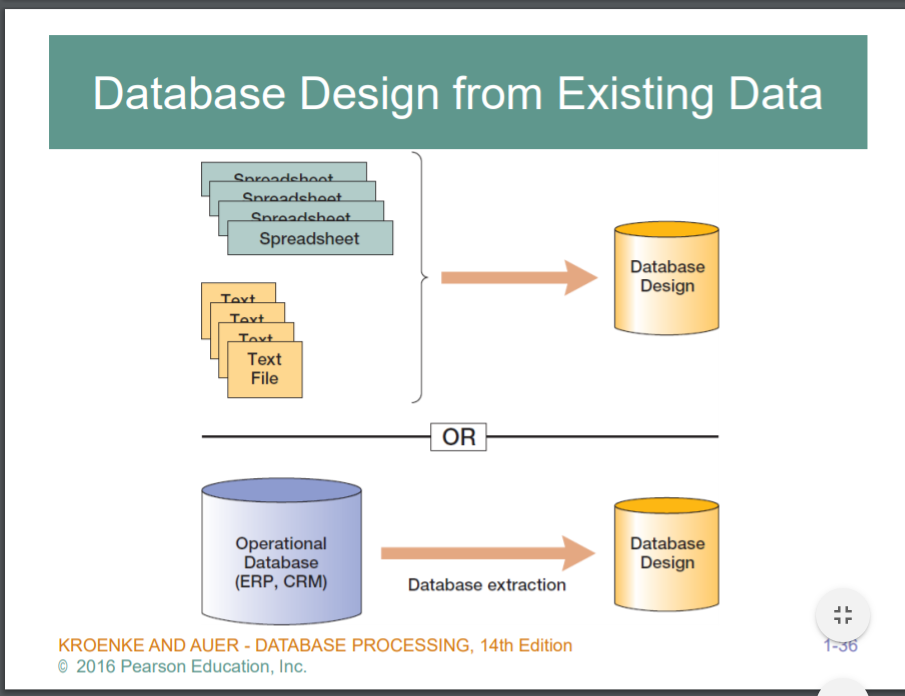
데이터베이스를 설계하는게 궁극적 목표...
이미 존재하는 스프레드 시트나 임의의 소프트웨어 기반 파일들이 존재할경우 그걸 가지고 db디자인으로 밖거나, 기존 operational한 db에서 부분적으로 발췌를 해서 분석용으로 db를 쓸때 어떻게 디자인하냐..
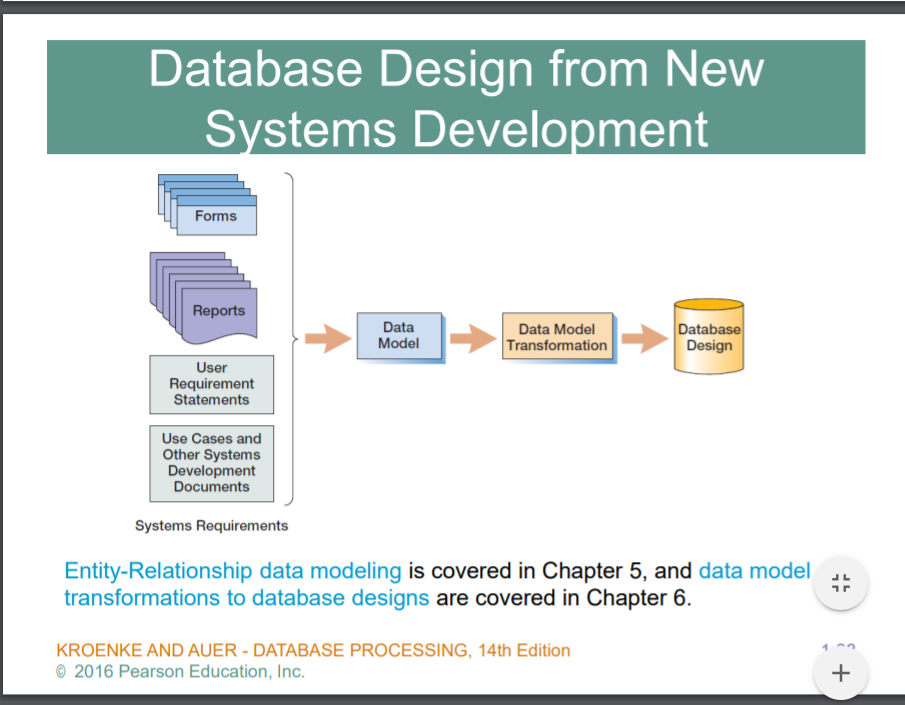
처음부터 데이터 모델을 만들고, 그 모델 안에 데이터를 집어넣는,, new systems development 라고 한다
이럴때 고려해야할 요소가 다르다 각각의 주제는 추후에 .. 다룰것
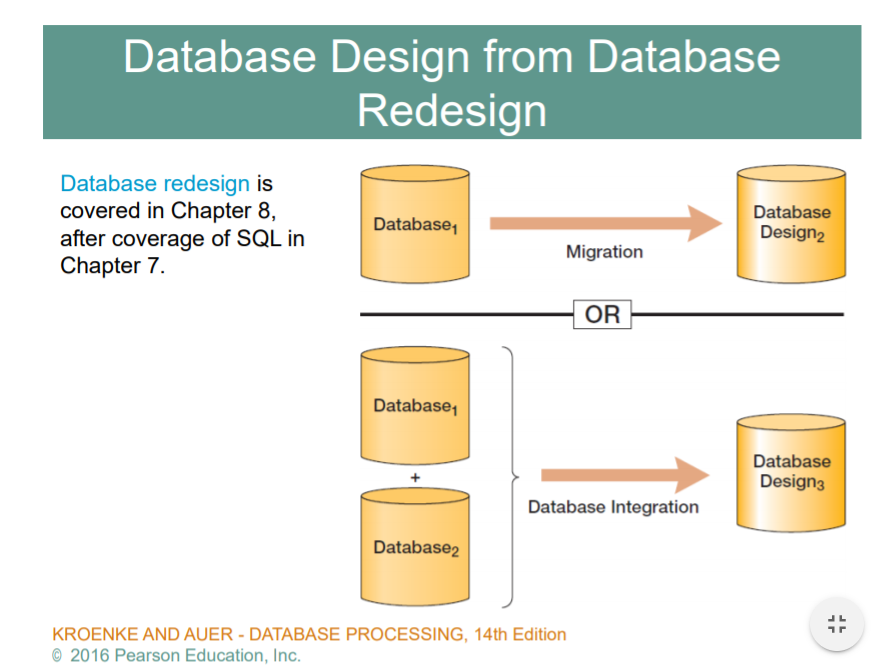
이미우리가 디비를 쓰고있을때 특정목적이나 새로운 기능을 덧붙히려고 할때 재개발할때 차세대 시스템으로 가려고 할때 기존 데이터베이스를 어떻게 migration 할거냐,, 여러버전의 디비를 어떻게 통합할거냐 -> Redesign

주력으로 배울내용...
RDB
관계형 데이터베이스.. 아주 장악력이 큰 db모델

noSQL..
Not only SQL
sql 을 쓰지만 also 이것도 있다~ 필요없다 이런게아님.
Database Integrity
일치성 , 통일성 (consistence)..
은행갔을때, 인터넷뱅킹이나 모바일뱅킹을 통해서 돈을 입금하는 경우, 그 입금한 돈이 입금한 시점에 바로 계정에 process 되어야 하는데, 내일쯤 10만원이 들어가게 되거나.. 열흘이따들어가게되면 짜증난다 -> 이런게 기존에 db에선 진짜 중요했다.
구글 검색은 실시간 consistency를 포기해도되는것처럼, 포기하면서 만들어낸게 nosql이다. noSQL 은 relation model을 replace가 아닌, 보완을 하자는 차원. 당장 즉시 업데이트 안해도 되는 상황에선 , 굳이 sql안써도 된다.. 이런식
09.10

business intelligence -> 일반적으로 기업에서 기업의 데이터가 운용되는 과정을 보면, 운영시스템이있고, 그 옆에 분석시스템이 따로 있다. 운영 시스템이 뭐냐면, 가령 은행에가서 돈을 입금하거나 출금하거나 또는 이체할때.. transaction이라고 통칭한다. 이 transaction을 그때그때 DB에 적는 과정, 반영하는 과정을 operational DB라고 부른다. 이러한 운영 DB를 분석하려고 할때, 은행에서 오늘 아침 10시부터 12시까지 돈을 얼마나 맡겼는지 알고싶을때.. 이러한걸 BI 라고 한다. 특정한 목적을가지고, 분석,플래닝,통제할때의 정보들을 얻고자 할때

질의를 하는것이다. (query) 잔고가 얼마있는지 확인하는 등의 반복적으로 일어나는 일들.. >> 일상적인 쿼리. 미리 시스템에서 준비를 하고 있는 상황. 소프트웨어적으로 계좌를 넣으면 답해주고..
아무도 예측할수없는 특정 목적에 부합하여 알고싶을 경우 보통 Ad-hoc queries 라고 한다. 미리 준비해놓을수없고, 원하는 조건을 넣어서 끄집어 내야하고, 이때 필요한것이 바로 SQL언어를 통해 db를 추출할수있게 된다. Ad-hoc 쿼리는 필요할때마다 유저에 의해 생성. 늘 발생하는 것과 상반되게 임의의 쿼리를 아무떄나 할수 있는것 -> Ad-hoc query라고 부른다.
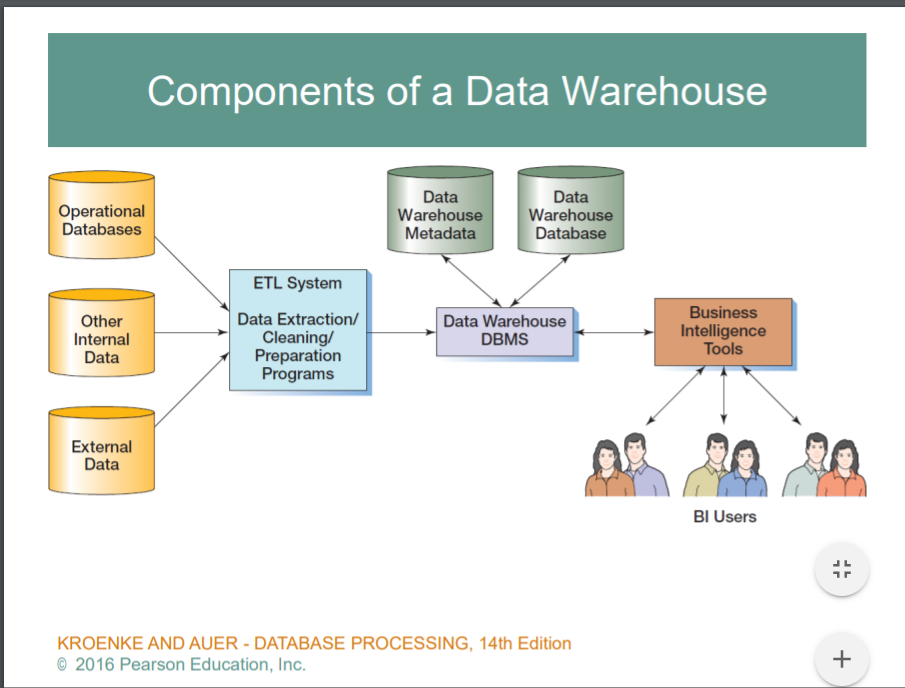
BI 에서 애드혹쿼리가 필요. BI에선 operational 한 db, 그외에도 내부적으로 가용하는 데이터가 있으면 , 다른 internal Data, 더 나아가서는 external Data 까지 모아서 내가 분석하고자 하는 일종의 데이터베이스 툴을 만들게 한다. 그 툴을 보통 Data Warehouse라고 부른다. 이러한 Data로 부터 ETL(extraction transformation, Load / 주로 밤에 이루어짐) 과정을 거쳐서, 데이터 웨어하우스에 적재를 한다. DB자체는 self-describing한다. 데이터 웨어하우스를 왜 굳이 만들어야 하냐? >> operational db, internal,external data 로부터 직접 가져오면 안되나..? >> 왜 가져오면 안되냐면 ,,,, ... ? 디비접근하여 읽거나쓰거나하려면 블로킹을한다. db가 멀티유저 환경이기때문에... 넣거나 뺴거나 할떄 그 데이터 접근하는 순간 다른 사람은 이용할수없게 블로킹하기때문. 통계를 내기 위해선 모든사람의 db를 다접근하여야 하기때문에 전부 블로킹하게되면 사용자들은 이용할수없기떄문에 실질적인 운영에 지장이 간다..

SQL 프로그래밍은 DB에선 가장 핵심 스킬.

기능에따라 5가지..
DDL,DML,SQL/PSM,TCL,DCL

DDL >> 테이블을 만들고 관계를 설정 , 테이브를 선언하고 구조를 정의

쿼리를 위한용도 데이터를 넣기위한 용도 수정용도 지우는 용도
CRUD 통칭하여 DML이라한다.
빈테이블에 데이터 넣는것이 INSERT statement 실행

제한적 코딩 지원 .. 나중에 자세히

한번 transaction 시작해서 끝날떄까지 블록 형성, 그블록이 완성되지않으면 과거로 돌아간다.. >> 은행에서 돈을 꺼내는데 , 10만원 인출시 에러가 날경우 , 초기상태로 되돌리는 것. 거래가 완성되도록 하는, 안됐을때 이전상태로 돌리는 통제 - TCL 나중에 자세히

사용자환경 A 사용자 -> 볼수있고 B 사용자 -> 보기도 하고 고칠수도있고
C 사용자 는 또 ~~하고.. 사람과 group에 대한 기능 허용 여부 의사결정
실습

케이프코드 예제.. 아웃도어 스포츠
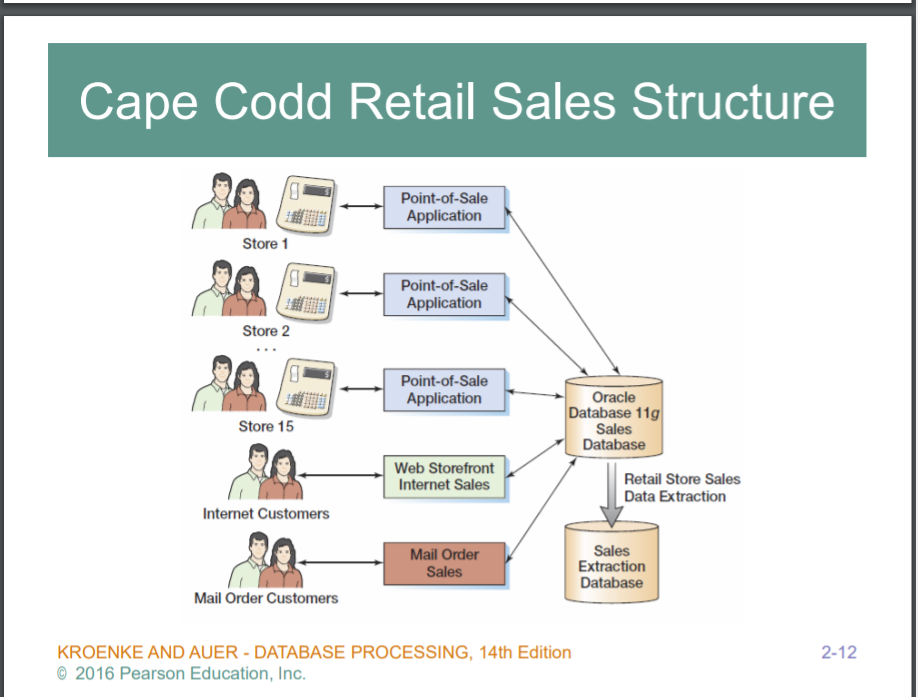
1~15까지 가게 있고, 인터넷, 메일오더 다 있음. 실제 스토어에서는 포스시스템 매출이 기록됨 -> Oracle DB에 기록됨 . Oracle Database 11g Sales Db에는 직접 접근하면안되므로,, Extraction과정을 거쳐 SalesExtraction Database에 ad-hoc query를 할것이다.
09.14

데이터 추출 -> 3가지 statement
SELECT , FROM , WHERE
테이블에 접근하기 위한 키워드
FROM : 어떤 테이블 / 보고싶은 테이블이름
테이블이 결정되면
row 결정 >> selection
column 결정 >> projection
-> 특정 셀 확정
참고로 selection 과 SELECT는 다름
SELECT : projection 결정
WHERE : 조건
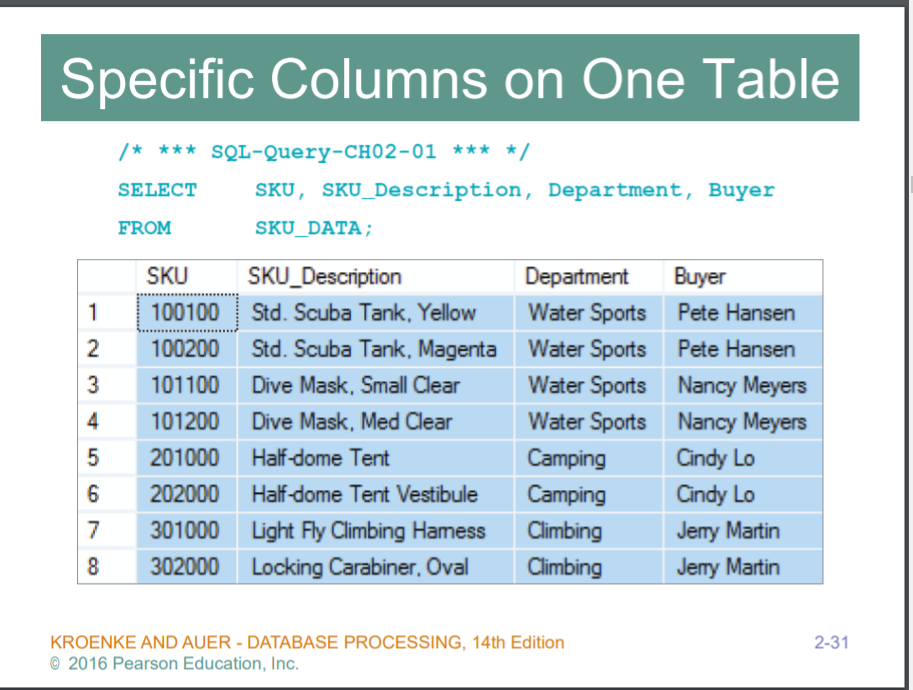
where가 없다 >> 모든 행을 보겠다
FROM SKU_DATA >> SKU_DATA 테이블을 보겠다
SELECT SKU, ....
해당 column을 보겠다
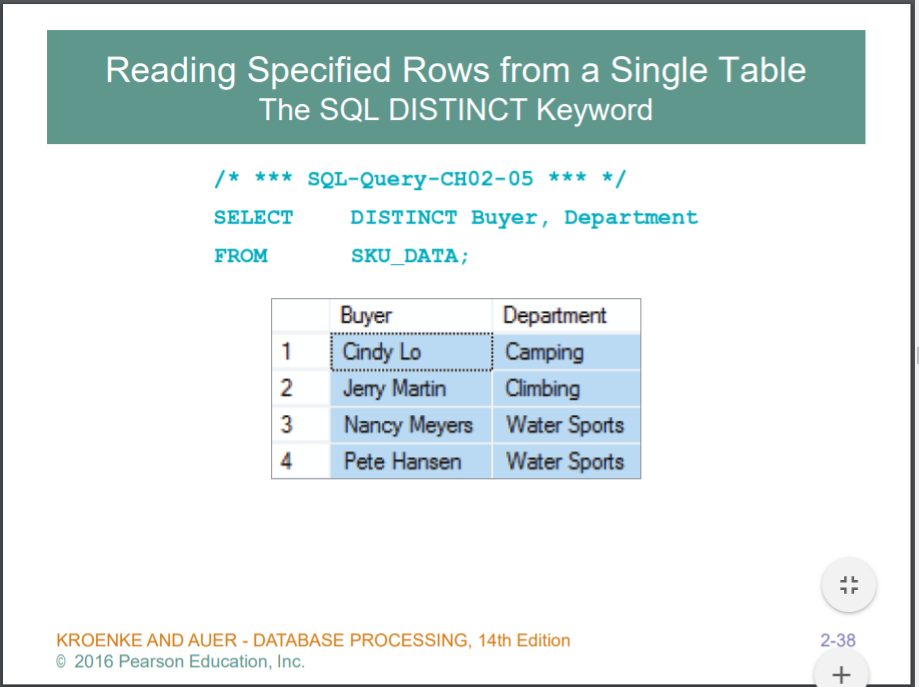
DISTINCT : 중복 해결
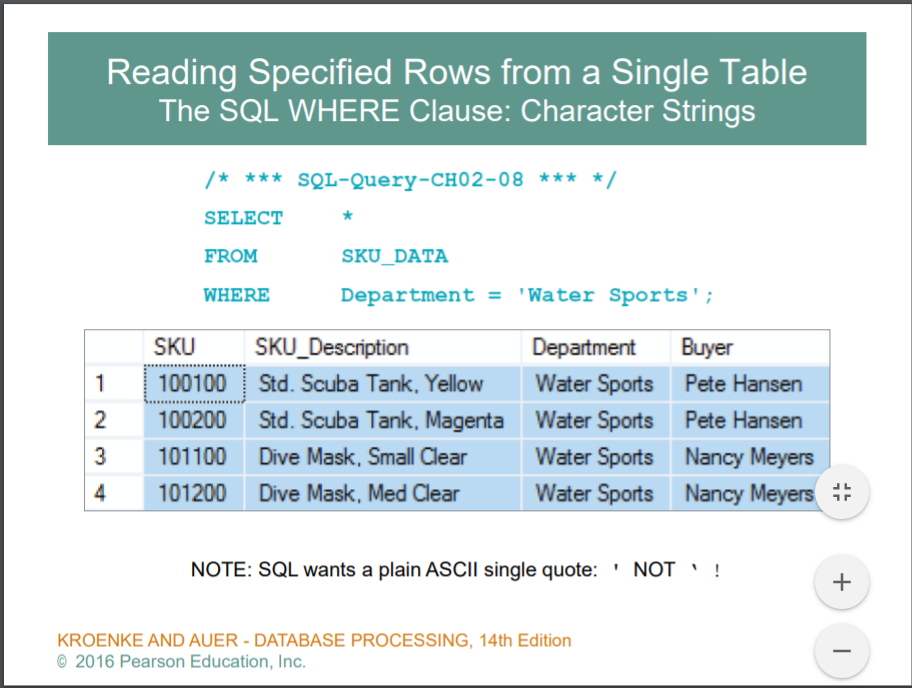
WHERE : 조건
SQL 에서는 작은따옴표를 사용한다.
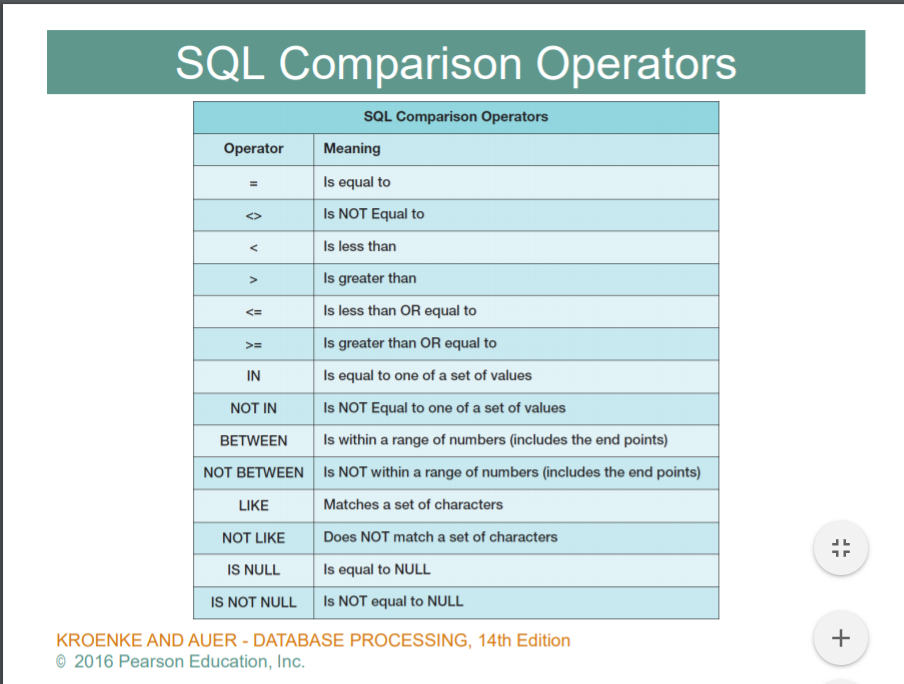
WHERE 문 안에서 쓸 수 있는 연산자
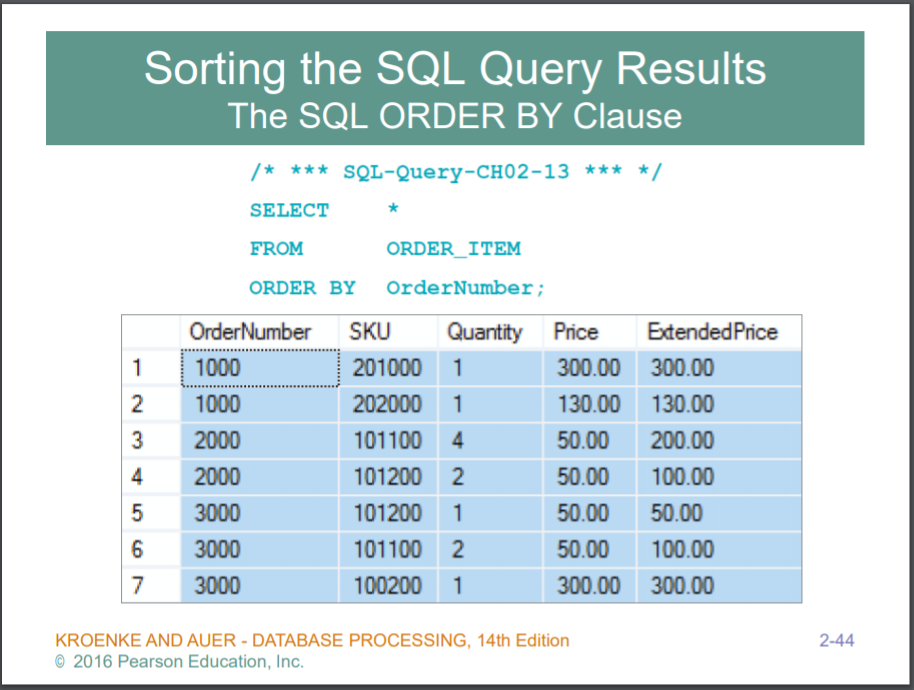
ORDER BY : 해당 column 기준으로 위에서 아래로 정렬 (default ascending)
sorting 방향 결정
DESC - DESCENDING ORDER
ASC - ASCENDING ORDER
로 정렬
앞에 쓰여진 column을 먼저 소팅한다
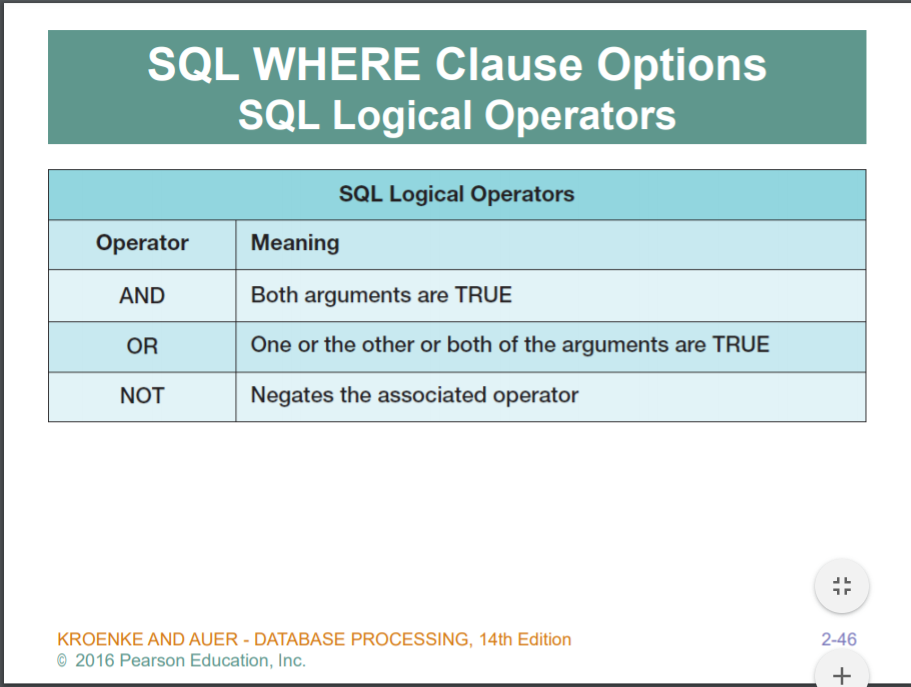
WHERE 문 논리연산자
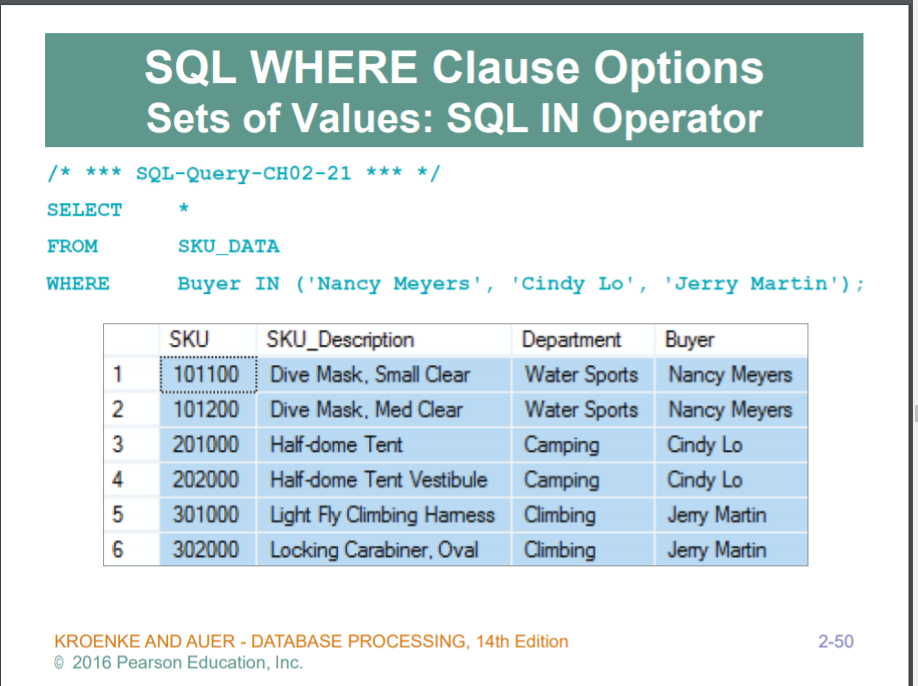
IN, NOT IN : 집합관계와 동일

와일드 카드
SQL의 경우, _ >> 한 캐릭터에대한 와일드카드
% >> 복수개의 캐릭터의 집합에 대한 와일드카드

패턴매칭을 위해선, LIKE 와 %
Pete 뒤엔 어떤것이 와도 된다.
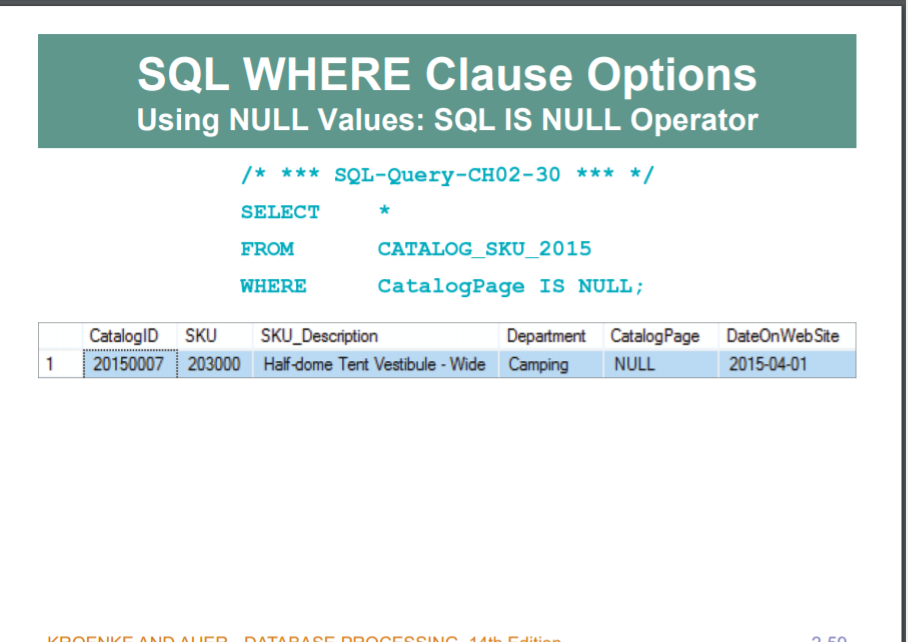
IS NULL , IS NOT NULL : 말 그대로 = Null , != Null
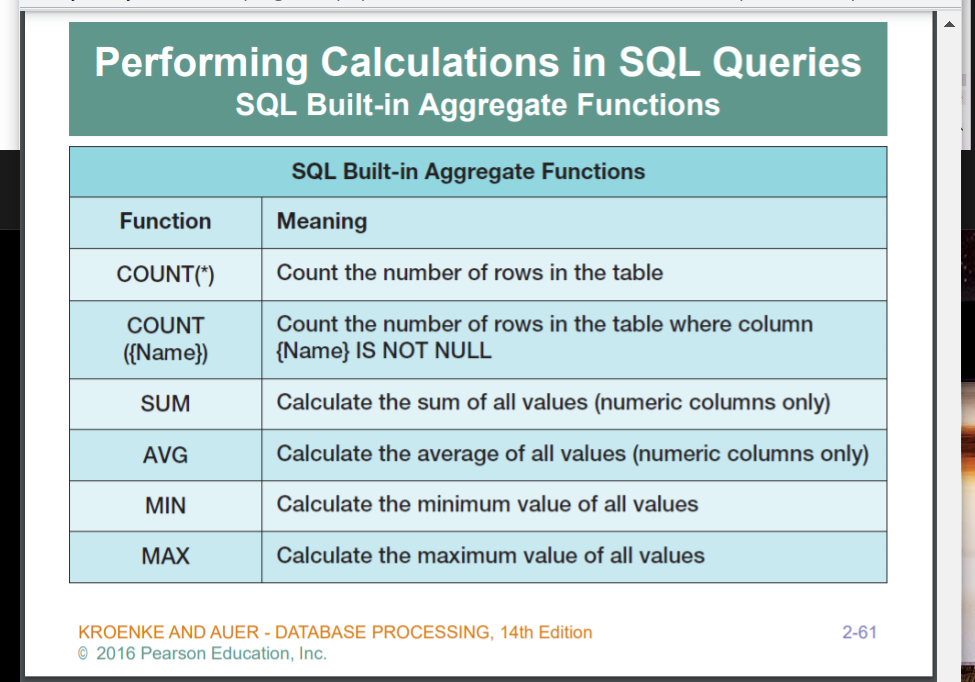
SQL 이 제공하는 빌트인 function
여러개의 데이터를 복합적으로 봐서 어떤 값을 만들어 낼때 쓰는 함수들
COUNT : COUNT의 파라미터로 줘도되고 안줘도도된다 . *을 주게 되면, 모든 행을 세서 알려준다. column정보를 주면 , 그 column의 값이 차있는게 몇개이냐 NULL은 제외, 중복은 count 함
SUM : 당연히, 숫자있는 column에만 적용, 핪을 제공 , column name 을 인수로 받고, AS 키워드와 함께 column name 을 사용하여 테이블을 반환한다. column name 을 안주면 자동으로, 명시적으로 표현하면 그대로 만들어진다.
AVG : 평균
MIN,MAX : 최소 최대

AS
우리가 쓰는 언어 >> Relational algebra
operation 할 떄 인풋으로 들어가는 것도 동일한 도메인이고, 아웃풋도 동일한 도메인에서 나와야함. 정수 > 정수 실수 > 실수
어떤 query에서 나오는 결과도 테이블이다.
어떤 column 전부 더해서 값을 달라고 요청하면, 값이 하나만 나오는데, 이것 역시 table이다.

쿼리에서도 calculation 이 가능하다.
나중엔 function도 사용할 수 있다.

CONCAT
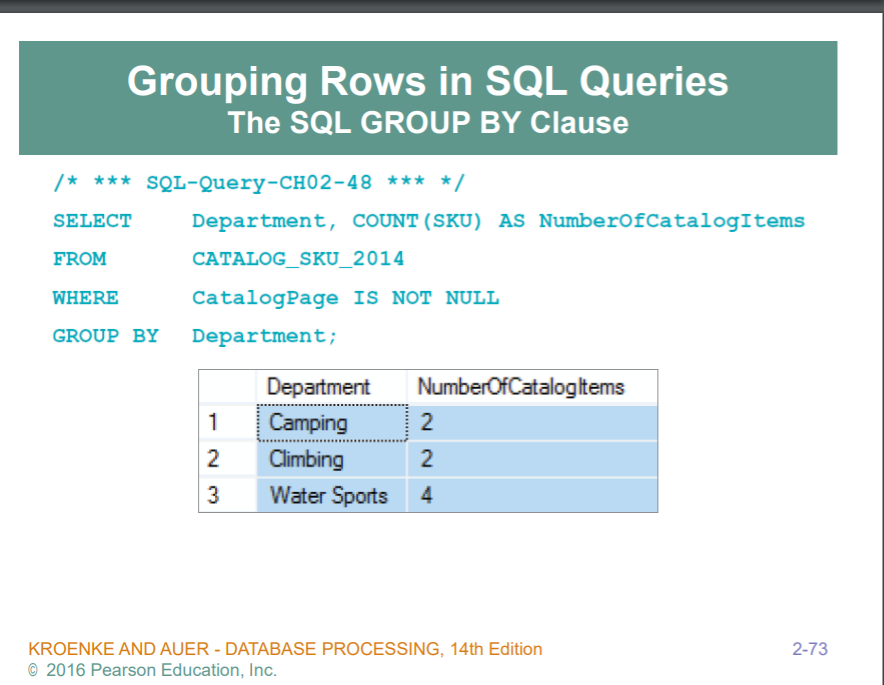
GROUP BY : 지정한 column 별로 뭔가의 작업을해서 보여달라.. 예시에선 department 별로 sku를 카운트해달라
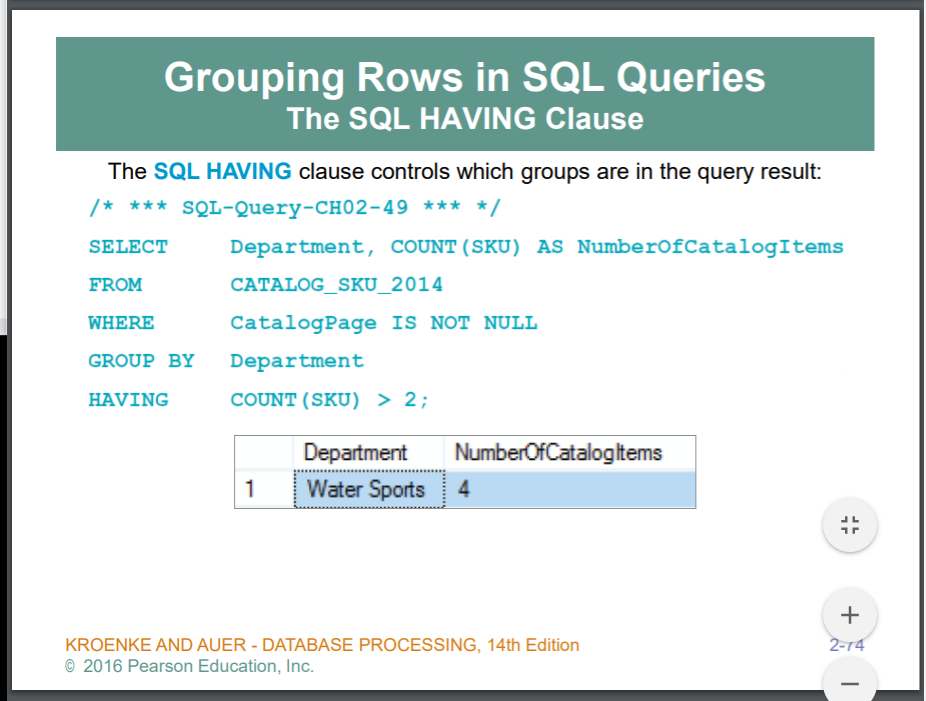
결과물에서의 필터.. >> HAVING
09.17
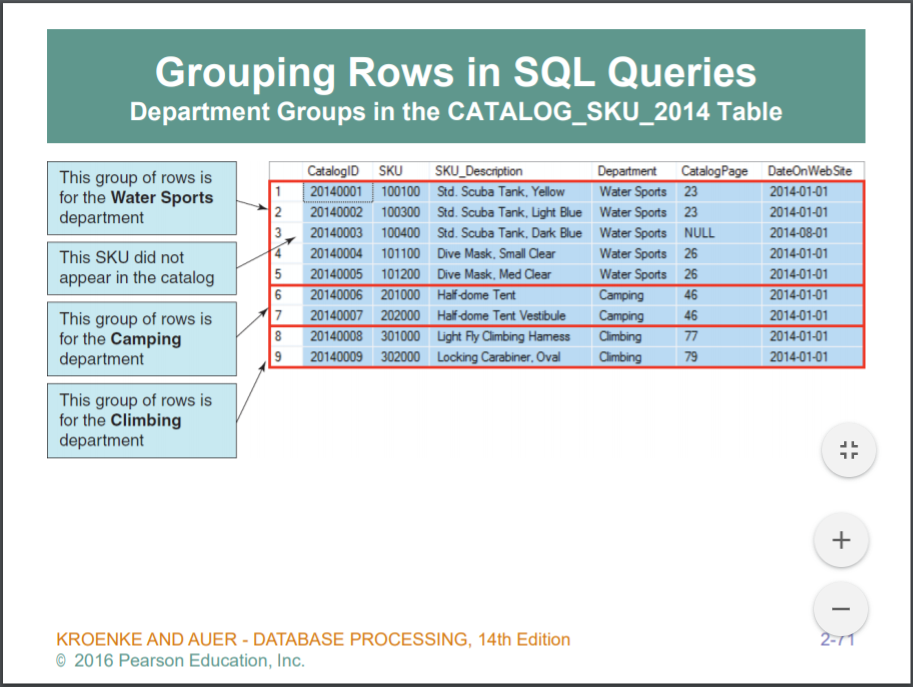
department 로 group by 하면 , 3개의 행을 지니는 테이블이나온다..


WHERE 절이 있다면, 그 다음에 HAVING을 써라
