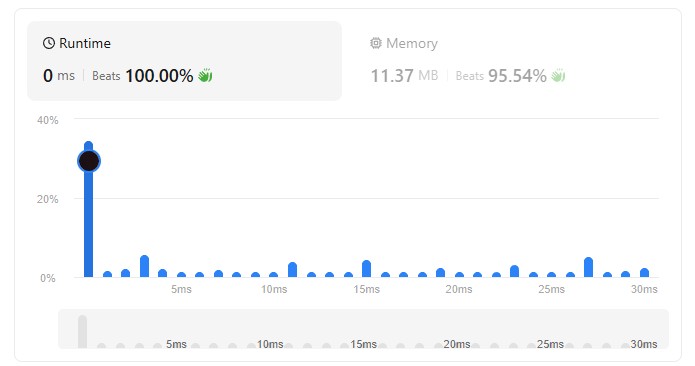
문제
주어진 요리의 만족도(satisfaction) 배열을 활용해서, 만족도 조리 시간(순서)의 총합이 최대가 되도록 요리 순서를 정하거나 특정 요리를 포기하는 문제.
문제 분석
- 정렬의 필요성: 만족도가 큰 요리일수록 나중(후반)에 조리해야 시간 곱셈(Time Multiplier)이 커져 총합이 최대화됨. 따라서 오름차순 정렬은 필수.
- 음수 값의 활용 전략: 만족도가 음수인 요리라도, 얘를 먼저 조리해서 시간을 소모하면 뒤에 나오는 큰 양수 요리들의 조리 시간을 뒤로 미뤄 가중치를 높이는 역할을 할 수 있음. 당장의 손해보다 뒤에서 얻는 이득이 크다면 조리하는 게 이득.
알고리즘
1. 동적 계획법 (Dynamic Programming)
DP 풀이로 나아가는 도출 과정은 다음과 같다.
Step 1: Naive (완전 탐색 - )
각 요리 를 현재 시간 에 조리할지 말지 결정하는 재귀 함수 GetMaxSum(i, t)를 생각할 수 있다.
- 조리하는 경우 (Cook): 현재 요리의 가치(
satisfaction[i] * t)를 더하고, 다음 요리는 시간 에 확인해야 함satisfaction[i] * t + GetMaxSum(i + 1, t + 1) - 조리하지 않는 경우 (Don't Cook): 가치를 더하지 않고, 다음 요리를 현재 시간 에 그대로 확인해야 함
GetMaxSum(i + 1, t) - 한계: 매 요리마다 2가지 선택지가 강제되므로 트리 형태로 분기되어 의 시간 복잡도를 가짐.
Step 2: 2차원 DP 고안 (dp[i][t] - )
완전 탐색을 진행하다 보면 GetMaxSum(20, 16)처럼 동일한 요리 인덱스 와 시간 의 조합이 여러 번 중복 호출되는 문제가 발생(Overlapping Subproblems). 이를 막기 위해 계산 결과를 테이블에 저장하는 2차원 DP를 도입할 수 있다.
dp[i][t]정의: 번째 요리부터 마지막 요리까지 고려했을 때, 현재 시간이 일 때 얻을 수 있는 최대 만족도.- 마지막 요리부터 거꾸로 계산해 오는 Bottom-up 방식을 쓰면 점화식은 아래와 같아짐.
int cook = satisfaction[i] * t + dp[i + 1][t + 1];
int dontCook = dp[i + 1][t];
dp[i][t] = max(cook, dontCook);
- 이 상태에서는 탐색 범위가 요리 개수 최대 시간 이 되어 시간 복잡도가 으로 줄어들지만, 공간 복잡도 역시 을 차지하게 된다.
Step 3: 1차원 공간 최적화 (dp[t] - 공간 )
2차원 점화식을 다시 보면 아주 중요한 특징이 있다. dp[i][t]를 구하기 위해 필요한 값은 오직 바로 다음 행인 i + 1행의 값들(dp[i+1][t+1], dp[i+1][t])뿐이다. 즉, 이전의 모든 행을 메모리에 유지할 필요 없이 바로 직전에 계산된 하나의 행 정보만 있으면 테이블을 하나로 압축할 수 있다.
따라서 테이블을 1차원 dp[t]로 줄이고, 시간 루프를 1부터 n까지 순방향(오름차순)으로 돌리면 된다.
dp[t] = max(satisfaction[di] * t + dp[t + 1], dp[t])연산을 수행할 때:- 우변에 있는
dp[t + 1]은 아직 이번 회차()에서 갱신되기 전의 값, 즉 이전 행()의 값. (가 커지는 방향으로 루프를 도니까 은 미래에 바뀔 값이지 지금은 이전 행의 유산임) - 우변의
dp[t]역시 아직 갱신 전이므로 이전 행()의 값.
- 따라서 루프를 앞에서부터 돌려도 이전 행의 데이터가 오염되지 않고 고스란히 활용되기 때문에, 임시 변수나 2차원 배열 없이도
dp[i][t] = max(dp[i+1][t+1]..., dp[i+1][t])로직이 완벽하게 성립. 최종적으로 공간 복잡도를 까지 극적으로 줄이게 됨.
2. 탐욕 알고리즘 (Greedy)
- 원리: 배열을 정렬한 뒤, 가장 만족도가 높은 맨 뒤의 요리부터 앞으로 역순회하면서 누적합을 구하는 방식.
- 수학적 접근: 앞에 새로운 요리를 하나 추가하면, 그전에 추가해 뒀던 모든 요리들의 조리 시간이 1씩 밀리게 된다. 이건 곧 이전에 선택한 요리들의 만족도 총합(
total)을 결과값(rst)에 한 번 더 더한다는 의미다. - 조건: 따라서 현재 요리의 만족도(
satisfaction[i])와 지금까지 모은 요리 만족도의 합(total)을 더했을 때 0보다 크다면(total + satisfaction[i] > 0), 이 요리를 추가하는 게 최종 결과에 무조건 이득
자료구조
- DP 접근법: 크기가 인 1차원 배열
vector<int> dp를 사용해서 각 조리 시간 에 얻을 수 있는 최대 만족도를 저장하고 갱신함. - Greedy 접근법: 별도의 컬렉션 자료구조 없이, 누적합을 저장할
int total과 총합을 계산할int rst같은 스칼라 변수만 써서 메모리를 최소화함.
결과
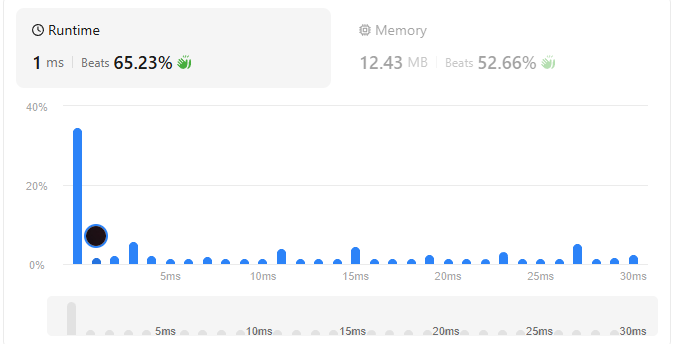
- DP 풀이:
- 시간 복잡도: (정렬에 이 들지만, 이중 for문 연산이 지배적임)
- 공간 복잡도: (1차원 dp 배열 사용)
class Solution {
public:
int maxSatisfaction(vector<int>& satisfaction) {
sort(satisfaction.begin(), satisfaction.end() );
int n = satisfaction.size();
vector<int> dp(n+2, 0);
for ( int di = n - 1; di >= 0; di-- )
{
for ( int t = 1; t <= n; t++)
{
int cook = satisfaction[di]*t + dp[t+1];
int dontCook = dp[t];
dp[t] = max(cook, dontCook);
}
}
return dp[1];
}
};
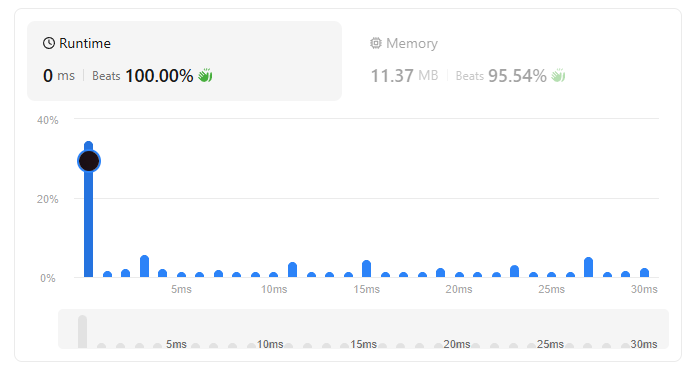
- Greedy 풀이:
- 시간 복잡도: (정렬 시간이 전체 성능을 좌우하고, 순회는 에 끝남)
- 공간 복잡도: (별도의 추가 공간 없이 변수 몇 개만 사용)
class Solution {
public:
int maxSatisfaction(vector<int>& satisfaction) {
sort(satisfaction.begin(), satisfaction.end() );
int n = satisfaction.size();
int rst = 0;
int total = 0;
for ( int i = n -1; i >= 0 && total + satisfaction[i] > 0; i-- )
{
total += satisfaction[i];
rst += total;
}
return rst;
}
};
Other
단순히 "DP로 풀었다"에서 끝내는 게 아니라, 2차원 dp를 1차원 dp로 최적화한 부분이 중요했다. 특히, 왜 내부 루프를 순방향으로 돌려도 이전 행의 값(dp[t+1])이 깨지지 않고 유지되는지 그 인덱스 종속성을 정확히 이해하고 구현한 점이 중요.
