새로 참여하게된 프로젝트에서 채용공고를 크롤링하는 스프린트를 부여받았다.
부트캠프때 한 번 해본 작업이긴하지만, 다시 하려니 오류가 많이났었다.
그래서 이 포스트에서는 크롤링이라는 개념보다는 내가 스프린트를 수행하면서
막혔던 부분을 정리하고자한다.
사람인 채용공고 크롤링
사람인에서 채용공고를 크롤링해오는건 생각보다 간단했다.
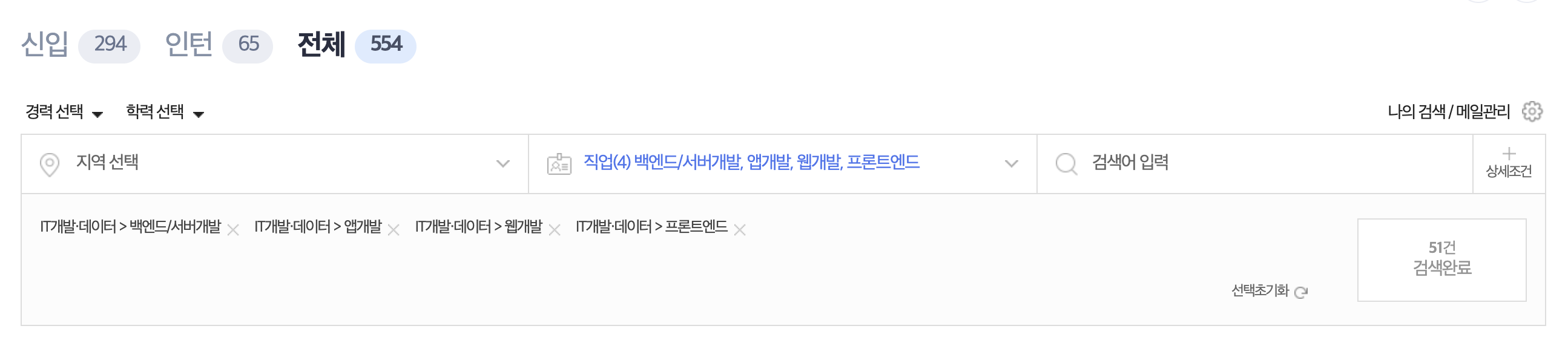
미리 이렇게 카테고리를 선택해두면
이 URL에 지정해둔 카테고리 정보가 남아있어서 따로 Selenium 코드를 작성하지 않고도 카테고리가 저장된 URL을 불러올 수 있어서 귀찮은 작업을 피할 수 있었다.
즉, HTML에서 요소를 찾고, 데이터베이스에 저장하는 코드만 작성하면 됐다.
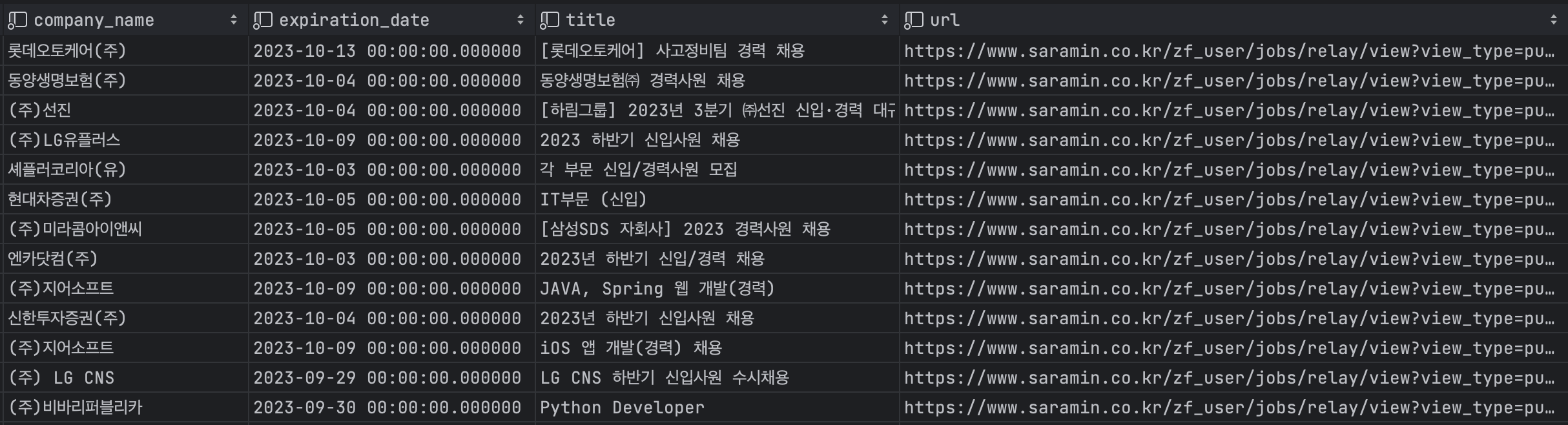
우리는 회사명, 내용, 채용상세URL, 마감기한이 필요했다.
회사명, 내용, URL은 손 쉽게 찾을 수 있었다.
companies = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.list_item .col.company_nm a.str_tit, .list_item .col.company_nm span.str_tit')))
contents = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.list_body .col.notification_info .job_tit .str_tit')))
urls = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.list_body .col.notification_info .job_tit a.str_tit')))물론, 마감기한 정보도 구할 수 있긴 했다.
dates = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.list_body .col.support_info .support_detail .date')))그렇지만 마감기한 정보를 데이터베이스에 저장할 때 문제가 발생하였다.

이런식으로 ~몇월.며칠(요일) 이런식의 데이터도 있었지만,

며칠 남지않는 공고는 이런식으로 D-숫자 형태로 되어있었다.
그래서 하나의 경우의 수로는 날짜를 계산할 수 없었다.
match_d = re.search(r"D-(\d+)", date_text)
match_date = re.search(r"~(\d+\.\d+)\((\w+)\)", date_text)
if match_d:
days_to_add = int(match_d.group(1))
current_date = datetime.now()
calculated_date = current_date + timedelta(days=days_to_add)
date = calculated_date.strftime("%Y-%m-%d")
elif match_date:
month_day, day_of_week = match_date.groups()
current_year = datetime.now().year
date_text = f"{current_year}-{month_day}"
date = datetime.strptime(date_text, "%Y-%m.%d").strftime("%Y-%m-%d %H:%M:%S.%f")그렇기 때문에 조건문을 사용하여 D-숫자 형태와, ~월.일(요일) 형태 두 가지를 모두 읽어오고 맞는 형식으로 처리하도록 하게 하였다.
저렇게 바꾸고나니 사람인의 채용공고가 데이터베이스에 잘 저장되는것을 확인할 수 있었다.
잡코리아 채용공고 크롤링
사람인과 다르게 잡코리아는 URL에 선택한 카테고리가 저장되지 않았다..
그래서 Selenium으로 일일이 카테고리를 선택하는 코드를 작성해야했다.
duty_btn = driver.find_element(By.CSS_SELECTOR, 'p.btn_tit')
duty_btn.click()
dev_data_label = driver.find_element(By.CSS_SELECTOR, 'label[for="duty_step1_10031"]')
dev_data_label.click()
backend_dev = driver.find_element(By.XPATH, '//span[contains(text(), "백엔드개발자")]')
backend_dev.click()
frontend_dev = driver.find_element(By.XPATH, '//span[contains(text(), "프론트엔드개발자")]')
frontend_dev.click()
web_dev = driver.find_element(By.XPATH, '//span[contains(text(), "웹개발자")]')
web_dev.click()
app_dev = driver.find_element(By.XPATH, '//span[contains(text(), "앱개발자")]')
app_dev.click()
career_btn = driver.find_element(By.XPATH, '//p[contains(text(), "경력")]')
career_btn.click()
newbie_label = driver.find_element(By.XPATH, '//label[contains(@for, "career1") and .//span[text()="신입"]]')
newbie_label.click()
search_button = driver.find_element(By.ID, 'dev-btn-search')
search_button.click()위 처럼 일일이 카테고리를 하나하나 클릭해서 검색하는 코드를 작성해주었다.
그 후, 사람인과 동일하게 HTML요소를 찾아서 회사명, 내용, 마감기한, 채용정보URL을 찾고, 출력해봤다.
그런데.. 또 마감기한이 출력이 안됐다.





사람인보다 훨씬 다양했다..😰
이번에도 역시 조건문을 사용하여 처리하였다.
date_match = re.search(r"~(\d{2}/\d{2})\((\w+)\)", date_text)
if date_match:
month_day, day_of_week = date_match.groups()
current_year = datetime.now().year
date_text = f"{current_year}-{month_day}"
expiration_date = datetime.strptime(date_text, "%Y-%m/%d")
elif "오늘마감" in date_text:
expiration_date = datetime.now()
elif "내일마감" in date_text:
expiration_date = datetime.now() + timedelta(days=1)
elif "모레마감" in date_text:
expiration_date = datetime.now() + timedelta(days=2)
elif "상시채용" in date_text:
expiration_date = datetime.now() + timedelta(days=365)
else:
expiration_date = None동일한 오류가 contents에서도 발생했었다.
contents = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'td.tplTit strong a.link.normalLog')))이 코드인데, 지금 보면 'td.tplTit strong a.link.normalLog' 이러한 CSS를 찾아서 요소들을 불러온다고 되어있다.
그런데 잡코리아의 여러가지 요소를 찾아본 결과
<a href="/Recruit/GI_Read/42953829?rPageCode=SL&logpath=21" class="link normalLog" title="[주5일/3시 퇴근] 보상처리 담당자 모집" data-clickctgrcode="B02" target="_blank" onclick="GA_Event('상세검색_PC', '채용공고', '디비손해보험_[주5일/3시 퇴근] 보상처리 담당자 모집')">[주5일/3시 퇴근] 보상처리 담당자 모집</a>이런식으로 link normalLog 클래스 안에 들어있는 경우도 있었지만
<a href="https://www.gamejob.co.kr/List_GI/GIB_Read.asp?GI_No=233219" class="link" target="_blank">[퍼즐원스튜디오] 모바일 캐주얼 퍼즐게임 서버 프로그래머 인턴 (채용연계형)</a>이렇게 그냥 link 클래스 안에 들어있는 경우도 있었다.
그래서
content = contents[i].get_attribute("title")
if not content:
content = contents[i].text.strip()contents도 조건문을 사용하여 title이라는 요소가 없으면, 텍스트에서 추출하게 바꾸었다.
이렇게 바꾸고 나니 데이터베이스에 잘 저장되는 것을 확인할 수 있었다.
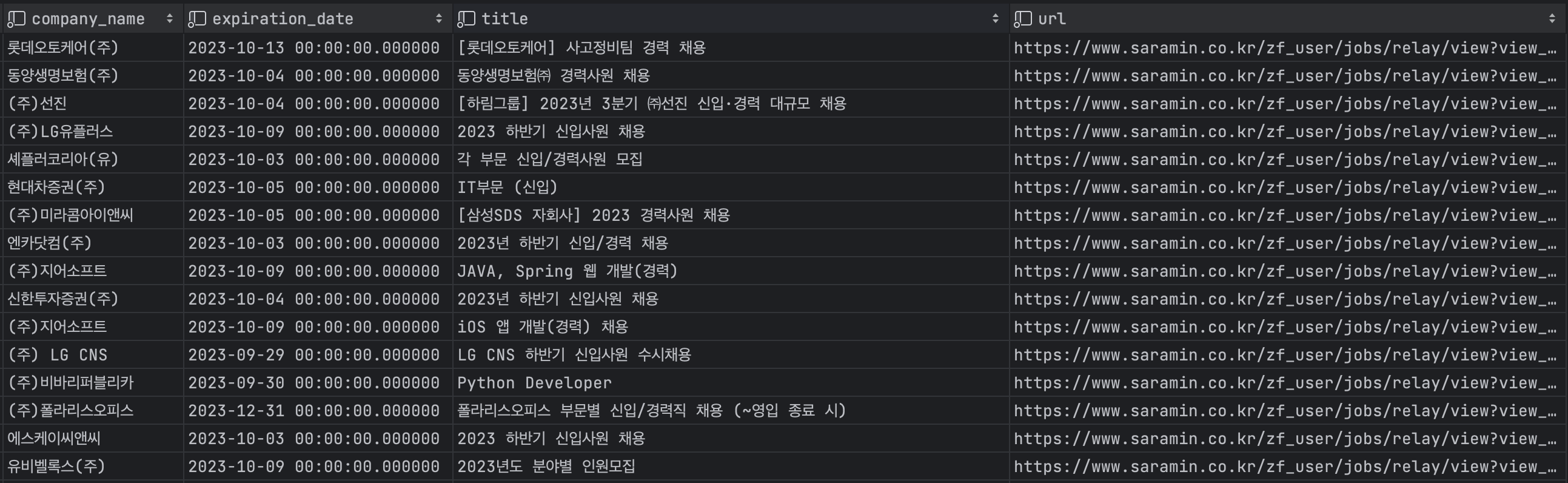
이로써 사람인, 잡코리아 두 개의 사이트에서 채용공고를 크롤링하는 코드가 작성되었다.
