
나는 개인적으로 회사의 데이터 관리를 위해 테이블 명세서를 생성하고 관리하는 것은 매우 중요하다고 생각한다.
테이블 명세서는 개발자, 기획자, 회사의 다른 이해관계자들이 회사에서 관리하는 데이터를 빠르고 구체적으로 파악할 수 있게 해주는 핵심 문서이다. 그리고 유지보수나 시스템 확장 시에도 정확한 정보를 제공해 오류를 방지하고 효율적인 협업을 가능하게 한다.
이러한 테이블 명세서를 일일이 수동으로 업데이트하는 대신, 자동화를 통해 주기적으로 업데이트하여 시간을 절약하고자 해당 프로젝트를 진행했다.
😐 문제 상황
- 기존 테이블 명세서들은 각 플랫폼 별로 Excel 파일로 관리되고 있었다.
- DB구조가 변경(필드 생성&삭제 등)될 때마다 매번 테이블 명세서를 수동으로 업데이트 해야하는 번거로움이 있음
- DB에 포함된 테이블들을 한눈에 파악할 수 있는 파일이 있으면 어떨까..?
따라서 Google Sheets에서 테이블 명세서(Data Catalog) 작업을 더 빠르고 효율적으로 진행하기 위해 Google Sheets API를 활용하여 시트(sheet)를 쉽게 추가하고 업데이트할 수 있는 프로젝트를 기획했다.
Google Sheet API 란
코드 상에서 구글 스프레드시트를 조작하여 스프레드시트를 읽고 수정하고 삭제할 수 있는 인터페이스이다.
※ 아래 글을 참고하여 설정 했다.
Google Sheets API를 통해 스프레트시트 읽기/쓰기
파이썬으로 구글 스프레드시트 편집 자동화하기 3단계
Data Catalog 생성 자동화
- DB 존재하는 table 각각의 google sheet 파일 생성
- table google sheet 내에 information_schema.columns 일부 컬럼과 row 삽입
- 각 table google sheet link들을 master google sheet에 리스트업
- 위 모든 작업을 코드/함수화
결과
1️⃣ Master Sheet (DB명세)
💡 DB별 테이블명, 테이블 설명, 데이터 수, 컬럼 수를 알 수 있다.

- TABLE_SCHEMA : 운영 서버 DB명
- TABLE_NAME : 테이블명
- ROW_COUNT : 데이터 수
- COLUMN_COUNT : 컬럼 수
- TABLE_DESCRIPTION : 테이블 설명란
- TABLE_SHEET : 테이블 명세서 구글 스프레트 시트 링크
관련 쿼리
SELECT TABLE_NAME, TABLE_ROWS, TABLE_COMMENT
FROM information_schema.tables
WHERE TABLE_SCHEMA = '{dbName}' ORDER BY TABLE_NAME;// Column Count 구할 때 필요한 쿼리
SELECT TABLE_NAME, COLUMN_NAME
FROM information_schema.columns
WHERE table_schema='{dbName}' ORDER BY TABLE_NAME;2️⃣ Table Sheet (Table명세)
💡 table별 테이블명, 필드 정보들을 알 수 있다.
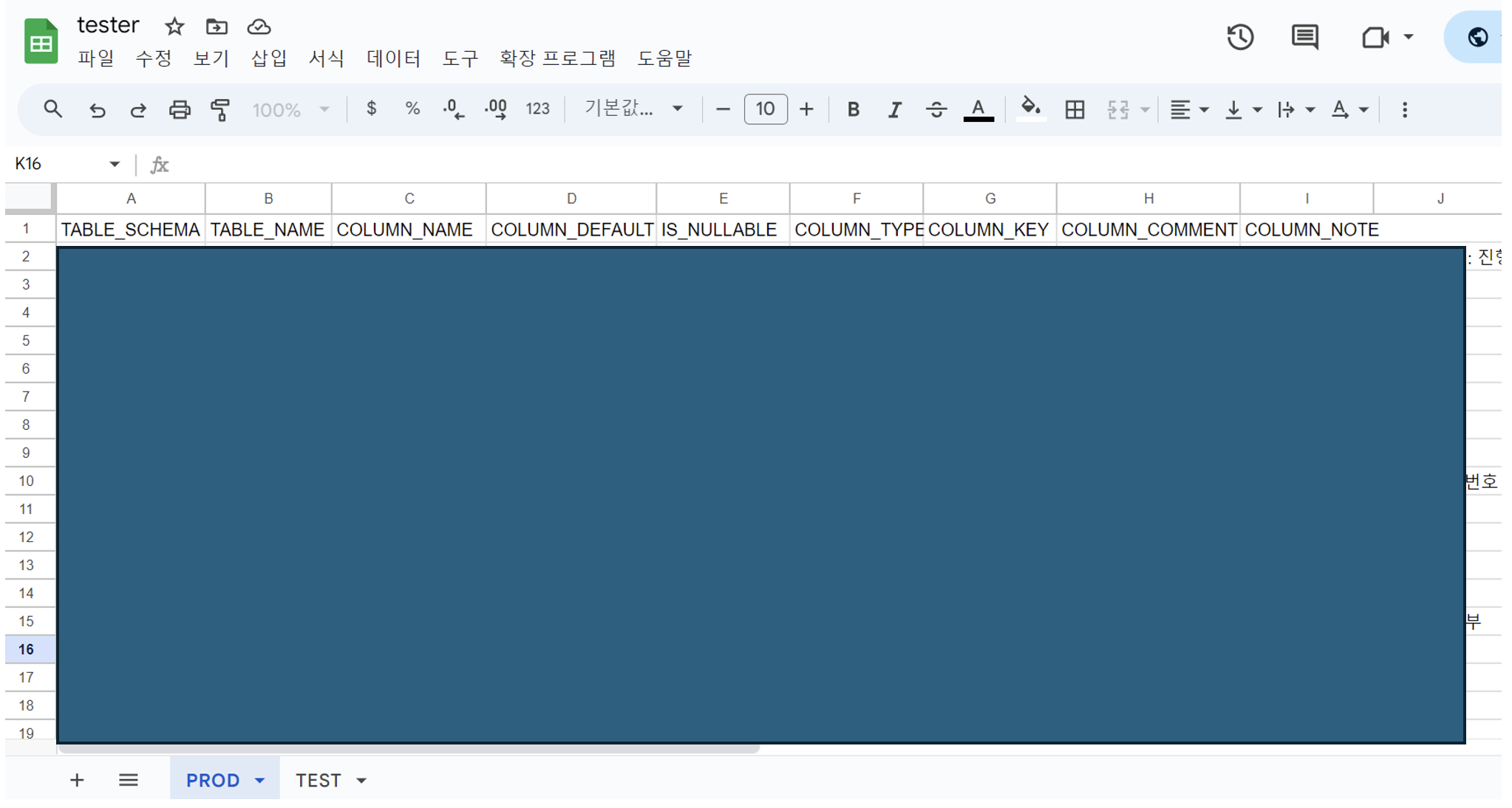
- COLUMN_NAME : 컬럼명
- COLUMN_DEFAULT : 컬럼 기본 값
- IS_NULLABLE : Null 값 허용 여부
- COLUMN_TYPE : 컬럼 타입
- COLUMN_KEY : 컬럼 Key 정보 (PRI, MUL, UNI)
- COLUMN_COMMENT : 컬럼 정보
- COLUMN_NOTE : 컬럼 정보 (COLUMN_COMMENT가 비었을 경우에 수동으로 작성)
관련 쿼리
SELECT TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, COLUMN_DEFAULT, IS_NULLABLE, COLUMN_TYPE, COLUMN_KEY, COLUMN_COMMENT
FROM information_schema.columns
WHERE TABLE_SCHEMA = '{dbName}' ORDER BY TABLE_NAME;파이프라인
- DB의 테이블 구조가 업데이트 되었을 때(컬럼 추가), 사용자는 Test server → catalog 컨테이너에 접속하여 main.py를 실행하여 변경된 사항을 table sheet에 반영해준다.
- (Flask) 매일 새벽 6시마다 python의 scheduler를 이용하여 주기적으로 Master sheet를 업데이트한다
Flowchart
Table Sheets
Master Sheets
Code (+Process)
- 사용 언어 : 파이썬
→ Dataframe을 다루기 용이함
1. Maria DB ↔ Python
pymysql을 사용해서 DB와 python 연결, 쿼리 결과를 pandas dataframe으로 받는다.
# prod db에 연결하는 함수
def connectProdDB(companyName):
dbInfo = openDBInfo()
connect = pymysql.connect(
host = dbInfo[f'{companyName}_PROD_DB']['HOST'],
port = dbInfo[f'{companyName}_PROD_DB']['PORT'],
user = dbInfo[f'{companyName}_PROD_DB']['USERNAME'],
password = dbInfo[f'{companyName}_PROD_DB']['PASSWORD'],
use_unicode = True,
charset = 'utf8',
cursorclass=pymysql.cursors.DictCursor
)
cursor = connect.cursor()
return cursor
cursor = connectProdDB(companyName)
cursor.execute(query)
res = cursor.fetchall()
df = pd.DataFrame(res)2. Google Sheets API 사용 준비
위 설정글 참고
3. GSpread 라이브러리
gspread는 Google Sheets를 위한 라이브러리로, 쉬운 사용법이 장점이다.
https://docs.gspread.org/en/latest/user-guide.html
# -- 사용 예시 --
# 인증
gc = gspread.authorize(credentials)
# Create
gc.create('sheet_name', folder_id = 'folder_id')
# Open - open / open_by_key / open_by_url
worksheet = gc.open('sheet_name').worksheet('Sheet1')
# update
worksheet.update('A1', [[1, 2], [3, 4]])4. Google sheet 파일 생성
4.1 dataframe 삽입
gspread_dataframe라이브러리의set_with_dataframe함수로 worksheet에 dataframe(쿼리 결과) 삽입- gspread_dataframe
set_with_dataframe(worksheet, dataframe)4.2 Create sheet
newSheetFile = gc.create(tableName, folder_id = folderId)
prodSheet = newSheetFile.sheet1
prodSheet.update_title("PROD")
# 시트에 DF 삽입
set_with_dataframe(worksheet = prodSheet, dataframe = df[df['TABLE_NAME'] == tableName])
# 새로 생성된 sheet의 ID 추가
sheetId = newSheetFile.id
idDict = openSheetIdInfo(dbName)
idDict[tableName] = sheetId
addSheetIdAndSave(dbName, idDict)5. Update Data Catalog
5.1 기존 sheet와 비교
# folder에 존재하는 각 sheet의 id와 name을 가져온다.
results = driveService.files().list(q=f"'{folderId}' in parents and trashed=false", fields="files(id, name)").execute()
items = results.get('files', [])
df['COLUMN_NOTE'] = np.nan
for tableName in tqdm(df.TABLE_NAME.unique()):
existingFile = None
itemsCopy = items.copy()
for item in items:
if item['name'] == tableName:
existingFile = item # item에 없는 것이 df에 있을 때 → 파일 추가
itemsCopy.remove(item)
break5.2 기존 Sheet의 데이터 가져오기
gspread_dataframe라이브러리의get_as_dataframe함수로 worksheet에 dataframe(쿼리 결과) 삽입
prodSheet = gc.open_by_key(existingFile['id']).get_worksheet(0)
existingDF = get_as_dataframe(prodSheet)5.3 업데이트 수행
# 1. item에 있는데 df.TABLE_NAME에 없음 -> existingFile = None (삭제된 테이블)
# 2. item에 없는데 df.TABLE_NAME에 있음 -> existinfFile = None (새로 추가된 테이블)
# 3. item에 있고 df.TABLE_NAME에 있음 -> existongFile = Exist
# 3
if existingFile:
prodSheet = gc.open_by_key(existingFile['id']).get_worksheet(0)
existingDF = get_as_dataframe(prodSheet).dropna(how = 'all').iloc[:,:9]
# 새로운 컬럼 확인 후 업데이트
newRows = df[(df['TABLE_NAME'] == tableName) & (~df['COLUMN_NAME'].isin(existingDF['COLUMN_NAME']))]
if not newRows.empty:
set_with_dataframe(worksheet = prodSheet, dataframe = newRows, row = existingDF.shape[0] + 2, include_index = False, include_column_header = False)
# 2
else:
newSheetFile = gc.create(tableName, folder_id = folderId)
prodSheet = newSheetFile.sheet1
prodSheet.update_title("PROD")
set_with_dataframe(worksheet = prodSheet, dataframe = df[df['TABLE_NAME'] == tableName])
# sheet ID 딕셔너리 업데이트
sheetId = newSheetFile.id
idDict = openSheetIdInfo(dbName)
idDict[tableName] = sheetId
addSheetIdAndSave(dbName, idDict)
# 1
if len(itemsCopy) != 0:
for item in itemsCopy:
deletingFile = item # df에 없는 것이 item에 있을 떄 → 파일 삭제
driveService.files().delete(fileId = deletingFile['id']).execute()6. Master_data_catalog 생성
# Master Sheet 파일 생성 및 새 워크시트 생성하는 함수 (새 워크시트를 생성하는 경우: 새로운 DB가 추가되었을 떄)
def makeMasterCatalog(orderType, dbName, df, sheetName = "Master_data_catalog", folderId = "1ZSp_OrzjBun9eqXW*************"):
idDict = openSheetIdInfo(dbName)
query = f'''select TABLE_NAME, TABLE_ROWS, TABLE_COMMENT
from information_schema.tables
where table_schema = '{dbName}' order by TABLE_NAME;'''
masterDF = queryReturnDf("PROD", query,'Company1')
masterCatalog = df.groupby(['TABLE_SCHEMA','TABLE_NAME']).agg({
'COLUMN_NAME': lambda x:x.count()
}).reset_index().rename(columns={'COLUMN_NAME':'COLUMN_COUNT'})
masterCatalog['ROW_COUNT'] = masterDF['TABLE_ROWS']
masterCatalog['TABLE_COMMENT'] = masterDF['TABLE_COMMENT']
masterCatalog['TABLE_DESCRIPTION'] = ''
masterCatalog['TABLE_SHEET'] = masterCatalog['TABLE_NAME'].apply(lambda x:"https://docs.google.com/spreadsheets/d/%s" % idDict[x])
masterCatalog = masterCatalog[['TABLE_SCHEMA','TABLE_NAME', 'ROW_COUNT', 'COLUMN_COUNT', 'TABLE_COMMENT','TABLE_DESCRIPTION','TABLE_SHEET']]
gc = getCertified()
if orderType == "CREATE": # Master_data_catalog sheet 파일 생성
newSheet = gc.create(sheetName, folder_id=folderId)
newMasterSheet = newSheet.sheet1
newMasterSheet.update_title(dbName)
else: # "ADD" , # Master_data_catalog sheet의 새로운 worksheet 생성
gc.open(sheetName, folder_id=folderId)
newMasterSheet = gc.open(sheetName).add_worksheet(title=dbName, rows=100, cols=20)
set_with_dataframe(worksheet=newMasterSheet, dataframe=masterCatalog)- 해당 쿼리를 불러와, TABLE_NAME(테이블명), TABLE_ROWS(데이터 수), TABLE_COMMENT(테이블 정보) 데이터를 masterDF에 저장한다.
- df으로부터 COLUMN_COUNT 정보를 얻고, 이를 masterCatalog에 데이터프레임 형식으로 저장한다.
- masterDF에 있는 모든 정보를 masterCatalog으로 옮긴다.
TABLE_SHEET는 DB별 모든 테이블의 sheetID가 저장된 idDict 딕셔너리 데이터를 활용하여, 테이블별 시트 URL을 저장- 가공된 masterCatalog dataframe을 Master-Data-Catalog 시트에 삽입
orderType == “CREATE” : (Master data catalog 파일 없을 시) 새 파일 생성
gc.create(sheetName, folder_id=folderId)orderType == “ADD” : 새 DB가 추가됨에 따른 기존 파일에 새 워크시트 생성
gc.open(sheetName, folder_id=folderId) # 파일명을 sheetName으로
newMasterSheet = gc.open(sheetName).add_worksheet(title=dbName, rows=100, cols=20)
# 워크시트명을 dbName으로7. Update master ROWS_COUNT, COLUMN_COUNT
- master catalog에 존재하는
ROWS_COUNT,COLUMN_COUNT는 수치가 매번 달라질 가능성이 높으므로, 두 컬럼만 업데이트하는 로직을 추가했다, - 새벽 6시마다 배치 실행
7-1. 먼저 테이블 변경사항이 있는지 확인
# 먼저 테이블 변경사항이 있는지 확인
gc = getCertified()
sheet = gc.open(sheetName, folderId).worksheet(dbName)
maxRow = len(sheet.get_all_values()) - 1
masterDF = get_as_dataframe(sheet)[:maxRow]
masterDF = masterDF.drop(columns = [c for c in masterDF.columns if "Unnamed" in c]).dropna(how="all")
query = f'''select TABLE_SCHEMA, TABLE_NAME, TABLE_COMMENT
from information_schema.tables
where TABLE_SCHEMA = '{dbName}' order by TABLE_NAME;
'''
df = queryReturnDf("PROD", query, company)
newRows = df[(df['TABLE_SCHEMA'] == dbName) & (~df['TABLE_NAME'].isin(masterDF['TABLE_NAME']))]7-2. 새로운 테이블 및 삭제된 테이블 확인 후 업데이트
# 새로운 테이블 확인 후 업데이트
if not newRows.empty:
idDict = openSheetIdInfo(dbName)
newRows['ROW_COUNT'] = np.nan
newRows['COLUMN_COUNT'] = np.nan
newRows['TABLE_DESCRIPTION'] = np.nan
newRows['TABLE_SHEET'] = newRows['TABLE_NAME'].apply(lambda x:"https://docs.google.com/spreadsheets/d/%s" % idDict[x])
newRows = newRows[['TABLE_SCHEMA','TABLE_NAME','ROW_COUNT','COLUMN_COUNT','TABLE_COMMENT','TABLE_DESCRIPTION', 'TABLE_SHEET']]
set_with_dataframe(worksheet = sheet, dataframe = newRows, row = masterDF.shape[0] + 2, include_index = False, include_column_header = False)
masterDF = masterDF.append(newRows, ignore_index = True)
# 삭제된 테이블 확인 후 masterDF에서 제거
dfTableNames = df['TABLE_NAME'].tolist()
deletedTables = masterDF[~masterDF['TABLE_NAME'].isin(dfTableNames)]
if not deletedTables.empty:
idDict = openSheetIdInfo(dbName)
# 삭제할 행 번호와 TABLE_NAME 리스트 생성
rowsToDelete = []
for index, row in deletedTables.iterrows():
rowsToDelete.append((index + 2, row['TABLE_NAME']))
for rowNumber, tableName in sorted(rowsToDelete, key=lambda x: x[0], reverse=True):
sheet.delete_rows(rowNumber)
idDict.pop(tableName)
masterDF = masterDF[masterDF['TABLE_NAME'].isin(dfTableNames)]
deleteSheetIDAndSave(dbName, idDict)7-3. ROW_COUNT , COLUMN_COUNT 업데이트
# ROW_COUNT, COLUMN_COUNT 업데이트
rowQuery = f'''select TABLE_NAME, TABLE_ROWS
from information_schema.tables
where table_schema = '{dbName}' order by TABLE_NAME;
'''
cursor = connectProdDB(company)
cursor.execute(rowQuery)
rowRes = cursor.fetchall()
rowCountDict = {}
for i in rowRes:
rowCountDict[i['TABLE_NAME']] = int(i['TABLE_ROWS'])
colQuery = f'''
select TABLE_NAME, COLUMN_NAME
from information_schema.columns
where table_schema='{dbName}' order by TABLE_NAME;
'''
cursor.execute(colQuery)
colRes = cursor.fetchall()
colCountDict = pd.DataFrame(colRes).groupby('TABLE_NAME')['COLUMN_NAME'].count().to_dict()
masterDF['ROW_COUNT'] = masterDF['TABLE_NAME'].apply(lambda x: rowCountDict[x])
masterDF['COLUMN_COUNT'] = masterDF['TABLE_NAME'].apply(lambda x: colCountDict[x])
set_with_dataframe(sheet, masterDF)