
※ 본 글은 "업무에 바로 쓰는 SQL 튜닝" 도서를 학습하며 정리한 글입니다.
🙋🏻♀️ 튜닝 여부를 판단할 때는 짧은 소요 시간만을 기준으로 삼지 않는다. 더 나은 쿼리로 변경할 수 있다면 모두 튜닝 대상이 된다.
프로파일링
시작하기
- 프로파일링 설정값 OFF → ON으로 변경
show variables like 'profiling%';
set profiling = 'ON'실행하기
// 프로파일링된 쿼리 목록 확인 (query id로 구분됨)
show profiles
// 특정 쿼리 ID에 대한 프로파일링된 상세 내용 확인
show profile for query 2- 상세내용은 각 status별 Duration을 확인할 수 있음 (p. 157)
- 만약 특정 status에 해당되는 Duration 값이 높게 나타난다면 문제가 될 소지가 높은 구간
- status 종류
- starting: SQL문 시작
- checking permissions: 필요 권한 확인
- Opening Tables: 테이블 열기
- executing: 실행
등등
- 만약 추가 정보를 확인하고 싶다면(CPU, BLOCK IO 등)
show profile all for query 2
show profile cpu for query 2
show profile block io for query 2SQL문 성능 개선
☝🏻 기본키는 변형하지 말자
- 기본키를 통해 데이터에 빠르게 접근할 수 있다
- 기본키를 가공하여 작성(⇒ 테이블 풀스캔)하는 것보다 기본키 그대로 사용하는 것이 더 좋다.
나쁜 예 0.25초
SELECT * FROM 사원 WHERE SUBSTRING(사원번호,1,4) = 1100좋은 예 0.00초
SELECT * FROM 사원 WHERE 사원번호 BETWEEN 1100 AND 1109☝🏻 형변환은 가급적 피하자
- ‘급여’라는 테이블에는 ‘사용여부’라는 열이 있다고 가정. ‘사용여부’ 열에는 0,1 값이 string (char) 형태로 저장되어있다.
- 문자유형을 숫자유형으로 써서 데이터에 접근할 경우, ‘사용여부’ 인덱스를 제대로 사용하지 못하고 전체 데이터를 스캔
나쁜 예 0.15초
SELECT COUNT(1) FROM 급여 WHERE 사용여부 = 1좋은 예 0.0초
SELECT COUNT(1) FROM 급여 WHERE 사용여부 = '1'☝🏻 중복되는 일이 없다면 UNION 보다는 UNION ALL를 사용해라
(이하 생략)
☝🏻 그룹핑 순서를 주의하라 (인덱스를 고려하자)
- 그룹핑할 때, 꼭 Explain을 사용해서 인덱스명(key)을 확인하자
EXPLAIN
select 성, 성별, count(1) as 카운트 from 사원 group by 성, 성별key : I_성별_성 (해당 인덱스는 성별 열과 성 열 순으로 정렬됨)
⇒ 위 SQL문은 I_성별_성 인덱스의 결과를 다시 ‘성’ 열과 ‘성별’ 열 순으로 재정렬한다 ⇒ 비효율적
개선 코드
select 성, 성별, count(1) as 카운트 from 사원 group by 성별, 성☝🏻 전체 데이터의 과반수 이상을 추출하는 쿼리 ⇒ ignore index를 사용하자
※ 먼저, count와 group by를 이용해서 데이터가 차지하는 비율을 알아보자
나쁜 예 3.7초
select * from 사원출입기록 where 출입문 = 'B'- 위 쿼리는
I_출입문인덱스로 인덱스 스캔을 수행하는데(Explain 참고), 이는 인덱스에 접근한 뒤 테이블에 랜덤 엑세스하는 방식이다. - 전체 데이터의 약 50%에 달하는 데이터를 조회하려고 인덱스를 활용하는 것이 과연 효율적일까
좋은 예 0.85초
select * from 사원출입기록 ignore index(I_출입문) where 출입문 = 'B'- 내부 실행되는 인덱스를 무시할 수 있도록(즉, 인덱스를 사용하지 않도록) IGNORE INDEX를 사용하자
☝🏻 범위 조건을 사용할 때 고려할 점
- 전체의 약 17%에 해당하는 데이터를 가져올 때, 과연 인덱스를 사용하는 것이 효율적일지 확인해야함
- 만약, 입사일자 기준으로 매번 수 년에 걸친 데이터를 조회하는 경우가 잦다면, 인덱스 스캔보다는 테이블 풀 스캔 방식(인덱스 없이 테이블에 직접 접근)을 설정하는 것이 더 나을 것이다.
나쁜 예 1.21초
select 이름, 성 from 사원
where 입사일자 between STR_TO_DATE('1994-01-01', '%Y-%m-%d')
and STR_TO_DATE('2000-01-01', '%Y-%m-%d')좋은 예 0.2초
select 이름, 성 from 사원 where YEAR(입사일자) between '1994' and '2000'- where 조건을 위와 같이 가공하여
I_입사일자인덱스를 사용하지 못하도록 했다. - 테이블에 직접 접근하면, 한번에 다수의 페이지에 접근하므로 더 효율적
☝🏻 작은 테이블이 먼저 조인에 참여하는 나쁜 SQL문
- 조인 쿼리일 경우, Explain을 통해서 각 테이블의 행 수(row)를 비교해보자
- 상대적으로 규모가 큰 테이블의 조건절을 먼저 적용한다면, 조인할 때 비교 대상이 줄어들 것
- STRAIGHT_JOIN : from 절에 작성된 테이블 순서대로 조인에 참여할 수 있도록 고정
나쁜 예 13.2초
select 매핑.사원번호, 부서.부서번호 from 부서사원_매핑 매핑, 부서
where 매핑.부서번호 = 부서.부서번호 and 매핑.시작일자 >= '2022-03-01'- STRAIGHT_JOIN이 없어서 랜덤으로 조인 테이블 순서가 정해짐
좋은 예 0.17초
select STRAIGHT_JOIN 매핑.사원번호, 부서.부서번호 from 부서사원_매핑 매핑, 부서
where 매핑.부서번호 = 부서.부서번호 and 매핑.시작일자 >= '2022-03-01'- STRAIGHT_JOIN을 사용했기 때문에, 고정적으로 매핑 → 부서 테이블 순으로 조인
- 상대적으로 대용량인 매핑 테이블을 테이블 풀 스캔으로 처리하고, 부서 테이블에는 기본키로 반복 접근하여 1개의 데이터(조인 후 조회되는 부서 테이블 데이터 row 수)에만 접근하는 식으로 수행 (Explain 참고)
☝🏻 서브쿼리 VS 조인
- 조인이 더 성능에 유리하다
나쁜 예
select ~ from ~ where ~ and (select max(연봉) from 급여 where 사원번호 ...)좋은 예
select ~ from ~ where ~
group by ~
having max(급여.연봉) > 1000000☝🏻 존재여부만 파악하고자 할 때는 EXISTS를 사용하자
- 최종 결과에 사용하지 않고 단지 존재 여부만 파악하려고 할 때
나쁜 예
select count(distinct 기록.사원번호) as 데이터건수
from 사원, (select 사원번호 from 기록 where 출입문 = 'A') 기록
where 사원.사원번호 = 기록.사원번호- 기록 테이블의 사원번호는 사원 테이블과 조인을 수행하는 과정 중에 값의 존재 여부만 알면 된다.
좋은 예
select count(1) as 데이터건수
from 사원 where EXISTS (select 1 from 기록
where 출입문 = 'A' and 기록.사원번호 = 사원.사원번호)- 출입문 A에 관한 기록이 있는 사원번호에 대해 조인을 수행한 뒤, 해당하는 데이터만 집계
☝🏻 처음부터 모든 데이터를 가져오는 나쁜 SQL문 - 스칼라 서브 쿼리
- 스칼라 서브 쿼리를 이용해보자
나쁜 예
select 사원.사원번호, 급여.평균연봉, 급여.최고연봉, 급여.최저연봉
from 사원, (select 사원번호, ROUND(AVG(연봉),0) 평균연봉
ROUND(MAX(연봉),0) 최고연봉
ROUND(MIN(연봉),0) 최저연봉
from 급여 group by 사원번호) 급여
where 사원.사원번호 = 급여.사원번호 and 사원.사원번호 between 10001 and 10100
좋은 예
select 사원, 사원번호,
(select ROUND(AVG(연봉),0) from 급여 as 급여1 where 사원번호 = 사원.사원번호) as 평균연봉,
(select ROUND(MAX(연봉),0) from 급여 as 급여2 where 사원번호 = 사원.사원번호) as 최고연봉,
(select ROUND(MIN연봉),0) from 급여 as 급여3 where 사원번호 = 사원.사원번호) as 최저연봉
from 사원
where 사원.사원번호 between 10001 and 10100- where 절을 먼저 수행하여 100건의 데이터만 가져온다. → 이후, 필요한 사원정보에만 접근한 뒤, 급여 테이블에서 평균연봉, 최고연봉, 최저연봉을 각각 구한다.
- 급여 테이블에 3번을 접근하지만, where 절에서 추출하려는 사원 테이블의 데이터가 사원 테이블의 전체 데이터 대비 극히 소량에 불과하므로 인덱스를 활용해 수행하는 3번의 스칼라 서브 쿼리는 많은 리소스를 소모하지 않는다.
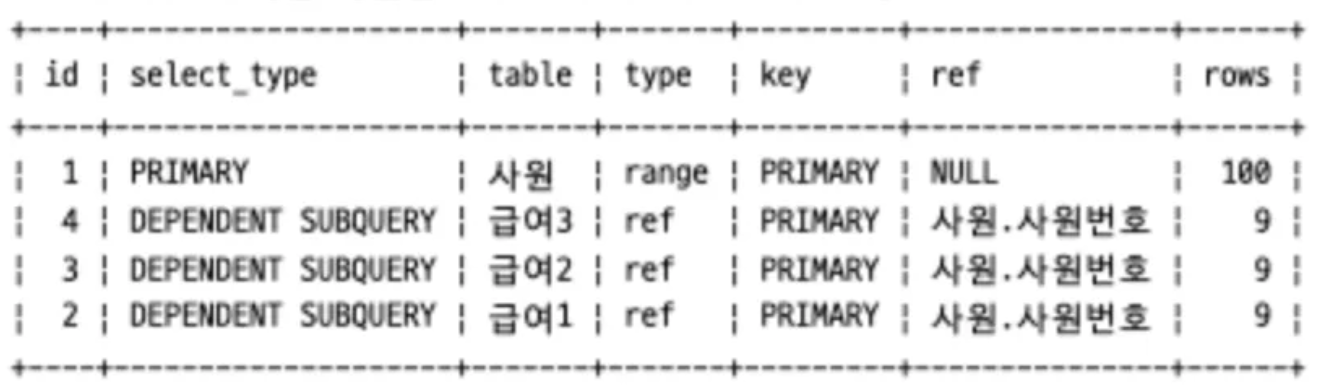
☝🏻 LIMIT를 적절히 활용하여 비효율적인 페이징을 막자
나쁜 예
select 사원.사원번호, 사원.이름, 사원.성, 사원.입사일자
from 사원, 급여
where 사원.사원번호 = 급여.사원번호 and 사원.사원번호 between 10001 and 50000
group by 사원.사원번호
order by SUM(급여.연봉) desc
LIMIT 150,10 // 150번째부터 10건- 전체 데이터를 가져온 뒤 마지막으로 소수 건(예: 10건)의 데이터만 조회하는 방식은 비효율적
좋은 예
select 사원.사원번호, 사원.이름, 사원.성, 사원.입사일자
from (select 사원번호 from 급여
where 사원번호 between 10001 and 50000
group by 사원번호
order by SUM(급여, 연봉) desc
LIMIT 150,10) 급여, 사원
where 사원.사원번호 = 급여.사원번호- 그룹핑 작업과 정렬 작업을 FROM 절의 인라인 뷰로 작성
- 인라인 뷰에 필요한 데이터 건수만큼 LIMIT 절로 제약을 설정하여 사원 테이블과 조인할 수 있는 데이터 건수를 줄일 수 있다.
☝🏻 조인하기 전, 미리 중복을 제거하자
- 수십만 개의 데이터를 조인하기 전에 미리 중복 제거를 할 수는 없을지 고민해봐야함
나쁜 예
select distinct 매핑.부서번호 from 관리자, 매핑
where 관리자.부서번호 = 매핑.부서번호 order by 매핑.부서번호- distinct으로 최종 부서번호 결과에서 중복을 제거하고 order by로 오름차순 정렬
- 위 쿼리의 실행계획(explain)을 보면 매핑의 Row는 331143개, 관리자는 2개이다
⇒ 두 테이블 모두 데이터에 접근한 뒤 부서번호가 같은지 일일이 확인하는 작업이 과연 필요할까?
좋은 예
select 매핑.부서번호 from (select distinct 부서번호 from 매핑) 매핑
where EXISTS (select 1 from 관리자 where 부서번호 = 매핑.부서번호)
order by 매핑.부서번호- from 절에서 매핑 테이블의 데이터를 가져올 때 부서번호 데이터를 미리 중복제거
- 이렇게 가벼워진 매핑 테이블의 데이터에 대해 관리자 테이블은 같은 부서번호 데이터가 있는지 여부만 판단
- 굳이 관리자 테이블의 데이터를 모두 확인하지 않아도 동일한 부서번호가 있다면, 이후의 데이터에는 더 접근하지 않는 EXISTS 연산을 활용
⇒ 중복 제거를 미리 수행하고, select 절에서 활용하지 않는 관리자 데이터는 존재여부만 판단하기
☝🏻 인덱스를 활용하자
예시 쿼리
select * from 사원 where 이름 = 'George' and 성 = 'Wielonsky'- 단 1건의 데이터를 가져오기 위해 테이블을 처음부터 끝까지 스캔(테이블 풀 스캔)하는 방식은 비효율적
- 위와 같은 쿼리가 자주 호출될 경우 인덱스를 활용하는 것을 추천
- ‘이름’ 열에는 1275개 데이터가 있고 ‘성’ 열에는 1637개 데이터가 있음 → 데이터 범위를 더 축소할 수 있는 ‘성’ 열을 선두 열로 삼아 인덱스를 생성
※ 인덱스 생성 전, 위 쿼리의 인덱스(key)는 null로 확인
인덱스 생성
alter table 사원 add index I_사원_성_이름 (성,이름)인덱스 생성 확인
show index from 사원☝🏻 인덱스를 여러개 활용하자
예시 쿼리
select * from 사원 where 이름 = 'Matt' or 입사일자 = '1997-03-31⇒ 전체 30만건 중, 330건 출력
- 실행계획(explain)을 통해 인덱스(key)를 확인해보자 → Null
- 조건절에 해당하는 데이터 분포를 확인해보자
select count(*) from 사원; // 300024
select count(*) from 사원 where 이름 = 'Matt'; // 233
select count(*) from 사원 where 입사일자 = '1997-03-31'; // 111- 위와 같이 소량의 데이터를 가져올 때는 보통 테이블 풀 스캔보다 “인덱스 스캔”이 효율적
show index를 통해 조건절 열이 포함된 인덱스가 존재하는지 확인 ⇒ I_입사일자 인덱스는 있지만, ‘이름’ 열이 포함된 인덱스는 보이지 않음 ⇒ ‘이름’ 열에 대한 인덱스 추가 필요
ALTER TABLE 사원 ADD INDEX I_이름(이름);☝🏻 업데이트 작업 시, 인덱스는 걸림돌이 될 수 있다.
-
큰 규모의 데이터 업데이트에 한해서.
-
Update 문은 수정할 데이터에 접근한 뒤에 set 절의 수정 값으로 변경하므로, 인덱스로 데이터에 접근한다는 측면에서 인덱스의 존재 여부는 중요하다.
-
조회한 데이터를 변경하는 범위에는 테이블 뿐만 아니라 인덱스도 포함되므로, 인덱스가 많은 테이블의 데이터를 변경할 때는 성능적으로 불리하다
-
※ 총 업데이트된 데이터 개수를 알고 싶다면,
select @@autocommit;: 1 이면 자동 커밋, 0이면 자동 커밋X- 0으로 설정하라 (
set autocommit = 0;)
- 0으로 설정하라 (
예시 쿼리
update 출입기록 set 출입문 = 'X' where 출입문 = 'B';set 출입문 = ‘X’이므로 “출입문” 열을 포함하는I_출입문인덱스의 튜닝 여부를 고민해보자- 새벽 또는 서비스에 미칠 영향이 적은 시간대에 업데이트 작업이 이루어진다면, 해당 인덱스를 일시적으로 삭제한 뒤 대량 업데이트 작업을 수행해보자
ALTER TABLE 출입기록 DROP INDEX I_출입문;결과
30초 → 2초 (30만건 데이터가 업뎃 되었을 때)
☝🏻 인덱스(명) 순서를 바꿔보자
예시 쿼리
select 사원번호, 이름, 성 from 사원 where 성별 = 'M' and 성 = 'Baba';- 튜닝 전 : 성별+성 순서로 구성된
I_성별_성인덱스를 활용하여 데이터에 접근하고 있다. - 성 데이터 개수 : 1637건 , 성별 데이터 개수 : 2
⇒ 과연 데이터가 다양하지 않은 성별 열을 선두로 구성한 인덱스가 효율적일까..?
성별 열보다 성 열이 더 다양한 종류의 값을 가지므로 “성” 열을 먼저 활용하면 데이터 접근 범위를 줄일 수 있다.
- 튜닝 : 성+성별 순서로 구성된
I_성_성별인덱스로 변경한다.ALTER TABLE 사원 DROP INDEX I_성별_성, ADD INDEX I_성_성별(성, 성별);
