HTML → PDF 레포트 생성 최적화 분투기 (2) - puppeteer VS puppeteer-cluster 어떤 방식이 더 효율적일까?
사내 토이 프로젝트 & 업무 개선기

이전 포스팅
HTML → PDF 레포트 생성 최적화 분투기 (1) - 리소스 과부하 개선 & 비즈니스 로직 재설계
https://velog.io/@snghyun331/convertpdfone
1편에서는 코드 흐름만 재구성하는 방식으로 PDF 변환 시간을 약 9배 단축했다.
이번 2편에서는
Task Queue나 Kafka 같은 큰 도구를 꺼내기 전에 현재 PDF 변환에 사용 중인 Puppeteer 자체를 조금 더 깊게 들여다보려 한다.
먼저 Puppeteer가 무엇인지 간단히 짚고, 기존의 단독 Puppeteer 방식과 puppeteer-cluster 방식을 동일한 조건에서 직접 측정해 비교해보려 한다.
puppeteer
puppeteer은 Node.js 안에서 Chrome/Chromium 브라우저를 코드로 원격 조종하는 도구이다.
웹 스크래핑, 테스트, 스크린샷 찍기, PDF 생성 등의 작업을 자동화할 수 있게 해준다.
기본은 Chromium이지만 Firefox도 지원하며, 이 글에서는 Firefox를 기준으로 다룰 것이다.
※ Firefox: HTML→PDF으로 바꿔주는 브라우저. Firefox 안의 Gecko 라는 렌더링 엔진을 통해 HTML/CSS/JS 를 해석해서 화면을 그린다. 그리고 그 그린 결과를 PDF로 뽑아낸다.
동작 방식 (2가지)
- 헤드리스 모드 (headless: true) — GUI 창 없이 백그라운드에서 실행. 서버 환경에서 PDF를 만들 때 쓰는 모드다.
- 풀 브라우저 모드 (headless: false) — 실제 창이 떠서 디버깅에 유용하다.
동작 원리
그렇다면 Puppeteer은 어떻게 PDF를 생성할까?
HTML을 PDF로 바꾸려면 브라우저 엔진이 필요한데,
그 엔진은 단순한 라이브러리가 아니라 Chromium/Firefox 같은 하나의 독립된 브라우저 프로그램이기 때문에, Node.js 내부에서 직접 실행할 수 없다.
그래서 Node.js는 child_process를 통해 브라우저 프로세스를 별도로 띄워달라 부탁하고, Puppeteer는 그 브라우저와 WebSocket으로 통신하며 명령을 주고받는다.
※ Node는 "이 HTML 띄워", "PDF 뽑아" 같은 명령을 Websocket을 통해 Firefox에게 전달한다. Node와 Firefox는 서로 다른 프로세스이기 때문에 변수를 직접 공유할 수 없어서, HTTP 위에서 동작하는 양방향 통신 채널인 WebSocket이 중간 통로 역할을 한다.
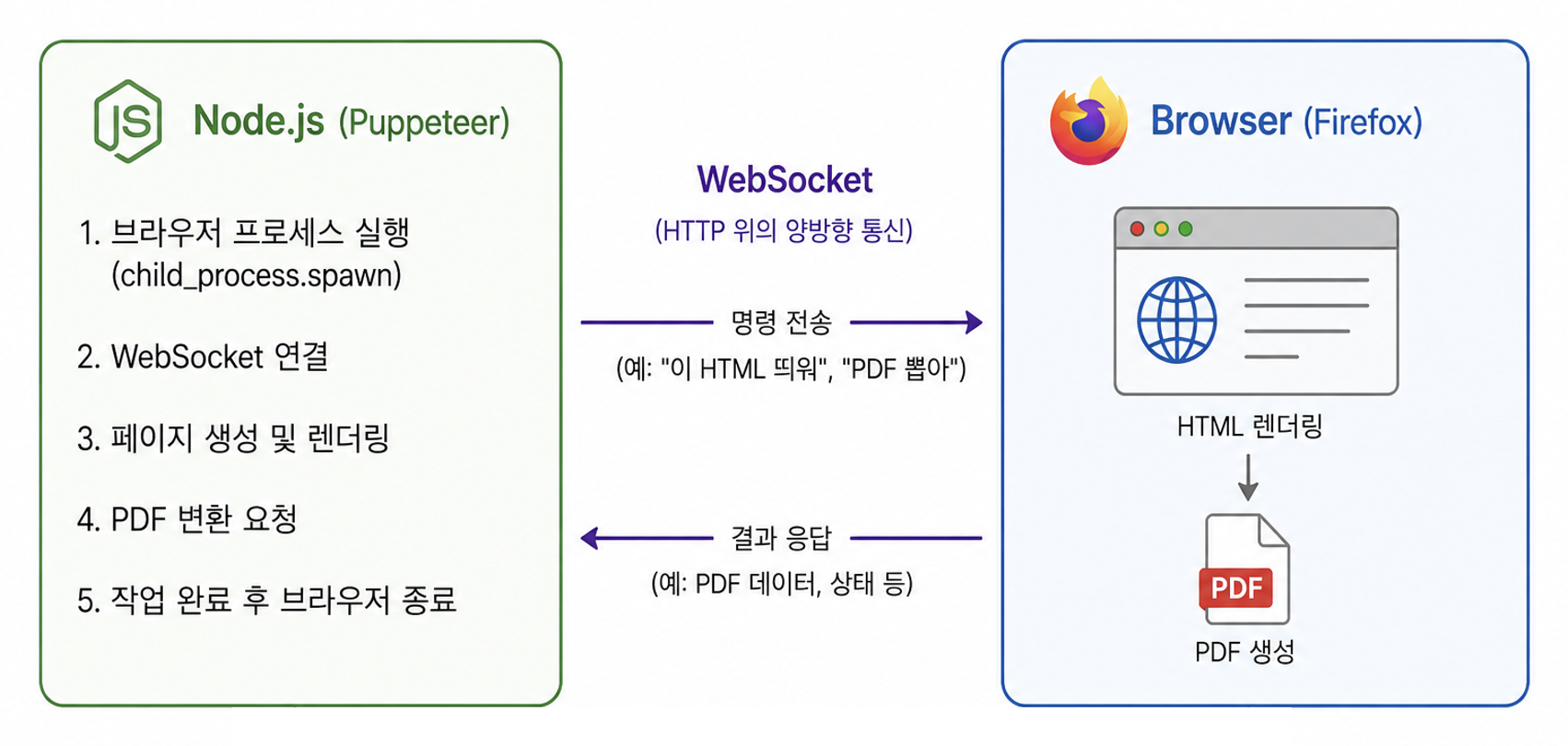
정리하면 Puppeteer는 내부적으로 다음 과정을 수행한다.
- 브라우저 프로세스 실행
- 브라우저와 WebSocket 연결
- 페이지 생성 및 렌더링
- PDF 변환 요청
- 작업 완료 후 브라우저 종료
➡️ 매 요청마다 브라우저 프로세스를 새로 띄우고 연결한 뒤 작업을 수행하고 종료한다.
코드 예시
import * as puppeteer from 'puppeteer';
async convertHtmlToPdf(...): Promise<void> {
let browser: puppeteer.Browser | null = null;
try {
/* ① 브라우저 띄우기 */
browser = await puppeteer.launch({
executablePath: '/usr/bin/firefox', // 컨테이너에 설치된Firefox 위치
product: 'firefox',
headless: true, // GUI 없이 백그라운드로 실행
args: [...],
});
/* ② 새 탭 열기 */
const page = await browser.newPage();
/* ③ HTML 읽어서 페이지에 주입 */
const htmlContent = fs.readFileSync(htmlFilePath, 'utf8');
await page.setContent(htmlContent, { ... });
/* ④ PDF로 출력 */
const pdfOptions: puppeteer.PDFOptions = {
path: pdfFilePath,
format: 'A4', // A4 크기
printBackground: true, // 배경색,이미지 포함
};
await page.pdf(pdfOptions);
} catch (error) {
...
} finally {
// 브라우저 정리
if (browser) {
await browser.close();
}
}
}① 브라우저 띄우기 — puppeteer.launch()
OS에 "Firefox 실행해줘"라고 부탁하고 그 프로세스(child process)와 WebSocket으로 연결한다.
② 새 탭 열기 — browser.newPage()
브라우저 안에 빈 탭을 하나 만든다. 이후 모든 작업(HTML 로드, PDF 생성)은 이 탭 위에서 일어난다. (한 브라우저에 여러 탭을 둘 수 있다.)
③ HTML 주입 — page.setContent()
디스크에서 HTML 파일을 읽어 문자열로 가져온 뒤, 그 내용을 탭에 통째로 밀어 넣는다. 이때 브라우저 엔진이 DOM 파싱 → CSS 적용 → 이미지/폰트 로드 → JS 실행까지 전부 처리한다. 즉, 브라우저가 페이지를 렌더링하는 단계이다.
④ PDF로 출력 — page.pdf()
렌더링이 끝난 페이지를 인쇄하듯 PDF 바이너리로 직렬화해서 파일에 쓴다.
⑤ 브라우저 정리 — browser.close()
WebSocket을 끊고 Firefox 프로세스를 종료한다. finally에 둠으로써, 좀비 프로세스가 쌓여 메모리가 새는 현상을 방지한다.
puppeteer-cluster
만약 하나의 PDF가 아니라 여러 PDF를 동시에 생성해야 하는 상황, 즉 대량 PDF 변환이 필요한 경우라면 단일 Puppeteer 인스턴스로는 처리 속도에 한계가 생긴다.
클러스터링(Clustering) 이란?
Node.js에서 클러스터링은,
"하나의 프로세스가 모든 작업을 처리하는 대신, 여러 워커 프로세스가 작업을 나눠 처리하는 방식이다."
Node.js는 기본적으로 단일 스레드 기반이다.
하나의 프로세스만 사용하면 CPU 코어가 여러 개 있어도 대부분 활용하지 못한다.
반면 클러스터링을 사용하면 여러 워커가 동시에 작업을 수행할 수 있다.
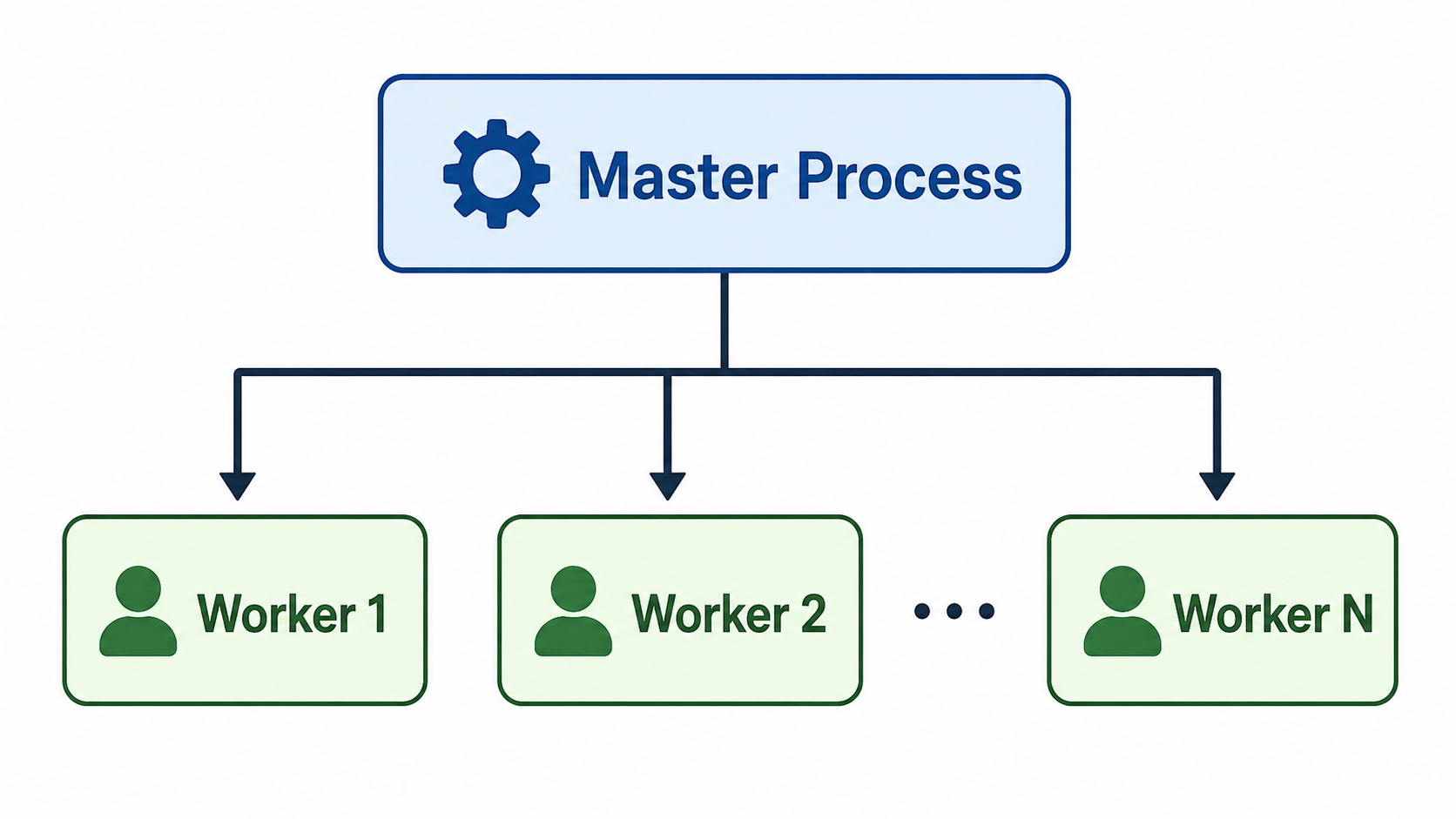
(각 워커는 독립적으로 동작하고, 마스터 프로세스가 작업을 분배하고 관리한다.)
puppeteer-cluster란?
puppeteer-cluster는 여러 Puppeteer 브라우저를 효율적으로 관리하기 위한 라이브러리다.
직접 puppeteer.launch()를 여러 번 호출하고 관리하는 대신, 브라우저들을 하나의 풀(pool)로 관리하면서 작업을 자동 분배해준다.
"Puppeteer 브라우저 여러 개를 관리해주는 작업 큐 매니저" 라고 이해하면 쉽다.
어떻게 동작할까? 장점은?
puppeteer-cluster는 브라우저 인스턴스 풀을 만든 뒤, 작업을 큐(queue)에 넣어 자동으로 분배한다.
동작 방식은 아래와 같다.
- 브라우저 여러 개를 미리 생성
- 작업이 들어오면 빈 인스턴스에 자동 할당
- 설정한 개수만큼만 동시 실행 (maxConcurrency)
- 실패한 작업은 자동 재시도
- 브라우저 충돌 발생 시 자동 복구
➡️ 우리는 작업을 등록만 하면 되고, 실행 관리와 분배는 puppeteer-cluster가 알아서 처리해준다.
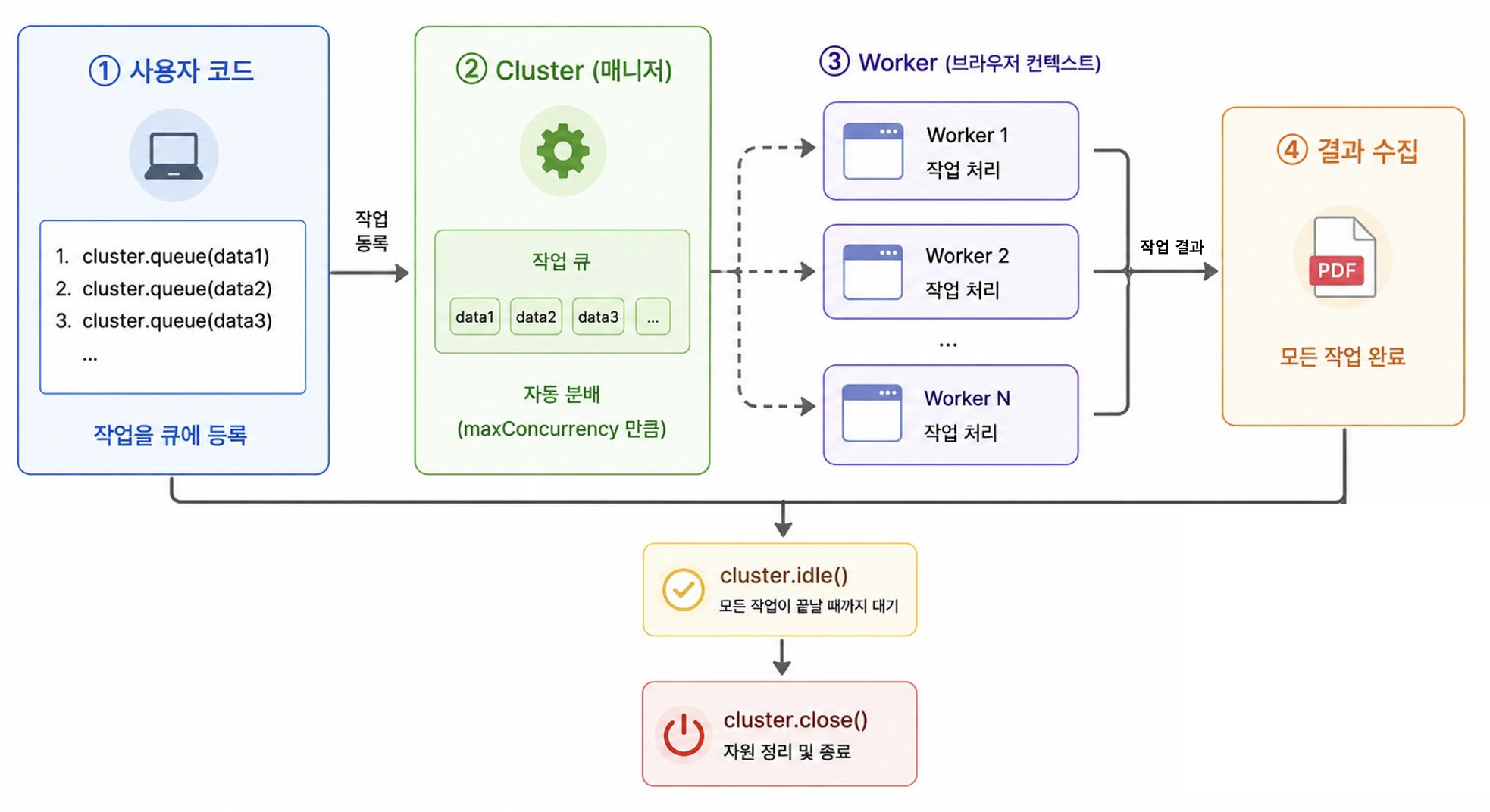
정리하면 puppetter-cluster는,
여러 Puppeteer 브라우저를 풀(pool) 형태로 관리하면서, 작업 분배 & 동시 실행 제어 & 자동 재시도까지 처리해주는 라이브러리다.
코드 예시
import { Cluster } from 'puppeteer-cluster';
async convertHtmlToPdf(...) {
// ① 클러스터 풀(Pool) 가동
const puppeteerCluster = await Cluster.launch({
concurrency: Cluster.CONCURRENCY_CONTEXT, // 모드
maxConcurrency: 5, // 병렬로 실행할 페이지 수 조정
puppeteerOptions: {
executablePath, // ex) /usr/bin/firefox
product: 'firefox',
headless: true,
args: [],
},
});
// ② 작업 매뉴얼 등록
await puppeteerCluster.task(async ({ page, data }) => {
try {
await page.setContent(data.html);
await page.pdf({
path: data.savePath.normalize('NFC'),
format: 'A4',
printBackground: true,
scale: 0.99,
});
} catch (error) {
...
}
});
await Promise.allSettled(
testerList.map(async (tester) => {
let htmlString = fs.readFileSync(filePath, 'utf8');
// ③ HTML 파일을 저장한다
fs.writeFileSync(`${reportResultFolderHtml}/${reportHtmlFileName}`, htmlString);
// ③ HTML 파일을 읽어와서 PDF 큐에 추가
await puppeteerCluster.queue({
html: reportHtml,
savePath: reportPdfSavePath,
filename: reportHtmlFileName,
});
// ④ 큐 비워질 때까지 대기
await puppeteerCluster.idle();
}),
);
// ⑤ Pool 정리
await puppeteerCluster.close();
}① 클러스터 풀 만들기 — Cluster.launch()
브라우저 풀을 관리할 cluster를 생성한다.
maxConcurrency: 5 = 최대 5개의 작업을 동시에 처리하겠다
(이때 Firefox가 바로 실행되는 것은 아니다.)
처음 작업이 큐에 들어오면 그때 브라우저와 워커가 생성된다. puppeteerOptions 값은 내부적으로 puppeteer.launch()에 전달된다.
② 작업 매뉴얼 등록 — cluster.task()
큐에 들어온 작업을 어떻게 처리할지 정의하는 함수다. 한 번 등록하면 이후 모든 작업이 이 함수로 실행된다.
page는 cluster가 자동으로 할당한 페이지이고, data에는 queue()로 전달한 값이 들어온다.
여기서는 setContent()로 HTML을 넣고, page.pdf()로 PDF를 생성한다.
③ (작업 처리하기) 응시자별 HTML 생성 후 큐에 등록 — fs.writeFileSync + cluster.queue()
Promise.allSettled 를 사용해 모든 응시자의 HTML 생성 작업을 동시에 처리한다.
- 각 응시자마다 템플릿 HTML을 디스크에서 읽어와 치환 및 저장
cluster.queue()로 "이 HTML 을 이 경로에 PDF로 저장해달라" 요청을 큐에 등록한다.- 큐에 작업이 들어오면, 비어 있는 워커가 해당 작업을 가져가 바로 PDF 생성 작업을 수행한다.
④ 큐 비워질 때까지 대기 (완료 대기) — cluster.idle()
큐에 남은 작업이 0개이고 모든 워커가 idle 상태가 될 때까지 대기한다.
"지금까지 enqueue 한 모든 PDF 변환이 끝났는가?" 를 확인하는 지점이다.
⑤ 풀 정리 — cluster.close()
풀에 있는 모든 브라우저와 페이지를 종료한다.
puppeteer의 browser.close()와 비슷하지만, 여러 브라우저를 한 번에 정리한다는 차이가 있다. 이 작업을 하지 않으면 Firefox 프로세스가 메모리에 남아 메모리 누수가 발생할 수 있다.
🤔 단일 puppeteer 방식, 계속 사용해도 괜찮을까?
기존 코드는 단일 puppeteer 방식으로 동작하고 있었다.
아직까지 큰 이슈는 없었지만, 실제 운영 환경에서는 공채 시즌에 하나의 공고에서 500명 이상의 응시자 레포트를 한 번에 다운로드하는 경우도 있었다.
이런 대량 PDF 변환 상황에서 브라우저를 매번 새로 실행하는 구조가 과연 효율적이고 안정적인 방식인지에 대한 의문이 들기 시작했다.
실제 단일 puppeteer 적용 로직
import * as puppeteer from 'puppeteer';
const batchSize = 40;
for (let i = 0; i < testerInfoList.length; i += batchSize) {
const batch = testerInfoList.slice(i, i + batchSize);
// 배치 내 파일들을 병렬로 처리
await Promise.all(
batch.map(async (testerInfo: TesterReportInfoDto) => await this.convertHtmlToPdf(htmlFileName, testerInfo, reportResultFolder)),
);
}
async convertHtmlToPdf(
htmlFileName: string,
testerInfo: TesterReportInfoDto,
reportResultFolder: string,
): Promise<void> {
let browser: puppeteer.Browser | null = null;
try {
browser = await puppeteer.launch({
executablePath: '/usr/bin/firefox',
product: 'firefox',
headless: true,
timeout: 60000, // 타임아웃 60초
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
],
});
const page = await browser.newPage();
// HTML 파일의 전체 경로 생성
const htmlFileFolder = path.join(reportResultFolder, 'html');
const htmlFilePath = path.join(htmlFileFolder, htmlFileName);
// HTML 파일 내용을 직접 읽기
const htmlContent = fs.readFileSync(htmlFilePath, 'utf8');
// 타임아웃 설정
await page.setContent(htmlContent, {
waitUntil: 'domcontentloaded', // DOM 로드 완료까지만 대기
timeout: 60000,
});
// PDF 저장 디렉토리 생성 (reportResultFolder + '/pdf')
const pdfResultFolder = path.join(reportResultFolder, 'pdf');
// PDF 디렉토리가 없다면 생성
if (!fs.existsSync(pdfResultFolder)) {
fs.mkdirSync(pdfResultFolder, { recursive: true });
}
// PDF 파일명 생성 (HTML 파일명과 동일하게, 확장자만 변경)
const fileName = path.basename(htmlFileName, '.html');
const pdfFileName = `${fileName}.pdf`;
const pdfFilePath = path.join(pdfResultFolder, pdfFileName);
// 기존 PDF 파일이 존재하면 삭제 (권한 문제 방지 - ERROR in EPERM: operation not permitted, open)
// -> Puppeteer가 같은 이름의 파일을 다시 생성하려고 할 때 기존 파일에 쓰기 권한이 없어서 발생하는 문제
if (fs.existsSync(pdfFilePath)) {
try {
fs.unlinkSync(pdfFilePath);
} catch (error) {
this.logger.warn(`기존 PDF 파일 삭제 실패: ${pdfFilePath}`, error);
}
}
// PDF 생성 옵션
const pdfOptions: puppeteer.PDFOptions = {
path: pdfFilePath,
format: 'A4',
printBackground: true,
};
// PDF 생성
await page.pdf(pdfOptions);
} catch (error) {
this.logger.error(
`PDF 변환 중 오류 발생 (파일: ${htmlFileName}${testerInfo ? `, 응시자IDX: ${testerInfo.testerIdx}` : ''})`,
error,
);
} finally {
// 브라우저 인스턴스 정리
if (browser) {
await browser.close();
}
}
}여러 명의 PDF를 기존 Puppeteer 방식으로 처리하면,
아래처럼 응시자 한 명을 처리할 때마다 브라우저를 새로 실행하고 다시 종료하게 된다.
for (const url of urls) {
const browser = await puppeteer.launch(...) // 매번 띄우고
const page = await browser.newPage()
await page.setContent(...);
await page.pdf(...)
await browser.close() // 매번 닫고
}작업마다 브라우저를 반복해서 띄우고 닫는 구조이기 때문에
대량 PDF 변환 상황에서는 메모리와 CPU 사용 측면에서 비효율적일 수 있다.
puppeteer-cluster 적용
puppeteer-cluster으로 적용한 로직
await Promise.allSettled(
groupIdxList.map(async (groupIdx: number) => {
const testerList: TesterEntity[] =
await this.schedulerRepository.getTesterInfoList(
groupIdx,
);
if (testerList.length !== 0) {
// HTML => PDF 변환
await this.convertHtmlToPdf(groupIdx, testerList);
}
}),
);
private async convertHtmlToPdf(
groupIdx: number,
testerList: any,
) {
// Firefox 경로 자동 탐지
const getFirefoxPath = () => {
const paths = [
'/opt/homebrew/bin/firefox',
'/usr/bin/firefox',
'/usr/local/bin/firefox',
];
for (const path of paths) {
if (fs.existsSync(path)) {
return path;
}
}
return undefined;
};
const puppeteerCluster = await Cluster.launch({
concurrency: Cluster.CONCURRENCY_CONTEXT,
maxConcurrency: 5,
puppeteerOptions: {
executablePath: getFirefoxPath(),
product: 'firefox',
headless: true,
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
],
},
});
await puppeteerCluster.task(async ({ page, data }) => {
try {
await page.setContent(data.html);
await page.pdf({
path: data.savePath.normalize('NFC'),
format: 'A4',
printBackground: true,
scale: 0.99,
});
} catch (error) {
await this.logger.error(
`✅ PDF Error: ${error}, (${data.fileName})`,
);
}
});
// 레포트 결과 폴더
const reportResultFolder = `resource/download/company/${companyIdx}/group/${groupIdx}/tester/result/personal`;
const BATCH_SIZE = 40;
// 배치 처리
for (let i = 0; i < testerList.length; i += BATCH_SIZE) {
const batch = testerList.slice(i, i + BATCH_SIZE);
try {
await Promise.allSettled(
batch.map(async (testerInfo: any) => {
let htmlString = fs.readFileSync(filePath, 'utf8');
// 레포트 HTML 파일 경로
const reportResultFolderHtml = `${reportResultFolder}/html`;
// PDF 저장 경로
const reportResultFolderPdf = `${reportResultFolder}/pdf`;
// HTML 파일 경로가 없다면 생성한다
if (!fs.existsSync(reportResultFolderHtml)) {
fs.mkdirSync(reportResultFolderHtml, { recursive: true });
}
// PDF 파일 경로가 없다면 생성한다
if (!fs.existsSync(reportResultFolderPdf)) {
fs.mkdirSync(reportResultFolderPdf, { recursive: true });
}
// HTML 파일을 저장한다
fs.writeFileSync(`${reportResultFolderHtml}/${reportHtmlFileName}`, htmlString);
// HTML 파일을 읽어와서 PDF 큐에 추가
const reportFilePath: string = path.join(reportResultFolderHtml, reportHtmlFileName);
const reportHtml = fs.readFileSync(reportFilePath, 'utf8');
const reportPdfSavePath = path.join(reportResultFolderPdf, reportHtmlFileName.replace('.html', '.pdf'));
await puppeteerCluster.queue({
html: reportHtml,
savePath: reportPdfSavePath,
filename: reportHtmlFileName,
});
},
),
);
await puppeteerCluster.idle();
} catch (error) {
await this.logger.error(
`✅ PDF Error: ${error}`,
);
}
}
await puppeteerCluster.close();
}puppeteer-cluster는 여러 명의 PDF를 생성해야 하는 상황에서, 브라우저를 매번 새로 띄우지 않고 실행 중인 브라우저들을 재사용하면서 동시에 처리할 수 있다.
const cluster = await Cluster.launch({ maxConcurrency: 5});
cluster.task(async ({ page, data }) => { await page.pdf(data); });
for (const url of urls) {
cluster.queue(url)
}
await cluster.idle()
await cluster.close()실제 운영 환경 리소스 비교
433명의 응시자 레포트를 대상으로 동일 서버 환경에서, 기존 단일 Puppeteer 방식과 puppeteer-cluster 방식을 각각 적용한 뒤 서버 리소스 지표를 비교했다.
- 00:22 ~ 00:27 → 단일 Puppeeteer 방식
- 00:30 ~ 00:35 → puppeteer-cluster 방식
Load Average 비교
- 초록: 1m (최근 1분 평균 부하)
- 주황: 5m (최근 5분 평균 부하)
- 빨강: 15m (최근 15분 평균 부하)
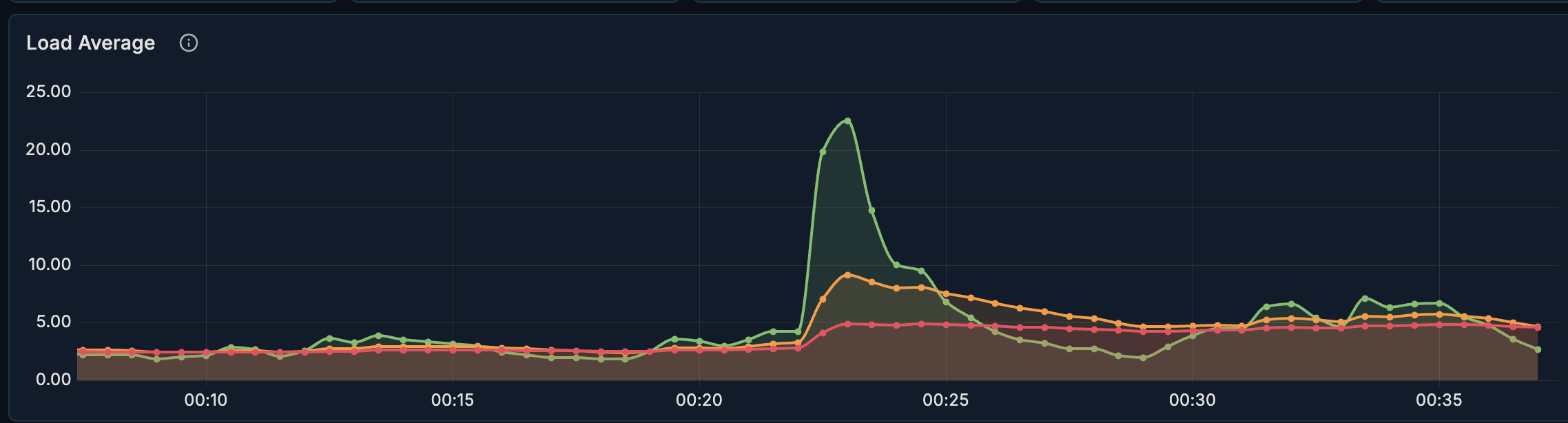
그래프를 보면 단일 Puppeteer 방식은 작업 구간에서 부하가 급격하게 치솟는 반면,
puppeteer-cluster 방식은 상대적으로 안정적인 패턴을 유지하는 것을 확인할 수 있었다.
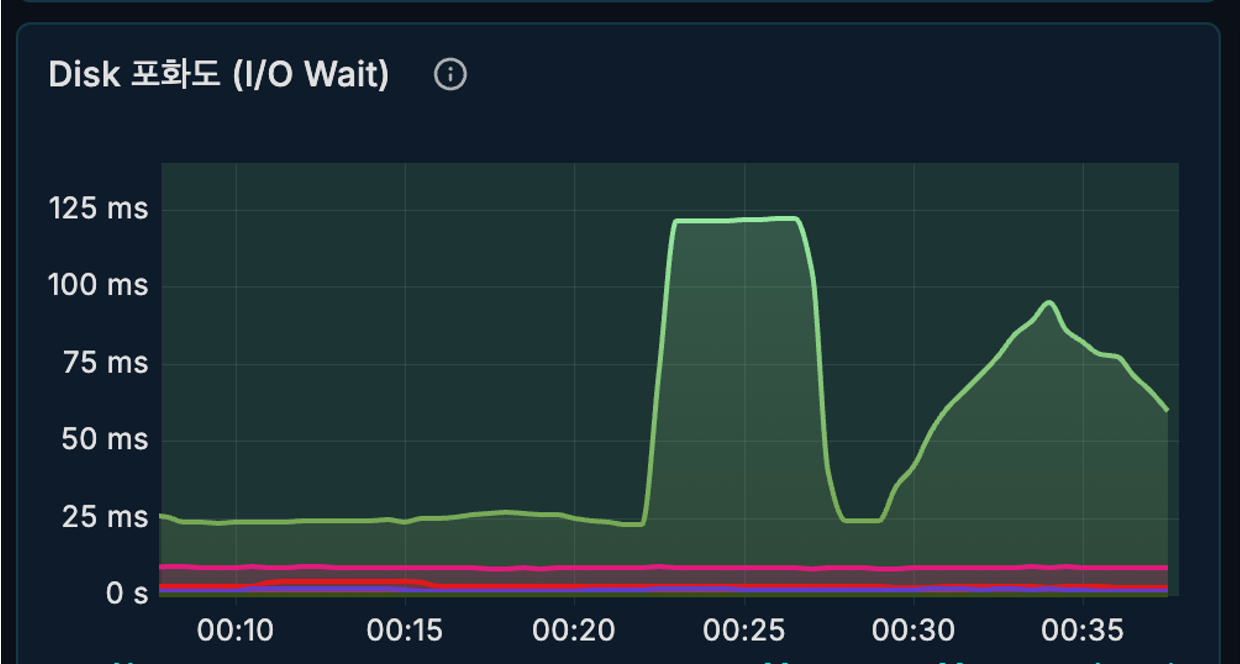
디스크 I/O Wait 비교
디스크 I/O Wait는 디스크 작업을 기다리느라 CPU가 대기하는 시간을 의미한다.
단일 Puppeteer 방식은 작업 구간에서 I/O Wait가 크게 증가했지만,
puppeteer-cluster 방식은 비교적 안정적으로 유지되는 모습을 확인할 수 있었다.
종합해봤을 때
puppeteer-cluster 방식이 대량 PDF 생성 상황에서 훨씬 안정적인 리소스 사용 패턴을 보여줬다.
puppeteer-cluster, 더 많이 알려졌으면 하는 라이브러리
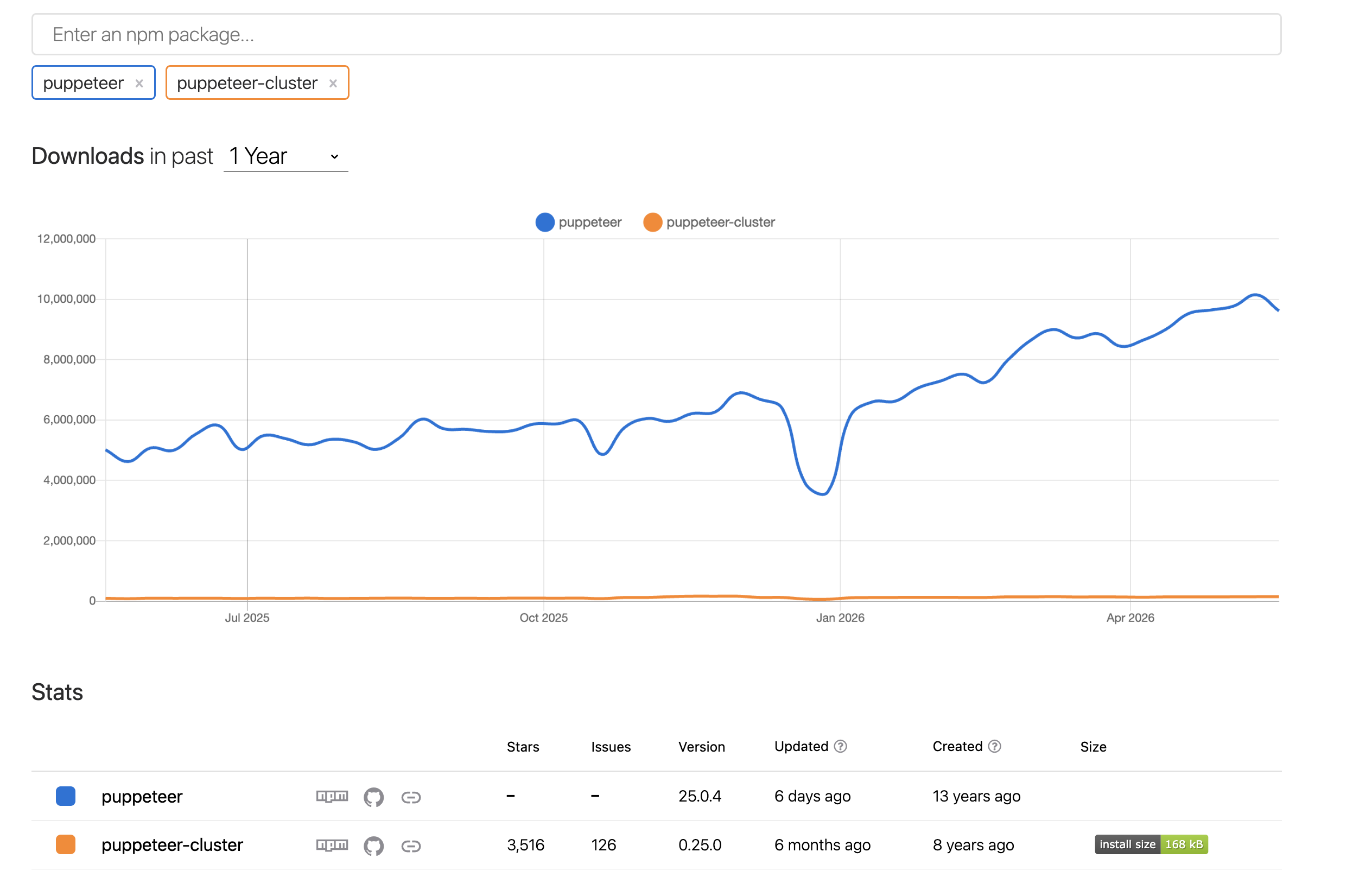
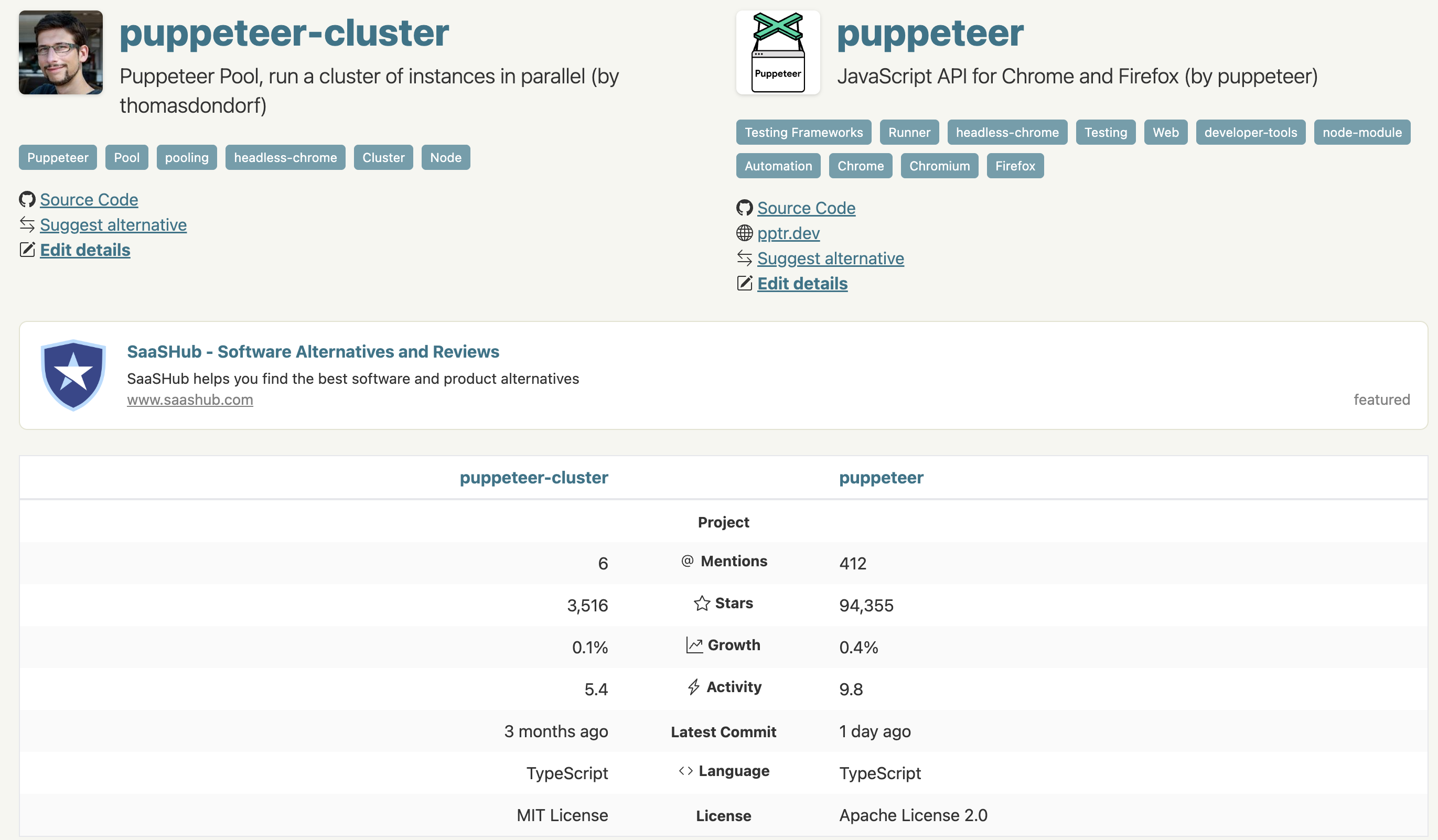
여러 PDF를 생성하는 환경에서는 puppeteer-cluster가 리소스 관리 측면에서 꽤 큰 장점을 가지고 있음에도 npm trends를 보면 아직은 puppeteer에 비해 사용률이 많이 낮은 편인 것 같다.
물론 모든 상황에서 puppeteer-cluster가 필요한 것은 아니지만
대량 PDF 생성이나 반복적인 브라우저 작업이 있다면, 한 번쯤은 꼭 고려해볼 만한 라이브러리라고 느꼈다.
참고
Puppeteer란?
Puppeteer Cluster: Beginner guide
puppeteer-cluster VS puppeteer
Puppeteer Cluster: Basic & Advanced Setup Explained
