🤦♀️ 테이블 명세서, 언제까지 수동으로 관리해야 할까
사내에서는 DB 테이블 명세서를 엑셀로 관리하고 있었다.
하지만 DB 구조가 변경될 때마다 명세서를 직접 수정해야 했고, 테이블 수가 늘어날수록 관리 부담도 점점 커졌다.
이 문제를 해결하기 위해 먼저 Google Sheets API + Python을 이용해 테이블 명세서를 자동화하는 프로젝트를 진행했었다.
📎 Google Sheet API를 이용한 테이블 명세서 생성 자동화(Python)
프로젝트에 대해 간단히 요약하면,..
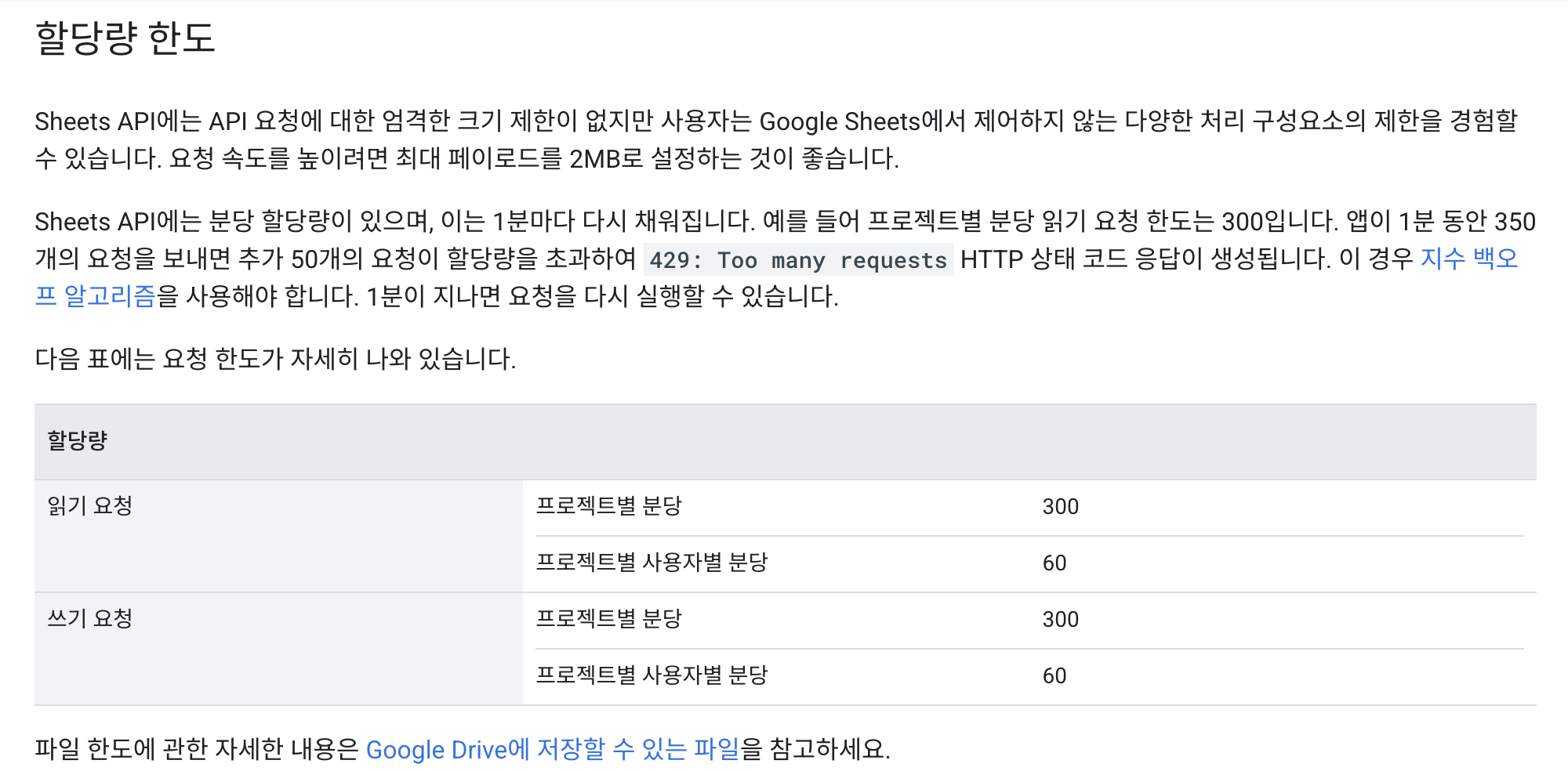
PyMySQL로information_schema를 조회하고 조회한 정보를 Google Sheets에 자동으로 삽입- 전체 테이블 목록을 관리하는 Master Sheet와 각 테이블의 상세 정보를 관리하는 Table Sheet를 분리
Flask+Scheduler을 이용해 매일 최신 DB 구조를 Google Sheets에 반영
🤦♀️ 운영하면서 드러난 Google Sheets 방식의 한계
처음에는 Google Sheets 기반 자동화만으로도 충분해 보였다.
하지만 관리해야 할 테이블 수가 늘어나면서 업데이트 도중 Google Sheets API의 읽기/쓰기 할당량 제한에 자주 걸리기 시작했다.
특히 gspread Quota exceeded 에러가 빈번하게 발생했다.
업데이트 작업을 테이블 단위로 나누거나, 요청 사이에 time.sleep(10)과 같은 딜레이를 추가하는 방식도 시도해보았지만..
이런 방식은 근본적인 해결책이 되기 어려웠다.
결국 Google Sheets를 이용한 자동화 방식에는 한계가 있다고 판단해 Data Catalog를 관리하기 위한 전용 서비스를 직접 만들기로 했다.
그렇게 탄생한 서비스가 바로 Data Catalog Service 다.
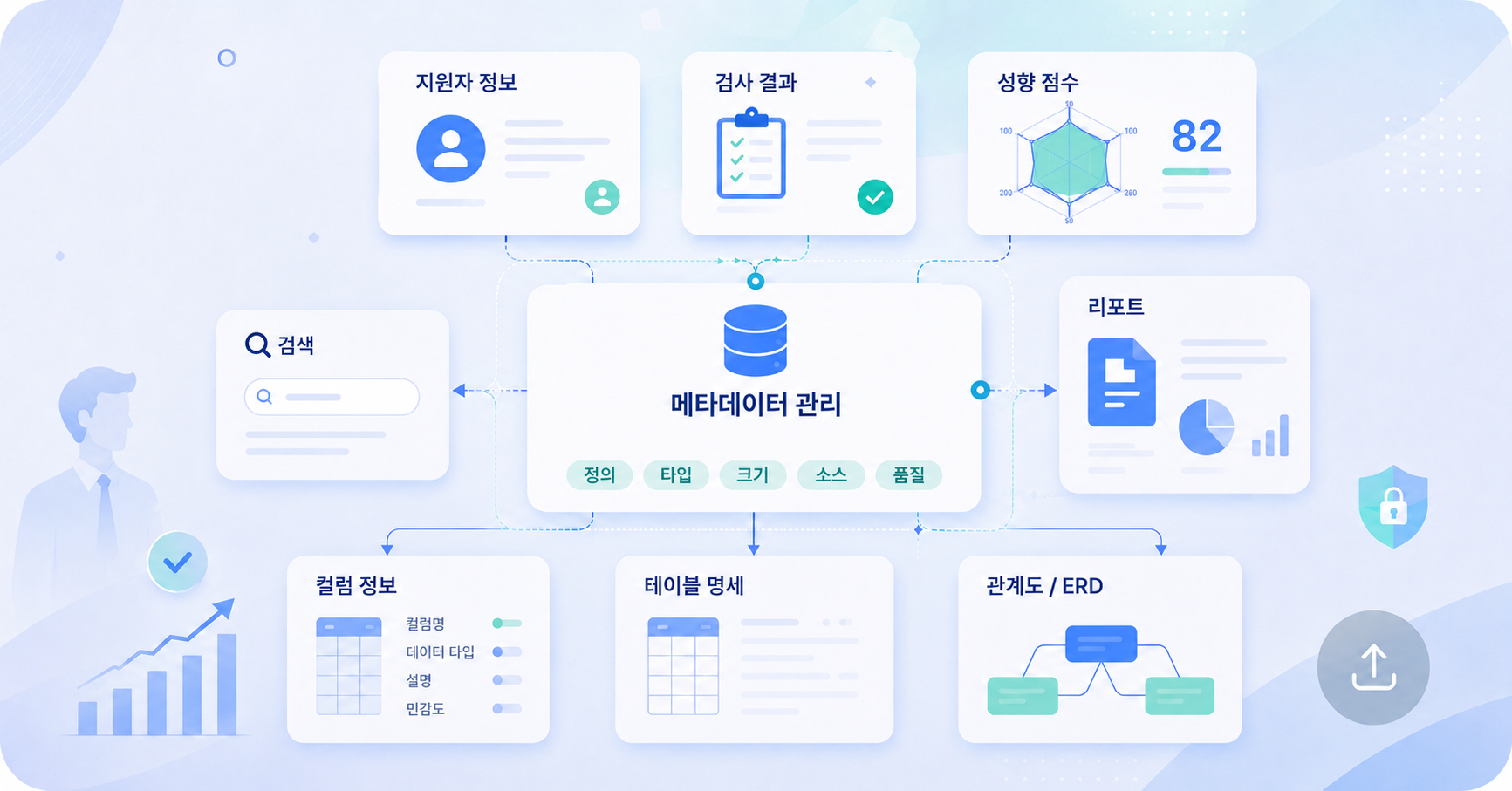
Data Catalog Service의 주요 기능들
Data Catalog Service는 DB / Table / Column 정보를 관리하고, 운영 중인 DB 구조를 더 쉽게 파악하기 위한 기능들을 제공한다.
프로젝트의 자세한 기능은 README에서 확인할 수 있다. 📎 Github Link
-
Database Catalog
관리 중인 DB 목록과 기본 정보를 조회한다. -
Table Catalog
각 DB에 속한 테이블 정보와 row 수 등 테이블 단위 정보를 관리한다. -
Column Catalog
컬럼명, 데이터 타입, Nullable 여부, Key 정보 등 컬럼 명세를 조회한다. -
ERD 시각화
information_schema의 FK 정보에 기반해 테이블 간 관계를 시각화한다. -
통계 대시보드
전체 DB 수, 테이블 수, 총 데이터 행 수, 마지막 업데이트 시각 등을 홈 화면에 한눈에 보여준다. -
스키마 변경 감지
추가 / 삭제 / 수정된 테이블과 컬럼을 감지하고, 확인 후 변경 사항을 "클릭 하나"로 즉시 반영할 수 있다.
기존 Google Sheets 자동화 프로젝트에서는 Database / Table / Column Catalog만을 제공했다.
이번 Data Catalog Service에서는 여기에 ERD 시각화, 통계 대시보드, 스키마 변경 감지 기능을 추가해 단순 명세서 관리에서 한 단계 확장했다.
❗️ 서비스를 만들면서 마주한 문제들
Data Catalog Service를 직접 구현한 뒤 코드를 다시 살펴보니 몇 가지 아쉬운 부분들이 눈에 들어오기 시작했다.
ERD 시각화처럼 AI의 도움을 받아 비교적 빠르게 구현한 기능도 있었지만, 기능이 동작한다고 해서 곧바로 운영하기 좋은 서비스가 되는 것은 아니었다.
단순히 동작하는 코드를 만드는 것과
안정적으로 관리하고 유연하게 확장할 수 있는 구조를 만드는 것은 다른 문제였다.
이제부터는 서비스를 제작하면서 발견한 문제점들과 개선 과정, 그리고 그 과정에서 AI를 어떻게 활용했는지 정리해보려 한다.
🤖 AI (Claude + Codex)를 활용한 방식
이번 프로젝트에서는 Claude CLI에서 Codex MCP를 연동해, 두 AI를 아래와 같은 역할에 따라 나눠서 활용했다.
Claude는 주로 문제 분석과 설계 방향을 잡는 데 사용했다.
현재 구조와 문제 상황을 설명하면 여러 개선안을 제안해줬고, 그 중 어떤 방식을 적용할지는 서비스 규모, 현재 코드 구조, 구현 복잡도를 기준으로 직접 판단했다.
방향이 정해지면 Codex를 이용해 실제 코드 변경, 버그 수정, 검토를 진행했다.
| 단계 | 활용 방식 |
|---|---|
| 문제 분석 / 개선안 비교 | Claude에게 여러 개선안 요청 |
| 의사결정 | 제안받은 방식 중 직접 판단해 선택 |
| 코드 작성 | Codex에게 선택한 방향에 맞춰 코드 수정 요청 |
| 검토 / 버그 수정 | Codex로 코드 리뷰와 수정 진행 |
🐞 문제 1 : Firestore 다수 API 호출과 데이터 정합성 문제
서비스를 처음 만들고 코드를 들여다보니 바로 눈에 띄는 문제가 있었다.
DB를 새로 등록하는 과정에서 Firestore에 데이터를 저장할 때, 테이블과 컬럼을 하나씩 개별 API 호출로 저장하고 있었다.
await this.firebaseService.saveDatabase(...); // DB 정보 저장
await this.firebaseService.saveTable(...); // 테이블 수(N)만큼 호출
await this.firebaseService.saveColumn(...); // 컬럼 수(M)만큼 호출테이블이 10개, 컬럼이 100개라면 DB 등록 한 번에 최소 111번의 저장 호출이 발생하는 구조였다.
또 다른 문제는 트랜잭션이 적용되지 않아 데이터 정합성이 깨질 수 있다는 점이었다.
중간 단계에서 에러가 발생하면 일부 데이터만 저장된 채로 남아 데이터 정합성이 깨질 수 있었다.
// ❌ 문제 코드
await this.firebaseService.saveDbConnection(companyCode, dbInfo); // 먼저 저장됨
const connection = await this.catalogRepository.getConnectionToDB(companyCode);
try {
await this.firebaseService.saveDatabaseBatch(...); // 여기서 에러가 발생한다면?
} catch (err) {
throw err; // dbConnection은 이미 저장된 상태로 남음
}기존 로직은 dbConnection을 먼저 저장 한 뒤, 이를 다시 조회해 MySQL에 연결하고 카탈로그 데이터를 저장하는 흐름이었다.
이때 카탈로그 저장 중 에러가 발생하면 연결 정보만 저장되고, databases에는 카탈로그 데이터가 저장되지 않을 수 있는 구조였다.
☝🏻 Claude의 제안: runTransaction vs batched Writes
이 문제를 Claude에게 설명했더니 두 가지 방식을 제안해줬다.
| 방식 | 장점 | 단점 |
|---|---|---|
runTransaction | 읽기 + 쓰기 가능, 동시성 제어에 적합 | 구현이 비교적 복잡함 |
Batched Writes | 구현이 단순하고 Batch 단위 원자성 보장 | Firestore 내부 읽기 작업 불가 |
현재 구조는 MySQL에서 데이터(스키마 정보)를 읽어온 뒤, Firestore에는 데이터를 저장(쓰기)하기만 하면 된다.
따라서 Firestore에서는 읽기가 필요한 부분은 없기 때문에 runTransaction은 현재 상황에서는 다소 오버스펙이라고 판단했고,
여러 쓰기 작업을 묶어서 한번에 저장하는 Batched Writes를 선택했다.
이후 실제 코드 수정은 Codex에게 요청했다.
✌🏻 Codex가 수정한 로직
핵심 변경은 크게 두 가지 였다.
① DB 최초 등록 시 직접 연결
기존에는 dbConnection을 Firestore에 먼저 저장한 뒤, 다시 Firestore에서 해당 정보를 조회해서 MySQL에 연결하는 구조였다.
그래서 최초 등록 시에는 일단 connection 정보를 먼저 저장하지 않고, 요청으로 전달받은 dbInfo DTO로 우선 MySQL에 직접 연결하도록 수정했다.
// Firestore 조회 없이 dto로 직접 연결 (단일 커넥션)
const connection = await this.catalogRepository.createDirectConnection(dbInfo);이렇게 변경하면서 "dbConnection 저장 → Firestore 조회 → MySQL 연결"로 이어지던 불필요한 의존성을 제거할 수 있었다.
② Firestore 쓰기 작업를 Batch로 묶어서 처리
MySQL에서 DB / Table / Column 정보를 모두 조회한 뒤, dbConnection, database, tables, columns 저장 작업을 하나의 Batch 작업으로 묶어 처리하도록 변경했다
// 데이터를 Batch로 묶어서 한번에 저장
await this.firebaseService.saveAllBatch(
companyCode, dbInfo, dbInfo.dbName, databaseDoc, tables
);이렇게 하면 하나의 Batch 안에 포함된 작업들은 함께 커밋되기 때문에 중간 실패로 인한 데이터 정합성 문제를 줄일 수 있다.
다만, Firestore Batched Writes는 한 번에 최대 500개의 작업(job)만 처리할 수 있다.
테이블과 컬럼 수가 많아지면 500개를 초과할 수 있기 때문에, 이를 대비해 작업 목록을 chunk 단위로 나누어 처리하도록 구현했다.
private async executeBatchInChunks(operations): Promise<void> {
const BATCH_LIMIT = 500;
const chunks = this.chunkArray(operations, BATCH_LIMIT);
for (const chunk of chunks) {
const batch = this.firestore.batch();
chunk.forEach(({ ref, data }) => batch.set(ref, data, { merge: true }));
await batch.commit();
}
}chunk를 적용하면 500개를 초과하는 쓰기 작업도 비교적? 안정적으로 처리할 수 있지만..
전체 작업가 아닌, 각 chunk단위의 작업에 대해서만 원자성이 보장된다.
그래도 기존처럼 dbConnection을 먼저 저장한 뒤 나머지 데이터를 따로 저장하던 구조에 비하면 저장 흐름이 훨씬 명확해졌고 정합성이 깨질 가능성도 줄일 수 있었다.
🐞 문제 2: Firestore 컬렉션(Collection) 구조
두 번째로 눈에 들어온 문제는 Firestore 컬렉션 구조였다.
처음 플랫폼을 처음 구현할 때 Firestore 컬렉션 구조는 별다른 고민 없이 Google Sheet 기반의 구조를 그대로 가져왔다.
이전 Google Sheet에서는 DB마다 Master Sheet 하나를 두고, 각 테이블별로 개별 Table Sheet를 만드는 방식으로 명세서를 관리했다. Master Sheet에는 테이블 목록과 테이블 상세 정보(테이블명, 컬럼 수, 행 수, 사이즈, description 등)가 담겼고, 각 Table Sheet에는 컬럼 상세 정보(타입, nullable, default, description 등)가 들어갔다.
Firestore로 옮길 때도 이 구조가 자연스럽게 이어졌다.
- Master Sheet →
masterCatalog - Table Sheet →
tableCatalog
기존에 익숙했던 구조였기 때문에 별다른 의심 없이 그대로 적용했다.
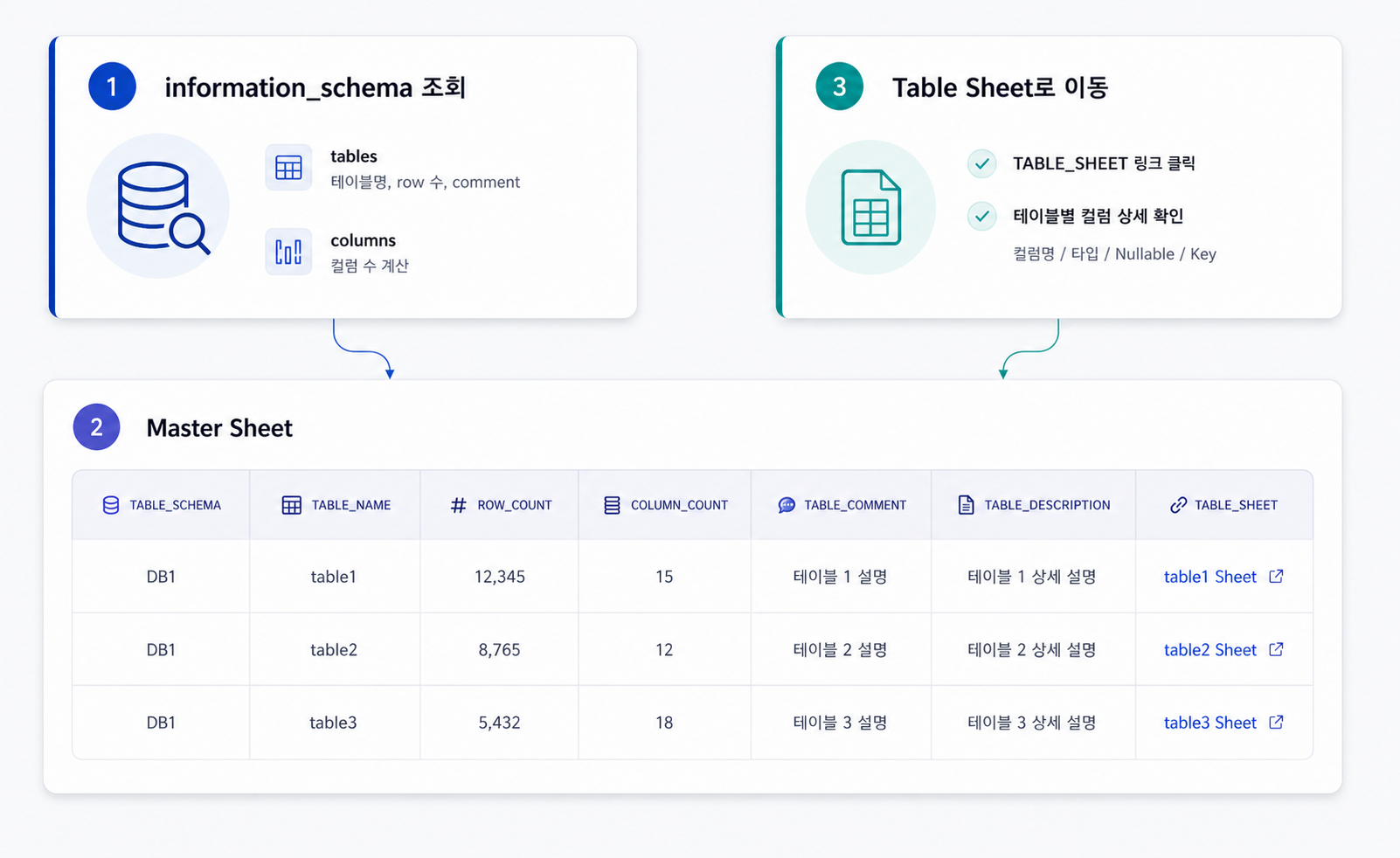
기존 컬렉션 구조
├── dbConnections/{companyCode}
│ ├── host, port, userName, password, dbName
│
├── company/{dbName}
│ ├── companyCode, companyName
│
├── database/{dbName}
│ ├── tableList[], dbSize, totalRows, lastUpdated, dbTag
│
├── masterCatalog/{dbName}
│ └── tables/{tableName}
│ ├── TABLE_SCHEMA, TABLE_NAME
│ ├── TABLE_ROWS, TABLE_COLUMNS
│ ├── TABLE_COMMENT, TABLE_DESCRIPTION, DATA_SIZE
│
└── tableCatalog/{dbName}
└── {tableName}/{columnName}
├── TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME
├── COLUMN_DEFAULT, IS_NULLABLE
├── COLUMN_TYPE, COLUMN_KEY
├── COLUMN_COMMENT, COLUMN_NOTE
운영하면서 드러난 문제
처음에는 이 구조도 크게 문제 없어 보였다.
하지만 실제로 서비스를 구현하고 데이터를 조회해보니 비효율적인 부분들이 보이기 시작했다.
하나의 DB 정보를 화면에 보여주기 위해 company, database, masterCatalog, tableCatalog를 각각 따로 읽어야 했다.
Firestore는 문서 읽기 횟수를 기준으로 과금되는 구조라, 단순 조회에서도 불필요한 읽기가 발생되고 있었다.
새 DB를 등록할 때도 마찬가지였다.
여러 컬렉션에 데이터를 순서대로 저장하다가 중간에 실패하면 데이터가 어중간하게 남아버리는 상황이 생겼다.
그래서 Firestore에 맞는 구조로 다시 설계해야겠다고 판단했다.
☝🏻 Claude의 제안: DB 문서를 중심으로 계층적으로 관리하자.
기존 컬렉션 구조와 문제 상황을 Claude에게 설명하고 Firestore에 더 적합한 구조를 추천받았다
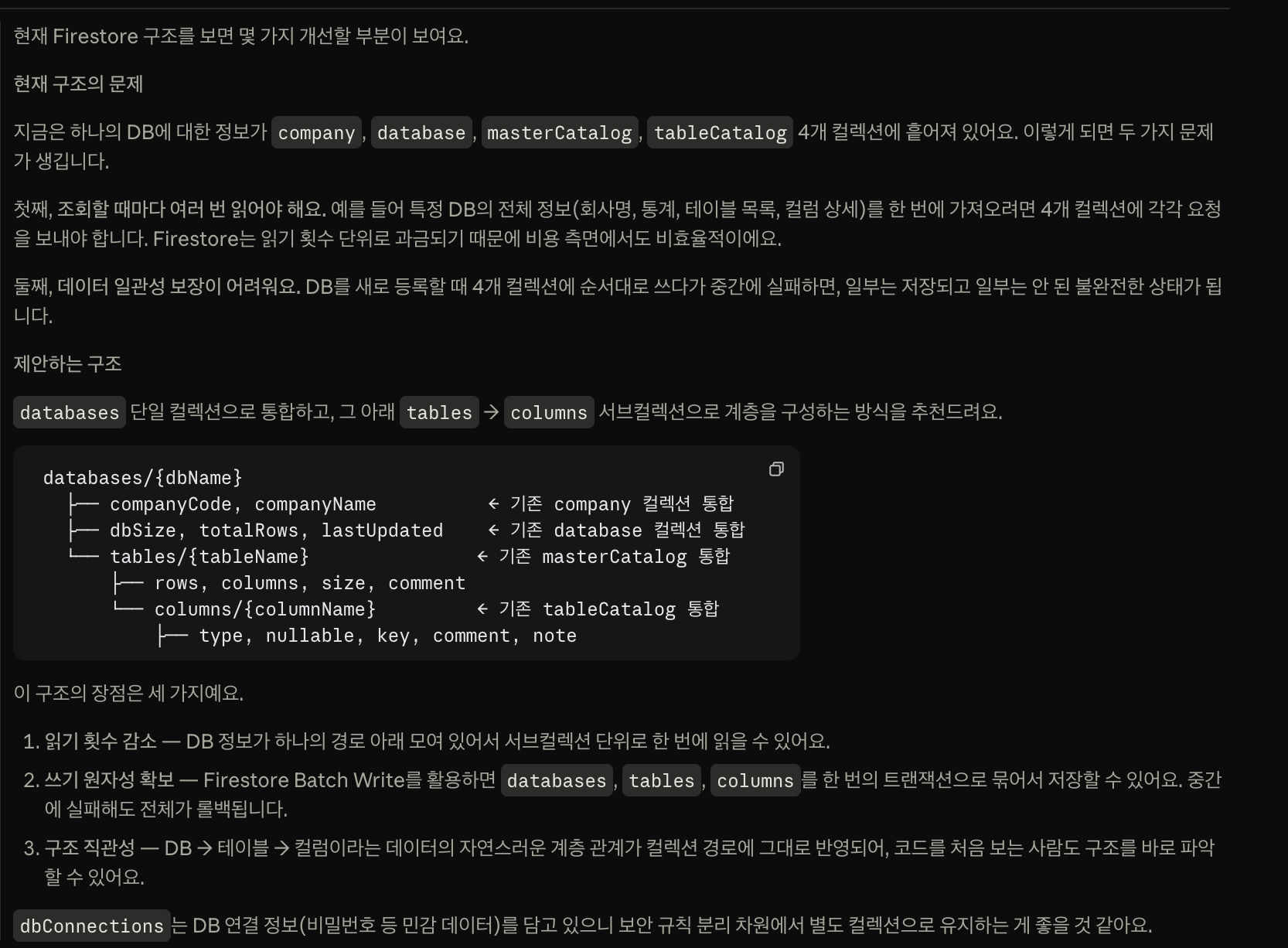
Claude는 관련 데이터를 DB 문서를 중심으로 계층화하는 구조를 제안했다.
├── dbConnections/{companyCode}
│ ├── host, port, userName, password, dbName
│
└── databases/{dbName}
├── companyCode, companyName
├── dbSize, totalRows, lastUpdated, dbTag
└── tables/{tableName}
├── rows, columns, size, comment, description
└── columns/{columnName}
├── type, nullable, default, key, comment, note기존에는 회사 정보, DB 정보, 테이블 정보, 컬럼 정보가 여러 컬렉션에 나뉘어 있었지만,
변경 후에는 databases/{dbName} 아래에 테이블과 컬럼 정보를 계층적으로 관리하도록 바꿨다.
이렇게 구조를 바꾸면서 하나의 DB를 조회할 때 접근해야 하는 컬렉션 수를 줄일 수 있었다.
👏 구조 변경 후 개선된 점 : "Firestore 읽기 횟수 감소"
| API | 설명 | 이전 Firestore 읽기 | 이후 Firestore 읽기 | 절감 |
|---|---|---|---|---|
GET /:dbName/stats | DB 통계 조회 | database 1회 + company 1회 | databases 1회 | -1회 |
PUT /:dbName | 카탈로그 업데이트 | company 1회 + 이후 처리 | databases 1회 + 이후 처리 | -1회 |
GET /:dbName/diff | 스키마 변경 감지 | company 1회 + tableCatalog N회 | databases 1회 + tables N회 | -1회 |
GET /:dbName/erd | ERD 데이터 조회 | company 1회 + 이후 처리 | databases 1회 + 이후 처리 | -1회 |
기존에는 companyCode가 별도 company 컬렉션에 저장되어 있어서 이를 필요로 하는 API마다 company 컬렉션을 한 번씩 더 읽어야 했지만,
이제는 companyCode가 databases/{dbName} 안에 포함되어 별도의 읽기 작업이 사라졌다.
🐞 문제 3: Firestore 읽기 사용량 제한
카탈로그 페이지를 반복해서 조회하며 테스트하던 중, 조회할 때마다 API가 호출되면서 Firestore 읽기 사용량 제한에 도달하는 문제도 발생했다.
일일 무료 문서 읽기 횟수(일일 5만건)를 초과하자 아래와 같은 읽기 에러(Quota exceeded)가 발생했고 페이지 로드가 실패하는 현상이 나타났다.
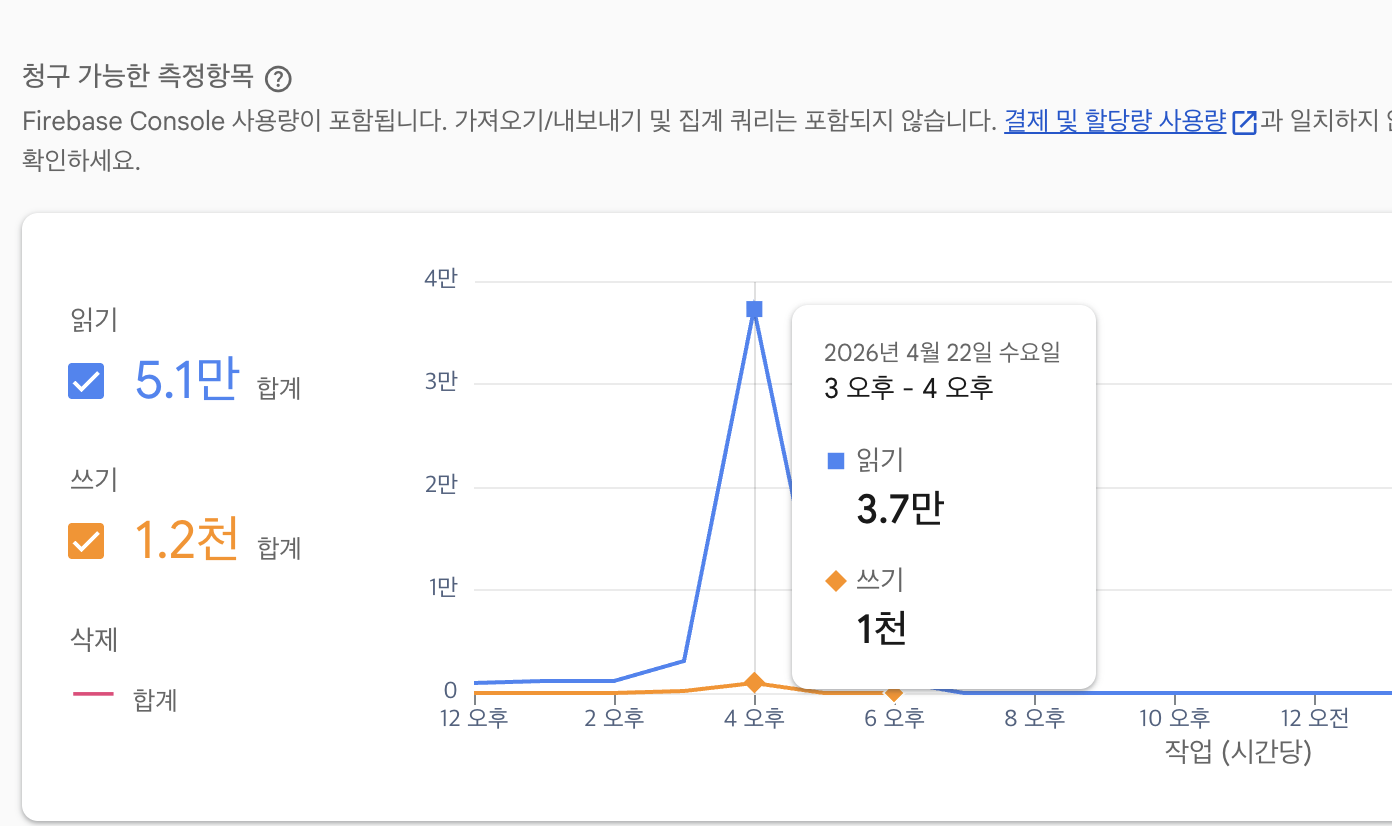 읽기 사용량 한도 초과 |
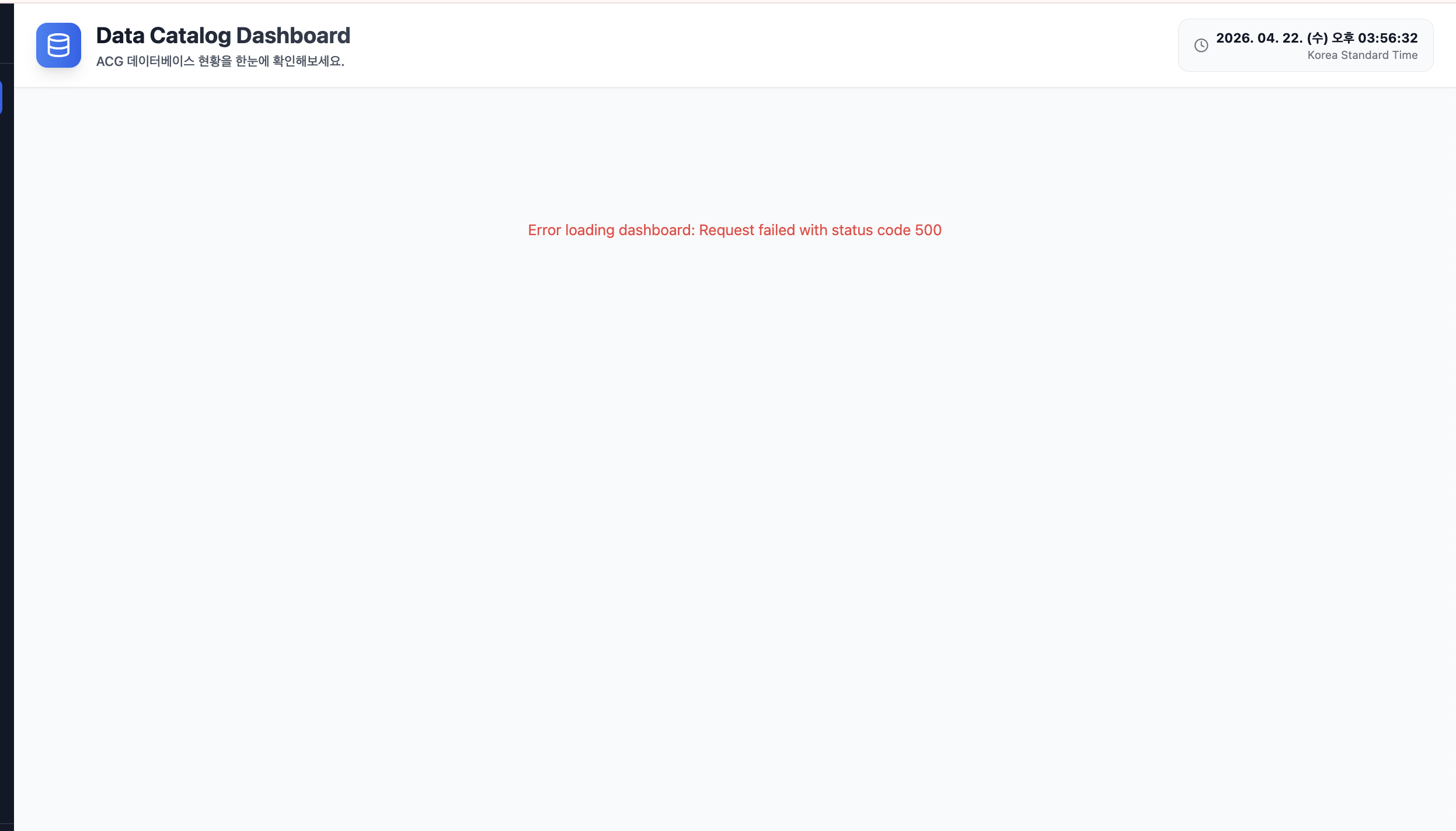 페이지 로드 실패 |
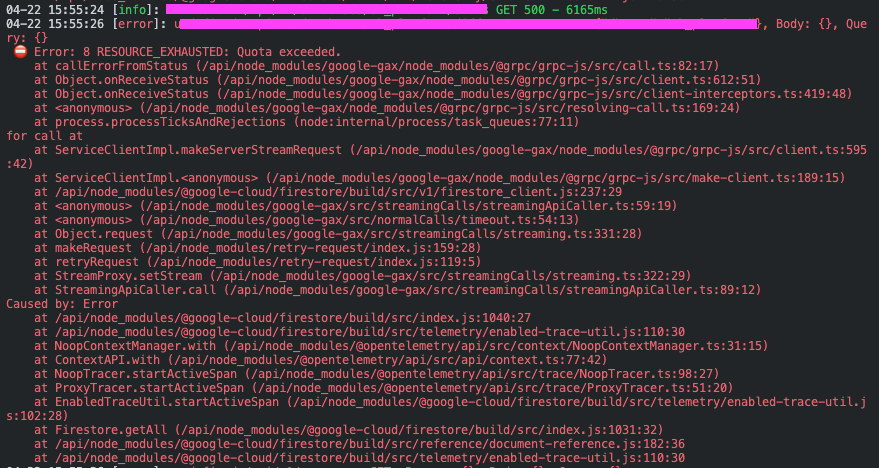 Quota Exceed 에러 |
원인
카탈로그 페이지를 조회할 때마다 호출되는 API들이 매번 Firestore에서 테이블과 컬럼 데이터를 "통째로" 읽어왔다. 한 번 조회할 때마다 수십 건의 읽기(Read)가 발생해서 페이지를 몇 번만 이동해도 무료 한도가 금방 채워질 수 밖에 없는 구조였다.
따라서 캐시(Cache) 방식을 도입하기로 했다.
자주 조회되지만 변경은 드문 데이터를 일정 시간 저장해 재사용하면 Firestore 접근 횟수를 줄일 수 있다고 판단했다. 또한 DB 부하를 낮추면서 API 응답 속도까지 개선할 수 있어, 성능과 비용 측면에서 효율적이라고 생각했다.
Redis 캐시 적용
조회한 결과를 Redis에 잠시 저장해두고, 동일한 요청이 들어오면 Firestore까지 접근하지 않고 Redis에서 바로 응답하도록 변경했다.
기존 애플리케이션 로직에 캐시 계층만 얹는 방식으로 가볍게 적용했다.
async getMasterCatalog(dbName: string) {
const key = `db:${dbName}:tables`;
// 1. 캐시에 있으면 그대로 반환
const cached = await this.redisService.getValues(key);
if (cached) return cached;
// 2. 없으면 Firestore에서 가져온다
const result = await this.firebaseService.getAllTables(dbName);
// 3. 다음 요청을 위해 캐시에 저장 (30분 후 자동 만료)
await this.redisService.setValues(key, result, 1800);
return result;
}“캐시 확인 → 없으면 조회 → 캐시에 저장”이라는 전형적인 Cache-Aside 패턴만으로도 충분해 보였다.
다만 실제 운영 환경에서는 단순 구현만으로 끝나지 않는 경우가 많다.
그래서 Codex와 함께 “이 구조에서 발생할 수 있는 예외 상황은 무엇이 있을까?”를 기준으로 여러 케이스를 검토했고, 아래와 같은 문제들을 추가로 점검하게 되었다.
☝🏻 Codex 권장: 같은 DB 이름으로 재등록될 때 대비하기
- 새 DB 정보를 등록할 때, 과거에 동일한 이름의 DB가 존재했다가 삭제된 뒤 다시 등록되는 경우가 있을 수 있다.
- 이때 이전 데이터나 빈 결과가 캐시에 남아 있다면, 새로 등록한 데이터가 반영되지 않는 문제가 발생할 수 있다.
➡️ DB 등록 직후 관련 캐시를 미리 삭제하는 안전장치를 추가
async createDbAndCatalog(dto) {
await this.firebaseService.saveAllBatch(/* ... 새 DB 저장 ... */);
// 같은 이름으로 과거에 캐시가 남아있을 수 있어 미리 비워둔다
await this.redisService.delKeys(`db:${dto.dbName}:tables`);
}☝🏻 Codex 권장: 빈 결과는 캐시하지 않기 (음수 캐싱 방지)
- 존재하지 않는 DB명이나 테이블명으로 잘못된 요청이 들어오면, 빈 배열이 그대로 캐시에 저장될 수 있다.
- 이후 실제 데이터가 등록되더라도 TTL이 만료되기 전까지는 계속 빈 결과만 반환되는 문제가 발생한다.
- 이런 현상을 음수 캐싱(Negative Caching) 문제라고 한다.
➡️ 조회 결과가 비어 있는 경우에는 캐시에 저장하지 않도록 처리
async getMasterCatalog(dbName) {
// ... 캐시 확인 및 Firestore 조회 ...
// 빈 결과는 캐시하지 않는다
if (result.length > 0) {
await this.redisService.setValues(key, result, 1800);
}
return result;
}☝🏻 Codex 권장: 캐시 키 정규화
- 캐시 키는 공백 한 칸이나 대소문자 차이만으로도 서로 다른 키로 인식된다.
- 따라서 저장 시 사용한 키와 삭제 시 사용한 키가 조금이라도 다르면 캐시 무효화가 실패할 수 있다.
- 쉽게 말해, 실제 데이터는 수정됐는데 사용자 입장에서는 “수정했는데 왜 반영이 안 되지?” 같은 상황이 발생할 수 있다.
➡️ 키 생성 함수에서 trim()을 적용해 키를 정규화
private keyMaster(dbName: string): string {
return `dc:v1:db:${dbName.trim()}:tables`;
}
private keyTable(dbName: string, tableName: string): string {
return `dc:v1:db:${dbName.trim()}:table:${tableName.trim()}:columns`;
}☝🏻 Claude 권장: Redis가 죽어도 서비스는 살아있게
- 당시 구조는 Redis 장애가 발생하면 관련 API 자체가 500 에러를 반환하는 상태였다.
- 하지만 캐시는 어디까지나 성능 최적화를 위한 “보조 수단”이지, 서비스 동작 자체를 멈추게 만드는 “필수 요소”가 되어서는 안 된다고 생각했다.
➡️ Redis 컨테이너가 죽더라도 캐시만 우회하고, 실제 데이터는 Firestore에서 조회하도록 흐름을 변경했다.
(일시적으로 응답 속도는 느려질 수 있지만 서비스 자체는 계속 동작하도록 하는 것이 목표였다.)
기존 구조 (Redis 장애 시 즉시 실패)
async getValues(key: string): Promise<string | null> {
const raw: string = await this.redis.get(key); // Redis 죽으면 throw
if (!raw) return null;
const values = JSON.parse(raw);
return values;
}개선 구조 (Redis 장애 시 캐시만 무시하고 장상 흐름 유지)
(Redis와 관련된 모든 메서드 로직을 try/catch로 감쌌다.)
// 캐시 조회
async getValues(key: string): Promise<string | null> {
try {
const raw = await this.redis.get(key);
if (!raw) return null;
const values = JSON.parse(raw);
return values;
} catch (err) {
this.logger.warn(`Redis 조회 실패 (${key}): ${err.message}`);
return null; // 캐시 miss로 간주
}
}
// 캐시 저장
async setValues(key: string, value: any, ttlSeconds: number): Promise<void> {
try {
await this.redis.set(key, JSON.stringify(value), 'EX', ttlSeconds);
} catch (err) {
this.logger.warn(`Redis 저장 실패`); // 저장 실패해도 응답은 정상 반환
}
}
// 단일 및 복수 키 삭제
async delKeys(keys: string | string[]): Promise<void> {
const list = Array.isArray(keys) ? keys : [keys];
if (list.length === 0) return;
try {
await this.redis.del(...list);
} catch (err) {
this.logger.warn(`Redis 삭제 실패`); // 삭제 실패해도 쓰기 작업은 성공 처리
}
}📊 결과: Firestore 읽기량 98% 감소
캐시가 적용된 Master Catalog 조회 API를 대상으로 JMeter를 활용해 부하 테스트를 진행했다.
테스트 설정
| - | 값 |
|---|---|
| Number of Threads (users) | 10 |
| Ramp-up Period | 5초 |
| Loop Count | 10 |
=> 5초에 걸쳐 10명의 사용자를 0.5초 간격으로 투입했고, 각 사용자는 응답을 받는 즉시 다음 요청을 보내는 방식으로 10번씩 반복해서 총 100건의 요청을 발생시켰다.
측정 결과
| - | 캐시 미적용 | 캐시 적용 |
|---|---|---|
| Firestore 읽기량 | 4.4천 | 72 (약 98.4% 감소) |
| Min 응답 시간 | 32ms | 2ms |
| Max 응답 시간 | 2348ms | 960ms |
단순히 Redis 캐시 계층을 추가한 것만으로도 Firestore 읽기량이 약 98% 이상 감소 (4.4천 → 72)했고, 응답 속도도 많이 개선되었다.
특히 이전에는 요청이 몰릴 때마다 Firestore 조회가 계속 발생해서 응답 속도가 상대적으로 느렸지만, 캐시 적용 후에는 대부분 Redis에서 바로 처리되다 보니 전체적으로 훨씬 안정적으로 동작하는 걸 확인할 수 있었다.

|
 캐시 미적용 (catalog-before) |
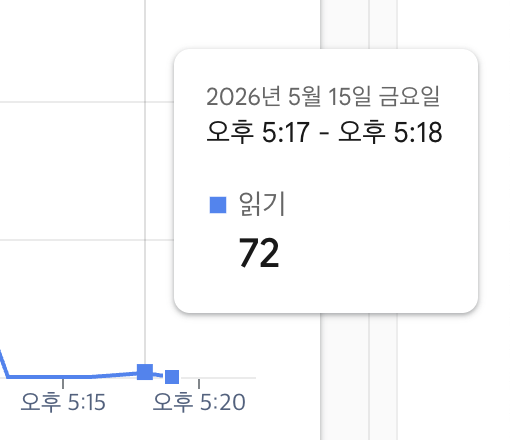 캐시 적용 (catalog-after) |
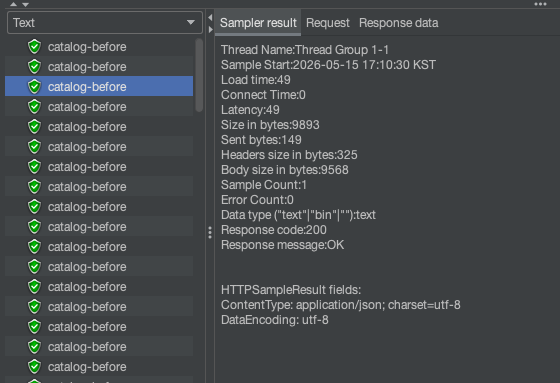 캐시 미적용 (catalog-before) |
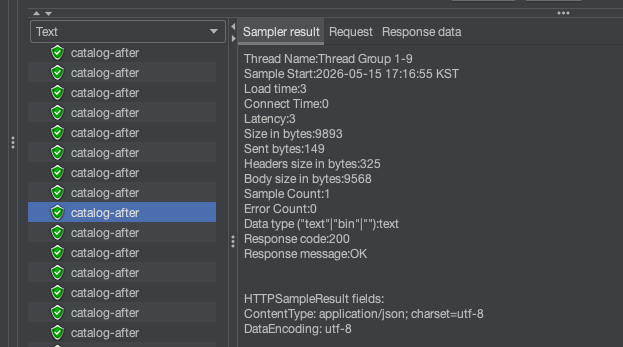 캐시 적용 (catalog-after) |
🐞 문제 4: mysql Pool 방식 개선
네 번째 문제는 새 DB를 등록하는 API에서 발견됐다.
DB를 새로 등록하는 시점에는 아직 해당 DB에 대한 Connection Pool이 존재하지 않는다.
일회성으로 MySQL에 직접 연결하기 위한 createDirectConnection() 함수를 별도로 사용하고 있었는데, 이 함수 안에서 단일 커넥션이 아니라 createPool()로 새로운 Pool을 생성하고 있었다.
// repository.ts
import { PoolConnection, createPool } from 'mysql2/promise';
async createDirectConnection(dbInfo): Promise<PoolConnection> {
const pool = createPool({ ...dbInfo, connectionLimit: 10 });
return pool.getConnection();
}
// service.ts
...
finally {
connection.release(); // 커넥션을 pool에 반납할 뿐, pool이 종료되지는 않음
}pool은 함수 내부 지역 변수라, 함수가 끝나면 참조가 사라진다.
따라서 connection.release()를 호출해도 이는 풀에 반납하는 것일 뿐, 풀 자체는 닫히지 않는다.
왜 문제가 될 수 있을까?
POST DB 등록 API 호출 횟수별 누적
호출 1회 -> orphan pool 1개
호출 10회 -> orphan pool 10개
호출 50회 -> orphan pool 50개
호출 100회 -> MySQL max_connections 기본값(151)에 근접 -> 서비스 장애
※ orphan pool: 정리되지 않은 pool정리되지 않는 pool이 쌓이면 MySQL connection을 계속 점유하게 된다.
이 상태가 누적되면 신규 DB 등록 API 뿐만 아니라 정상적으로 동작하던 다른 API까지 connection을 못 얻는 상황으로 이어질 수 있었다.
따라서 해당 코드를 Claude에게 보여주고 분석을 요청했다.
☝🏻 Claude의 제안 3가지
Claude는 수정 방향 세 가지를 제안했다.
| 방법 | 설명 |
|---|---|
| 방법 A | createPool() 대신 createConnection()으로 단일 연결만 생성하고, 작업 후 connection.end()로 완전히 종료 |
| 방법 B | 풀을 생성하되 풀 참조도 함께 반환해서, finally에서 pool.end() 호출을 보장 |
| 방법 C | 신규 DB 등록 시에도 기존 poolCache에 일시적으로 통합해 관리 |
필자는 방법 A를 선택했다.
신규 DB 등록 과정은 일회성 연결만 필요하다.
등록 시점에 잠깐 MySQL에 연결해서 스키마 정보를 조회하고 작업이 끝나면, 그 즉시 연결을 종료하면 된다.
따라서 이 상황에서 pool까지 생성하고 관리하는 것은 오버스펙이라고 판단했다.
※ createConnection VS createPool
createPool(): 커넥션을 여러 개 미리 만들어두고 재사용하는 방식. 여러 요청이 동시에 들어올 때 커넥션을 빌려쓰고 반납하는 구조이므로, 장기 운영되는 서비스에 적합createConnection(): 커넥션 하나만 생성하는 방식. 일회성 연결로 주로 사용되며, 작업이 끝나면connection.end()로 즉시 닫아버리고 재사용하지 않음.
✌🏻 Codex가 수정한 로직
이후 실제 코드 수정은 Codex에게 요청했다.
Codex는 createPool 대신 createConnection을 사용하도록 변경했고, 작업이 끝난 뒤 finally에서 connection.end를 호출하도록 수정했다.
// 수정 후
import { createConnection } from 'mysql2/promise';
async createDirectConnection(dbInfo): Promise<Connection> {
return await createConnection({
host: dbInfo.dbHost,
port: dbInfo.dbPort,
user: dbInfo.dbUser,
password: dbInfo.dbPw,
database: dbInfo.dbName,
});
}그리고 호출부에서는 작업 완료 후 연결을 확실히 종료하도록 처리했다.
// service.ts
finally {
await connection.end();
}추가로 Codex는 기존 Pool 관리 로직에서도 개선 포인트를 하나 더 제안했다.
같은 DB에 대한 요청이 동시에 들어올 경우, Pool이 중복 생성될 수 있는 구조였기 때문에 Pool 생성 Promise 자체를 캐시에 먼저 등록하는 poolPromiseCache 방식을 제안했다.
다만 해당 서비스의 특성상 같은 DB에 대한 요청이 동시에 몰릴 가능성은 낮다고 판단해서,
이 개선안은 참고만 하고 실제 반영은 (아직) 하지 않았다.
/* Pool 생성 또는 캐시 재사용 (동시 생성 방지: Promise 캐시) */
private poolPromiseCache: Map<string, Promise<Pool>> = new Map();
private async getPool(companyCode: string): Promise<Pool> {
if (!this.poolPromiseCache.has(companyCode)) {
const poolPromise = this.createAndCachePool(companyCode);
this.poolPromiseCache.set(companyCode, poolPromise);
}
return this.poolPromiseCache.get(companyCode)!;
}
private async createAndCachePool(companyCode: string): Promise<Pool> {
const dbConfig = await this.connectDBConfig.getDBConfig(companyCode);
const pool = createPool({
host: dbConfig.host,
port: dbConfig.port,
user: dbConfig.userName,
password: dbConfig.password,
database: dbConfig.dbName,
waitForConnections: true,
connectionLimit: 10,
queueLimit: 0,
});
this.poolCache.set(companyCode, pool);
return pool;
}이번 수정의 핵심은 일회성 연결에는 pool을 쓰지 않는 것이었다.
기존에는 새 DB 등록 시마다 pool을 만들고도 종료하지 못할 가능성이 있었지만
수정 후에는 단일 connection만 생성하고 작업이 끝나면 connection.end()로 명확하게 종료하도록 했다.
🤷♀️ What's Next ..?
이번 글에서 다룬 개선 작업은 여기까지다.
"Firestore Batch Write 적용",
"컬렉션 구조 재설계",
"Firestore 읽기 사용량 개선",
"MySQL Connection 누수 가능성 줄이기" 까지.
처음에는 기능이 동작하는 데 집중했다면 이번에는 동작은 하지만 안정적이지 않았던 부분들을 점검하고 개선하는 데 집중했다.
그 과정에서 계속 머릿속에 남는 질문이 있었다.
Data Catalog를 왜 만들었는가
메타데이터가 제대로 관리되지 않으면 사람도 AI도 결국 추론에 의존하게 된다.
이 컬럼이 어떤 의미인지, 어떤 테이블과 연결되어 있는지, 어떤 맥락에서 사용되는지를 매번 추측해야 한다면 데이터 해석의 오류는 피하기 어렵다.
Data Catalog는 이런 추측의 여지를 줄이고 데이터를 더 신뢰할 수 있게 만드는 도구라고 생각한다.
앞으로는 단순한 테이블 명세 관리에서 더 나아가, 조금 더 데이터 허브 에 가까운 방향으로 확장해보려한다.
데이터가 어디서 오고 어떻게 흐르는지 추적하고, 품질을 관리하고, 사람과 AI 모두가 이해할 수 있는 메타데이터를 쌓아가는 것이 다음 목표다.
-
Data Lineage
데이터가 어떤 테이블에서 시작해 어디로 이동하고 어떤 서비스나 분석 과정에서 사용되는지 추적하기 -
Data 품질 관리
null 비율, 중복 데이터, 누락 값, 비정상 값을 기준으로 데이터 품질을 점검할 수 있는 구조 만들기 -
비즈니스 메타데이터 강화
단순 컬럼 설명 + 컬럼의 업무적 의미, 담당자, 사용 목적 등을 함께 관리하기 -
AI가 이해할 수 있는 Catalog 구조
AI가 테이블과 컬럼의 의미를 더 정확히 이해할 수 있도록 설명, 태그, 관계 정보를 구조화하기
사실 이건 글을 쓰면서 떠오른 아이디어들을 브레인스토밍한 것에 가깝다.
물론 처음부터 완벽한 데이터 플랫폼을 만들 생각은 없다.
지금 필요한 구조를 먼저 만들되, 나중에 확장할 가능성을 열어두는 방향으로 설계하려 한다.
지금은 어디까지 만들고 무엇을 열어둬야 나중에 무리 없이 확장할 수 있을까
이 질문을 계속 붙들고 Data Catalog Service를 조금씩 더 신뢰할 수 있는 데이터 허브로 발전시켜보려 한다.
