도메인 문서에 대한 RAG 시스템의 정확도 향상을 위해 간단하게 진행했던 실험들 기록
Code
1. 평가용 QA 데이터셋 구축
RAG 방법론의 효과를 검증하기 위해 RAGAS 프레임워크와 AI API ( gpt 5.2 )를 사용한 정답/오답 채점을 사용했습니다.
이를 위해 다음과 같은 데이터 컬럼을 준비합니다.
| Question | Ground Truth | Answer | Retrieved Contexts |
- Question : 사용자 질의
- Answer : SLM 모델 답변
- Contexts : VectorDB로 부터 Retirever가 답변 생성을 위해 찾은 근거 Contexts
- Ground Truth : 사용자 질의에 대한 정답
Question, Ground Truth 컬럼 문항 제작에는 NotebookLM을 활용했는데 단락 출처 기능을 통해 Context에 근거하여 올바른 Answer가 도출되었는지 타당성을 검증하기 용이하기 때문입니다.
도메인 pdf 문서는 대략 500 page 정도이며 QA 데이터셋은 105문항 준비하였습니다.
NotebookLM에서 사용된 프롬프트는 다음과 같음.
프롬프트
당신은 Retrieval-Augmented Generation(RAG) 시스템 평가를 위한 QA 데이터셋을 제작하는 전문가입니다.
아래에 주어지는 문서를 기반으로, RAGAS 평가에 사용 가능한 고품질 질문–답변(QA) 쌍을 생성하세요.
모든 질문과 답변은 반드시 문서 내용에만 근거해야 합니다.
아래 규칙을 반드시 모두 지키세요.
[규칙]
1. 모든 질문과 답변은 반드시 한국어로 작성하세요.
2. 각 질문은 문서의 정보 없이는 답할 수 없어야 합니다.
3. 각 질문은 단 하나의 명확하고 모호하지 않은 정답을 가져야 합니다.
4. 의견형, 추론형, 주관식, 열린 질문은 생성하지 마세요.
5. 일반 상식이나 외부 지식이 없어도 문서만으로 답할 수 있어야 합니다.
6. 정의, 조건, 수치, 명시적인 사실에 대한 질문을 우선적으로 생성하세요.
7. 답변은 한 문장 이내의 간결한 사실 진술이어야 합니다.
8. 문서에 정보가 충분하지 않다면 질문 수를 줄이세요.
9. 해당 문서 조각이 검색되지 않으면 실패하는 질문이어야 합니다.
[출력 형식 – 매우 중요]
- 엑셀에 붙여넣기 하기 편하도록 표로 만들 어주세요.
- 표에는 Question, Answer, Context로만 구성되어야합니다.
- 표는 | 질문 | 정답 | Context| 형태를 따라야 합니다.
- Context는 근거가 되는 문장을 변형없이 그대로 적어주세요.- 프롬프트 7번항목의 “ 답변은 한 문장 이내의 간결한 사실 진술이어야 합니다.” 때문에 RAGAS 평가 metric중 answer_relevancy의 절대값이 낮게 나옴.
- 상대적인 비교가 중요하기 때문에 그대로 진행.
- NotebookLM을 통해 Context를 생성하긴 하지만 개인 검증용이며 RAGAS 프레임워크 사용시 활용되는 Context는 아님. RAGAS에는 실제 RAG 파이프라인에서 답변을 위해 사용되는 Context가 사용됨.
2. 실험 환경 및 Baseline 구축
사용 모델들
LLM: Gemma3 12b
Embedding Model: ko-bert-sts
Reranker: bge-reranker-v2-m3
Vector DB: ChromaDB
3. 테스트
2-1 Exp(1) : Baseline
Chunking 전략 : RecursiveCharacterTextSplitter (size 500, overlap 50)
- Vector DB 빌드 흐름도
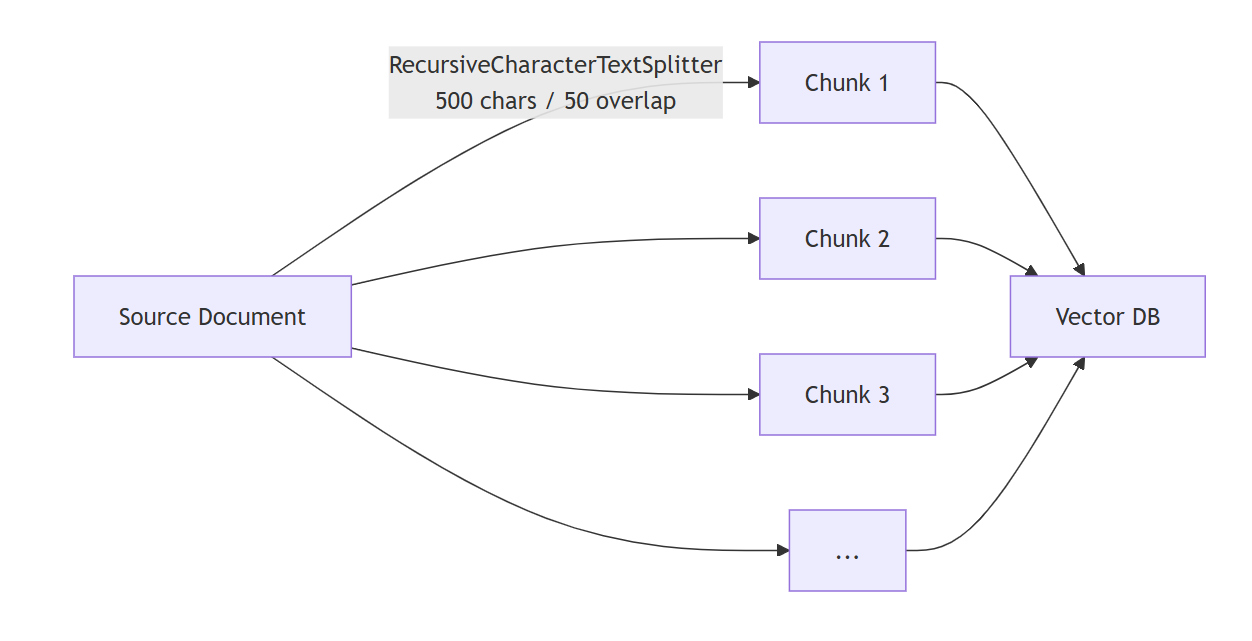
- RAG 흐름도

RAGAS 평균 점수:
- Faithfulness: 0.8267
- Answer Relevancy: 0.5043
- Context Precision: 0.6792
- Context Recall: 0.6762
정답 개수: 67 / 105
정확도(Accuracy): 63.81%
2-2 Exp(2) : Chunking 전략 변경
Chunking 전략 : : Hierarchical Chunking (Parent-Child)
Exp(1)에서 잘못된 문맥 단락을 가져오는 오답케이스가 많아 이를 개선하기위해 작은 단락이 포함된 큰 단락을 context로 제공하는 Hierarchical Chunking을 도입했습니다.
- DB 빌드 흐름도
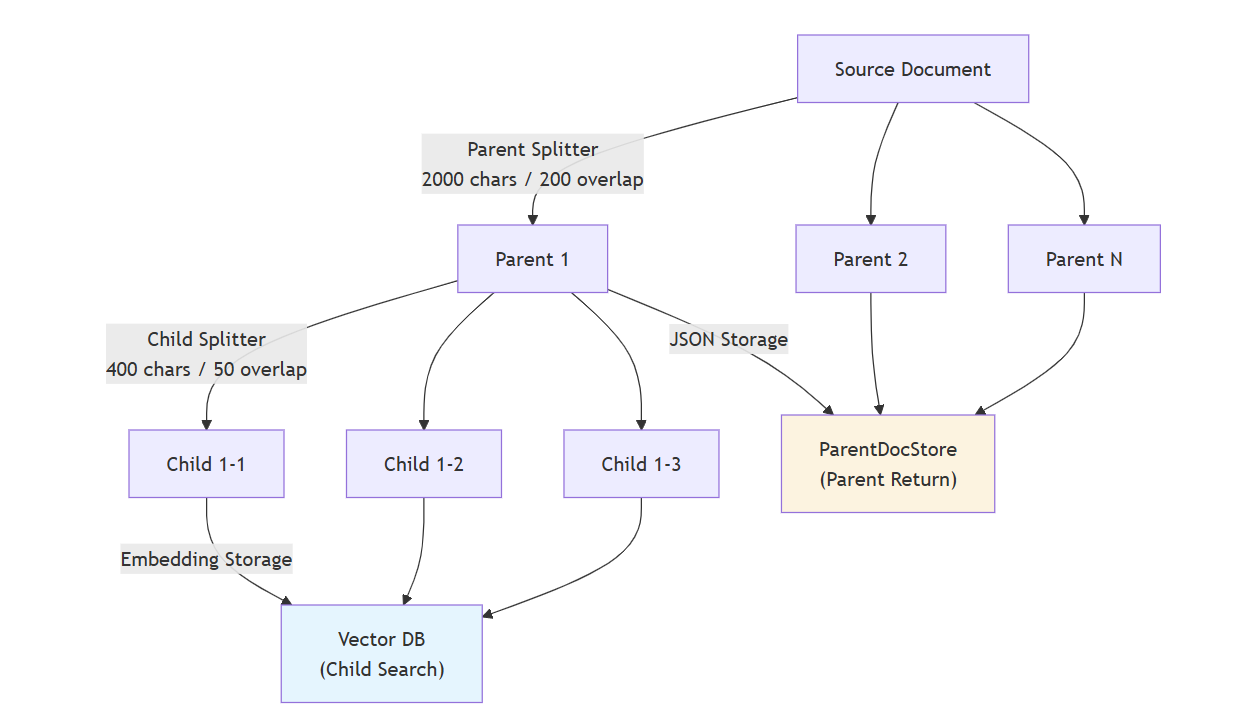
- Chunking 전략에 따른 흐름 차이

시간 관계상 Baseline에서 틀린 문항 38개에 대해서만 재평가를 진행했습니다.
RAGAS 평균 점수:
- Faithfulness 0.8581 | Baseline + 0.0314
- Answer Relevancy 0.4985 | Baseline - 0.0058
- Context Precision 0.7337 | Baseline + 0.0545
- Context Recall 0.7429 | Baseline + 0.0667
틀린 38문항 중 9문항 (23.68%)
최종 누적 정확도: 72.38% (76/105)
2-3 Exp(3) : GraphRAG 도입
구체적인 수치가 누락되거나 틀리는 오답을 처리하기 위해 Graph RAG 도입을 시도했습니다. 하지만 IE(Information Extration) Model 도입, Graph DB 구축 등 리소스 문제로 인해 보류 후 Exp(4)로 진행했습니다.
2-4 Exp(4) : Hybrid Search (BM25 + Dense Retriever) 구성
구체적인 수치나 전문용어가 context 검색에서 누락되는 문제를 해결하기위해 단어의 정확한 매칭 빈도를 고려하는 TF-IDF계열 알고리즘 BM25을 도입한 하이브리드 검색을 구현했습니다.
- Hybrid Search 흐름도.
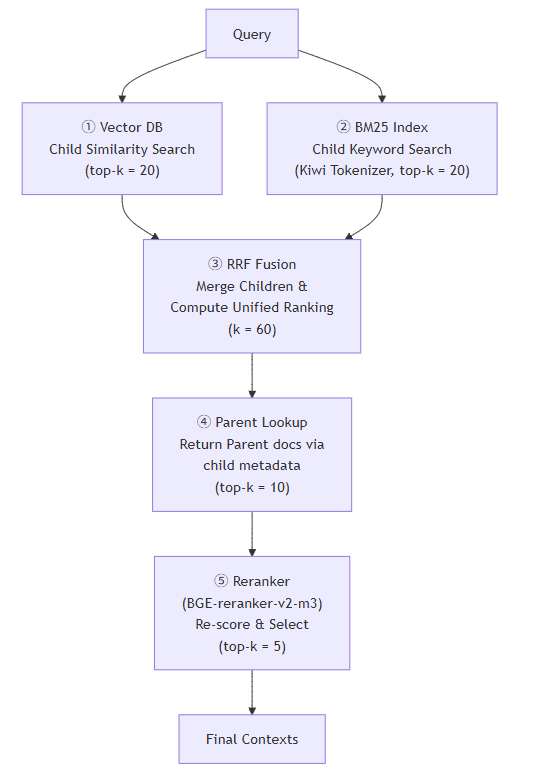
RAGAS 평균 점수:
- Faithfulness: 0.8267 | Baseline + 0.0160
- Answer Relevancy: 0.5164 | Baseline + 0.01210
- Context Precision: 0.8078 | Baseline + 0.1286
- Context Recall: 0.8095 | Baseline + 0.1333
틀린 29문항 중 13문항 정답 (44.83%)
최종 누적 정확도: 84.76% (89/105)
의견 : 가져오는 Context 부분에서 크게 개선됨.
4. 오류 유형 분석
정확도 84.76% 달성 후, 여전히 틀린 문제들을 4가지 유형으로 분류하여 분석했습니다.
유형 1. 리트리버 실패 (완전 오답 - 8건):
- 검색기가 필요한 문서를 아예 가져오지 못한 경우입니다.
유형 2. 일부 누락 (애매한 오답 - 3건):
- 정답에 있는 조건 중 일부만 답변한 경우입니다. (예: 제품 사양의 여러 카테고리 중 모두 정확하나 한 카테고리의 수량 만 누락)
유형 3. 질문 자체의 오류 (2건):
- QA 데이터셋 설계 문제로, 평가에서 제외합니다. 시간 관계상 QA데이터셋 검토하는 필터링에서 누락된 걸로 보입니다.
유형 4. 오답 처리되었으나 실제론 정답인 경우 (3건):
- LLM이 의미상 맞는 말을 했으나, 정답의 형태(백분율 계산식, 미만/이하 표현 등)와 달라 오답 처리된 케이스입니다.
부적절한 질문(유형 3)을 모수에서 제외하고, 유형 4를 정답으로 인정하면 89.32% (92/103).
여기에 일부 누락(유형 2)까지 정답으로 관대하게 인정할 경우 최종 정확도는 92.23% (95/103) 입니다.
5. 결론
Hierarchical Chunking 및 Hybrid Search 전략만으로도 성능이 크게 개선되는 것을 확인할 수 있었음.

취업 공고를 보면 Late-interaction도 사용되는 것 같음
Late-interaction, GraphDB 도입을 통한 추가 실험 제안
Reference.
3 Proven Strategies to Boost RAG Accuracy Beyond the Baseline
