온프레미스 환경 제약에서 수행한 Text2SQL 실험에 대해 기록함.
참고자료.
SQL이 필요한 이유 - AWS
Table Augmented Generation (TAG)
Text2SQL파이프라인 설계 사례 - Pinterest
Text2SQL이 어려운 이유
Text2SQL은 왜 자꾸 틀릴까?
2025 Text2SQL 서베이 논문
코드.
github
1. Text2SQL 이란?
Text2SQL은 사용자가 입력한 자연어 질문을 데이터베이스에서 실행 가능한 SQL(Query)로 변환하는 기술이다. 이를 통해 사용자는 SQL 문법을 직접 작성하지 않아도 자연어만으로 데이터베이스에 질의할 수 있다.
예를 들어,
사용자 : “최근에 발생한 알람 5개를 보여줘”
⬇
SQL 생성.
SELECT *
FROM alarm
ORDER BY create_time DESC
LIMIT 5;과거에는 Seq2Seq 기반 신경망 모델을 통해 Text를 SQL문으로 바꾸는 연구가 활발했지만.
최근에는 LLM을 통해 Text 문장을 SQL 문장으로 생성하는 연구가 주류임.
2. Text2SQL 기술이 필요한 이유.
비전문가의 데이터 접근성 향상을 위해 필요하다.
예를 들어, Text2SQL 기술 도입을 통해
데이터 분석 요청 → 데이터 팀 → SQL 작성 → 결과 전달 파이프라인을
자연어 질문 → SQL 자동 생성 → 결과 조회 로 변경할 수 있음.
3. Text2SQL 기술이 어려운 이유.
1. 사용자 의도 파악의 어려움
- 자연어의 모호성에 의해 사용자의 의도를 파악하기 어려움.
예를 들어, "최근 알람 많이 발생한 장비 알려줘" 라는 질의에서 최근이 언제인지, 많이가 어느 정도인지, 어떤 장비인지 불명확함. LLM이 DB를 보고 판단해야함.
2. 비즈니스 맥락 부족
- 동일한 용어(예: 매출, 가동률)라도 부서나 상황에 따라 정의 혹은 계산 로직이 다를 수 있으며, 이를 설명하는 정보가 없으면 LLM이 잘못된 판단을 내림.
예를 들어, '가동률'을 계산할 때 일일 가동률일 수도있고 월간 가동률일 수도있음.
결국, Text2SQL에서 높은 성능을 달성하기 위해서는 DB 설계와 메타데이터 관리 단게에서 많은 공수가 들어가야함.
4. 실험 환경.
| 구분 | IR Pipeline | Coder Pipeline |
|---|---|---|
| LLM | Gemma 12b (vLLM 서빙) | Qwen2.5-Coder-7B (vLLM 서빙) |
| Embedding | Qwen3-Embedding 0.6b (TEI Docker) | 동일 |
| DB | PostgreSQL | 동일 |
5. 평가 방법.
단일 테이블에 한정해, 난이도에 따라 3단계로 나눠 {사용자 질의 - SQL 정답 - DB 실행 결과} 데이터셋을 제작함.
총 37개 테이블 중 description이 있는 26개 테이블 기반으로 49건 제작.
실험 대상 DB는 description 및 관련 문서가 부재했기 때문에 LLM을 활용해 명확한 테이블에 한해 한 줄 description을 추가했으며, 해당 description은 vector search 기반 semantic 스키마 링킹에 활용됨.
- Level 1-1 (19건): 단순 조회 — SELECT, FROM, WHERE (=, IN), ORDER BY, LIMIT
- 예시: "admin의 전화번호 알려줘"
- Level 1-2 (19건): 집계/패턴 매칭 — COUNT, SUM, AVG, GROUP BY, HAVING, LIKE, IS NULL
- 예시: "상태가 FAULT인 장비의 운영 로그는 몇건이지?"
- Level 1-3 (11건): 복합 논리 — 시간 계산, CASE문, 서브쿼리, 윈도우 함수
- 예시: "장비별 가장 최근에 발생한 운영 로그 하나씩 뽑아줘"
다중 테이블은 향후 실험 예정
6. IR-use Pipeline.
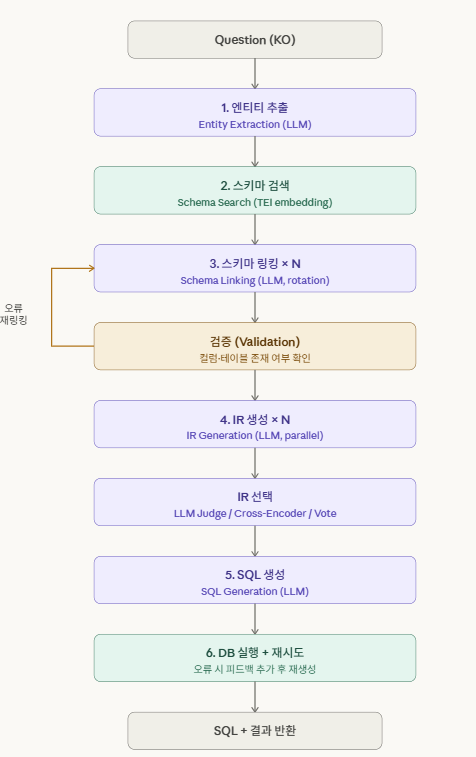
실험 결과
| 버전 | 주요 변경 | 1-1 | 1-2 | 1-3 | 전체 |
|---|---|---|---|---|---|
| V1 (베이스라인) | IR-use 파이프라인 기본 구조 | 26.3% | 42.1% | 18.2% | 30.6% |
| V2 | DB 스키마 기반 엔티티 추출 | 47.4% | 47.4% | 18.2% | 40.8% |
| V4+ | 컬럼 description + Self-Correction | 63.2% | 36.8% | 18.2% | 42.9% |
| V5 | SQL 프롬프트 태그 파싱 규칙 명시 | 52.6% | 63.2% | 9.1% | 46.9% |
| V7 | 프롬프트 전반 정제 | 57.9% | 63.2% | 27.3% | 53.1% |
V7에서 최고 53.1%를 달성했으나, 이후 파이프라인을 더 복잡하게 구성해도 성능이 오히려 하락함 스키마 링킹 → IR → SQL로 이어지는 다단계 구조에서 오류가 누적되는 것이 근본적인 문제였으며, V10 기준 평균 응답시간이 84초 수준으로 실 서비스 적용이 어려운 레이턴시였음
7. Coder Pipeline
구조
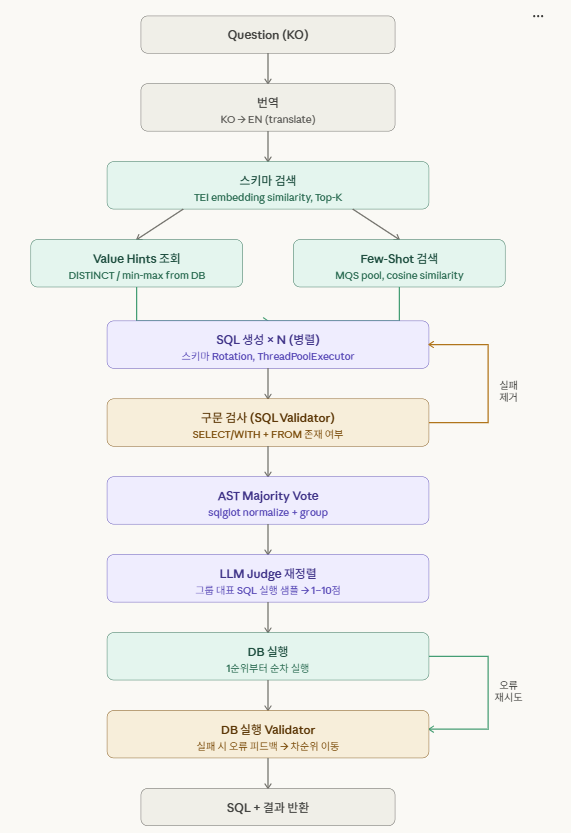
주요 도입 기술
Dynamic Few Shot
Spider 공개 데이터셋(~10,000개 질문-SQL 쌍) 기반 Pool을 구성하고, 사용자 질의와 유사한 예제를 임베딩 검색으로 찾아 프롬프트에 동적으로 추가함. 임베딩 모델을 통해 행렬 벡터(npz)로 저장하고 Exact Vector Search로 검색함.
Value Hints
스키마 후보 테이블의 실제 컬럼 값 일부를 DB에서 조회해 SQL 생성 프롬프트에 추가.
AST 기반 그룹핑
sqlglot 라이브러리를 통해 SQL 후보를 파싱하고, 의미적으로 동일한 쿼리를 그룹핑해 중복을 제거함. Majority Voting의 중복 문제를 해결하기 위해 처음 도입. LLM Judge 방법에서도 프롬프트의 양이 줄어들기 때문에 중복 제거는 필수적.
LLM Judge
Majority Voting 도입 시 틀린 SQL이 다수를 차지하는 문제가 있어 LLM Judge로 대체. 각 후보 SQL을 제한된 LIMIT로 미리 실행한 결과 샘플을 함께 첨부해 1~10점으로 채점 후 우선순위 정렬.
SQL Validator / DB 실행 Validator
- SQL Validator: SELECT/WITH로 시작하는지, FROM 절 존재 여부 등 기본 구문 검사. 통과 못 하면 후보군에서 제외.
- DB 실행 Validator: 1순위 SQL부터 실행 후 실패 시 오류 메세지를 프롬프트에 추가해 SQL 수정을 재요청. 재생성 실패 시 2순위로 이동.
8. 성능 변화 요약.
| 파이프라인 | 전체 정확도 | 평균 응답시간 |
|---|---|---|
| IR Pipeline 베이스라인 (V1) | 30.6% | — |
| IR Pipeline 최고 (V7) | 53.1% | ~84s |
| Coder 3B | 63.3% | ~1.5s |
| Coder 7B | 73.5% | — |
| Coder Pipeline + Coder 7B | 91.8% | ~1.5s |
9. 결론.
1. Coder 모델 도입 필수
General LLM 대비 Coder 모델의 SQL 생성 품질이 크게 높음. 3B는 답변 다양성이 부족해 생성 SQL의 숫자를 늘려도 효과가 없었으므로 최소 7B 이상이 필요함.
2. Coder Pipeline이 IR Pipeline보다 성능/속도 모두 우수
IR 기반 접근은 단계마다 오류가 누적되는 구조적 한계가 있었음. 최근 coder LLM의 reasoning 능력이 충분히 발전한 상황에서, 중간 표현 단계는 필요없음.
3. 향후 개선 사항 1 — GraphDB(온톨로지) 도입
다중 테이블 실험 시 JOIN Path 등이 중요해짐. GraphDB 구조로 스키마 관계를 표현하면 다중 테이블 링킹에서 효과적일 것으로 기대됨.
4. 향후 개선 사항 2 — DB 인덱스 튜닝
현재 실행 부하를 줄이기 위해 LIMIT 200을 붙이고 있으나, 실 서비스에서 대량 데이터를 렌더링해야 하는 경우 제거해야 한다. 관련해서 DB 인덱스 설계 필요할듯
