tensorflow-keras
1.Tensorflow에서 Distributed Training: 분산 학습하기

딥러닝 모델이 점점 커지면서 한 대의 GPU 또는 CPU만으로 학습을 완료하기 어려운 상황이 있다. 이를 해결하기 위해 사용하는 방법이 바로 분산 학습 (Distributed Training) 이다. Tensorflow는 이 과정을 지원하는 API를 제공하는데, 이를
2.Keras에서 Custom Loss Function 만들기
딥러닝 모델을 설계할 때, 기본 제공되는 손실 함수(MSE, MAE 등)로 충분하지 않을 때가 있다. 예를 들어, 데이터의 특정 패턴에 민감한 손실 함수가 필요하거나, 불균형 데이터에서 성능을 극대화하려는 경우들이 있다. 오늘은 keras에서 custom loss fu
3.Keras 사용자 정의 레이어: tf.keras.layers.Layer를 활용한 맞춤형 딥러닝 레이어 구현
Keras는 딥러닝 모델을 빠르고 간편하게 개발할 수 있도록 다양한 기본 레이어를 제공한다. 하지만 모든 경우에 기본 레이어만으로는 원하는 모델을 구현하기 어려울 수 있다. 예를 들어, 특정 계산이 포함된 복잡한 레이어나, 데이터의 특징에 맞춘 맞춤형 레이어가 필요할
4.tf.keras.layers.MultiHeadAttention 사용하기
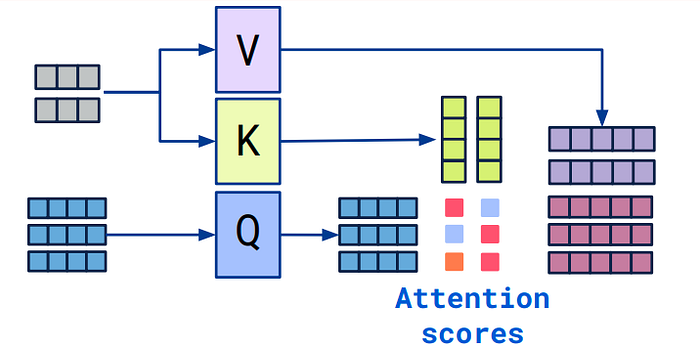
딥러닝 모델의 발전과 함께 Attention Mechanism은 다양한 분야에서 핵심적인 역할을 담당하게 되었다. 특히 Attention은 입력 데이터의 특정 부분에 집중할 수 있도록 하여, 모델이 더 나은 성능을 발휘할 수 있게 돕는다. 이 중에서도 Multi-Hea
5.Keras에서 모델 가중치 저장하기 !
딥러니 모델을 훈련할 때 ModelCheckpoint 콜백을 사용하면 특정 조건을 만족하는 가중치를 저장할 수 있다. 기본적으로 모든 에폭마다 가중치를 저장할 수도 있지만, 가장 좋은 성능(예: val_loss가 최소인 경우)을 보인 가중치만 저장하는 방법이 있다.기본