딥러닝 모델의 발전과 함께 Attention Mechanism은 다양한 분야에서 핵심적인 역할을 담당하게 되었다. 특히 Attention은 입력 데이터의 특정 부분에 집중할 수 있도록 하여, 모델이 더 나은 성능을 발휘할 수 있게 돕는다. 이 중에서도 Multi-Head Attention은 Transformer 아키텍처의 중요한 구성 요소로, 자연어 처리와 컴퓨터 비전 분야에서 혁신적인 결과를 이끌어낸 핵심 기술이다.
Multi-Head Attention은 단순히 하나의 Attention 매커니즈을 사용하는 대신, 여러 개의 Attention Head를 병렬적으로 사용한다. 이를 통해 모델은 서로 다른 표현 공간에서 정보를 학습하며, 데이터의 다양한 관계를 포착할 수 있다. 이러한 접근 방식은 단일 Attention보다 더 풍부한 표현력을 제공하며, 학습 성능을 크게 향상시킨다.
Keras에서는 tf.keras.layers.MultiHeadAttention 레이어를 통해 이러한 기능을 손쉽게 구현할 수 있다. 이 글에서는 Multi-Head Attention의 기본 개념을 살펴보고, Keras를 활용한 예제를 통해 이를 어떻게 적용할 수 있는지 설명할 것이다.
1. Multi-Head Attention의 기본 개념
Multi-Head Attention은 Attention Mechanism을 확장하여 데이터를 더 효과적으로 처리할 수 있게 만든 기술이다. 이를 이해하기 위해 먼저 기본 원리를 간단히 살펴보자.
1.1. Attention Mechanism 기본 개념
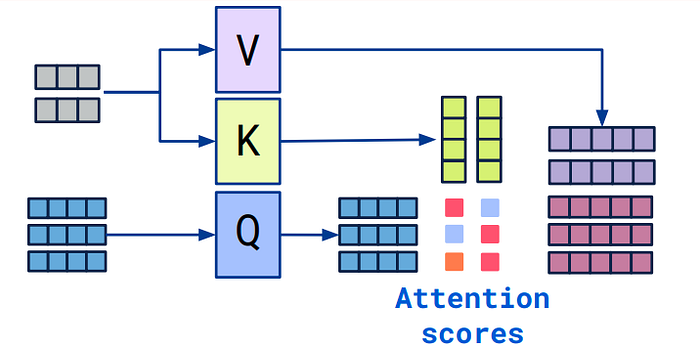
Attention Mechanism은 입력 데이터의 특정 부분에 집중할 수 있도록 가중치를 할당하는 과정이다. 이는 다음과 같은 세 가지 주요 입력으로 이루어진다:
- Query (Q): 현재 주목하고자 하는 정보
- Key (K): 데이터에서 각 항목을 식별하는 데 사용하는 정보
- Value (V): 실제로 추출하고자 하는 정보
Attention의 핵심은 Query와 Key 간의 유사도를 계산하고, 그 결과를 기반으로 Value의 가중합을 계산하는 것이다. 이를 통해 중요한 정보에 더 높은 가중치를 부여하고, 덜 중요한 정보는 줄이는 방식으로 작동한다.
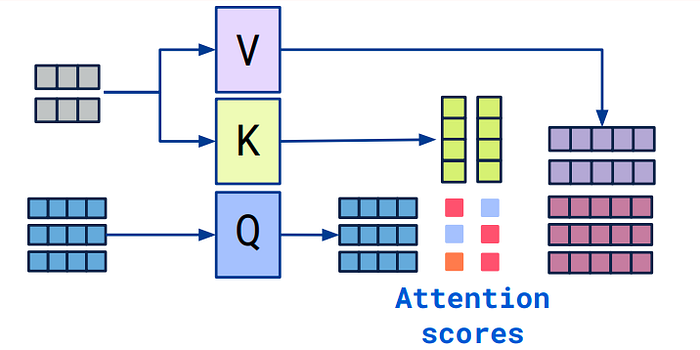
Attention Score는 Query와 Key 간의 유사도를 나타내는 값이다. 일반적으로 Attention score는 다음의 방법으로 계산된다.
- Dot Product: Query와 Key의 점곱을 계산하여 유사도를 얻는다.
- Scaling:L점곱 결과를 Key의 차원 의 제곱근으로 나눠 정규화한다.
수식으로는 다음과 같이 표현된다.
이 스코어는 Key가 Query와 얼마나 유사한지를 나타내며, 높은 스코어일수록 Query와 더 관련성이 높은 정보를 나타낸다.
1.2. value를 기반으로 한 최종 Attention Output
Attention score를 기반으로 Value에 가중치를 곱해 최종 Attention output을 계산한다:
여기서 각 Value는 Attention Score에 비례하여 조합된다. 결과적으로 중요한 정보는 더 높은 가중치를 받고, 덜 중요한 정보는 가중치가 낮아지며, 이를 통해 모델은 데이터에서 중요한 관계를 효과적으로 추출할 수 있다.
1.3. Multi-Head Attention 구조
Multi-Head Attention은 이러한 Attention mechanism을 확장하여 한 번에 여러 관점을 학습할 수 있게 만든 구조이다. 이를 통해 모델은 데이터를 다양한 방식으로 분석하고, 보다 풍부한 표현력을 갖추게 된다.
주요 단계:
- Query, Key, Value의 분리: 각 입력을 여러 Head로 나눔
- 독립적인 Attention Score 계산: 각 Head에서 독립적으로 Attention을 계산
- 결합: 모든 Head의 결과를 합쳐 최종 출력 생성
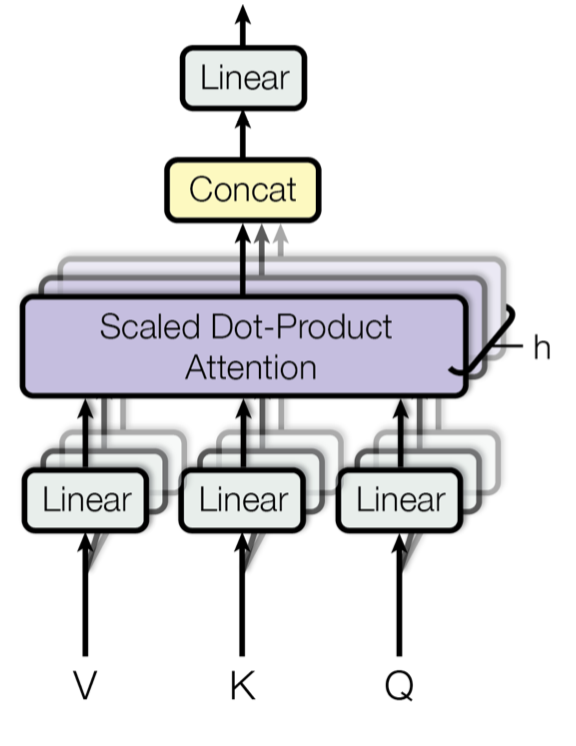
수학적 표현:
여기서 는 학습 가능한 가중치 행렬이다.
2. Keras Implementation: Multi-Head Attention 사용법
Keras에서는 tf.keras.layers.MultiHeadAttention 클래스를 사용하여 Multi-Head Attention을 간단하게 구현할 수 있다.
2.1. 주요 매개변수와 기능
tf.keras.layers.MultiHeadAttention 의 주요 매개변수는 다음과 같다:
num_heads: Attention Head의 개수를 지정한다. 각 Head는 서로 다른 관점에서 데이터를 분석한다.key_dim: 각 Head의 차원 크기를 정의한다. 이 값이 클수록 더 복잡한 표현을 학습할 수 있다.value_dim(선택 사항): Value 벡터의 차원 크기를 설정한다. 기본값은key_dim과 동일하다.dropout: Attention 계산 중 Dropout을 적용할 비율 설정.use_bias: Query, Key, Value에 Bias를 추가할지 여부 결정
이 때, num_heads와 key_dim은 모델의 성능과 계산 효율성에 영향을 미친다.
- Head 수가 너무 적으면 충분히 다양한 관계를 학습하지 못할 수 있다.
- 반대로 Head 수가 너무 많으면 계산량이 증가하고, 학습이 불안정해질 수 있다.
보통 Head 수는 4~8, key_dim은 64~128 사이의 값을 추천한다.
2.2. MultiHeadAttention의 입력과 출력
다음과 같은 입력을 받는다:
query: Attention의 query 텐서key: Attention의 key 텐서. Query와 동일할 수도 있다 (self-attention).value: Attention의 value 텐서
출력은 Attention 결과를 나타내는 텐서로, Query와 동일한 차원으로 반환된다.
2.3. Keras Implementation
import tensorflow as tf
mha = tf.keras.layers.MultiHeadAttention(num_heads=4, key_dims=64)
# self-attention
query = tf.random.uniform(shape=(2, 10, 128))
key = query
value = query
attention_output = mha(query=query, key=key, value=value)
print(attention_output.shape)
# (2, 10, 128)이 때 attention_output은 이 글의 앞서 1.2의 Attention Output이 계산된 값이다.
만약 Attention Score를 반환하고 싶다면 MultiHeadAttention 레이어에서 return_attention_scores=True로 설정하면 Score를 함께 반환받을 수 있다.
mha = tf.keras.layers.MultiHeadAttention(num_heads=4, key_dims=64, return_attention_scores=True)
# self-attention
query = tf.random.uniform(shape=(2, 10, 128))
key = query
value = query
attention_output, attention_scores = mha(query=query, key=key, value=value)
print(attention_output.shape) #(2, 10, 128)
print(attention_scores.shape) # (2, 4, 10, 10): (batch_size, num_heads, len_query, len_key)