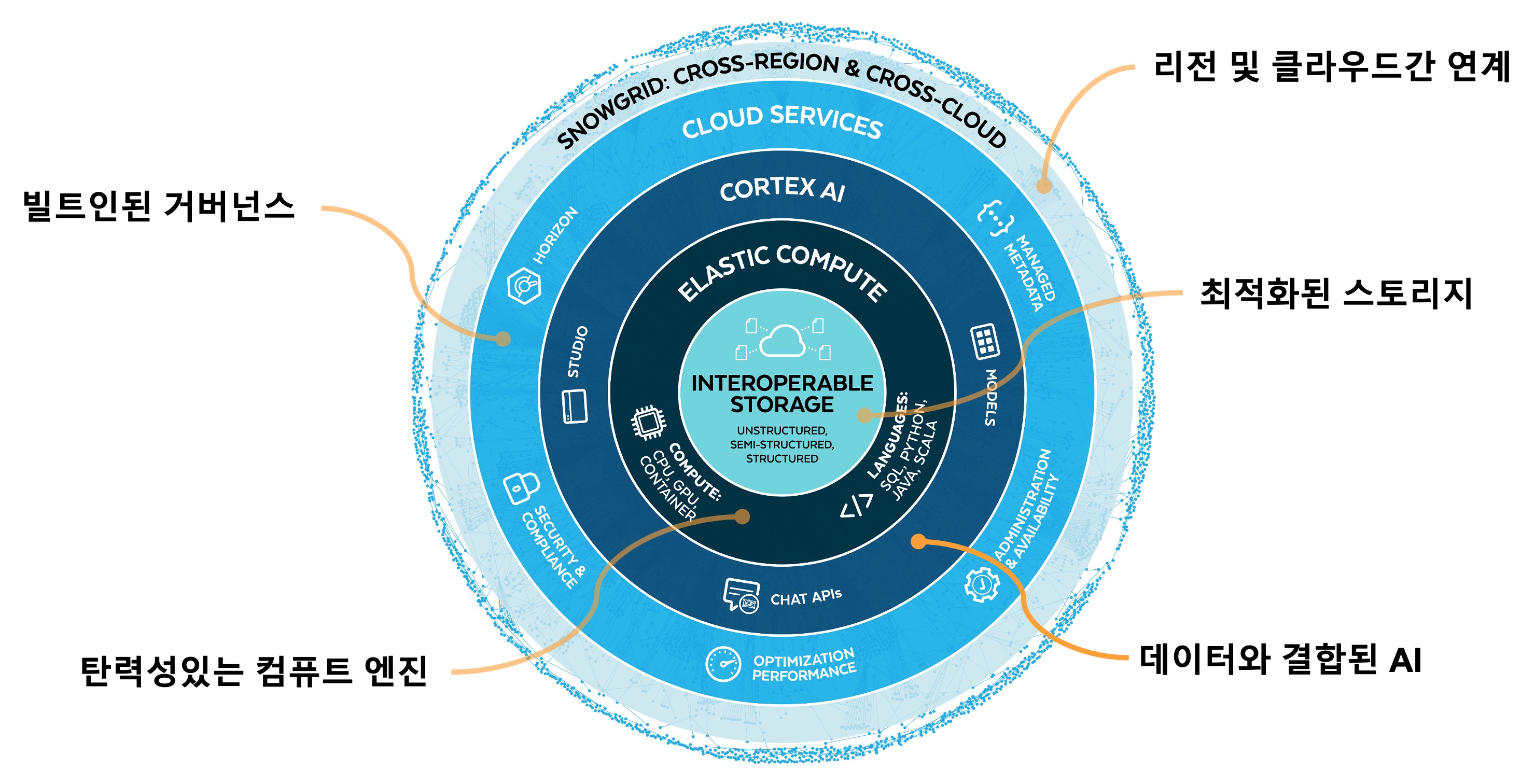
1.최적화된 스토리지
- 통합된 데이터 저장소
- 비정형, 반정형 및 정형 데이터를 위한 통합 저장소
- 단일 데이터 카피본: 여러 복제본 생성 불필요
- 필요시 데이터 볼륨이 온-디맨드 방식으로 자동 확장
- 관리 운영 자동화
- 컴퓨팅 리소스와 독립적으로 무한한 확장
- 자동 데이터 암호화 및 높은 압축
- 자동 백업, 무복사 클론
- 백업 작업 불필요
- 유연성 및 통합성 지원
- S3, Iceberg 및 On-Premise에 저장된 외부 데이터 직접 연결 지원
- 비용 효율성
- 사용한 만큼에 대해서만 과금되므로 스토리지 구축 및 확장을 위한 사이징 불필요
- 압축 후 크기를 기준으로 저장 공간에 대한 비용 청구
- 통합 빌링: 별도의 S3 청구 불필요
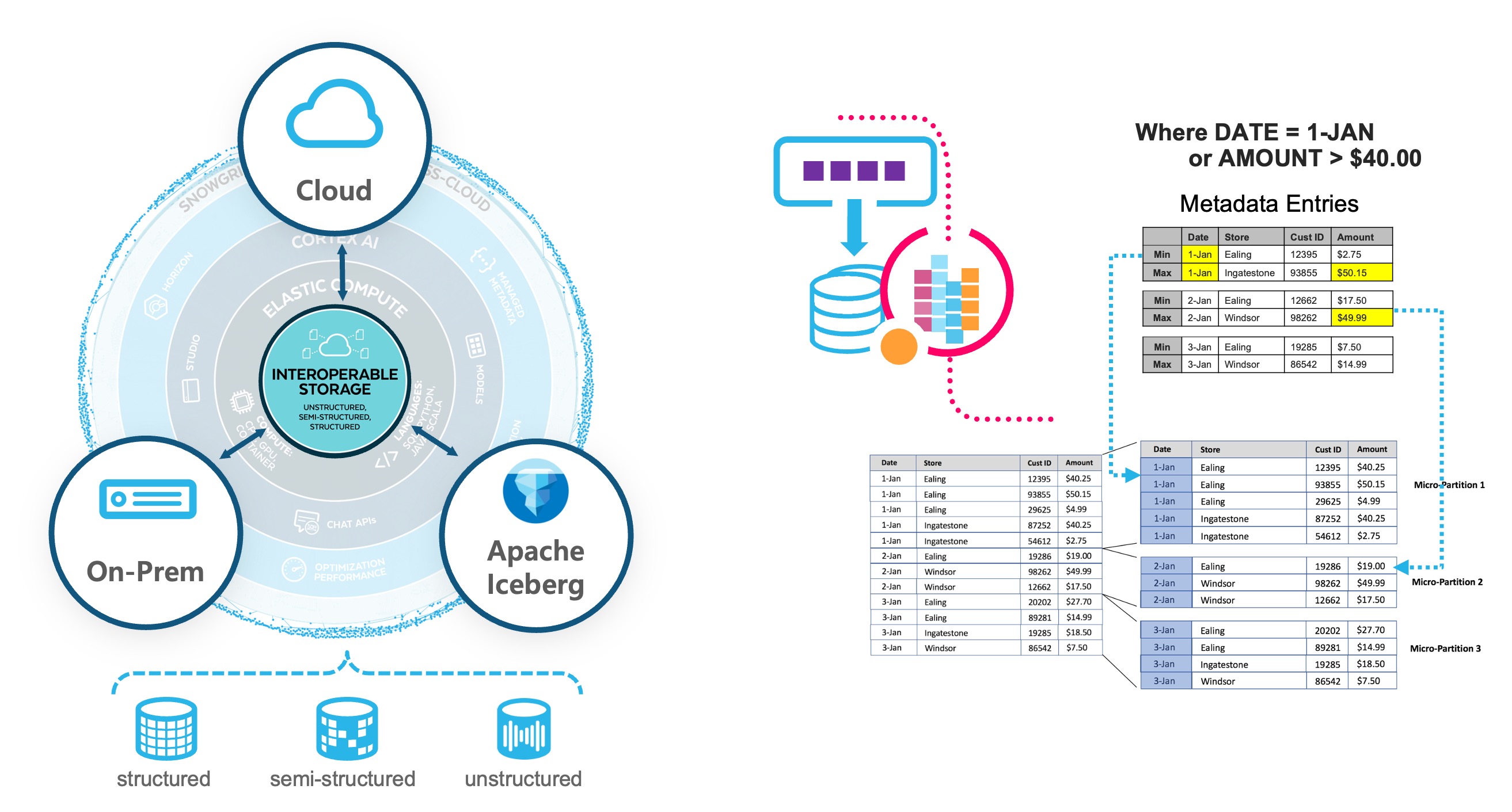
마이크로파티션 (Micro-Partitions)
- 자동 파티션
- 수집 순서에 따라 자동으로 분할
- DDL에 명시적인 파티션 정의 불필요
- 자동 압축
- 파티션 내에 컬럼 단위로 압축되어 약 16MB 단위로 파일 생성
- 비압축 기준 약 50MB ~ 500MB 데이터 포함
- 각 컬럼은 데이터 유형에 따라 가장 효율적인 압축 알고리즘 적용
- 주요 통계 정보 자동 관리 - 메타데이터
- 테이블 레벨 :
- row count
- table size
- table version
- file reference 등
- 컬럼 레벨 :
- min
- max
- range value
- distinct count
- null count
- 테이블 레벨 :
- 쿼리 효율을 위한 저장 방식
- 파티션 프루닝(Pruning) : 쿼리에 조회가 필요한 파티션을 메타데이터에서 확인하여 일부 파티션만 액세스
2.탄력성 있는 컴퓨트 엔진
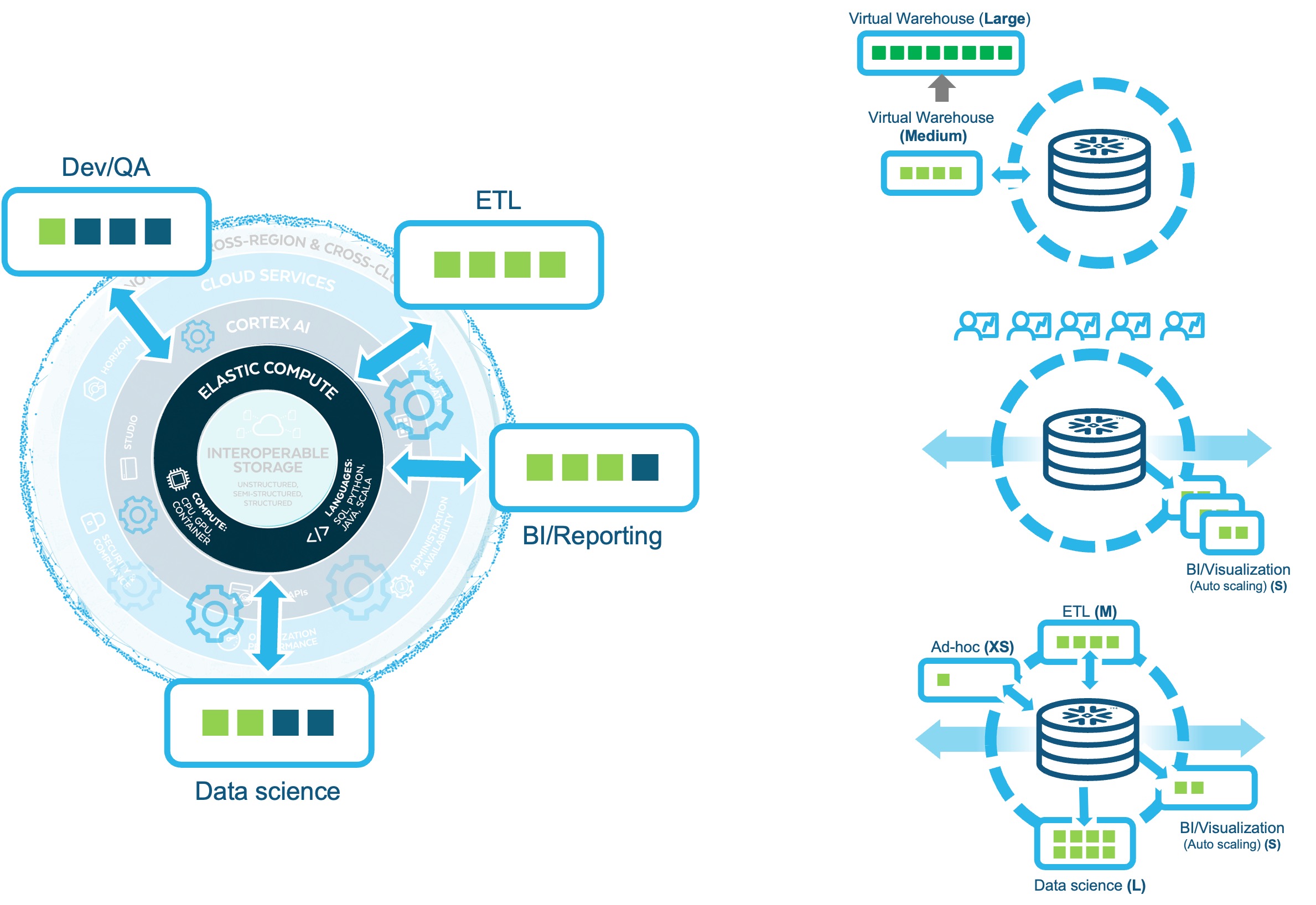
- 가상웨어하우스 - 스토리지와 분리된 컴퓨팅 환경
- 자유로운 scale up/out 확장성
- 온디맨드
- 가상 웨어하우스가 시작될 때 시스템 리소스 사용
- 자동 시작 및 중지 기능
- 가상 웨어하우스가 동작 중일 때만 비용 계산 (초 단위, 기본 1분)
- 워크로드 격리
- 다양한 워크로드별 가상 웨어하우스를 별도로 할당하여 샌드박스 형태의 실행 환경 구성
- 여러 워크로드가 리소스 경합없이 동시에 실행
- 사이즈
-
size XS S M L XL 2XL 3XL 4XL 5XL 6XL Credit/hour 1 2 4 8 16 32 64 128 256 512
-
가상 웨어하우스의 확장성
- Scale-Up
병렬 처리 수준을 높이는 방식으로 더 많은 시스템 자원을 병렬로 동시에 사용하여 더 많은 양의 데이터와 더 복잡한 쿼리의 성능을 높입니다 - Scale-Out
워크로드를 처리하는 가상 웨어하우스를 n개로 복제 생성하는 개념으로 다수의 사용자가 동일한 워크로드를 동시에 처리하는 경우 자동으로 확장됩니다 - Scale-Across
워크로드 유형별로 물리적으로 격리된 가상 웨어하우스 실행 환경을 구성하여 다수의 워크로드가 시스템 자원의 경합없이 수행되는 확장성을 가집니다
Scale-Up 확장성의 효과 - 비용과 성능의 균형
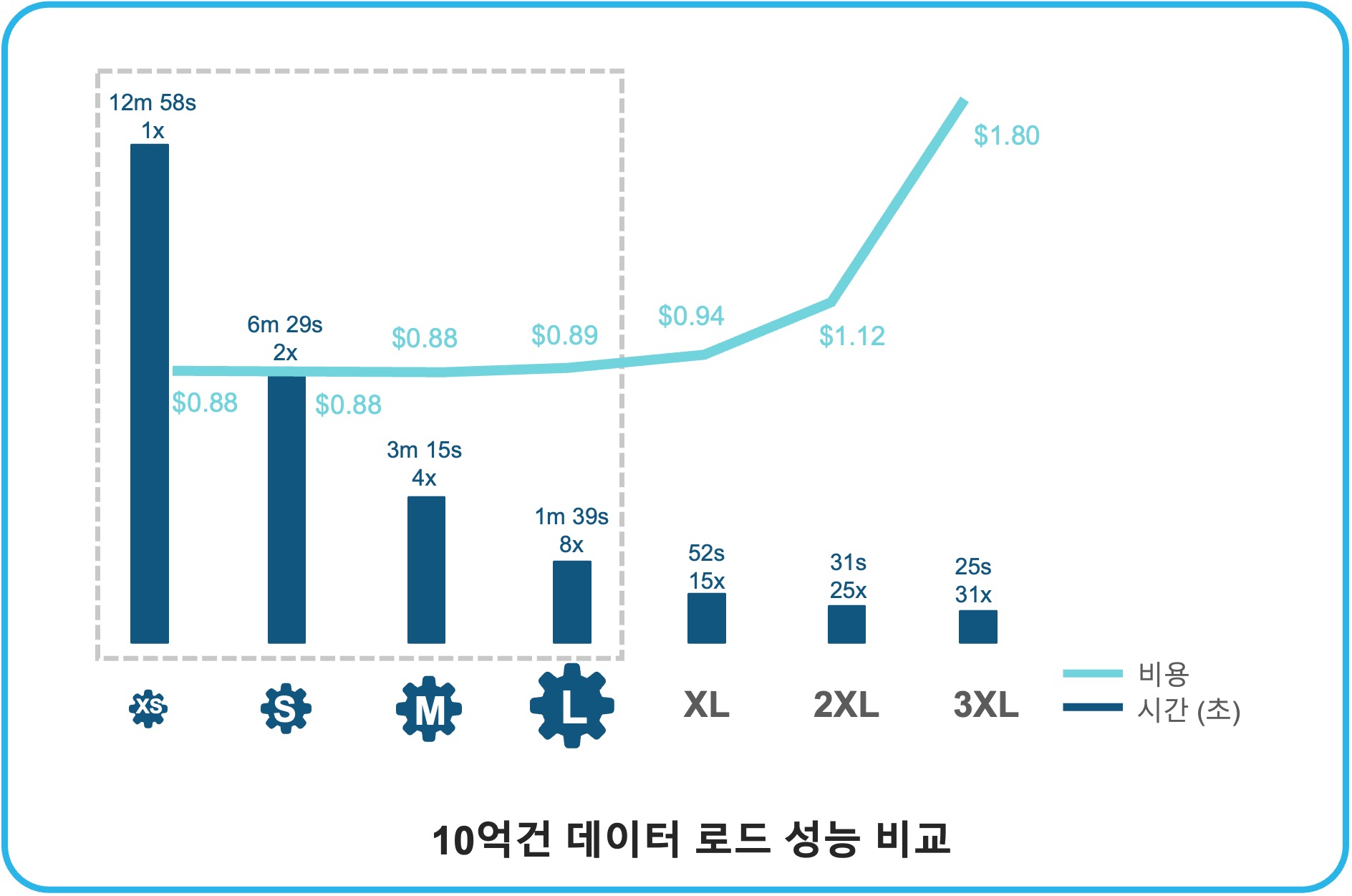
- 시간당 웨어하우스 크레딧 : Scale-up이 되면 2배 증가
- 처리 성능 : Scale-up으로 성능 2배 향상, 처리 시간 1/2 감소
- 비용 대비 효과 : 동일한 비용으로 처리 시간 감소
Scale-Out 확장성의 효과 - 워크로드 최적화
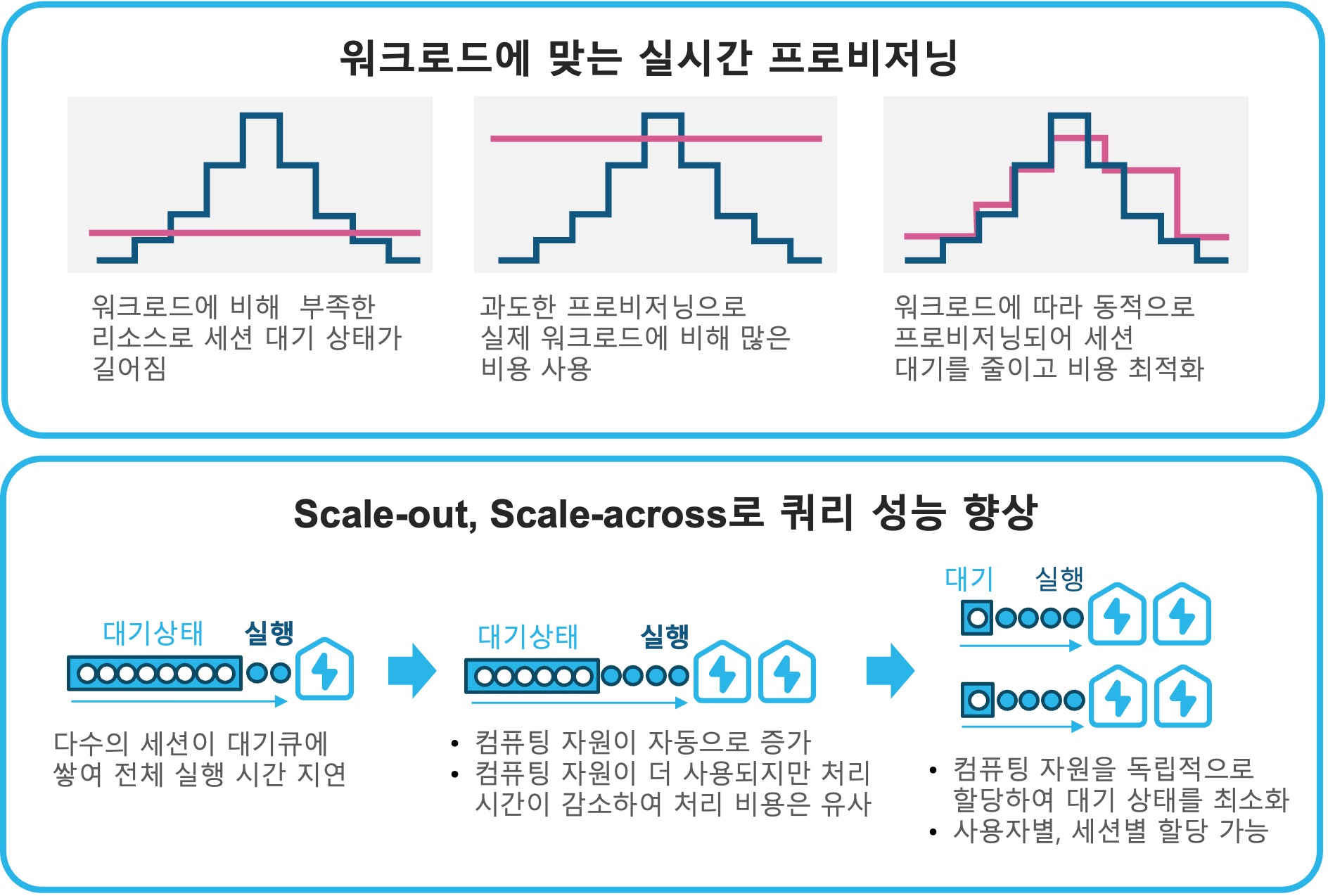
- 멀티클러스터 설정
- 세션에 대기큐가 쌓이면 자동으로 동일한 가상 웨어하우스가 추가
- 수행되는 세션이 없으면 추가된 가상 웨어하우스는 자동 반환
- 처리 성능
- 대기 상태의 세션수가 줄어 전체 평균 처리 시간이 감소
- 비용 대비 효과
- 멀티 클러스터 구성 시 활성화된 가상 웨어하우스 만큼 비용 발생
- 하지만 대기 세션이 줄어들어 전체 웨어하우스 사용 시간의 합은 유사
- 개별 세션의 처리 시간 중 대기 시간이 줄어들어 전반적 성능 향상
3.데이터와 결합된 AI
AI Data Cloud
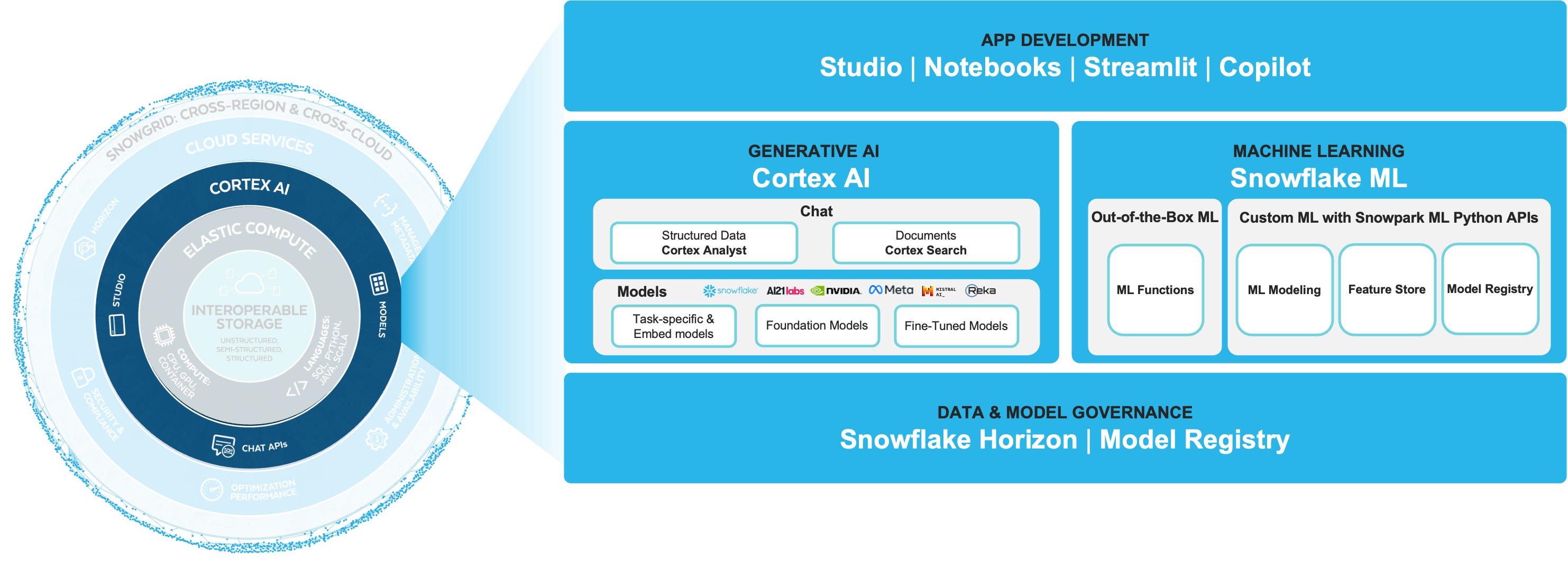
- EASY
- 통합된 데이터 및 AI 인프라로, 개발 비용과 복잡성을 줄일 수 있습니다
- EFFICIENT
- 최신 AI 모델과 프레임워크로 개발부터 배포까지의 주기를 단축시켜, 더 나은 품질과 운영 비용 절감을 실현할 수 있습니다
- TRUSTED
- 보안과 통합된 거버넌스를 통해 데이터를 보호하고, 다양한 조직에서 신뢰할 수 있습니다
4.거버넌스와 자동 관리 서비스

- 완전 관리형 서비스
- 비용이 많이 들고 복잡한 작업을 자동화하여 실수를 줄이고 효율성 증대. 릴리스를 통해 자동으로 투명한 성능 향상 적용
- Near zero management로서 사용자는 데이터 관리가 아닌 비즈니스에 집중할 수 있게 됩니다
- 내장된 단일화된 거버넌스
- 규정 준수, 비즈니스 연속성, 데이터 품질 모니터링 및 데이터 계보(lineage)를 통해 데이터를 보호하고 감사할 수 있습니다.
- 지속적인 리스크 모니터링과 보호 기능, RBAC(역할 기반 접근 제어)*, 세분화된 권한 정책을 통해 환경을 안전하게 보호합니다
- 고급 프라이버시 정책과 데이터 클린룸을 통해 민감한 데이터의 가치를 안전하게 활용할 수 있습니다
- 접근성 및 상호운용성
- Apache Iceberg 호환 카탈로그 및 엔진, 그리고 데이터 카탈로그 및 데이터 거버넌스 파트너와의 통합을 지원합니다.
- 데이터, 애플리케이션 등을 분류하고, 공유하며, 발견하고, 여러 지역 및 클라우드에서 즉각적인 조치를 취할 수 있습니다.
5.리전 및 클라우드간 협업
Snowgrid
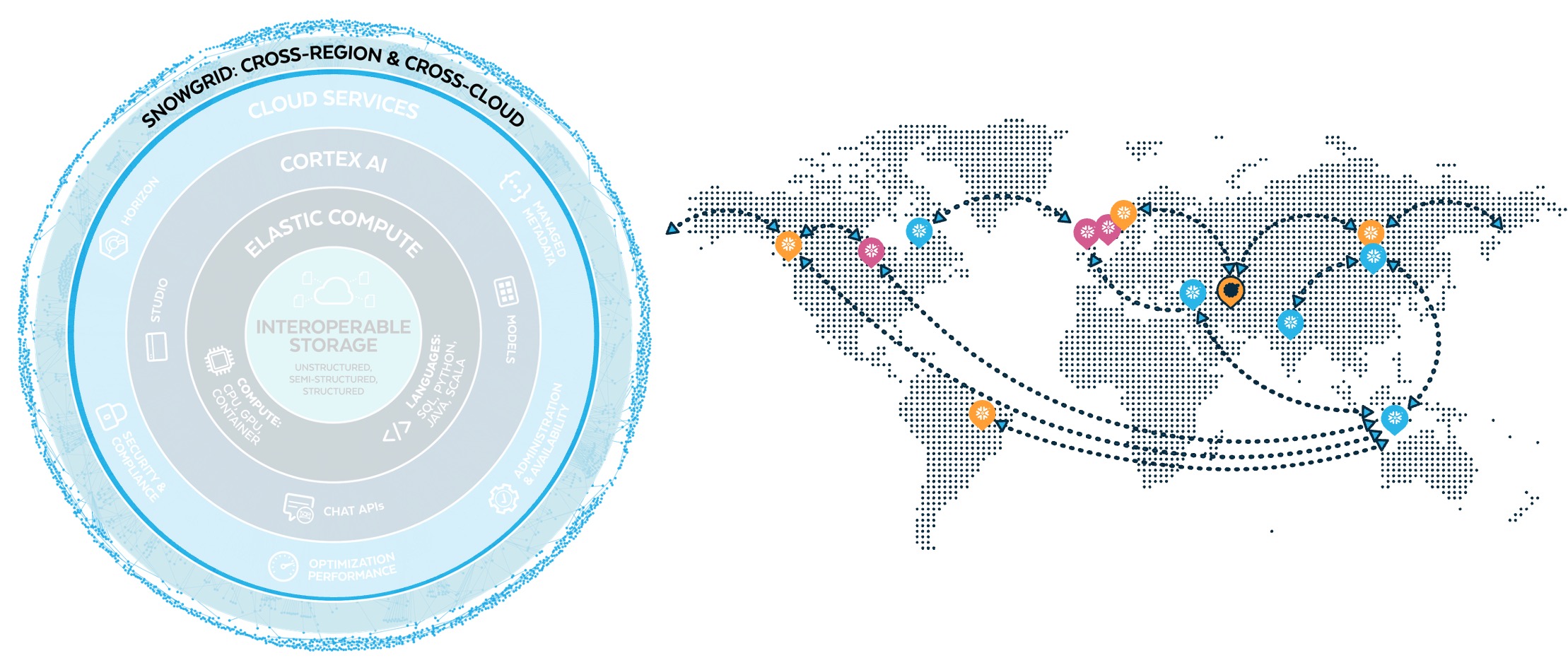
- Cross-Cloud Collaboration
- ETL없이도 전 세계적으로 데이터, 서비스, 앱을 즉시 검색, 액세스, 공유 가능합니다
- Cross-Cloud Governance
- 리전, 클라우드, 사용자 및 워크로드 전반에 걸쳐 보안정책을 시행하여 위험을 최소화하는 동시에 가치를 극대화합니다
- Cross-Cloud Business Continuity
- 업계 최고의 가용성을 가지고 비즈니스 중단을 제거하고, 변화하는 규정이나 통제를 지속적으로 준수합니다

Snowflake Korea SE