0. 실습 시나리오
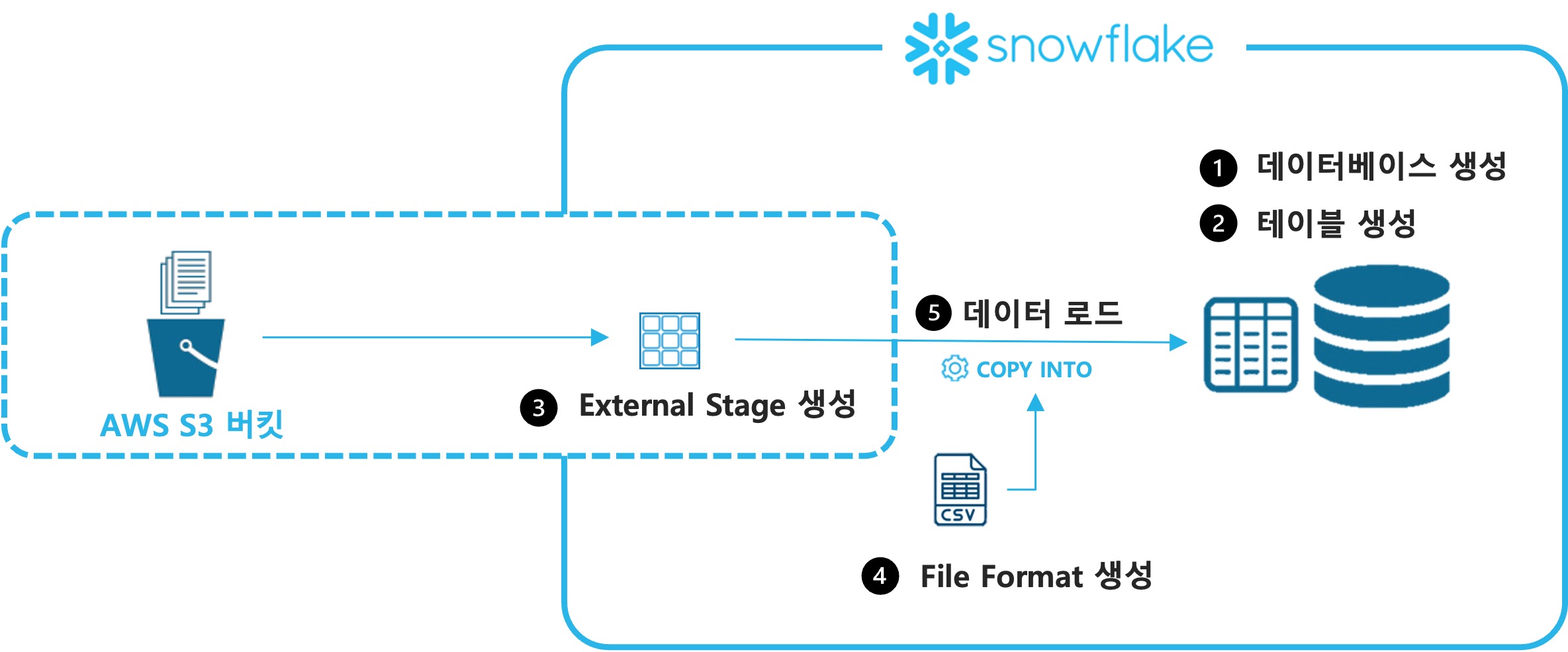
Snowflake의 frostbyte팀이 생성한 Tasty Bytes 데이터를 이용하여 클라우드 스토리지에 있는 정형 데이터를 적재합니다
- 데이터베이스 이름은 tasty_db로 생성합니다
- 두 개의 스키마를 생성합니다
- raw_pos
- raw_customer
- 각 스키마에 아래와 같은 테이블을 생성합니다
- raw_pos.country
- raw_pos.franchise
- raw_pos.location
- raw_pos.truck
- raw_customer.customer_loyalty
- 익스터널 스테이지 s3load를 생성합니다
- 파일 포맷을 정의합니다 : csv_ff
- copy 문장을 이용하여 테이블에 데이터를 초기 적재합니다
1. 데이터베이스 생성
실습에 사용할 데이터베이스를 생성합니다
- Data > Databases
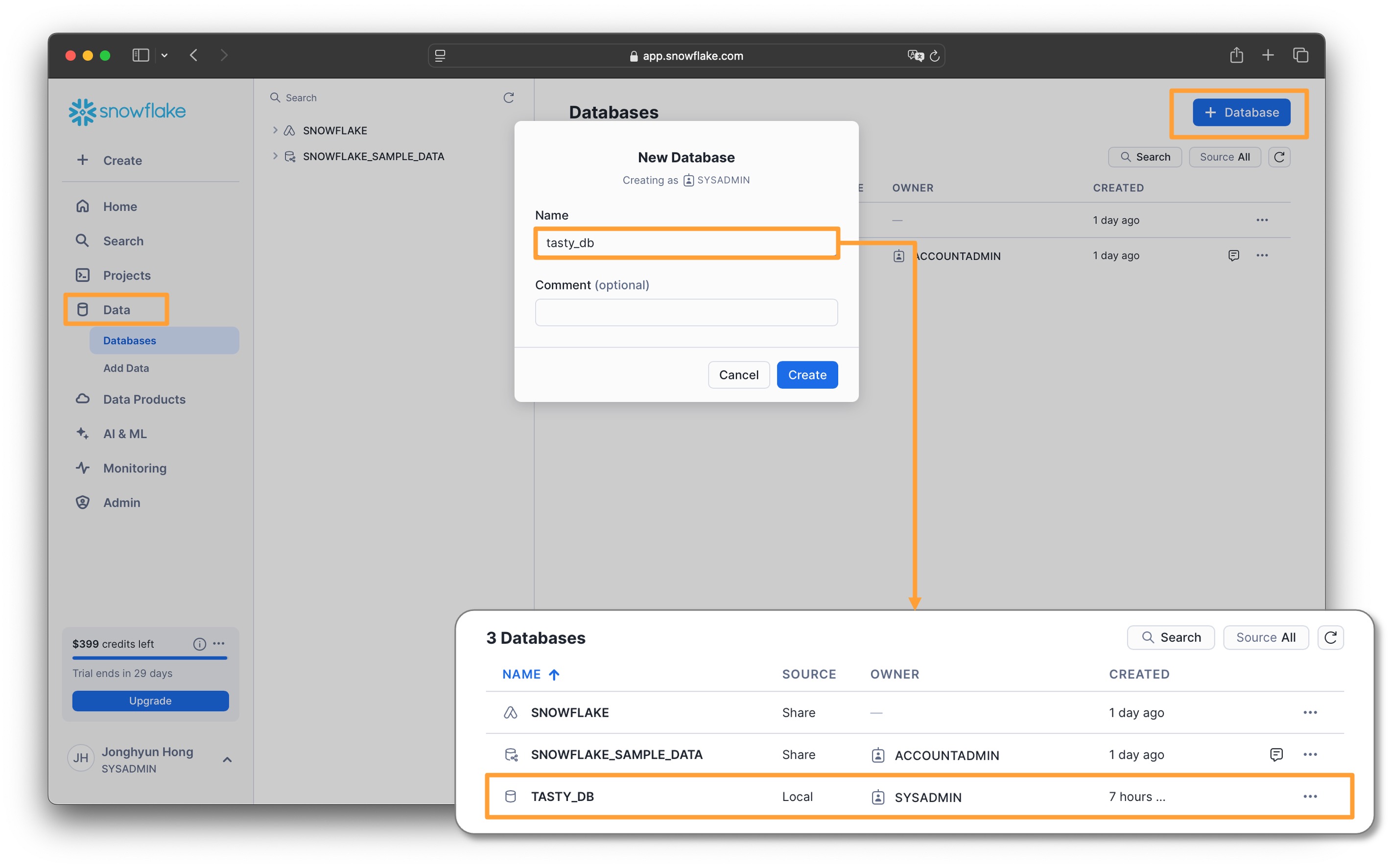
- 오른쪽 상단에서
+ Database버튼을 클릭합니다 - 데이터베이스 이름을 입력합니다 : tasty_db
- 생성된 데이터베이스가 데이터베이스 리스트에서 확입됩니다
다음과 같이 SQL을 이용해서 데이터베이스를 생성할 수도 있습니다// 데이터베이스 생성 USE ROLE sysadmin ; CREATE OR REPLACE DATABASE tasty_db ;
2. 테이블 생성
스키마와 테이블을 생성합니다
-
Projects > Worksheets
-
이전 실습에서 열었던 SQL Worksheet의 이름을 변경합니다
- 시간으로 표시된 Worksheet에서
...를 클릭하여RENAME을 클릭 - Lab2. Data Load로 변경
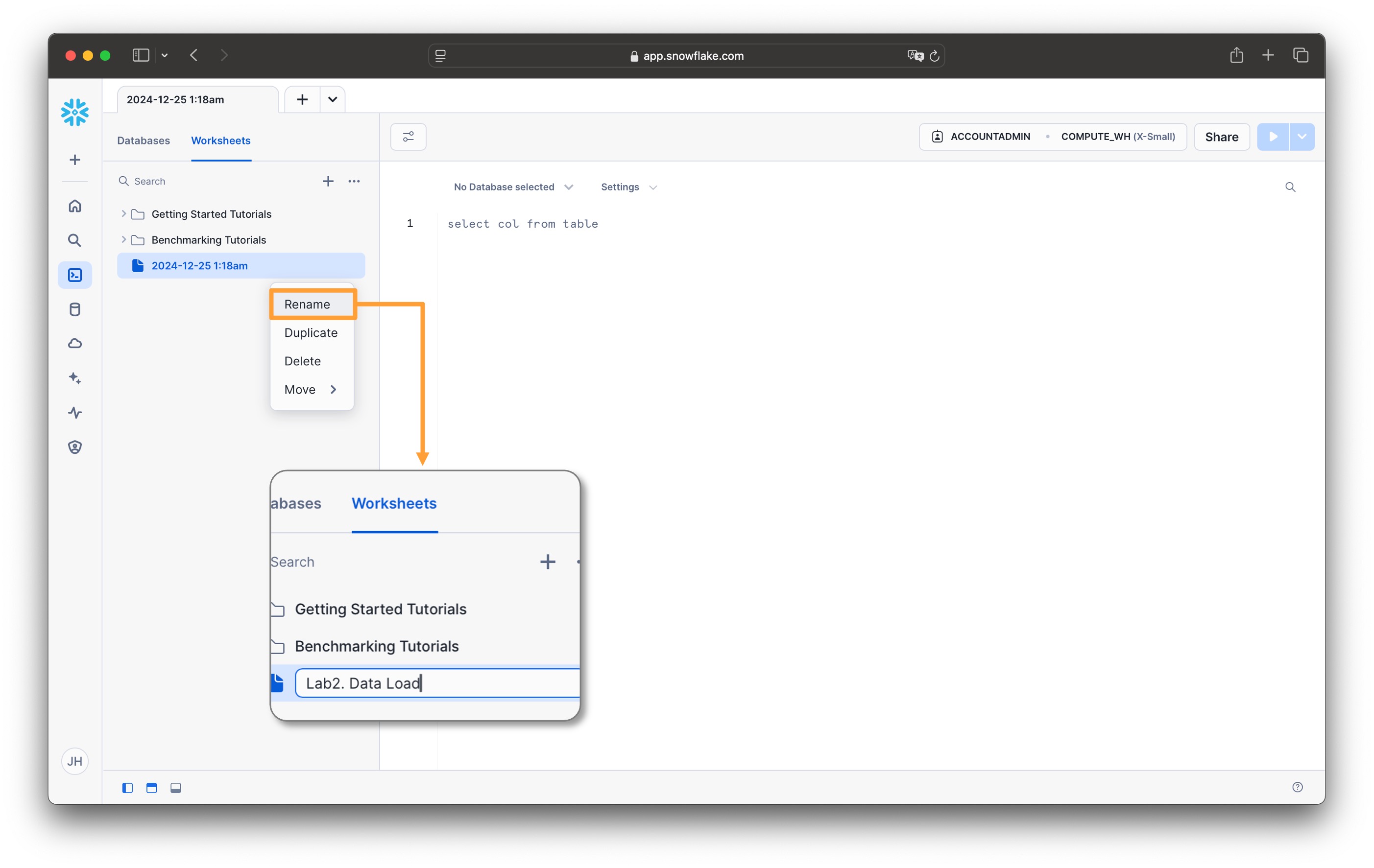
- 시간으로 표시된 Worksheet에서
-
현재 Worksheet의 컨텍스트(context)를 설정합니다
- 우측 상단의 역할(role)을 SYSADMIN으로 설정합니다
- 좌측 상단의 데이터베이스를 TASTY_DB로 설정합니다
다음과 같이 SQL을 이용해서 context를 지정할 수 있습니다// 사용할 데이터베이스 지정 USE ROLE sysadmin ; USE DATABASE tasty_db ;
-
스키마를 생성합니다
// 스키마 생성 CREATE OR REPLACE SCHEMA raw_pos ; CREATE OR REPLACE SCHEMA raw_customer; -
raw_pos 스키마에 다음 테이블을 생성합니다
// raw_pos를 기본 스키마로 지정 USE SCHEMA raw_pos ; // 테이블 country 생성 CREATE OR REPLACE TABLE country ( country_id NUMBER(18,0), country VARCHAR(16777216), iso_currency VARCHAR(3), iso_country VARCHAR(2), city_id NUMBER(19,0), city VARCHAR(16777216), city_population VARCHAR(16777216) ); // 테이블 franchise 생성 CREATE OR REPLACE TABLE franchise ( franchise_id NUMBER(38,0), first_name VARCHAR(16777216), last_name VARCHAR(16777216), city VARCHAR(16777216), country VARCHAR(16777216), e_mail VARCHAR(16777216), phone_number VARCHAR(16777216) ); // 테이블 location 생성 CREATE OR REPLACE TABLE location ( location_id NUMBER(19,0), placekey VARCHAR(16777216), location VARCHAR(16777216), city VARCHAR(16777216), region VARCHAR(16777216), iso_country_code VARCHAR(16777216), country VARCHAR(16777216) ); // 테이블 truck 생성 CREATE OR REPLACE TABLE truck ( truck_id NUMBER(38,0), menu_type_id NUMBER(38,0), primary_city VARCHAR(16777216), region VARCHAR(16777216), iso_region VARCHAR(16777216), country VARCHAR(16777216), iso_country_code VARCHAR(16777216), franchise_flag NUMBER(38,0), year NUMBER(38,0), make VARCHAR(16777216), model VARCHAR(16777216), ev_flag NUMBER(38,0), franchise_id NUMBER(38,0), truck_opening_date DATE ); -
raw_customer 스키마에 다음 테이블을 생성합니다
// raw_customer를 기본 스키마로 지정 USE SCHEMA raw_customer ; // 테이블 customer_loyalty 생성 CREATE OR REPLACE TABLE customer_loyalty ( customer_id NUMBER(38,0), first_name VARCHAR(16777216), last_name VARCHAR(16777216), city VARCHAR(16777216), country VARCHAR(16777216), postal_code VARCHAR(16777216), preferred_language VARCHAR(16777216), gender VARCHAR(16777216), favourite_brand VARCHAR(16777216), marital_status VARCHAR(16777216), children_count VARCHAR(16777216), sign_up_date DATE, birthday_date DATE, e_mail VARCHAR(16777216), phone_number VARCHAR(16777216) );스키마, 테이블 등의 오브젝트를 생성하는 DDL 구문은 컴퓨팅 자원인 가상 웨어하우스를 사용하지 않기 때문에 비용이 발생되지 않습니다
-
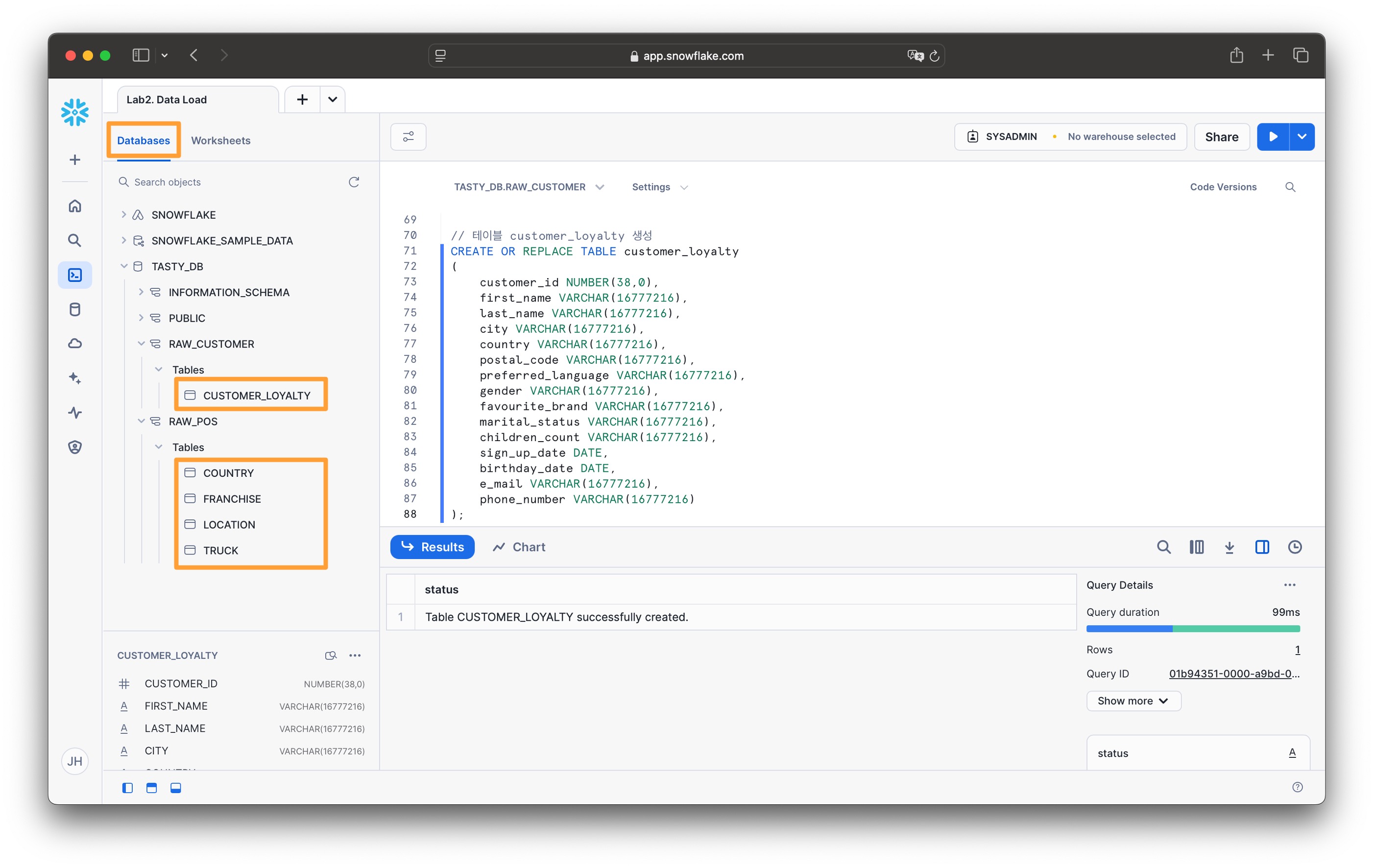
생성된 테이블 목록을 확인해 봅니다
- Data > Databases 또는 Worksheets의 Databases 탭으로 이동
- TASTY_DB > RAW_POS > TABLES
- TASTY_DB > RAW_CUSTOMER > TABLES
목록이 보이지 않으면새로고침(refresh)아이콘을 클릭하세요
3. 익스터널 스테이지 생성
외부 S3 버킷에 있는 데이터를 적재하기 위해서 외부 버킷의 위치를 인식하도록 지정합니다.
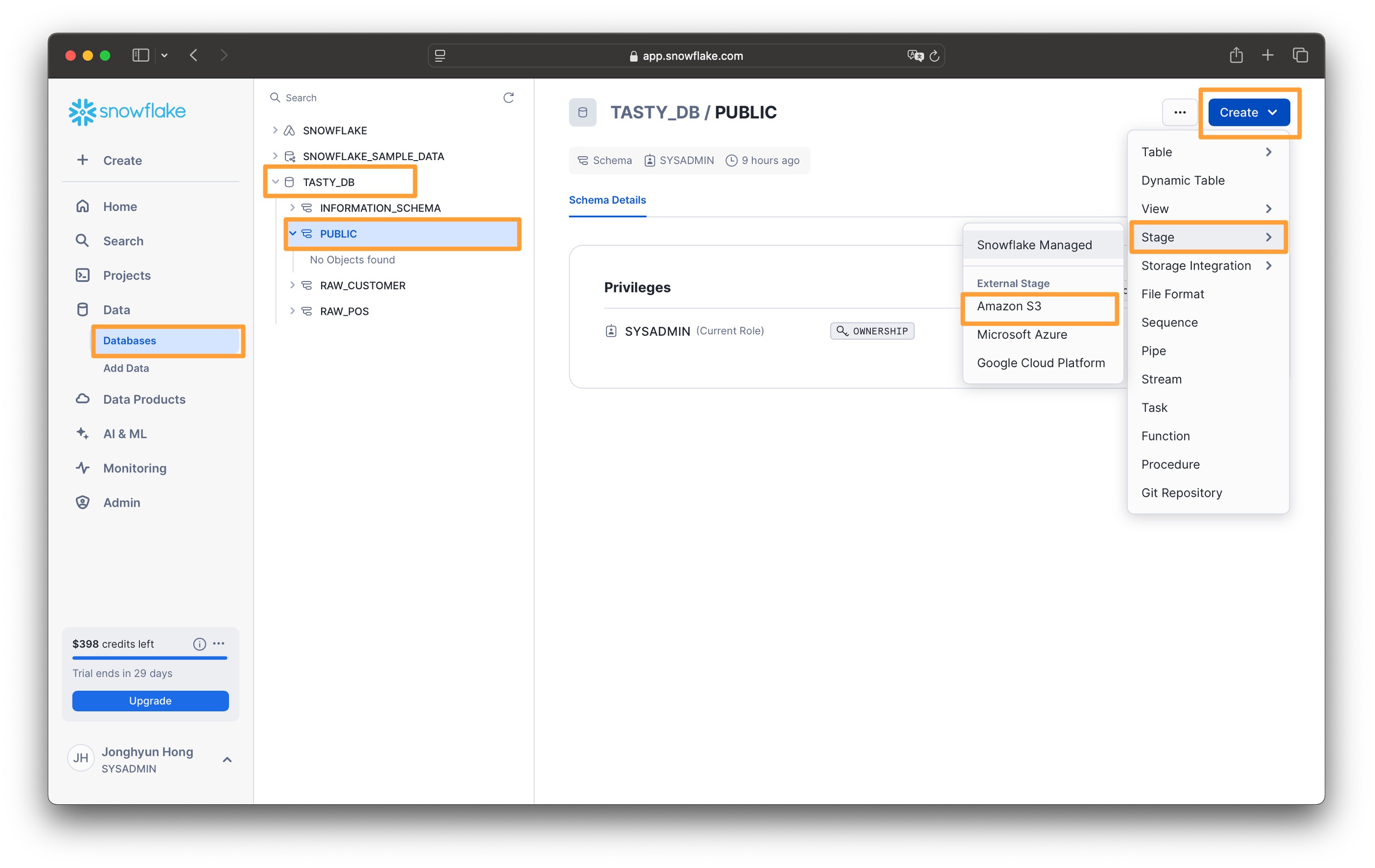
1. Data > Databases 로 이동합니다
2. TASTY_DB 에서 PUBLIC 스키마를 선택합니다
3. 오른쪽 상단의 Create 버튼을 클릭하고 Stage > Amazon S3로 들어갑니다
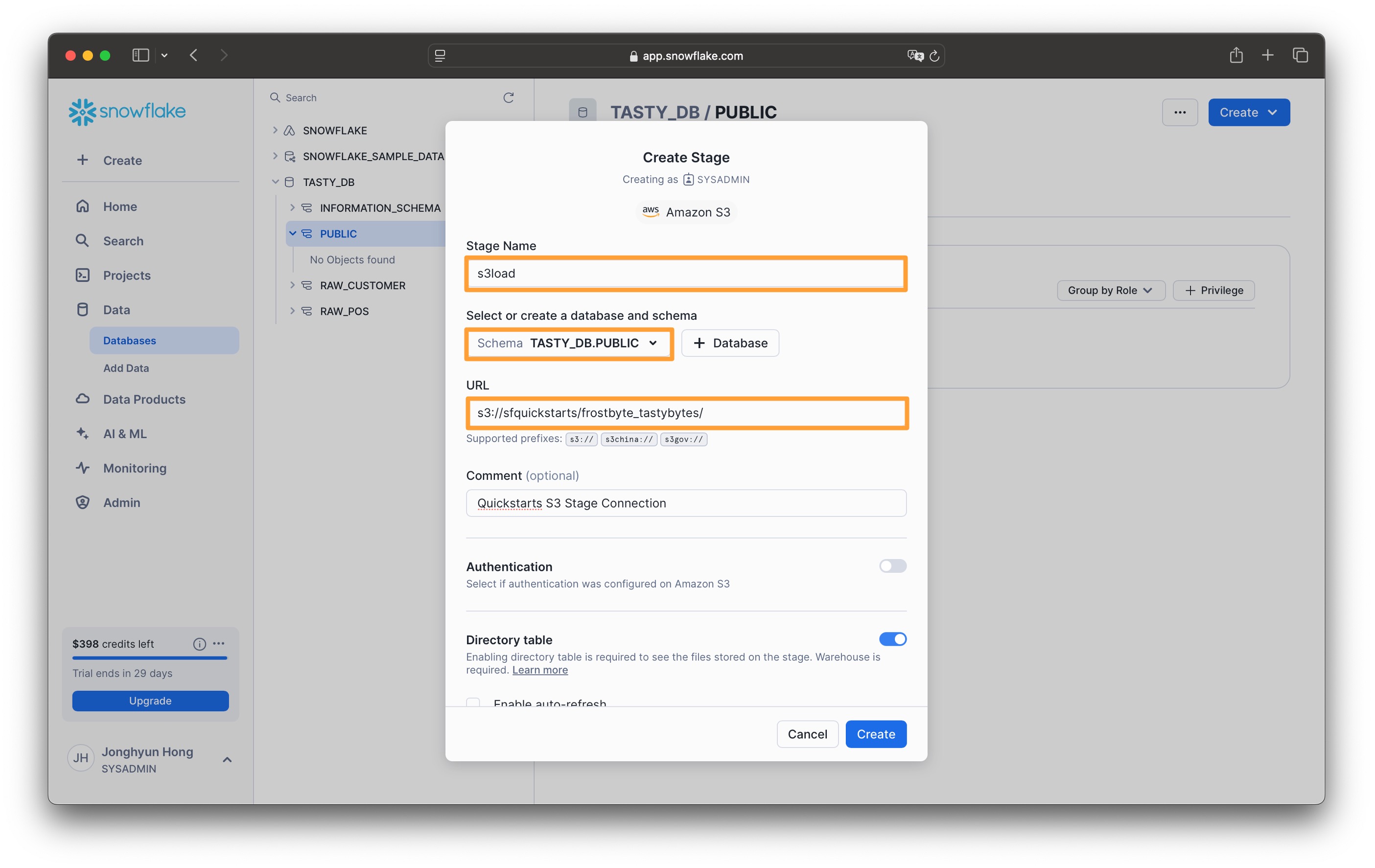
4. Create Stage 창에서 다음과 같이 입력하고 Create 버튼을 클릭합니다
- Stage name : s3load
- URL : s3://sfquickstarts/frostbyte_tastybytes/
이 과정은 SQL Worksheet에서도 다음의 DDL을 실행하여 external stage를 만들 수 있습니다// 익스터널스테이지 생성 CREATE OR REPLACE STAGE public.s3load COMMENT = 'Quickstarts S3 Stage Connection' url = 's3://sfquickstarts/frostbyte_tastybytes/' ;
- Worksheet에서 다음을 차례로 실행하여 S3에 저장된 데이터 목록을 확인해 봅니다
// 익스터널스테이지의 파일 확인 LIST @public.s3load ; LIST @public.s3load/raw_pos/ ; LIST @public.s3load/raw_customer/ ;
4. 파일 포맷 생성
데이터 적재를 위해서 데이터 구조를 설명하는 파일 형식을 정의합니다.
-
CSV 파일 포맷을 정의합니다
// 파일 포맷 정의 CREATE OR REPLACE FILE FORMAT public.csv_ff type = 'csv'; -
다음 SQL을 실행하여 생성된 CSV 파일 포맷 정의를 확인합니다
// 파일 포맷 확인 SHOW FILE FORMATS IN DATABASE tasty_db ;
- 참고
- format_options 컬럼에는 해당 데이터 타입의 상세 옵션이 지정되어 있습니다.
- 현재는 명시적으로 지정된 옵션이 없기 때문에 모두 디폴트값을 사용하고 있습니다
| 파라매터 | 설명 | 기본값 |
|---|---|---|
| TYPE | CSV,JSON,AVRO,ORC,PARQUET,XML | |
| RECORD_DELIMITER | 레코드 구분자 설정 | \n |
| FIELD_DELIMITER | 필드 구분자 설정 | , |
| FILE_EXTENSION | 스테이지로 언로딩된 파일의 확장명을 지정 | |
| SKIP_HEADER | 파일 시작에서 건너뛸 줄의 개수 | 0 |
| PARSE_HEADER | 컬럼명을 결정하기 위해 데이터 파일의 첫 번째 행을 사용할지 여부 | false |
| DATE_FORMAT | 날짜형식 | AUTO |
| TIME_FORMAT | 시간형식 | AUTO |
| TIMESTAMP_FORMAT | 타임스탬프 형식 | AUTO |
| BINARY_FORMAT | 이진 입력 또는 출력의 인코딩 형식을 정의 : HEX,BASE64,UTF8 | HEX |
| ESCAPE | 이스케이프 문자로 사용되는 문자 지정 | NONE |
| ESCAPE_UNENCLOSED_FIELD | 괄호로 묶이지 않은 필드 값에 대해서만 이스케이프 문자지정 (예, \134 : 백슬래시) | \ \ |
| TRIM_SPACE | 데이터 필드의 공백 제거 여부 | false |
| FIELD_OPTIONALLY_ENCLOSED_BY | 문자열을 묶는데 사용되는 문자 지정 (예, \042 : 큰따옴표) | NONE |
| NULL_IF | NULL값으로 변환할 문자열 지정 | \ \N |
| COMPRESSION | AUTO : 압축 알고리즘 자동 감지 (참고) 지원알고리즘 : gzip,bz2,brotli,zstd,deflate,raw_deflate | AUTO |
| ERROR_ON_COLUMN_COUNT_MISMATCH | 입력 파일의 컬럼 수가 테이블의 컬럼 수와 일치하지 않는 경우 구문 분석 오류를 생성할지 여부 | true |
| SKIP_BLANK_LINES | 데이터 파일에서 발견되는 빈 줄을 건너뛰도록 지정 | false |
| REPLACE_INVALID_CHARACTERS | 유효하지 않은 UTF-8 문자를 유니코드 대체 문자(�)로 대체할지 여부를 지정 | false |
| EMPTY_FIELD_AS_NULL | 데이터를 로딩할 때 입력 파일의 빈 필드에 SQL NULL을 삽입할지 여부 | true |
| SKIP_BYTE_ORDER_MARK | 데이터 파일의 BOM(바이트 순서 표시)를 건너뛸지 여부 | true |
| ENCODING | 데이터를 테이블로 로딩할 때 원본 데이터의 문자 세트를 지정 | UTF8 |
5. 데이터 적재
이제는 COPY 명령을 사용하여 external stage에 있는 csv 형태의 파일의 데이터를 앞에서 생성한 테이블에 로드 (bulk loading)합니다
-
데이터를 로드하기 위해서 다음과 같은 COPY 구문을 사용합니다
// raw_pos 스키마 지정 USE SCHEMA raw_pos ; // country 테이블 데이터 적재 COPY INTO country FROM @public.s3load/raw_pos/country/ file_format = (format_name = 'public.csv_ff') ;이런!! 오류가 발생했습니다. 지금까지는 DDL 작업만 있었기 때문에 컴퓨팅이 필요 없었지만 이제는 데이터를 로드하기 위해서 컴퓨팅 파워가 필요하게 되었습니다.

Snowflake의 컴퓨팅 노드는 가상 웨어하우스 (Virtual Warehouse)라고 하는데, worksheet에서 가상 웨어하우스를 지정하고 COPY를 실행해야 합니다. 데이터 적재를 위해서 가상 웨어하우스를 먼저 만들겠습니다. -
가상 웨어하우스 (Virtual Warehouse) 생성
- Admin > Warehouses
- 우측 상단의
+ Warehouse버튼을 클릭하고 다음과 같이 입력합니다- Warehouse Name : demo_build_wh
- Warehouse Size : xsmall
- Auto-resume : check
- Auto-suspend : check
- Suspend After 1 min(s) of inactivity
Create Warehouse를 클릭합니다
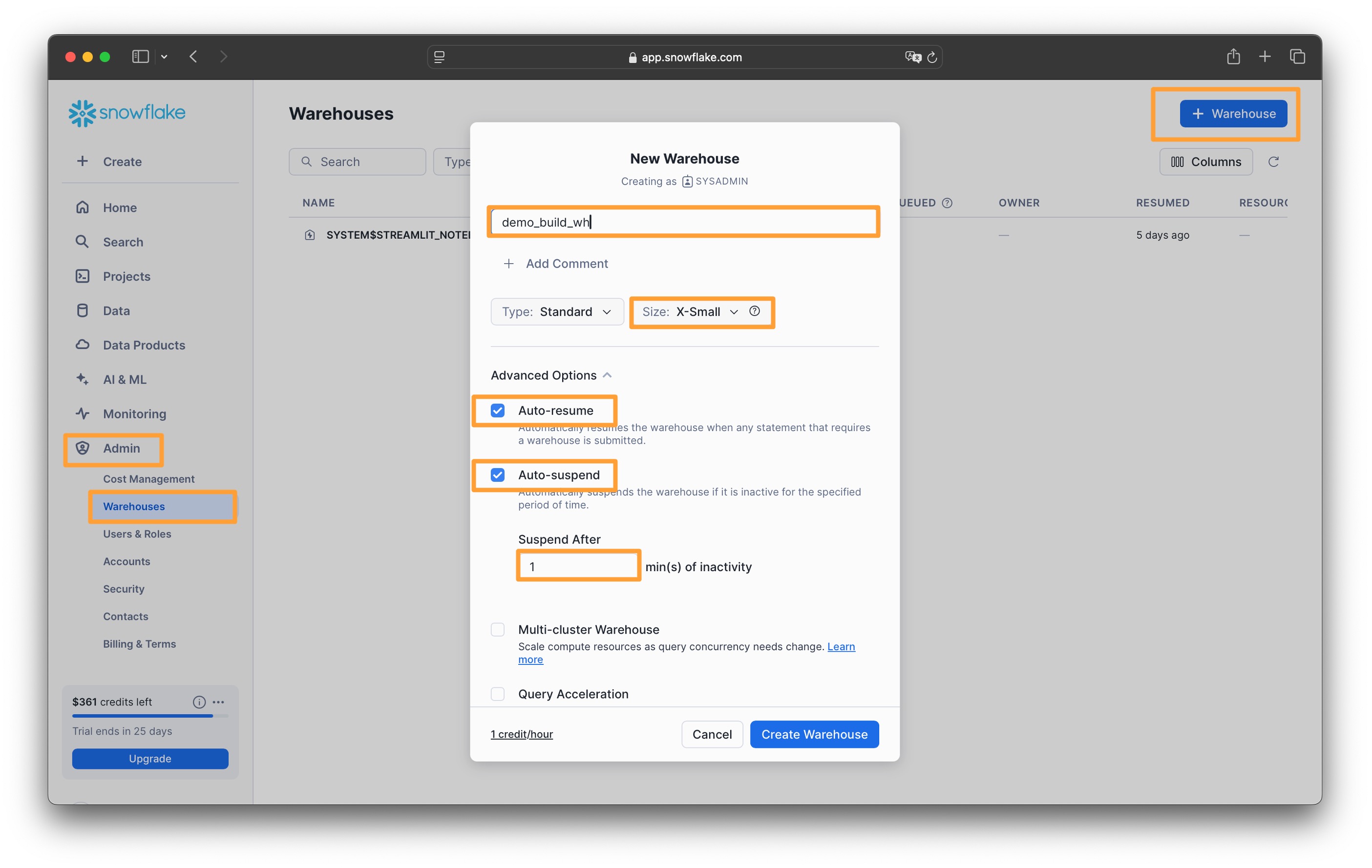
이 작업은 다음과 같이 워크시트에서도 생성할 수 있습니다// 웨어하우스 생성 CREATE OR REPLACE WAREHOUSE demo_build_wh WAREHOUSE_SIZE = 'xsmall' WAREHOUSE_TYPE = 'standard' AUTO_SUSPEND = 60 AUTO_RESUME = TRUE INITIALLY_SUSPENDED = TRUE ;
-
다시 이전에 작업하던 worksheet로 돌아와서 웨어하우스를 지정하고 COPY를 실행합니다
// 웨어하우스 지정 USE WAREHOUSE demo_build_wh ; // raw_pos 스키마 지정 USE SCHEMA raw_pos ; // country 테이블 데이터 적재 COPY INTO country FROM @public.s3load/raw_pos/country/ file_format = (format_name = 'public.csv_ff') ;이제 정상적으로 실행되었습니다. 실행 결과에는 데이터 파일 및 로드된 데이터 행수와 에러수가 출력됩니다. 실행 결과의 오른편에서는 실행 시간 등의 간략한 통계를 볼 수 있습니다.
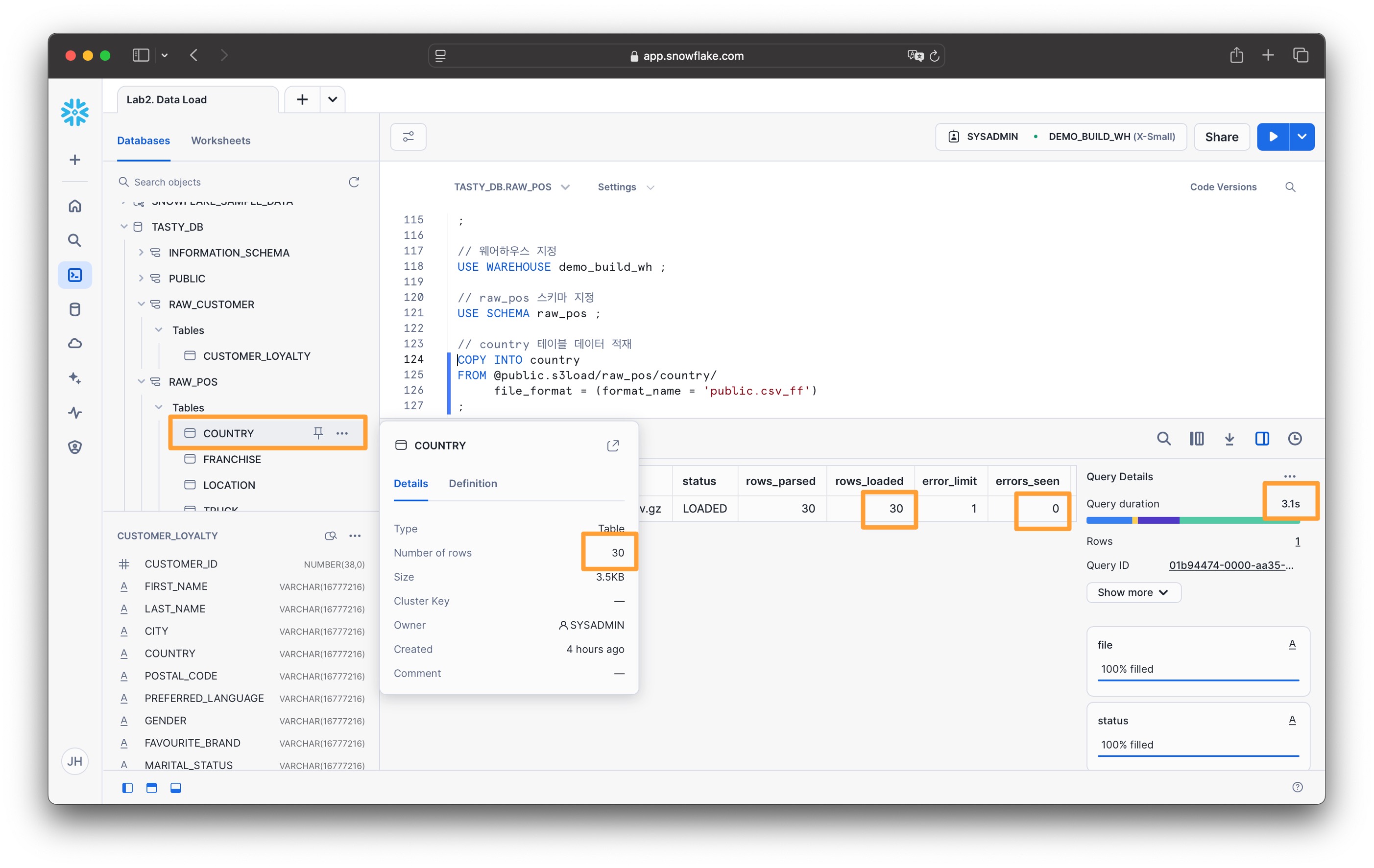
-
나머지 테이블도 모두 적재합니다
// raw_pos 스키마의 나머지 테이블 적재 USE SCHEMA raw_pos ; // franchise 테이블 데이터 적재 COPY INTO franchise FROM @public.s3load/raw_pos/franchise/ file_format = (format_name = 'public.csv_ff') ; // location 테이블 데이터 적재 COPY INTO location FROM @public.s3load/raw_pos/location/ file_format = (format_name = 'public.csv_ff') ; // truck 테이블 데이터 적재 COPY INTO truck FROM @public.s3load/raw_pos/truck/ file_format = (format_name = 'public.csv_ff') ; // raw_customer스키마의 테이블 데이터 적재 USE SCHEMA raw_customer ; COPY INTO customer_loyalty FROM @public.s3load/raw_customer/customer_loyalty/ file_format = (format_name = 'public.csv_ff') ; -
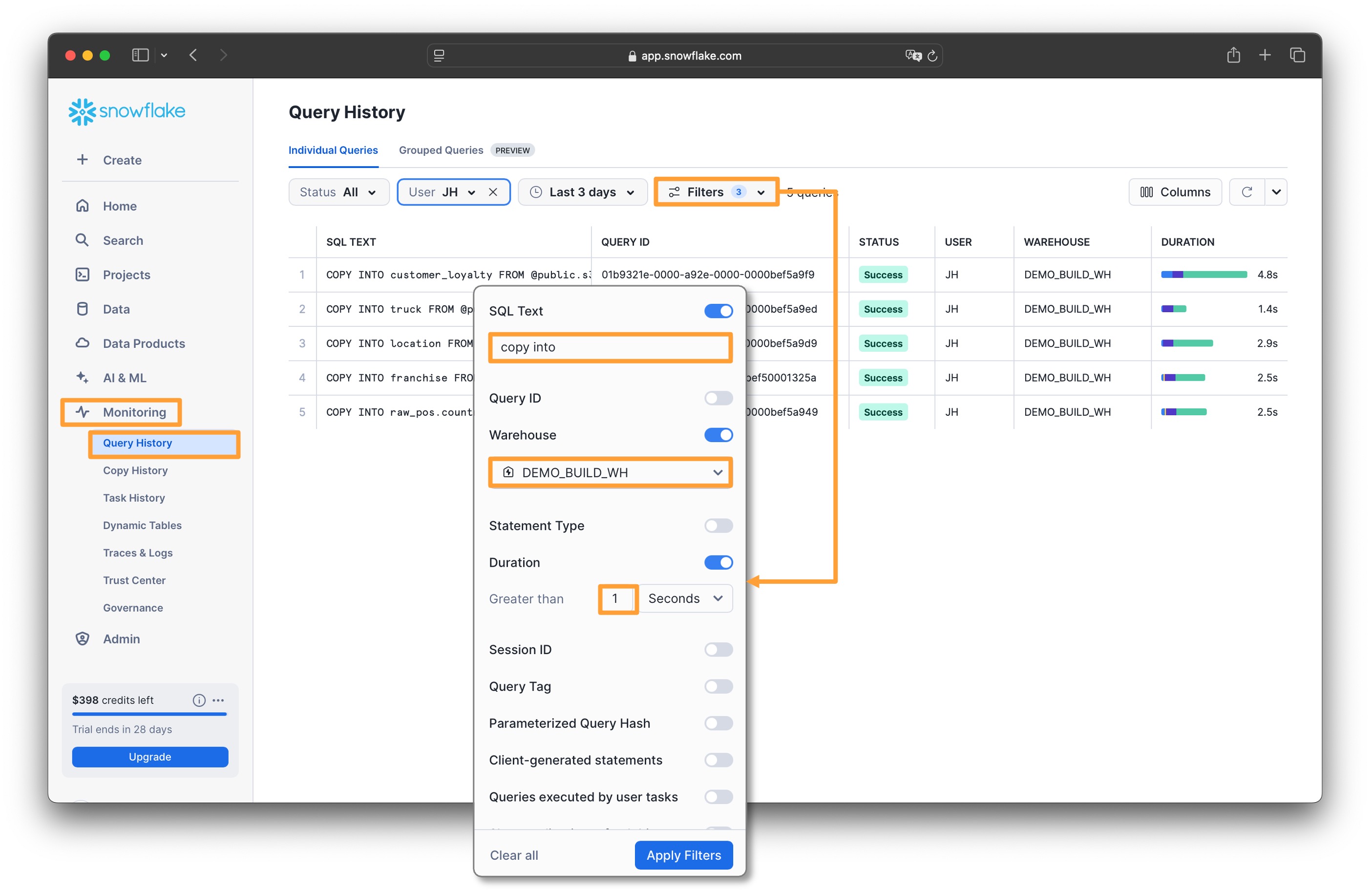
데이터 적재 결과를 모니터링 합니다
- Monitoring > Query History
- 상단의 Filters를 클릭하여 다음 필터 조건을 추가합니다
- SQL Text : copy into
- Warehouse : DEMO_BUILD_WH
- Duration : 1 Seconds
Apply Filters를 클릭하여 필터 조건을 적용합니다