이전 두개의 포스팅에서 카프카의 개념 및 주요 내용에 대해 다루었다.
이제 윈도우 환경에서 카프카를 실제로 테스트 해보도록 한다.
카프카의 기본 구성 요소 등을 모두 학습했다는 가정하에 작성하였다.
실행 환경: Window
기본 설치 요소: Java, Zookeeper, Kafka
kafka 설치 폴더 경로: C:\kafka\kafka_2.13-3.3.1
📌 실행에 필요한 기본 환경 구축
👉 Java 설치
주키퍼는 독립적으로 사용이 불가능하며 자바에 의존성이 있기 때문에, 오라클 자바를 설치해야 한다.
설치 후 경로를 복사하여 시스템 속성 > 고급 > 환경 변수 > 시스템 변수 항목에 다음을 추가해준다.
JAVA_HOME = C:\Program Files\ojdkbuild\java-1.8.0-openjdk-1.8.0.332-1 (본인의 자바 설치 경로)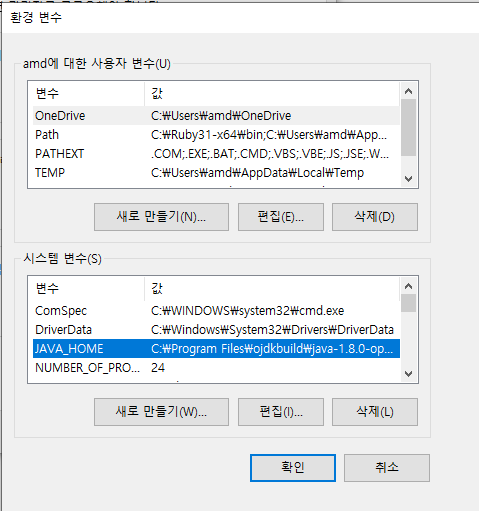
👉 Zookeeper 설치
- https://archive.apache.org/dist/zookeeper/stable/
- 카프카를 띄우기 위해 반드시 실행해야 하는 주키퍼를 다운로드한다.

👉 Kafka 설치
- https://kafka.apache.org
- 위의 경로에서 tgz 파일을 다운받은 후 적절한 경로에 압축을 해제한다.

📌 실행해보기
1. Zookeeper 서버 띄우기
- 윈도우 cmd 창을 열고 주키퍼를 띄운다.
- kafka 설치 경로에서 실행한다. (예제의 경우, C:\kafka\kafka_2.13-3.3.1)
C:\kafka\kafka_2.13-3.3.1> .\bin\windows\zookeeper-server-start.bat config\zookeeper.properties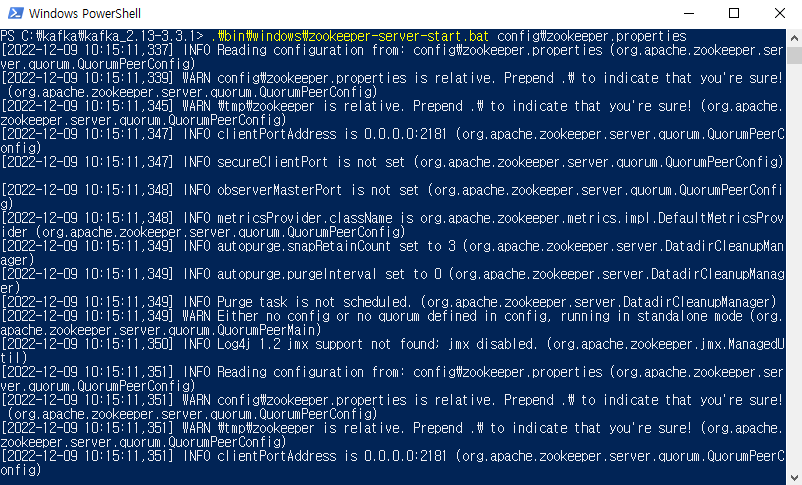
그러면 위와 같이 이런 저런 메시지들이 나오고, 주키퍼가 정상 실행 되었음을 알리는 zookeeper 문구를 확인할 수 있다.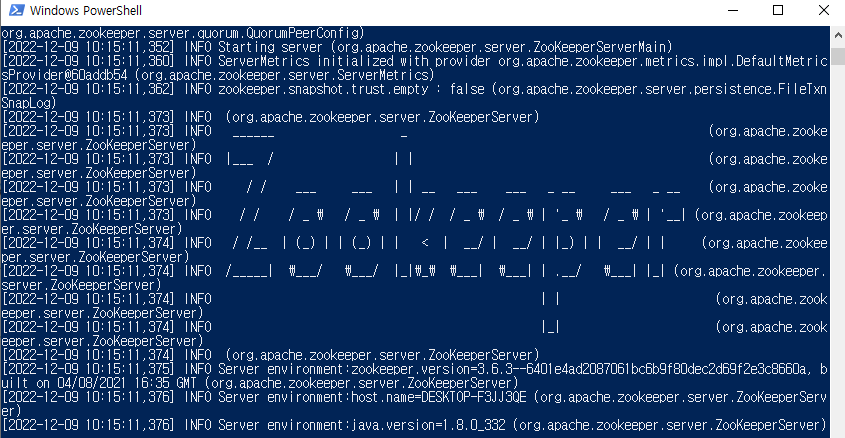 그리고 하단으로 쭉~스크롤하면 커서가 깜빡깜빡 하고 있을 것이다. 여기까지 왔다면 주키퍼 띄우기 성공이다.
그리고 하단으로 쭉~스크롤하면 커서가 깜빡깜빡 하고 있을 것이다. 여기까지 왔다면 주키퍼 띄우기 성공이다.
2. Kafka 서버 띄우기
- 위에서 띄운 cmd 창은 그대로 두고, 다른 cmd 창을 열어 이번에는 kafka를 띄워본다.
- 역시 이전과 동일한 경로에서 진행한다.
C:\kafka\kafka_2.13-3.3.1> .\bin\windows\kafka-server-start.bat config\server.properties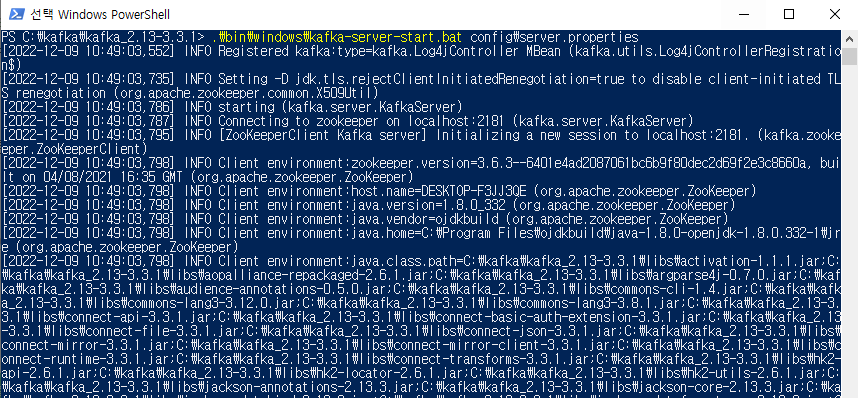
❌ 그런데 나는 이 과정에서 에러를 마주했다. ❌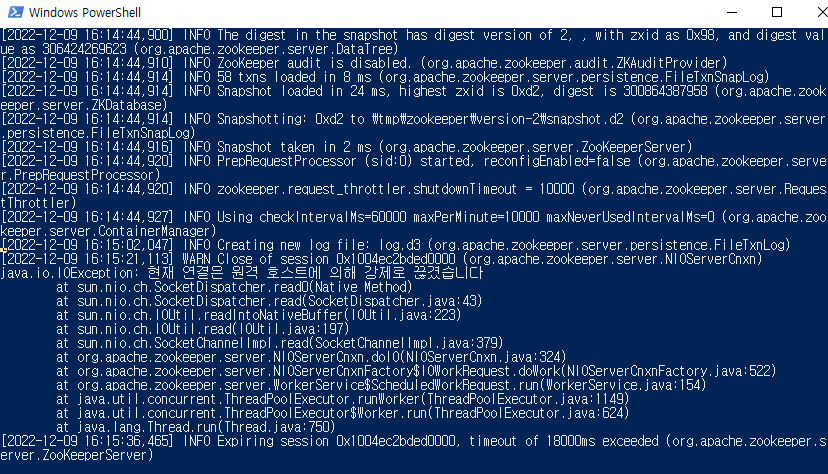 1에서 실행한 주키퍼 서버에서 "java.io.IOException: 현재 연결은 원격 호스트에 의해 강제로 끊겼습니다" 와 같은 에러 메시지가 나타났고, 카프카 서버 실행을 시도했던 cmd 창에서도 다음과 같은 메시지와 함께 이 과정에 실패하였다.
1에서 실행한 주키퍼 서버에서 "java.io.IOException: 현재 연결은 원격 호스트에 의해 강제로 끊겼습니다" 와 같은 에러 메시지가 나타났고, 카프카 서버 실행을 시도했던 cmd 창에서도 다음과 같은 메시지와 함께 이 과정에 실패하였다.

구글링 후, 다음과 같은 방법으로 해결하였다.
..
log.dirs=/tmp/kafka-logs
..카프카 설치 디렉토리/config/server.properties 파일의 log.dirs 항목에서 설정되어 있는 카프카 log path로 가보면 meta.properties라는 파일이 있다. 해당 파일을 지워주고 카프카를 재시작하였다.
실행 과정 중 비슷한 오류가 몇 번 있었다.zookeeper, kafka를 실행시키면 기본적으로 C:\tmp 위치에 로그 정보가 생성된다. 이전에 설치되었던 정보가 있거나 실행 시 오류가 발생할 경우 tmp 폴더를 제거하고 zookeeper와 kafka를 다시 실행시키면 대부분 정상 동작한다.
 역시, 1의 결과와 동일하게 메시지가 쭈욱 나온다. 실행 성공!🙆♀️
역시, 1의 결과와 동일하게 메시지가 쭈욱 나온다. 실행 성공!🙆♀️
3. Kafka 토픽 생성하기
이제 실행에 필요한 환경은 구축하였다. 실제로 토픽을 생성해보자.
- 이번에도 새로운 cmd 창을 열어 진행한다.
C:\kafka\kafka_2.13-3.3.1\bin\windows> .\kafka-topics.bat --create --topic [topic name] --bootstrap-server [host]:[port] --partition 1- 옵션:
--create --topic: 토픽을 생성한다.
--bootstrap-server: 클라이언트가 접근하는 토픽의 메타데이터를 요청하여 원하는 브로커를 찾기 위한 설정이다.
--replication factor n: 토픽의 파티션 복제본 개수를 설정한다.
--partition n: 파티션의 개수를 설정한다.
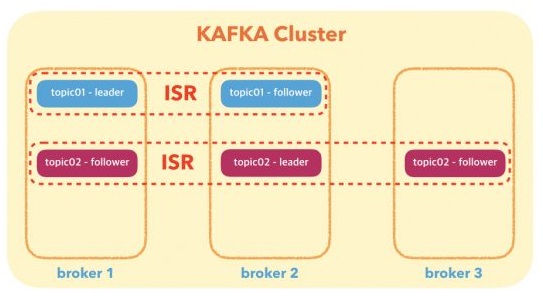
🤚 여기서, replication factor란?
토픽 파티션의 복제본을 몇 개를 생성할 지에 대한 설정이다.
eg) replication factor:3 -> 복제본을 2개 생성한다.
메시지를 복제해 관리하면서, 장애 발생시 신속하게 작업을 이어 받아 다른 브로커가 역할을 대신할 수 있도록 도와줄 수 있다. 중요한 데이터의 경우 replication factor를 크게 설정하는 것이 데이터 처리에 효과적일 것이다.
하지만, replication factor가 많다고 무조건 좋은 것은 아니다. 데이터 복제로 인한 성능이 저하될 수 있는 점은 고려해 설정하는 것이 좋다.
여기서의 ISR(In-Sync Replication)은 replication factor의 group이라고 볼 수 있다. 각각의 동일한 replication factor로 묶인 그룹을 의미한다.
 토픽 생성 결과를 확인해보자.
토픽 생성 결과를 확인해보자.
매우 단순하다. 내가 지정한 토픽명(new-topic)이 생성되었다.🙂
Created topic new-topic.4. Producer로 Topic에 메시지 전달하기
이제 메인 기능, 위에서 생성한 토픽에 실제 메시지를 전달해보자.
(토픽 명: new-topic/ localhost:9092)
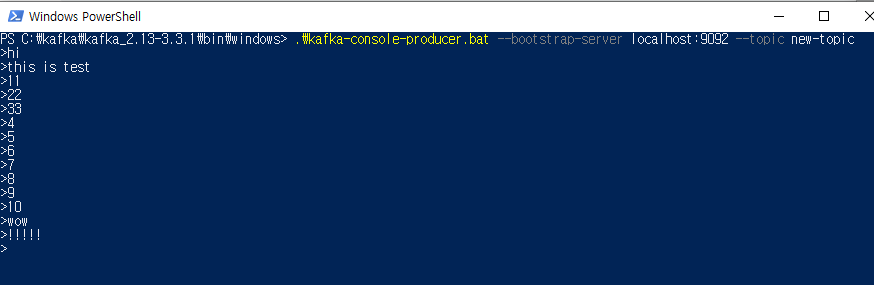
C:\kafka\kafka_2.13-3.3.1\bin\windows> .\kafka-console-producer.bat --broker-list localhost:9092 --topic new-topic 다음과 같이 new-topic에 여러 개의 메시지를 전송하였다.
5. 생성한 Topic Consumer로 구독해 데이터 받아오기
이제 Producer가 발행한 메시지를 Consumer가 받아올 차례이다.
- 새로운 cmd 창을 열어 앞에서 생성한 토픽을 구독해보자.
C:\kafka\kafka_2.13-3.3.1\bin\windows> .\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic new-topic --from-beginning- 옵션:
--from-beginning: 이전의 데이터를 모두 출력한다.
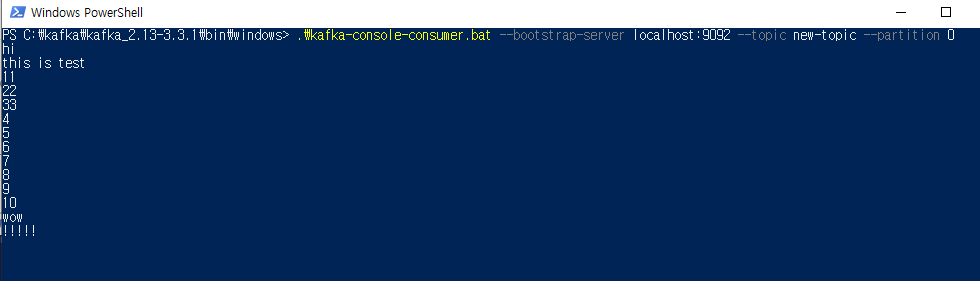 프로듀서가 보낸 데이터 그대로 실시간으로 컨슈머가 수신하는 것을 확인할 수 있다.
프로듀서가 보낸 데이터 그대로 실시간으로 컨슈머가 수신하는 것을 확인할 수 있다.
마치며,
지금까지 윈도우 로컬 환경에서 가벼운 예제로 카프카- 프로듀서와 컨슈머를 실습해보았다. 상용 서버에 적용할 때에는 카프카 전용 서버도 따로 두는 등 기본적인 환경부터 다르겠지만, 개념을 익히며 가볍게 이해해 본 정도로 오늘은 여기에서 마무리한다.
이후에는 한 단계 더 나아가서 파이썬에서 많은 양의 데이터를 주고 받아 테이블에 insert하는 예제도 다뤄보아야겠다. 🙋
